
基于YOLO-v5 的星载SAR 图像海洋小目标检测
2021-12-15 02:37窦其龙颜明重朱大奇
应用科技 2021年6期
窦其龙,颜明重,朱大奇
上海海事大学 智能海事搜救与水下机器人上海工程技术研究中心,上海 201306
合成孔径雷达(SAR)是根据电磁散射回波的原理对区域进行成像,其成像范围广、空间分辨率高,因而在资源勘探、灾害监测、海洋管理及军事领域得到了广泛的应用。基于星载SAR 图像,对大范围的海上目标,尤其是特定区域的船舶目标进行准确的检测、定位或识别,具有重要的现实需求[1]。
当今国内外的研究机构对于遥感卫星图像的目标检测做了大量的相关研究。传统的检测手段主要有区域选择、特征提取和分类器分类3 个步骤。区域选择即对可能存在目标的区域进行分割,如在星载SAR 图像里常用的CA-CFAR[2]算法等。特征提取就是在待检索区域将鲁棒性强的特征进行保留,在SAR 图像中比较常见的有标准差特征提取法(standard deviation,SD)[3]、加权秩填充比特征提取法(weighted-rank fill ratio,WRFR)[4]等。分类器分类就是将提取特征输入分类器,和已知数据进行比对分类。传统的检测方法受图像噪声的影响较大,存在选择区域冗余、特征鲁棒性较差、处理时间长等弊端。
自从2014 年Ross Girshick 提出卷积神经网络深度学习算法(regions with convolutional neural network features,RCNN)[5],并在PASCAL VOC[6]数据集取得突破性进展后,深度卷积神经网络就进入了迅猛发展的时代,基于深度学习的神经网络模型也因其强大的特征提取能力而被广泛应用于各种实体目标的检测[7-8]。在RCNN 卷积神经网络提出之后,Shaoqing Ren[9]和郭昕刚等[10]又分别提出了Fast RCNN、Fsater RCNN,使得神经网络不断优化和拓宽,训练速度不断提高,误检率不断降低。华北电力大学的赵文清等[11]就利用Fsater RCNN 算法对存在缺陷的绝缘子进行准确识别,从而对输电线路进行故障诊断和修复。上述算法一般都是通过神经网络提取候选框、分类处理、回归等操作进行目标特征的学习,从而进行目标检测与分类。近些年,基于端到端(end to end)学习的实例检测算法被提出,典型的代表为 单步多框预测(single shot multibox detector,SSD)算法和YOLO(you only look once)家族[12]。