
基于Hive的高寒草地海量数据高效分析系统设计研究
2021-12-15 08:01:14李亮丹晔沙谢夏胡月明谢健文周悟游小敏
农业资源与环境学报 2021年6期
李亮丹,晔沙,谢夏,胡月明,,3,4,谢健文,3,4,周悟,游小敏
(1.华南农业大学资源环境学院,广州 510642;2.海南大学热带作物学院,海口 570228;3.青海-广东自然资源监测与评价联合重点实验室,西宁 810016;4.广州市华南自然资源科学技术研究院,广州 510642)
高寒草地生态系统是我国海拔最高、面积最大的生态系统类型,也是我国重要的畜牧业基地,其对于高原地区的水源涵养、生物多样性保护、固碳等生态功能具有不可替代的作用[1-4]。然而,高寒草地生态系统具有脆弱性与敏感性的特点,一旦被破坏,容易导致水土流失、江河湖泊断流干涸、虫鼠灾害、沙尘暴等一系列生态灾害问题。而高寒草地一旦退化,修复和治理往往需要很长时间,且要耗费极大的人力和物力资源。
为了解决高寒草地退化问题,我国在高寒草地生态系统监测、草地生态修复方面开展了大量的工作[5-8]。2000 年,我国启动青海三江源自然保护区生态保护和建设工程[5]。不少学者就三江源生态保护和建设工程的成效进行了定性或定量的分析[6],提出了启示性的建议[7],并对三江源生态保护和建设成效进行了评估[8]。除此之外,也有大量的学者从事高寒区域生态评价、高寒草地评价等工作。在生态评价方面,气候变化[9]、土壤特征[10]等是学者们关注的重点。在高寒草地评价方面,植被覆盖变化[11]、生态因素与植被的关系[12]、草地退化评价[13]等也受到了广泛关注。随着国家相关部门和众多学者对高寒草地多方面、多手段的监测和研究,其数据量也随时间呈爆炸式增长,合理有效地利用高寒草地海量数据进行高寒草地退化研究,通过对价值密度较低的海量数据进行挖掘及综合分析,不仅能够系统、科学地对高寒草地的退化与沙漠化的情况进行评价,而且能够为高寒草地监测与管理政策的科学制定提供理论依据。
基于海量数据进行高寒草地退化研究的基础在于数据的存储和分析。目前高寒草地涉及的数据按来源主要可归纳成4大类:①Landsat系列、Sentinel系列、国产高分以及中分辨率成像光谱仪(MODIS)等多传感器的遥感数据[14];②来自监测站点的监测数据,如气候、生物量等基础地理数据;③相关部门信息资料,如各类社会经济统计表格、描述文献、地形图、CAD 测绘图件、GIS 数据等;④实验数据,如根据不同实验目的布设样点得到的各类土壤和草地健康系数、草地覆盖度等监管指标数据。总体来说,我国积累的高寒草地数据主要呈现以下特点:①数据规模庞大,数据分布不均衡;②多源多结构数据并存,异构数据量大、种类多;③空间性强;④数据格式多样,数据质量参差不齐。针对以上高寒草地数据的特点,本研究提出通过分布式技术解决其高效存储与分析的问题,旨在为高寒草地的监测与管理提供更多的方法与思路,并为后续政策制定及决策提供科学的数据支持。
1 高寒草地海量数据分析系统整体设计
1.1 需求分析
针对高寒草地数据的特点,本系统设计与实现了基于Hive 的高寒草地海量数据分析系统,以解决高寒草地退化评价中数据存储与分析的问题,主要需求如下:
(1)数据搜集
数据搜集是关键的第一步,需要遵循全面、准确、直观、科学的原则,多渠道、多手段地对高寒草地实时监测数据及海量历史数据进行搜集,主要包括监测站信息数据、草地类型数据、生物量数据、气象数据、水文数据等。
(2)数据管理
