
基于分布式技术的用电信息采集主站系统设计与应用
2021-12-12 07:57:58闫海峰唐伟宁覃华勤马先芹
电力系统自动化 2021年23期
钱 奇,闫海峰,唐伟宁,覃华勤,马先芹
(1. 南瑞集团有限公司(国网电力科学研究院有限公司),江苏省南京市 211106;2. 北京科东电力控制系统有限责任公司,北京市 100192;3. 国网吉林省电力有限公司电力科学研究院,吉林省长春市 130022)
0 引言
中国“十四五”规划建议提出,加快数字化发展,并对建设智慧能源系统、提升新能源消纳和存储能力、加快电力市场改革提出了明确要求[1]。国家电网有限公司2020 年6 月15 日提出建设“客户侧数字新基建”重点任务,将分布式数据中心作为核心基础平台,以提升数字化连接感知和计算处理能力,分布式数据中心呈现出大型化、规模化的发展趋势[2-3]。随着电力体制改革、能源互联网建设工作的深入开展[4-5],分布式能源、储能、电动汽车等新设施的规模化接入[6]以及电力客户便捷用电和智慧用能需求的快速增长,使得计量专业的业务边界、业务内容、业务形式发生了新的变化,电力用户用电信息采集系统(以下简称“采集系统”)的定位已逐渐从单一抄表向设备状态感知、能源双向互动、负荷柔性调控、数据实时共享等方面延伸。随着高速电力线载波[7](HPLC)技术在低压集中采集的推广应用,采集数据项由电能示值、需量扩增到了电压、电流、功率因数、功率及事件等,采集频次从每日冻结1 次数据提升到了每15~60 min 采集1 次甚至每5 min 采集1 次数据,使得采集数据总量达到PB 级别[8],呈现了爆发式增长,对数据的采集质效、信息的存储分析与指令的快速响应提出了更高要求。
采集系统由主站系统、通信信道、采集终端、智能电表等组成,主站系统是采集系统的关键部分,主要实现数据搜集、信息处理融合、在线监控和应用扩展等功能[9-11]。传统主站系统对集中式架构存在依赖性,系统性能提升主要依靠增加CPU、内存、磁盘等方式,可扩展空间有限,在实时用电数据的采集、存储、计算方面,暴露出了明显的性能瓶颈,已无法满足高频全量集中采集需求[12-13],亟须优化主站系统架构和功能设计,全面支撑配电网设备全面感知、需求侧实时响应、负荷智能调控、用户友好互动等功能,以满足服务政府的外需、应对公司企业数字化转型的内需、引导用户用能的软需、解决新兴营销业务缺乏支撑手段的刚需。
针对当前能源互联网形势下主站系统面临的问题,文献[14]提出了一种基于云计算技术的主站系统,通过在存储系统、并行处理机制方面应用云计算技术,以增强主站系统在海量数据入库、查询、计算方面的处理能力。文献[15]提出一种应用Apache Kafka 分布式消息队列与HBase 列式数据库技术相结合优化主站系统的方法,提升了海量数据的入库性能及数据查询效率。文献[16]采用流式计算、微服务、分布式并行计算等技术改造原有集中式架构,构建了云计算平台上的分布式架构用电信息采集系统。这些技术方法对于解决当前在运主站系统所面临的大规模采集数据入库或计算问题,具有一定优化能力,但因尚未综合考虑通信、服务器、终端设备、应用扩展等影响因素,难以满足大规模用户采集的实际工程应用需求。
