
结合集成学习的序贯三支情感分类方法研究
2021-12-12 02:51王琴,刘盾
计算机工程与应用 2021年23期
王 琴,刘 盾
西南交通大学 经济管理学院,成都 610031
近年来随着在线评论的爆炸性增长,情感分析[1-2]受到了学术界和业界越来越多的关注。文本情感分析(也称为观点挖掘)可以从文本中发掘人们的观点和情感[1]。情感分类是情感分析领域的一项重要任务,具有许多应用价值。Pang和Lee对Twitter和Facebook等社交媒体平台上文本内容进行观点挖掘和情感分析,并进一步对消费者行为进行了预测和评估[2]。Hu和Liu对电子商务中的评论进行文本分类,以帮助消费者做出更明智的购物决策[3]。另外,对用户生成内容(UGC)的情绪进行分类也被广泛应用到个性化推荐之中[4]。由此可见,情感分类已成为自然语言处理和文本挖掘的重要研究方向之一。
情感分类研究作为情感分析的重要组成部分,其研究方法主要可以分为两类:基于词典的方法和基于语料库的方法。基于词典的方法通常使用情感词字典,并结合副词和否定词强化或否定来计算每个文本的情感。现有的基于语料库的方法主要有两类:机器学习方法和深度学习方法[5]。机器学习方法是通过对文本进行向量化表示,然后结合分类算法来完成情感分类。深度学习方法专注于使用神经语言模型和自然语言处理技术,对学习到的词向量进行合成来指导分类[6]。现有大多情感分析研究主要致力于提高模型分类精度,较少考虑错误分类所产生的误分类成本。此外在实际应用中,将不同类别错误分类所产生的误分类成本可能是不一样的。
三支决策[7]是在二支决策的基础上发展而来的一种理论,因其符合人类的决策思维而受到广泛关注。其主要思想是“三分而治”,将只有接受、拒绝的二支决策变成接受、延迟决策、拒绝三种决策,对掌握信息不充分的对象延迟决策,等待更多信息到来后再做决策。周喆等将三支决策的决策规则应用于情感词典分类中[8];王磊等提出了一种将主题特征与三支决策理论相融合的多标记情感分类方法[9];Zhang等在多个文本粒度中研究了上下文有关主题依赖和情绪分类的相关问题[10]。序贯三支决策是一种典型的动态三支决策方法,通过构建多层次的粒结构得到一系列的序列决策结果,从而更好地平衡决策结果代价与决策过程代价[11]。张刚强等[12]利用N-gram语言模型构建多粒度的序贯三支情感分类模型,并获得了较好的效果。
为了提升序贯三支情感分类模型的整体效果并且降低分类成本,本文在已有序贯三支分类模型上引入集成三支思想,构建结合集成学习的序贯三支情感分类模型。集成三支则是将多个分类器的三支划分结果进行最大投票,最终确定分类对象的域,即将每一个分类算法当作一个决策者,分别独立作出将实例对象划为正域、边界域和负域的决策,再进行最大投票法对决策行为进行集成以得到最终决策结果。
基于上述分析,本文在序贯三支的基础上融合集成学习和三支决策,主要研究结合集成学习的序贯三支情感分类模型。首先,通过N-gram语言模型构建文本多粒度结构;其次,针对每一粒度,集成三个分类算法以提高在该粒度下的分类效果;最后,利用不同数据集来验证模型的有效性。实验结果表明:结合集成学习的多粒度序贯三支情感分类模型不仅能够提高分类性能,而且可以降低分类成本。
1 相关理论
1.1 集成学习
集成学习技术主要通过构建并结合多个学习器来完成学习任务,用以提高分类准确性[13]。由于集成方法的泛化能力通常比单个学习者更强大,这使得集成方法被广泛应用。但在实际问题中,良好的集成学习器需满足两个条件:准确性和多样性[14]。按照个体分类器之间的种类关系可以把集成学习方法分为异态集成学习和同态集成学习[15]。异态集成学习指的是使用各种不同的分类器进行集成,异态集成学习的两个主要代表是叠加(Stack Generalization)和元学习(Meta Learning)。同态集成学习是指集成的基本分类器都是同一种分类器,只是它们之间的参数设置有所不同。此外,从基分类器获得方式来看,主要有Boosting和Bagging两种方法;从异质分类器整合的方式来看,主要有投票表决法和Stacking方法[13]。
1.2 序贯三支决策
三支决策是由粗糙集延伸而来的处理不确定性方法[16]。在传统的二支决策模型中,只有接受或拒绝、是或非两种选项。然而,在很多实际问题中,当信息不充分或证据不足时,强制作出接受或拒绝选择,可能会付出不必要的代价或造成严重后果。相对于二支决策,三支决策引入延迟决策策略,对论域中部分对象暂时不作决策,以等待更多、更有力的信息或证据去判断。可以看到,三支决策引入了不承诺选项,能够规避和降低错误接受或错误拒绝造成的损失。
序贯三支决策是粒度由粗到细的一种动态三支决策过程[17]。从粗粒度层到细粒度层,在每一粒层,当现有信息充分时,可以直接作出接受或拒绝的判断;而对当前信息不能支持其作出决策时,可以将对象划分到边界域中,并在更细粒层下获取更充分的信息后对其进行划分,依此类推,直到边界域中的对象被逐渐地划分到正域或负域中。
1.3 粒计算
粒计算是当前人工智能研究领域中模拟人类决策思维和解决复杂问题的方法论[18]。通常,粒度结构是由多个级别组成的层次结构,每一个粒层由一组具有相似信息粒度的粒子组成。显然,多层粒度结构自然会导致多层划分和多步决策过程。基于三支决策和粒度计算的结合,序贯三支决策逐渐用于解决实际问题,例如增量学习[19]、特征选取[20]和人脸识别[21]。序贯三支决策方法正是应用了粒计算中逐步计算的思想,实现了由粗粒层到细粒层之间的序贯决策。粒计算中结构化问题求解的思想是一种典型的信息处理方法,对于复杂问题的求解是非常有效的。
2 结合集成方法的序贯三支情感分类模型
2.1 三支情感分类
表1给出了三支决策下的情感分类准则。Pr(P|x)表示待分类文本x属于正类的条件概率。通过Pr(P|x)与阈值α和β比较,可以将待分类文本划分到相应的决策区域。P、B、N表示三种不同决策区域对应的决策规则。显然,待分类文本的分类结果取决于概率Pr(P|x)和阈值α和β的大小。