本研究需要完成对高寒草地海量数据可靠的分布式存储。Hive支持各种数据类型,包括基础数据类型tinyint、smallint、int、bigint、float、string 等,同时也支持array、map、struct、union 等复杂的数据类型。Hive支持的文件格式主要包括textfile(文本文件)、sequencefile(二进制文件)、rcfile(Hive 推出的面向列的数据格式)。同时,Hive 继承了分布式文件系统HDFS 的数据存储性能,具有极优秀的拓展性,适合对大量的高寒草地数据进行存储与处理。
(3)数据分析
一方面,基于海量数据的高寒草地退化评价需要对高寒草地实时监测数据及海量历史数据进行批处理,而现有的技术往往难以保证数据批处理的效率,存在计算能力不强的问题,因此,需要提高对海量数据批处理分析的效率。另一方面,植被生长状况、植被生产力和土壤侵蚀状况等都需要经过一系列复杂的分析和计算,然而通过简单的分类、统计往往难以从海量高寒草地数据中获取足够的、有价值的信息,因此,需要提升系统的分析拓展能力,能够通过编写代码或调用脚本的方式,完成代码层面的拓展,满足更新的分析需求。
1.2 数据来源
本研究数据由多个渠道获取,主要数据来源为青海省草原总站、青海湖流域生态环境综合数据平台等,结合国内高寒草地研究领域的相关学术论文,以保证数据的真实性与数据处理的科学性。对于高寒草地退化,学者们主要从植被退化、土壤退化等方面进行研究[1,15-19],参照相关研究内容,本研究从生物量、植被类型、土壤、气象、水文等因子考虑,进行相关数据指标的确定。通过走访青海大学、青海省草原总站、青海省图书馆、青海省环境监测中心站、青海省水土保持局、中国科学院西北高原生物研究所、青海省测绘地理信息局、青海省气象局等单位,最终完成数据的搜集。完成数据搜集后,通过三个标准(表1)进行数据的筛选。

表1 高寒草地数据搜集筛选标准Table 1 Data collection and selection criteria for alpine grassland
1.3 整体架构设计
本系统的整体架构分为数据源、数据存储模块、数据分析模块、数据应用。各模块功能如图1所示。
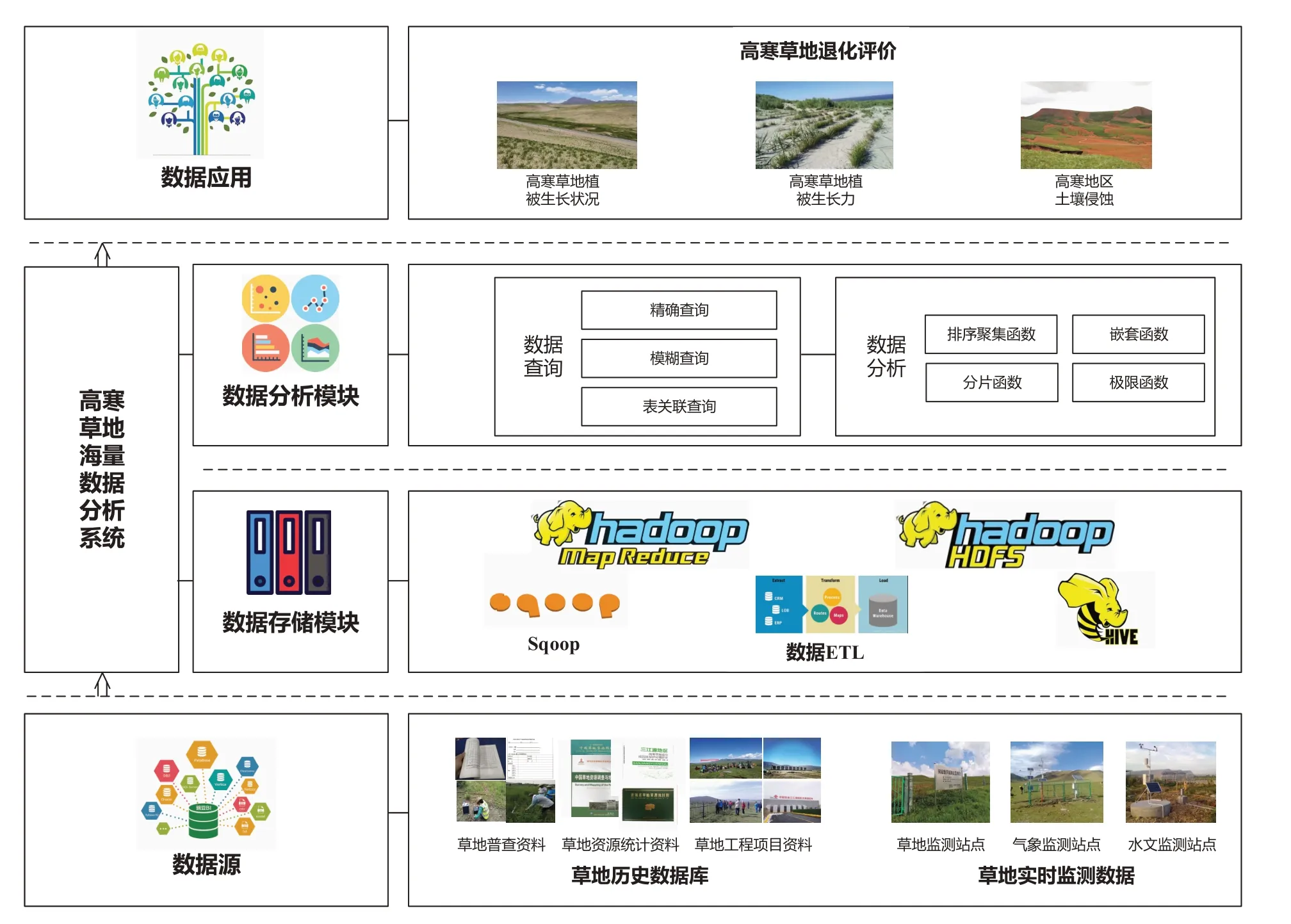
图1 系统整体架构设计图Figure 1 The overall system design diagram
数据源:系统搜集高寒草地海量科学数据,对高寒草地生态、基础环境、社会经济等各方面的信息进行记录。数据源为整个系统中最为基础的模块。本研究的数据分为高寒草地的历史数据与草地实时监测数据。历史数据采用关系型数据库进行管理,为本系统提供原始数据,这些原始数据通过草地普查资料、草地资源统计资料、草地工程项目资料等方式获取,存储于MySQL数据库中;草地实时监测数据主要通过各草地监测站点、气象监测站点、水文监测站点等监测站点网络动态监测的数据汇总得到,主要包括监测站信息、草地类型、生物量、气象、水文。
数据存储模块:数据存储模块的功能主要由Hadoop 平台完成,主要为HDFS、MapReduce、Hive 和Sqoop,各组件承担起系统数据存储的相应功能。通过拓展并合理应用以上组件,将海量数据导入Hive中,完成数据存储。
数据分析模块:数据存储是系统的基础,对存储于系统中的海量数据进行数据查询和分析是本研究的重点之一。目前,已构建排序函数、聚集函数、数据过滤模型等,用于高寒草地海量数据精细与复杂分析,以进行决策辅助与状态监测。并且提供相应易于控制与操作的用户接口,使得非专业技术人员可以进行管理与访问。
数据应用:本系统的开发是为基于海量数据的高寒草地退化评价服务的,旨在为高寒草地植被生长状况、植被生长力、土壤侵蚀等高寒草地退化综合评价提供相应的技术支持,最终实现数据应用。
