
基于多智能体强化学习的区块链赋能车联网中的安全数据共享
2021-12-09 08:29:12李明磊康嘉文徐敏锐DusitNiyato
广东工业大学学报 2021年6期
李明磊,章 阳,2,康嘉文,徐敏锐,Dusit Niyato
(1. 武汉理工大学 计算机科学与技术学院,湖北 武汉 430000;2. 南京航空航天大学 计算机科学与技术学院,江苏 南京 210016;3. 广东工业大学 自动化学院,广东 广州 510006;4. 新加坡南洋理工大学 计算机科学与工程学院,新加坡 639798)
随着无线通信与人工智能技术的快速发展,智能互联汽车得到迅速推广与普及。先进的车载传感系统与高级的车载娱乐服务使智能汽车产生越来越多有价值的数据(如交通信息、车载娱乐数据)。这些数据常被收集并共享于其他智能汽车或智能交通设施,从而构建更为先进的智能交通系统,为智慧城市的建设打下坚实基础[1-2]。然而,现有的数据共享中心化管理方式容易遭受单点失效、数据篡改等安全威胁,系统可靠性难以保障。尽管P2P(Peer-to-Peer)共享网络一定程度上克服了单点失效的问题,但由于安全防护和访问权限问题,其在车联网场景下并不实用。
近年来,区块链技术因其去中心化、不可篡改、安全可靠等优点被广泛应用于构建安全可靠的车联网数据共享系统[3]。文献[2]提出了基于PoW(Proof of Work)和PoS(Proof of Stake)共识的去中心化可信数据管理系统,以实现对车辆数据可信度的评估与管理。在文献[4]中,区块链技术被用于解决数据交易中缺乏透明性、可追溯性和非授权数据修改等问题,作者设计了一种基于区块链的车联网数据交易通用框架,该框架能实现车联网数据安全交易。但上述方法因其共识计算量过大、系统搭建成本过高等问题,并不适用于搭建安全高效的区块链赋能的车联网数据共享系统。现有研究已经把高效的DPoS(Delegated Proof of Stake)共识机制引入到车联网中[5-6]。