
质性研究的样本量判断 *
——饱和的概念、操作与争议
2021-12-04 03:06:40谢爱磊陈嘉怡
华东师范大学学报(教育科学版) 2021年12期
谢爱磊 陈嘉怡
(广州大学粤港澳大湾区社会发展与教育政策研究院,广州 510006)
一、背景与目的
在质性研究设计中,一个常被提及的重要问题是“样本量多少才算足够?”在开展数据收集工作时,该类研究往往采用目的性抽样而非概率抽样,更重数据的多样性和丰富性,这让这一看似简单的问题往往无法得到直接回答(Morse,2000;Malterud et al.,2016;Hennink,2017)。不过,大体而言,质性研究者常视饱和为一个可接受的评估样本量是否充分的标准(Morse,2015a),它常被看作是质性研究方法论的必要组成部分。研究者提出,假如在发展理论的过程中做不到饱和,会影响质性研究的质量(Fusch & Ness,2015)。饱和是质性研究人员最常标榜的严谨性保证,业已成为决定抽样策略的“黄金法则”,“常规”与“法则”(Morse et al.,2002;Sparkes et al.,2012;Guest et al.,2017)。
问题是尽管饱和已经在质性研究中获得了近乎正统的地位,但其内涵在中文文献当中依然没有得到系统介绍。这大体和如下四个方面的原因有关。首先,即便是在常被视作理论资源的英文文献中,饱和概念也有多重含义—有些研究者常使用数据饱和(data saturation)的概念,有些则常使用理论饱和(theoretical saturation)的概念,有些则倾向于使用主题饱和(thematical saturation)的概念,三者之间的区别又常语焉不详。其次,在关于质性研究方法论的讨论中,是否需要一系列一般性的评价所有质性研究质量的标准这一问题一直存在争议(Mays & Pope,2000;Caelli et al.,2003;Tracy,2010)。巴伯尔(Barbour,2001)指出,在质性研究中采用一系列标准或可增加研究人员对质性研究效度的信任,推动这一研究范式被更多研究人员接受。但其内在困境是在质性研究内部又可细分为不同进路(approach),毫无批判地接受一系列标准可能适得其反—尤其是当这些标准在本体论和认知论上与质性研究的基本假设有内在冲突时。再次,在汇报研究发现时,大部分情况下研究者只简略提及自身做到了饱和,至于如何做到了饱和(操作)则极少描述,这给后来者加以系统总结和提炼带来了一定的挑战。最后,在当前的中文文献中,对于如何开展质性研究,见解和探索依然非常多样,研究者常常不在同一个意义上使用质性研究概念。例如,为了区分较早期的实践和近期探索,研究者常使用“定性研究”“质化研究”“质性研究”以求相互区别(马凤岐,谢爱磊,2020)。就宏观范式展开的讨论,常常脱离对中观的规范和程序以及细节的技术和方法的审查,饱和问题自然不在讨论之列。
在经验研究(empirical research)中,抽样依然被视为影响研究项目成功与否的关键。质性研究的抽样显然不能简单地照抄量化研究设计的逻辑,因为前者的重心不在于计算数量或对某种观点的认可程度,而在于探求观点的多样性以及某一问题的不同表征(Gaskell,2000),前者也并不特别寻求结论在统计学意义上的可推广性而重在有充分样本以发展理论(Bowen,2008)。样本是否充分又与饱和的概念紧密相连。正因饱和概念在质性研究中的重要地位,本文力图对其进行较为系统的梳理和评述,介绍其概念源头、发展与分类、具体操作(包括在何种情形下如何做到饱和),并讨论在使用这一概念时,研究人员中间存在的一些基本争论。
二、饱和的概念与分类
谈及饱和,研究人员一般追溯其源头至格拉泽和斯特劳斯于1967年出版的经典著作《发现扎根理论:质性研究策略》。在这部著作中,他们提出:
“判断何时停止抽取不同群体样本的标准要视乎类属,亦即类属的理论饱和程度。饱和的意思是社会学家在发展类属属性的过程中,再没有新的数据出现。当他们在一遍又一遍看到相似的情形不断出现时,研究者即可从经验层面确认类属的发展已经实现饱和。这时,他还可以寻求其他办法,收集更加多样化的数据,以确定饱和的判断是基于和类属有关的非常广泛的数据的基础上做出的。”(Glaser & Strauss,1967,p. 61)
