
基于机器视觉的智能导盲机器人系统设计
2021-12-21 07:45:54王政博陈国栋卢书轩姚承志
河北水利电力学院学报 2021年4期
王政博,唐 勇,陈国栋,卢书轩,姚承志
(1.河北水利电力学院电气自动化系,河北省沧州市黄河西路49号 061001;2.江苏省先进机器人技术重点实验室,江苏苏州相城区济学路8号 215123;3.河北省高校水利自动化与信息化应用技术研发中心,河北省沧州市黄河西路49号 061001)
视觉是人类获取知识和经验的主要感知来源,约占人体总媒介信息来源的80%,丧失视觉能力,意味着人们将失去最重要的信息与知识的感知来源。当今生活环境日益复杂,这给盲人的生活带来了更多的不便,甚至面临危险。视力有障碍的人都希望有一个辅助自己来到达目的地的机器人,让他们像正常人一样行走,或者说能保证让他们在行走过程中感到安全。给盲人提供一个安全、可靠、智能、高效的出行方式,是彰显人人平等、时代快速发展重要标志。“十四五”规划和2035年远景目标明确指出要健全多层次社会保障体系。智能语音导盲机器人不仅能够在导盲辅助设备研究中发挥优势,也能在提高低视力人群生活质量的同时,为视觉障碍患者提供多种帮助。
当前功能相对完善的导盲机器人大致可以划分为三种类型:手杖类的导盲辅助工具、佩带式的导盲辅助工具、运动型的导盲机器人。国内外的机构都得出了一些比较有说服力的结论,日本Amemiya等人[1]自主开发的一种手持导航器“伪吸引”是利用了人类的特殊感知习惯,在二维平面上产生特殊的震荡和振动,引导用户在任意一个平面上、任意一个方向“推、拉”。西安交通大学朱爱斌[2]领导团队成功开发并自主设计了一款基于人类双眼导盲视觉的全新的可穿戴型双眼导盲检测机器人,该导盲机器人用两个成像传感器来定位周围的障碍物并建立三维模型,通过多个传感器,使多个信息融合,获得信息之后可以以振动的形式传递给视觉障碍者。Borenstein j[3]提出的运动型的导盲机器人。视觉障碍者可以把牵引杆置于自己胸前,通过握住手柄,当有牵引力的牵引时,就开始转向,这种导盲机器人可以方便地、安全地引导视觉障碍者到达目的地。日本山梨大学研制了一种智能手推车ROTA。这个手推车安装了非常发达的视觉传感器以及能辨别任何声音的传感器等,它对盲人出行提供了便捷。
文中主要是基于视听相结合的智能导盲机器人的设计,结合了计算机技术、传感器、语音识别,通过现代图像处理技术完成特定目标对象的识别,通过控制机器人的运动解决导盲的问题。
1 智能语音导盲机器人的方案设计
