
一种基于神经网络识别人脸进行内容审核的技术
2021-12-13 06:32陈欣
电视技术 2021年10期
陈 欣
(广西润象信息网络工程有限公司,广西 南宁 530001)
1 需求分析
一些保健品、药品投放的电视广告中出现的“神医”“专家”往往误导大众,可能让人们付出金钱却得不到预期的治疗效果,甚至可能耽误患者的治疗时间,使患者错过最佳治疗时间而影响患者身体健康。这些“神医”演员往往扮演了多个角色。例如,由高振宗扮演名医代言的“蒙药名目二十五味丸”,被河北省药品监督管理局和广州市工商行政管理局查处过,原因是宣传不真实、误导消费者。这种问题受到观众朋友质疑,虚假医药广告竟然在省级电视台播放,影响恶劣。究其原因,是内容审核工作人员需要审核的内容太多,只能审核出明显的违规内容,而无法识别出内容是否为虚假广告。这些“演员式神医”在不同的电视台,更换不同的身份和名字,用不同的头衔售卖不同功能的保健品、药品。
针对这个问题,可以利用人工智能(Artificial Intelligence,AI)的机器学习算法[1],让AI去记录这些“神医”“专家”的人脸图像,由AI自动、逐帧地审核影像,将涉嫌违规内容影像鉴别出来,进行下一步处理。
2 神经网络图像识别
2.1 AI机器学习概述
2.1.1 机器学习
机器学习是一种概念,不必编写与具体问题相关联的程序代码,通过泛型算法即能给出数据结论。无需编码,只要在泛型算法[2]中输入数据,泛型算法就可以根据输入的数据构建出自己的逻辑。例如,有一种用来分类的泛型机器学习算法,可以将输入的数据划分到不同的组,可以识别手工书写的数字;在不修改代码的情况下,还可以用来分类垃圾邮件和非垃圾邮件。分类算法如图1所示。给同一个泛型机器学习算法输入不同的训练数据,算法就能构建出对应的分类逻辑。泛型机器学习算法类似于一个“黑盒子”,通过输入不同的数据来解决不同的分类问题。

图1 分类算法示意
2.1.2 机器学习算法分类
机器学习算法可以分为监督式学习[3]和非监督式学习[4]两大类。监督式学习可以依据训练数据创建函数,通过函数推测出新实例,由输入数据(一般是向量)和对应的预期输出来组成一组训练数据,函数输出值通常是一个预测的连续值(回归分析)或是预测的一个分类标签。非监督学习指的是在没有类别信息的情况下,通过对所研究对象的大量样本的数据分析,实现对样本分类的一种数据处理方法。因此,机器学习的“学习”可以理解为“在一定量的样本数据基础上找出一个函数来解决特定的问题”。
假设对于任意的分类、聚类、回归等问题,在自然界中总是存在一个精确的模型与之相对应,可以根据获取的样本来反推并确定这个模型。然而,由于无法遍历这个问题的所有情况,因此只能根据获取的样本去尽可能接近地确定这个模型。
可以将以上描述公式化为:问题对应的模型隐藏在假设空间[5](Hypothesis)hθ(x)中,需要通过观测样本,确定其中的值。在确定θ值的过程中,定义一个损失函数(Cost Function)J(θ),如果获取的样本在某一个参数θ时可以使损失值达到最小,即表示当前θ值确定的模型可以使预测值很接近观察值。那么这个模型就是目标模型。
对于监督学习,其目标就是确定目标函数[6]、损失函数[7],通过样本训练,得到损失值最小的一组参数值。用该参数值代入目标函数,即可得到对应问题的模型。以单一变量的线性回归模型[8]为例,目标函数为:

