
结合AMS的C-LSTM船舶轨迹预测
2021-12-17 03:18:00吴春鹏冯姣
船海工程 2021年6期
吴春鹏,冯姣
(南京信息工程大学 电子与信息工程学院,南京 210044)
随着船舶运输行业的发展,船舶碰撞事件也急剧增加,如何通过技术手段提前预知船舶将行进位置,避开事故高发地或者隐藏障碍地,成为国内外学者的研究热点。
在船舶轨迹预测方面,有学者采用BP(back propagation)神经网络预测船舶航迹,得到的预测较为准确[1-2],但BP网络是将一个时间步内所有数据一并输入网络,缺乏对船舶轨迹时序性的体现。有学者运用循环神经网络(LSTM,GRU)对船舶轨迹进行预测,最终预测结果相对于BP网络有明显提升[3-6],但依然存在单一模型预测精度低的问题。有学者分别将LSTM或Bi-LSTM与注意力机制、CNN结合[7-8],增加网络复杂度,从而提高预测精度。为进一步提升预测精度,提出将LSTM和BP结合的复合LSTM(Composite LSTM,C-LSTM)船舶轨迹预测模型,利用BP神经网络对LSTM网络的输出进行误差修正,并针对经纬度高精度的预测要求,提出运用最新的自适应优化算法AMS代替主流自适应优化算法ADAM来优化整个系统模型。
1 理论基础
1.1 BP神经网络
在神经网络设置合适权值和合理结构后,可以使用误差梯度下降优化算法来最小化输出值和真实值之间误差,以达到逼近各种非线性连续函数效果,具有一层隐藏层的BP神经网络见图1。
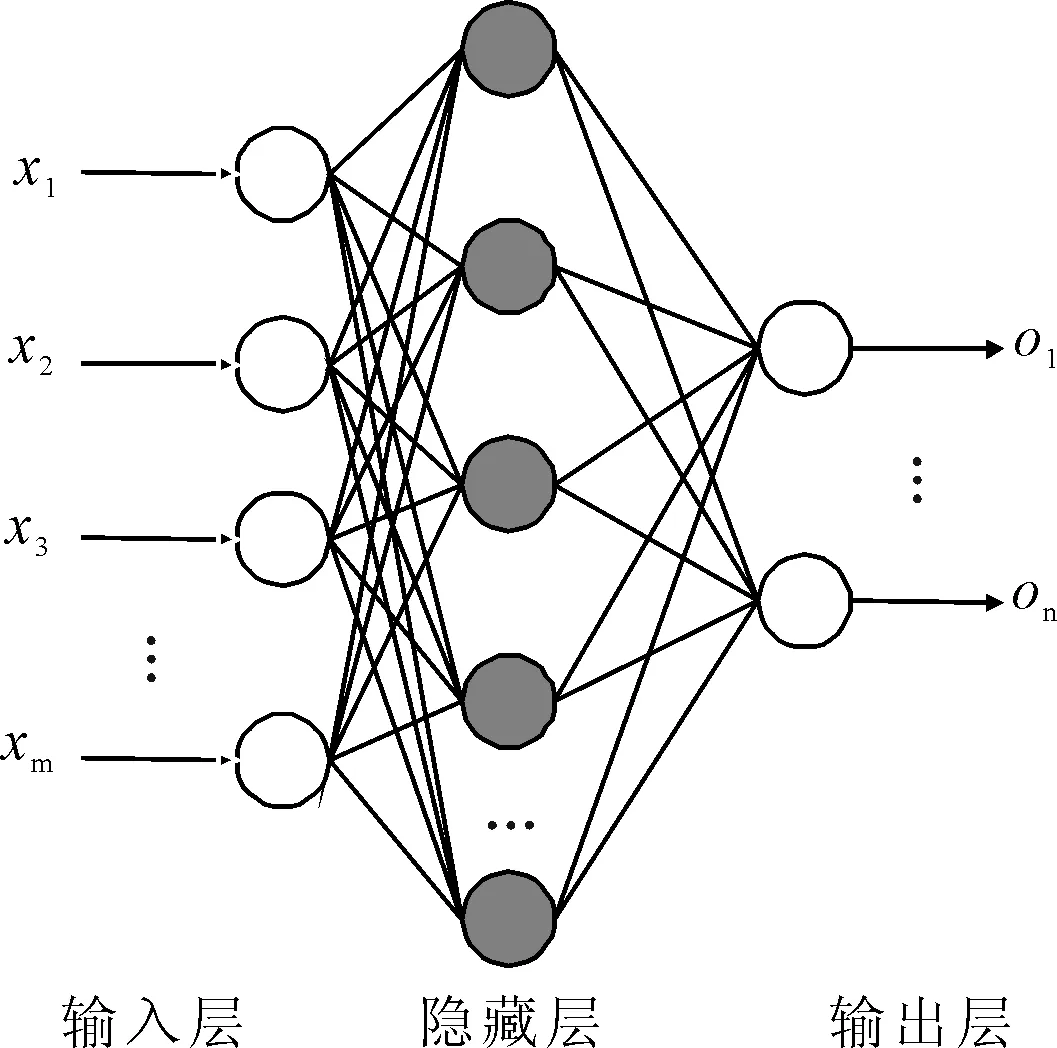
图1 BP神经网络
神经网络输入与输出之间关系为
(1)
式中:l为隐藏层节点数;k为输入层节点数;σ为激活函数,此处为sigmoid函数。
1.2 LSTM网络
LSTM(long short-term memory)是一种时间循环神经网络,是为解决一般RNN(循环神经网络)存在的长期依赖问题而专门设计出来的。
LSTM单元结构见图2,LSTM核心是细胞状态c,由穿过细胞的水平线来表示。细胞的状态和传送带一样,贯穿整个小区但只有几个分支,可以保证信息不变地流经单元。LSTM由3个门控制,分别叫做遗忘门、输入门和输出门。