格拉泽和斯特劳斯(Glaser & Strauss,1967,pp. 21−44)认为,扎根理论的核心任务在于生成和发展理论—就在特定社会环境中发生的社会过程中生成和发展描述和解释性的理论。在理论层面,这意味着研究者要能够通过发展抽象概念和理论把握具有持久和稳定特性的社会过程,揭示其阶段性特征;在数据分析层面,这意味着以充分的数据发展主题(theme)和理论类属(theoretical category)(清晰地阐释概念,有力地论证概念间关系);在数据收集层面,则意味着通过理论抽样(以涌现理论—阐释概念、论证概念间关系—所需的必要的相似性和差异性为标准抽取样本)充分地收集数据。格拉泽和斯特劳斯深受实证科学研究范式(positivist paradigm)的影响,指出实现理论饱和意味着理论类属发展的“可重复性”和“可验证性”(Morse et al.,2002),但也显示了对质性研究内在特征的深度思考,认为实现理论饱和有助于确保理论类属的“综合”(comprehension)和“完整”(completeness)。另外,就理论饱和的概念,格拉泽和斯特劳斯还提出了一个逐步推进的工作方法,亦即当一个理论类属实现饱和后再去发展其他理论类属,通过这样递进的方式实现所有理论类属的饱和—当然,这一提法本身亦有线性思维之虞。在格拉泽和斯特劳斯的原初定义中,饱和与理论抽样紧密相连,饱和的核心是发展理论类属,理论抽样的目标在于找到最具典型性的样本以帮助发展理论类属。也正是由此,质性研究当中的“抽样”“数据收集”“数据分析”工作才交织到一起,而非呈现出各自分离、前后相继的线性特征—这一点也是质性研究与量化研究的重要区别。总体而言,格拉泽和斯特劳斯提出的饱和概念,其重点主要落在数据中已找到的理论类属的发展程度上,且饱和是决定是否继续收集数据的基本依据。
在格拉泽和斯特劳斯之后,饱和概念在扎根理论的持续影响下进一步发展。例如,厄克特(Urquhart,2013,p. 194)主张在数据分析阶段过程中以是否出现新编码为依据判断饱和,即当数据中反复出现相同的编码、再无新编码出现时就可视为达到饱和状态。由于编码是主题涌现的技术基础,所以亦有研究者提出,当新增数据不能再带来新的主题时,即可判断达到饱和状态(Birks & Mills,2015,pp.85−107;Olshansky,2015,pp. 19−28;Given,2016,p. 135),这有助于研究者获得对研究参与者视角和观点的完整理解。不难发现,上述观点将新编码,尤其是将与之相连的新主题是否继续涌现作为理论饱和的重要判断标准,故后来者又将其称之为主题饱和(thematical saturation),并强调可以其为标准判断是否需要继续分析数据。当然,从编码到主题的思路体现的往往又是演绎进路的研究设计逻辑,亦即在研究的初始阶段,只有明确的研究问题和基本的概念透镜(conceptual lens),而概念的细节和内涵依然要通过分析数据逐步获得,所以这类主题饱和又被称为演绎主题饱和(inductive thematic saturation)。
而在较早时期,斯塔克思和特立尼达(Starks & Trinidad,2007)则指出,相当一部分质性研究设计遵循的实际上是归纳进路的设计思路,在这种情况下,研究者在开展研究设计时即已经有明确的研究问题和既定的理论框架—清晰的概念和对概念间关系的假设,这两者直接指引着后续数据收集、分析和汇报工作的展开。在这种情况下,饱和的核心则在于构成理论的所有要件(包括概念和概念间关系)都能有充分的数据予以支撑。与演绎主题饱和不同,这类饱和强调的是有充分的数据能够说明和支撑理论,它亦关注数据分析工作的充分程度。由于其总体上强调自上而下、以概念框架指导数据分析工作(尤其是编码工作的特征),故而又被称为既定主题饱和(a priori thematic saturation)。
不过,总体而言,无论是理论饱和还是主题饱和,它们的焦点都在理论和主题的发展上,强调理论和数据,编码和概念提炼之间的持续互动—这亦是质性研究区别于量化研究设计的重要特点之一。但后来者依据自身的理解,在扎根理论传统之外提出了数据饱和(data saturation)的概念,其核心是:当研究人员在数据收集的过程中发现新收集的数据与已有数据有重复且显得“多余”时,即可算作达到饱和状态。在工作层面,它具体表现在研究者在访谈过程中开始一遍遍听到与之前的对话相同的内容。如果这样,他们就可以停止收集数据并开始着手分析工作了(Grady,1998,p. 26)。在这一意义上,数据饱和通常与信息冗余这一概念交替使用。不难发现,理论饱和与主题饱和的提法深受扎根理论的影响且一贯强调数据的收集和分析是一个交错互动的过程。但数据饱和的概念淡化了这一认识,认为饱和的重点在数据而不在理论,亦即是否饱和的判断完全可以基于数据是否冗余做出,不必等到判断理论或主题是否发展充分而做出。
从上述对饱和概念发展的系统梳理来看,过去的研究人员一般在三种意义上使用这一概念:理论饱和、主题饱和与数据饱和(见表1)。其中主题饱和又可再分为演绎主题饱和与既定主题饱和(Saunders et al.,2018)。理论饱和与主题饱和都特别关注理论的生成以及数据收集或分析工作与理论发展的交互;数据饱和则视数据的收集和分析为相对独立的工作,尤为关注信息冗余的出现—这貌似赋予了数据收集工作某种客观色彩。

表1 饱和的三种模式
三、饱和的操作I—在何类设计中、在何时饱和?
在操作层面,关于饱和常需回答的问题是:不同类型的质性研究设计是否都需饱和或需要什么样的饱和?可以在何时判断是否实现饱和?究竟多少样本能够保证实现饱和?又有哪些具体的工作方法可以有助于并向读者证明已经实现饱和?