文献[13]针对行人检测方法误检率高的问题提出了基于改进SSD 网络的行人检测(pedestrian distinction,PDIS)模型。文献[14]提出了基于YOLO-v2 和支持向量机(support vector machine,SVM)的船舶检测分类算法,在网络模型最后一步全局特征池化后,利用SVM 实现船型的分类,有效地实现了不同种类船只的识别。中国科学院的陈科峻等[15]提出了基于YOLO-v3 模型压缩的卫星图像实时检测,采用K-means 聚类算法选取初始锚点框(anchor),然后用多尺度金字塔图像进行模型训练,采用压缩后的模型大幅度减少了系统计算的时间,节约了计算机的计算空间。
SAR 图像目标检测的关键是加强对船舶等被检测目标的注意力,忽略无用信息的干扰。随着SAR 图像分辨率的不断提高和不同工种模式下图像获取的极化方式、照射角度、干扰因子不同,因此对SAR 图像目标的自适应检测并不理想[16]。本文将YOLO-v5 深度神经网络模型应用于星载SAR 图像中的船舶目标检测。针对船舶目标在星载SAR 图像中占比很小的特性,进行图像预处理和数据增强,采用K-means 改进锚点框的尺寸大小,并优化神经网络模型,嵌入GDAL 模块,对星载SAR 图像目标的位置信息等进行读取。
1 YOLO-v5 的网络结构
1.1 输入端Mosaic 数据增强
参考文献[17]的CutMix 数据增强方式,将重新组合图像的数量由2 张增加到4 张。首先从数据集中取出不重复的4 张图像;然后对图像依次进行随机的缩放、裁剪和拼接;最后需要将图片进行灰色填充的操作,以获得符合网络特征训练的大小统一的检测图像。
图1 为采取数据增强处理后的图像效果。图1 中的灰色填充部分对神经网络的学习并没有帮助,因此灰色部分越少,训练时间越少,训练效果越好。我们采用式(1)~(3)的计算方法进行灰色填充。
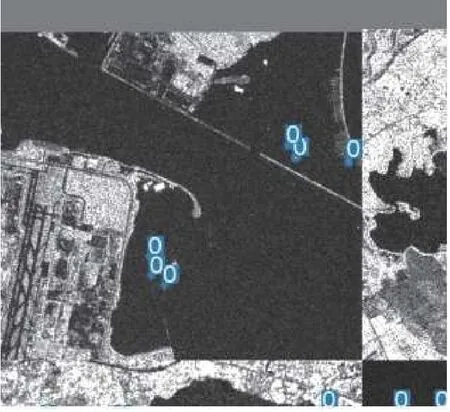
图1 Mosaic 数据增强(包含灰色填充)
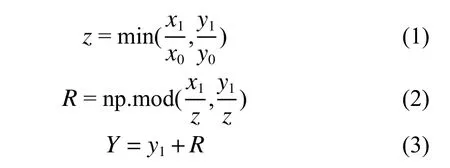
式中:x0、y0(x0≥y0)为原始图像尺寸的长度与宽度;x1、y1为图像缩放后的长度与宽度;z为缩放系数;R是x1/z整除y1/z的余数,R表示灰色填充的数值。最终得到宽度为Y的图像。
这种方法根据图像原尺寸和缩放尺寸中较小的缩放系数来使得填充的灰色尽可能的小,从而减少计算时的内存占用,达到加快训练速度的目的。