表1 三支情感分类准则Table 1 Criteria of three-way sentiment classification
此外,为了衡量分类代价,需要将待分类文本的真实类别与预测类别进行比较。三支情感分类代价矩阵如表2所示。其中,λPP、λBP和λNP分别表示待分类文本x真实情感类别属于正类时采取决策规则P、B和N产生的成本;λPN、λBN和λNN分别表示待分类x真实情感类别属于负类采取决策规则P、B、N产生的成本。其中,λPP、λNN表示正确分类成本。λNP、λPN表示误分类成本,λBP、λBN表示延迟决策成本。

表2 三支情感分类代价矩阵Table 2 Cost matrix of three-way sentiment classification
此外,在分类过程中,误分类成本往往比延迟决策产生的成本高,延迟决策成本也比正确分类的成本高,因此有:λPP<λBP≤λNP,λNN<λBN≤λPN。根据表2的情感分类代价矩阵和决策规则,分类总成本可以根据式(1)计算:

其中,cost(P|x)、cost(B|x)和cost(N|x)分别代表待分类文本x划分到正类、延迟决策类和负类时产生的代价。根据贝叶斯决策准则,选择期望损失最小的行动集作为最佳行动方案,可以得到如下三条决策规则:
(P):如果Pr(P|x)≥α,则将x划分到正类;
(B):如果β<Pr(P|x)<α,则将x划分到延迟决策类;
(N):如果Pr(P|x)≤β,则将x划分到负类。