就第一个问题,莫斯(Morse,2015b)指出,所有类型的质性研究都需实现饱和。这种一刀切的提法常引致后来者的批判。批判的立论基础是,饱和概念在本质上涉及“主题发展”,亦即事关跨个案共同“规律”(能够描述一类现象/过程的抽象概念,解释一类现象/过程的理论)的提炼和总结。但某些特殊类型的质性研究设计关注的个体数量通常极为有限,饱和的概念或许并不适用。例如,在口述史和叙事研究当中,研究人员通常关注的是数量有限的个体在陈述自身故事的过程中流露出的线索(strand),而不一定是跨个案的主题(theme)。线索从本质上来说是持续性的、有时间维度的,而主题通常是截面的(Saunders et al.,2018)。在判断数据质量时,口述史和叙事研究较为关注个体叙述的“完整性”—是否和所研究话题相关的故事都有收集到,这显然不同于饱和对“理论充分发展”的追求。另外,在解释现象学分析(interpretative phenomenological analysis)中,关于是否需要实现饱和,研究人员之间的分歧也大于共识。例如,不少研究者指出,解释现象学分析追求的应当是“完整和丰富的个人陈述”,重点不应落在跨个案观点的共性上。范梅南(van Manen et al.,2016)甚至提出现象学研究和饱和没有必然联系。但也有部分研究者认为,这一研究设计应当追求饱和,其内涵应当为“不同个案表述的观点中体现出的共识”(Turner et al,2002)。
莫斯关于所有类型的质性研究都需实现饱和的提法深受后来者批判的另一重要原因是,其并未深究不同类型的质性研究设计是否需要不同类型的饱和这一问题。桑德斯等人(Saunders et al.,2018)指出不同类型的研究设计需要对应不同类型的饱和。他们对研究设计的分类依据主要是基于演绎还是归纳逻辑。桑德斯等人指出,在完全或主要依赖先前设定的编码、主题或其他分析类属来分析数据的演绎逻辑的研究设计中,饱和应当主要是指先前设定的编码和主题等是否在数据中获得充分展现和支持。因而,演绎主题饱和是对应的指导数据分析和判断数据充分程度的依据。而在归纳逻辑的研究设计中,饱和的主要判断标准是指新涌现编码或主题是否和在数据中已找到的既有编码和主题相同,和/或新数据能否有助于生成新的理论洞见。如此,既定主题饱和则是对应的指导抽样和判断数据充分程度的依据。
就第二个问题“可以在何时判断是否实现饱和?”而言,研究者指出其应视研究者采信的具体饱和模式来判断。例如,倘若接受数据饱和的概念,亦即以信息冗余作为判断标准,那么在研究的早期即可找到饱和点。这一思路将数据收集和正式的数据分析过程分开。在何时实现饱和的判断则高度依赖于个体在研究过程中针对自身听到了什么、观察到什么做出判断。听到的和观察到的内容是否和较早时间听到和观察到的有所重复通常可以在数据分析工作正式开始之前—亦即在编码和发展理论类属之前做出(Saunders et al.,2018)。问题是,由于此时理论发展可能尚处初始阶段,个体判断极有可能失于肤浅。另外,将理论发展工作和数据收集和分析工作割裂,也不符合质性研究范式一贯主张的在理论上坚持螺旋上升、在数据收集上保持开放、在理论和数据两者的关系上强调交互的特性(Glaser,1978,pp. 124−126)。
倘若接受演绎主题饱和的概念,即以是否出现新编码和新主题作为判断是否达到饱和的标准时,对饱和的判断时间同样可能比较早。尽管这一思路将数据收集和数据分析过程视为交织展开的过程,但如果将关注点放到是否有“新”之上,极易使研究人员忽视质性数据的其他重要特性,例如“多面”“深度”“入微”等。此外,在质性研究中,理论类属的发展总是一个螺旋上升的过程,早期既定编码极有可能随着研究的不断推进发生调整,此刻判断“不新”的数据极有可能在下一刻“新”起来。因而,太过关注是否出现新编码和新主题,是“搞错了方向”(Hennink et al.,2017)。如果能够秉持这样的认识,对饱和的判断同样可能较晚—到数据收集工作稍晚的阶段。倘若接受理论饱和或既定主题饱和的概念,理论类属的特征是否得到了充分挖掘、理论建构是否能得到充分证明(概念的内在维度得到充分说明,概念间关系得到充分阐释)便是判断饱和是否实现的重要标准(Strauss & Corbin,1998,pp.143−150)。如此,对是否实现饱和的判断,在时间上也会比较晚。
四、饱和的操作II—饱和与样本量