2 高寒草地海量数据分析系统具体实现
2.1 基于Hadoop的高寒草地海量数据处理平台搭建
基于Hadoop 的高寒草地海量数据处理平台搭建过程主要包括以下三个方面:单节点配置、集群配置、Hadoop组件配置。主要的技术流程如图2所示。
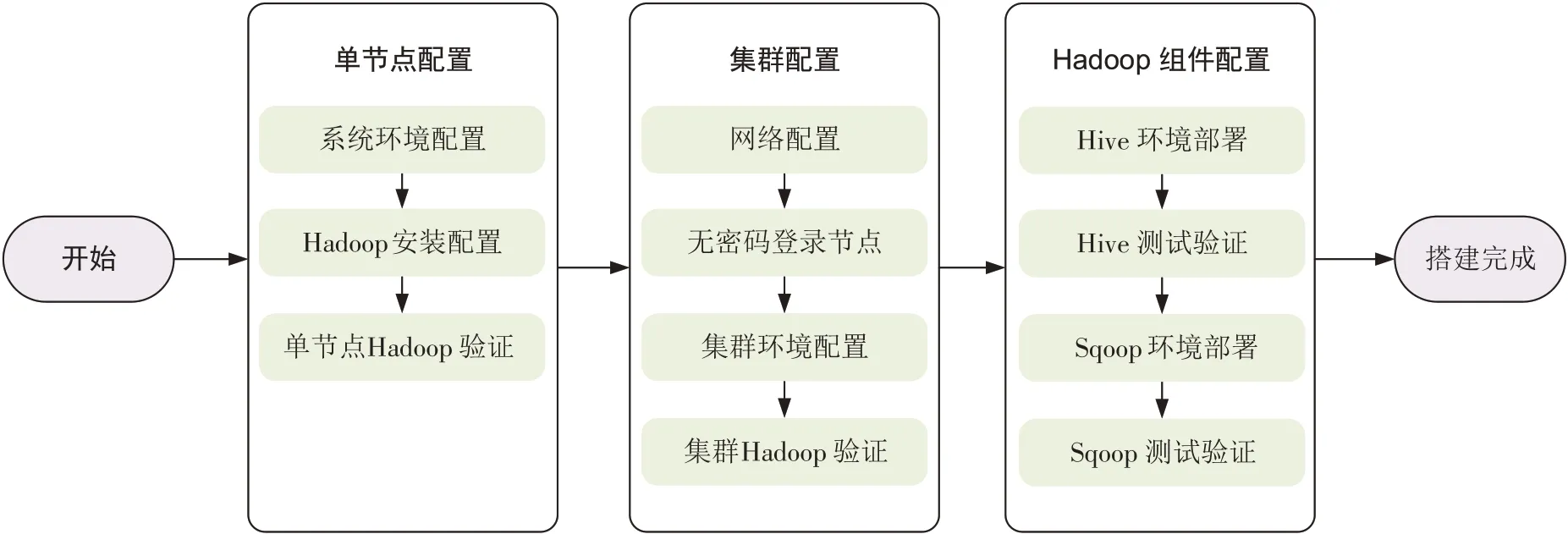
图2 基于Hadoop的高寒草地海量数据处理平台搭建流程Figure 2 The process of building a massive data processing platform for alpine grassland based on Hadoop
(1)单节点配置
选择一台计算机节点作为名称节点,其余的计算机节点作为数据节点。在每个节点上进行系统环境的配置,安装SSH(Secure Shell)登陆、安装JAVA 并配置环境变量(本研究使用OpenJDK 1.7 作为JAVA环境)、选择稳定的Hadoop 2.7.3 版本进行安装,并通过命令行验证单节点配置是否完成。
(2)集群配置
集群配置的第一步是进行网络配置,确保集群内所有节点处于同一局域网内。第二步是通过SSH 配置无密码登陆节点,使得名称节点可以无密码SSH登陆到各数据节点上。第三步是通过修改配置文件完成集群环境配置。第四步是集群Hadoop 验证,并通过命令行或访问Hadoop的Web 界面的方式验证集群搭建是否成功。
(3)Hadoop 组件配置
在完成Hadoop 集群配置后,需进行Hive 环境及Sqoop 环境的部署。Hive 环境部署步骤如下:第一步是下载并解压最新稳定版本的Hive 源程序,本研究使用Hive 1.2.2;第二步是修改配置Hive 的PATH环境变量;第三步是修改Hive 的配置文件;第四步是选择MySQL 作为Hive 的元数据库而不是使用自带的derby 元数据库;第五步是启用Hive,并测试验证是否安装成功。Sqoop 环境部署步骤如下:第一步是下载并解压最新稳定版本的Sqoop 程序;第二步是修改Sqoop 的配置文件;第三步是配置Sqoop 的环境变量;第四步是将 MySQL 驱动包拷贝到SQOOP_HOME/lib;第五步是测试利用Sqoop 将远程数据导入Hive 是否成功。
2.2 数据ETL
ETL是英文Extract-Transform-Load 的缩写,它定义为将数据从来源经过抽取(Extract)、转换(Transform)、加载(Load)到数据库的过程。其主要的步骤包括:从数据源中获取数据,数据清洗以提高数据质量,最终按照预先定义好的数据模型将数据加载到数据仓库中。本研究从数据源获取的草地实时监测数据经过数据预处理后,导入已设计完成的高寒草地生态数据表中,完成数据ETL处理。
(1)数据预处理
通过对源数据的分析,对源数据进行基本的预处理,进行数据填充[20]的操作,将得到的数据从Excel格式转换为文本文件格式进行存储,每条高寒草地数据中的字段用制表符分隔,每条记录用换行符分隔,以适应HDFS的存储方式,方便导入Hive中。
本研究以2012—2014 年部分草地监测统计数据中完整的生物量数据为例,进行数据填充预处理,具体数据如表2 所示,共8 个字段,69 条记录。对该完整数据集中的紫花针茅和矮火绒草两个字段各随机去除6 个数据,构建完全随机缺失数据集(Missing completely at random,MCAR),数据缺失率略低于10%。由于样方之间联系紧密,且数据缺失率不高,因此,选用EM 算法[21](Expectation-Maximum,也称期望最大化算法)对构建缺失数据集进行填充。
