
基于图匹配网络的可解释知识图谱复杂问答方法
2021-12-14 11:32孙亚伟瞿裕忠
计算机研究与发展 2021年12期
孙亚伟 程 龚 厉 肖 瞿裕忠
(计算机软件新技术国家重点实验室(南京大学) 南京 210023)
随着大规模开放性知识图谱的增多[1-2],人们获取知识的需求愈发突出[3],知识图谱问答是从知识图谱中获得知识的最佳途径之一[4].同时,问答系统的可解释性也受到了广泛关注[5].
早期知识图谱问答聚焦在简单问句,比如问句“Who is the wife of Obama?”,通过知识图谱中的实体“Obama”的单步关系(“spouse”)可获得答案.然而回答复杂问答(涉及多步边或聚合操作的问句)是一个难题[6].本文聚焦在复杂问句,比如“What movies were directed by the actor in Titanic?”,回答该问句需要知识图谱中实体“Titanic”的多步边(本文采用该问句作为例子贯穿全文).
近几年涌现不少知识图谱复杂问答的工作[7-13].尽管这些工作取得了一定效果,但问句结构尚未被充分利用.按照利用问句方式不同,可以分为基于序列编码(sequence-based encoder)[7-10]和基于路径编码(path-based encoder)[11-13]两类方法.他们各自存在不足:
1)序列编码缺乏可解释性.具体地,序列编码视问句为单词序列,通过编码构造问句表示,如QGG[7]直接把问句通过预训练语言模型BERT[14]编码,然后进行查询图预测.KBQA-GST[8]利用卷积神经网络对问句序列和关系路径序列编码,然后计算内积得到相似度.Slot Matching[9]把问句通过BERT编码,然后利用注意力机制得到问句表示.DAC[10]通过双向GRU编码问句,然后把所有单词隐状态求均值,作为问句表示.
2)路径编码忽略问句整体结构信息.具体地,路径编码视问句为语法路径(如依存或AMR结构路径)进行编码,从而获得更丰富的问句表示,如gAnswer[11]利用依存路径表示问句查询图(超图),然后通过子图匹配算法映射成可执行的查询.CompQA[12]利用循环神经网络对问句中疑问词和主题实体的依存路径编码.NSQA[13]取AMR结构中的路径表示问句结构.
由此可见,现有工作缺乏从图结构编码(graph-based encoder)的视角对问句结构进行整体表示.
如图1所示,该例子反映了本文工作的动机,即从图结构角度对问句建模的必要性.具体地,从序列编码角度,图1(c)容易误判为正确查询图,因为对于图1(c)的序列:“film,actor,directed_by”和图1(d)的序列:“directed_by,actor,starring”,问句和图1(c)的语义匹配看似大于问句和图1(d)的匹配.但一旦引入图1(b)未定查询图,图1(d)就可以识别出来.因为图1(b)的“?movies-directed_by→?actor”和图1(d)的“?x-directed_by→?c”语义匹配大于和图1(c)的“?x-film→?m”匹配.图1(b)中的“Titanic-in→?actor”与图1(d)的“m.0dr_4-starring→?m-actor→?c”语义匹配大于和图1(c)的“?m-actor→?c←directed_by-m.0dr_4”匹配.