本文从实际工程应用角度出发,设计了一套基于分布式技术的高性能、高可用采集主站系统架构,提出了解决海量终端并发的异步网络通信模型,研究了分布式任务调度算法,进行了分布式存储体系设计改造,引进了分布式并行计算方法,整体提升了主站系统采集能力、数据存储能力及分析处理能力。最后,通过工程实例分析验证了系统的实用性,满足了新一代采集系统支撑用户灵活、便捷、高效、实时的用能的需求。
1 总体架构
分布式架构被广泛应用在输配电领域,作为一种专门针对海量数据场景的有效解决方案[17-19],由部署在不同服务器上实现不同功能的节点组成,各节点之间相互连接、相互协同从而实现整个系统的高效处理,适用于能源互联网形势下的新一代采集主站系统建设。本文基于分布式技术构建了高并发、低延时、易扩展、高稳定性的采集主站系统分布式架构,如图1 所示。
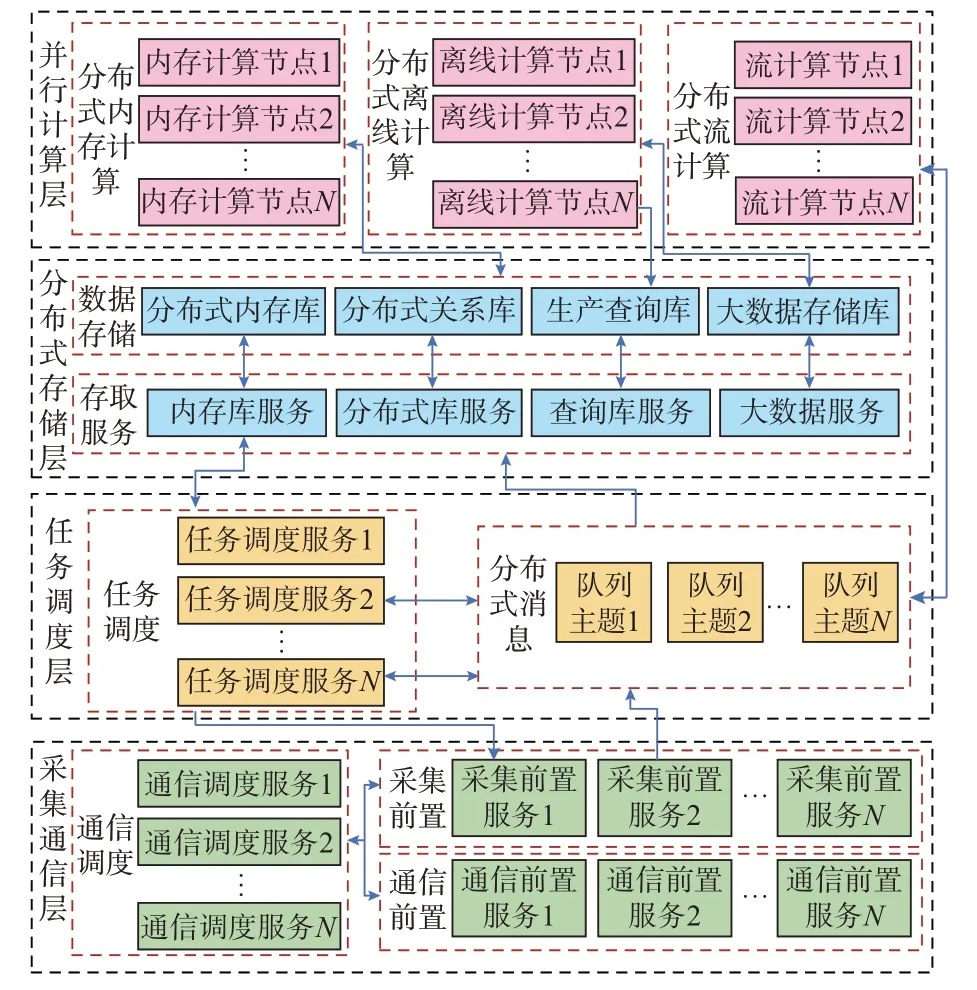
图1 分布式主站系统架构Fig.1 Architecture of distributed master station system
采集主站系统分布式架构方案在4 个层次完成设计,分别为采集通信层、任务调度层、分布式存储层及并行计算层。采集通信层通过构建分布式异步网络通信完成海量终端高并发接入及报文分布式处理,任务调度层通过分布式任务调度实现采集任务的分片执行,分布式存储层基于混合存储策略实现数据按类型、时间、用途的综合存储,并行计算层通过引入高效计算框架提升采集数据的实时分析能力。
2 分层设计
2.1 采集通信层
采集通信层整体负责与采集终端及任务调度层的通信,通过通信调度集群、通信前置集群和采集前置集群构建分布式前置采集架构,实现采集任务报文的组装下发及终端采集信息报文的识别处理。主站系统分布式前置采集架构如图2 所示。
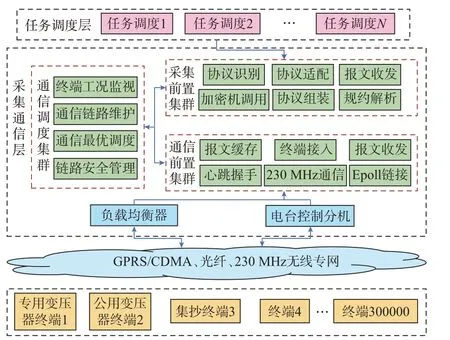
图2 分布式前置采集架构Fig.2 Architecture of distributed pre-acquisition
采集终端经过通用分组无线业务(GPRS)、码分多址(CDMA)、光纤、230 MHz 无线专网等网络渠道与采集通信层进行交互。为降低数据采集在通信过程的逻辑处理复杂度,基于通信调度构建分布式异步网络通信模型,实现通信层协同工作,降低采集通信间的耦合性,同时提升通信交互整体效率。基于通信调度的异步网络通信模型如图3 所示。
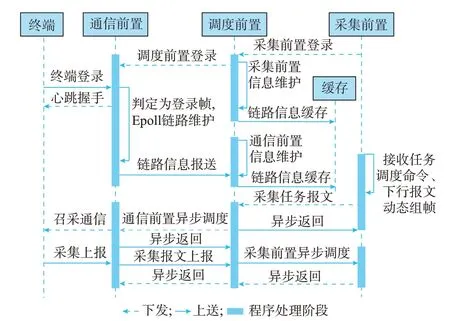
