
DOCX 文档解析及隐藏信息提取算法
2021-12-14 01:48:22秦志红
通信技术 2021年11期
秦志红
(河南警察学院,河南 郑州,450046)
0 引言
微软的Office是目前最常使用的办公软件套装,其中的一个组件Word 是文字处理的必备工具。早期的Word 使用的是DOC 文档,是一种复合文档,由头部和扇区组合而成,其中的文字、图片、公式等信息以流的形式被区分,分别存储在不同的仓库中;而现在主流的DOCX 文档采用的文件组织方式则是一种基于压缩文件的新型可扩展标记语言[1](Extensible Markup Language,XML)格式。与之前的DOC 类型相比,DOCX 格式的文件打包方式可以减少文件大小、节省磁盘空间。由于DOCX 格式结合压缩和XML 格式,能加载语音、文字、图像、视频、链接等多媒体,DOCX 文档结构复杂;因此,一旦存在隐藏信息,比较难以发现。对于从事电子数据取证的专业人员,如果不能深入了解DOCX 文档的组织结构,则无法从中提取隐藏的有效信息,势必影响证据分析和证据链的形成。基于此,本文针对DOCX 文档进行研究,通过解析文档结构,提出信息隐藏的可能性并设计对应的隐藏信息提取算法。
1 DOCX 文档结构解析
DOCX 文档的文件头为“50 4B 03 04”,与ZIP 文件头类似,这是由于DOCX 文档的结构是按照压缩原理设计的;因此DOCX 文档的目录结构[2]展开来看和压缩文件一样具有文件系统的文件组织形式,并以树状结构排列,包含目录和子目录,其中叶子节点是一些文件流。
DOCX 文档中所包含的文件夹和文件各自定义数据和属性,但相互之间有一定的联系,而完整地读取其内容需要借助对应的应用程序。应用程序读写文档时,能够将全部的目录、文件解压出来并打开指定的目录,读写出其中某个文件流。一般来说,DOCX 文档包含[Content_Types].xml 文件、docProps文件夹、rels 类文件和文档内容类文件(一般在word、custom 等文件夹下),如图1 所示。

图1 DOCX 文档的目录结构
1.1 [Content_Types].xml 文件解析
[Content_Types].xml 文件对整个文档中内容所对应的媒体类型进行说明。在DOCX 文档中每使用一类媒体或元数据,[Content_Types].xml 都要增加一项类型包定义来说明,其中包含了所增加的媒体或元数据对应的入口位置以及解释方式,例如,rels 的媒体类型是“application/vnd.openxmlformatspackage.relationships+xml”,由这个顶级包负责解释。因此,应用程序读取DOCX 文件时,先解析[Content_Types].xml,就可以在[Content_Types].xml 中得到文档所用到的格式、内容、图片等所对应的媒体类型以及保存的位置,为下一步调用指出入口,具体如图2 所示。对于大部分DOCX 文档来说,[Content_Types].xml 的内容都是类似的,也就是说文档格式的媒体类型一样,生成的文件夹和子文件夹以及文件名称相同,只是在项目数量上有区别,例如某个文档没有插入图片,在[Content_Types].xml 中就会缺少<Default Extension="jpeg" ContentType="image/jpeg"/>语句。

图2 [Content_Types].xml 内容示例
1.2 rels 文件解析