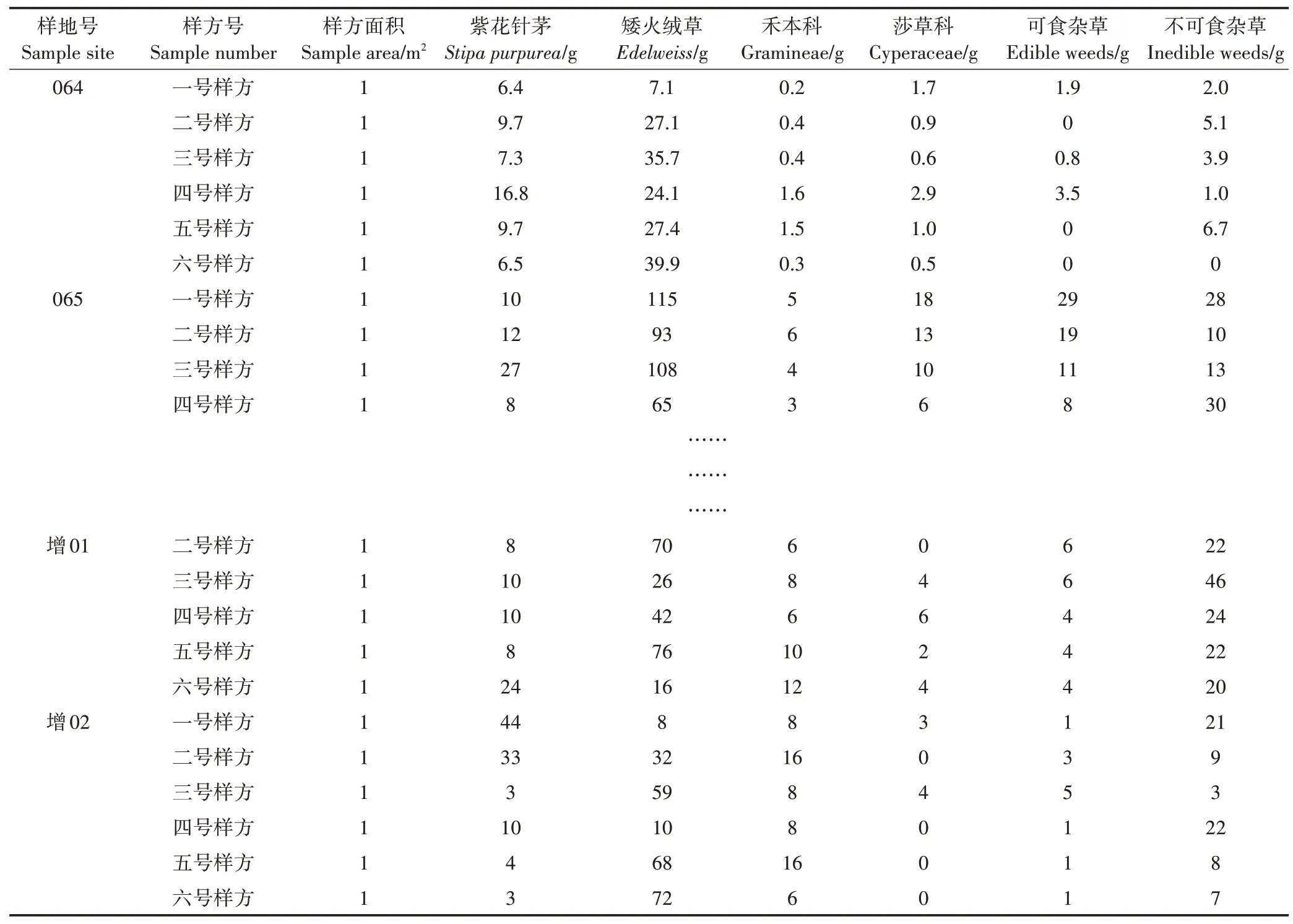
表2 草地鲜草质量样例预处理数据Table 2 Sample data of fresh grass weight for data preprocessing
通过EM 算法对缺失的草地生物量样例数据进行填充,并对填充后数据集与完整数据集进行平均绝对误差[22]、平均相对误差[23]、最大绝对误差[24]、均方根误差[25-26]等四个指标的对比,填充结果见表3和表4。
从紫花针茅字段的三组缺失数据填充结果(表3)来看,三组填充结果的平均绝对误差第一组最高,第三组次之,第二组最低,与之相对应的第一组平均相对误差最高,达到了39.12%,第二组、第三组分别为16.53%、26.81%。在最大绝对误差方面,第一组为25.91%,也远高于第二组、第三组。从表3可知,第一组的平均相对误差较大,说明第一组填充值与真实值之间的偏差与真实值的比值较大,原因是所构建的缺失数据集的缺失率不高,当第一组出现最大绝对误差达到25.91%的数据时,对整个数据集的填充造成比较大的影响。在反映数据填充精密度的均方根误差上,第一组最大,为12.34%,第二组最小,为2.30%,说明第一组的填充值与真实值之间的离散程度更高。

表3 紫花针茅三组缺失数据填充结果(%)Table 3 Filling results of three groups of missing data of Stipa purpurea(%)
从矮火绒草字段的三组缺失数据填充结果(表4)来看,三组填充结果的平均绝对误差第二组、第三组较为接近,分别为11.72%、11.01%,第一组相对其他两组更低,说明单个填充值与真实值之间的偏差不大。三组填充结果的平均相对误差值都不高,说明三组数据填充整体效果较好,数据可信度较高。在最大绝对误差方面,第二组、第三组均比第一组的值更高,这一特点同样在均方根误差上有所反映,第二组、第三组的均方根误差比第一组的值高,这是由于均方根误差对第一组值中较大或较小的误差较为敏感。由于不同样方、不同样地的生长条件不同,紫花针茅和矮火绒草生物量的真实值间也存在差异,因此这三组数据填充的最大绝对误差较大。

表4 矮火绒草三组缺失数据填充结果(%)Table 4 Filling results of three groups of missing data of Edelweiss dwarf(%)
一般来说,平均相对误差更能反映数据填充的可信程度,平均相对误差的值越小,数据填充效果越好[23]。总体而言,相较于孙华艳等[27]和熊秋芬等[28]研究中的数据精度,紫花针茅和矮火绒草字段数据填充结果的平均相对误差都较低,说明数据填充效果较好,数据预处理可信度较高。
(2)导入数据
把数据预处理之后得到的结构化数据映射为数据库表,导入Hive 数据仓库内。21 世纪以来,针对高寒草地生态变迁与退化的特性,我国在高寒区域广泛、连续地开展草地生态系统的监测活动,形成了一系列完整的生态监测站网体系,在这个过程中也累积了海量的历史数据,并产生了不断更新的实时监测数据[5,29]。
对于海量的历史数据与实时监测数据,本研究采用不同的处理方式导入Hive 中,完成数据的存储。对于海量的历史数据,使用Sqoop 从MySQL 关系型数据库中导入到Hive。将海量历史数据导入到Hive 中的方法建立在已经搭建完成Sqoop 的使用环境。首先通过Sqoop list database 命令定位到在Hive 中需要导入数据的数据库;然后筛选所需要的表及其相关的字段、属性;最后通过Sqoop import命令将数据导入到Hive 中。而对于实时监测数据,导入Hive 通常有两种方法:①直接从本地加载数据到Hive 数据仓库中,适用于数据量不大的情况;②数据文件导入Hadoop的分布式文件系统HDFS 中,再利用Hive 命令将数据从HDFS 中加载至Hive,适用于数据量较大的情况。本研究使用方法②将结构化数据导入草地类型主题表中指定的分区内。