损失函数为:
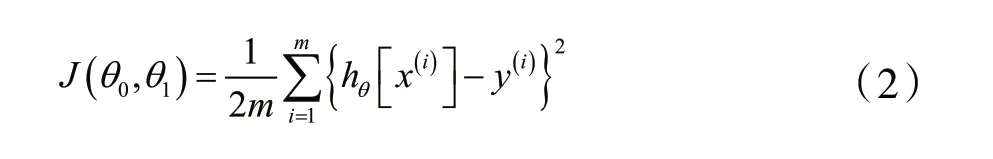
式中:hθ[x(i)]为第i个样本,y(i)为第i个样本对应的实际值。
接下来的目标就是找到一组参数值,使得损失函数值最小,即:

求损失函数最小值时,使用梯度下降(Gradient descent)的方法,分别求θ0和θ1的偏导数,然后用该导数值更新参数值。求损失函数J(θ0,θ1)对θ0和θ1的偏导数:

上述线性回归模型的输出结果为连续值,如果面对的是一个分类模型,比如判断对象是否为垃圾邮件或者其他分类问题时,不能直接使用线性回归模型,需要使用逻辑回归模型[9]。逻辑回归模型是在线性回归模型上的一个演变,通过一个逻辑函数可以将线性回归模型的输出结果转变为0或1的离散输出。
逻辑函数即Logistic Function,也称为Sigmoid Function,表示为:

Sigmoid Function可以将连续值转变为0或1的离散值。如果将上面的逻辑函数g(z)应用在线性回归模型的目标函数hθ(x)上,就可以得到逻辑回归模型。
目标函数为:

当y=1时,hθ(x)的值可以理解为是对当前样本x在参数θ的情况下被预测为1的概率,即:
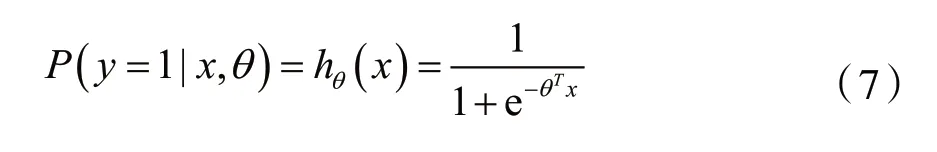
在上文的线性回归模型中,损失函数为:

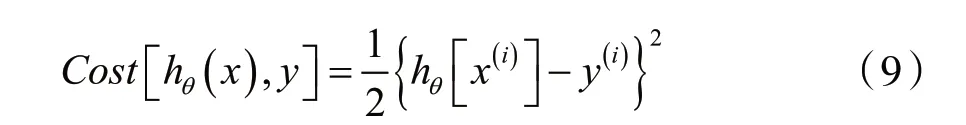
那么线性回归的损失函数可以写成:
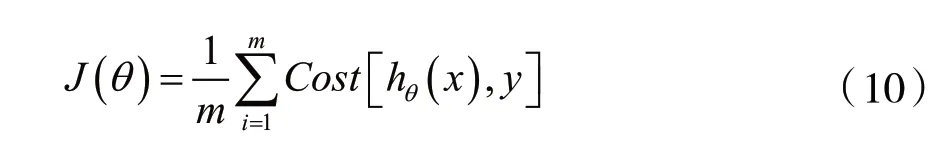
逻辑回归模型中使用的是对数损失,定义为:

当y=1并且hθ(x)=1时,Cost=0;当y=1并且hθ(x)→0时,Cost→∞。y=0时情况类似。
最后,将逻辑回归的对数损失函数进行融合:

将Cost[hθ(x),y]代入J(θ)可以得到逻辑回归完整的损失函数为:
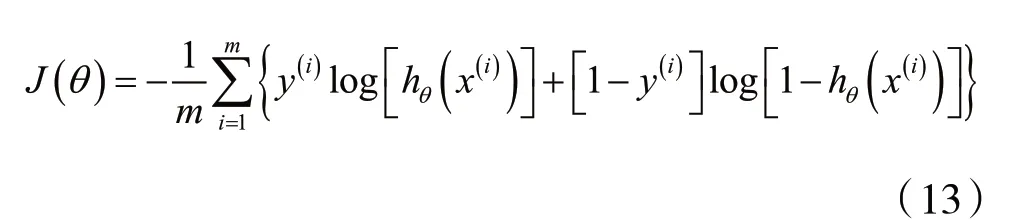
逻辑回归使用对数损失函数来求解参数,与采用极大似然估计求参数是一致的。以下为对数损失函数和极大似然估计的分析过程。
假设样本服从伯努利分布(0-1分布),则有:
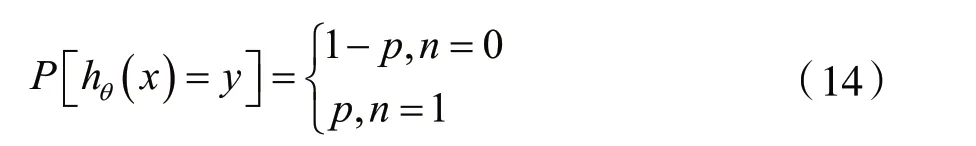
似然函数为:

对数似然函数为:
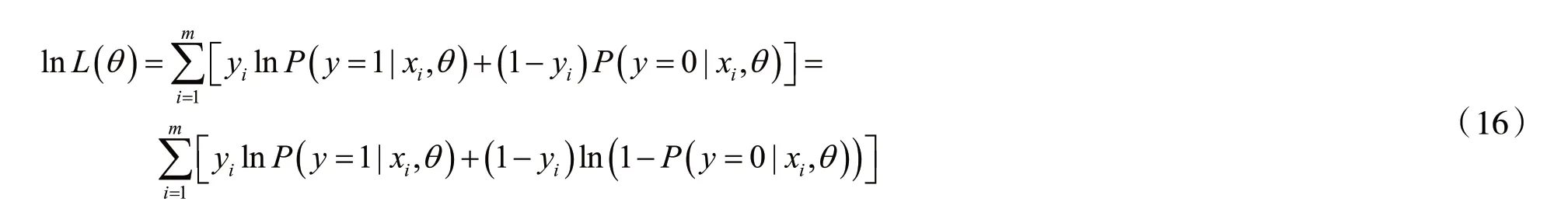
根据对数损失函数的定义:

那么对于全体样本,损失函数为:
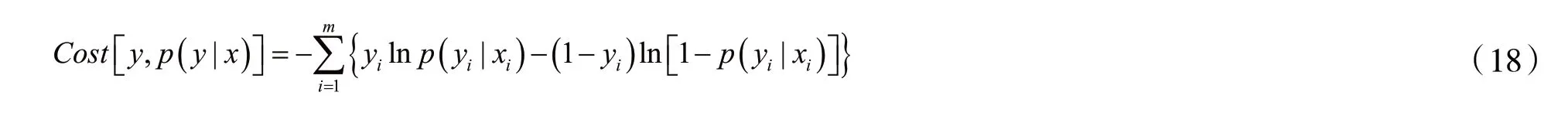
可以看到,对数损失函数与极大似然函数本质上是等价的,因此,逻辑回归直接采用对数损失函数与采用极大似然估计是一致的。
2.2 神经网络简述
以一个房地产的估价为例,先建立一个简单函数,把决定房屋价格的因素(假定是卧室数量、面积、地段)乘以它的权重(来自经验值),再把每个因素与权重的乘积结果求和,算出房子的预估价格。函数如图2所示。
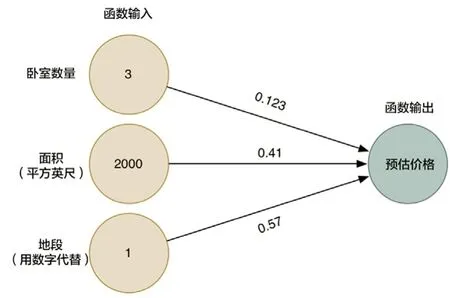
图2 房价估算函数示意
这个算法仅能用于处理一些简单的问题,如那些输入和输出存在线性关系的问题。如果真实价格和决定因素的关系并不是如此简单,例如,地段对于大户型和小户型的房屋有很大影响,而对中等户型的房屋并没有太大影响,因此为了更加智能化,可以利用不同的权重来多次运行这个算法,收集各种不同情况下的估价。如图3所示,用4种不同的算法(输入相同,权重不同)来解决该问题.