委托权益证明DPoS共识机制是PoS共识机制的一种衍生机制,其基本思路是先从持有股份的节点中选出部分代表性节点作为矿工,再由这些矿工依次充当矿工领导者对交易信息进行打包,并由矿工领导者与验证者(即剩余的矿工)共同参与区块验证,进而产生新的区块[7]。该机制不仅能有效解决PoW共识机制计算资源浪费和PoS共识机制的股份集中化问题,还可以快速地处理交易数据,并具有较高的系统吞吐量,因此该机制能很好地匹配车联网场景服务高并发的需求,具有广泛的应用前景。
然而,传统的基于DPoS共识算法的区块链赋能车联网系统中区块验证者数量有限(常为21个),容易出现验证者串通合谋、产生错误区块验证结果的情况,从而危害区块链系统的安全性[8]。为了解决验证者串通合谋的威胁,保证区块验证的安全性,当前矿工领导者产生的区块数据可由轻节点充当验证者进行共同验证和审查[9]。文献[10]表明智能手机等边缘设备可以充当验证者参与区块验证。虽然更多的随机轻节点参与区块验证能提升区块验证的安全性,但因为区块验证过程需要消耗算力、带宽等资源,所以需要设计有效的激励机制鼓励轻节点参与到区块链赋能车联网的区块验证中。文献[9]利用契约理论激励轻节点参与区块验证以防止验证节点的内部共谋,但该机制无法及时响应轻节点的频繁变更情况。文献[11]提出斯坦伯格博弈来权衡区块验证中的安全要求、验证时延和成本,但该博弈模型建立在所有矿工已知完备环境信息的假设上,并不适用于轻节点频繁更换、环境信息未知的车联网场景。
针对上述研究工作的问题,本文在文献[11]的基础上,把智能汽车和DPoS共识算法的矿工间交互过程建模成斯坦伯格博弈模型,并由区块链用户(即智能汽车)作为博弈主方提供交易费以促进矿工快速、安全地完成区块的打包、验证。验证者作为博弈从方随机招募一定数量的轻节点提供验证服务并赚取交易费。此外,车辆的高移动性会导致车联网环境动态多变[12],传统的方案并不适用于此类场景,存在效果差、可扩展性弱等问题[13],因此,本文提出基于多智能体强化学习的方案以有效地解决动态多变环境中的区块验证决策问题。并可在环境信息不完备的情况下收敛到接近最优策略,从而最大化区块链用户与验证者的收益,实现高效、安全、可靠的区块验证。