2.3 数据存储
(1)数据结构的设计
根据表1 的标准,最终确定高寒草地关注度较高的数据:监测站信息、草地类型数据、生物量数据、气象数据、水文数据。根据以上数据内容对数据存储进行设计,归纳为以下5 个表:site_information、grasstype_data、biomass_data、meteorological_data、hydrological_data,主要的数据类型为string、int、float、date。本文以水文数据表(表5)为例进行数据结构设计。

表5 水文数据表字段Table 5 Hydrological data table fields
(2)数据存储分区设计
创建高寒草地数据库,设计高寒草地生态数据表,本文以草地类型数据表为例进行描述。本研究使用分区的方法对高寒草地数据表进行设计,主要原因如下:①由于Hive 适合对数据进行批量处理,在处理单条数据时较慢,每一次数据查询都要对数据仓库中所有的数据进行检索,因此,通过对数据表进行分区优化可以达到隔离数据和优化查询的目的;②采用分区的方法可以建立多维度的数据模型,在分析数据时可以选择不同的维度对数据进行处理。具体的分区如下。
时间:对于任何数据源的任何数据,时间都是一个很重要的属性,对于高寒草地的数据来说,时间是最必要、最基本的维度。本研究从历史数据库中导入日积月累的数据,同时也导入草地实时监测的更新数据,以保持系统的可靠性,因此,以时间为标准进行分区很有必要。
地域:考虑高寒草地数据主要从监测站点或者草地样方监测得到,本研究将高寒草地的数据以监测站点所在行政单位的行政区划代码为分区依据,同一行政区的所有草地监测数据被放在同一个分区之内,使得对于某个特定行政区内的数据进行查询和分析时,只需扫描分区内的数据。
来源:本系统的数据来源为青海省草原总站、青海省环境监测中心站、青海省气象局等部门,为了区分数据来源,将数据来源作为分区的标准。
高寒草地的数据主要由科学实地考察或者监测站点定时监测获得,因此,本研究通过以数据测定的监测站所在行政单位的行政区划代码为分区依据,使得对于某个特定行政区内的数据进行查询和分析时,只需扫描分区内的数据,避免对所有数据进行检索,从而大幅提升数据查询与分析的效率。另外,可以根据实际工作的需求,调整“分区”的划分,如以时间、来源、海拔等条件进行分区也是常用的选择。
2.4 数据查询分析
数据分析的目的是根据高寒草地数据的具体内容,通过本系统的数据处理过程,将处理结果进行保存并展示。根据高寒草地工作中的具体需求,本研究设计并实现以下几类数据查询与数据分析的函数。
(1)数据查询
数据查询是通过设置某些查询条件,从表或其他查询中选取全部或者部分数据,以表的形式显示数据供用户浏览。系统主要提供精确查询、模糊查询、表关联查询等基本数据查询方式,以从海量高寒草地数据中找到所需记录。
(2)数据分析
根据Hive 的特性及高寒草地海量数据的特点,本研究设计以下数据分析的函数用于处理高寒草地海量数据,主要包括:排序聚集函数、极限函数、嵌套函数、分片函数等。
嵌套函数:本研究构建嵌套函数,通过设计相关的嵌套查询语句查找每个水文监测站每年的最高径流量的均值。

分片函数:本研究通过构建分片函数进行数据分析,下文为水文数据分析示例。