图3 4组权重不同的房价估算函数示意
利用这4种估价方法得到结果,汇总到一个最终估价函数当中,如图4所示。
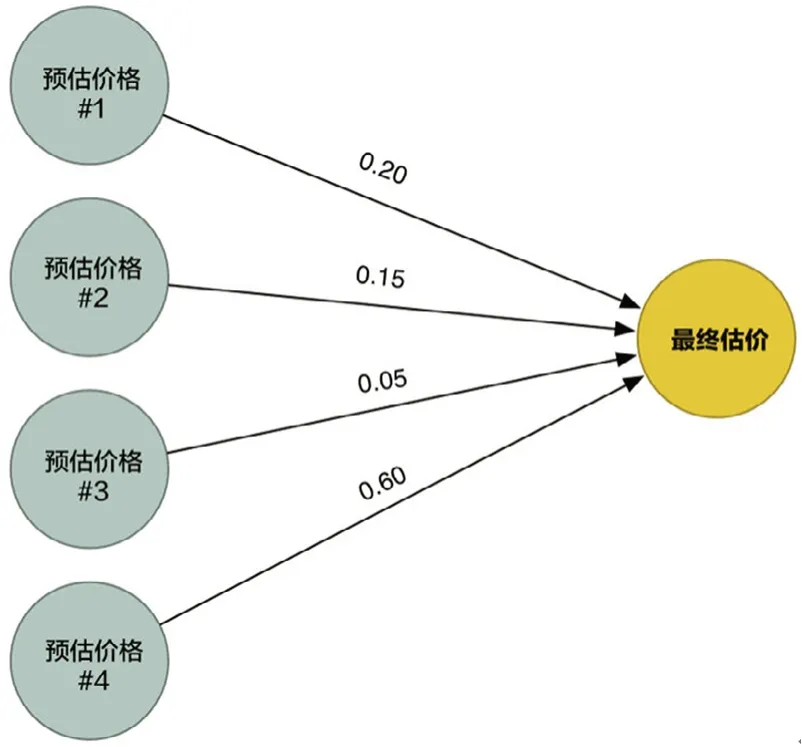
图4 最终估算函数示意
再把这4种不同的预测函数整合到一个图中,即每个节点都知道收集怎样的一组数据,并找到对应的权重,做出对应的输出值(即价格预测),把这些节点连接到一起,形成一张神经网络,如图5 所示。
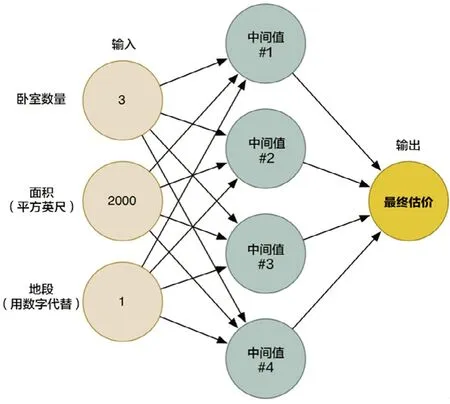
图5 房屋估价神经网络示意
把这个权重×因素的简单函数叫做神经元。通过连接许许多多的简单神经元,能够模拟那些不能被一个神经元所模拟的函数。
2.3 使用神经网络识别一个数字图像
机器学习可以重复使用同一个泛型算法来处理不同的数据、解决不同的问题。以识别数字“8”为例,演示用神经网络来识别手写文字。
机器学习只有在有大量训练数据的情况下才能有效,因此需要用大量的手写“8”的图片来进行训练,可以利用其他人已建立好的手写数字数据库MNIST。MNIST数据库里有超过6万张手写数字图片,每张图片的分辨率为18×18,如图6所示。
图6 MNIST数据库中的数字“8”
上文描述的房屋估价神经网络,原来只接受三个参数(卧室数量、面积、地段)的输入,但是现在需要使用神经网络来处理图像,因此要先将图片转换成数字,输入神经网络。对于计算机来说,图片就是一连串代表每个像素颜色的数字,把一张大小为18×18像素的图片转化为一串有324个数字组成的数组,如图7所示,就可以通过该数组把图片当作神经网络的输入了。