图2 LSTM单元结构
LSTM遗忘门决定细胞状态需要丢弃哪些信息,由一个叫做遗忘门的sigmoid单元处理,通过检查ht-1和xt信息输出一个介于0和1之间的向量。向量中的值0-1表示单元状态ct-1中信息被保留或丢弃程度。0表示全部丢弃,1表示全部保留。公式如下。
ft=σ(Wf·[ht-1,xt]+bf)
(2)
下一步是向单元状态添加新信息。首先,ht-1和xt用于通过输入门的操作来决定新候选细胞信息更新程度,然后ht-1和xt通过tanh层用于获得新候选细胞信息,其可以被更新为细胞信息。
it=σ(Wi·[ht-1,xt]+bi)
(3)
(4)
接下来,将过去细胞信息ct-1更新为新细胞信息ct。更新规则是通过遗忘门选择来遗忘部分过去细胞信息,通过门选择输入部分候选细胞信息来获取新细胞信息。公式如下:
(5)
在单元状态更新后,需要ht-1和xt来确定输出单元的哪个状态特征,这里需要把输入通过一个叫做输出门的sigmoid层来得到判断条件。然后,单元的状态通过tanh层得到一个介于-1和1之间的向量,最终LSTM单元的输出通过将该向量与输出门的判断条件相乘得到。
ot=σ(Wo·[ht-1,xt]+bo)
(6)
ht=ot·tanh(ct)
(7)
1.3 AMS优化算法
为缩减训练时间加快模型收敛速度,引入优化算法。基于随机梯度下降(SGD)优化算法在科研和工程的很多领域里都是极其核心的。尽管传统mini-batch SGD优化算法在深度学习中表现优良,但也存在一些缺点,比如选择合适的学习率很困难。