rels 是relationships 的缩写,用来定义文档格式与媒体类型之间的对应关系。读取DOCX 文档时,根据rels 可以快速得到各部件和媒体类型格式包的对应关系,此时不需要考虑具体的格式,可以节省读取时间,因此统一命名为rels 类型。[Content_Types].xml 中解释了rels 的媒体类型,属于Office Open XML 的文件格式,可以按照XML 读取内容。在根_rels 文件夹和word、custom 等文件夹下都存储有rels 类文件,根文件夹下的rels 文件解释文档中主部件和顶级包的关系,如图3 所示,对主部件app.xml、core.xml 和document.xml 定义了对应关系。word 文件夹下的rels 文件document.xml.rels 列出document.xml 所需的其他部件,如果文档中有用户自定义的一些属性,则会在custom 文件夹下分别创建以item 命名的rels 文件,进一步解释当前文件夹下子部件和包的对应关系。

图3 rels 内容示例
1.3 docProps 文件夹解析
docProps 文件夹中包括core.xml、app.xml、custom.xml 等,在根文件夹下的rels 文件中解释了这些xml 文件和包的对应关系。custom.xml 记录文档的自定义属性,core.xml 和app.xml 用于记录DOCX 文档的主属性。core.xml 中的信息涵盖了文档的创建时间、修改时间、标题、作者等OpenXML文档格式的通用文件属性,app.xml 描述DOCX 文档的其他一些属性[3],例如文档类型、安全属性、只读信息、版本等特有的文件属性,这些内容以新型文件系统(New Technology File System,NTFS)主文件流的方式保存[4],与文件属性中的详细信息保持一致。core.xml 和app.xml 涵盖了文档详细信息的各个项目内容,如图4 所示。
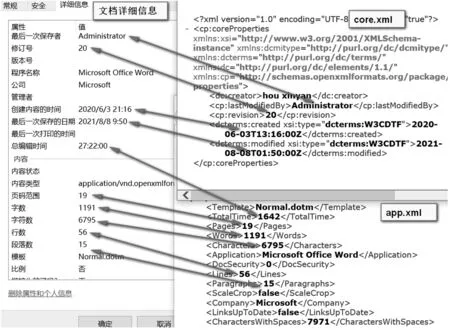
图4 core.xml、app.xml 和文档属性的对应
1.4 文档内容解析
word、custom 等文件夹保存了用户对文档的各种操作。custom 中以item 为首命名的xml 文件解释文档中的自定义数据部件,这个部件对文档的整体内容影响不大,即使缺失也可以正常读取文档内容。word 文件夹中包含了大量xml 文件,用来解释文档的页眉、页脚、批注、脚注、尾注、web 设置、自定义设置、格式、内容等,具体地,是在header1.xml、footer1.xml、comments.xml、footnotes.xml、endnotes.xml、websettings.xml、styles.xml、settings.xml、document.xml 等文件中解释。此外,还有一些子文件夹如theme、embeddings、media 等对文档中涉及的其他对象进行了说明,theme 文件夹中的theme1.xml 记录文档的格式主题,media 文件夹中存放着插入文档中的图片、视频等其他格式文件的缩略图,embeddings 文件夹中存放着文本文档等类型的文件。这些xml 文件按照WordXML 的语法格式对内容进行组织[5],具有很高的灵活性。在这些文件中,document.xml 非常关键,它是用来记录DOCX 文档正文内容的文件,文档内容在<w:body>…</w:body>中解释,在body 体内有3 类节点,分别是:<w:p>表示段落格式、<w:r>表示字符格式、<w:t>表示文本内容。其中,<w:t>包含在<w:r>体中,<w:r>包含在<w:p>体中。WordXML对不同的段落、字符格式进行相应的语法指定,例如某段文本为粗体,则用<w:b w:val=”on”>表示。图5 为document.xml 中的一段<w:p>体,文档的格式内容都有详细解释。
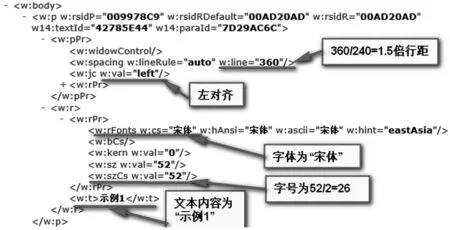
图5 document.xml 示例
