
离散制造智能工厂场景的AGV路径规划方法
2021-12-09 08:29:12郭心德丁宏强
广东工业大学学报 2021年6期
郭心德,丁宏强
(1. 广东工业大学 自动化学院,广东 广州 510006;2. 物联网智能信息处理与系统集成教育部重点实验室,广东 广州 510006;3. 香港中文大学,广东 深圳 518172)
机器人技术的飞速发展见证了现代机器人的出现。越来越多的机器人被用以协助或取代人类在大量领域执行复杂控制操作和规划任务。然而,为移动机器人设计可靠的路径规划通常是一个复杂的过程,即使是专门为移动机器人进行路径规划的专家也需要花费大量的时间进行设计和试验[1]。移动机器人面临的不确定环境的复杂性使得机器人的路径规划相当困难,手动路径规划通常是一个昂贵且非常耗时的过程。因此,与其为机器人预先编写路径规划程序,不如让机器人自己学习路径规划[2]。
路径规划技术已被广泛应用于移动机器人、机械臂、无人机的导航中。路径规划是指机器人在复杂的环境中规划出一条从初始位置到目标位置的合适路径,是移动机器人导航最基本的部分[3]。配备多种传感器的移动机器人可以通过路径规划技术进行定位、控制运动器、检测障碍物并避开障碍物。自主智能的路径规划可以使得移动机器人根据环境信息进行综合判断和智能决策[4]。
近年来,许多经典的路径规划方法已经被深入研究,常见的有A*算法[5]、D*算法[6]、人工势场法[7-8]和蚁群算法[9]。然而,这些方法仍然存在一些缺点,例如无法或难以处理复杂的高维环境信息(如图像)或在复杂环境中容易陷入局部最优。相比之下,强化学习(Reinforcement Learning, RL)是近年来构建自适应和智能系统的强大方法。在强化学习的框架中,智能体是决策者,它可以在环境中采取行动,并在与环境进行交互的过程中获得强化信号,该信号通常称为奖励(或惩罚),是评估一个动作的结果。智能体不断进行环境交互与训练,以最大化一段时间内的总累积奖励[10]。此外,深度强化学习(Deep Reinforcement Learning, DRL)具有深度学习的强大感知能力和强化学习的智能决策能力,在面对复杂的环境和任务时表现突出[11]。例如,文献[12]中应用了深度强化学习的AlphaGo打败了人类。文献[13]将深度强化学习成功应用于复杂的交通灯周期控制。近年来,在将DRL应用于移动机器人路径规划方面也有突破性的工作。例如,在文献[14]中,应用DRL的行星车可以成功避开碎石和岩石。在文献[15]中,基于DRL的智能体可以在复杂3D迷宫中实现端到端的导航,即使在开始/目标位置频繁变化时,其表现也与人类水平相似。在文献[16]中,一种基于DRL的方法用于移动机器人的轨迹跟踪和动态避障,实现了视觉感知到动作决策的端到端学习方式。在文献[17]中,应用DRL的水面舰艇(USV)实现了在复杂未知的环境中最优的跟踪控制方案。