在YOLO 算法中,初始锚框是针对VOC[12]等数据集计算得到的,本文中YOLO-v5 的锚点框大小的选择与星载SAR 图像中的目标尺寸有关,为此,通过数据集和实验来进行设定。网络在初始锚框(anchor)的基础上输出预测框,进而和真实框(ground truth)进行对比,计算损失函数,再反向更新,迭代网络参数。由于YOLO-v5 采用的CNN卷积网络对特征图像分别进行了32 倍、16 倍和8 倍的下采样,每次下采样对应3 个锚点框。32 倍的下采样用较大的锚点框去检测感受视野较大的特征图像,16 倍和8 倍的下采样分别采用中等的和较小的锚点框去检测感受视野中等和较小的特征图像,从而降低模型在训练的时候寻找被检测目标的盲目性,有助加快模型寻找被检测目标的速度。
在YOLO-v5 中加入了自适应锚框的计算,在进行每次训练之前,通过K-means 算法在训练集中对所有样本的真实框进行聚类,从而找出高复杂度和高召回率中最优的那组锚点框。K-means算法步骤如下。
1)K-means 聚类法即先输入k的值,即我们所希望得到的k个类别。
2)从数据集中随机选取k个二维数组作为质心(centroid)。
3)对集合中的每一个二维数组进行计算,与哪一个质心接近则与其分为一组。
4)在每一组中选出一个新的质心使其与每个点的距离更接近。
5)当新的质心与旧的质心的直线距离小于设定的阈值时,则算法收敛,聚类区域稳定。
6)当新的质心与旧的质心差距较大时,重复迭代步骤3)~5)。
针对本文的数据集,经过YOLO-v5 自适应锚点框计算后所得锚点框设置如表1 所示,四舍五入取整后得到表2 的锚点框数据,更新模型中的原始锚点框进行神经网络训练。从表2 中可见,海面船舶小目标框也有明显的大小分别,主要分布在5×5~25×21 pixel。

表1 K-means 聚类结果

表2 星载SAR 图像锚点框聚类
1.2 YOLO-v5 主干网络(Backbone and Neck)
图2 为YOLO-v5 的主干网络结构,该模型主要由注意力(FOCOUS) 模块、卷积归一化(convolution and batch normalization,CBL) 模块、跨阶段局部网络(cross stage partial,CSP) 模块、跨阶段缩放局部网络(scaling cross stage partial,SPP) 模块和张量拼接(Concat) 模块构成。
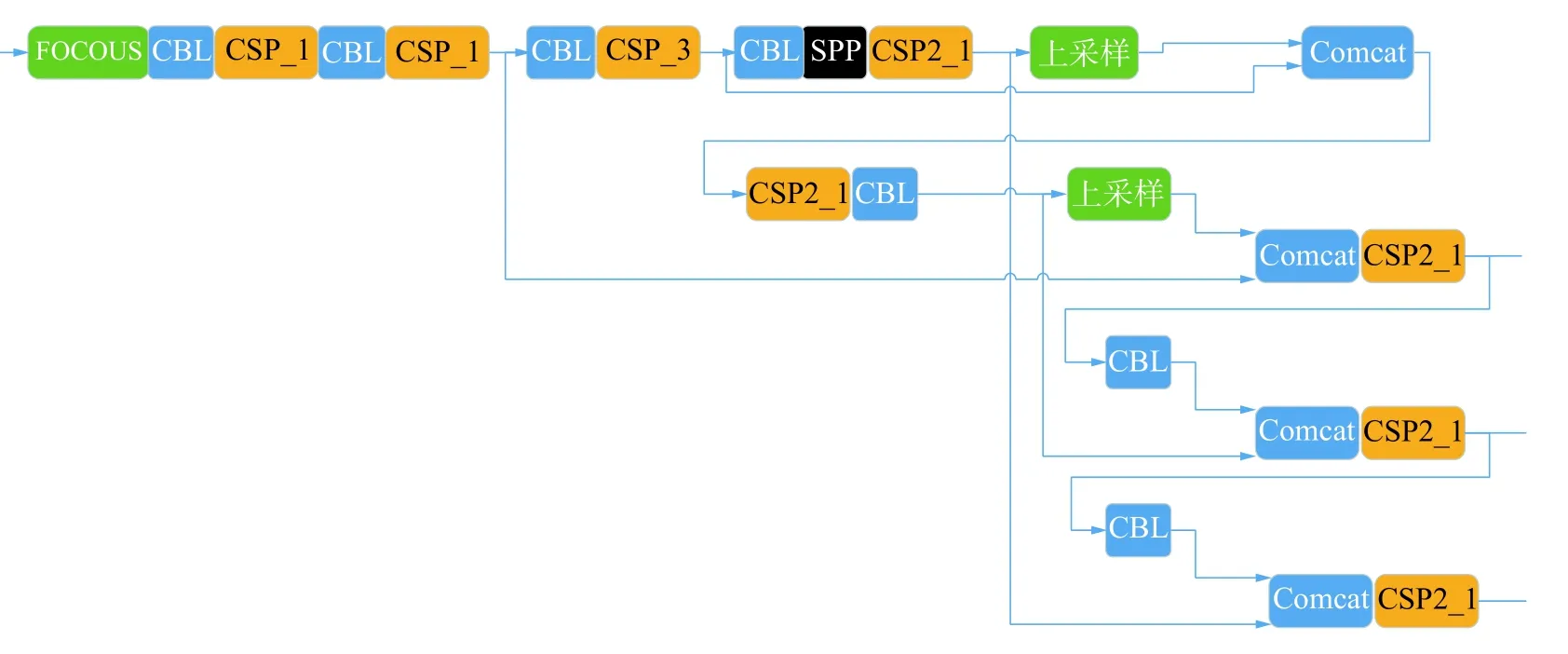
图2 YOLO-v5 思维Backbone 和Neck 结构