本文的主要贡献如下:(1) 将轻节点引入到基于DPoS共识算法的区块链赋能车联网的数据共享区块验证过程中,保证了区块验证的效率的同时,也提升了区块链用户的满意度。(2) 将智能汽车和验证者之间的交互过程建模成斯坦伯格博弈模型,并通过多智能体近端策略优化算法(Multi-Agent Proximal Policy Optimization ,MAPPO)求解上述博弈过程的纳什均衡解。(3) 与传统Deep Q Network (DQN)方案进行性能对比,并对MAPPO的收敛性能进行了模拟和评估。
1 基于多智能体强化学习的区块安全验证方案
1.1 系统模型
如图1所示,本文考虑的基于DPoS共识算法的区块链网络主要包含以下实体:(1) 区块链用户(智能汽车);(2) 矿工;(3) 轻节点。其中矿工和轻节点在区块验证阶段均为验证者角色[14]。车辆间进行数据共享交易,并定期将生成的交易记录广播到网络中的矿工节点。在DPoS共识算法中,矿工轮流充当区块生产者,每个矿工在一个时间窗口内只能充当一次区块生产者,其余矿工将充当区块验证者角色。具体而言,当前的区块生产者将时间窗口内的合格交易记录放入一个区块中,并将该区块广播给其他矿工进行验证。与PoW等传统方案相比,DPoS中的矿工不需要相互竞争来获得挖矿奖励,矿工群体在完成区块打包和验证任务后,可分得一定奖励(用户交易费总和)。为了防止矿工之间验证合谋,矿工将新区块随机传播给合作的轻节点进行验证,从而保证区块的安全性与可靠性[15]。
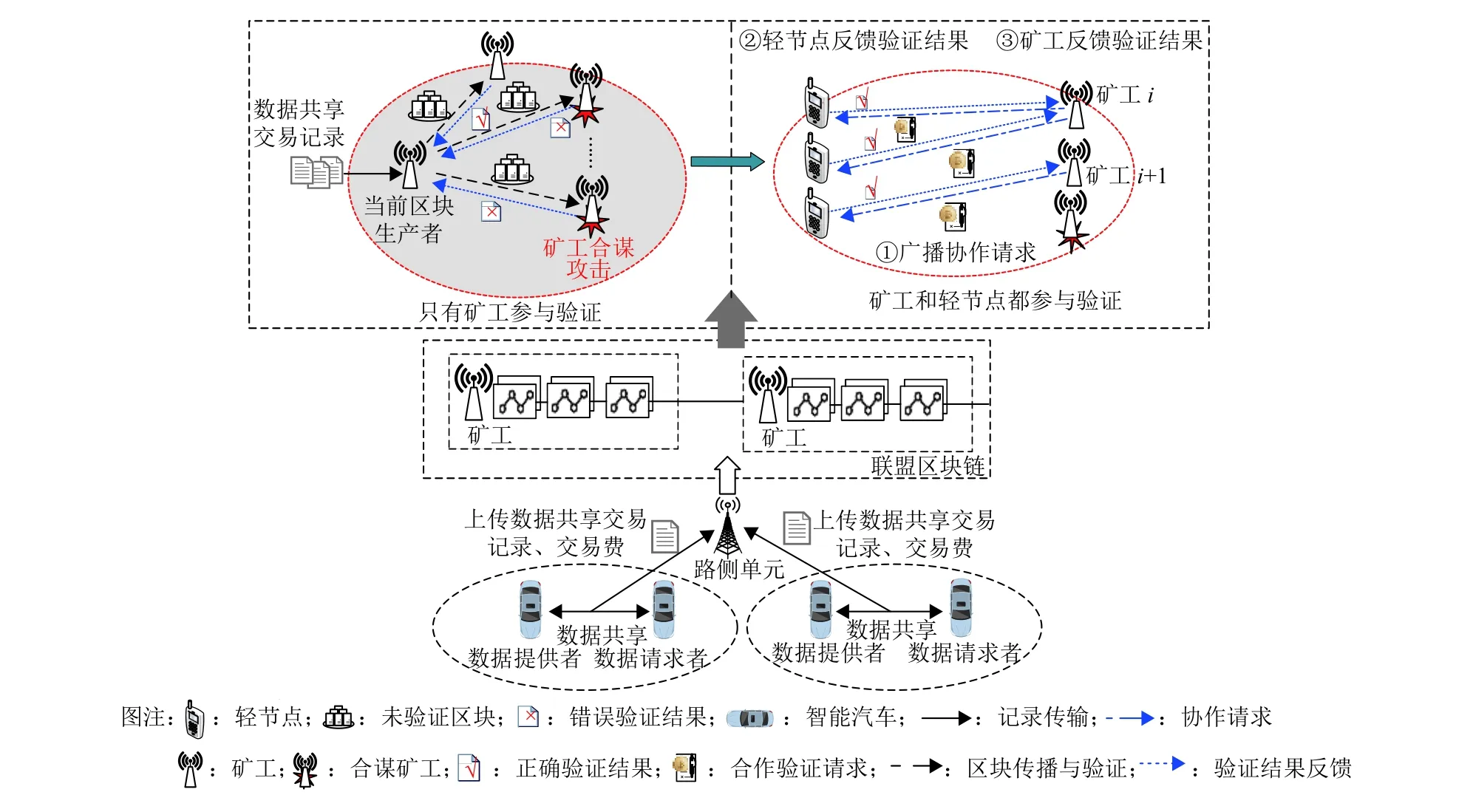
图1 安全数据共享系统模型Fig.1 A system model of secure data sharing
与文献[16-17]类似,基于DPoS的区块链中的每个矿工都根据自己的合作轻节点来分配特定的验证任务。因此,每个矿工都可以根据各自的验证贡献,即合作验证者(轻节点)的数量,从区块链用户那里分享到交易费用f,而矿工和验证者之间也会存在通信成本。轻节点完成区块验证任务后会获得服务奖励,并将验证结果反馈给矿工。