图3 异步网络通信模型Fig.3 Asynchronous network communication model
通信调度集群是实现通信层整体异步网络通信及分布式管理的控制枢纽,负责采集前置机和通信前置机间的通信管理。一方面将通信前置机上送的采集报文异步甄别后按终端及任务类型分布式调度至对应采集前置机处理,另一方面将采集前置机的下行采集报文异步判别后按终端分布式调度至相应通信前置机。终端链路经硬件负载均衡器负载均摊于通信前置机集群,通信前置机将终端链路信息上报至调度前置机进行统一维护,调度前置机按照通信优先级、终端链路信息实现通信报文、响应报文的上下交互控制,在提高系统整体并发性能的同时实现主站系统数据采集与交互能力的提升。
通信前置集群负责维护采集主站系统与终端之间的远程通信链路,实现信道底层的心跳握手、链路连接及原始通信报文的收发。针对海量终端高并发链接请求量达30 万以上,且均为长链接的需求,基于非阻塞式输入输出(NIO)的通信框架,将通信链路原有的select 技术升级为使用Linux 内核提供的异步Epoll 多路复用技术,构建终端链接层的异步网络通信机制,基于自平衡二叉树红黑树并结合双向链表,将链路维护时间复杂度由O(n)降低为O(1),实现以最小的资源消耗满足最大并发处理的需求。表1 为并发接入能力提升的测试数据依据。
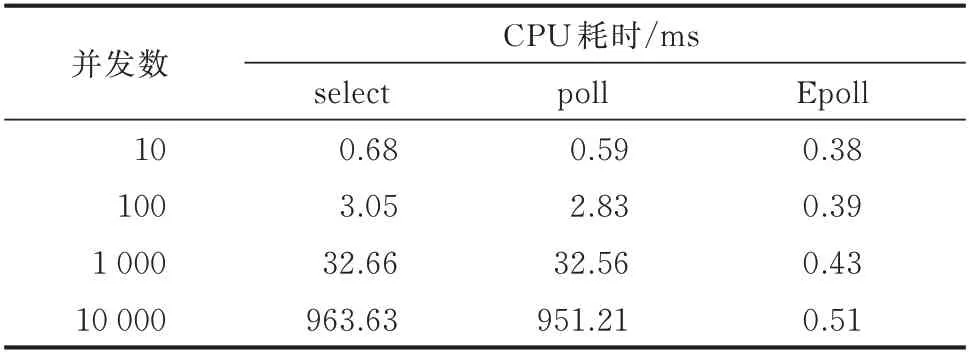
表1 并发链路维护技术的CPU 耗时对比Table 1 CPU time-consuming comparison of concurrent link maintenance technology
经过底层通信改造,系统单台前置的接入能力从3 万提升到10 万,并发通信能力从5 000 提升到3 万,结合硬件负载均衡模式及通信调度的管理,实现了终端数量的动态扩展,满足全省终端接入及海量数据高并发通信需求。
采集前置集群负责将采集任务按规约类型组装成通信报文,调用加密机对其进行加密并按国家电网公司安全应用层(State Grid secure application layer,SSAL)协议进行二次封装后经调度前置机下发至通信前置机,同时接收通信前置机上送的终端上行报文,识别规约类型并解析后上送至任务调度层。为提升通信资源的最大化利用,采集前置设计了动态组帧策略,主站系统按照终端厂家、协议版本在组帧时自动组装成不同的下行报文,并计算单终端下行请求最优帧数,其公式为:
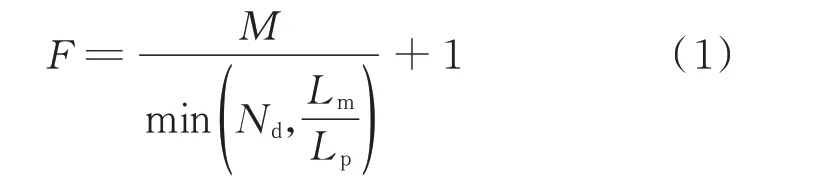
