
特征增强U形网络的图像语义分割
2021-12-21 11:18:02陈乔松段博邻官暘珺范金松
重庆邮电大学学报(自然科学版) 2021年6期
陈乔松,段博邻,官暘珺,范金松,邓 欣,王 进
(重庆邮电大学 数据工程与可视计算重庆市重点实验室,重庆 400065)
0 引 言
图像语义分割技术广泛应用于人工解析、虚拟现实、自动驾驶汽车等领域。语义分割目标是区分图像场景所包含的具有不同语义的目标和区域,并对它们进行像素级别的标注,它隐含地涉及了图像分类、对象定位和边界描绘等问题,复杂场景中的分割目标种类多而且尺度变化大。因此,图像语义分割是一项需要多尺度和多层次识别的计算机视觉任务。随着卷积神经网络(convolutional neural networks,CNNs)的快速发展,一种全卷积神经网络(fully convolutional network,FCN)[1]方法逐渐代替了传统的图像分割方法,因其具有层次特征提取和实现了端到端训练结构,后来很多基于全卷积神经网络的方法在像素级别的语义分割任务中都取得了不错的效果。
语义分割任务面临的一个挑战是图像中存在多尺度的目标,神经网络需要同时学习到大尺度的显著目标和较小尺度的非显著目标,而深度卷积神经网络善于学习到整个图像的抽象特征表示,这导致图像的每个区域里更加显著的目标特征更容易被学习到,同时起主导性的作用来影响网络对邻近的微弱目标特征进行学习,从而不利于对具有很多细小尺度目标的复杂场景进行语义分割,现有的一些语义分割方法在利用编码器提取语义特征过程中,采用多尺度卷积来兼顾对大尺度和小尺度目标特征的学习,取得了不错的效果。但没有特殊考虑小尺度的非显著目标特征点容易受到周围显著特征点支配的问题,为使网络能够提取区分周围特征的局部感知特征,我们在编码结构的基础上,提出局部特征增强模块(local feature enhanced, LFE)并作用在基础特征网络的末端,将局部的特征与周围的多尺度多层次的特征形成对比,从而起到局部特征增强的作用。
完整的卷积神经网络各层分工明确,较浅层负责提取边缘、纹理、形状等信息,而较深层负责在前面提取的特征基础上获得更加具体的个体目标特征,更接近实际场景中的完整事物,由此可见,网络中深层特征图与浅层特征图的差异性。另外,随着网络层的加深,特征图分辨率减小,包含空间细节信息越少,得到分割结果前要进行分辨率的重建,成为语义分割任务的另一个难点。目前一类U形网络(编码器-解码器)方法,将深层特征图与前面编码阶段的浅层特征图进行简单融合来解码更多的空间细节信息。但这些方法没有考虑深浅层特征图之间的特征表示差异,从而可能导致最终同类像素预测的不一致。浅层特征图融合前需要更多的全局上文信息来过渡,采用全局池化方法设计全局特征增强模块(global feature enhanced, GFE)来改善解码阶段的深浅层特征图的融合,考虑深层特征图每个通道实际上是对不同类别特征的响应,利用各通道的全局信息形成影响因子来增强浅层特征图中对应类别的特征,保证对融合后特征图中同一类别像素的预测一致。
1 相关工作
复杂场景中的分割目标具有多尺度的特点,为实现针对每个尺度目标进行特征学习,出现了DeepLab系列[2-3]方法,采用不同比率的空洞卷积(atrous conv)实现多尺度结构,PSPNet[4]利用空间金字塔池化(spatial pyramid pooling,SPP)来提取多尺度的目标特征,但空洞卷积和金字塔池化可能导致像素定位信息的丢失。另一种解决方法是将输入图像调整为多种分辨率分别送入网络中进行训练,将输出的各特征图进行融合达到多尺度学习的效果,例如ICNet[5]等结构,但大量的计算和网络对图像输入尺寸的限制也成为了该类方法的弊端。
随着卷积网络层数的加深,网络层得到的特征图更加抽象,分辨率减少导致大量空间信息即细节信息丢失,为重建分辨率直到特征图恢复到输入图像尺寸,出现一种编码器加解码器的U形结构,最早由Ronneburger等[6]提出U-Net,在解码过程中将每个阶段上采样过后的特征图与前面的编码器对应阶段特征图进行融合,用浅层特征图来帮助深层特征图恢复细节信息,但直接融合操作可能导致网络对同一目标的分类结果不一致。类似的编码解码网络如RefineNet[7],GCN[8],DDSC[9],都是分辨率重建过程中设计复杂的解码模块来提升分割效果,但也增加了网络的学习复杂度。其他轻量的U型结构如SegNet[10],ENet[11],DeconvNet[12],则是编码器和解码器的结构比较平衡,但也只能获得中等的分割效果。为实现同时提取语义特征和空间细节特征,也出现了BiseNet[13]等两分支网络的结构。针对以上问题,本文方法同样采用U形结构,从方法[14]谈及的神经网络浅层和深层表达特征的差异性出发,设计类似SE模块[15]的结构来改善特征图融合,同时为改善小尺度目标分割,采用差值卷积[16]方法来增强小尺度目标的局部感知特征。
2 方 法
模型的整体框架如图1,分为编码和解码2个过程,输入图片经过编码器中的基础网络被提取不同层次的特征,再到达局部特征增强模块(LF进行局部感知特征突出,随后逐层通过全局特征增强模块进行上采样和特征融合,最终得到预测结果。图1中,左侧分数代表ResNet不同阶段特征图相比原输入缩放的比率,蓝色线和红色线分别代表下采样和上采样操作,黑色线不改变特征图尺寸。