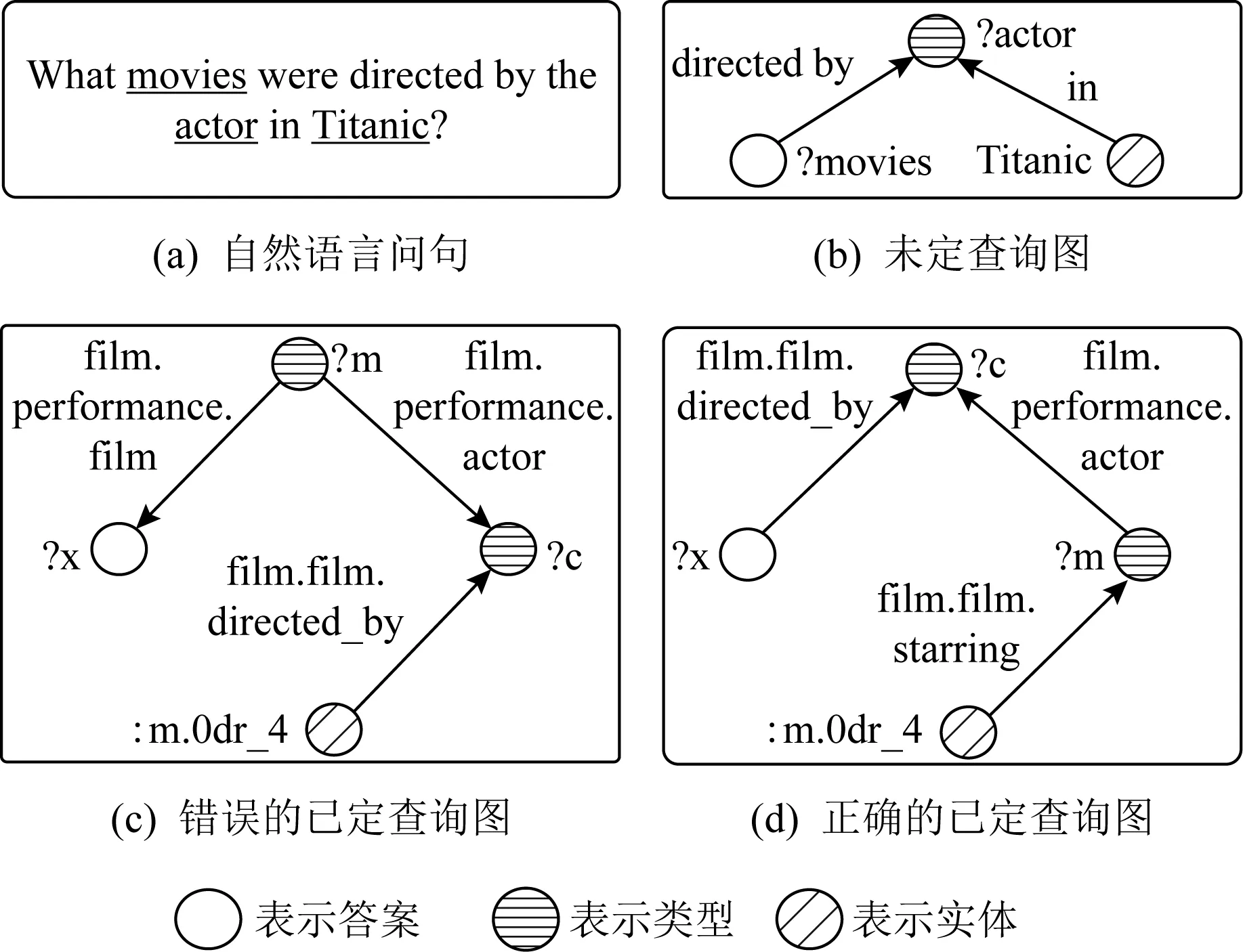
Fig.1 Motivation of our work
为了对问句结构整体表示,本文提出一种基于图匹配网络的知识图谱复杂问答方法TTQA.首先,通过依存分析,构造一个与知识图谱无关的问句查询图(简称未定查询图).其次,基于预训练语言模型和图神经网络技术,提出一种图匹配网络(graph matching network, GMN),用于生成可执行的结构化查询(简称已定查询图).最后在给定知识图谱执行查询,获得答案.TTQA生成未定查询图和已定查询图作为参照,提升了方法的可解释性.
本文的主要技术贡献是提出了一种适用于知识图谱问答的图匹配网络GMN,其结合了预训练模型和图匹配网络学习技术,计算未定查询图和已定查询图的语义匹配.相比序列编码和路径编码方式,基于图结构的方法不仅完整地建模问句信息,而且还使得问答系统更具有可解释性.
在2个常用知识图谱复杂问答数据集LC-QuAD 1.0[15]和ComplexWebQuestions 1.1[16]进行实验.实验结果表明,TTQA超过了现有基准方法.同时,消融实验验证了GMN模块的有效性.
本文提出的方法已开源:https://github.com/nju-websoft/TTQA.
1 相关工作
知识图谱复杂问答可以分为3类:基于语义解析方法(semantic parsing, SP-based)、基于信息检索方法(information retrieval, IR-based)和其他方法.语义解析具有可解释性,而信息检索和其他方法缺乏可解释性.
1.1 语义解析方法
语义解析的目标是生成可执行的结构化查询(如SPARQL).根据问句编码方法不同,可以细分为基于路径编码和基于序列编码的方法.
基于路径编码的语义解析方法.CompQA[12]提出一种基于GRU的语义匹配模型,该模型融入问句依存路径信息,从而得到更丰富的问句表示;gAnswer[11]提出一种子图匹配的查询图方法,利用问句依存路径构造语义查询图,再利用子图匹配映射成可执行的查询图;TextRAY[17]提出一种基于拆解和拼接方法,通过指针网络拆解复杂问句,利用依存路径匹配查询图;NSQA[13]提出一种基于抽象语义表示(abstract meaning representation, AMR)的查询图方法,使用AMR工具分析问句,利用基于路径编码的映射方法把AMR结构转换成查询图,映射时采用了关系链接工具SemREL[18].