式中:F为总帧数;M为终端采集的总电表数;Nd为数据单元个数;Lm为最大响应长度(单位为B);Lp为采集单只电表终端可能回码长度(单位为B)。如一只1376.1 终端召测100 只电表日冻结正向有功示数,假设配置的数据单元个数是8、最大响应长度为500 B,组帧一只表终端可能回码的长度为50 B,则总帧数为13 帧。采集前置按照终端型号,配置每种终端单帧报文支持的最大响应长度和数据单元个数。在对某个终端下行请求组帧时,根据终端参数动态组帧,选择最优帧数。经优化改造,采集前置将更专注于报文处理,整体效率提升近3 倍,同步提升了资源利用率及通信成功率。
2.2 任务调度层
任务调度层主要解决既定周期或动态新增采集任务、业务请求任务、数据上报任务等的并行调度执行,同时支撑定时任务配置、任务状态分析、任务补抄、系统资源监视等功能。采集主站系统(以国网吉林省电力有限公司为例)每日至少执行45 类、约215 个非高频采集任务,需耗费大量系统资源处理任务编排及任务执行,集中式任务调度受资源及并行效率限制,难以匹配高频采集任务需求。基于分布式任务调度技术,重点实现对采集前置按终端进行采集任务的分布式分配,由分布式消息队列配合完成。分布式任务调度逻辑架构如图4 所示。

图4 分布式任务调度逻辑架构Fig.4 Logic architecture of distributed task scheduling
为满足采集系统整体资源调度性能需求,分布式任务调度由自行全新设计的TNRM(由Task、Node、Resource 及Mutual exclusion degree 首字母构成)算法实现,算法综合考虑任务频次、终端节点数量、服务器资源间的相互关系,实现最优终端采集任务分配。分布式任务调度算法描述如下:
描述1:令T表示任务集合{t1,t2,…,ti},其中i为任务数。 任务ti按执行周期展开表示为{ti1,ti2,…,tij},其 中tij表 示 第j个 周 期 执 行ti的 子任务。
描述2:令N表示终端集合{n1,n2,…,np},其中p为终端数。
描述3:令服务器资源综合性能评估指标集合R表示为{r1,r2,…,ro},其中o为分布式服务器节点数,ro指标数据由对第o个服务器节点经性能调优后,通过单一任务经压力测试机性能测试后的服务器综合表现得出,取并发处理能力。令Co表示服务器节点o在所有节点中的分布式处理能力占比,表示为如下公式:

式中:htn表示第t个子任务是否处理终端n的采集任务,是则为1,否则为0。
描述5:为了将不同终端任务放置于同一服务器节点执行,且保证互相干扰性最小,引入任务互斥度概念,假设M12表示终端n1与终端n2在同一服务器节点上执行时的综合互斥度,m表示终端n1与终端n2在执行具体子任务时的互斥度,则进行如下定义。
1)如果有相同任务执行,则完全互斥,m=1。
2)如果无相同任务执行,但执行时间重合,则完全互斥,m=1。
3)如果无相同任务执行,且执行时间不完全重合,则部分互斥,通过式(4)计算互斥度。

式中:At12为终端n1与终端n2在执行子任务时相重叠的时间秒数;Bt12为2 个终端在执行相同子任务时共同需要的时间秒数;0 <m<1。
