
基于Bert-A-BiR神经网络的文本情感分类模型
2021-12-13 06:32:00李明超张寿明
电视技术 2021年10期
李明超,张寿明
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引言
文本情感分析是自然语言处理领域(Natural Language Processing,NLP)一个重要的研究方向,是利用计算机手段对带有情感倾向的文本进行处理、分析、归纳及推断的过程。
在基于深度学习的文本情感分析研究方向上,KALCHBRENNER等人[1]提出了第一个基于卷积神经网络(Convolutional Neural Networks,CNN)的TC模型,该模型使用动态-max-pooling,称为动态CNN(DCNN);此后又出现了循环神经网络[2](Rerrent Neural Network,RNN)及其各种变体,如长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环网络(Gated Recurrent neural network,GRU)[3],都是旨在更好地捕获长期依赖关系。随着训练模型复杂度不断提升和模型处理语料日益庞大,研究人员提出了预训练模型(Bidirectional Encoder Representations from Transformers,BERT)[4]。 通过大量基准语料对模型预训练,使模型能够对给定语句中的词语嵌入更丰富语义,这些嵌入将被应用到相关模型后续任务中,极大地改善模型情感分 析性能。
但是,在以上的单一神经网络模型中依然存在各种问题:卷积神经网络无法提取文本时序特征,而LSTM和GRU虽能提取到时序特征,但只能利用到当前和过去信息,不能利用未来信息;另外,BERT模型的输入长度是固定的,被截取的超出部分可能包含有价值信息,因此还有提升空间。
针对上述问题,本文提出Bert-BiR-A模型架构,利用训练集对BERT模型进行微调,然后利用预训练BERT模型对文本序列进行词嵌入,使词语获得更丰富表征;利用双向GRU对文本进行双向特征提取,并引入注意力机制对提取特征赋予不同权重,给予关键信息更高关注度,更有利于情感分析,提取语句深层语义;为验证不同BERT模型对整个模型框架的影响,设计了6组模型进行试验获得最优模型。
1 Bert-BiR-A模型构建
Bert-BiR-A模型结构包括BERT预训练层、双向循环网络层、注意力层以及输出层4个信息处理层,如图1所示。

图1 Bert-BiR-A模型结构图
1.1 训练BERT词向量
输入词向量序列记为X={w1,w2,…,wm},将X输入BERT模型中进行训练,最终获得相应词向量表示,如式(1)所示:

式中:X'为BERT词嵌入后的向量,W'为转置矩阵,b'为偏置值。
1.2 BIGRU层特征提取
对于任意一条给定的评论S={t1,t2,…,ti,ti+1,…,tm},经过BERT网络模型训练后转化为序列X'。BIGRU网络使用了双向GRU模型,其中一路GRU向前传播建模,一路向后传播建模,使得每个词对应的输出能够同时提取到基于上下文两个方向的信息,获得信息更充分。在进行建模的过程中,前向GRU与后向GRU参数不进行共享,两者的表 达式为:

最后将每个词向量对应的前向GRU输出值和后向GRU输出值进行拼接,结果即为BIGRU网络的模型的输出,如式(4)所示:

1.3 注意力目标词向量
将从BiGRU层的输出连接到Attention层,然后加入注意力机制算出其注意力值。从BiGRU层输出的句子为S={t1,t2,…,ti,ti+1,…,tm},计算目标词向量t2注意力,通过Attention层将t2训练出其基于注意力机制的序列t2'。然后可以按照对t2的计算方式推出整个文本序列的词向量训练。通过分析词与词之间的相关性及词与序列之间的重要程度,利用注意力机制算出其权重值,构建出上下文向量,最后将构建出的向量连接到对应词上。训练词向量的具体步骤如式(5)、式(6)所示:
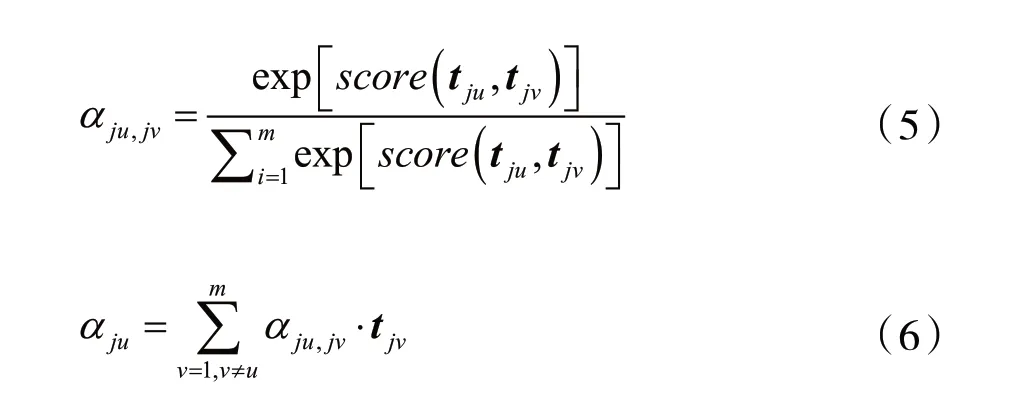
式中:tju和tjv代表第j条语句中任意两个不同的词的向量,αju,jv代表权重系数。
对输入词矩阵进行多次遍历以上计算步骤后,计算出每个词所对应的权重,最终生成权重矩阵A,最后将权重矩阵与后续BIGRU网络的输出进行 拼接。
1.4 输出层
将经过注意力机制的得到的输出Ai连接到输出层,然后送入softmax分类器中进行感情极性分类,最终的分类结果如式(7)所示:

式中:W0为输出层权重矩阵,bo为偏置值。
利用交叉熵定义损失函数如式(8)所示:

2 实验与分析
2.1 实验设置
为了能够对本章所提出的模型BERT-A-BIR进行更好的评估,本章选用了两个在文本情感分析领域广泛应用的公开数据集IMDB和SST-5。其中,IMDB数据集主要用于二分类,情感极性分为积极和消极,训练集包括25000条评论,测试集包含 25000条评论;SST-5数据集主要应用于情感分析五分类,情感极性分为非常消极、消极、中立、积极以及非常积极,训练集包含157918条评论,测试集包含2210条评论。
2.2 评估指标
用被分对的样本数除以总的样本数得出正确率(Accuarcy)。在通常情况下,正确率越高,代表分类效果越好,其计算方法如式(9)所示:

式中:FP是指实际积极的样本被判别为消极的样本;TP是指实际积极的样本被判定积极样本;TN是指实际消极的样本被判别为消极的样本;FN是指实际消极样本被判别为消极的样本。
2.3 对比实验
模型分别在数据集IMDB和数据集SST-5上进行情感分析任务,同时设置多组对照实验。
2.3.1 分类模型对比实验
不同模型的预测准确率结果如表1所示。由表1可以看出,在IMDB数据集上,单一神经网络中CNN的准确率最高,为87.6%,但是本文提出的BERT-A-BiR模型均优于其他模型,且相对CNN提升了7.1个百分点;在SST-5数据集上进行单句预测,CNN相对BiLSTM准确率降低1.1个百分点,但本文提出的模型与BiLSTM相比提升了1.8个百分点;BERT-A-BiR与BERT-BiR相比在两个数据集上准确率都更高,说明了引入注意力机制的有效性。整体而言,本文的模型在了IMDB和SST-5数据集上都取得了不俗的表现。