图7 图片“8”按像素颜色转换为数组
为了输入要训练的数据图片数据,需要扩大神经网络的输入节点到324个,如图8所示。
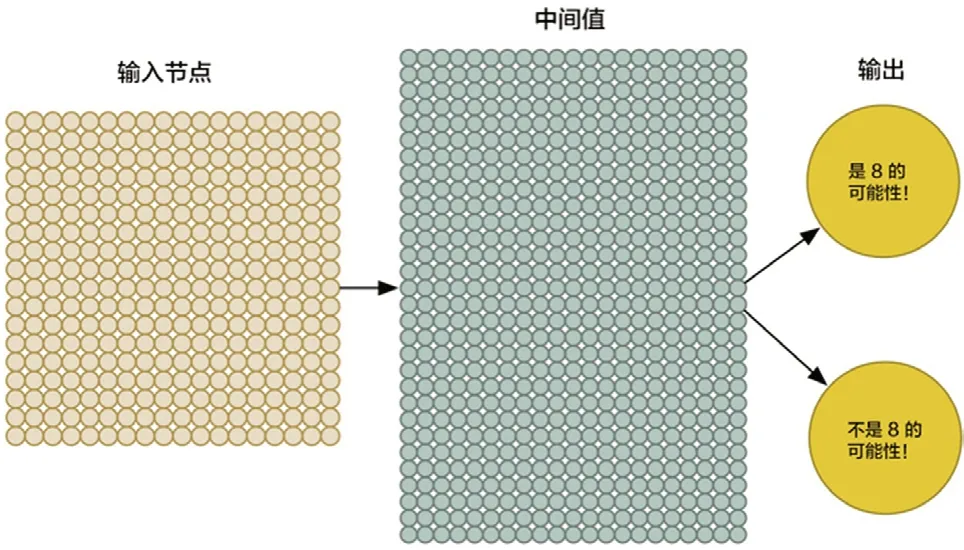
图8 识别数字“8”神经网络示意
修改神经网络的输出为两个。第一个输出结果是预测输入图片是“8”的概率,第二个输出结果是预测输入图片不是“8”的概率。这样就可以通过分组不同的输出结果,利用神经网络把要识别的物品(图片)进行分类。通过输入大量的“8”和非“8”的图片来训练这个神经网络,如果输入神经网络的是一个“8”的图片,需要告诉神经网络该图片是“8”的概率为100%,而不是“8”的概率为0%,反之亦然。部分训练数据如图9所示。

图9 识别数字“8”神经网络的训练数据
在普通计算机中训练这种神经网络的时间成本很低。训练完成后,就可以获得一个能比较准确地识别字迹图片“8”的神经网络。
3 人脸识别技术方案
3.1 找出所有的面孔
首先采用方向梯度直方图[10](简称HOG)的方法找到图片中的面孔。具体做法是:首先将图片转换为黑白图,将黑白图分割成大小16×16像素的小方块;逐行查看小方块中的每一个像素,针对每个像素,查看围绕它的其他像素,找出并比较当前像素与直接围绕它的像素的深度,通过画一个箭头来代表图片变暗的方向,逐个像素重复这个过程;在每个小方块中,计算出各方向箭头的个数,用方向箭头个数最多的那个方向箭头来表示原来的那个小方块,最终原始图像转换成了一个比较简单的表达形式(即HOG形式),如图10所示;在这个HOG图像中找到脸部;从HOG图像中找到与已知的一些标准HOG图案里最相似的部分,通过机器学习,将这些部分截取下来。