在所有就饱和问题展开的论述中,样本量大小的讨论都占据了重要的位置(Hennink et al.,2019)。与量化研究不同,一般而言,质性研究遵从目的性抽样的逻辑。研究者选择样本的目标在于选择合适的最具生产性的样本以有效地回答研究问题和发展理论。例如,在扎根理论研究中,理论抽样的基本逻辑是,以早期访谈中涌现的理论为指引选择后续样本。早期的访谈是开放式的、旨在初步发展理论的深度访谈,但随着研究的推进和理论雏形的涌现,后续的访谈逐步变为半结构式的,旨在探索理论类属,检验理论类属间关系,寻找否证并解释这些案例为何“例外”。在这种逻辑下,后续访谈参与者的选择都是按需而来的,被选中的个体要能够提供与理论发展相关的充分的信息。这样,理论发展和样本选择便呈现出回环往复的特征—这是质性研究不同于量化研究另一重要特征。在扎根理论之外,研究样本的选择基本依照类似的逻辑—最有生产性、最有利于理论生成。最大化多样性抽样(maximum diversity sampling)、配额抽样(quota sampling)、例外抽样(deviant sampling)、典型个案抽样等,无不如此。也正是由于这一逻辑,合适样本量的判断即在很大程度上受制于每个“个案所能提供的信息的完整性”“访谈的质量”以及“访谈对象的差异和多样性”等,而非样本的绝对数量(Guest et al.,2006)。因此,在研究开始前就难以判断到底需要多少样本(Kerr et al.,2010)。
当然,在大部分情况下,当科研人员申请不同类型的科研基金时,一般会被预期提出可能的样本数量—这是科研人员必须面对的现实要求。另外,不能预估样本也可能带来研究伦理方面的质疑—研究样本过大,极有可能导致公共研究资助以及研究参与者时间和精力的浪费;研究样本过小,带来不可靠的结论,也极有可能导致同样的问题(Francis et al.,2010)。
基于这一问题本身的复杂性,稍早的研究一般不对可达成饱和的样本量大小做具体讨论,而只提供指导性的抽样标准(Mason,2010)。但随着质性研究范式的不断完善,在部分专门的教科书和论文当中,科研人员开始基于长期的实践建议可能的样本量范围(range)。例如,贝尔托(Bertaux,1981,p. 35)在《传记与社会:社会科学中的生活史研究》一书中就质性研究中一般可采纳的样本量大小提出的建议是:15个研究参与者是最小可接受的数字。在由邓津和林肯于1994年出版的经典著作《质性研究手册》中,莫斯专门撰文指出,人种志或人类学研究的样本可采纳的建议值是30-50个(Morse,1994,pp.220−235)。伯纳德(Bernard,2000,pp. 143−187)在2000年出版的《社会研究方法》一书中则建议人类学研究的访谈样本可以是在30-60个之间。就扎根理论与现象学研究来说,莫斯(Morse,1994,pp.220−235)和克雷斯维尔(Creswell,2013,p. 199)也先后在编著《质性研究手册》以及《质性探索和研究设计:五种传统》中提出了可参考的样本量(见表2)。
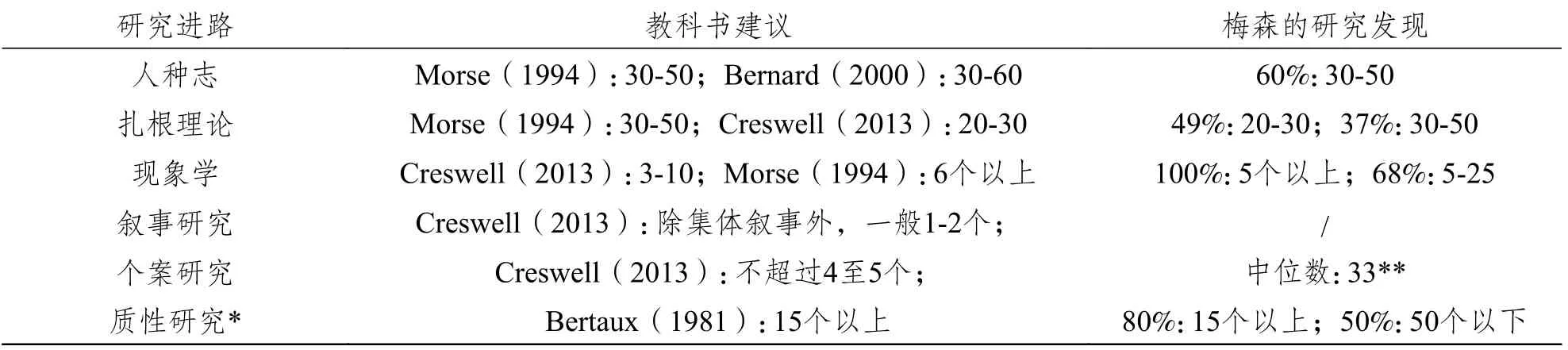
表2 质性研究中的样本量:建议与实际
为了解研究人员在开展质性研究的过程中实际的样本量选择情况,梅森(Mason,2010)在2009年对被收录入《论文索引—大不列颠和爱尔兰大学高等学位论文综合目录》中声称使用了质性研究设计的共560篇博士论文进行了分析,并分类汇报了这些论文的样本量范围。例如,他发现:在行动研究中,最大样本是67,最小为3,平均样本数为23;在案例研究中,最大样本是95,最小为1,平均样本数为36;在扎根理论研究中,最大样本为87,最小为4,平均样本数为32;在生活史研究中,最大样本为62,最小为1,平均样本数为23;在现象学研究中,最大样本是89,最小为7,平均样本数为25。
由于篇幅有限,梅森论文当中汇报的质性研究在声称的进路上又太过庞杂未做再分类—共26种,我们选择其中常见的几种—人种志,扎根理论,现象学,叙事研究,个案研究,与教科书建议做简单对比(见表2)。在未声称具体研究进路、只表明自身所做的研究为质性研究设计的博士论文中,80%的选择了15个以上样本(与贝尔托所建议的数量基本吻合),50%的选择的样本在50个以下。总体而言,实际抽样与教科书的建议值较为接近。在声称采用了人种志、扎根理论和现象学的研究中,实际选择的样本数也几乎与教科书的建议值相近。