图1 模型整体框架Fig.1 Overview of framework
2.1 基础网络结构
编码器提取特征的基础网络采用ImageNet[17]数据集上预训练过的ResNet-50[18],同时采用了比率为2的空洞卷积替换Res5层中的常规卷积,解决去掉池化层引起的单元感受野缩小,所以基础网络ResNet输出特征图尺寸为输入图片的1/16而不是原始的1/32,不同于图像整体分类任务,增加特征图分辨率有利于模型在解码阶段的分辨率重建。接着采用LFE模块作用于ResNet的输出,这一步通过卷积操作来增强特征图的局部感知特征,但不再改变特征图大小。下一步将尺度缩小到1/16的特征图逐层地与经过3×3卷积和GFE模块处理后的ResNet各层特征图进行融合,最终对最后一个GFE模块输出的特征图直接进行4倍上采样恢复到原输入尺寸得到模型的预测结果。其中的上采样操作采用双线性插值方法,不同于GCN中用到的反卷积操作,线性插值可以准确恢复像素点,同时没有引入复杂的计算。
2.2 局部特征增强模块
在图像级分类任务当中,深层卷积神经网络能够生成用于对象识别的相对高级的语义特征。这种特征具有全局化和上下文语义相关的特点,不完全适用于需要对每个像素进行标记的精细化场景语义分割任务。由于对整体图像进行内容理解所需要的上下文语义特征表现在图像中的主要对象上,即一些尺寸较大的特征显著的前景目标,往往忽略小尺度目标的非显著特征。况且复杂场景图像包含更丰富的目标类别以及目标间存在复杂的连接,不加选择地收集某一目标周围的特征信息可能引入有害噪声,为解决以上问题,设计了局部特征增强模块来更加关注于提取非显著目标的局部感知特征,如图2。

图2 局部特征增强模块Fig.2 Local feature enhancement module
图2中输入图片经过卷积后,黄色边框位置的任一像素A属于特征图中的非显著事物,不断的常规卷积操作会收集像素A周围的上下文语义来生成区别性像素点特征,导致在一些同A类似的特征点位置上,特征表达会被邻近的对更大范围语义表达起主导作用的目标区域所影响,导致该点缺乏类别区分性,在最后的预测结果中该位置的像素标注错误。因此,LFE采用一种平行结构[14]:常规3×3卷积提取局部特征,一定比率(rate)的空洞卷积(atrous conv)提取粗糙的全局上下文特征,2种特征形成对比来获得增强的局部感知特征,具体地,差值卷积计算为
EL=Fconv(x,wl)-FAconv(x,wc)
(1)
(1)式中:x表示输入特征图;Fconv和FAconv分别表示常规卷积和空洞卷积操作;wl和wc表示卷积核参数,将2种卷积操作结果做相减运算,得到的EL即为增强的局部感知特征,将小卷积核和大卷积核提取到的特征形成对比,将小目标点的局部特征信息从周围的主导性语义特征中凸显出来,原理上类似于人眼聚焦于一个关键时,主动模糊其周围的信息,相减的操作起到一个削弱关键点周围引入噪声的作用,使该方法更加聚焦于小尺度对象的非显著特征。图2中,整体的LFE模块采用比率为3,5的2种空洞卷积来实现对多尺度特征的关注。最后将LFE模块输出的所有特征图进行concatenate操作,即通道维度的特征图叠加,最后经过1×1卷积操作整合特征得到模块的输出。
2.3 全局特征增强模块
在基础网络的编码器结构中,根据特征图的大小可以将ResNet分为几个阶段,图1中,每个阶段具有不同的识别能力,低阶段的浅层网络对图像的空间细节信息进行编码,很少关注全局语义信息;高阶段的深层特征图是经过多层次卷积来不断扩大感受野,聚合了丰富的语义信息,但空间信息会减少。RefineNet ,GCN等方法的解码器先将较深层特征图上采样,再与较浅层特征图进行通道堆叠或像素相加等简单的融合操作,其目的是在像素重建过程中兼得空间和语义信息,但忽略了深浅层特征图之间的差异性。深层特征图的每个通道可以视为对不同目标类别的响应,而浅层特征图通道关注的是各种形状细节信息,直接对2部分按通道融合,可能削弱了各目标类别间的区分性特征,导致融合结果中对同类别像素预测的不一致。
为改善深浅层特征的融合,采用全局池化的方法设计全局特征增强模块,加入到融合操作当中,如公式(2)
E=Upsample(A)+FGFE(A,B)
(2)
(2)式中:A代表解码器中当前层特征图;B则是A在编码器中对应阶段的上一层特征图,文中分别称之为深、浅层特征图。A经过上采样与GFE模块输出进行逐像素相加得到融合结果E,其中,GFE模块的具体操作如图3,对深层特征图的每个通道进行全局池化(global pooling)获得全局上下文信息,经过1×1卷积和Sigmoid函数形成影响系数,通过乘积作用于浅层特征图。其中,在乘积操作之前,浅层特征图经过了3×3×C卷积,C代表特征通道数且等于分割类别数。GFE模块的目的是用深层特征图各通道的全局上下文信息,来增强浅层特征图自身的类间区别性特征,从而缩小浅层特征图与深层特征图之间差异来改善融合操作,有助于对同一类目标像素预测的一致性。