对机器人进行方案设计以及软硬件选择时,首先进行的是要充分了解导盲机器人的功能。针对盲人视觉上的缺陷可以知道,盲人生活的周围环境不会过于复杂,我们需要利用多个传感器融合技术以及目前比较热门的机器视觉相关算法来探测盲人前方的障碍物,进而大大方便盲人的出行。
在目标检测与识别方面,采用基于Darknet网络结构的You Only Look Once(YOLO)算法对待测物体的图像库进行训练和识别测试,从而实现对图像中多个目标的检测与识别。机器人控制单元系统主要结构包括了一个主控单元、检测单元、运动控制处理单元、语音控制处理单元四大部分。主控单元主要功能是专门用来设计实现对一台导盲机器人各运动模块之间的运动协调控制,导盲机器人运动的原理计算和控制运转以及数据分析,检测单元是利用超声波检测与障碍物的距离。运动控制单元主要负责对机器人运动状态进行实时运动控制,其中主要包括控制机器人左转、右转、直行。语音控制单元主要是通过语音识别模块进行识别。硬件方面,优化避障效果,配备了单目摄像机、WIFI设备,完成信息采集和通信功能。该设计方案由硬件部分和软件部分构成,如图1所示。
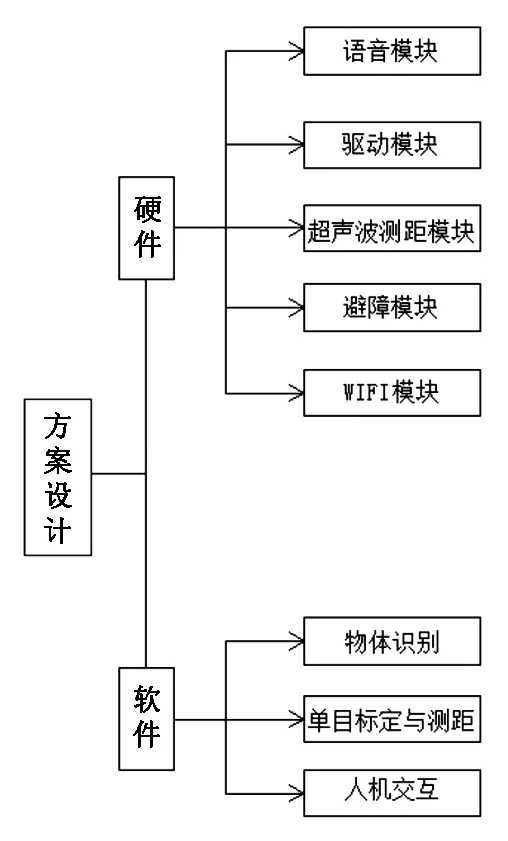
图1 总体方案设计图
本设计智能语音导盲机器人系统总体框图,主要包括物体识别、单目测距,语音交互、运动控制四大模块,如图2所示。综合软硬件设计,智能语音导盲机器人实现了精准智能的语音播报,以提示盲人前方物体的距离及方向,使盲人能够准确了解前方环境。
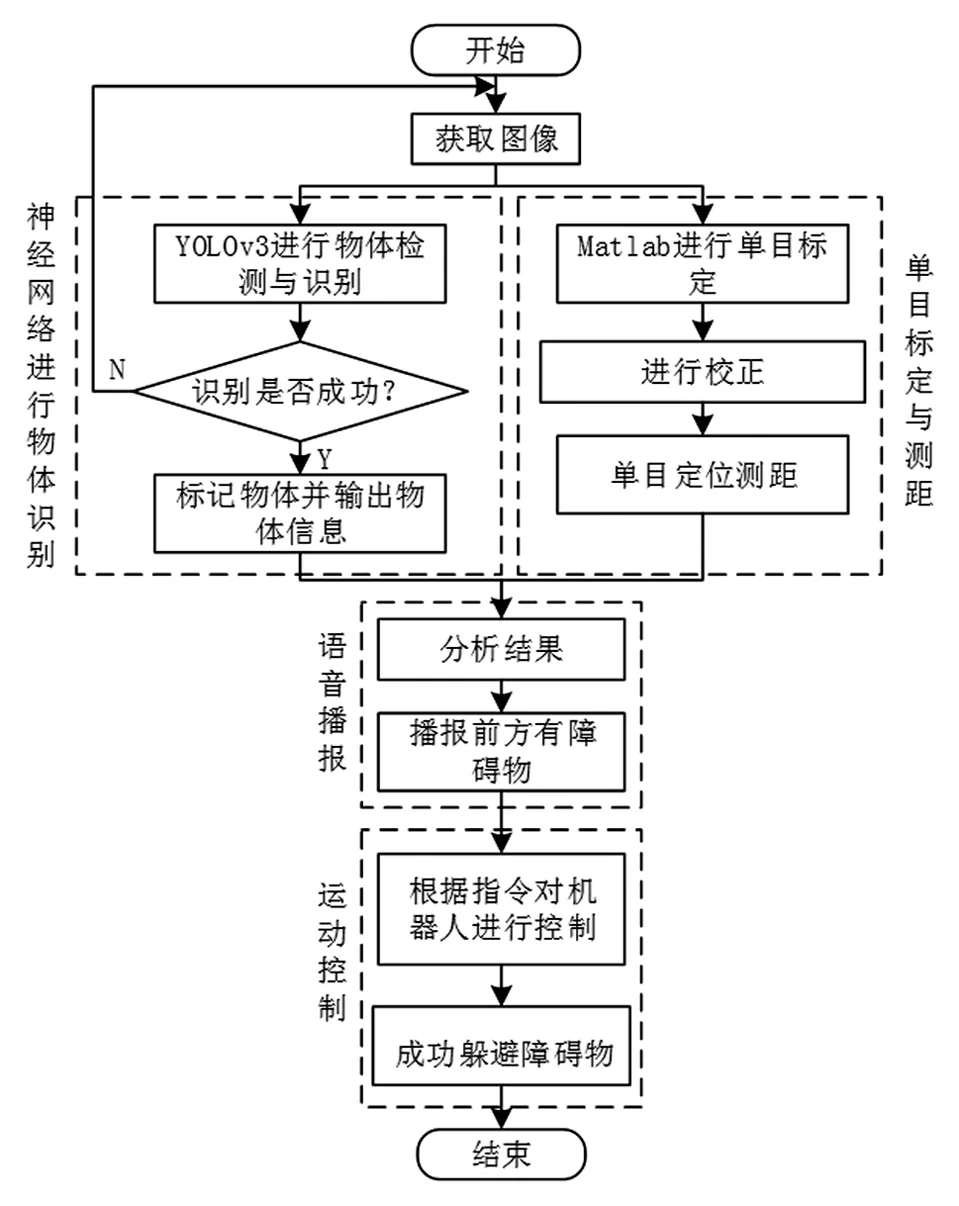
图2 系统总体框图
2 目标检测算法研究
2.1 物体检测与识别
机器人对周围环境的感知,精准地对物体进行检测与识别是本系统的重点,故要对于摄像机接收到的图像信号中多物体进行检测并精准识别出物体类别。目标检测的方法有很多种,常见的算法有Region-CNN(R-CNN)、Single Shot MultiBox Detector(SSD)以及YOLO。R-CNN模型不能快速的定位物体,在单一图片处理上比较浪费时间;SSD模型会随着输入图片的规格扩大,从而导致效率下降;YOLO算法的出现无疑是在目标检测的领域内带来了极大的便利,该算法进行合理变换可以保证实时性的基础上给特定物体的识别效果带来很大的提升[4]。
2.2 YOLO算法