4)如果无相同任务执行,且执行时间不重合,则完全不互斥,m=0。
由此可得到终端n1与终端n2在同一服务器节点执行所有子任务时的互斥度矩阵为:

由此可得到所有终端在同一服务器节点执行时的互斥度矩阵为:

式中:Mp1为第p个终端与第1 个终端的综合互斥度,直接置零表示与本身不互斥。
则只要求出终端间互斥度行列相加之和最小的数,且满足并发执行任务数小于服务器节点处理能力即可求得最佳分配路径。
描述6:设G为最优分配集合,v为集合中所有终端在同一时间执行时的最大任务并发数,w为集合中所有终端间互斥度行列相加之和,则G应满足min(w)且v<ro K,其中K为系数,服务器资源调用不能超过此系数,通常取0.8 以下。
经以上综合步骤,通过将服务器资源、并发任务数、终端并发量、资源占用互斥度的综合计算,实现了采集任务的分布式分配及服务器资源的最大化利用。本算法同时也与任务调度较常用的蚁群算法及传统轮询调度、min-min 类算法进行了特性对比,如表2 所示。

表2 任务调度算法特性对比Table 2 Characteristic comparison of task scheduling algorithms
蚁群算法需进行信息素长期积累训练[20],传统算法未充分考虑分布式环境的复杂性[21],本文算法虽在单一任务最优化上存在弱势,但综合考虑了复杂任务类型与终端链路的最佳匹配,除提升服务器资源利用率外可节省网络资源消耗,并可实现算法的自优化,以及支撑服务器资源的动态扩增。经工程应用跟踪验证,采集任务全部均摊至理想节点,链路命中率100%,本文算法适用于高并发终端链接下的采集主站系统任务调度。
在任务调度中融入分布式消息队列Kafka,可对系统中各类采集任务按照紧急程度、重要性进行分类[22],以多消息主题、多优先级任务收发队列实现任务的分级管理,支撑数据召测、参数下发、控制指令下发、采集数据上送等任务分主题交互,提高采集交互效率的同时,降低任务与通信层的依赖。
2.3 分布式存储层
分布式存储层实现采集系统业务数据的综合存储。针对采集数据日均增量超80 GB、月均增量超2.5 TB、年均增量超30 TB 的情况,综合考虑高频数据采集引起的高并发入库性能需求、存储可扩展性需求、对外数据共享需求,通过引入多类型分布式存储框架,重构由分布式存取服务、分布式内存库、分布式关系库、生产查询数据库以及分布式大数据库共同组成的主站系统存储体系,以支撑海量多用途的数据存储。分布式存储架构如图5 所示。

图5 分布式存储逻辑架构Fig.5 Logic architecture of distributed storage
存储层首先将上送至分布式消息队列的采集数据(上报任务数据和异常事件)经数据存取服务监听并反序列化后按类型、频度分别存储于分布式内存库、分布式关系数据库、生产查询库及分布式大数据库,实现数据的按需分类存储。