图3 全局特征增强模块Fig.3 Local feature enhancement module
3 实 验
实验中给基础网络ResNet-50加载ImageNet数据集上预训练过的参数,再用城市街道场景数据集Cityscapes[19]和CamVid[20]上来训练并评测本文提出的完整模型,对比验证提出模块的有效性,并与其他语义分割方法进行了实验结果的比较。
3.1 模型训练细节
实验所用GPU型号为NVIDIA TESLA V100(内存32 GByte) ,软件采用深度学习框架Tensorflow配合python,模型训练过程中采用RMSProp(均值平方根)自适应学习率优化算法,配合初始学习率1e-4,学习率衰减0.995,根据输入尺寸调整batchsize(处理图片批量),并随机对输入图片进行旋转,仿射变换,亮度调节等数据增强操作。训练损失函数采用交叉熵损失(cross-entropy loss)。
由于实验数据集属于复杂场景分割数据集,样本具有包含目标类别多且数量不均衡的特点,导致模型不能平均地学习每个类别的特征,保证每一类的分割精度。这里采用类别平衡方法,计算每个类别的出现频率fqi,即该类别像素数目除以数据中总像素数目,其中,i代表第i类,求出所有类别出现频率fqs的median 值,除以该类别对应的频率得到该类的权重,计算公式为
weighti=median(fqs)/fqi
(3)
用生成的类别权重作用于损失函数,使其对出现频率小的类别更加敏感,增加权重后的损失函数公式为
(4)
(4)式中:wi为第i类的权重;yi,ti分别为图像中所有第i类的预测值和标签值,语义分割任务是对像素类别和空间位置进行预测,本文实验采用评价指标为平均交并比(mean intersection-over-union,mIOU),评估网络输出的像素预测结果和真实的像素级图像标签之间的差距。
3.2 模块有效性验证
为验证各模块的有效性,分别在CamVid和Cityscapes数据集的训练集上依次对基础网络组合不同模块进行训练,并在2个数据集各自的验证集上进行评估,得到相应的mIOU测评值,实验结果如表1。首先,只用基础网络Res-50进行实验,对网络输出进行简单上采样和特征融合得到最终输出,计算相应的评价指标值。接着将局部特征增强模块作用在基础网络末端来验证该模块的有效性,在2个数据集上的mIOU值较基础网络分别提高了2.2%和1.4%,以CamVid的验证集为例,增加LFE模块前后的分割效果如图4,网络对电线杆和行人等具有细微局部特征的目标分割更加清晰,起到了局部特征增强作用。接着在前面结构基础上加入GFE模块指导上采样和融合工作,得到的mIOU值较加入GFE模块前网络提高了1.9%和2.1%,以Cityscapes验证集为例,分割效果如图5,其中,红色虚线框显示在对同类别目标像素分类的一致性上,GFE模块起到了作用。最后对完整的网络模型训练采用CB(类别平衡)操作,使得模型在CamVid和Cityscapes的验证集上mIOU评测值得到进一步提升,同时为了验证基础网络层数对模型分割性能的影响,实验又将模型的基础网络Res-50替换为Res-101,增加了一倍网络层数的模型在Camvid验证集上的mIOU测评值提高到了66.1%,考虑Cityscapes图片尺寸较大,硬件内存有限等因素,没有将本文方法的基础网络改为ResNet-101在Cityscapes上进行实验。同时保留ResNet-50作为本文方法的基础网络。
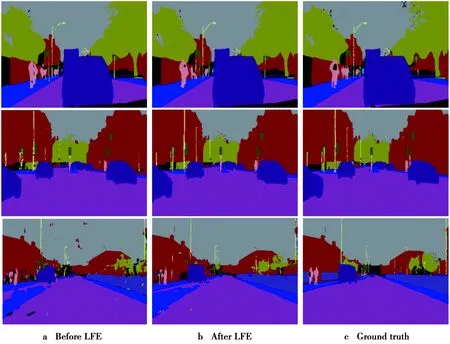
图4 增加LFE模块前后CamVid数据集的分割结果(Ground truth为标签)Fig.4 Results of LFE moduleon CamVid (Ground truth is the label)

