
融合知识表示学习的双向注意力问答模型
2021-12-12 02:51潘志松
计算机工程与应用 2021年23期
卢 琪,潘志松,谢 钧
中国人民解放军陆军工程大学 指挥控制工程学院,南京 210000
知识图谱以节点和边来表示真实世界中存在的各种实体及其之间的关系,最早于2012年由谷歌提出,起初用于提高搜索引擎智能化搜索能力,如今各公司,如微软Bing、搜狗知立方、百度知心等,都构建了自己的知识图谱。而随着Freebase、DBpedia、YAGO等大规模开源知识图谱的诞生,知识图谱相关的研究和应用在多个领域飞速发展[1],知识图谱问答(Question Answering over Knowledge Graph,KGQA)便是研究热点之一。
近年来智能问答取得了极大的发展,很多智能问答系统走进了人们的生活,为人们带来了很大的便利。苹果公司研发的智能语音助手Siri不仅能智能问答还可以对手机进行语音控制等操作。之后各大公司也推出了自己的语音助手或者问答系统,如微软开发了Windows上的语音助手微软小娜Cortana,百度推出了自己的人工智能助手小度,腾讯开发的聊天机器人QQ小冰等。根据数据的来源可以把智能问答分为三类:(1)基于知识库问答,也称为知识图谱问答,即直接从构建好的结构化知识库中检索答案;(2)基于文本问答,也称为机器阅读理解式(Machine Reading Comprehension,MRC)问答,每个问题对应若干篇非结构化文本数据,从文本数据中检索和抽取答案;(3)基于社区的问答,用户生成的问答对组成了社区问答的数据,例如百度知道、搜狗问答、知乎等论坛。随着知识图谱的发展,知识图谱问答有了越来越重要的现实意义。
知识图谱问答任务形式定义为:给定一个包含若干三元组的知识图谱G和一个自然语言问题q,要求根据知识图谱正确回答问题。如今知识图谱问答的方法要分为基于语义解析和基于信息检索两种方法,近年与深度学习相结合,取得了优异的表现,但是仍然面临诸多的挑战。Bordes[2]、Huang[3]等人都基于知识嵌入设计了有效的知识图谱问答框架,在简单问题方面实现了优异的性能,但是模型推理能力较差,回答多跳问题的能力有待提升。Sun等人[4]增强了模型的推理能力,并且在知识图谱的基础上引入了额外的文本数据,但是仍然无法有效处理知识图谱中数据缺失和数据稀疏的问题。此外,Sun[5]、Bao[6]等人的工作都是通过限制问题的跳数先得到知识图谱的子图,然后在子图上进行推理得到答案。综上可知目前的知识图谱问答仍然存在下列问题:(1)复杂的场景下,要求模型具有推理能力,从而正确回答多跳问题;(2)当知识图谱的信息不完整时,如何保证知识图谱问答的性能;(3)如今的多跳知识图谱问答大多对跳数有所限制,模型仅对知识图谱局部建模,损失了长距离信息。
针对上述问题,本文提出一种融合知识表示学习的双向注意力模型,该模型引入知识表示学习以解决知识图谱数据稀疏和数据缺失问题,BiDAF[7]模型使用了双向注意力模型在机器阅读理解任务上取得非常优异的性能,受Seo等人启发,KR-BAT模型构建了双向注意力模型来提高模型的推理能力,能够更好地处理多跳问题。主要贡献为:(1)设计一个主题实体预测模型,引入知识表示,对于未登录实体也能预测其表示,有效解决知识图谱不完整所带来的信息损失;(2)结合双向注意力机制和LSTM,提高模型的多跳推理能力;(3)提出融合知识表示的双向注意力模型,经过实验,模型针对多跳问题和不完整知识图谱情况实现了优秀的性能。
1 相关工作
1.1 知识表示学习
知识表示是知识组织的前提和基础,表示学习把数据转换成一种机器能够有效处理的方式,便于模型提取特征。
早期的独热表示[8](One-hot representation)是一种简单有效的数据表示方法,独热表示通过0和1将数据编码成向量,如果数据维度为L,则独热编码中只有一维元素为1,其余L-1维为0。独热表示方法优点在于通过无监督的方法,有效地把数据区分开来,耗费少。但是该方法的缺点也较为突出,独热编码认为数据之间都是独立的,无法对数据之间的语义相似度进行建模,然而在自然语言处理领域中,语义相似度尤为重要,这样会导致信息损失严重;其次,当数据规模较大时,独热表示容易造成维度灾难,且编码的向量过于稀疏。
与独热表示相比,基于机器学习的表示学习能够把数据映射成低维的向量,解决了数据稀疏问题,并且学习过程能够对数据之间的语义相似度进行建模,更有利于模型提取特征。
知识表示学习是以知识图谱中节点和关系为对象的表示学习[9],目标是把知识图谱中的节点和关系映射为低维向量,实现对知识的建模,对知识图谱的构建、补全、推理和应用有着重要意义。
结构表示(Structured Embedding,SE)是距离模型的一种,对于每个三元组(h,r,t),模型为关系r定义了两个投影矩阵,分别用于头实体h和尾实体t的投影,然后计算两个实体投影直接的距离,距离代表该三元组中头实体和尾实体的语义相似度。但SE中头实体和尾实体是根据两个不同的矩阵进行投影,语义关系的建模能力较差。
双线性对角模型DistMult[10]把关系矩阵设置为对角阵,提高处理多关系数据能力的同时,极大简化了模型。但是DistMult过于简化,无法处理非对称关系,于是ComplEx[11]在DistMult基础上提高非对称关系建模能力,通过把实体和关系映射到复数空间,利用埃尔米特乘积对非对称关系进行建模。
受到Word2Vec[12]中平移不变的启发,Bordes等人[13]提出TransE模型。对于每个三元组(h,r,t),TransE把尾实体向量νt看作头实体向量νh经过关系向量νr平移得到,希望满足νh+νr≈νt。TransE模型参数较少、简单有效,是知识表示学习中最为经典的模型之一,但是无法建模复杂关系。TransH[14]在TransE的基础上把实体向量投影到关系向量对应的超平面上,以此缓解复杂关系下的学习过度收敛问题。TransR[15]在TransH的基础上定义了两个投影矩阵,把实体向量投影到关系语义空间中,经过投影的实体区分度增加,提高复杂关系建模能力。但是TransR构造的两个投影矩阵提高了模型的计算复杂度,TransD[16]把TransR的投影矩阵分解成两个向量,降低了模型的复杂度,并且关系和实体共同参与构造投影矩阵,模型对语义建模能力更强。
1.2 知识图谱问答
知识图谱问答的关键在于把用户的自然语言问题转化为机器可以理解的形式查询。目前知识图谱问答方法主要分为两类:基于语义解析的方法和基于信息检索的方法。
基于语义解析的方法:把要解决的问题看作语义解析问题,即把自然语言问题转化成语义表示,再映射成逻辑形式,在知识图谱上进行查询得到答案。Zhang等人[17]提出了一个基于注意力机制的模型来根据候选答案的不同侧重点动态地表示问题,利用了知识图谱的全局信息,并且一定程度上解决了未登录词的问题。Alvarezmelis等人[18]提出了一种改进型树状解码器,使用两个独立的RNN分别对父-子和兄弟-兄弟节点之间的信息流建模,提供了使用RNN从自然语言查询生成可执行的查询语言这一思路。Mohammed等人[19]用最基本的神经网络结构(CNN、LSTM)加上一些简单的规则,便能在简单问题上达到很好的性能。
基于信息检索的方法:先确定用户查询中的中心实体,然后链接到知识图谱中确定相关实体得到候选答案集合,之后通过评分或者排序的方式找出最可能的答案。Yih等人[20]使用卷积神经网络解决单关系问答。通过CNN构建两个不同的匹配模型,分别用来识别问题中出现的实体和匹配实体与KG中实体的相似度,相似度最高的三元组作为问题的答案,但是模型难以处理复杂的多关系情况。Hao等人[21]更关注问题的表示,提出了一种新的基于Cross-Attention的模型,根据不同的答案类型赋予问题中不同单词的权重,这种动态表示不仅精确而且更加灵活。
在引入知识表示学习之后,Bordes等人[2]进行了进一步的研究,仅使用少量的手工特征来学习单词和知识的低维向量。Li等人[22]提出使用多列卷积神经网络(Multi-column CNN)从答案路径、答案类型和答案上下文三个角度来表示问题,提取了更丰富的信息并且不依赖手工特征和规则。Huang等人[3]基于知识嵌入设计了一个简单有效的知识图谱问答框架(KEQA),针对简单问题,要求模型恢复出实体和谓词,在简单问题方面实现了优异的性能,但是模型不具有推理能力,无法处理多跳问题。Saxena等人[23]基于预训练模型设计了EmbedKGQA模型,在多跳问题上有很好的处理能力,尤其是当知识图谱不完整时,利用链接预测实现知识补全而不需要额外的文本数据。
2 融合知识表示学习的双向注意力模型
本文结合知识表示学习和双向注意力机制,提出了一个融合知识表示学习的双向注意力模型(KR-BAT)用于知识图谱问答,模型框架如图1所示,主要包括两个模型:(1)主题实体预测模型:预测问题中主题实体的表示;(2)双向注意力模型:问题与实体进行交互并返回答案。图1中紫色部分TEP(Topic Entity Prediction,TEP)即为主题实体预测模型,剩下的部分构成了双向注意力模型(Bidirection ATtention,BAT)。在BAT中的注意力层实现两个模型的有机结合,TEP模型的输出作为BAT模型中注意力层的输入,通过双向注意力实现信息交互。TEP为三层结构的层级模型,BAT模型由四层组成,两个模型的细节部分将在2.2节和2.3节进行详细介绍。在介绍模型框架之前,先介绍相关概念及任务形式。
2.1 相关概念及任务形式
一个三元组表示为<h,r,t>,h和t分别表示头实体(head entity)和尾实体(tail entity),r表示两个实体间的关系。知识图谱是由众多三元组构成的集合,对于知识图谱可以形式化描述为G={ }E,R,E,其中E和R分别表示所有实体和关系的集合。对于知识图谱G,使用如TransE等知识表示学习模型可以得到关系和实体的分布式表示,一个三元组被表示为<eh,er,et>。
知识图谱问答任务形式定义为:给定一个知识图谱G和一个自然语言问题q,要求根据知识图谱正确地回答问题。
2.2 主题实体预测模型
知识图谱问答首先要预测出问题中的主题实体,可以通过序列标注、语法句法解析等方法来检测出主题实体。但是,面对用户给出的问题可能包含未登录实体,以及知识图谱不完整等情况,这些方法难以检测出主题实体。针对上述问题,构建了主题实体预测模型(TEP)。
TEP是一个层次结构,架构如图2所示,主要由三层构成,输入层(Input Layer)、建模层(Modeling Layer)、输出层(Output Layer)。输入层中,给定一个长度为J的自然语言问题,首先把J个单词表示成词向量{qj},j=1,2,…,J。词向量输入建模层后,使用BiLSTM[24]进行建模提取语义信息,得到正向的隐层状态序列和反向的隐层状态序列。