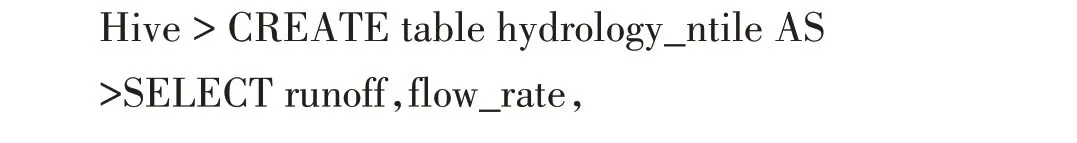

2.5 后置处理
(1)查看系统执行计划
在执行完成查询分析处理后,可以通过explain关键字查看执行查询计划的详细信息,包括抽象语法树、Hive 执行各阶段之间的依赖图、执行语句所对应的MapReduce代码及每个阶段的信息,以上信息有助于对查询分析处理进行调优,更加高效地使用Hive。
(2)数据分析结果保存
在完成数据查询分析处理后,需要对分析结果进行保存以便日后调用。由于经过分析查询得到的结果往往是经过筛选的数据或经计算得到的成果,因此数据量不会太大。为了方便使用,本系统使用insert overwrite local directory 语句将得到的结果保存在本地系统,方便查看。在完成保存结果后,可以通过shell 语句调用vim 或者gedit 文本编辑器对数据处理结果进行查看。
3 高寒草地海量数据分析系统性能测试
利用已经实现的基于Hive 高寒草地海量数据分析系统,分析其整体运行的情况,并通过设计三组实验的方式,对系统各项主要性能进行测试,了解本系统是否能满足高寒草地海量生态数据存储与分析的需求,得出本系统在处理海量数据方面的性能特点。本文对开展的三个实验进行说明。
3.1 测试实验
(1)第一组实验
为了验证Hadoop 平台是否对海量数据的存储有很好的适应性,本研究使用Hadoop 的基准测试工具TestDFSIO 测试Hadoop 平台的文件读写性能。通过TestDFSIO 工具,改变系统存储与读取文件的文件大小、文件数量,获取总运行时间和平均运行时间,以对集群的性能进行评价。控制文件数量为10,文件大小从5 MB 增加到500 MB,对系统的读写性能进行测试,获取总运行时间和平均运行时间,对系统的大小、文件读写性能进行评价。考虑到单次实验的偶然性,本研究进行了3 次实验取其平均值,实验结果如图3和图4所示。
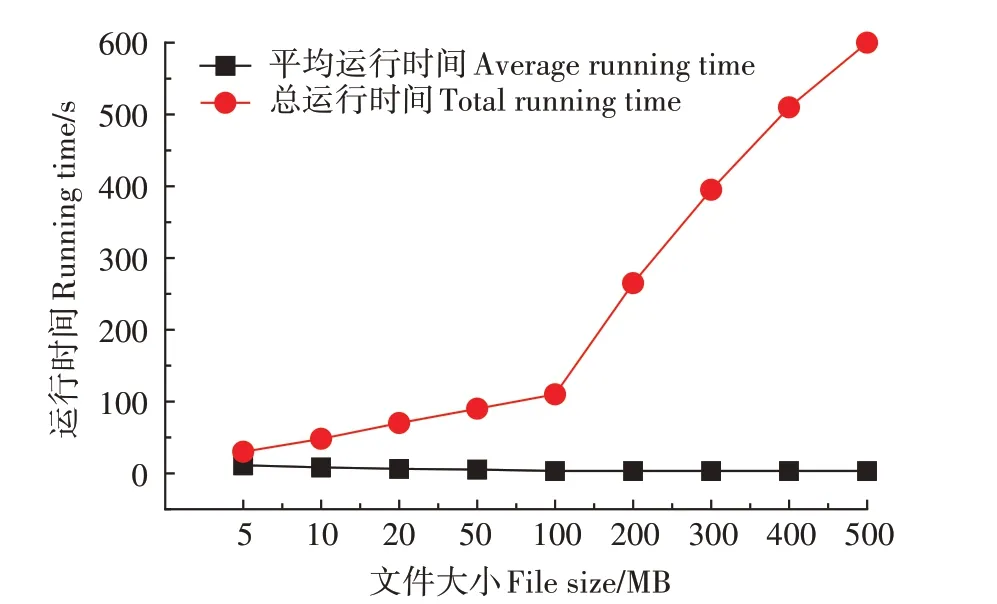
图3 Hadoop平台的存储数据文件与运行时间之间的关系折线图Figure 3 The line graph of the relationship between the stored data files and the running time of the Hadoop platform
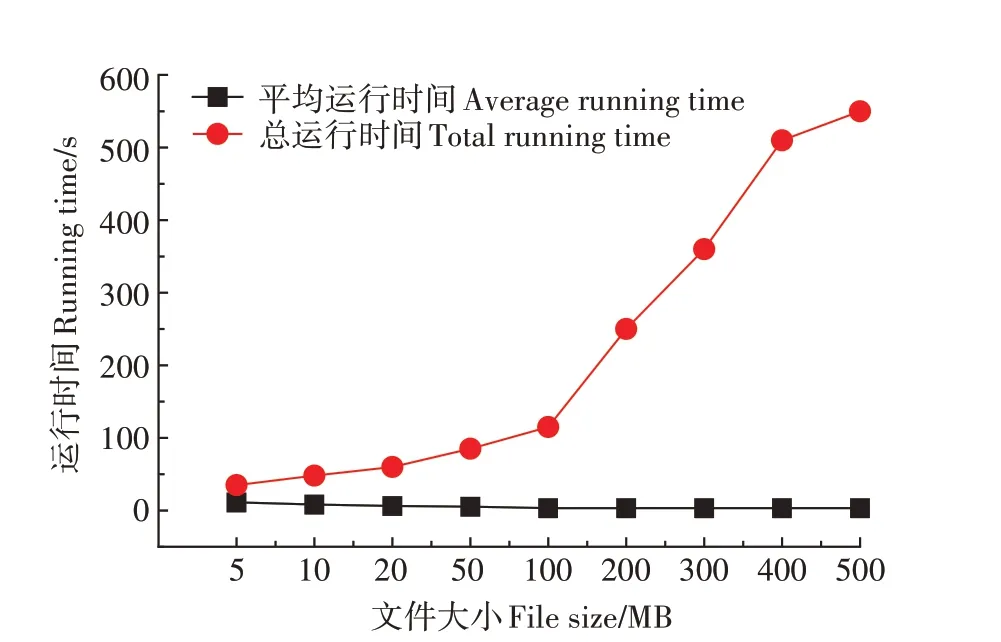
图4 Hadoop平台的读取数据文件大小与运行时间之间的关系折线图Figure 4 The line graph of the relationship between the size of the read data file and the running time of the Hadoop platform
图3 是数据规模的变化对系统存储数据文件与运行时间的影响。由图3 可知,随着文件大小的增加和总体数据规模的增大,系统的总运行时间一直呈增长的状态,但是平均运行时间(平均写1 MB数据所使用的时间)呈降低的趋势。总运行时间在文件大小高于100 MB 后,有非常明显的拐点且以更高的斜率上升,这与数据量的增加有关,说明系统对于大数据量的存储具有良好的性能。
图4是数据规模的变化对系统读取数据文件与运行时间的影响。由图4 可知,随着文件大小的增加和总体数据规模的增大,系统的总运行时间一直呈增长的状态,但是平均运行时间呈降低的趋势,说明随着数据量的增加,系统读取海量数据的能力也增强。
以上说明随着数据量的增加,系统并行处理海量数据的能力得到体现。因此,Hadoop 集群对高寒草地海量数据的存储有很好的适应性。