本文研究了离散制造智能工厂中AGV (Automated Guided Vehicle)的自主路径规划问题。为了提高AGV的自主路径规划能力和导航自由度,首先将AGV路径规划问题表述为马尔可夫决策过程模型,该模型包含3个主要元素:状态、动作和奖励[18]。AGV上多个传感器感知到的多模态环境信息被作为状态空间,由此产生的马尔科夫决策过程模型是一个高维模型,它包含由多模态环境信息组成的高维状态空间和二维动作空间。融合了DQN[19-20]3种经典改进(Double Deep Q Network[21]、Dueling DQN[22]、Prioritized Experience Replay[23])的Dueling Double DQN with Prioritized Experience Replay (Dueling DDQN-PER)深度强化学习方法,进行AGV在复杂环境中最优控制策略训练。
本文的主要工作如下:
(1) 基于机器人操作系统(Robot Operating System, ROS)和机器人仿真工具箱Gazebo对物理仿真环境进行建模。这2项工作能够为智能体和环境建立一个交互平台,并为基于深度强化学习的AGV路径规划提供一个实验平台。
(2) 在实际的离散制造智能工厂的智能物流系统中,除了货架和工作区的位置固定外,其他AGV的位置是在不断变化的。为了解决复杂智能物流系统中AGV的路径规划问题,本文在AGV路径规划方法中应用了基于深度强化学习的路径规划方法提高规划成功率。同时,本文重新设计了一种可以处理多模态传感器信息的神经网络结构,其可以同时处理来自AGV传感器的位置、速度、图像和激光雷达点云信息。
(3) 本文首先在无障碍环境中对AGV进行全局路径规划训练,该仿真实验比较了几种不同DQN算法的训练性能,并为复杂环境下的路径规划训练提供预训练策略。随后,在复杂的智能物流仿真环境中验证所提出的基于深度强化学习的路径规划方法。
1 AGV路径规划问题描述
在离散制造智能工厂的智能物流系统中,AGV常用以运输原材料,对于进行路径规划的AGV来说,货架、工作区、其他AGV和边界围栏都是障碍。因此,需要控制AGV的速度和角速度来进行最优路径规划。AGV可以利用全局信息进行全局路径规划,找到一条从起始位置到目标位置的相对较短且接近直线的路径,并利用局部信息进行局部路径规划以避开障碍物。主要目标是在不遇到障碍的情况下使路径长度最短。
本文应用ROS和Gazebo构建了离散制造智能工厂仿真环境。整个环境为一个被围墙包围的30 m×30 m的正方形区域,内有6个2 m×2 m的工作区、8个货架、10个其他AGV和一个主体AGV-Agent。本文中智能物流仿真环境如图1所示。

图1 离散制造智能工厂仿真环境Fig.1 Discrete manufacturing smart factory simulation environment

图2 RGB图像Fig.2 RGB image

图3 激光点云信息可视化图Fig.3 Visualization of laser point cloud information