2.2 序贯三支情感分类
序贯三支决策是一种动态的三支决策方法。基于粒计算理论的多层次结构,本文采用自上而下的策略,从最粗的粒度到最细的粒度进行三支决策。粗粒度表示较少的信息,细粒度表示更详细的信息,序贯三支的思想就是在每一粒度中,将落入边界域的对象放入下一个粒度进行再决策,直到边界域中的对象被逐渐地划分到正域或负域中。然而,随着粒度的细化,获取信息和作出决策的成本也会随之增加,因此可以在合适的粒度获得最终的情感分类结果。
在序贯三支情感分类问题中,首先定义多粒度结构:G={g1,g2,…,gi,…,gh}(1≤i≤h),其中gi表示第i个粒层。在每一粒层中,根据条件概率Pr(P|x)与阈值对(αi,βi)的大小关系可以将待分类文本划分到正类、负类和延迟决策类,其数学表达式为:
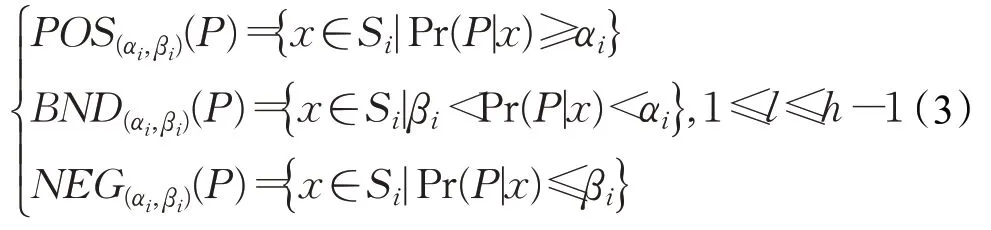

这里,γh通常设为0.5。由式(3)可知,在每一粒层gi的分类结果受Pr(P|x)和阈值对(αi,βi)的影响。根据式(2)可以计算每一粒层的阈值αi和βi:

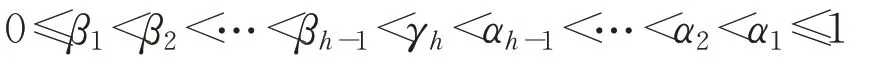
2.3 多粒度文本表示
本文参照文献[12]的模型,将N-gram语言模型的一元模型和二元模型作为文本的多粒度表示方法。N-Gram是一种基于统计语言模型。该模型假设第N个词的出现只与前面N-1个词相关,而与其他词都不相关,其计算表达式为:

在式(6)中,出现整句概率P(wi|w1,w2,…,wi-1)为各个词出现概率的乘积,这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常见的有一元(unigram)、二元(bigram)、三元(trigram)模型。
与英文分词方法不同的是,在中文文本分类、情感分类等应用中,通常把语料进行分词之后的词语作为文本特征。本文将文本内容按照词进行大小为N的滑动窗口操作,形成长度为N的词或词组。将一元、二元和一元加二元作为多粒度的文本表示。假设一条文本内容为“其他都很一般,叫出租不是太方便”,类别为负,分词之后得到“很不错出租不方便”。该文本的unigram表示为“很不错出租不方便”,其中“方便”隐含了积极语义,而“不”可能隐含消极语义,因此整体来说语义表达不够清晰;bigram表示为“很一般一般出租出租不不方便”,其中“不方便”就准确表达了消极语义。trigram表示为“很一般出租一般出租不出租不方便”,短语“很一般出租一般出租不”在语料中其他文本中出现的概率几乎为0,而“出租不方便”虽然有很强的语义信息,但出现的概率很小,会造成文本特征非常稀疏。因此,本文不考虑将三元词作为特征,将一元词作为第1粒度的候选特征;二元词作为第2粒度的候选特征,一元词加二元词作为第3粒度的候选特征。文本多粒度情感信息表示示例如表3。