文献[5]中提到,YOLO是一种实时的且准确的对象检测算法,YOLO V1版本已可以检测每秒四十多张图片,随着版本的更新换代,YOLO算法已经更新了4代,其中还伴随更新了一些轻量级算法,文中选用的是目前兼具速度和检测质量的YOLO V3版本,YOLO算法是属于卷积神经网络,它是由卷积层、全连接层还有池化层组成的。其训练的样本无需从样本图像中特意裁剪出,而是对整个图像进行训练和检测,提升了系统的稳定性。需要检测的图像被分割为n×n个网格,每个格子都分别负责检测是否有被测物体的中心落在了相应的格子内,当每一个小物体的网格需要检测时,自动产生一个被检测者所看到的中心框,每个被检测的中心边框都包括5维的物体信息(x,y,w,h,CObjct),x代表的是边框中心的横坐标,y代表的是纵坐标,w和h分别代表的整个被测照片的宽度、高度,CObjct代表的是包围框的置信度,置信度如公式(1)所示:
(1)
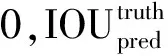
YOLO算法在卷积层[6]中提取相应特征,在全连接层进行目标预测功能。当Pr(Object)的值为1的时候,这幅图片的置信度如式(2)所示。
(2)
式(2)中Pr(Class∣Object)是待检测目标的分类条件概率。Pr(Class)是预测了某类别的概率。经过上述计算后,设置被检测包围边框的阈值,滤掉得分低于阈值的包围边框,并对被检测包围边框中所有阈值以下的包围边框,进行非极大阈值的抑制处理,即可获得被检测的结果。
2.3 YOLO V3网络
文中物体检测部分采用YOLO V3。YOLO V3是在2018年提出来的,该检测系统基于Darknet-53[7]深度学习框架环境进行物体识别,融合Feature Pyramid Networks(FPN)思想,预测三种尺度的框,解决了小目标检测算法上的效果不好的问题。YOLO V3不仅可以实现图片中的目标检测,还可以实现对运动目标的实时检测。Darknet-53的网络结构共包含了53个卷积层。
5个残差块构成了Darknet53的网络结构,残差神经网络[8]的思想在Darknet53的网络结构里有了充分的应用。众多的残差单元构成一个个的残差块,通过残差单元输入两个数码累计DBL来执行操作,就这样构成了残差单元,其中DBL单元包含了卷积层归一化和leaky ReLU激活函数。YOLO V3对检测的图片进行了5次降采样[9],最后3次降采样中对目标进行预测。YOLO V3算法主要由训练模块、模型模块、预测模块、检测模块组成,其相关联系如图3。其中模型模块是YOLO V3的核心,其作用就是根据给定的网络结构构建对应的模型,模型用于训练与检测。
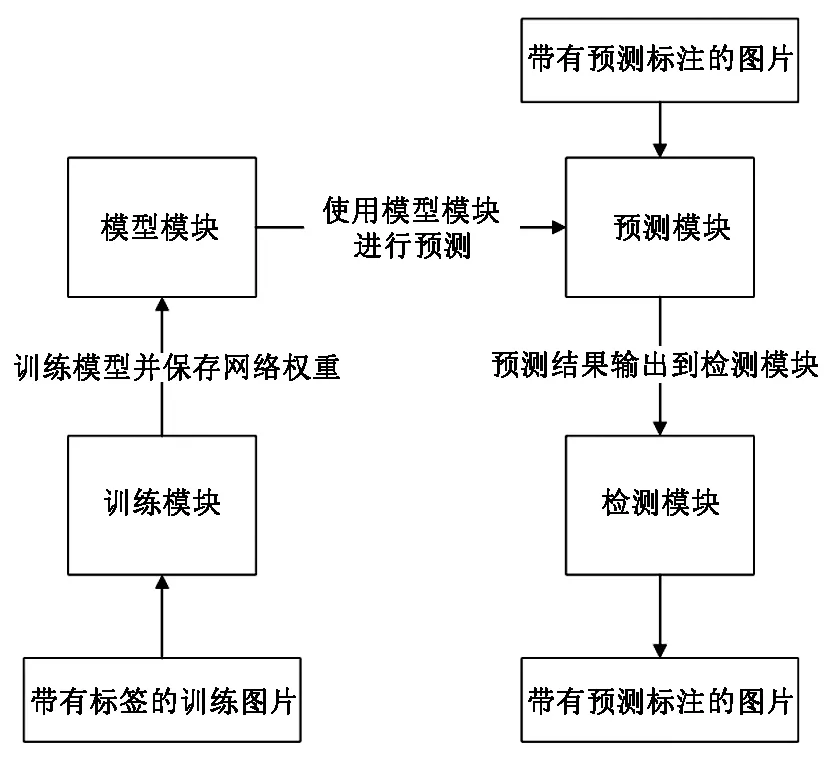