AGV-Agent可以通过自身位置和目标位置信息识别图像信息前方是否有障碍物,并不断接近目标位置。为了让智能体更有效地学习,对AGV状态信息进行预处理。将768×1 024×3的图像转换为80×80×3的RGB图像,并记为simg,位置与速度信息融合成一个四维向量[d,θ,v,ω],其中d表示AGV与目标位置的距离, θ表示与目标位置的角度。
本文的AGV-Agent控制量是速度和角速度,将速度为0 m/s、0.5 m/s、1 m/s和角速度为0 rad/s、0.5 rad/s、−0.5 rad/s、1 rad/s、−1 rad/s组合成10种动作选择。虽然动作总数是任意的,但其中有一种选择不应该组合,即速度为0 m/s,角速度为0 rad/s,原因是当最优策略选择此动作组合时,AGV-Agent获取到的环境信息是没有变化的,因此很容易造成AGVAgent长时间停留在固定位置上。
在强化学习的框架中,AGV的奖励设置对于策略网络的收敛速度和训练效果至关重要。合适的奖励设计有利于策略的快速收敛,相反,不适合的奖励设计可能会降低收敛速度甚至会导致无法收敛,进而造成智能体训练失败。本文在考虑实际的离散制造智能工厂环境下,提出了一种有利于智能体进行学习的奖励和惩罚的设计。

2 本文方法
2.1 神经网络结构设计
本文重新设计的处理多模态传感器信息的神经网络架构如图4所示。AGV-Agent在每次交互过程中接收一张来自前置摄像头的768×1 024×3的RGB图像、来自激光雷达的360维激光点云信息和一个包含速度、角速度、目标位置距离和目标位置角度的四维向量。因此,重新设计的神经网络结构使用3个卷积层来提取RGB图像的特征信息,并使用一个全连接层来提取更远的环境信息。长短期记忆人工神经网络(Long Short-Term Memory,LSTM)用于提取激光雷达点云特征信息,全连接层用于提取四维向量特征信息。最后,使用CONCAT层进行特征信息融合。综合的特征信息作为Dueling网络结构的输入。
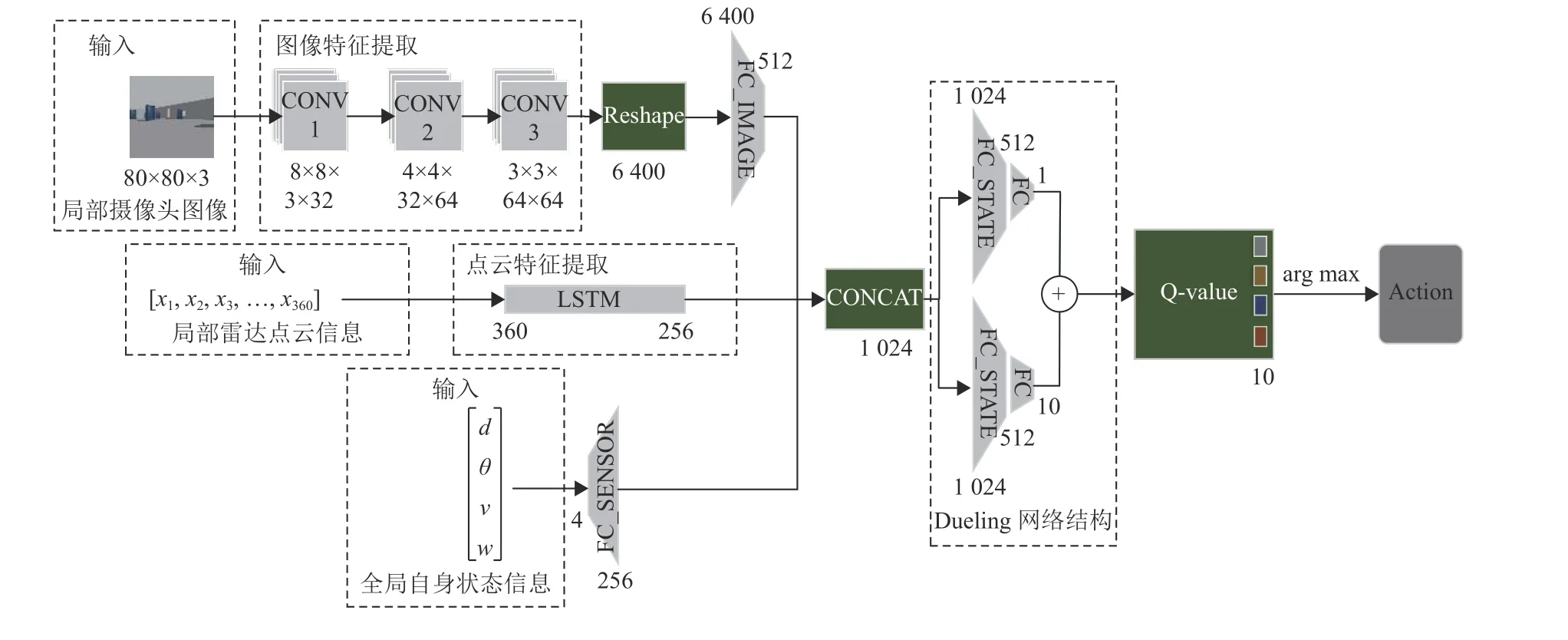
图4 神经网络结构Fig.4 Neural network structure
Dueling网络结构分别对动作值函数A(s,a;θ,β)和状态值函数V(s;θ,α)进行评估,最后形成Dueling网络结构的最终输出Q值,即为
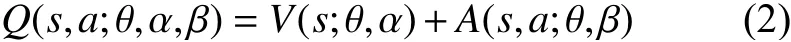
式中:s为当前状态,a为当前状态下的动作, θ为共享层的神经网络参数, α为状态值函数的神经网络参数, β为动作值函数的网络参数。
Dueling网络结构的应用可以提高最终Q值评估的准确性,最终提高学习效率和学习性能。最终网络会输出某个状态输入下的10个动作Q值,进而实现状态空间到动作空间的映射。最终选择Q值最大的动作作为AGV-Agent与环境交互的动作。
卷积网络本质上是一种输入到输出的映射。它可以学习到大量输入和输出之间的映射关系,而不需要输入和输出之间的任何精确的数学表达式,只要已知模型训练卷积网络,并且网络具有输入和输出对之间的映射能力。因此,使用3个卷积层来提取AGV-Agent的前视摄像头获得的预处理图像信息。3个卷积核的大小分别为8×8×3×32、4×4×32×64、3×3×64×64。