media 文件夹和embeddings 文件夹会对文档中所插入的图片、对象等内容详细解释。图片类以源文件的形式保存在media 文件夹中,其他类型的对象在embeddings 文件夹中以OLE 形式保存二进制内容,media 文件夹中只保存缩略图。图6 为测试文档中分别插入exe、mp3、txt、jpg 等对象,在media 文件夹中都以image 为首命名,jpg 对象大小不变,在本示例中对源文件“示例.jpg”和“image4.jpg”分别计算Hash 值,得到二者的MD5 值都为“BB139707C16E35A85A6D94B7BEB023A5”,表示文件内容没有发生改变;但其他对象很明显有改变。要提取其具体内容,需要进一步分析。
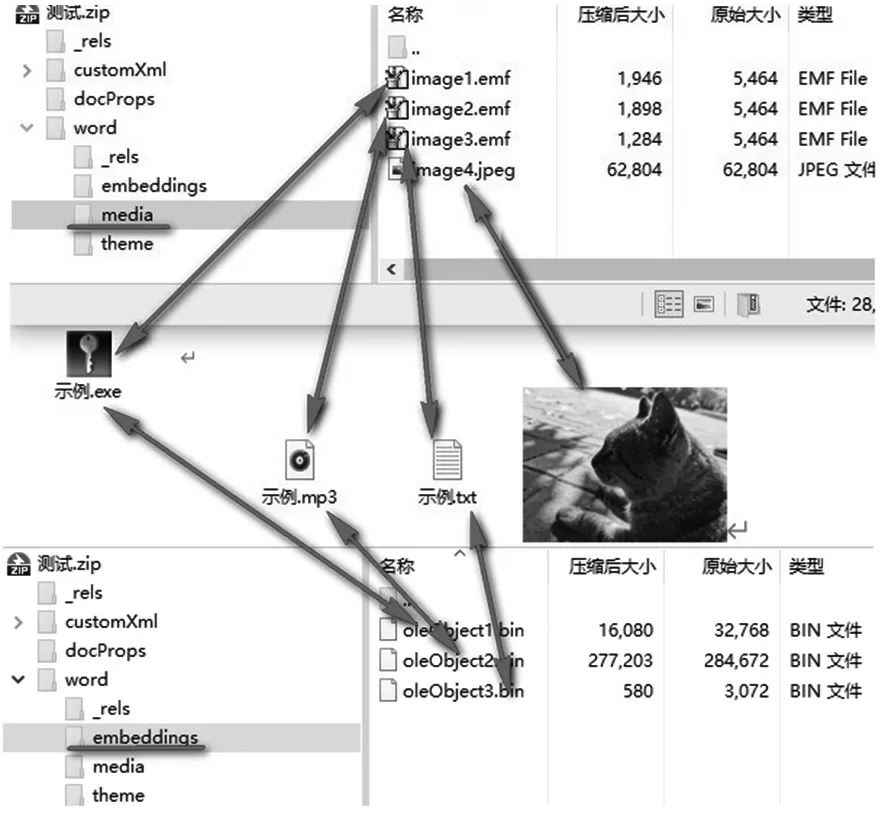
图6 DOCX 插入对象的存储方式
embeddings文件夹中的bin文件指向其他对象,DOCX 对这些对象采用OLE 技术进行封装,延续了复合文档技术,以扇区链的方式对数据流进行存储[6]。文档头在首扇区,大小为512 个字节,其后是Sectors 区,Header 中的参数包括复合文档标识、版本号以及扇区、短扇区等定义。图7为插入文件“示例.exe”在DOCX 中生成的OLE 对象oleObject.bin的文件头。

图7 DOCX 插入OLE 对象的Header 示例
示例中OLE 对象扇区大小为512 个字节,短扇区大小为64 个字节,扇区分配表(Sector Allocation Table,SAT),短扇区分配表(Short Sector Allocation Table,SSAT)都是占用1 个扇区,目录流位于第1 扇区。目录流按照红黑树的结构对数据进行组织,根据Header 中的参数,结合SAT为文件流创建的扇区编号SID 链,从目录流的入口得到数据存放的位置,并从文件头开始提取,可以得到插入的源文件。按照Header 参数计算后,在偏移16 进制数0A BC 处发现文件内容。该文件以“MZ”开头,与exe 文件头一样,说明找到了正确的文件保存位置。其他类型的OLE 对象可采用同样方法提取文件内容[7]。
2 DOCX 文档信息隐藏方法
上文研究了DOCX 文档的组织结构,对常用的部分做了解析。笔者发现,尽管DOCX 文档组织结构严密,但由于内容复杂,部分文件存在冗余,给信息隐藏提供了一些机会。事实上,电子数据取证人员在处理案件时也曾遇到这类隐藏数据。在DOCX 文档中隐藏数据时需要结合其组织结构,找到对文档没有影响并且不易被发现的位置。xml、rels 以及插入文档的对象之间存在关联,隐藏信息时一般都会对这些关系进行梳理后找到隐藏位置并自我伪装。
2.1 基于关联对象的信息隐藏
[Content_Types].xml 作为DOCX 文档的入口,文档中每添加一类对象,就需要在[Content_Types].xml 进行声明,那么如果所添加的对象没有在其中声明,是否DOCX 就无法对其识别解释,而实际达到隐藏数据的目的呢?笔者将上文中的测试文件改变扩展名为zip 后,在media 文件夹中添加jpg 文件image.jpeg,结果DOCX 文档能够正常打开,而添加png 文件image.png 后,文档出现了错误。对[Content_Types].xml 的内容进行分析,发现内容中存在语句:
<Default Content Type="image/jpeg"Extension="jpeg"/>
结合前面的解析,该语句是对jpg 类型的声明,如果文档插入有此类对象,则默认存在其他jpg 对象。而[Content_Types].xml 中缺少了对png 类型对象的声明,所以文档在media 文件夹中发现png对象后会出现错误。按照这个思路篡改[Content_Types].xml 内容,添加语句:
<Default Content Type="image/png"Extension="png"/>
发现DOCX 文档可以正常使用。
