
随机森林算法在气象与空气质量分析中的应用★
2021-12-13 07:23:20邵凯旋吴映涵
山西建筑 2021年24期
邵凯旋,吴映涵,梅 钢
(中国地质大学(北京),北京 100083)
1 概述
近年来,随着经济的高速发展和人民生活质量的不断上升,社会对空气质量的关注度日益增高。空气质量是健康和生活的重要影响因素之一。局部环境空气质量除了受局地大气污染物排放的直接影响,也受局地气象要素及气候变化的影响。有研究表明,在污染源排放相对稳定的条件下,气象条件对空气质量起主导作用。研究气象要素与大气污染物的关系,并将气候变化与其结合起来,预测未来各气象要素变化对各大气污染物的潜在影响,对我国节能减排政策的制定具有一定的指导意义。对同一地区而言,由于天气状况等自然条件的不断改变极其他因素的影响,在同一地点对同一来源的污染物的监测结果也可能出现很大差异。北京作为我国首都,在国家发展中扮演着极其重要的角色,其空气质量问题也常常受到全国人民的普遍关注。
机器学习是一种数据分析的方法,作为人工智能的一个分支,它可以自动化构建分析模型。它的理念是,系统仅需要最小的人工干预就可以从数据中学习,识别模式并且做出决策。机器学习的种类有很多,随机森林便是一种非常简便且易于使用的算法。作为一种监督学习算法,随机森林具有很强的抗干扰能力,可用于许多不同的领域。它能够处理具有很多特征的高维度数据,并在大多数情况下避免了过拟合问题,近年来越来越多地应用于人们日常生活的各个方面。随机森林可以用多种编程语言实现。Julia作为一种新兴的编程语言,拥有着简洁的语法,优良的运行速度,强大的元编程能力,可以轻松使用Python,R,C/C++和Java多种语言中的库,极大地扩展了Julia语言的使用范围。除此之外,它还可以调用其他许多成熟的高性能基础代码。与其他编程语言相比,Julia非常易用,可以大幅减少需要写的代码行数,并有着更丰富的工具包和库等,它不仅解决了许多传统编程语言问题,还为机器学习和人工智能提供了强大的深度学习工具。
在世界范围内的许多国家环境问题越来越受到政府和公民的重视,国内外的许多学者都对空气质量的预测问题进行了多方面的分析与研究。周兆媛等[1]使用主成分分析的方法将多个气象要素简化为两个主成分并进行线性回归分析,根据回归系数得到了气象要素与空气质量的相关关系;祁晓雨等[2]使用数据分析和挖掘的方法对北京六种大气污染物浓度和五种气象因子的数据集进行分析,通过拟合发现相较于单一气象因子,多种气象因子组合对大气污染物浓度的影响更加显著,并分析了相同的气象因子对不同污染物的不同影响;任才溶等[3]在构建基于气象参数的随机森林预测模型时使用K-Means算法对训练样本进行聚类,对不同的聚类使用不同的分类模型,