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。与一般的神经网络相比,它可以处理时空序列变化的数据。LSTM是一种特殊的RNN,主要解决长序列训练过程中梯度消失和梯度爆炸的问题。LSTM在更长的序列中比普通RNN表现更好。因此,将LSTM单元的单位设置为256来提取360维激光点云信息。
全连接层(Fully Connected Layers, FC)在神经网络中扮演“分类器”的角色。如果卷积层、LSTM等网络结构将原始数据映射到隐藏层特征空间,则全连接层起到将学习到的分布式特征表示映射到样本标签空间的作用。全连接层在本文的网络结构中有2个功能,一是提取AGV-Agent的速度和地理位置信息的特征,二是将信息融合后的特征映射到动作空间中。
2.2 基于深度强化学习的路径规划方法
RGB图像simg、四维向量作[d,θ,v,ω]和360维激光点云信息[x1,x2,x3,···,x360]为预处理后的环境信息s,它们被作为神经网络结构的输入,神经网络最终输出为在该状态下的10种动作Q值,Q值为动作−价值函数的值,表示未来奖励的期望回报。
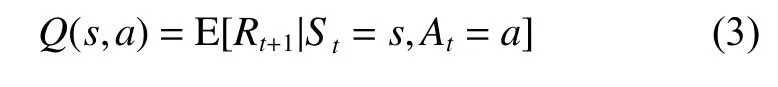
式中:St为状态空间S中t时刻的状态,At为动作空间A中t时刻的动作。在DRL中,利用神经网络作为函数近似器来估计动作−价值函数Q(s,a)。
选取神经网络输出的最大Q值对应的动作作为AGV-Agent的当前动作a,并以该动作与环境交互得到奖励r、下一状态s′和回合结束标记Fterminal,由此形成五元组〈s,a,r,s′,Fterminal〉,将该五元组存入经验池D中。使用Double DQN和Dueling DQN来避免过估计并提高训练性能。因此存在2个网络:当前网络Q,目标网络Q︿。通过经验优先回放方法在重放记忆D中选择固定数量的〈s,a,r,s′,Fterminal〉片段,形成一个Bminibatch并用于更新当前网络的参数θ。目标Q值yj可以通过式(4)计算。


在训练过程中,AGV-Agent的位置初始化对网络的收敛性有关键影响。AGV-Agent的初始位置位于整个轨迹的开头,这会导致在初始位置一定范围内过度学习,从而导致网络对该状态下环境信息形成过估计,而靠近目标位置的状态序列会缺乏学习,从而造成AGV-Agent无法更快地到达目标位置。为了克服这个问题,本文使用的起始位置初始化方案为:货架前面的位置和目标位置8 m内的位置的初始化各占50%的概率。

然后,根据一定的概率从该策略中生成一定的样本放入记忆池中。
3 仿真结果
3.1 预训练策略仿真结果
在无障碍环境中,AGV-Agent在每个回合开始时随机初始化起始位置和目标位置,初始化需要满足这两个位置的距离在20~25 m之间。当AGVAgent到达目标位置或当前回合达到最大300步时,该回合结束,并进入下一回合的训练。