图5 增加GFE模块前后Cityscapes数据集的分割结果(Ground truth为标签)Fig.5 Results of GFE moduleon Cityscapes (Ground truth is the label)

表1 模块有效性验证实验结果
3.3 CamVid测试结果
CamVid数据集是从剑桥街道场景视频中提取出的少量图片数据集,图片大小为720×960个像素,分为训练集367张,验证集100张,测试集233张图片,其中包含11类用于语义分割的目标对象。本实验训练中不对输入图片进行剪切操作,保持图片原尺寸,采用较小的batchsize 值6。3.2节中我们在验证集上评估了模型,本节将在测试集上对模型进行实验,与近几年代表方法的实验对比结果如表2,本文方法FEUNet的mIOU值达到了65.4%,分割效果优于SegNet和Deeplab-v2,与近两年方法BiSeNet和CGNet[21]相近,逊于ICNet。综合来看,FEUNet在CamVid数据集上取得了可观的效果。

表2 不同方法在CamVid测试集上的表现
3.4 Cityscapes测试结果
Cityscapes数据集包含30类目标,其中19类用于语义分割任务,提供5 000张精准标记图片,19 998张粗糙标记图片,本节将精准标记图片分成2 979张训练集图片,500张验证集和1 525张测试集图片进行实验。同样地,对输入图片不进行裁剪操作,保留原尺寸1 024×2 048,根据GPU内存限制,batchsize值设为3。表3列举了本文方法和其他典型方法的模型参数量及mIOU测评值,本文提出的FEUNet参数量为25.6 M(M为百万),mIOU值达到73.2%,都处于居中水平。虽参数量多于ICNet,但mIOU值更高。对比类似结构GCN和RefineNet,本文方法mIOU较低,但在参数量上优于RefineNet。对比结构差异大的BiSeNet,本模型具有更少的参数。在3.3节实验结果中,FEUNet和DeepLabv2在Camvid数据集上的mIOU测评值低于ICNet,而在Cityscapes上的表现优于ICNet,经分析,ICNet采用多分支结构和多尺度输入的级联训练方法,对各367张的Camvid训练集样本和标签进行不同尺度的缩放,输送网络的不同分支进行级联训练和监督,增加了训练样本数量,即增加模型对多尺度目标学习的泛化性;而Cityscapes数据集包含2 979张训练图片,其中富含更多场景,目标尺度变化更大,所以ICNet在Cityscapes数据集下的多尺度级联训练优势减弱,同时ICNet在2个数据集的mIOU测评值为67.1%和69.5%,提升值比较FEUNet和DeepLabv2更小,也证明了结构优势的减小。综合来看,本文提出的FEUNet模型在Cityscapes数据集上的分割性能具有一定竞争力。

表3 方法的参数量及Cityscapes测试集表现对比
4 结束语
本文提出了一种有效的增强局部特征和全局特征的编码器-解码器结构,其中局部特征增强模块对局部特征和周围特征进行差值提取,获得了增强的局部感知特征,改善非显著目标的分割效果。全局特征增强模块提取了上文特征图通道间的全局信息,用于对下文特征图进行全局特征增强,改善2部分特征图间的融合,增加了同语义目标分类的一致性。实验在具有多尺度多类别的复杂场景数据集CamVid和Cityscapes上验证了模块的有效性,并对比其他现有方法,本文提出方法在IOU评测上表现并非最突出,但在模型体积上更加轻量化,优势在于更加适用于GPU内存或计算力性能有限的硬件环境。对比具有相似结构的现有方法GCN和RefineNet,本文方法改善了原有的特征图融合方式,解码器网络参数计算更加简单。同时在不降低网络分割性能的前提下,可以对网络进行宽度上的压缩剪枝。
猜你喜欢
建材发展导向(2021年24期)2021-02-12 02:00:24
环境影响评价(2020年5期)2020-12-02 01:18:56
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
水利规划与设计(2016年10期)2017-01-15 14:01:14
太空探索(2016年5期)2016-07-12 15:17:55
新校长(2016年8期)2016-01-10 06:43:59
华北地质(2015年3期)2015-12-04 06:13:29
时代英语·高三(2014年5期)2014-08-26 17:01:17
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