基于序列编码的语义解析方法.QGG[7]提出一种基于状态转移的查询图生成方法,为了给候选查询图排序,该方法采用BERT对问句和查询进行序列编码;Slot Matching[9]提出一种基于槽匹配的语义匹配方法,利用LSTM对问句和查询图序列编码,再利用注意力机制生成问句表示;GGNN[19]提出一种基于门控图神经网络方法,使用卷积神经网络对问句序列编码;DAC[10]提出一种基于强化学习的导演-演员-评论者(director-actor-critic)框架.
本文提出的TTQA属于语义解析方法,相比路径编码和序列编码,TTQA采用图结构编码,这样做有助于完整地考虑问句结构信息.进一步,TTQA利用多视角匹配的注意力机制,从而增强了语义匹配的效果.
1.2 信息检索和其他方法
信息检索的目标是直接在知识图谱上检索答案.该类方法可解释性欠佳,多数工作的问句编码方式是基于序列编码.具体地,NSM[20]提出一种基于神经状态机器的教师和学生网络框架,学生网络用于查找正确答案,教师网络用于学习中间监督信号来提升学生网络的推理能力.SRN[21]提出一种基于强化学习的逐步推理(stepwise reasoning)网络,把问答形式化为序列决策问题,通过执行路径搜索来获取答案,同时考虑了束搜索(beam search)来减少候选数量.为了减少延迟和稀疏奖励问题,该方法提出了奖励塑造策略.KBQA-GST[8]是一种基于主题单元的生成与打分框架.该框架分2个步骤:主题单元链接和候选答案排序,采用强化学习联合优化.WDAqua[22]提出一种多语言的知识图谱问答方法,该方法分4个步骤:问句扩展、查询构造、查询排序和回应决策(response decision).其中查询排序采用包含问句序列信息5个特征的线性组合.
同时也存在基于图编码方法:AQG[23].近期还出现知识图谱表示学习[24]、结合文本和知识图谱混合式问答方法[25]、基于拆解和阅读理解方法[16]等.
相比这些可解释性欠佳的方法,TTQA基于语义解析生成的未定查询图和已定查询图提高了模型可解释性,且在语义匹配模型中考虑了问句结构,增强了模型的性能.
2 TTQA方法概述
本节首先给出问题定义,然后描述提出的TTQA方法框架.
2.1 问题定义
表1为本文方法所用的符号,给出定义1.
定义1.复杂问句.q=w1,w2,w3,…,wl涉及多边或多实体(数值)的问句;涉及聚合/计数/比较/最高级操作的问句.本文关注涉及多边或多实体(数值)的问句.

Table 1 Summary of Notation in Our Approach


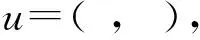
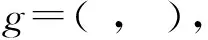
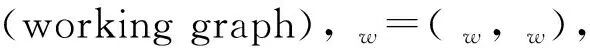

Fig.2 Working graph
定义7.语义近似匹配.由于u和g之间可能异构,严格匹配定义不适用,故采用图近似匹配,即图近似匹配任务[27]中的定义sim(u,g)→表示近似匹配.
2.2 TTQA方法框架
本文提出的TTQA如图3所示,主要包含2个部分:1)未定查询图生成模块;2)已定查询图生成模块.通过这2个模块,最后把已定查询图转换成标准查询语句(如SPARQL),在知识图谱执行,获得答案.

Fig.3 The framework of GMN-based TTQA
2.2.1 未定查询图生成
输入问句q,未定查询图生成模块的目标是生成u.如图3所示,该模块分3个子模块:1)语法分析;2)顶点识别;3)关系抽取.其中语法分析子模块采用作者提出的骨架解析方法[28],首先获得该问句的宏观结构,然后进行细粒度依存分析用于得到骨架内部的修饰关系.顶点识别子模块结合了BERT分类器、CoreNLP工具和SUTime来识别实体提及、数值提及、类型变量和答案顶点[28].关系抽取采用顶点优先框架[11]进行关系抽取,并合并变量得到未定查询图u.
例1.针对图1(a)问句,识别出答案顶点“?movies”、类型变量“?actor”和实体提及“Titanic”.通过关系抽取子模块,构造未定查询如图1(b)所示.
2.2.2 已定查询图生成
例2.如图1所示,给定图1(b)未定查询图和Freebase知识图谱,实体链接把实体提及“Titanic”链接到实体“m.0dr_4”,然后通过子图检索,获得若干候选已定查询图,其中包含图1(c)和图1(d).通过GMN模型,返回图1(d),作为预测已定查询图.
2.2.3 聚合限定和重排序
复杂类问句中有一类涉及聚合操作(如计数、比较和最高级等类问句),本文不作为重点,仅做了启发式规则处理,具体涉及:聚合类问句识别,聚合限定和聚合类问句重排序.