(2)第二组实验
为了解Hive 在分析海量高寒草地数据方面的效率,本研究对Hive 以及关系型数据库RDBMS 对数据处理的性能进行对比。测试数据采用2014 年青海省称多县草地样方监测数据和部分虚拟数据,总数据量约为3 958 万条,7.56 GB。对此数据采用SQL Server 2008 与Hive 集群进行字段“植物种类”中的查询处理,得到数据处理性能的对比。考虑到单次实验的偶然性,每组实验进行三次处理并取平均值得到最后结果。实验结果如图5所示。
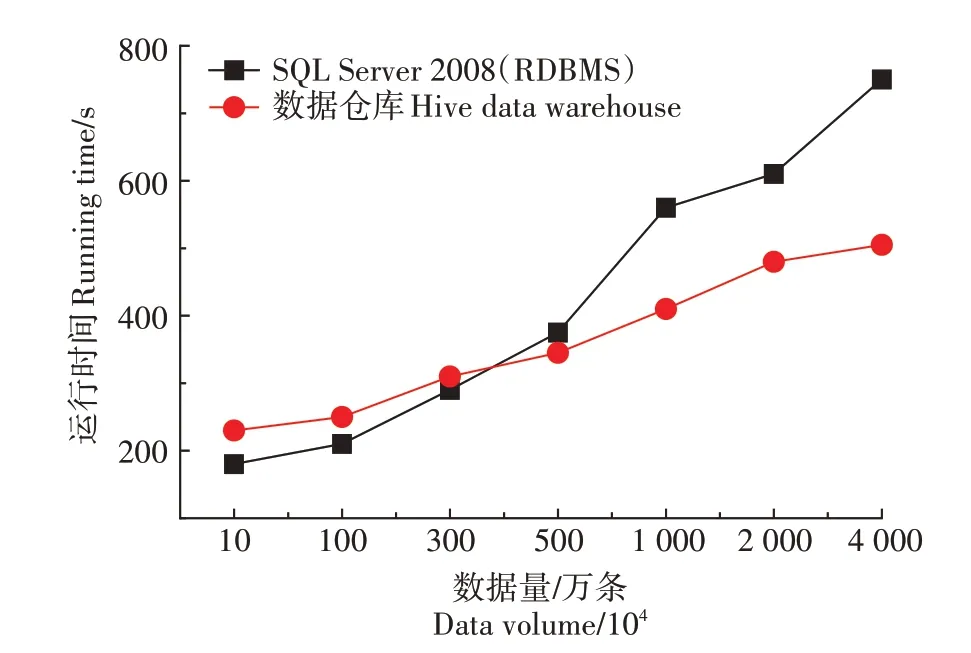
图5 高寒草地分析数据的数据量与运行时间关系折线图Figure 5 The line graph of the relationship between the data volume and the running time of the analysis of alpine grassland data
实验结果表明,当数据量较小的时候,RDBMS 的处理效率更高,本系统并行处理效率没有体现,但随着数据量的增大,当数据量超过350 万条后,本系统处理效率逐渐超过RDBMS,Hive 处理海量数据的优势十分明显。这是由于本系统是建立在Hadoop 平台上的数据批处理技术,集群对环境的初始化、任务调度及数据传输耗时较长,但当数据规模逐渐增大时,这些额外耗时基本稳定,额外耗时所占比例减少,本系统对海量数据的分析优势得以体现。实验证明,本系统对高寒草地海量数据的分析效率较高。
(3)第三组实验
在创建基于Hive 的高寒草地生态数据仓库后,可以通过HiveQL 对高寒草地生态数据进行分析处理,从海量数据中获取有用信息。为了验证本系统对海量数据的分析处理能力,开展第三组实验,实验采用2000—2015 年青海省草地类型数据,从中统计青海省东南部三县2007—2014 年的主要草地类型及其营养枝与生殖枝高度,通过本系统分析处理之后得到的结果如图6 所示。主要植物种类为:早熟禾、火绒草、高山嵩草、蒲公英、龙胆、苔草、马先蒿,其中早熟禾与蒲公英的营养枝、生殖枝高度较高,火绒草与高山嵩草高度较低。

图6 Hive系统数据分析处理结果Figure 6 Data analysis and processing results of the Hive system
为了验证以上数据分析结果的正确性,本研究开展相应的对照实验。首先从2000—2015 年青海省草地类型数据中筛选出2007—2014 年数据,再从中筛选出研究区的数据。然后,通过多次使用计数函数的方法统计各草地类型出现的频次,并对其进行排序,提取研究区最主要的草地类型。之后,分别计算每种草地类型的营养枝与生殖枝的高度,结果见图7。最后,将Hive 数据分析技术得到的结果与对照实验结果进行比对,发现两组处理结果相同。因此,实验证明,基于Hive 的数据分析技术可以从海量高寒草地生态数据中提取有效信息,分析效率较高,分析结果对于草地退化评价和草地生态保护等工作都具有较好的指导意义。
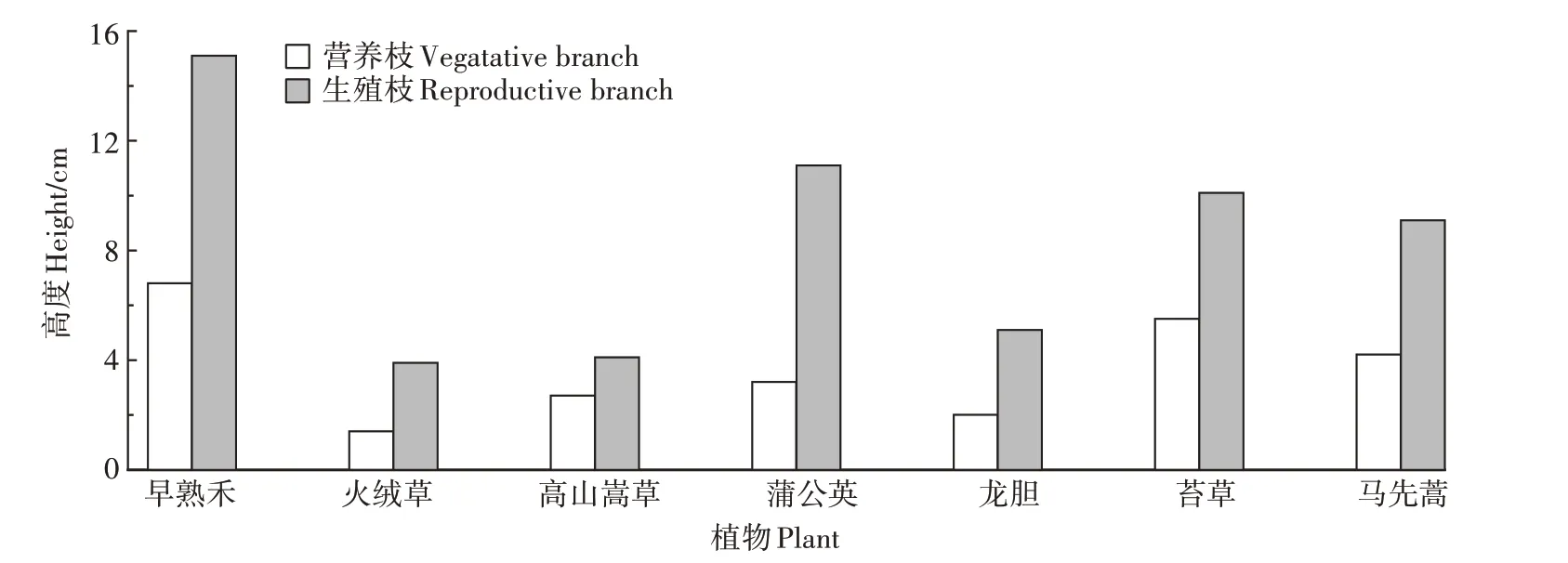
图7 对照实验数据分析处理结果Figure 7 Data analysis and processing results of control experiments
3.2 实验结果