表3 文本多粒度情感信息表示示例Table 3 Example of text multi-granularity sentimental information representation
2.4 结合集成方法的序贯三支情感分类模型
为了进一步提高分类效果和减少分类成本,本文在序贯三支情感分类基础上融入集成学习的方法,将多个分类器当作独立的决策者,将它们的三支决策结果进行投票集成,构建结合集成学习方法的序贯三支情感分类模型(Ensemble Learning for Sequential Three-Way Sentiment Classification,ESTWSC)。图1为模型的研究框架,其基本思路为:在每一粒度进行三支决策时,引入多个分类器先分开独立进行三支决策,将文本对象预划分为正类、负类和延迟决策类,对多个分类器的决策结果进行少数服从多数投票规则以确定最终的类别。
3 实验结果与分析
在本章中,本文以文献[12]中基于N-gram语言模的多粒度序贯三支情感分类模型(NSTWSC)为基准对比算法。NSTWSC采用多个LR作为分类器,本文所提出的ESTWSC方法采用SVM、LR和NB作为集成分类器。为了验证本文所提方法的有效性,在4个数据集上进行分类质量和分类成本比较。
3.1 实验数据
本文所使用的实验数据均来自网上公开的用于情感二分类的评论数据集,包含计算机、酒店、外卖和书籍多个领域的评论(数据来源https://github.com/SophonPlus/ChineseNlpCorpus)。首先对数据进行删非中文表达和分词等预处理,经过数据清洗和预处理得到表4所示的实验数据集。评论情感类别标签为1和0,分别表示正类评论和和负类评论。
3.2 实验设置
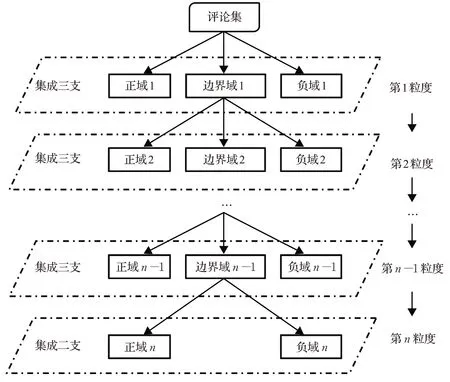
图1 结合集成学习方法的序贯三支情感分类模型Fig.1 Sequential three-way sentiment classification model combined with ensemble learning
根据第2.2节的阈值设置方法,并考虑信息获取成本随粒度细化而随之增加。为简便起见,这里设置第i粒层比第i-1粒层的成本依次增加2个单位。考虑到真实评论情感分类过程中,消费者对负评论的感知更加敏感,假设:将正类评论划分为负类评论的成本小于将负类评论划分为正类评论的成本,且两类误分类成本均大于延迟分类成本。通常,与错误或延迟分类相比,正确决策成本可以被忽略,即λPP=λNN=0。基于上述分析,表5给出了不同粒度下的代价损失矩阵。
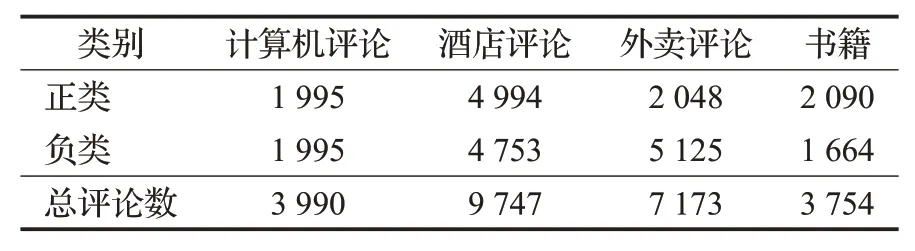
表4 数据集基本信息Table 4 Basic information of datasets
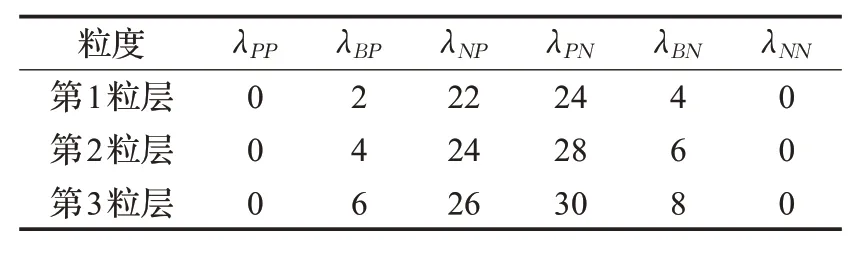
表5 不同粒度下的代价损失矩阵Table 5 Cost matrix with different granularity
3.3 评价指标
为了验证本文所提算法有效性,下面分别从分类质量和分类成本两个方面进行实验分析。
3.3.1 分类质量指标
对于情感正负二分类问题,根据预测情感类别和真实情感类别构建相应混淆矩阵。其中,TP、FP、TN、FN分别表示真正例、假正例、真反例和假反例对应的样本数。利用查准率Precision,召回率Recall、F1值以及准确率Acc作为分类质量的评价指标,其定义如下:

3.3.2 总分类成本
为了更好地评价本文所提方法的优劣性,本文还从总分类成本和平均分析成本两方面进行比较分析。总分类成本为错误分类所产生的误分类成本和延迟决策的成本,它是每一决策阶段的分类成本总和:
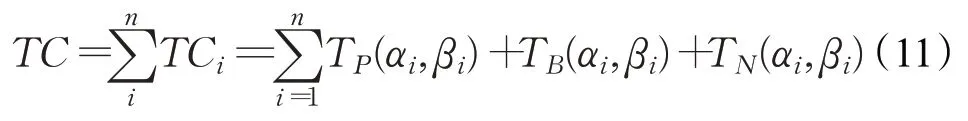
其中,i表示第i粒层,TP(αi,βi)、TB(αi,βi)、TN(αi,βi)分别表示在第i粒层阈值对为(αi,βi)时,将文本对象划入正类、延迟决策类和负类的成本。给定第i粒层的代价损失矩阵,TCi的计算公式如下:
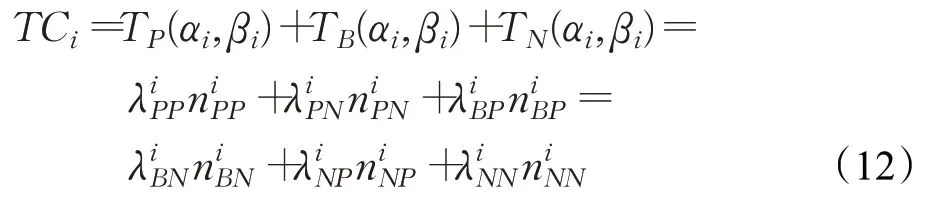
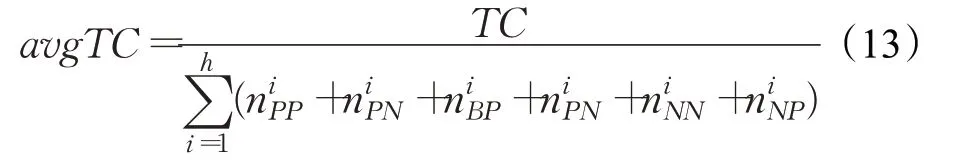
3.4 实验结果及分析
为了进一步验证文中所提出算法的有效性,本文以N-gram作为基准算法,首先在第1粒度下验证结合集成方法后分类性能的提升效果;然后分别在4个数据集上对比整个模型的查准率、召回率、F1值以及准确率。
3.4.1 验证结合集成学习方法的效果
本文首先以酒店数据集为例,在第1粒层上验证结合集成方法的分类性能。表6和图2为第1粒度下结合集成方法的对比结果,其中SVM、LR和NB是三个独立的分类器,ETW为三者的集成分类器。

表6 在第1粒度下结合集成方法的对比结果Table 6 Comparison results of ensemble learning in first granularity

图2 在第1粒度下结合集成方法的准确率对比Fig.2 Accuracy comparison results of ensemble learning in first granularity
从表6中可以得出:正类精度在SVM算法上最高,但其算法的未分类文本数也是最多的;负类精度在LR算法上最高,但其未分类文本较多。NB算法在三个分类指标上都比较差,然而其未分类文本数却最低。经过ETW方法在正类精度和负类精度均为次高;正类召回率最高且负类召回率为次高。此外,ETW方法在F1值表现最好,且未分类文本数较少。结合图2的准确率对比结果发现,集成三支方法的准确率最高。基于上述分析,经过集成学习综合了三个独立分类器的优势,这能够更好地平衡分类性能和未分类个数。