其中FOCOUS 是图像切片操作。如图3 所示,将图像按照像素格进行分割再融合。当原始图像输入为608×608×3 pixel 时,通过切片操作进一步提取特征变成304×304×12 pixel 的图像,再经过32 个卷积核的操作最终变成304×304×32 pixel的特征图像。

图3 切片操作
CBL 是由卷积(convolution)、批量归一化(batch normalization,BN)和激活函数(Leaky_relu)等3 部分构成。由于输入的分布逐渐向非线性函数的两端靠拢,神经网络收敛速度较慢,BN 层将输入的分布通过式(4)拉回到均值为0、方差为1 的正态布,从而使输入激活函数的值在反向传播中产生更明显的梯度,避免了梯度消失的问题。
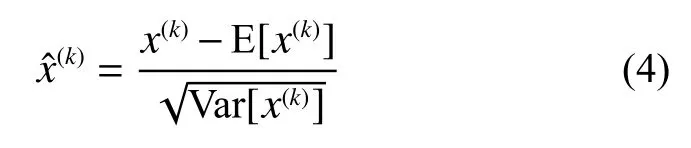
式中:x(k)为经过该层线性变换后的损失函数值,Var 为均方差操作符。
将输入分布变为标准状态分布后,输入的值靠近中心的概率变大,此时采用sigmod[18]函数,即使输入存在微小的变化,也能够在反向传播时产生较大的变化。Leaky relu 激活函数如式(5)所示。
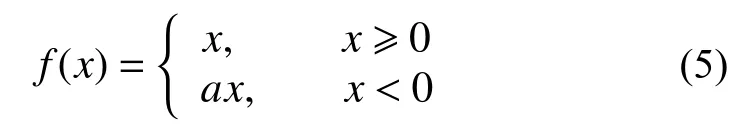
式中a采取一个很小的数值,本文设置为0.01。传统激活函数直接取值为0,这样可以保证输出小于0 的神经元也进行小幅度的更新。
SPP 采用1×1、5×5、9×9 和13×13 的最大池化方式,进行多尺度融合操作。Concat 为扩充维度的张量拼接。YOLO-v5 与YOLO-v4 一样采用了CSP Darknet53 的网络结构,与YOLO-v5 不同的是,YOLO-v4 中只有主干网络中设计了CSP(由卷积层和Res unint 模块张量拼接而成)结构,而YOLO-v5 在主干网络Backbone 和Neck 中设计了2 种不同的CSP 结构。CSP 结构主要优点是在网络模型轻量化的同时保证准确性,同时降低了对计算机设备的要求。新增的CSP2 进一步加强了网络特征融合的能力。
1.3 损失函数计算
损失函数计算公式如式(6)所示,表示2 个方框所在区域的交并比(intersection over union,IoU)。

如图4 所示,2 个方框完全重合时,XIoU=1;2 个方框交集为空时,XIoU=0;2 个方框重叠一部分时,XIoU的值在0 和1 之间。但是当2 个框的交集为0 时,不管2 个框相距多远,IoU 损失函数值恒等于0,无法表示该情况下的损失大小。在YOLO-v5 中采用了IoU 的损失函数公式为