聚合类问句识别.采用一种基于BERT的问句类型分类器,预测非聚合、比较和最高级等类型.
聚合限定.采用现有方法[29],即一旦遇到涉及比较/最高级类问句,追加数值属性约束.
聚合类问句重排序.由于未定查询图缺乏表达聚合能力,所以在图匹配网络后,叠加后处理:对聚合类问句重排序.采用基于GloVe[30]打分函数,抽取g中涉及聚合三元组或路径与q计算词级相似度.最后与图匹配网络的置信度线性组合,得出g最终置信度.
3 图匹配网络模型
现有的序列编码和路径编码方法是线性模型,只能获取问句局部信息,无法捕获问句整体信息.针对该局限性,本文提出一种基于注意力机制的图匹配网络GMN.输入u和g,输出匹配度sim(u,g).如图1所示,目标是sim(u,gd)>sim(u,gc).gc表示表示图1(c),gd表示图1(d).
把sim(u,g)视为机器学习二分类问题,学习一个类型概率分布p(g|u),取正类型的概率作为sim(u,g).
3.1 模型框架
跨图注意力机制的图匹配模型GMN框架如图4所示,包括3个部分:1)文本编码;2)图编码和3)模型预测.其中,以未定查询图u和已定查询图g作为输入,文本编码模块使用BERT对u和g进行序列编码;图编码模块使用图匹配网络对u和g进行编码,并采用了跨图注意力机制融入上下文信息,从而得到更丰富的图表示用于模型预测;模型预测模块采用多层感知机(multi-layer perceptron, MLP)预测概率分布.

Fig.4 Cross-graph attention graph matching network
3.2 文本编码
文本编码模块是从语言模型角度,对u和g编码表示和聚合信息.形式化为
zLM=fenc(Text(u),Text(g)),
(1)
其中,zLM为两者文本编码输出表示,Text(u)是u的文本序列,Text(g)是g的文本序列,fenc是编码函数.本文把用标签替换实体/数值提及的问句作为Text(u).同时,采用一种基于字符序的深度优先遍历算法把g序列输出作为Text(g).
本文采用BERT编码作为fenc.如图5所示,形式化为
hbert=BERT([CLS]Text(u)[SEP]
Text(g)[SEP]),
(2)
其中,hbert是BERT编码输出隐向量.把聚合信息CLS位置对应的隐向量hCLS,作为文本编码输出zLM.
例3.对图1(b)序列化,Text(u)=What movies were directed by the actor ine?.对图1(d)序列化,Text(g)=?x directed by?c actor?m starringe.
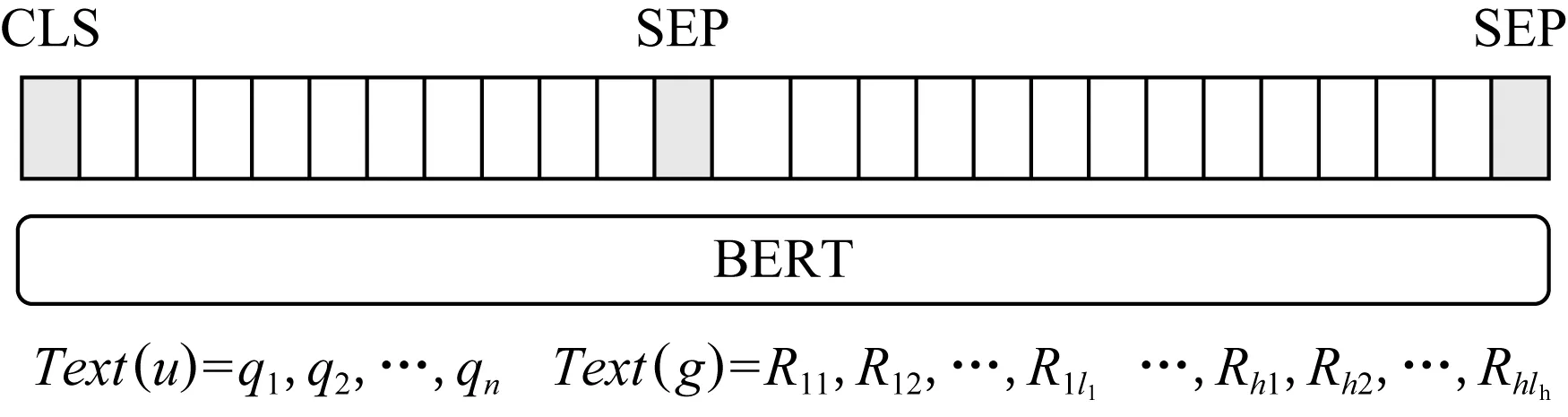
Fig.5 BERT-based text encoder
3.3 图编码
(3)

3.3.1 顶点嵌入层
1)从BERT输出的隐向量hbert中截取相应位置向量,均值池化(mean pooling),作为v初始表示hv.