表7 不同数据集上的分类效果比较Table 7 Comparisons of classification results on different datasets
3.4.2 分类质量对比分析
下面,分别从分类的查准率、召回率以及F1值三个指标对分类质量进行实验分析。具体实验结果如表7所示。其中,LR-GS、SVM-GS、NB-GS分别为LR、SVM和NB在粒度GS下的静态二支分类算法,将其作为基准算法,并利用两种序贯三支模型NSTWSC和ESTWSC与它们作实验比较分析。
通过表7可以看到,相对于三个二支分类算法,两个三支分类算法在查准率、召回率和F1值上均有较好表现。对于二支分类算法,NB-GS在酒店数据、计算机和书籍数据集上表现最优;而在外卖数据上,三种二支模型表现相当。对于三支分类算法,ESTWSC在计算机和书籍数据上3个指标较NSTWSC均有明显的提升。在酒店和外卖数据集上,ESTWSC在大多数指标上表现比NSTWSC优异。另外,考虑到高的分类质量可能是由于对待分类文本拒绝分类而造成的。表8进一步考查了两个三支分类算法在未分类文本比率情况,相对于NSTWSC,ESTWSC在计算机、酒店、外卖和书籍4个数据集的未分类文本比率分别降低了4.39、1.75、2.16和0.78个百分点。综合分析表7和表8的实验结果,可以得到:ESTWSC优于NSTWSC和三种二支分类算法,ESTWSC比NSTWSC对更多的样本进行正确分类,且分类性能优于NSTWSC。

表8 未分类文本数比例Table 8 Ratio of unclassified text
3.4.3 总分类成本、平均分类成本比较
最后,通过式(11)和(13)计算NSTWSC算法与ESTWSC算法在各个数据集上的总分类成本和平均分类成本。一般而言,在追求分类高准确率时,可能会对很多待分类文本进行拒绝分类。为了验证NSTWSC与ESTWSC在分类成本的表现情况,表9讨论了两种算法在每一粒度上的总分类成本和平均分类成本。在表9中,ESTWSC在4个数据集上每一粒度的分类成本都小于NSTWSC的分类成本,且最终总分类成本和平均分类成本均小于后者。究其原因是因为ESTWSC比NSTWSC能够正确识别更多的待分类文本,这自然会降低分类成本。

表9 总分类成本和平均分类成本比较Table 9 Comparisons of total classification cost and average classification cost

图3 NSTWSC与ESTWSC整体分类性能比较Fig.3 Overall classification performance comparisons on ESTWSC and NSTWSC
进一步地,为了综合比较上述两个模型的分类质量和分类成本,本文采用准确率和F1值衡量分类质量,利用总分类成本和平均分类成本来衡量分类成本,实验结果如图3所示。
一方面,图3(a)展示了两个三支分类算法在总分类成本和平均分类成本的对比情况。从图3(a)中可以看到:ESTWSC的总分类成本和平均分类成本比NSTWSC下降了26.3%、12.2%、12%和9.8%,这说明ESTWSC在降低成本方面更有优势。另一方面,从图3(b)分类质量来看,ESTWSC在分类准确率和F1值相较NSTWSC均有所提升,其中在计算机数据集的准确率上升了1.49个百分点,外卖数据集的F1值上升了1.13个百分点,且未分类文本比率有所下降。
基于上述分析,本文将集成学习方法与序贯三支决策相结合的方法是合理可行的,它不仅可以提高分类质量,降低未分类样本数量;还能够降低分类成本,提高整体分类性能。
4 结论与展望
本文利用集成学习的优势,将三支思想与集成学习思想融合,提出了一种结合集成学习的序贯三支情感分类方法,探讨了N-gram语言模型构建文本多粒度结构过程,通过在每一粒层下采用集成方法,来提高模型的整体分类效果,并分别从分类质量和分类成本两个方面来评估算法有效性。实验结果表明:本文所提方法不仅能够提高分类性能,而且可以降低分类成本,这说明将集成方法与三支有效结合能够提高整体模型的分类性能。然而,本文在集成学习中仅采用了简单投票法,其数学机理和集成策略还有待深入思考。此外,本文所提出的集成学习方法不仅可以运用在情感序贯三支决策上,还可以运用到其他实际决策和文本分析问题中。
猜你喜欢
纺织科学研究(2021年9期)2021-10-14
粉末冶金技术(2021年3期)2021-07-28
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
系统工程与电子技术(2016年12期)2016-12-24
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
浙江大学学报(工学版)(2016年11期)2016-06-05
应用海洋学学报(2015年3期)2015-11-22
电测与仪表(2014年15期)2014-04-04
测绘科学与工程(2013年2期)2013-03-11