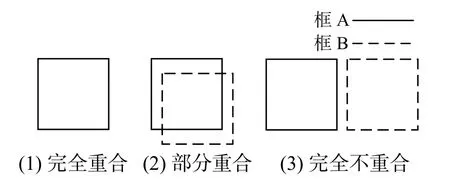
图4 IoU 损失函数算法
在IoU 的基础上衍生出的GIoU[19]表示先计算2 个方框的最小闭包区域面积(也就是2 个框重合的交集)。用C和A∪B比值的绝对值除以C的绝对值得到闭包区域中不属于2 个框的区域的比重,最后计算IoU 与比重的差值,最终得到GIoU的值。在2 个框无限趋近重合的情况下XGIoU=XIoU=1。
如图5 所示,采用IoU 损失函数时,当2 个框不重合时,无论差距多大,损失函数都为0。与IoU 不同的是GIoU 算法不仅关注2 个框重叠区域的大小,也加入了非重合区域,因此YOLOv5 避免了上述问题。
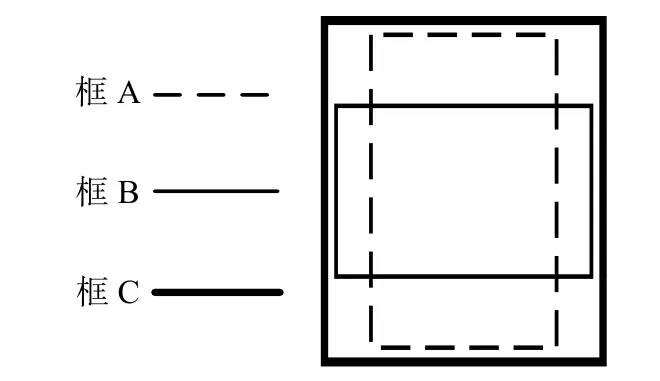
图5 GIoU 损失函数算法
2 GDAL 模块
在星载SAR 图像海洋目标检测时,本文在检测头部分(detect)中嵌入了GDAL 模块,直接读取TIF 图像中每个目标的经纬度坐标,使得目标数据更为直观、清晰。
GDAL 是一个对遥感卫星等地理图像进行读取、写入和转换的库。遥感图像是一种带大地坐标的栅格数据,每个栅格点所对应的数值为该点的像元值,像元值包含了该点的大地坐标等空间投影信息,GDAL 通过仿射矩阵的坐标变换将栅格数据转换为经纬度等信息。
首先使用GDAL 模块对遥感卫星图像进行图像校正(需要指定3 个已知正确的空间坐标点),然后再进行目标经纬度的读取与显示。
在截取星载(SAR)图像的子图像时保留TIF格式,从而保留遥感卫星图像的像素格属性。利用式(7)和式(8)进行栅格数据转换,从而读出图像经纬度信息。

在经过校正的北向上的星载SAR 图像中,padfTransform[1] 是像素的宽度,padfTransform[5]是像素高度,padTransform[0]和padTransform[3]分别是星载SAR 图像左上角的经纬度坐标。
3 实验结果与分析
3.1 实验平台
本文中的实验模型在Pytorch0.8 框架上,采用Darknet53 学习网络,在PyCharm Community Edition 2020.2.1 x64 平台上实现。模型训练在Titan2080Ti(显存12GB)GPU,CUDA10.0 实验环境下完成,操作系统为Windows.x64。YOLO-v5 随着神经网络宽度和深度的增加分为YOLO-v5s、YOLO-v5m、YOLO-v5l 和YOLO-v5x 这4 个模型,本次实验采用YOLO-v5l,并加入与YOLO-v3 神经网络训练模型的对比。