除上述教科书所建议的标准以及梅森的研究所呈现的实践之外,还有部分研究人员就可以达成饱和的样本做了一些不同的判断,但总体而言,在大部分情况下,建议的样本范围都在6至25之间。例如,盖斯特等人(Guest et al.,2006)提出了“6的倍数”这一指导原则。他们指出,在参与者较为同质化的情况下,94%的高频编码会在首次接受访谈的6个个案中出现,97%的会在首次接受访谈的12个个案中出现,因而,可以在每6个访谈结束后进行编码和主题检查,判断饱和情况。康斯坦丁努等人(Constantinou et al.,2017)则声称所有可能的主题都可以在访谈前7位研究参与者后获得。安窦等人(Ando et al.,2014)则认为12个访谈足以提供研究者所需的所有主题。哈咖曼和伍提驰(Hagaman &Wutich,2017)依据自身的研究经验指出,对于相对同质、特定环境中的群体来说,要达成饱和,16个以下个案即足够,不过针对跨文化群体的研究,往往需要20至40个个案才能达成饱和。韩宁柯等人(Hennink et al.,2017)则认为25个访谈足够达成饱和。
需要指出的是,不宜对上述教科书和研究就样本量所做的建议做过度解读—将其奉为圭臬。在质性研究中,对样本数量的预估要考虑的因素复杂而多样。除了要考虑最有生产性、最有利于理论生成与发展这一原则外,还要考虑的其他因素,包括:“研究的目的”(假如研究的目的是探究经验的本质,小样本应该可以有助于达成饱和)(Onwuegbuzie & Leech,2007)、范围,“研究设计的类型”(Morse,2004),“研究对象的同质性程度”(高度同质性的样本,小样本同样可以有助于达成饱和),“选择样本的标准”,具体的“数据收集方法”,研究人员的“研究技能水平”(Ritchie & Lewis,2003,p. 84)(假如是初学者,未必能够在较早阶段即能通过较小样本发展理论,达成饱和)与“精力”(Bernard,2000,pp.143−187),工作强度(Roy et al.,2015),以及“预算和资源”(Mason,2010)。
此外,需要注意的是,在样本量大小和饱和之间没有简单的线性关系—并非样本量越大,越有助于实现饱和。威睿等人(Wray et al.,2007)在针对样本量大小和新主题涌现之间关系的研究中即发现,在实际访谈和编码工作中,一直增加接受访谈者数量总会带来新的编码和主题—即便是人数增至200以上时依然如此。不过,他们也指出,新主题的出现总体呈现递减的规律,亦即随着访谈人数的增加,实际增加的新主题数会越来越少(见图1,源自Wray et al.,2007)。威睿等人的研究有两个方面的深层含义。首先,在质性研究中,单纯以是否出现新编码和新主题为标准判断饱和的实现情况不太恰当,这印证了本文上述所提到的内容;其次,暂停数据收集工作亦有现实考量,在新编码和主题涌现递减、每增加一个新编码和主题所需访谈的人数过多的情形下,投入过度物力、财力与人力也不太恰当。例如,威睿等人提出,在已有参与者为25人的情形下,新增一主题大约需要增加1位参与者即可,但当已有参与者人数达到400时,新增一主题大约需要增加108位参与者(见表3,源自Wray et al.,2007)。

表3 新增1主题需新增参与者数
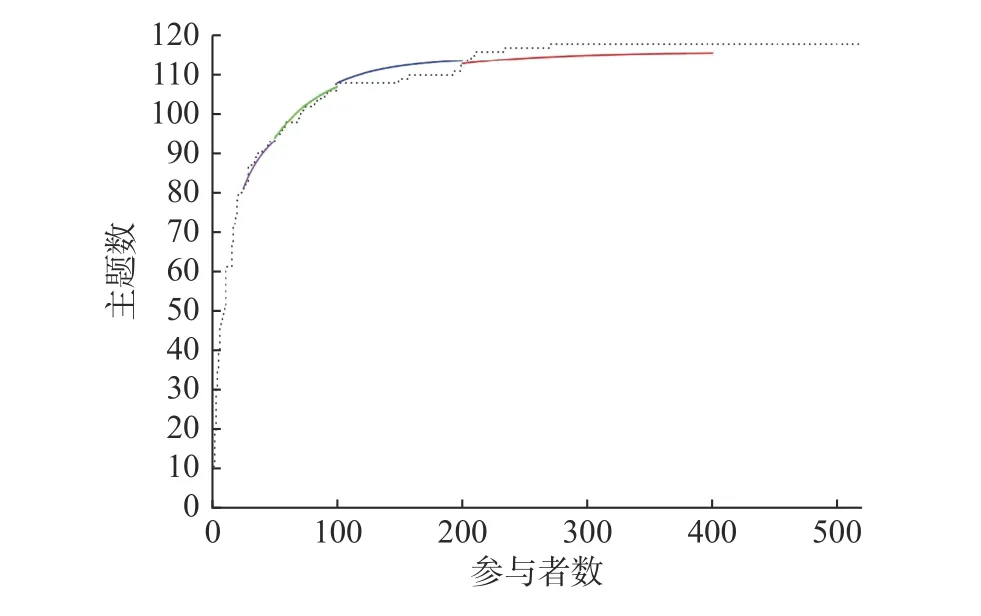
图1 参与者与主题数
五、饱和的操作III—记录与判断饱和的三种具体方法
谈及饱和,研究者尤为关注的另一个问题是可以通过哪些方法记录并对其进行判断。科尔等人(Kerr et al.,2010)指出,在大部分情况下研究人员都不会就自身如何在研究中做到了饱和做出详细说明。其他研究人员也有类似发现(Bowen,2008;O’Reilly & Parker,2012)。例如,卡尔森和格朗东(Carlsen & Glenton,2011)曾对220个质性研究进行述评,他们发现:这些研究中的83%都声称自己在决定抽样时用到了数据饱和作为标准,但却并未就如何评估达到饱和做出说明。当然,具体说明如何判断饱和并以其为标准决定实际抽样的确有其内在矛盾—因为饱和只有在数据收集的过程中才能操作,但研究计划却要求在研究开展前即对样本量做出预估。因而,正如哈默斯利(Hammersley,2015)所言,这种内在矛盾的根源之一在于“研究体制”。但如上文所述,如果将研究计划中的样本量预估看作是一个范围的概念或者约数,那么这种内在矛盾或可部分地忽视。