将每个模型的结果汇总得到最终的PM2.5等级预测结果;Efnan等[4]通过从空气质量数据中提取统计特征并将其输入线性和非线性分类器,提出了一种适用于大范围地理区域的空气质量预测模型;Paulo等[5]提出了一种基于随机游走的时间序列预测体系,在不依托于其他外部信息的条件下,仅用过去的污染物浓度变化预测未来的污染物浓度;此外,神经网络也是用于空气质量预测的常见方法之一,鲍慧[6]等使用遗传算法对BP神经网络进行优化,通过研究往年空气污染物浓度的变化规律,建立基于时间序列的网络模型,得到了较好的预测结果,但神经网络结构的设置缺乏一定的理论依据,且搜索过程具有一定的随机性,无法确保最优解的得出。
在上述研究和分析中,国内外学者采用神经网络、数据挖掘、随机森林等多种方法对空气质量预测问题进行了研究,但也存在着统计分析方法较单一、因子选择具有一定的主观性和随机性、多重因素综合作用的影响考虑不足等问题。本文采用准确度高、针对性强、综合多因素的随机森林算法对空气质量预测问题进行了研究。在对空气质量和气象条件之间的关系进行研究的基础上,本文选择合适的特征作为依据,使用Julia语言建立随机森林预测模型,借助易于得到的实时气象条件数据,通过算法得到空气质量相关数据,在应用程序进行预测的同时,本文对预测准确度与节点特征和决策树数目的关系进行了研究,在对两个参数进行调整后得到了较好的预测结果,对得到更加客观准确的空气质量及空气质量的预测有较为重要的意义。
2 材料与方法
2.1 数据来源
本文所采用的数据为2017年1月至2018年1月北京市朝阳区奥体中心空气质量监测站的实时空气质量监测数据及其对应的气象条件数据。其中,空气质量数据包括该监测站点测得的PM2.5,PM10,NO2,CO,O3,SO2每小时内的浓度值;气象条件数据包括该地区每小时内的气温、气压、湿度、风向、风速及天气状况。在本文中,为便于研究空气质量与天气状况之间的联系,以如下关系表示不同的天气状况:1=“Sunny/clear”;2=“Rain”;3=“Fog”;4=“Haze”;5=“Snow”;6=“Dust”;7=“Sand”。
北京市朝阳区空气质量监测站和气象站位置见图1。

2.2 空气质量评价等级
在日常生活中,人们通常习惯于根据大气污染物的浓度对空气质量的优劣进行评价,并将其划分为优、良、轻度污染、中度污染、重度污染、严重污染等多个等级。根据我国发布的空气质量指数的评级规定[7],本文根据表1所示的空气质量指数及对应各项污染物浓度的参考值,将空气质量数据的具体数值划分为6个等级,并以字母A~字母F表示,用以代表各项污染物的严重程度,从而通过分类提高使用随机森林对空气质量进行预测的实用性和可操作性。