(4)
2)构造一个多层感知机用于把hv映射到图匹配网络的语义空间,形式化:
hv=MLP(hv)=Linear(ReLU(Linear(hv))).
(5)
(6)
(7)
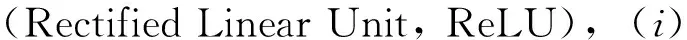

Fig.6 GCN-based node embedding layer

Fig.7 Example of cross-graph attention mechanism
3.3.2 跨图注意力的匹配层
受图近似匹配工作[32-34]启发,本文采用注意力机制[35]融入上下文跨图匹配信息.该模块包括2个部分:1)学习上下文向量;2)匹配当前向量.
1)学习上下文向量.如图7所示,首先对当前图u顶点i与跨图g任意顶点j,计算注意力权重ai,j为
(8)
其中,s是向量相似函数,本文采用余弦函数.
(9)
2)匹配当前向量,本文采用多视角匹配函数(multi-perspective matching function)[33-34]:
(10)
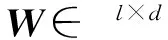
(11)
其中,∘表示逐元素相乘,Wk是第k视角可调向量.
以同样的方式,计算g中顶点j的匹配向量.最后得匹配向量m,赋值给当前顶点,传入图池化层.
3.3.3 图池化层
如图8所示,图池化层用于从顶点表示计算图结构的表示,使用均值池化(mean pooling),获得u和g的低维连续空间表示hu和hg,形式化:
(12)
(13)
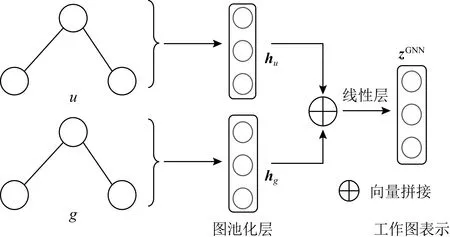
Fig.8 Graph pooling and working graph representation
3.3.4 工作图表示层
如图8所示,工作图表示层用于计算工作图表示zGNN.本文把hu和hg拼接,然后过一个线性层(feed-forward network, FFN),输出zGNN.
zGNN=FFN([hu,hg]).
(14)
3.4 模型预测
预测函数.把文本编码zLM和图编码zGNN拼接成一个向量,然后通过一个随机丢弃(dropout),最后过一个多层感知机,输出2分类概率分布p(g|u):
p(g|u)=MLP([zLM,zGNN]),
(15)
pg表示从概率分布p(g|u)取正类维度的置信度.
(16)
损失函数.本文采用交叉熵损失函数来优化模型.
(17)
其中,j是真实标签(ground-truth label)的下标.
4 实 验
本节介绍实验情况,依次介绍2个公开数据集、采用的评测指标、基准方法、实验设置,然后给出实验结果和消融实验,最后对实验结果进行错误分析.
4.1 数据集
本文采用2个公开的复杂问答数据集:LC-QuAD 1.0和ComplexWebQuestions 1.1.之所以选择这2个数据集,是因为它们是DBpedia和Freebase上较为常用的复杂问答数据集.数据集规模统计如表2所示:
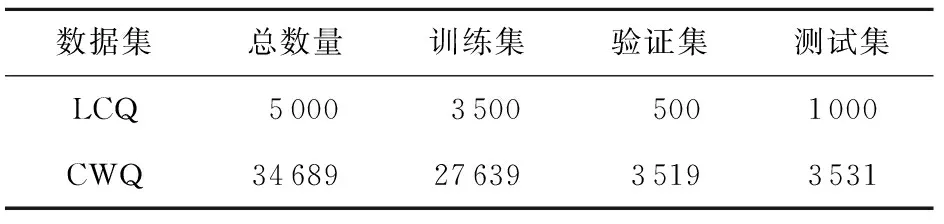
Table 2 Dataset Size Distribution
1)LC-QuAD 1.0(LCQ)[15]包含5 000个问句.它是DBpedia(2016-04版本)上的一个复杂问答数据集,其中超过80%问句涉及多边、布尔或计数操作.由于数据集作者未提供验证集,按照1∶7比例从训练集随机采样500个问句,作为验证集,剩余作为训练.
2)ComplexWebQuestions 1.1(CWQ)[16]包含34 689个问句,它是Freebase(2015-08-09版本)上的一个复杂问答数据集.其中所有问句涉及多边或聚合操作(比较和最高级).本文采用的训练集、验证集、测试集来源于数据集作者提供,另外数据集作者也提供了文本片段来求解问句,但是本文只关注知识图谱求解问句.