表1 ADAM及AMS算法伪代码
2 模型
2.1 数据预处理
事实上,AIS数据质量会受到较多因素影响,从而导致数据会出现缺失、错误以及时间间隔不同等现象。针对该问题,采用四分位间距(IQR)误差检测法对数据进行检测,剔除异常数据,空缺数据采用线性插值法来填补。同时,LSTM网络对数据有时序性要求,故每组数据之间时间间隔要相等,过小间隔(秒级别)数据对于船舶的轨迹预测的研究意义较小,因此综合已有数据质量,将时间间隔定为1 min。
2.2 归一化
由于不同的特征向量可能在数量级上差别很大,可能导致绝对值小的数据被大数据“吃掉”的情况。因此,数据被归一化以确保每个特征被神经网络同等对待,故将采用最小最大归一化方法变换数据,转换如下。
(8)
式中:Xf为原始值,Xmin和Xmax分别为最小值和最大值,Xn为归一化后的数据。处理后,原始数据值范围转换为[0,1]。
2.3 流程图
基于结合AMS的C-LSTM船舶轨迹预测流程见图3,具体步骤如下。
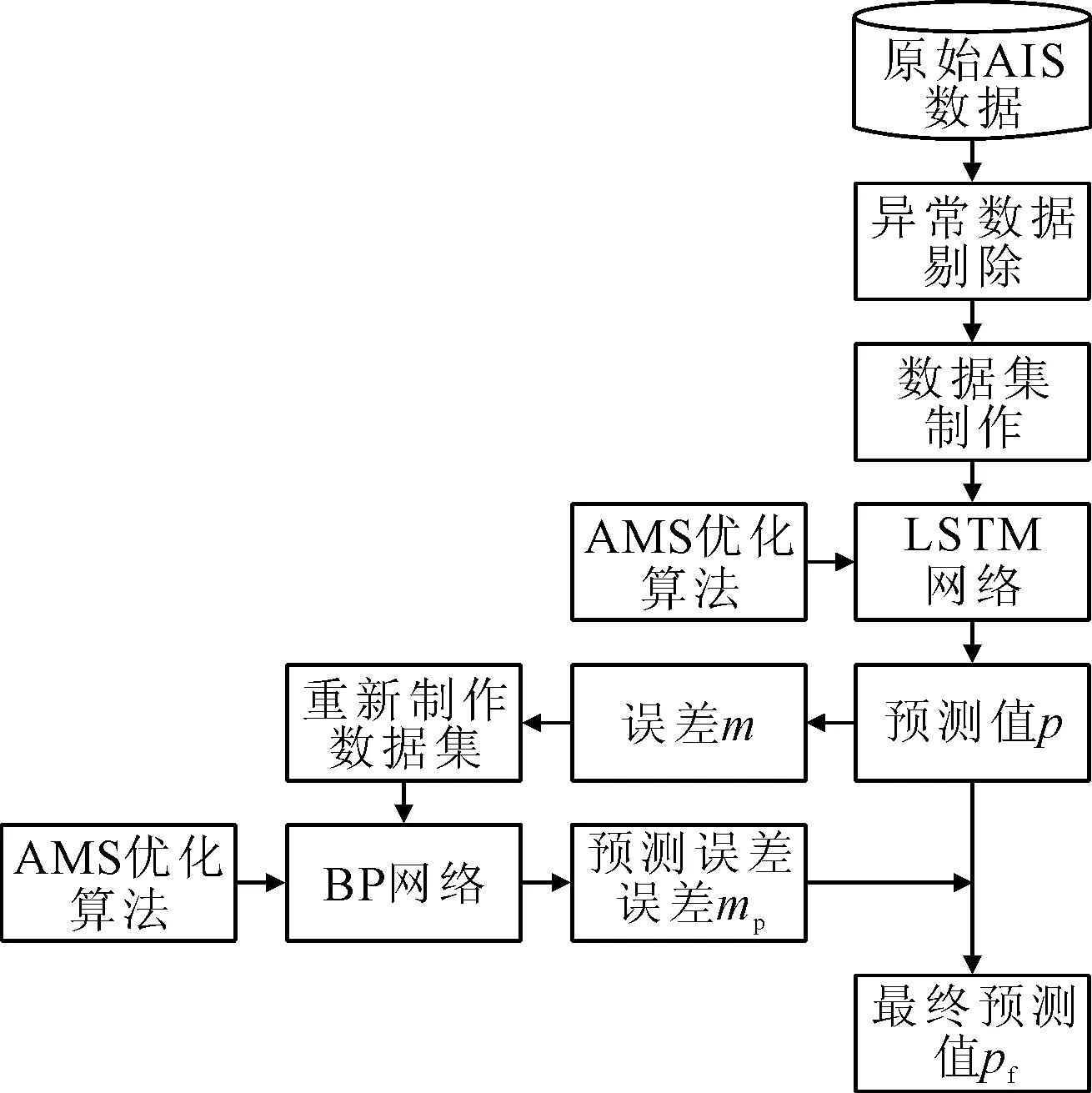
图3 结合AMS的C-LSTM船舶轨迹预测流程
步骤1。获取原始AIS数据。
步骤2。对原始数据进行异常值剔除。
步骤3。制作训练数据集和测试数据集。
步骤4。进入LSTM网络进行训练,利用AMS优化算法对其进行优化。
步骤5。将训练集输入训练好的LSTM网络得出预测值p,将之与真实值pr进行作差,计算出误差m:
m=pr-p
步骤6。重建数据集,将训练集轨迹信息作为输入,误差m作为输出。
步骤7。将新数据集送入BP网络进行误差训练,利用AMS优化算法对其进行优化。