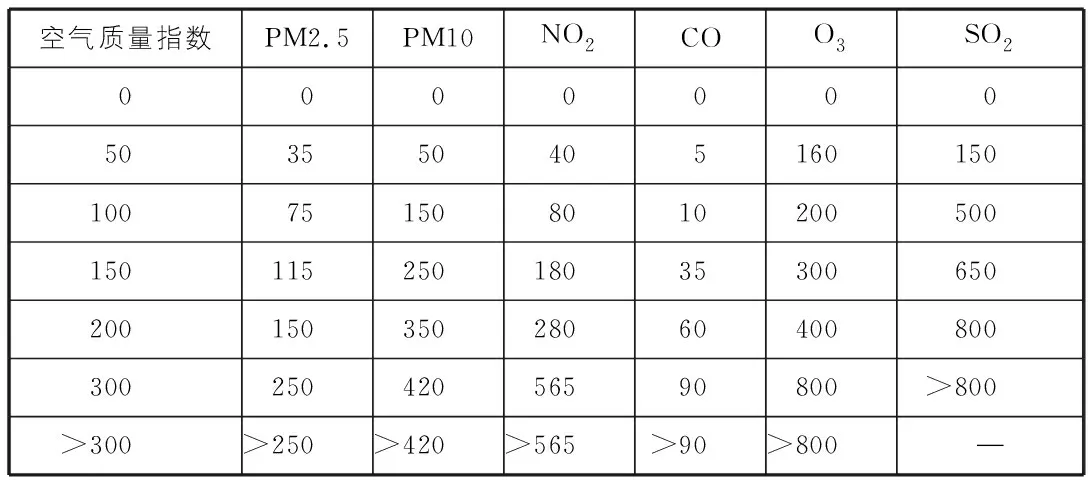
表1 空气质量指数及各项污染物质量浓度参照表 μg/m3
2.3 分析方法
本文采用基于Julia语言的随机森林算法对空气质量预测问题进行研究。在对数据进行简单处理的基础上,本文通过空气质量与时间因子和气象条件的相关性的分析对特征因子的选择进行了探究,并将选择出的适当的特征因子作为参数输入到随机森林模型中进行空气质量预测的应用研究。在随机森林中,每一个决策树的“种植”和“生长”都大致包含以下几个步骤:
1)假设原始训练集中的样本个数为N,然后通过有放回地重复多次抽样获得这N个样本,这样的抽样结果将作为我们生成决策树的训练集。
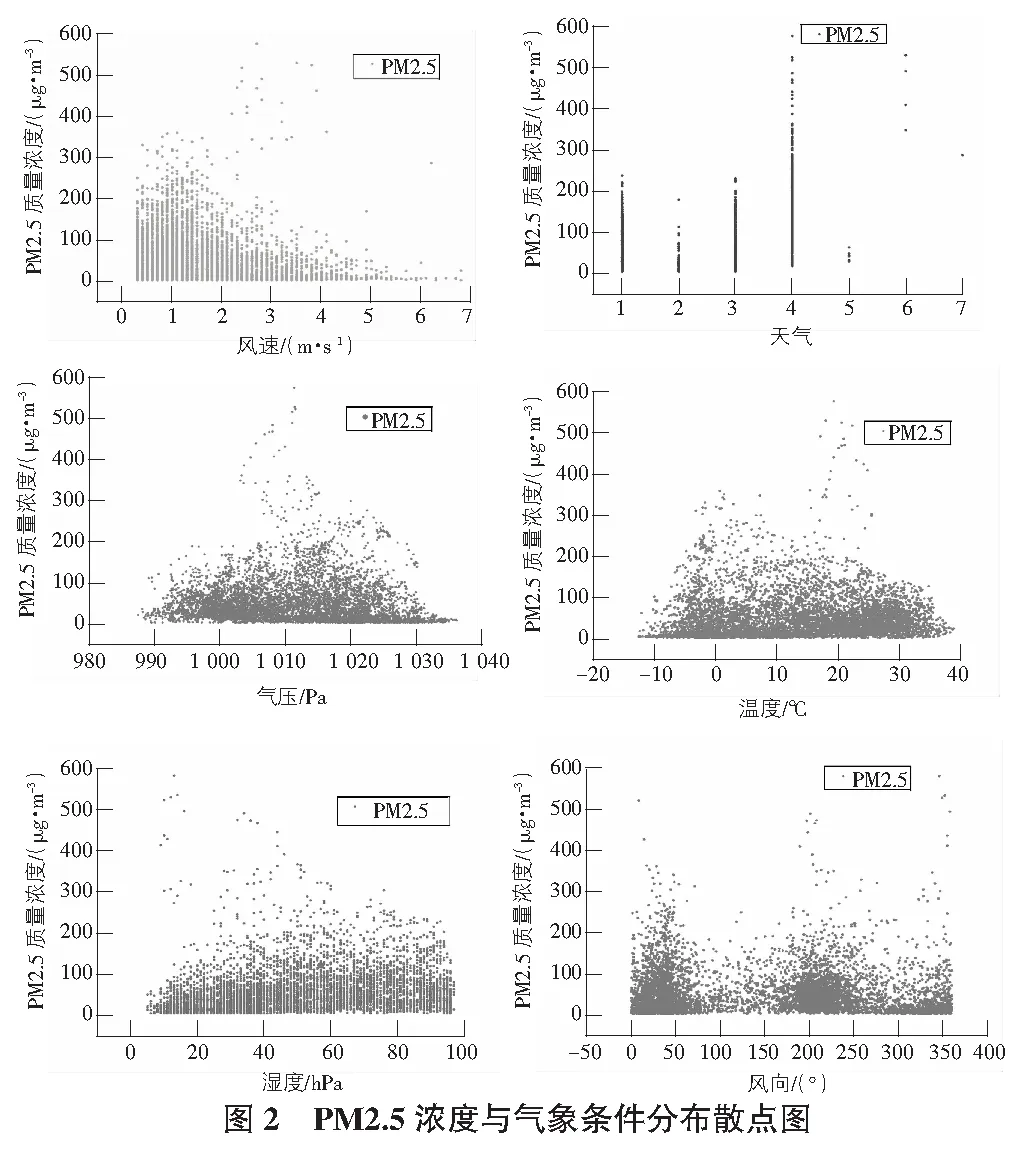
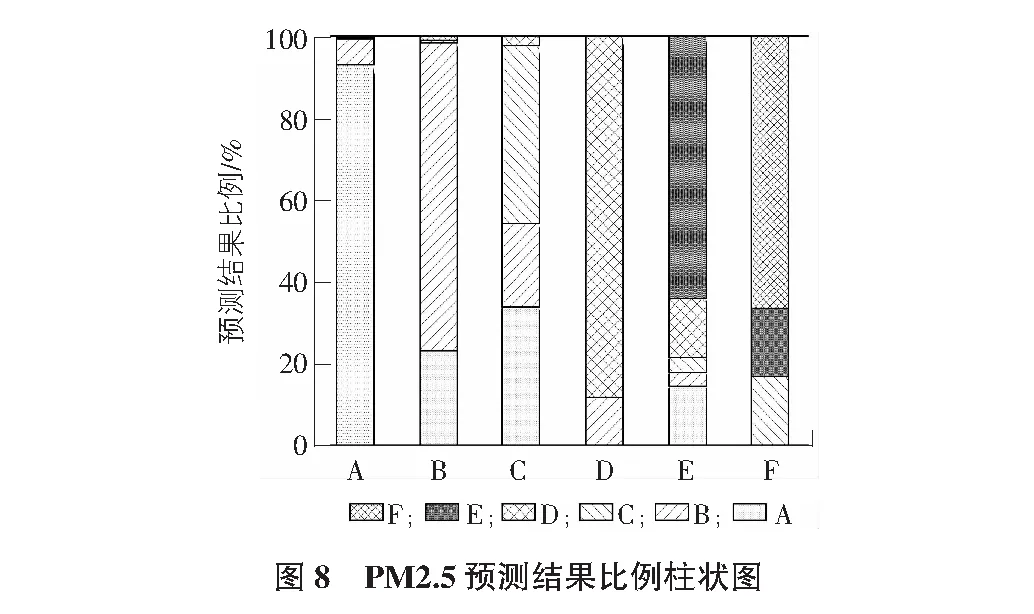
2)设有M个输入变量,在每一棵树每个节点都将随机抽取m(m 3)每棵决策树都最大限度地生长且不进行任何修剪。 4)将生成的多棵分类树组成随机森林来预测新的数据(在分类时采用多数投票,在回归时采用平均)。 在应用程序进行预测的同时,本文对预测准确度与节点特征和决策树数目的关系进行了研究,并对其预测结果进行了分析讨论。 在本节中,本文首先对大气污染物与各气象条件和时间因子的相关性进行了分析,之后采用选择出的特征值对随机森林预测模型进行了训练,最后应用经训练的模型进行预测并对预测结果准确度进行了分析。 3.1.1 气象因子的相关性分析 在人们通常的认识中,阴雨天气往往比晴朗天气更容易出现空气污染较为严重的情况。显然,空气质量与气象条件之间确实存在着一定的联系,某些气象条件可能会在污染物的流通扩散等过程中发挥着复杂而显著的作用[8]。然而,衡量某地区气象条件的内容通常是复杂多样的。使用随机森林方法进行预测的主要工作原理是在构建和应用随机森林预测模型之前,如果不对空气质量和气象条件之间内在联系进行分析并得出基本的认识,直接进行计算可能会带有一定的主观性和偶然性。因此,本文对大气污染物与各气象条件进行了相关性分析,从而帮助评价和修改预测模型。 以PM2.5与气温、风速等各气象条件之间的相关性分析为例,表2给出了使用SPSS求得的PM2.5与各气象条件之间相关系数的具体数值,图2为根据PM2.5与各气象条件数据绘制的散点图。通过图表并结合Pearman相关系数的计算可以看出,除天气状况以外,PM2.5与各气象条件之间并无明显的线性相关关系。 表2 PM2.5与各气象因子相关系数表 结合Spearman相关系数进行分析,可见气象因子与湿度和天气状况之间存在相对明显的正相关关系,而与风速之间存在相对明显的负相关关系。