1.2 问题描述




通过多跳中继与远处的验证者进行通信,这也会导致更长的区块传播时间[11]。因此,本文定义了一个安全延迟度量 µi来平衡网络规模和矿工i的区块传播时间关系,µi的表达式为[11]

区块链用户和矿工之间的交互可以表述为一个斯坦伯格博弈,其中区块链用户是主方,矿工是从方[11,22]。在第1阶段,区块链用户设定支付给矿工们的交易费,矿工们根据交易费大小在第2阶段中以最优比例招募验证者。理性的矿工不会以负利润参与挖矿,因此假设区块链用户提供的交易费大于最小值fmin。主、从双方的目标函数为[11]
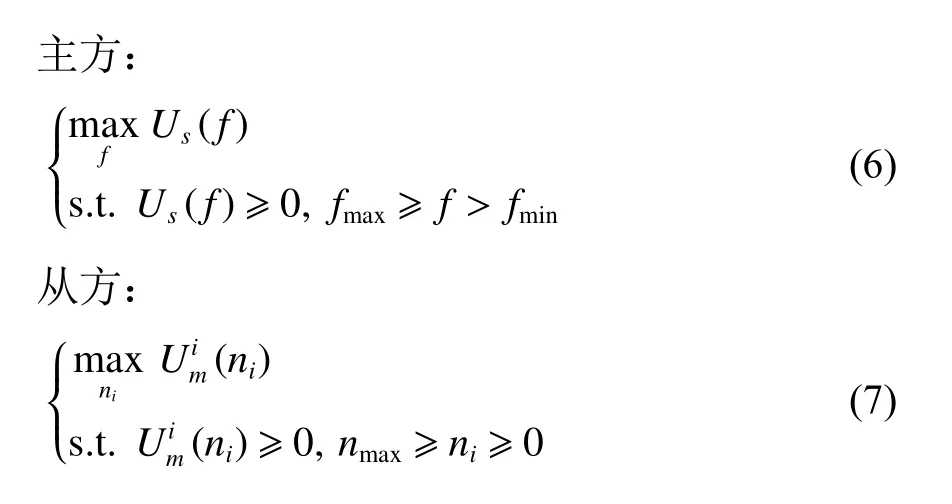
2 多智能体强化学习设计
在本节中,首先介绍多智能体近端策略优化算法,然后利用该算法来解决上述斯坦伯格博弈问题。将多用户参与的斯坦博格博弈转化为局部可观测的马尔可夫决策过程,包括状态空间、观测空间、动作空间、奖励空间和状态转移概率。然后让多智能体在与环境的交互中进行策略迭代与策略提升,找到该博弈的均衡。
2.1 多智能体系统与局部可观马尔可夫决策过程
多智能体系统是环境和环境中的多个智能体组成的集合,其目标是将大而复杂的系统建设成小而彼此互相通信协调的易于管理的系统[23]。在智能体学习过程中,智能体首先会观测当前环境的状态,然后根据自身的观察和策略做出动作,并在环境中获得奖励,最后通过最大化累计奖励的方式来更新自身的策略。具体如图2所示。
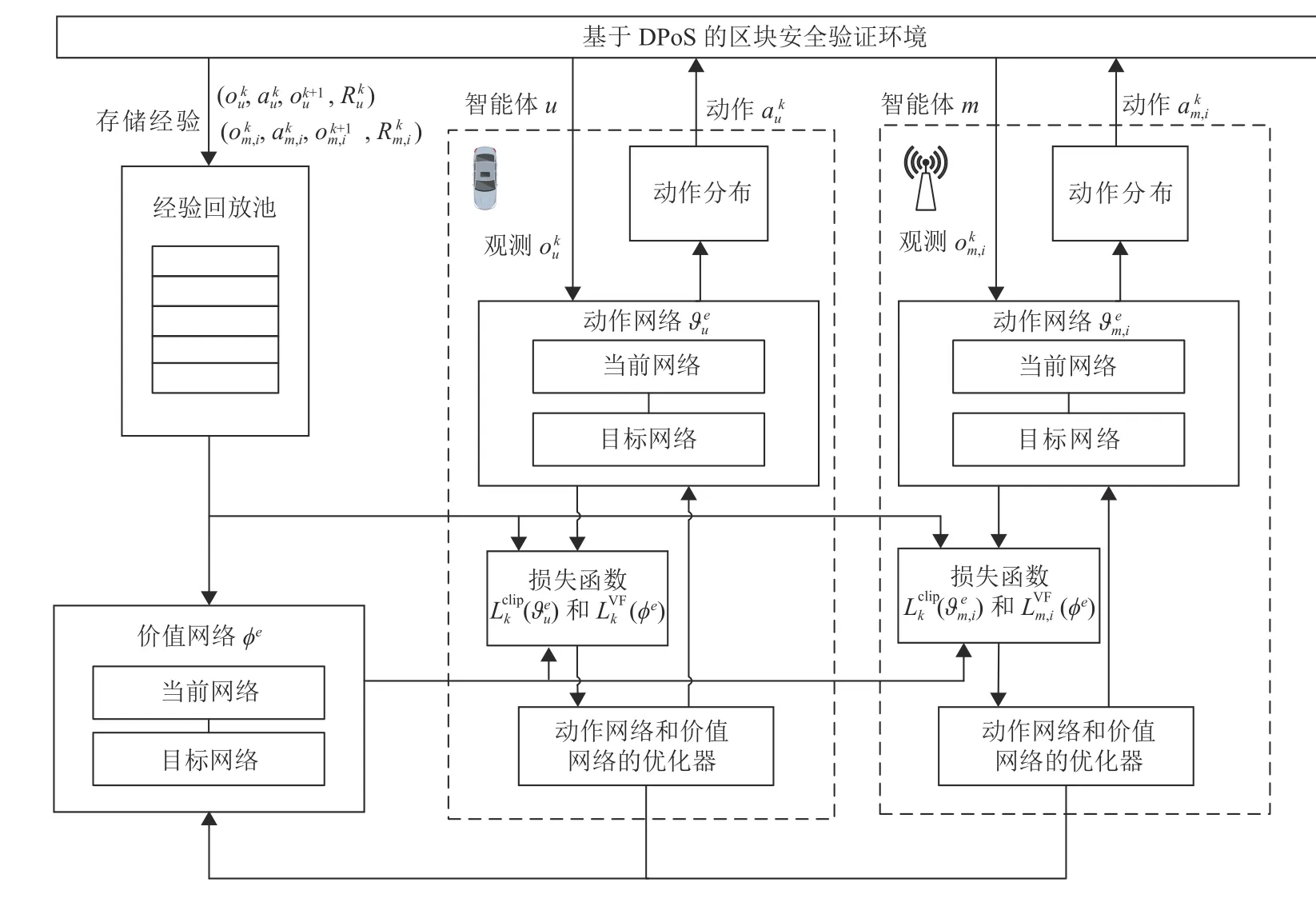
图2 多智能体强化学习框架Fig.2 The architecture of multi-agent reinforcement learning

2.2 策略迭代