步骤8。最终的预测值pf=p+mp,其中mp为BP对误差的预测。
2.4 数据集的制作
将一组t时刻的轨迹数据表示为
D(t)={lat,lon,sog,cog}
(9)
式中:lat、lon、sog、cog分别为纬度、经度、航速、航向数据。
LSTM模型的输入为前2个时刻数据D(t-2)、D(t-1)和当前时刻数据D(t),输出为当前时刻的下一时刻的轨迹信息D(t+1)。BP误差纠正模型的输入为3个时刻的轨迹信息,输出为下一时刻特征的误差值mp。
3 模型验证
3.1 实验环境
实验的硬件条件:CPU为锐龙r7处理器,内存16GB。软件条件:PyCharm 2020.3×64,编程语言为Python3.6,软件采用Tensorflow2.0(无AMS优化器,需据理论编写)。
3.2 模型参数与实验数据
模型参数:LSTM隐藏层数为3,节点数为110,学习率为0.000 3,激活函数为Relu函数,数据整批进行训练;BP误差纠正网络隐藏层数为5,隐藏层节点数为100,学习率0.000 1。参数选取需与所选数据集相适应。
实验选取mmsi(maritime mobile service identify,水上移动通信业务标识码)为412 761 070,船名为“汇航9-HUIHANG”的船舶数据,通过宝船网api,调取2020年1月8日的历史轨迹数据,部分实验数据见表2。选出实验数据共400组,分为直行和转向两组,每组将前177组作为训练集,后23组作为测试集,按照前述方法分别制作成训练集和测试集合,将训练集输入网络进行训练。