图1 KR-BAT整体框架图Fig.1 Overview of KR-BAT
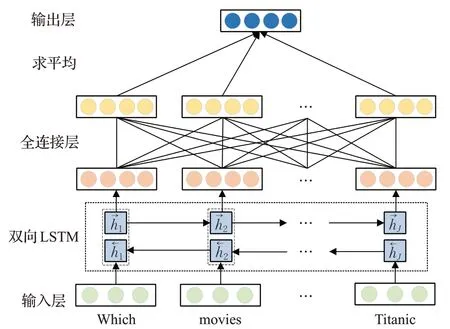
图2 主题实体预测模型Fig.2 Topic entity prediction model
正向隐层状态可通过公式(1)~(5)得到:
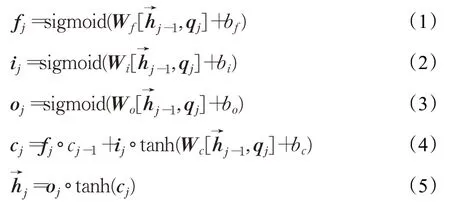
其中,fj、ij和oj分别是LSTM遗忘门、输入门和输出门的激活向量,Wf、Wi、Wo、Wc与bf、bi、bo、bc分别为三个门控机制与记忆细胞的权重和偏置,cj是记忆细胞状态向量,°是对应元素乘积。正向和反向状态拼接得到当前词的隐层状态:。输出层中经过全连接层,得到token的目标向量rj,再对所有token的目标向量求平均得到主题实体表示向量:

当给定一个自然语言问题作为输入时,TEP目标并非判断主题实体的位置,而是直接对主题实体的表示进行预测,使预测的表示尽可能接近该实体经过知识表示学习得到的向量表示,注意这里是经过知识表示学习的向量et,而非主题实体的词向量qt。即使问题中的主题实体是未登录实体,TEP也能给出该主题实体经过知识表示学习后的向量,通过主题实体预测模型引入知识表示学习,得到包含知识图谱中其他节点信息的主题实体表示,这时的实体表示是具有知识图谱感知的主题实体(KG-aware Topic Entity)。
2.3 双向注意力模型
双向注意力模型(BAT)为图1中TEP模型右侧部分,由四层组成:输入层(Input Layer)、问题嵌入层(Query Embedding Layer)、注意力层(Attention Layer)和输出层(Output Layer)。
(1)输入层。把一个长度为J的自然语言问题中的每个词,映射到向量空间:{qj},j=1,2,…,J,qj∈ℝd。这里使用Manning等人[25]提出的GloVe预训练词向量,GloVe是基于共现矩阵分解得到的表示,向量包含了全局信息。
(2)问题嵌入层。使用一个BiLSTM对词向量表示的问题进行建模,实现问题内部的信息传递,对BiLSTM正向和反向隐层表示进行拼接,获得隐层表示hj∈ℝ2d,j=1,2,…,J。
(3)注意力层。TEP输出预测的主题实体表示向量,与候选答案实体表示eai拼接:

首先计算Q和E的相似度矩阵S∈ℝT×J:

Sij表示第i个候选答案与问题中第j个词的相似度,Ei为E的第i个列向量,Qj为Q的第i个列向量,α是可训练的映射函数,用于编码输入向量之间的相似度,本文使用的映射函数为:

其中w(S)∈ℝ6d,为相似度矩阵S的权重向量。然后用相似度矩阵S得到行和列两个方向的注意力。
①行注意力(Row-wise Attention,RA)。行注意力如图3所示,针对相似度矩阵的每一行计算注意力:

图3 行注意力Fig.3 Row-wise attention

ai∈ℝJ表示问题中哪个词qj与每个答案实体ei最相关,Si为相似度矩阵的第i行。则加权后问题的每个单词表示向量为:,加权后的整个问题编码矩阵为。
②列注意力(Column-wise Attention,CA)。列注意力如图4所示,针对相似度矩阵的每一列计算注意力,先对相似度矩阵每一行求最大值,然后对列进行归一化得到:

b∈ℝT,maxrow表示对行求最大值,加权后的实体表示向量为,重复T次得到加权后整个实体编码矩阵,。
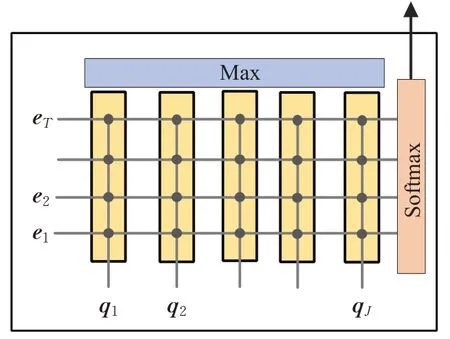
图4 列注意力Fig.4 Column-wise attention
得到两个方向的问题编码和实体编码之后,进行拼接得到问题感知的实体表示:

(4)输出层:输出层以问题感知的实体表示{gi},i=1,2,…,T为输入,输出每个实体为答案的概率:

使用两层全连接层和softmax函数得到每个候选答案实体的概率,概率最大的即为预测答案,其中Wfc为全连接层的权重。
3 实验
3.1 实验数据
本文使用开放数据集MetaQA[26]进行实验,该数据集是WikiMovies的扩展,包含用于单跳和多跳推理的40万多个问题,数据分为1跳、2跳和3跳,具体数量如表1所示。此外,MetaQA还提供了一个知识图谱,该知识图谱包含13.5万条三元组、4.3万个实体以及9种关系。表2展示了MetaQA中三种跳数的问题形式。
3.2 实验设置
实验使用的操作系统为Ubuntu16.04,GPU使用显存为32 GB的V100,开发环境为Python3.7、Pytorch 1.7.1。
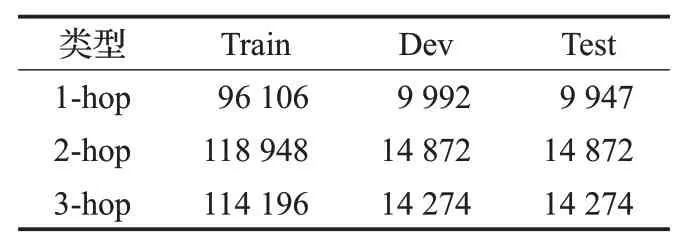
表1 MetaQA数据集Table 1 MetaQA dataset

表2 MetaQA数据集问题(跳数示例)Table 2 MetaQA dataset questions(hop example)
两个模型的具体参数设置如表3所示。其中预训练词向量采用GloVe,知识表示方法采用TuckER[27]。