就如何记录并判断饱和,过去的研究主要提供了三种方法:结构性编码本、饱和表以及概念深度量表。其中,结构性编码本的设计重在记录编码和主题的出现和变化(见表4)。在一个典型的结构性编码本里,研究人员需要从分析第一个案例时即适时记录编码的出现和发展情况,并对编码下简要定义(Kerr et al.,2010;Roberts et al.,2019),就如何在数据分析过程当中使用这一定义做明确说明(操作性定义),再具体说明在数据分析过程中哪些情形适用或哪些情形不适用(例如,有些案例可能更适合作为此处而非他处的例证),并在最后给出明确的例证(详见表4案例给出的结构)。使用结构性编码本的优势有:首先,由于能够适时记录编码的出现和发展情况,结构性编码本给予了研究人员准确判断新编码是否持续出现的依据—尤为适合采纳演绎主题饱和与数据饱和标准的研究;其次,由于其就定义、定义适用或不适用的情形都做了明确界定,这非常有利于小组协作,特别有利于团队成员各自独立工作开展交叉检验从而提升数据分析的透明度和质量;再次,由于能够全程记录,编码的修订也能够及时得到体现,有助于研究人员掌握主题发展的情况和脉络;最后,结构性编码本的使用可与数据分析过程高度结合,这使得这部分工作可以嵌入数据分析过程,与后者同时进行(Guest et al.,2006)。

表4 结构性编码本举例(Roberts et al.,2019)
饱和表是研究人员开发的另一类记录和判断饱和情况的工具。较为常见的饱和表有两类。第一类饱和表被称为主题饱和表,主要形式为由不同个案和编码、主题数记录等条目组成的交叉表(见表5)。它有助于研究人员从分析第一个个案起即记录每个个案中呈现的编码数、主题数,与之前的个案分析重复的主题数、新出现的主题数以及已分析的个案中的主题数总计,当然,研究人员也可以由前述数字而计算出每个个案中涌现的主题数的覆盖率(亦即其占最终总主题数的百分比情况)。通过主题饱和表,研究人员可以直观地判断出,在分析至多少个案时,新的主题不再出现—亦即达到饱和状况(可参考表5第5列开始出现数字0的节点),也可以有助于他们判断不同个案所含信息的丰富程度。第二类饱和表可被称为编码饱和表,主要形式为由编码和个案条目组成的交叉表(见表6)。它有助于研究人员从分析第一个个案起即记录编码首次在某个具体个案中的出现情况。在编码和个案条目对应的交叉位置,研究人员既可以以星号记录编码的首次出现时间(第几个个案),也可以以注的形式做其他适当说明(Kerr et al.,2010)。编码饱和表的主要用意在于,在记录完所有编码首次出现的个案节点后,其后的空白即表示已达饱和状态—所有主题都能得到数据支持。
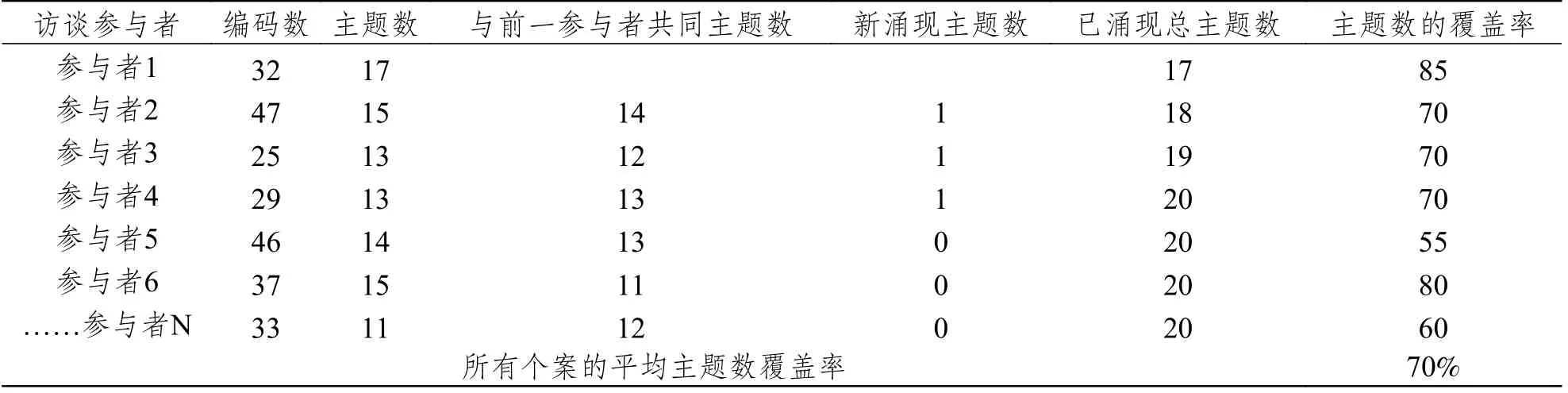
表5 主题饱和表举例(Constantinou et al.,2017)

表6 编码饱和表举例(Kerr,Nixon & Wild,2010)
饱和表的制作虽然也与数据分析工作同步进行以求准确记录编码和主题的发展情况,但与结构性编码本不同,它的制作是对数据编码工作的再加工。饱和表较易制作,但其受质疑的地方主要在于,质性数据的分析往往是一个回还往复的过程—在数据分析的一开始设定的编码和主题可能在后期会得到不断修正。因而记录的实际编码数和主题数以及新编码出现的时间等信息都需要不断修正,这增加了记录和判断饱和工作的复杂程度。不过,也正是基于这一考虑,在采纳既定主题饱和模式特别强调既定主题能够得到数据有效支撑的研究中,使用饱和表要更为合适。
对于结构性编码本和饱和表,克尔等人(Kerr et al.,2010)颇有微词。这两者或能够把握数据的广度和时间维度,但对于质性研究一贯强调的数据的深度却未能予以展现。在坚持扎根理论路径、没有既定概念透镜或理论框架、采信理论饱和模式的情况下,结构性编码本和饱和表的使用也稍为困难。尼尔森(Nelson,2017)认为在判断研究的质量和采样是否充分时,应当放弃饱和概念,回归扎根理论传统,强调“概念深度/密度”和“理论类属的丰富程度”,甚至认为应当以“概念深度”概念替代“饱和”概念。不过,总体而言,他的概念深度是对饱和概念的升级。其所开发的概念深度量表亦有助于我们判断一项研究的饱和状况。尼尔森主张应当围绕五个方面来判断一项研究的概念深度:
(1)范围:数据中有一系列证据能用来阐释概念。
(2)复杂性:概念是由主题和概念组成的网络的一个部分,它们以复杂的形式相连。
(3)微妙性:研究者能够理解概念的微妙性,能够对其含义的丰富性做建构性解读。
(4)回应性:概念可以回应所在研究领域的既有文献。