为了测试本系统能否满足高寒草地海量数据存储与分析的需求,一共进行3 组实验,结果表明:①基于Hadoop的集群面对数据量增加时,整体并行处理能力得到体现,集群对海量数据的存储、读取都有很好的适应性。②Hive 系统对高寒草地海量数据进行处理时,相较RDBMS 方法具有更高的分析效率。③对照试验表明,Hive系统可以从海量高寒草地数据中提取有效信息。综上,Hive系统在对海量高寒草地数据进行存储和数据分析方面具有良好的性能,能够有效满足高寒草地海量数据的存储与分析要求。
4 结论与展望
4.1 结论
根据高寒草地数据存储的需要,本研究搭建基于Hadoop 的高寒草地海量数据处理平台。使用基于Hive的分布式数据仓库技术进行结构化数据的存储,使用HiveQL 语句对数据进行分析。通过使用EM 算法进行数据填充、数据导入、数据分区存储等步骤完成数据ETL及存储。之后,通过函数编码实现系统内各查询功能、分析功能,将数据分析结果进行后置处理,完成高寒草地海量数据分析。最后,进行系统性能测试。主要结论如下:
(1)Hadoop 平台具有较强的数据存储和读取性能。在文件数量为10 个,每个文件大小增加时,总体数据规模增大,系统整体存储、读取时间一直处于增长的状态,但是平均运行时间(平均处理1 MB数据所使用的时间)呈降低的趋势。说明随着数据量的增加,系统并行处理海量数据的能力得到体现。
(2)基于Hive的高寒草地数据分析系统对不断增长的海量数据具有较好的并行处理能力,并在查询的数据量超过350万条时,查询效率比SQL Server更高。
研究结果对高寒草地海量数据的存储和分析提供了新的思路及可行的方法,且能够满足实际应用的需求,对高寒草地海量数据的可靠存储和高效分析具有重要意义。
4.2 展望
本研究初步设计完成基于Hive 的高寒草地海量数据分析系统,主要的功能均已实现,相较于传统的Oracal、Mysql 技术具有拓展性能更强、计算效率更高的优势。但还有许多工作需要进一步研究和探讨,具体如下:
(1)系统功能的拓展
本系统的数据查询、数据分析功能是基于Hive进行设计实现的,通过对Hive 的特性研究了解到,仍有许多拓展性的技术有待开发应用于高寒草地海量数据分析系统。可以通过编写更多的用户定义函数(UDF),并在数据查询分析的时候调用,完成系统拓展,使得系统功能更丰富与强大。
(2)可视化交互界面
本系统目前由专业程序员使用,考虑到成本及开发时间因素,暂时没有提供可视化用户交互界面。因为很多的系统功能仍可进行拓展,目前的主要工作目标仍放在完善系统功能上,在系统运行过程中并未提供用户交互界面,因此,设计美观大方的系统可视化界面将是未来研究的一个重点。
(3)未来的研究方向
本系统是搭建在Hadoop 分布式计算框架上,通过对Hive 数据仓库工具进行开发实现的,Hive 只是本研究应用的所属于Hadoop 的其中一个工具,而在Hadoop 生态系统中仍有许多工具有待研究以应用于高寒草地数据的存储分析。HBase 可以用于高寒草地多源异构海量数据的存储,研究重点可放在基于HBase 对矢量空间数据并行存储和查询或者基于HBase 对遥感影像进行多维度并行存储。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
幼儿100(2020年31期)2020-11-18 03:42:00
电脑爱好者(2020年19期)2020-10-20 06:02:06
电子制作(2019年13期)2020-01-14 03:15:18
疯狂英语·初中版(2019年4期)2019-09-10 07:22:44
当代陕西(2019年14期)2019-08-26 09:42:00
小太阳画报(2018年6期)2018-05-14 17:19:28
幼儿智力世界(2017年3期)2017-04-26 23:39:37