分布式内存库可缓解数据库服务器磁盘输入输出(IO)存取压力,提高数据访问实时性[23],采用Redis Cluster 技术研制实现。设计类关系型库表结构,将数据库态号、应用号、表号、域号、记录号按照规则生成唯一逻辑号,并与内存物理地址映射,数据存取时直接操作指定的内存物理地址。分布式内存库通过提供标准应用程序接口(API)传参方式,实现数据的快速存取,部分接口设计如表3 所示。
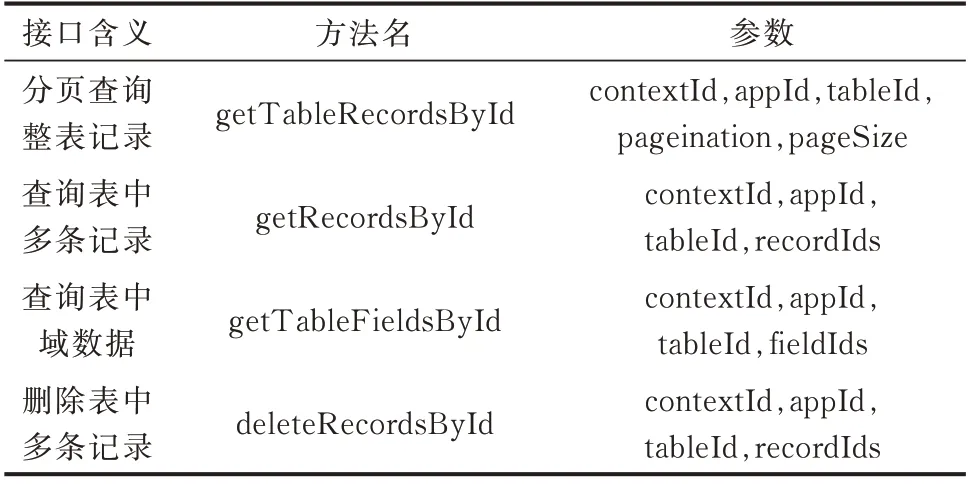
表3 分布式内存库接口设计Table 3 Interface design of distributed memory database
分布式内存库可存储档案数据、终端地址码、采集任务、终端在线信息、任务执行结果、实时计算结果、系统配置参数、高频更新数据等信息,保证了数据的实时访问,有效支撑了任务调度层及并行计算层的高效执行。
分布式关系数据库因存储节点可线性增加,不存在单点故障,海量数据并行入库能力强,具备高可用性及高扩展性等优点,用于支撑高频采集数据存储,实现在线事务处理应用。分布式关系数据库采用MySQL 数据库搭配MyCat 代理中间件构建,支持分片分析、路由分析、读写分离分析、缓存分析等数据处理功能[24]。在关系数据的分布式存储设计上采用了取模分片、范围分片、时间分片、哈希分片等多种混合分片策略实现,整体原则如下:
1)对于数据量小于等于500 万条且增量较小的实体,数据统一存储在同一个数据节点;
2)对于数据量大于500 万条、拆分后单表数据量小于等于1 000 万条且增量较大的实体,将实体主键值按照数据节点数量取模进行分库存储;
3)对于数据量大于500 万条、拆分后单表数据量大于1 000 万条且增量较大的实体,在实体主键值按照数据节点数量取模进行分库存储基础上,再按照数据采集日期切分策略进行分表存储,尽量保证水平切分后每个实体数据量小于1 000 万。
基于以上原则,将采集类数据以测量点ID 为分库键进行水平拆分,将事件类数据以终端ID 号为分库键实现分库存储,将数据量少、查询访问频率低和快速响应的业务数据(例如配置类及采集任务等数据)分配到某一节点上,以减少多库查询对数据集进行聚合带来的效率问题。分布式关系库支撑的数据存储类型主要包括近期(6 个月至1 年)采集数据、任务数据、事件数据、计算结果数据、系统配置数据以及全量的档案信息等。经实际工程应用表明,基于以上策略可实现数据的分片存储及快速查询,当存储节点扩容时,按照已有数据节点数量倍数扩展,可实现最小化数据平滑迁移,满足分钟级高频数据的存取需求。
生产查询库采用Oracle 数据库存储,基于Oracle GoldenGate(OGG)方式完成与营销档案系统数据的同步,同时通过保存系统档案、工单、日冻结数据及统计分析结果数据,支撑主站系统复杂关联查询类业务应用功能,以及对同安全区域系统的数据共享。