据此可以推断较大的风速在一定程度上有利于PM2.5的扩散,从而使其观测值降低;而湿度较大时,空气中含量较高的水蒸气可能有利于PM2.5的凝结,且水蒸气的存在可能造成PM2.5的观测值偏大的误差。同时,天气状况在很多方面与PM2.5的扩散和沉积等过程有着密切联系[9-10]。虽然相关系数显示风向与PM2.5浓度相关性很低,但结合散点图可以明显看出PM2.5浓度较高值均大致集中在三个方向,可推断该结果是在对应方向的上风向上存在排放量较大的企业或更密集的交通网等因素的影响下造成的。 此外,相关系数计算显示出PM2.5与温度之间存在着一定的正相关关系。而在其他研究中,北方地区在冬季往往处于采暖季,且由于气温较低往往容易出现逆温层,对PM2.5的扩散产生不利影响。这与其研究结果和日常生活中温度回暖,空气质量状况与供暖季相比有所改观的认识存在着一定的差异。通过对PM2.5变化的具体时间段进行分析可以看出,其年度峰值出现在五一小长假期间,在假期末尾PM2.5升高尤为明显,可推断由于假期出行及返程等因素的影响下,出现了温度较高时PM2.5浓度也存在明显升高的现象。此外,本文数据主要来源于奥体中心空气质量监测站,反映空气质量变化的地区范围有限,也在一定程度上影响了此处结果的出现。 通过对PM2.5与其他大气污染物之间的相关性进行分析(见表3),可以看出PM2.5在很大程度上与其他大气污染物存在着一定的相关性,PM2.5与各气象条件的相关性分析对其他大气污染物的分析而言同样具有一定的参考价值,进而帮助选择合适的因子用于预测并对模型进行评价和改进(见图3)。 表3 PM2.5与其他大气污染物相关系数表 3.1.2 时间因子的相关性分析 在应用气象条件对空气质量进行预测的过程中,考虑到气象条件在时间上往往存在一定的周期变化规律,本文同样对大气污染物与时间或季节的相关性进行了研究。以PM2.5为例,其一年内的观测数据与不同季节一天中的观测数据随时间的变化曲线如图4~图6所示。 由图4~图6可以看出,PM2.5浓度与时间具有较为明显的相关性,其按季节划分的变化规律较为明显。其中,PM2.5在1 d内各时刻平均浓度的季节性差异较大,在该站点的观测数据中,春季平均浓度最高,夏季平均浓度最低。而在1 d中的某些时刻,不同季节PM2.5浓度变化值的大小具有较明显的同步改变现象。例如,在15:00~16:00这一时间段内,秋、冬、春三个季节的PM2.5浓度均存在明显升高,夏季PM2.5浓度存在明显降低。PM2.5浓度值不仅与季节和月份有关,在同一天的不同时段同样存在着一定变化规律。 通过以上分析可以看出,大气污染物浓度与时间之间同样具有较为明显的相关性。为了得到更加准确的预测结果,本文在应用气象因子预测空气质量的过程中同样将时间因子作为预测的参考特征之一纳入了考虑范围,从而进一步提高预测结果的可靠性。 