考虑到智能体需要同时与环境和环境中其他的智能体进行交互,智能体在做决策时,其他智能体也在采取动作,因此很难得到一个稳定的最优的策略[24]。与此同时,多智能体环境在非平稳状态下容易导致马尔可夫性失效,因此直接在多智能体环境中应用单智能体强化学习很难保证收敛性[25]。MAPPO是PPO(Proximal Policy Optimization)算法应用于多智能体环境的变种,MAPPO同样采用actor-critic架构,不同之处在于critic学习的是一个中心化值函数[26],可以保证更好的收敛性能和样本复杂性。



3 分析与实验评估
本节采用仿真的方式评估多智能体强化学习算法在上述博弈模型中的相关性能。
3.1 仿真设计
本文仿真实验环境是基于gym构建的,具体参数配置见表1。仿真实验运行在配置Intel Xeon CPU@1.6 GHz×12、TITAN X GPU、64 G 内存、Ubuntu 18.0.1系统、Pytorch 1.2、Python 3.6的台式机上。
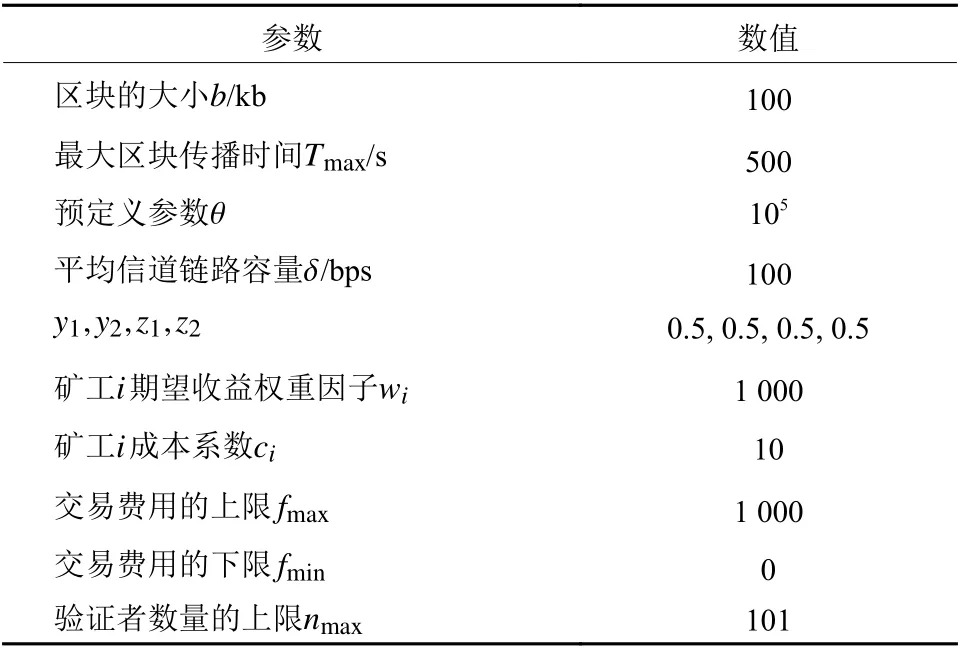
表1 仿真参数设定[11]Table 1 Parameter Setting in the Simulation
在实验过程中,对于所提MAPPO算法,本文采用Adam优化器,学习率(α=β)设置为3×10−4。策略和值网络均采用两层全连接网络,其中每层有64个神经元,采用ReLU激活函数。设置折扣因子γ为0.99,裁剪率ϵ为0.2,GAE截断系数λ为0.95,过去经验轮数L为4,批大小为32。本文采用传统深度强化学习Deep Q Network (DQN)算法作为仿真实验的对比算法,所有智能体的策略网络均采用两层全连接网络,其中每层有64个神经元,采用ReLU激活函数,学习率(α=β)设置为3.5×10−4,折扣因子 γ为0.99,探索率为0.01。同时对上述2种算法进行训练,训练轮数E为100,决策轮次长度K为16。
3.2 实验分析
首先分析所提算法的收敛性能,并进一步研究不同矿工数量对区块链用户和矿工的策略的影响。