除了可以在media 文件夹下隐藏图片类对象,还可以在embeddings 文件夹下隐藏exe、mp3 等其他类型的对象。按照DOCX 的语法,在media文件夹下隐藏的文件需要命名为image 开头,在embeddings 文件夹下隐藏的文件需要命名为oleObject 开头,否则应用程序无法正常打开。
为何所隐藏的文件能正常存在于文档中而不被DOCX 识别到呢?上文研究证明了隐藏文件能正常存在于文档是由于在[Content_Types].xml 中对对象的类别进行了声明,下面进一步分析实现隐藏的原因。
在rels 文件中对文档与媒体类型之间的关系进行了解释。图2 中是对顶级包和媒体类型之间确立关联关系,插入文档中的具体对象则在子文件夹中的rels 文件详细关联解释,例如上文中插入“示例.exe”后,先在[Content_Types].xml 中添加语句:
<Default Content Type="image/x-emf"Extension="emf"/>
声明在image 文件夹下添加这个文件的缩略图,还需要对word 下的rels 文件增加的两行语句为:
<Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image" Target="media/image1.emf"/>
<Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/oleObject" Target="embeddings/oleObject1.bin"/>
这两行语句分别对media 文件夹下的缩略图和embeddings 文件夹下的OLE 对象解释关联关系。
综上所述,可以得出:由于rels 中没有解释image.png 对象的关联关系,导致了应用程序读取DOCX 文档时,无法形成数据链,遗漏了存在于media文件夹下的image.png,从而实现了信息的隐藏。
2.2 基于文档扩展空间的信息隐藏
DOCX 文档的文字内容存在于document.xml 中,结合其他xml 文件解释页面、段落、字符内容及格式设置。这些xml 文件必须符合OfficeXML 格式和语法,如果在xml 文件中添加信息进行隐藏,则会因语法错误造成DOCX 文档不能正常读取。如果希望隐藏少量关键信息,则可以在扩展空间中操作[8],这种方式不会改变文档大小,隐蔽性强,不易被发现。
由于DOCX 采用了ZIP 压缩格式[9],可以根据ZIP 文件格式找到扩展空间,按照一定规律在扩展空间中对信息进行隐藏。ZIP 结构包括数据区(50 4B 03 04 标志)、目录区(50 4B 01 02 标志)和结束标志区(50 4B 05 06 标志)3 部分,其中,数据区和目录区按照压缩文件记录排列。数据区所占空间最大,包括头结构和数据,头结构如图8 所示,文件名长度为001CH(28 个字节),扩展记录长度为0108H(264 个字节),即文件名后的264 个字节为扩展记录,扩展记录的前8 个字节为有效内容,其他用0 填充,这样就存在256 个字节的填充区域,这部分扩展空间是冗余的,可以填充任何数值。

图8 DOCX 数据区头结构
在这个拓展区域中填充“password:123”后,文档正常读取,证明针对此区域的信息篡改不会对DOCX 文档造成任何影响,那么就可以利用这些拓展记录的填充区域隐藏数据。
3 DOCX 文档隐藏信息检测提取算法
上文中验证了在DOCX 文档中隐藏信息的可能性,在实际工作中需要检测并提取到这些隐藏信息。针对上述信息隐藏方法,笔者分别设计了基于关联对象隐藏信息的检测提取算法和基于文档扩展空间隐藏信息的检测提取算法。
3.1 基于关联对象隐藏信息的检测提取算法