本实验评估了基于DQN算法的3种不同关键改进(Double Deep Q Network[21]、Dueling DQN[22]、Prioritized Experience Replay[23])的3种组合算法,分别为Double Deep Q Network(DDQN)、Dueling Double Deep Q Network(Dueling DDQN)和Dueling DDQNPER。图5显示了预训练策略学习曲线,可以注意到Dueling DDQN-PER具有稍快的收敛速度和更好的稳定性,而其他两种算法在收敛后保持一定程度的振动。分别应用3种不同改进组合的DQN算法进行测试评估,其中前10个测试回合的路径长度统计在表1。从表1可以看出,Dueling DDQN-PER在10个回合内的平均路径长度为23.61 m,略优于DDQN的23.68 m和Dueling DDQN的23.87 m。

图5 预训练策略学习曲线Fig.5 Pre-training policy learning curve

表1 测试回合路径长度Table 1 Path length of test episodem
Dueling DDQN-PER是结合DQN算法的3个关键改进而衍生出来的,这意味着它具有Dueling网络结构对每个动作的Q值的相对准确的评估。Double DQN可以更好地避免过估计,经验优先回放机制可以为模型更快的收敛提供高效有益的数据。
本实验的对比结果可为复杂离散制造智能工厂环境下的路径规划选用最优的算法,且该预训练策略可用于复杂环境下AGV的环境交互,从而获得更优的训练回合数据供AGV进行训练。
3.2 离散制造智能工厂环境仿真结果
在无其他AGV的离散制造智能工厂环境中,经过本文方法训练后的AGV可以在保证规划成功率的前提下,使得规划长度较短。规划成功率从预训练策略的全局路径规划的34%提升至96%;在8个测试回合里,该方法的平均规划路径长度为22.11 m,优于快速扩展随机树算法(Rapidly-exploring Random Tree,RRT)的23.87 m。规划的路径轨迹对比如图6所示。
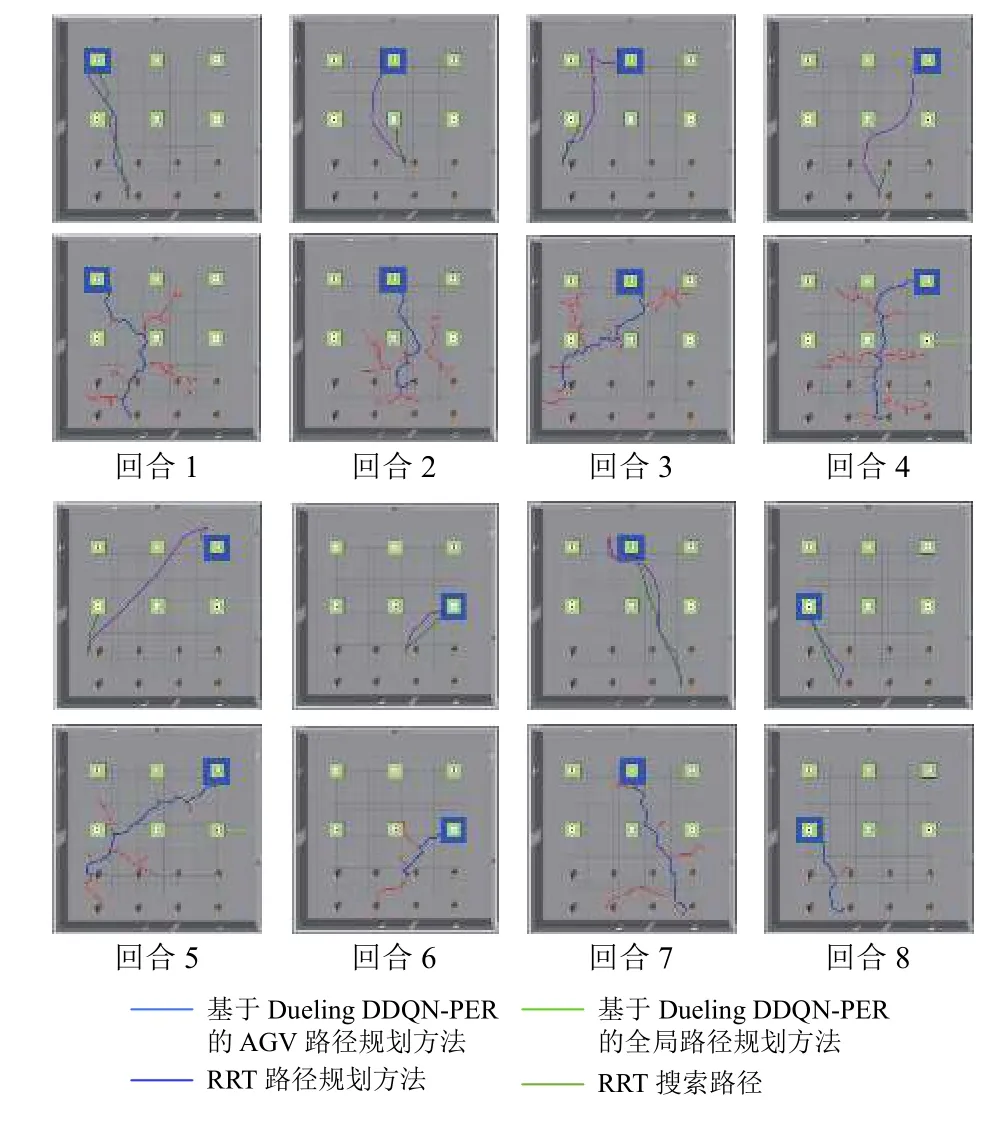
图6 路径规划轨迹对比图Fig.6 Comparison chart of path planning trajectory
离散智能制造工厂下的智能物流仿真环境中,不仅有一台主体AGV-Agent完成物料配送任务,环境中还包括多台AGV正在进行物料配送任务。在这种情况下,多台AGV会成为彼此的障碍,在避开工作区和货架的同时,也需要避开其他AGV。