图3 模块间的相互联系Fig.3 Interconnections between modules
3 基于单目视觉的目标测距
3.1 相机标定
当今世界,准确测量物体的空间位置是计算机视觉研究中的重点问题。测量的方法分为单目标定、双目标定、多目标定。单目和双目算法比较成熟,使用较多。针对两者进行比较,单目成本低,操作简单,但测距精度不高;双目操作复杂,测距精度高。由于本设计对于测距精度的要求不高,综合考虑成本和实现可能性,该导盲机器人采用单目标定及测距完成机器人对最近物体距离的感知。
以被测物体的几何中心为原点,建立如图4所示的世界坐标系[10],选择物体上除了原点之外的另外四个点并得到坐标,以便后续的计算。
图4 世界坐标系Fig.4 World coordinate system
下面对三种空间下的坐标系进行了简要说明:
世界坐标系:系统的绝对坐标系,在没有建立用户坐标系之前画面上所有点的坐标都是以该坐标系的原点来确定各自的位置。
摄像机坐标系:以相机的光心为坐标原点,X轴和Y轴分别平行于图像坐标系的X轴和Y轴,相机的光轴为Z轴,用(XCYCZC)来表示坐标。
图像坐标系:图像的左上角作为原点做为基准建立的坐标系,来描述图像中被测物体的位置,如式(3)。
(3)
式(3)中,t是3×3的平移矩阵,R是单位正交矩阵。
为了简化处理,将其转为平面坐标系,当图像成像坐标系中任意一点(x,y)在平面坐标系对应点为(m,n),则有式(5)的转化关系。
(4)
其中,dx表示传感器单个像素的宽,dy表示传感器单个像素的高,s0代表摄像机坐标系梁坐标轴之间的倾斜因子,m0和n0表示实际成像的坐标。
摄像机坐标系中任意一点(XC,YC)在成像平面上对应的坐标为(x,y),则可以得到式(5)
(5)
根据上述所描述的三个坐标系的转换关系,利用单目摄像头内部参数,可以大致的检测到距离前面障碍物的距离。根据关于成像模型中透视几何关系的推导[11],可以估算出于障碍物的距离。
将摄像头与主控制器设备连接,操作系统选用的win10,编写驱动程序,图像处理库采用matlab2016进行标定,标定过程大致分为六步:第一步,采集照片让棋盘在照片中占据最大比例,这样可以得到更多的信息,同时固定好相机;第二通过多个角度拍摄,本次拍摄了10张图片;第三步进行Matlab camera calibration标定工具箱进行标定;第四步导入预先拍好的照片,采用25mm的单元格;第五步设置校正参数为-0.2;第六步点击Calibrate开始标定,并导出计算结果,完成单目标定。整体过程如图5所示。