图10 HOG图像
3.2 处理脸部的不同姿势
扭曲第一步找到的每个脸部图片,使得眼睛和嘴唇总是在图片中的标准位置。可以使用一种名为面部特征点估计的算法,该算法的主要思路是通过找到人脸上普遍存在的68个特定点(特征点),包括每条眉毛的内部轮廓、每只眼睛的外部轮廓、下巴的顶部等,如图11所示,然后训练一个机器学习算法,让这个算法能够在所有面部图片中找到这68个特征点。

图11 将脸部特征转换为68个特定点
接下来旋转、缩放、错切面部图片,使得图片中的眼睛和嘴巴尽可能地靠近中心。为了不让图像失真,不能进行三维扭曲,只能使用那些能够保持图片相对平行的操作进行基本图像变换,如旋转和缩放(称为仿射变换),如图12所示。
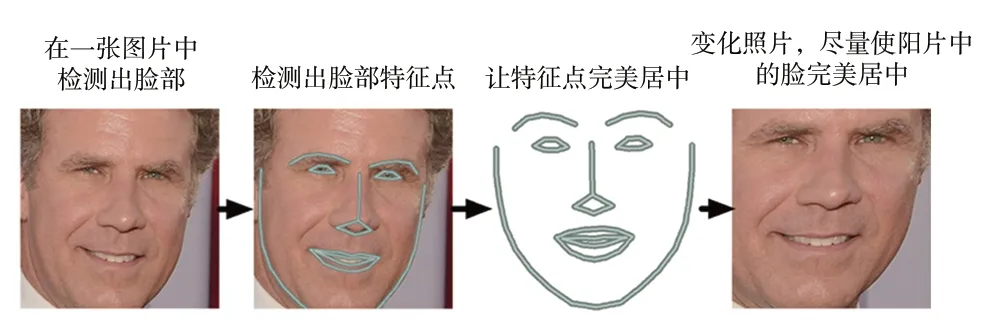
图12 图像调整示意图
3.3 给脸部编码
为AI训练一个神经网络,让它为上一步处理过的脸部图片生成128个测量值。每次训练都导入满足以下要求的3个脸部图像:
(1)加载一张已知的人的面部训练图像;
(2)加载同一个人的另一张照片;
(3)加载另外一个人的照片。
AI算法查看其为这3个不同脸部图片生成的测量值,根据测量值稍微调整神经网络,以确保同一个人的脸部图像(即第一张和第二张)生成的测量值大致相同,而不同的人的脸部图像(即第二张和第三张)生成的测量值略有不同。通过为上千人的数百万张人脸图片重复该步骤数百万次之后,神经网络就可以可靠地为每个人的脸部图片生成128个测量值,如图13所示,输入同一个人的任何不同照片,它都能给出大致相同的测量值。

图13 根据图像生成128个测量值示意图
通过训练神经网络来输出脸部测量值的过程,需要大量的面部图片和计算机强大的计算能力,需要大约24 h的连续训练才能获得良好的准确性,训练的时间越久准确性越高。神经网络训练完成后,即使从未见过这些面孔,神经网络也可以为这张面孔生成正确的测量值。
3.4 建立需要识别的脸部编码
将“神医”“专家”等的人脸图像输入神经网络,获得各面孔对应的测量值,将这些测量值录入审核数据库,并给每个面孔命名。
3.5 识别一段视频的所有面孔
将视频转化为单帧的图像(可以抽样稀释),输入神经网络获得编码,然后对比审核数据库里是否存在这个编码,如果有,将面孔用名字标识出来。
4 人脸识别测试
按照以下步骤进行人脸识别测试。
(1)确保开发环境已经安装了dlib、OpenFace以及python。
(2)在Openface所在文件目录中建立一个名为./training-images/的文件夹。命令为:
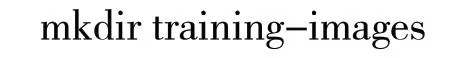
(3)在建好的文件夹下按人名为想识别的每个人建立一个子文件夹。命令为:

(4)将每个人的所有图像复制进对应名字的子文件夹,需要确保每张图像上只有一个面部,不用人工剪裁面部周围的区域,OpenFace可以完成 处理。
(5)运行align-dlib.py脚本,首先进行姿势校准和检测:
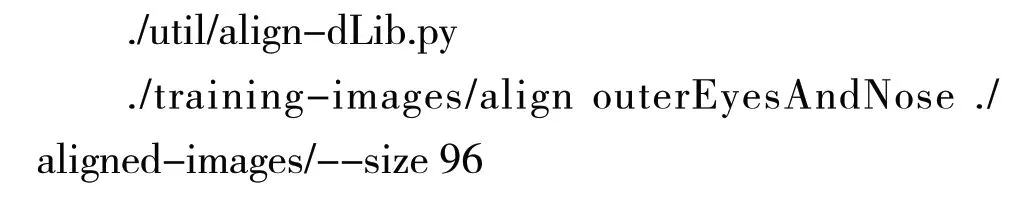
这个步骤会创建一个名为./aligned-images/的子文件夹,文件夹里保存的是每一个图像剪裁过、并且对齐的版本。接着运行main.lua,从每个剪裁过、并且对齐的图像中生成特征文件:

运行main.lua完后,会在./generated-embeddings/ 文件夹生成一个带有每张图像嵌入的 csv文件。
(6)运行classifier.py脚本训练面部检测模型。
classifier.py脚本运行完毕后会生一个成名为./generated-embeddings/classifier.pkl的新文件。该文件包含了用来识别新面孔的SVM模型。到这个步骤为止,成功创建了一个人脸识别器。
(7)识别面孔。使用任意一张未知面孔的新照片,执行classifier.py脚本:

可以得到以下预测结果:
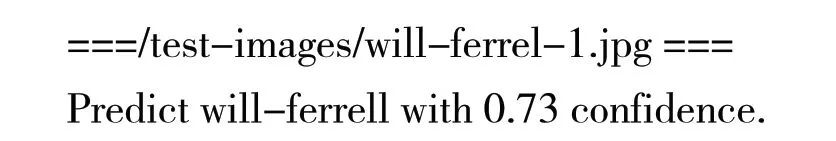
至此,完成了一个预测。后续可以通过修改classifier.py这个python脚本,让它匹配其他人的脸。假如得到的结果不够理想,说明训练数据不够,可以尝试在第4步为每个人添加更多不同姿势的 照片。
5 效益分析
5.1 经济效益
这种识别方法可以大大地提升内容审核的工作效率,预计每个地方电视台可以减少3~5名内容审核人员。按每个人员15万年薪计算,可以为每个地方电视台每年节约45~75万元的人员 经费。
5.2 社会效益
移动互联网时代,信息传播异常发达,如果电视传播的内容监督不到位,就会给广电行业相关部门造成不良影响,破坏广电形象,形成对广电行业不利的舆论。相关部门可以利用这种AI监督技术,不错过每个角落和细节,自动揪出广告乱象,打造健康的广告环境、影视环境。
6 结语
AI监督技术的应用可以减少审核员的工作量,提高工作效率,具有一定的经济效益和社会效益,可以在广电行业大力推广。
猜你喜欢
养生月刊(2022年8期)2022-11-25
小哥白尼(军事科学)(2022年2期)2022-05-25
数学小灵通·3-4年级(2021年5期)2021-07-16
红领巾·萌芽(2019年8期)2019-08-27
今日农业(2019年15期)2019-01-03
中国与非洲(法文版)(2017年10期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
世界科学(2014年4期)2014-02-28