基于关联信息的信息隐藏是对[Content_Types].xml、document.xml.rels 和media、embeddings 文 件夹下插入对象的关联关系进行篡改后实现的,那么检测并提取这些信息,就要按照这个思路对这些关联信息进行检测,如果出现关系链不完整的情况,则意味着存在隐藏信息。
具体算法流程如下:
(1)按照ZIP 格式解压DOCX 文档;
(2)检索[Content_Types].xml,如果检测到语句:
<Default Content Type="image/*"Extension="*"/>;
(3)则继续检索/word/_rels/document.xml.rels,如果检测到语句包含:
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image"Target="media/image?.*
则提取Target 的值;
(4)如果Target 的值包含“emf”,则检索/word/embeddings 文件夹,否则检索/word/media 文件夹;
(5)如果存在与(3)中不匹配的文件名,则确定该文件为隐藏文件,提取该文件。
3.2 基于文档扩展空间隐藏信息的检测提取算法
扩展空间中隐藏信息是在对DOCX 文档解压以前进行的,因此检测提取这些信息针对的是原始DOCX 文档。通过检索文档的编码找到扩展空间,提取冗余空间内容并分析获得隐藏信息。
具体算法流程如下:
(1)检索文档16 进制内容,设置检索关键字为“504B0304”,自上向下开始检索;
(2)当检索到关键字,按照16 进制从当前位置向后偏移1 个字节,提取该双字节数值len1,继续向后偏移2 个字节,提取该双字节数值len2;
(3)继续向后偏移len1+8 个字节,从当前位置开始提取len2-8 个字节长度的内容;
(4)分析提取的内容,如果不是0,则确定为隐藏数据;
(5)继续向下检索关键字“504B0304”,如果命中,则按(2)~(4)处理。
3.3 算法分析
上面两个算法分别针对不同的隐藏方式,在实际应用中可能存在两种方式并存的情况,因此要同时采用两个算法进行检测。第一个算法的操作对象是目录和文档内容,如果文档插入对象较多,则会影响检测速度。第二个算法是针对文档的源文件开展检索,运行速度较快,但是提取的内容为二进制,需要结合实际情况用智能分析手段判断数值的实际含义。
4 结语
随着对DOCX 文档更深入详细的解析,利用其组织结构中的漏洞进行信息隐藏的手段会越来越多。本文通过研究的信息隐藏方法,针对解压前的源文件和解压后的目录树,提出了检测算法。该算法涵盖了XML、OLE、插入对象等,覆盖面较广、可操作性强;但提取的可疑信息是否为有效线索,特别是如何获知扩展空间中二进制源码的含义,还需要进一步思考和研究。此外,document.xml 等xml 文件中包含的文档内容、格式,core.xml 和app.xml 中解释的文档属性,以及OLE、IMG 等部件中的对象等都是DOCX 文档的关键组成[10],如何针对这些重要部分进行信息篡改、设计检测算法,也值得继续开展研究和讨论。
猜你喜欢
小猕猴智力画刊(2023年4期)2023-04-23 08:50:18
南北桥(2022年2期)2022-05-31 04:28:07
销售与市场(营销版)(2021年10期)2021-11-21 20:15:03
销售与市场(营销版)(2019年6期)2019-06-21 01:16:38
电脑知识与技术·经验技巧(2017年9期)2018-02-24 19:55:20
网络安全技术与应用(2017年9期)2017-09-20 09:54:28
电脑爱好者(2017年15期)2017-08-31 20:21:12
西南交通大学学报(2016年4期)2016-06-15 20:29:36
计算机技术与发展(2016年10期)2016-02-27 00:44:08
电脑迷(2015年1期)2015-04-29 21:24:13