4.2 评测指标
为了与各数据集上基准方法公平对比,本文采用3个评测指标:Macro-F1,AverageF1和Precision@1.
1)Macro-F1(m-F1).首先计算每个问句的精确率(precision,P)和召回率(recall,R),然后在所有测试问句上求均值得到MacroP和MacroR,最后调和平均求出m-F1.细节请见文献[36].
2)AverageF1(avg-F1).首先计算每个问句的精确率和召回率,然后调和平均求出F1,最后取所有问句的F1均值,得出avg-F1.
3)Precision@1(P@1).最终排序的第一位置是正确答案的占比.细节请见文献[16].
4.3 基准方法
如表3所示,本文对比了已发表的近几年最佳的端到端方法.另外说明:NSM,AQG,PullNet,Slot Matching未被列入基准方法,是因为他们假设正确实体已知,结果与本文不可比.TextRAY未被列入基准方法,是因为其采用CWQ 1.0,结果与本文不可比.
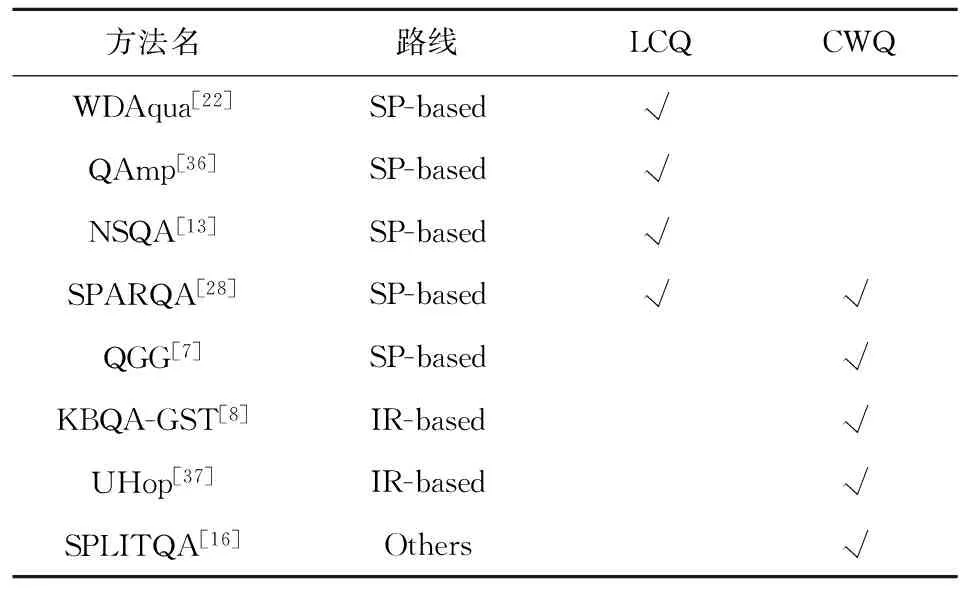
Table 3 Methods to Compare
1)WDAqua提出一个基于特征工程的方法,包括问句扩展、查询构造、查询排序和回应决策.
2)QAmp是一种基于矩阵乘法的消息传递方法,包括问句解析和消息传递.
3)NSQA是一种基于AMR的查询图生成方法,把AMR路径转换成查询图.
4)SPARQA提出一种基于骨架的语义解析方法,构造一个多粒度打分器来预测查询.
5)QGG提出一种基于状态转移的查询图生成方法,构造一个基于BERT的语义匹配模型来预测查询.
6)KBQA-GST是一种基于主题单元的生成与打分框架,包括主题单元链接和候选答案排序.
7)UHop是一种不限制跳数的关系抽取框架.
8)SPLITQA是一种基于问句拆解和阅读理解相结合的方法.
基准方法结果来源说明:LCQ数据集上对比了4个基准方法,其中WDAqua,QAmp和NSQA结果来源于原始论文,SPARQA结果来源于本地复现.CWQ数据集上对比了5个基准方法,其中SPARQA,QGG,KBQA-GST和SPLITQA结果来源于原始论文,UHop结果来源于QGG论文.
4.4 实验设置
所有层的图顶点表示维度为128维,GCN采用DGL框架[38].GCN层数为3.学习率为1e-5,批量大小取值范围为{16,32,64}.训练轮数为10,模型在验证集上调参,并根据验证集上的准确率,设置早停为5轮.候选已定查询图对应答案的F1大于一个阈值(本文设为0.8),则为正样本,否则是负样本.本文随机采样20个负样本作为监督数据.本文模型采用优化Adam优化器,warmup比例为0.1,Dropout=0.1,采用整流线性单位函数作为激活函数.