3.2 数据集
数据集采用了2020 年1 月—2020 年11 月期间由欧洲航天航空局(European Space Agency,ESA)拍摄的Sentinel-1 星载SAR 图像,选取长江三角洲、新加坡樟宜港口等船舶较多的码头港口地区。数据集包含41 张原始比例尺为1∶3 000 的SAR 图像,每张图像包含1~40 个不同的船舶目标,对其中100 张图像用Labelimg 工具软件进行坐标标记。该数据集包含了不同分辨率以及不同背景下(港口、近海、远海)不同尺寸的舰船目标,引入不同的岛屿港口背景是为了增加要素,增强训练效果。
3.3 实验参数
本次实验部分实验参数如表3 所示。

表3 训练模型参数
3.4 实验结果与分析
训练过程参数如图6 所示,YOLO-v3-spp 训练如图7 所示。图6 和图7 中(a)为各类别AP 均值(mean average precision,mAP),作为衡量网络模型训练的一个重要参数,其中RAP是以准确率Rprecision和召回率Rrecall为两轴作图后围成的面积,RmAP表示平均,@后面的数表示判定IoU 正负样本的阈值。图6 和图7 中(b)为找对的目标数量与找到的目标数量比值,图6 和图7 中(c)为找对的目标数量与实际待检测目标数量的比值。
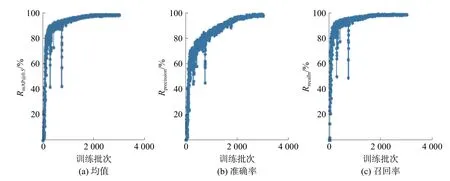
图6 YOLO-v5l 训练过程参数

图7 YOLO-v3 训练过程参数
从图6 和图7 对比可以看出,YOLO-v3 在训练2 000 epochs 时,准确率逐渐趋于平缓,而YOLO-v5l 的准确率有着进一步的训练上升空间。YOLOv3 经常出现错误的函数迭代方向,如图7 中的竖型分支,主要原因为:
1)进行了Mosic 数据增强,使得增强后的数据集目标分布更加均衡,并且这种重新组合图像的方式增强了数据集的丰富性,使得神经网络训练的鲁棒性更好。
2)加入了CBL 等模块的YOLO-v5 在反向传播更新模型参数时失误较少,有着更为明显和正确的梯度,训练参数曲线较为平滑。
最终训练结果的具体参数如表4 所示。YOLO-v5l 模型的召回率Rrecall为0.994 5,相比于YOLO-v3 提高了1.78%;YOLO-v5l 的召回率RmAP@0.5为0.994 5,相比YOLO-v3 提高了1.18%。