表3 模型参数设置Table 3 Model parameters setting
为了加快学习速度,防止过拟合以及模型不收敛等问题,设置了EarlyStopping,其中Patience表示当模型在指定数量的epoch内没有改进时,停止训练。
3.3 实验结果及分析
本文和以下几种基准模型进行比较:
(1)Bordes等人[2]基于子图嵌入表示提出的模型,学习单词和知识库子图组成的低维向量,向量用于给自然语言问题打分。
(2)VRN[26]:提出了一种端到端的变分学习算法,让模型能够处理问题中的噪声问题,同时具有多跳推理能力。
(3)KV-MemNN[28]:提出了一种基于Key-Value Memory Network的模型,可以通过键-值对的形式编码信息,并用于检索。
(4)GraftNet[4]:引入了知识图谱之外的非结构化文本用于数据增强,创建一个特定于问题的子图,该子图包含文本语料库中的KG实体、关系和句子,然后使用图表示学习方法来回答问题。
实验结果(hit@1)如表4所示,其中基准模型的结果来自Zhang[26]和Saxena[23]。知识图谱问答与机器阅读理解相比较为简单,因为数据都有一定的结构性并且答案一定存在于知识图谱中,为了验证当知识图谱不完整时模型的性能,设计了50%KG,即以50%的概率随机丢掉一条三元组。
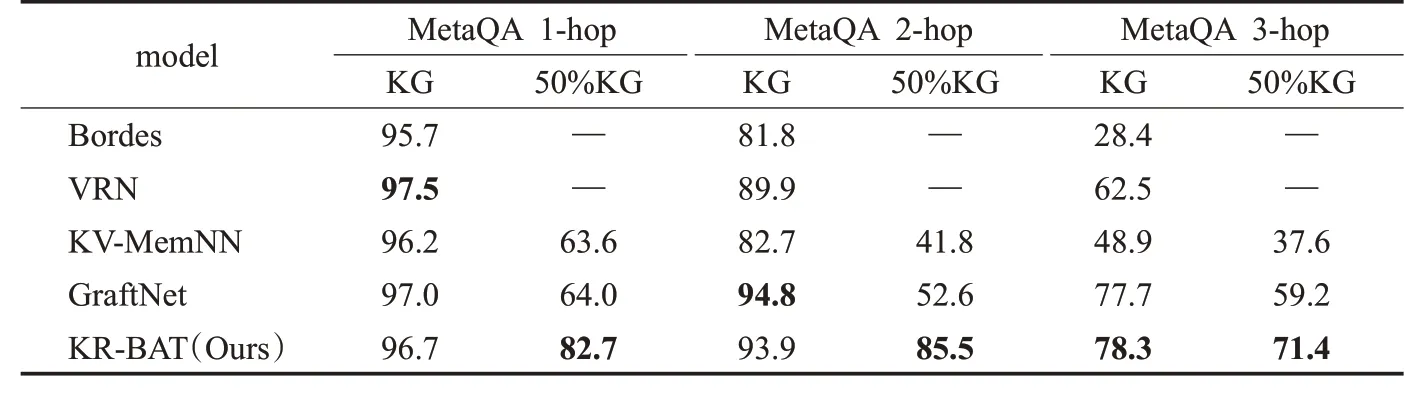
表4 实验结果对比Table 4 Comparison of experimental results %
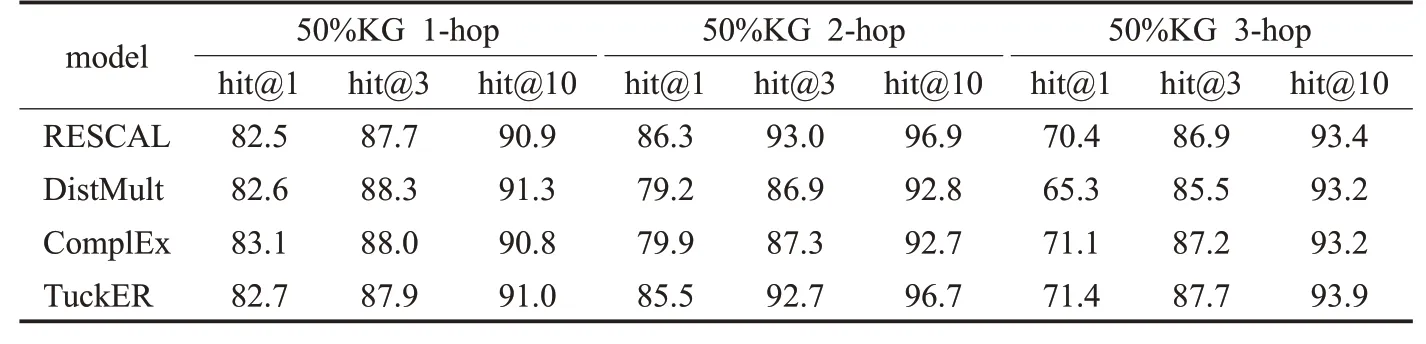
表5 不同模型结果对比Table 5 Comparison of results of different models %
对于完整的知识图谱,KR-BAT达到了很有竞争力的结果。当问题是1跳时,五个模型的结果较为接近,KR-BAT排名第三,性能略低于VRN和GraftNet,这是因为1跳问题为简单问题,仅用一条三元组即可回答问题,并不需要模型具有推理能力,而KR-BAT为了提高推理能力,聚焦于建模长距离信息,包含了丰富的全局信息,损失了部分局部信息。当问题是2跳时,KR-BAT性能排名第二,仅比GraftNet低0.9%,却大幅度由于第三名VRN(4%),这是因为GraftNet进行了数据增强处理,引入文本数据来辅助问答。当问题是3跳时,KR-BAT性能优于其他基准模型,这说明该模型具有优异的推理能力,能够很好地回答多跳问题。
对于不完整的知识图谱,KR-BAT在1跳、2跳和3跳问题上均大幅优于其他基准模型。当知识图谱不完整时,该任务对模型的链接预测能力要求很高,使用链接预测模型——TuckER来学习知识图谱的知识表示,即使面对不完整的知识图谱,也能通过模型进行知识补全,并把知识编码到知识表示中。此外,还对比了不同知识表示学习模型对KR-BAT在不完整知识图谱上的性能影响,结果展示在表5中。
4 结语
本文提出了一种融合知识表示学习的双向注意力模型用于知识图谱问答,其核心包括:(1)主题实体预测模型,用于融合知识表示并且对自然语言问题中的主题实体进行预测,有效解决了未登录实体和知识图谱不完整问题。(2)双向注意力模型,用于建模候选答案实体和问题之间的关系,捕捉答案和问题之间的信息,分析问题中的哪些词对于选择答案最重要以及哪些候选答案和问题相关,进行推理并选择答案。在MetaQA数据集上验证模型并与基准模型对比,在完整知识图谱中模型达到非常有竞争力的性能,在不完整知识图谱中,模型性能大幅优于其他基准模型。
在未来的工作中,考虑提高模型的局部建模能力,以提高模型在简单问题上的性能。此外,考虑将主题实体预测模型与双向注意力模型结合为一个整体,构建端到端模型联合训练。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
山西大学学报(自然科学版)(2021年1期)2021-04-21
少先队活动(2020年12期)2021-01-14
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
传媒评论(2017年3期)2017-06-13
中成药(2017年3期)2017-05-17
第二课堂(课外活动版)(2016年2期)2016-10-21
领导科学论坛(2016年9期)2016-06-05
现代防御技术(2014年6期)2014-02-28