在复杂环境的路径规划实验中,AGV-Agent经过70 000次连续的环境交互与迭代训练,策略神经网络的参数收敛到最优值。训练过程的代价曲线如图7所示。经过训练后的AGV-Agent学会了如何在未知复杂的环境中面对障碍物做出规避的动作选择。神经网络可以将AGV-Agent配备传感器获得的环境信息映射到最优动作选择。图8展示了6个测试回合的路径规划结果。可以观察到,AGV-Agent在面对障碍物时,不仅可以作出规避的动作选择,而且规划的轨迹也较为平滑。从图中的6条轨迹图也可以明显看出,当其他AGV出现在AGV-Agent前面时,其可以及时作出合适的动作选择,并改变当前的前进方向,从而避开障碍物。
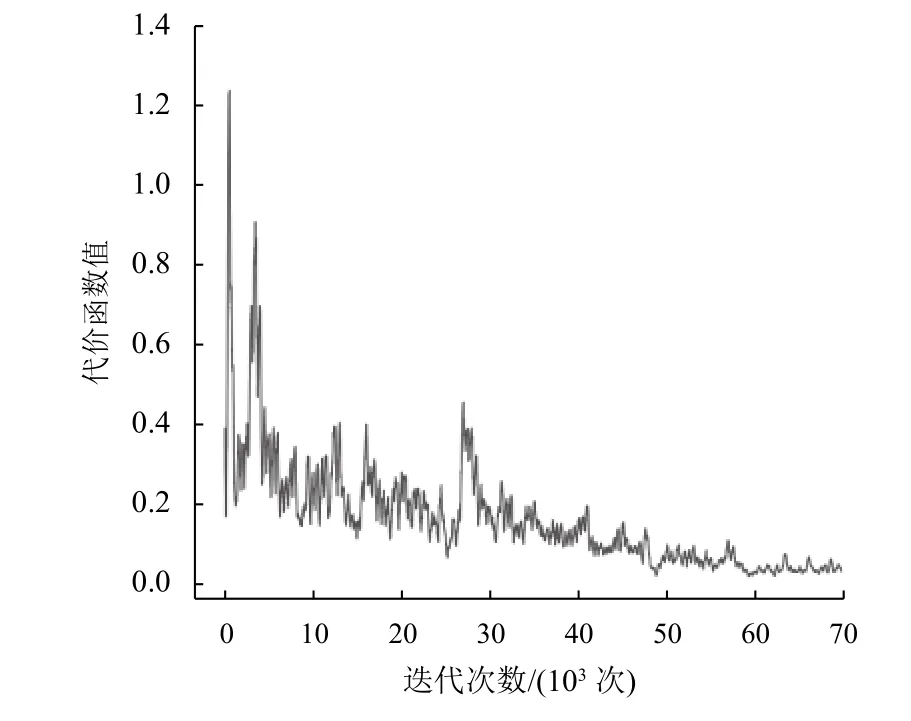
图7 复杂环境训练曲线Fig.7 Training curve of complex environment

图8 测试回合轨迹图Fig.8 Trajectory graph of test episode
在实验中,随着路径规划环境变得越来越复杂,障碍物的数量和类型也越来越多,AGV-Agent的规划决策也变得越来越困难。尽管如此,在大多数情况下,AGV-Agent可以成功规划路径轨迹。因此,本文设计的神经网络结构可以实现多模态传感器信息的融合感知,基于DRL的方法可以有效进行AGV路径规划的训练。实验证明了所提出的Dueling DDQNPER算法在不同路径规划环境下的可行性和稳定性。
4 结论
本文提出了一种基于RL的面向离散制造智能工厂路径规划方法。该方法主要基于Dueling DDQNPER实现,具有优先经验回放和全局路径规划策略的优势,提高了RL的收敛速度。此外,提出了一种新的神经网络,可以处理RGB图像、地理位置信息、速度信息和激光信息等多模式传感器信息。这可以让AGV-Agent获得足够的环境信息特征,以便更好地进行自主路径规划。实验结果证明了所提出的AGV路径规划方法的可行性,AGV-Agent可以在包含多台AGV且不可预测的离散制造智能工厂动态环境下安全地完成自主路径规划。本文提出的方法可以利用深度学习强大的感知能力和强化学习强大的决策能力,使AGV具有探索和避开障碍物的能力,从而可以更快地接近目标位置,并具有更短的路径轨迹长度。
在未来的工作中,继续加强学习的研究,尝试使用多智能体RL方法同时进行多台AGV的路径规划来完成某项任务。此外,将尝试使用RL方法进行连续动作控制,例如使用DDPG进行路径规划,可以更有效地模拟AGV的连续速度控制。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02 01:59:12
电子制作(2019年19期)2019-11-23 08:42:00
领导决策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
制造技术与机床(2017年3期)2017-06-23 08:11:21
中国卫生(2016年2期)2016-11-12 13:22:16
重型机械(2016年1期)2016-03-01 03:42:04
中国工程咨询(2016年4期)2016-02-14 07:28:28
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