在仿真中,选取并观察其中1个区块链用户和3个矿工的实验性能,分别通过MAPPO算法和DQN算法来学习区块链用户和矿工的安全验证策略。图3为DQN算法和MAPPO算法的收敛性能对比,其中fbest为最优交易费,n3,best为矿工3最优验证者数量。MAPPO算法在迭代约1 200次后,算法已基本收敛,这是因为在中心化值函数的指导下,智能体更容易学习到兼顾其他智能体的策略,能同时增加区块链用户的效用和矿工的个人利润。与MAPPO算法相比,DQN算法的性能表现较差,这是因为直接将单智能算法应用到多智能体环境中会导致其无法收敛。
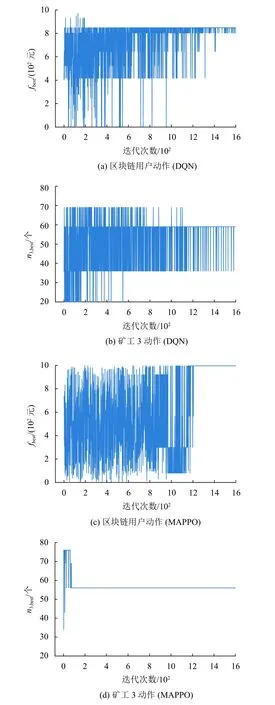
图3 DQN和MAPPO的收敛性能Fig.3 The convergence performance of both DQN and MAPPO
随后,评估不同矿工数量I对平均招募验证者数量navg的影响,并将结果记录在图4中。如图4所示,随着矿工数量的增加,验证者的数量先增加后减少。这是因为矿工的收益由其招募的验证者数量决定,随着矿工数量的增加,矿工们为了获得更大的收益,倾向于招募更多的验证者来提供更大的贡献。但随着矿工数量的进一步增加,通信和招募成本增加的速度大于收益增加的速度,矿工们的收益减少。图4同时也显示了用户交易费对平均招募验证者数量的影响。随着用户交易费用的增加,矿工们倾向于招募更多的验证者,这是因为用户交易费用的增加提高了矿工们的期望收益值。
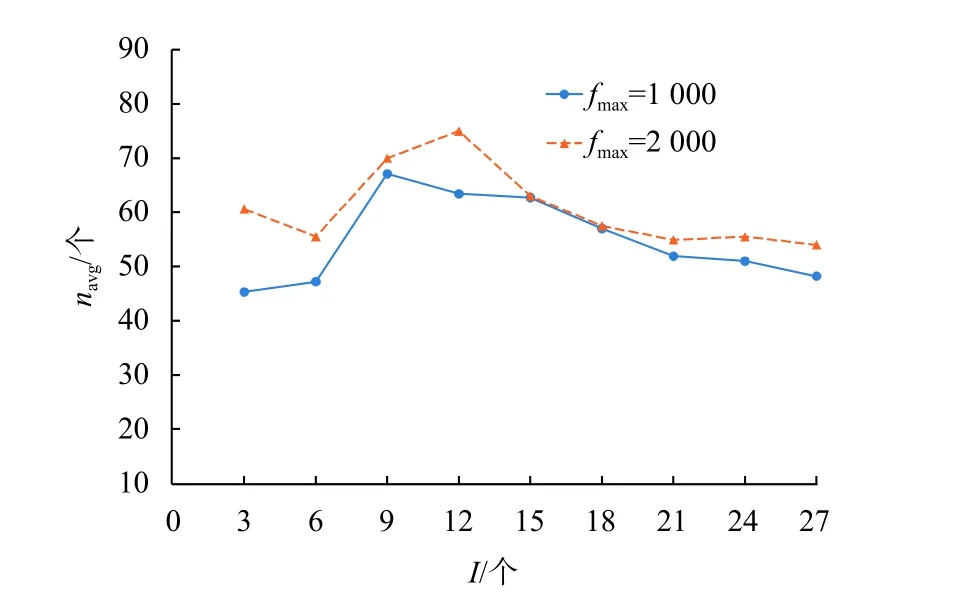
图4 矿工数量对平均招募验证者的影响Fig.4 Impact of the number of miners on average number of recruited verifiers
尽管平均招募验证者的个数随着矿工数量的进一步增加而下降,但总的验证者数量nsum却是在逐渐增加(如图5所示)。这是因为矿工之间的竞争在一定程度上影响了期望回报和招募验证者数量之间的关系,使矿工们依旧有获得回报的动机,这也在一定程度上提高了区块验证的安全性。