表2 部分船舶AIS数据
3.3 评价函数的选择
采用MSE(Mean Square Error)作为系统模型的评价函数。
(10)

3.4 实验结果分析
3.4.1 loss图对比
训练集和测试集在2种优化算法下的loss见图4、5。可以看出:AMS优化算法的收敛速度相对于ADAM优化算法收敛有明显的提升,ADAM最终降到的最低loss值为1.68×10-6,AMS最终降到的最低loss值为1.62×10-6,这与AMS算法理论相吻合。综上所述,该自适应优化算法能够提升该船舶预测模型性能。

图4 ADAM算法损失值

图5 AMS算法损失值
3.4.2 直行航迹对比
直行轨迹测试集在传统LSTM和C-LSTM上的误差对比见表3,该表就传统LSTM和C-LSTM2种模型在纬度、经度、航速、航向的最大最小误差以及评价函数值,对比上述各值,可见训练集在后者上表现比前者相对出色。

表3 直行测试集数据对比表
为验证模型实际应用能力,采用递归方式向后预测15个船舶位置,每个点之间时间间隔1 min,传统LSTM和C-LSTM模型递归轨迹效果见图6、7。

图6 直行LSTM递归

图7 直行经度误差
两种模型在直行轨迹不同递归预测时长下的经度、经度、航速、航向与真实轨迹的误差见图8~11。

图8 直行航速误差

图9 直行C-LSTM递归

图10 直行纬度误差
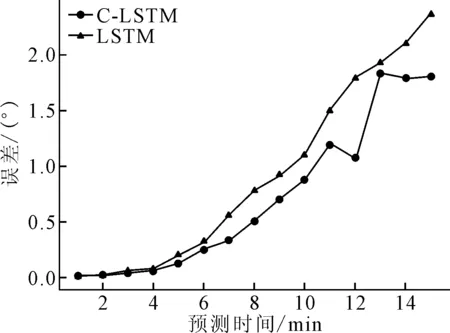
图11 直行航向误差
随着预测时长增加,传统LSTM模型的4种误差均在递增,C-LSTM的经纬度误差较为稳定,体现出该模型具有一定稳定性。且从图8~11可见C-LSTM模型的误差基本都在LSTM模型之下。LSTM和C-LSTM最大经纬度误差分别为1.70×10-3、9.79×10-5。综上所述,所提模型在直行航迹表现较为良好,且优于LSTM,可供参考。
3.4.2 转向航迹对比
转向轨迹测试集在传统LSTM和C-LSTM上的误差对比见表4,对比表4各项值,可见训练集在后者上表现相对前者依然出色。但两种预测模型在转向轨迹上的各项最大误差上和评价函数值均表现逊色于直行轨迹。同样采用递归的方式来验证模型在转向轨迹的表现,预测15 min船舶轨迹位置见图12、13。

表4 转向测试集数据对比表

图12 转向LSTM递归轨迹

图13 转向C-LSTM递归轨迹
两种模型在转向航迹的表现均不如直行轨迹,在转向部位开始出现较大偏差,其中LSTM模型偏差较大,但大致轨迹方向正确。而C-LSTM在转向表现上优于前者,还可以看出和真实轨迹较为吻合。
不同预测时长下转向航迹递归误差见图14~17。