编码模块.采用BERTBASE(L=12,H=768,A=12,totalparameters=110 M).编码序列最大长度设为64.顶点嵌入层:2层感知机通过批归一化和整流线性单位函数连接,维度依次设置:(768,384,128);跨图注意力的匹配层:l=128;工作图表示层线性层维度:(256,128);模型预测:2层感知机通过批归一化和整流线性单位函数连接,维度设为:(896,448,2).
4.5 实验结果
实验1.在LCQ数据集上验证TTQA方法性能.
在LCQ数据集上的实验结果如表4所示,TTQA超过所有基准方法,表明TTQA方法的有效性.值得一提是,TTQA超过最好基准方法NSQA达1.49个百分点(m-F1),而NSQA是基于预训练语言模型对语法路径和关系进行语义匹配.这说明了本文考虑图结构的有效性.TTQA超过SPARQA达6.14个百分点(m-F1).SPARQA采用多粒度打分器,这说明了TTQA中基于预训练模型的图匹配方法的有效性.
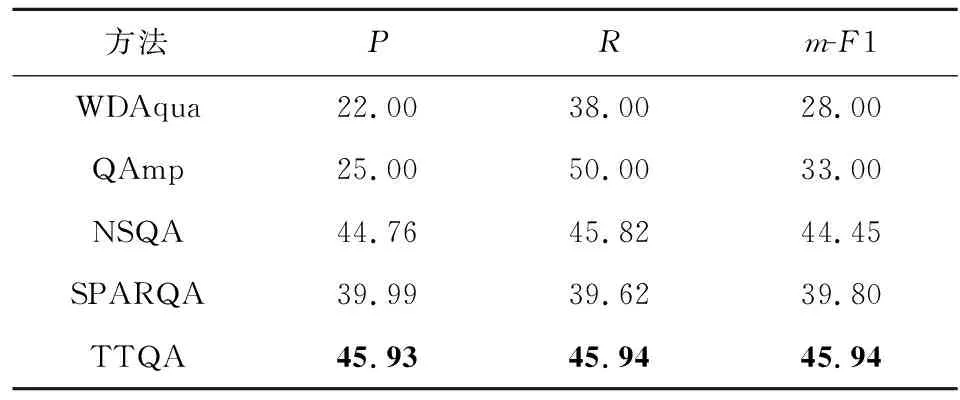
Table 4 Performance Comparison of Methods on LCQ
实验2.在CWQ数据集上验证TTQA方法性能.
在CWQ数据集上的实验结果如表5所示,TTQA超过所有基准方法,表明TTQA方法的有效性.值得一提是,TTQA超过最好基准方法QGG达3.9%(P@1),QGG采用预训练语言模型对问句和关系进行序列化编码,然后计算匹配度.而TTQA采用一种文本编码和图匹配编码的综合方法,这说明了TTQA中的图匹配编码的有效性.
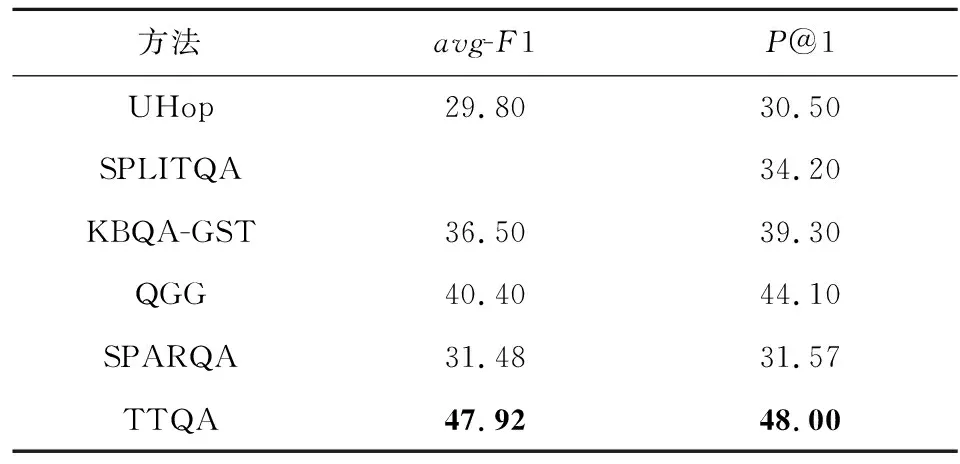
Table 5 Performance Comparison of Methods on CWQ
4.6 消融实验
实验3.在LCQ和CWQ数据集上进行消融实验,对比有无GMN的效果,从而验证其有效性.