图5 标定Fig.5 Calibration
3.2 单目校正
校正过程中,经常会出现畸变现象,我们通常使用的相机焦距很小,可视为凸透镜。当光通过不同厚度的透镜时,光的折叠方式会不同,这称为径向畸变,其远离透镜中心的光线比靠近透镜中心的光线弯曲得更严重,不利于我们计算图像物体的高度。除了径向畸变外,还有一个非常重要的切向畸变,由于镜头本身与像面不平行所导致的。
在MATLAB中,校正比较方便,只需要点击Calibrate开始标定后,点击Show Undistorted即可查看校正后的图像,然后再点击Export Camera Parameters即可保存参数。
3.3 单目测距
单目测距一般有两种方式,第一种是根据定位测量插值得到每个像素的坐标,第二种是根据相似三角比例计算出对应像素点的坐标。第一种必须固定摄像头,轻微的移动都会导致测量坐标的误差增大,本文利用第二种方式,利用相似三角形的几何关系,也是利用了小孔成像原理,获取图像的深度信息。
如图6所示,H为摄像头光心,P是世界坐标系中一点,PX是P点在世界坐标系XW轴上的投影,Py是P点在世界坐标系XW上的投影。α是固定相机的俯仰角,h是实际测量获取的摄像头光心OC距离地面的距离。假设P点与摄像头的水平距离为Dy,垂直方向距离Dx,则有
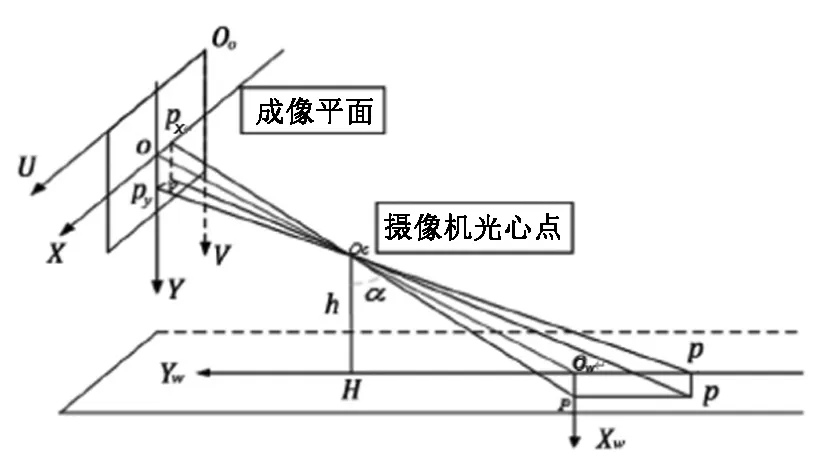
图6 小孔成像模型Fig.6 Pinhole model
Dy=h×tan(∝+β)
(6)
设β为线段PyP与光轴OOw的夹角,由几何关系可得
(7)
令OPy=Py,OOC=f,在△OOCPy中,可得
(8)
由式(7)、式(8)、式(9)可得
(9)
(10)
(11)
由式(9)、(10)、(11)可得
(12)
利用小孔成像模型,得到待测物体与成像平面的水平距离,即物体深度。
4 实验分析
4.1 硬件系统实验结果分析
本文以Arduino为主控板,结合多种传感器来完成机器人的运动。本设计可以控制导盲机器人在运动中如何进行前进、后退、左转、右转、停止。还能实现自主避障的功能。在设计中,运用了超声波舵机云平台、避障传感器进行避障,用来检测导盲机器人周围的障碍物,运用语音识别模块进行盲人与导盲机器人的交流。并结合WIFI模块进行通信。本论文初步设计的是障碍物距离导盲机器人10cm时候超声波模块传给Arduino,然后避障传感器进行避障,并通过语音形式告诉盲人障碍物的位置,智能导盲机器人如图7所示。