分布式大数据存储库将不具备联机查询价值但具备计算挖掘价值的采集原始数据,如采集全量日冻结数据、高频曲线数据、事件上报数据、计算结果数据、统计分析数据等海量数据,基于Extract-Transform-Load(ETL)、Sqoop、Flume 等工具完成数据同步,采用Hadoop 分布式文件系统(HDFS)、分布式列式数据库HBase 和廉价硬件环境完成存储。分布式大数据存储库可为并行计算提供大数据支撑,同时为主站系统提供历史数据存储备份。
2.4 并行计算层
并行计算层[25]基于分布式内存计算技术、分布式流式计算技术及数据挖掘、智能分析等组件构建“分布式大数据并行计算平台”,实现采集数据的实时处理及历史挖掘分析,以提升系统监测、用电预测、清洁能源消纳、供电安全等方面的智能化程度,满足分钟级的低压全量数据高频采集需求、海量数据实时并行计算的系统计算能力需求。并行计算架构如图6 所示。
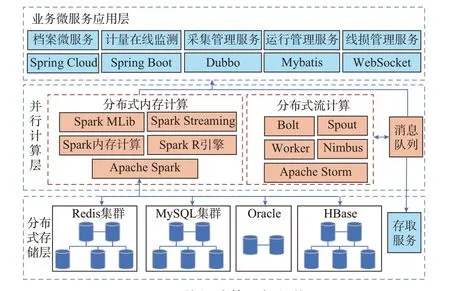
图6 并行计算逻辑架构Fig.6 Logic architecture of parallel computing
分布式内存计算基于Spark 技术的弹性分布式数据集(resilient distributed dataset,RDD)、有向无环图(directed acyclic graph,DAG)特性,实现计量在线监测分析、台区线损分析、多维指标统计、电量统计分析、台区负荷分析、防窃电挖掘分析等高级功能的并行计算。以台区线损分析为例,首先基于HBase 设计以台区编号、采集批次、测量点号为主的Rowkey,采集数据按Rowkey 规则存入列式数据库,经内存计算平台调用后,基于公式[(供电量−售电量)/供电量]×100%完成线损率[26]的并行计算。计算后的结果被推送至消息队列,应用层通过消息订阅,将计算结果以WebSocket 方式主动推送至线损可视化看板、线损在线监测等前端。通过对线损波动情况的实时掌握,帮助供电部门制定和实施经济合理的线损率指标,及时发现电网结构、用电、计量设备性能及运行状况等方面的薄弱环节,减少人为错误和高损发生率,为线损管理提供及时科学的决策支撑。
分布式流计算基于Storm 技术,实现消息流数据的边采集边计算,典型的应用有基于事件流的停电故障、停电范围实时研判。主站系统首先将上报的停电事件流推送至消息队列,流计算平台接收到订阅的消息后,对停电事件的有效性与真实性进行实时甄别,过滤掉无效事件及垃圾数据后,实时完成停电事件的准确性研判及有效性研判,以及停电影响范围的智能研判,经研判后的停电信息经接口动态推送至供电服务指挥系统及客户服务系统,支撑主动抢修业务,提升服务响应速度与客户体验。
3 工程实例