图14 转向经度误差

图15 转向纬度误差

图16 转向航速对比
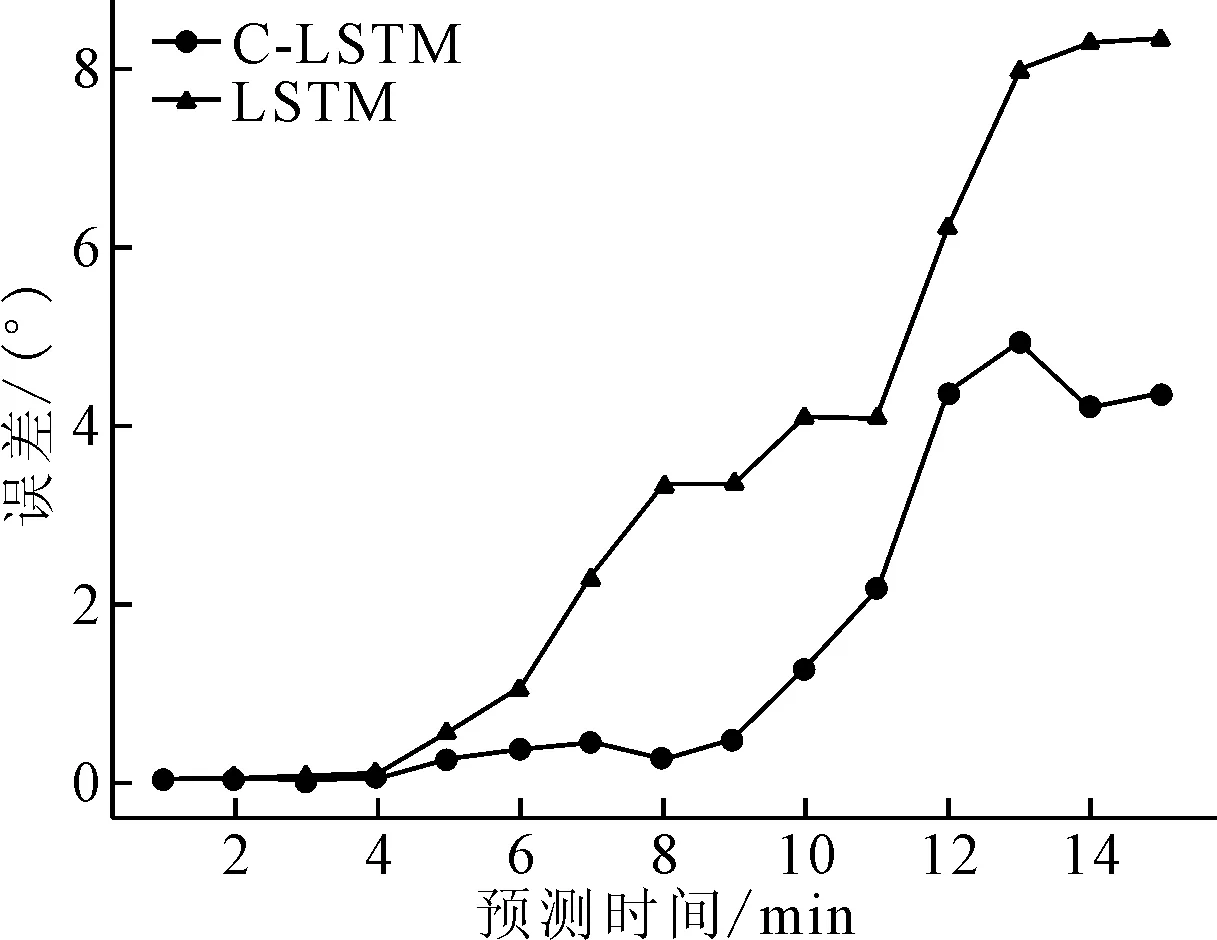
图17 转向航向对比
相对于直行轨迹,误差相对扩大,且随着时间增长,误差越来越大,LSTM模型和C-LSTM最大经纬度误差分别达到4.39×10-3、6.10×10-4。综上所述,C-LSTM模型在转向航迹表现优于传统LSTM,所预测轨迹具有一定的参考价值。
4 结论
依托AIS数据,通过建立复合模型C-LSTM,并将最新优化算法AMS应用到该模型,能够精准预测出下一段时间内的船舶轨迹,克服了单一性模型带来的弊端,相较于传统LSTM模型,精度存在明显提升,有着较高的鲁棒性、稳定性,对避免船舶的碰撞搁浅事故的发生有着较高实际应用价值。实验所选取实验轨迹数据较为稳定,在实验过程中发现轨迹的复杂度以及数据的预处理对模型的预测影响较大。下阶段研究重点将放在对转向轨迹预测性能上进行提升,考虑到转向轨迹的多变性与不确定性,单依据特征航向和航速不足以准确预测出航迹走向,因此模型需要得到充分学习,故将会尝试用大量高质量的数据来支撑模型性能。
猜你喜欢
船舶(2021年4期)2021-09-07 17:32:22
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
小哥白尼(趣味科学)(2019年10期)2020-01-18 09:16:22
电子制作(2019年19期)2019-11-23 08:42:00
船舶标准化工程师(2019年4期)2019-07-24 07:21:12
现代装饰(2018年5期)2018-05-26 09:09:39
中国三峡(2017年2期)2017-06-09 08:15:29
中国船检(2017年3期)2017-05-18 11:33:09
重型机械(2016年1期)2016-03-01 03:42:04