(5)效度:概念本身可以经得起外部效度的检验。
在其开发的概念深度量表中,尼尔森以这五个维度实现程度的“低—中—高”判断具体研究的概念深度状况(见表7)。例如,他指出,就“范围”指标,可以以编码的出现频次和多样性、数据来源的多样性加以判断,如果少有例证支持核心概念、数据类型单一则范围指标得分低;如果数据中有大量例证支持核心概念且数据类型多样,则范围指标得分高。同理,如果编码树、观点图和编码矩阵显示的编码皆为描述性、编码间的联系过于简单、分析性少,则复杂性指标得分低;如果概念网交错,抽象的理论类属涵盖了一系列编码和概念,则复杂性指标得分高。如果备忘录或世界观图中的概念语言看起来毫无问题且单向,则微妙性指标得分低;但如果概念语言理解起来丰富,甚至略显模糊和多面,则微妙性指标得分高。如果涌现的理论与既有文献和理论框架关联低,无法呼应后两者,则回应性指标得分低;反之,如果涌现的理论与既有文献有实质性对话,与其他理论框架有联系,甚至能带来变体和创新,则回应性指标得分高。如果研究发现理论化程度低,内向,对研究参与者或其他相似背景下的人不适用,则效度指标得分低;如果研究发现在抽象层面有理论化,外向,对那些在同一或相似社会环境下的人而言亦适用,则效度指标得分高。通过这五个指标的综合判断,研究人员即有可能把握具体研究的饱和状况。需要指出的是,尼尔森所提供的概念深度量表,相对于结构性编码本和饱和表更加脱离具体的数据分析过程,更加依赖研究者在数据分析工作结束后就饱和状况依指标做逐项判断。但较之于后两者又更加考虑理论的生成和发展的状况,尤为适合采信理论饱和模式的研究。
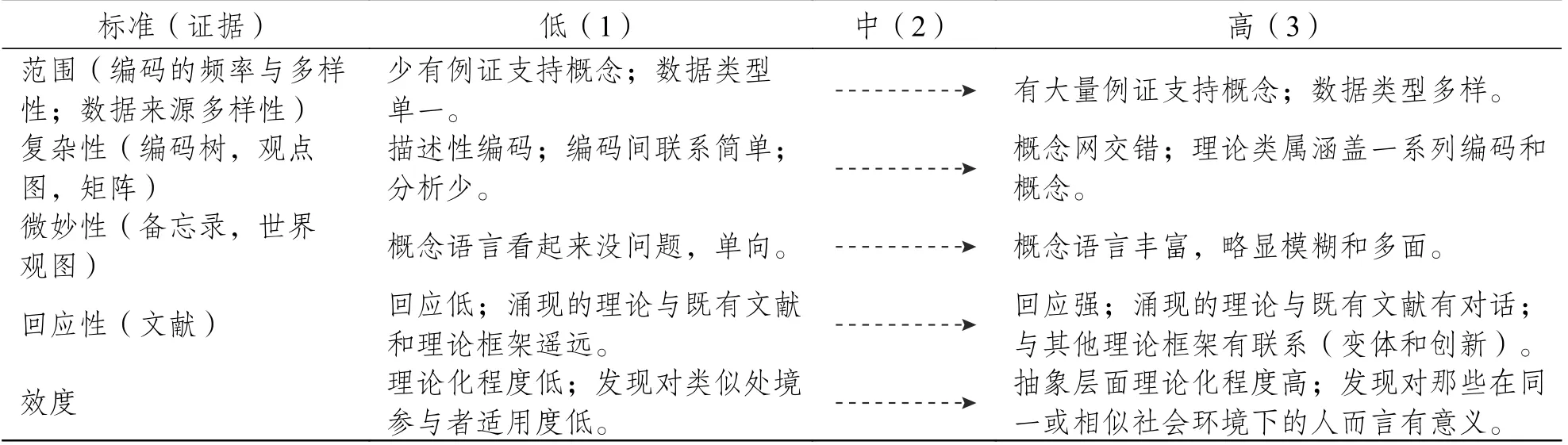
表7 概念深度量表举例(Nelson,2017)
六、争议与小结
当前,在质性研究人员中间,对饱和依然存在不少争议。这些争议既事关概念,也事关操作,既事关应然,也事关实然。对这些争议进行初步梳理并加以分析,当有助于研究人员更好地认识饱和概念并思考如何改善其操作。
围绕饱和的第一个争议存在于概念层面:在性质上,饱和到底可算一次“事件”还是一个“过程”?在大部分情况下,当提及饱和概念时,研究人员普遍会将其与“点”联系起来,意思是,饱和在本质上是非连续性质的“事件”(Jassim & Whitford,2014)。传统上,“没有新主题”“没有新编码”等提法和对理论类属“完整性”“全面性”与“充分”的追求的表述都易使研究人员认为饱和是一次事件—当达到饱和“点”后,新主题和新编码都不会再出现,作为理论生成和发展基础的理论类属也获得了完整性和全面性。但不断有研究人员就此认识提出质疑,指出饱和在本质上应是一个过程—而且是未尽的过程。例如,斯特劳斯和科宾(Strauss & Corbin,1998,pp. 325−326)在论及饱和时提到,最好将《发现扎根理论:质性研究策略》中理论饱和的概念理解为一个“度”的概念。尼尔森(Nelson,2017)曾直接指出,饱和应当是一个连续体和过程,对“点”或者“完整性”的追求都是对饱和的错误的静态的理解。我们认为,至少有两点理由可以使我们相信“度”而非“点”亦即“过程”而非“事件”更能把握饱和的本质。首先,正如在前文的梳理中所提到的,主题的涌现不会突然停止,只要一直推进数据收集工作,新的信息会持续出现—只不过边际效益会一直递减。新料不可避免,只是进展有度—当新数据无法持续带来与理论类属发展相关的新料时,我们可以考虑暂停/终止数据收集工作(Strauss & Corbin,1998,p.113)。其次,研究者通过生成和发展理论获得对社会过程的深度理解。理论分析工作不会突然变得“丰富”“富有洞见”,只会变得“更加丰富”“更有洞见”。这与质性研究的认识论基础有着密切关联—理论的意义不是不证自明的,它依赖研究者不断地发掘,理论本身是建构性的和情景化的(Low,2019)。就此而言,新意义总可挖掘,理论可以变得更加丰富、更有深度。这也是为什么后来者主张以“理论充分度”或“概念密度”或“概念深度”来取代“饱和”的重要原因(Dey,1999,p. 257;Nelson,2017)。