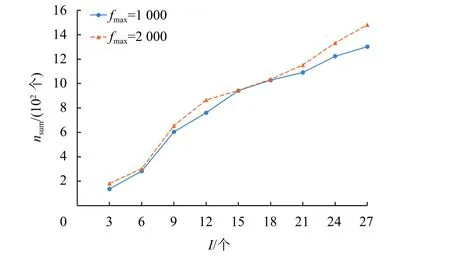
图5 矿工数量对总验证者数量的影响Fig.5 Impact of the number of miners on total number of recruited verifiers
图6显示了总的验证者数量nsum和矿工收益Um之间的关系。由于验证者之间存在竞争,当总的验证者数量增加时,矿工的收益减少。此外,本文博弈模型中的矿工利润比每个矿工招募相同数量的轻节点验证者的方案中的矿工利润高,这是因为每个矿工都可以计算最佳招募验证者数量来获得收益最大化。

图6 验证者数量对矿工收益的影响Fig.6 Impact of the total number of recruited verifiers on the profit of a miner
4 结束语
本文针对基于DPoS共识算法的区块链赋能车联网数据共享的区块验证过程中的共谋问题,把轻节点引入区块验证中,并且将智能汽车和矿工之间的交互建成斯坦伯格博弈模型。通过多智能体近端策略优化算法求解斯塔伯格博弈的纳什均衡解。实验结果表明所提方案可以有效搜索到接近最优的策略,从而保证区块验证的安全性与可靠性。
猜你喜欢
小哥白尼(趣味科学)(2021年4期)2021-07-28 02:23:56
小学生学习指导(当代教科研)(2021年6期)2021-05-23 13:24:38
科学(2020年5期)2020-11-26 08:19:12
马克思主义哲学研究(2020年1期)2020-11-26 07:25:48
科学(2020年6期)2020-02-06 08:59:56
人大建设(2019年12期)2019-11-18 12:11:06
中国盐业(2018年16期)2018-12-23 02:08:34
传媒评论(2018年4期)2018-06-27 08:20:12
现代企业文化(2018年13期)2018-06-09 08:22:21
作文通讯·高中版(2017年12期)2017-02-06 05:56:41