3.2.1 数据准备 在对数据进行分析之前的数据收集阶段,尽管数据集已经被进行初步处理,但在分析的过程中依然存在很多问题。例如,在进行相关性分析时得到的图2中可以明显看到,在庞大繁杂的数据中,大气污染物浓度较高的数据只占很小的一部分。目前现有的学习算法一般建立在各类数据数量相差不大的前提下。而在本文的数据集中,空气质量较好的数据和较差的数据所占比例很不平衡,这便导致了在随机森林学习和训练的过程中,在空气质量较好的方面能够搜集到的数据和规律要比空气质量较差的大的多,这便导致了在应用随机森林进行预测的过程中,得到的结果更容易偏向于空气质量较好的等级。数据集中不同等级的空气质量数据分布不均匀使预测结果产生了一定的误差。目前解决这类问题的主要方法有欠采样方法(undersampling)、过采样方法(Oversampling)及组合方法(Combination)等。本文采用过采样方法,通过复制或内插的方式,将人工合成的样本整合到原始样本中,从而提高空气质量较差数据的样本容量,改善数据类别不平衡带来的影响。 3.2.2 模型构建 根据空气质量与气象因子和时间因子的相关性分析,本文不放回地随机选择经过欠采样后的2017年1月~2018年1月北京市朝阳区奥体中心空气质量监测站的实时空气质量监测数据及其对应的气象条件的部分数据作为测试集,并将其余数据作为训练集,选择气温、气压、湿度、风向、风速、时间及天气状况作为特征值,并将其对应的空气质量等级输入模型进行训练,按照“特征数量(number of features)=2、决策树的数量(number of trees)=15、分段抽样比例(ratio of subsampling)=0.5”的初始参数构建随机森林。 3.2.3 模型应用 将测试集中的气象条件数据输入经过训练的随机森林预测模型之后,各项空气污染物指标预测的准确率如表4所示。 表4 大气污染物预测结果准确率表 在对随机森林进行训练的过程中,每次节点随机分割时选择的特征属性是从原始的输入因子中选取的,而随机森林最终的预测结果是根据多棵决策树的综合预测结果得到的,因此,对随机森林模型的预测性能影响最大的两个参数分别是节点分割时选择的特征属性和决策树的数量[11]。为进一步优化模型,以得到更好的预测效果,本文使用控制变量的方法,对两个参数变化时的模型预测准确度的变化进行了探索[12-13]。以PM2.5为例,图7给出了当节点分割时选择的特征属性数目分别为2~5时随机森林模型预测结果准确度随决策树数量不同而变化的曲线。 分析图7中的曲线可以看出,当决策树的数量在30以上时,随机森林的预测精度的变化趋于稳定。通过研究节点特征和决策树数目对随机森林预测精度的影响,可以帮助选择合适的参数对模型进行改进。 