围绕饱和的第二个争议依然存在于概念层面:饱和本质上是一个“数量”概念还是一个“质量”概念?长久以来,在论及饱和时,研究人员较为关心的核心问题还是两个层面的数量:首先,数据收集时的样本量—多大的样本合适?其次,数据分析时编码和主题的新增情况—是否没有新增编码和主题出现?也正是因此,不少研究人员指出,饱和本质上是个数量概念,在研究饱和时,他们将重心放在编码和主题涌现的数量及其随样本量增加而发生变动的基本规律这一问题上(Hancock et al.,2016)。但布尔迈斯特和艾特肯(Burmeister & Aitken,2012)则指出,饱和本身跟数据的深度有关。奥莱理和帕克(O’Reilly & Parker,2012)指出饱和首要的关切应当是信息的充分程度。富士和尼斯(Fusch & Ness,2015)更是强调,数据本身的丰富性—多层、错综、细节和入微才是饱和要更为关切的。我们认为,应当重归饱和概念的理论源头:大样本或者小样本都不能保证饱和,样本量多并不等于数据充分,也没有一个适合所有类型质性研究的样本量标准。样本的选取更应看重数据的质量而非数量、要有利于理论的生成和发展—数据的充分、丰富与深度都是针对理论发展需要而言的。即便是将饱和落在样本层面,选样的基本逻辑也应当是所选参与者带来的信息能够充分地表征研究问题(Fossey et al.,2002;Morse,2015b)。即便考虑数量,其基本目的也在于充分地展现各种类型、变体而非让其大到带来重复性的信息(Morse,1994,pp. 220−235)。
围绕饱和展开的第三个争议存在于实践层面:饱和到底是“先见之明”还是“事后诸葛”?不少机构已经关注到了质性研究和量化研究在抽样时的差异—不仅体现在是否采用概率抽样、追求数据上的可推广性上,也体现在何时能够判断样本量大小需要(量化研究通常在研究设计阶段就要决定样本量,而质性研究一般则是在数据收集过程中形成对合适样本量的判断)。但正如哈默斯利所言,“先见之明”既是“研究体制”的要求—资助者通常要求研究人员在撰写研究申请时就样本和成本做出预估,也是实证范式影响下研究人员对研究流程的固有认识—对于研究中的样本量应当有一定的“预见性”,它有助于研究人员知道何地、何时可以停止收集样本,这有助于降低研究中的“不确定性”。不过,更为常见的情形是,大部分研究者的实践是“事后诸葛”—意即研究者声称在已达理论饱和的情形下,再继续多开展数据收集工作,有意在达到所谓的饱和之后继续抽样,以证明自身抽样决定的合理性(Tutton et al.,2012;Naegeli et al.,2013;Jassim & Whiteford,2014;Vandecasteele et al.,2015)。由于对达成饱和的细节不做交代,这让饱和看来只是一个研究的合法性修辞。我们认为,饱和本身应当是具体的方法论实践,在研究的计划阶段,就样本量的范围做适当预估是可行的,也是必须的。在《发现扎根理论:质性研究策略》一书中,格拉泽和斯特劳斯也指出,假如没有能力计划研究—对样本量、数据收集和分析所需时间做出预估—会是研究计划和研究伦理中的重要缺陷(Glaser &Strauss,1967,p. 61)。但亦须指出,在质性研究中事先预估的样本量是个范围概念,也并不代表对何时达至饱和的准确预计,具体样本量的决定要等到数据收集工作开始,对饱和有所判断时才能做出。
由于契合质性研究的本体论和认识论基础(Constantinou et al.,2017),饱和业已成为判断质性研究质量的重要标准,被当作是质性研究中样本选取的重要依据(Vasileiou et al.,2018)。美国心理学会公共传媒委员会工作小组制定的《质性研究文章汇报标准》更是建议研究人员就停止收集数据的原因和达至饱和的过程做出说明(Levitt et al.,2018)。这样,在研究过程中清晰记录和判断饱和状态并对其进行说明逐渐成为英文发表的标准要求之一。中文质性研究也应当重视饱和概念,并对取得饱和的过程进行清晰陈述,这有助于提升其规范性、透明度、质量和认可度。
猜你喜欢
内蒙古统计(2021年4期)2021-12-06 02:49:20
河池学院学报(2021年1期)2021-07-10 05:14:02
英语文摘(2019年2期)2019-03-30 01:48:40
测控技术(2018年4期)2018-11-25 09:46:52
中华手工(2018年6期)2018-07-17 10:37:42
上海精神医学(2017年5期)2017-11-29 06:03:10
新课程研究(2016年2期)2016-12-01 05:52:55
天津护理(2016年3期)2016-12-01 05:39:52
中国民族医药杂志(2016年6期)2016-05-09 08:52:48
中国卫生(2015年7期)2015-11-08 11:09:50