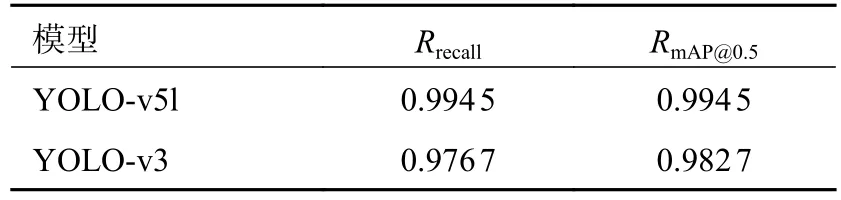
表4 YOLO-v5l 与YOLO-v3 模型训练结果对比
截取长江口和新加坡樟宜港区域的星载SAR 图像,采用改进后的YOLO-v5 检测模型并嵌入GDAL 模块后,水面船舶目标的检测结果分别如图8 和图9 所示。

图8 长江口区域的目标检测结果

图9 樟宜港区域的目标检测结果
在表5 和表6 中,包括了目标在图像中的坐标以及在地理位置上的经纬度信息。表5 和表6中的经纬度信息截取小数点后4 位,用GDAL 模块读取的星载SAR 图像经纬度信息与目标实际地理位置信息一致。目标的经纬度采用目标在图像中的检测框的中心位置。

表5 长江口区域目标位置信息
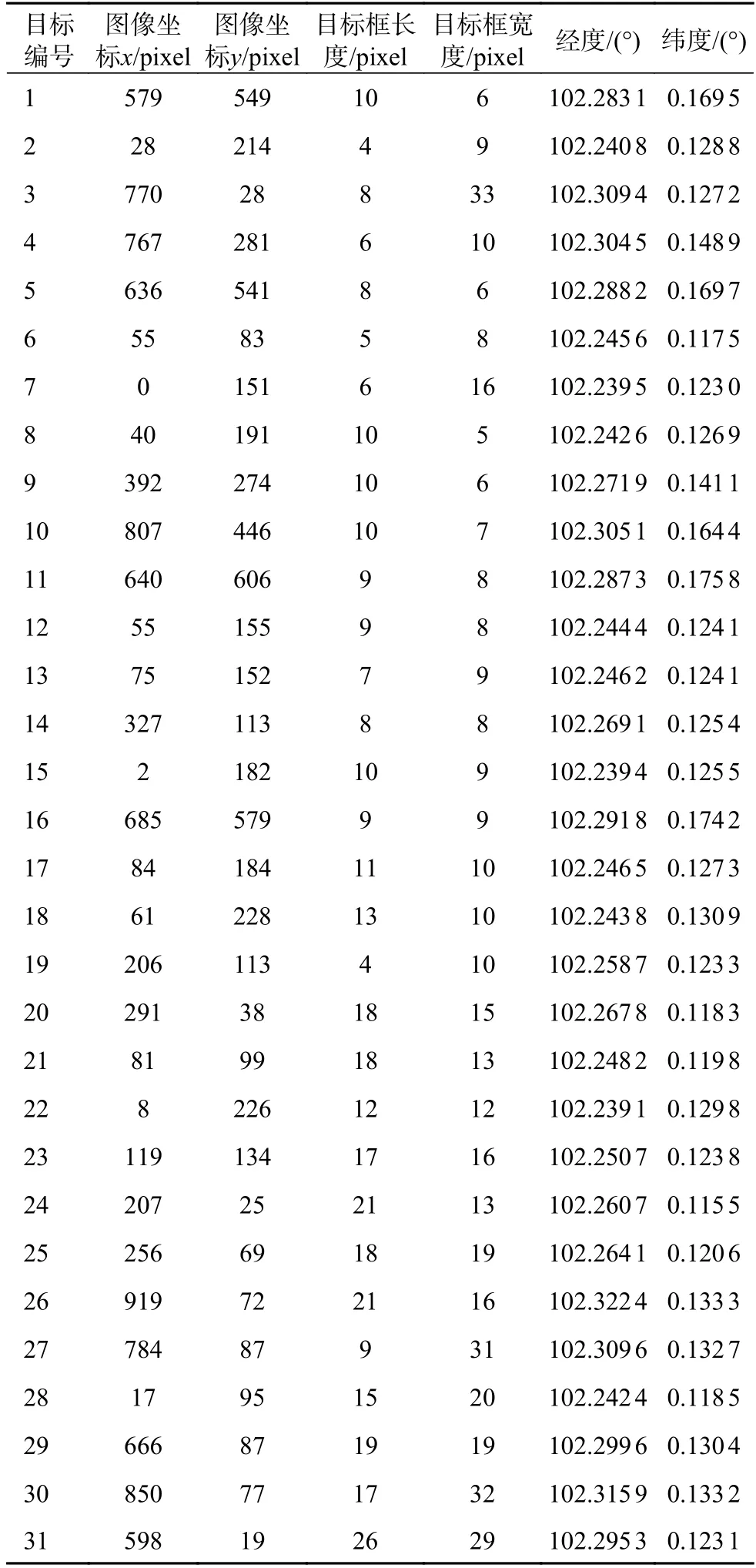
表6 樟宜港区域目标位置信息
可以看出,在图8 中,对于这种没有港口、海面开阔和船舶目标数量较少的星载SAR 图像,改进后的YOLO-v5 检测模型漏检率很低,即使目标在图像中占比较小也能准确地检测出来。在图9中,港口沿岸情况复杂、干扰因素较多、目标检测效果仍然较好,并且该模型能够有效检测到动态船舶目标,能够满足对于进出港口船舶的动态检测、定位和跟踪等应用需求。
4 结论
本文基于Darknet 神经网络,提出了利用优化的YOLO-v5 网络模型的目标检测的算法。
1)本算法泛化性较强,对于大范围的水面船舶小目标检测效果较好,并且检测时间较短,分辨率为720×720 pixel 的图像平均检测时间小于1 s。
2)加入CBL 模块的YOLO-v5 比YOLO-v3 在训练中的反向传播更为稳定,更新梯度更为平滑。
3)优化后YOLO-v5 的模型降低了漏检率,在提高检测效果的同时并没有增加检测模型文件的内存。
在未来的研究中,需要进一步优化网络模型结构,加快检测速度,并且用于与其他检测目标的手段进行实时的数据融合。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
通信电源技术(2021年2期)2021-05-21
电子技术与软件工程(2020年22期)2021-01-30
数字技术与应用(2020年12期)2021-01-22
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
移动通信(2020年5期)2020-06-08
电子制作(2019年19期)2019-11-23
重型机械(2016年1期)2016-03-01