经过模型构建和应用时对其预测性能与节点属性数目和决策树数量两个参数之间关系的研究,同时考虑到预测准确度和运算速度两方面对程序的影响,本文最终采用特征数量为2,决策树数量为30作为随机森林预测模型构建时的参数。其各等级的预测结果情况及准确率见图8。 本文基于随机森林算法研究了北京市气象条件与空气质量变化关系的相关性。通过以上研究发现:1)空气质量与温湿状况、风速风向及天气情况等气象因子之间存在一定的相关关系;2)北京市空气质量存在明显的季节性变化,受浮尘天气等因素的影响,春季空气污染物浓度最高;3)各空气污染物之间存在较明显的相关性;4)在一定范围内,随机森林预测精度与决策树数量成正相关。同时,对预测结果进行分析,PM2.5等级为优(A)的数据预测准确度最好,但其预测结果中包含的其他等级的种类也最多;PM2.5等级为轻度污染(C)的数据预测结果准确度相对较差,由此可见在该组数据中,PM2.5等级为轻度污染时其气象条件的特征性相对较差,在程序的不断优化中应对预测存在偏差的C类数据与气象条件的关系进行进一步探索,通过增加C类典型样本加强随机森林的训练或根据多次测试得出的误差概率对C类结果进行补偿等方式减小误差。该模型不仅可用于PM2.5的预测,在对其他大气污染物的预测中同样具有良好的表现,对得到更加客观准确的空气质量及空气质量的预测有较为重要的意义。采用该方法具有较强的针对性,但为保证较好的预测结果,对训练集的特征性要求较高,在对其他地区的空气质量进行预测时应重新选择数据集对该模型进行训练,对较大地理区域范围内空气质量的预测结果的准确性和普适性有待进一步研究。3 随机森林预测模型的建立
3.1 特征值选取及相关性分析






3.2 模型的建立及应用


4 结论
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
中国航海(2019年2期)2019-07-24 08:26:52
电子制作(2018年16期)2018-09-26 03:27:06
环境保护与循环经济(2017年3期)2017-03-03 20:08:30
汽车与安全(2016年5期)2016-12-01 05:22:14
汽车与安全(2016年5期)2016-12-01 05:22:13
中国环境监察(2016年11期)2016-10-24 05:25:12
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
西安工程大学学报(2016年2期)2016-06-05 12:25:17
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