表1 不同模型的预测准确率
2.3.2 不同BERT对比实验
为了提升整体模型性能,研究不同BERT对本章提出的BERT-A-BiR模型架构的影响,在模型的BERT模块分别采用BERT_base、RoBERTa[5]及DistillBERT[6]三种BERT,同时双向循环网络模块(BiR)采用了BiGRU和BiLSTM两种循环网络的变体模型,共设计了6个模型,相关实验组的结果如表2所示。
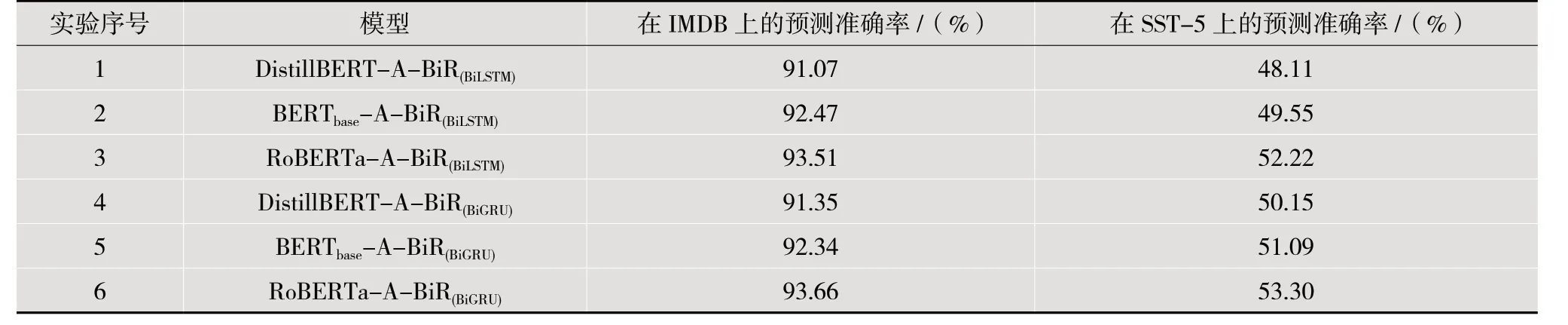
表2 6组不同模型在IMDB和SST-5数据集上的实验结果
对比1、2、3组实验可以发现,当BiR模块同为BiLSTM时,RoBERTa在两个数据集上表现最优;同理,对比4、5、6实验组可以发现,当BiR模块同为BiGRU时,RoBERTa在两个数据集上表现最优,故在BERT模块上RoBERTa最优。通过对比1和4、2和5、3和6可以发现,当BERT相同时,整体上而言,BiGRU更优,最终最优模型为RoBERTa-A-BiR_(BiGRU),在SST-5上取得了53.30%的准确率,在IMDB上取得93.66%的成绩。
2.3.3 微调实验
为了提升BERT模型的效果,利用训练集Dtrain对BERTbase进行微调。为了验证微调的效果,首先利用Dtest对没有经过微调的BERTbase进行测试,BERTbase经过微调后再次使用Dtest对其测试,实验结果如图2所示:

图2 BERTbase在IMDB数据集上的微调效果
在对IMDB影评数据集上进行情感二分类的过程中,对BERTbase进行微调后的准确率、召回率和F1值比没有微调前分别高出0.54、0.39和0.46。结合BERT预训练后在两个数据上的准确率、召回率及F1值可以看出,对BERT进行微调后的效果都要优于未对BERT进行微调的效果。这说明对BERT进行微调应用于特定任务,要优于不进行微调的BERT模型,证明了BERT微调的有效性。
3 结语
本文针对文本情感分析任务提出了BERT-ABiR模型架构,通过对BERT微调后利用其预训练模型进行词嵌入,然后通过双向RNN变体LSTM或GRU进行特征提取,此后引入注意力机制让模型对与当前任务相关的信息赋予更多关注度,提升模型情感分析能力。在不同数据集上的实验结果表明,与其他对照组相比,提出的模型准确率最高,证明了该模型的可行性。同时,为进一步提升模型架构性能,基于不同BERT对模型框架的影响设计了6组模型,通过实验选出最优模型。最终在IMDB数据集上取得了93.66%的成绩,在SST-5数据集上取得了53.3%的成绩。模型还有一定的优化空间,将在未来工作中进一步优化。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
电线电缆(2018年2期)2018-05-19 02:03:44
数学物理学报(2017年5期)2017-11-23 07:51:31
家庭影院技术(2017年10期)2017-11-23 03:35:51
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
教育科学论坛(2014年8期)2014-03-01 04:01:54
新课程学习·中(2013年3期)2013-06-14 05:55:20