消融实验结果如表6所示,在该2个数据集上,TTQA均优于未加GMN的TTQA,此结果表明GMN能够得到更丰富语义表示,从而增强了TTQA的效果.具体地讲,在LCQ数据集上,有1.38个百分点(avg-F1)的提升,验证了GMN在LCQ数据集上的有效性.同时,在CWQ数据集上有0.46个百分点(avg-F1)的提升,验证了GMN在CWQ上的有效性.
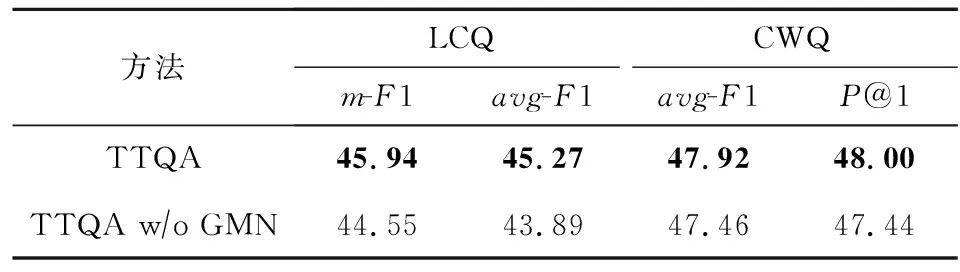
Table 6 Results of Ablation Study
此外,通过比较该2个数据集上消融实验可以发现,GMN在LCQ数据集上提升较为显著(1.38个百分点),而在CWQ数据集上仅提升0.46个百分点.可能原因为:1)CWQ是一个大规模的数据集(34 689),且训练集和测试集的已定查询图分布均匀具有较高重合度,该情况适合采用大规模预训练模型,所以仅用基于BERT的文本编码就可以获得具有竞争力的结果;2)CWQ有占比10%的聚合问句(比较和最高级),目前本文的未定查询图还不能处理该类问句的表达,改进未定查询图的表达能力是一个未来工作.
4.7 错误分析
本文随机采样400个错例(从LCQ和CWQ的错例中各随机采样200个),错误归类如表7所示.
主要分为5类错误,详细描述为:
1)实体识别和链接.识别长提及的实体是一个较大的问题,如表7所示,本文采用的基于BERT的模型误识别“Switzerland in 2004 and 2008 summer Olympics”为实体提及,而正确的应是“Switzerland in 2004”和“2008 summer Olympics”.
2)未定查询图生成.未定查询图生成是一个难题,尤其针对聚合类问句.如表7样例所示,“with the earliest publication start date”很难用未定查询图表达.
3)候选已定查询图生成.大规模知识图谱上生成候选已定查询图是一个较为困难的事情,尤其涉及多个实体或数值的问句.如表7所示,涉及“US President”“WW2”与“3-4-1933”做比较的数值顶.
4)语义匹配.有的问句未定查询图与已定查询图之间存在较大的语义鸿沟.如表7所示,边“about”蕴含着“dbp:format”关系.
5)其他.涉及问句中字符编码错误、类型变量约束、布尔型问句求解等,如表7所示.

Table 7 Failure Analysis of Our Approach
5 总 结
本文提出了一个基于图匹配网络GMN的可解释知识图谱复杂问答方法TTQA.GMN通过利用注意力机制和多视角匹配函数进行图匹配.相比序列编码和路径编码,GMN充分利用了图结构信息,从而得到更丰富的结构匹配表示,从而增强了问答系统的效果.在2个常用的复杂问答集上的实验,对比基准方法,TTQA达到了最佳结果,同时,消融实验还验证了GMN的有效性.并且TTQA生成的未定查询图和已定查询图提升了智能问答的可解释性.
从错误分析中看,未来可以从3点尝试:1)实体识别和链接:尽管它不是TTQA的重心,但它却是TTQA一个主要错误,未来可以尝试采用联合消歧手段进行实体识别和链接;2)聚合类问句求解(尤其多实体和聚合操作相结合的问句):如何在未定查询图上表达聚合操作是一个挑战的问题;3)语义匹配:图匹配模型还有提升空间,比如专门对图中参数顶点进行学习.
作者贡献声明:孙亚伟提出了方法详细思路、负责完成实验并撰写论文初稿,程龚提出了方法宏观思路、设计了实验方案并修改论文,厉肖参与完成实验并修改论文,瞿裕忠提出了指导意见并修改论文.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
中国典型病例大全(2022年7期)2022-04-22
计算机研究与发展(2022年1期)2022-01-19
新城乡(2018年6期)2018-07-09
文苑(2015年9期)2015-09-10
电影新作(2014年2期)2014-02-27
新课程学习·中(2013年3期)2013-06-14
中国计算机报(2009年27期)2009-04-27