在国网吉林省电力有限公司主站系统建设项目中,开展了基于分布式技术的采集主站系统工程应用。该省电力公司低压用户约1 360 万户,共计约14 万台集中器及16 万台专用变压器终端,整体部署运行在由近100 台服务器组成的节点、集群环境上。单台服务器基本配置为CPU 2 个,共16 核,主频2.1 GHz,内存128 GB。
选取了全量低压用户日冻结示值数据采集及变压器实时组合曲线采集2 个任务,只统计任务第1 次执行结果,观察一周计算平均性能。基于分布式技术的采集主站系统与集中式采集主站系统在并发接入、数据通信、任务调度、数据入库、计算各方面的平均性能对比如表4 所示。
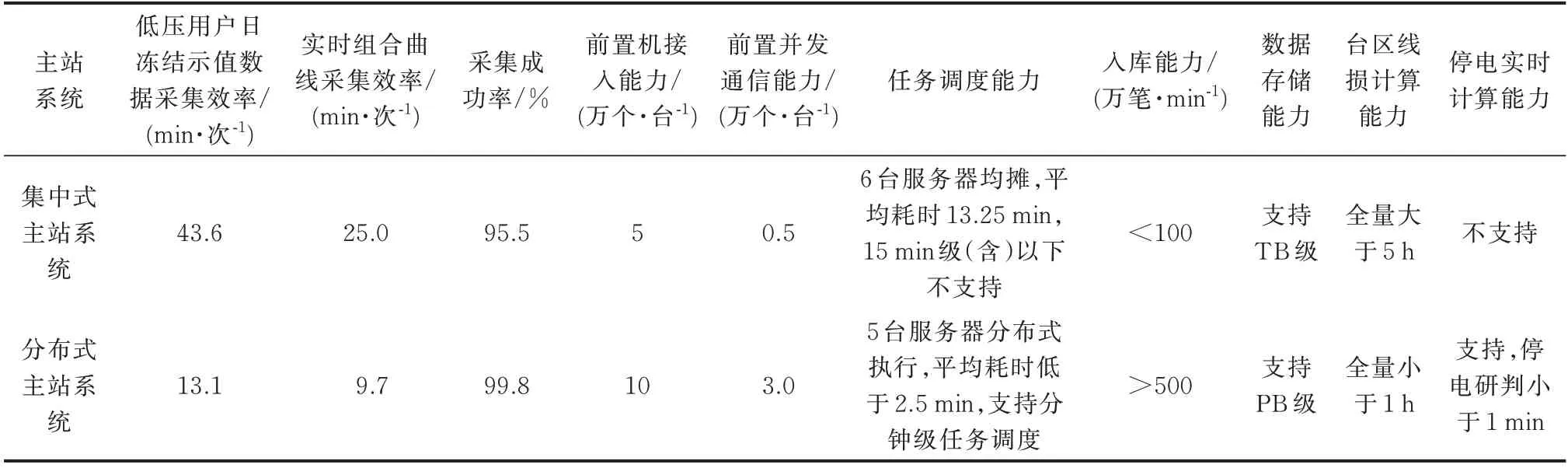
表4 2 种用电信息采集主站性能对比Table 4 Performance comparison of two main stations for power consumption information acquisition
2 种不同架构主站系统下,变压器实时组合曲线采集单个数据项,从采集任务调度、任务下发至完成入库,以及单台区线损计算(按服务器并行均摊后),分项平均耗时对比结果如图7 所示。
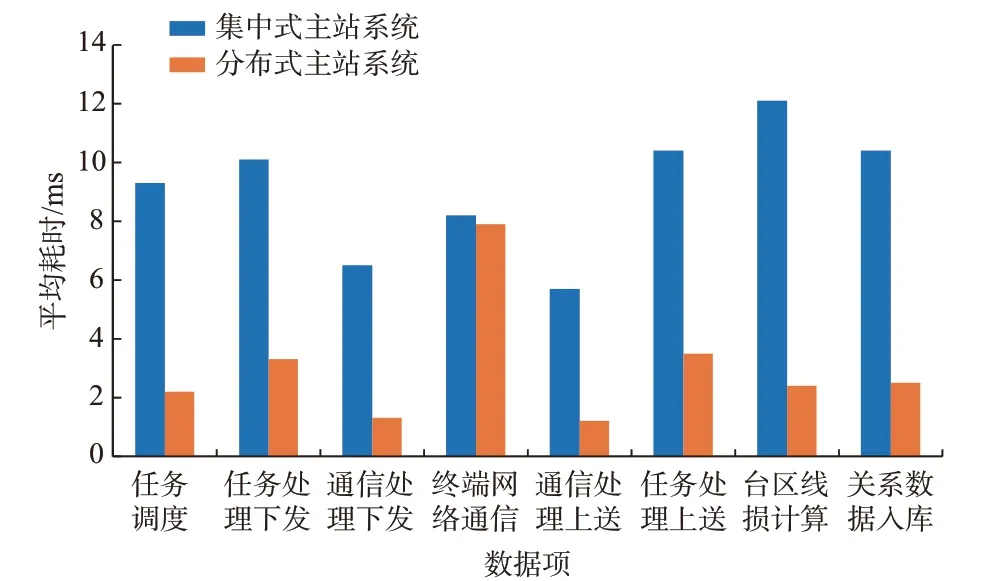
图7 实时组合曲线单个数据项处理平均耗时Fig.7 Average processing time of single data item of real-time composite curve
通过表4、图7 对比结果可知,本文设计的基于分布式技术的主站系统在海量数据采集、通信、存储、并行计算方面,相对于集中式主站系统,具有明显的性能优势,在提升采集效率与入库能力的同时,提升了前置并发处理能力及采集成功率。
4 结语
本文基于分布式技术提出了高性能采集主站系统架构,并在国网吉林省电力有限公司进行了应用验证。验证结果表明,基于分布式技术的采集主站系统可以有效地提升主站系统在大规模数据采集、入库方面的效率及服务能力,为智能电网采集系统下一步技术升级奠定了良好的理论和实践基础,对采集系统应用及提高采集系统对多种新需求的适应性具有借鉴意义。
猜你喜欢
中国生殖健康(2020年5期)2021-01-18 02:59:52
教书育人(2020年11期)2020-11-26 06:00:32
当代陕西(2020年13期)2020-08-24 08:22:02
制造技术与机床(2019年4期)2019-04-04 12:22:06
测控技术(2018年7期)2018-12-09 08:58:00
中国生殖健康(2018年5期)2018-11-06 07:15:42
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
信息通信技术(2015年6期)2015-12-26 01:16:54
雷达与对抗(2015年3期)2015-12-09 02:38:50