(a)前进中发现障碍物 (b)导盲车后退

(c)导盲车左转 (d)导盲车右转
如图7所示,机器人完成了自身底盘控制,可以自主的进行行走和避障,为导盲提供了基础。
4.2 软件系统实验结果分析
基于YOLO V3的物体检测与识别,可以对一张图片中多个物体进行检测,并可以将物体的类别显示出来。如图8所示,对花和水杯进行了识别。

图8 YOLO V3检测的物体Fig.8 Objects detected by YOLO V3
根据单目视觉的测距系统,对不同距离进行了各20次测距实验。如表1所示,对实际距离、测量距离、相对误差进行分析。
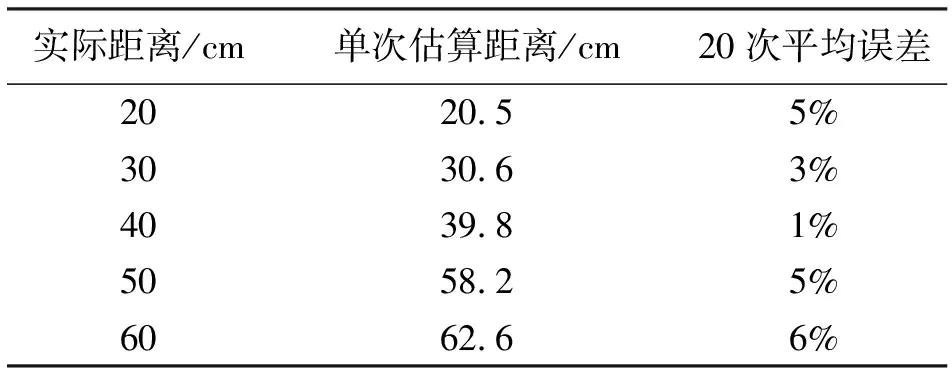
表1 测距结果
如表1所示,其中,实际距离是指相机距离待测物体的实际距离;单次估算距离指在20次测距实验中随机挑选1次以示例显示本设计单目测距的情况,根据实际测量可知,单目系统测距值会在实际值上下浮动;20次平均误差是每次相对误差的平均值,即单目测距系统平均相对误差。
分析不同距离时的测距结果得知,单目视觉测距误差稍大[12],但符合本系统的导盲要求,且成本较低。
结合Yolo识别结果和单目测距的结果,系统将自动进行语音播报,举例说明语音播报内容:前方发现障碍物凳子,距离您40厘米,请注意。
5 结束语
时代不断进步,科技不断发展,AI程度也越来越高。盲人由于生理上有缺陷,不能像正常人一样生活。本设计硬件部分完成了机器人本体的行走、避障等控制设计,软件部分完成了机器人搭载的视觉系统,可实现物体的识别检测、物体的测距和综合信息的语音播报功能。经过初步实验,本设计的导盲机器人能为助盲设备的落地化提供一定思路。
猜你喜欢
玩具世界(2022年3期)2022-09-20 01:45:56
客联(2022年3期)2022-05-31 04:28:08
科学(2020年3期)2020-01-06 04:02:51
中国惯性技术学报(2019年1期)2019-05-21 00:58:30
测控技术(2018年10期)2018-11-25 09:35:52
科学大观园(2018年2期)2018-05-30 14:47:58
北京航空航天大学学报(2017年4期)2017-11-23 05:48:16
电子制作(2017年7期)2017-06-05 09:36:13
光学精密工程(2016年4期)2016-11-07 09:05:11
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:53:55
