
集中核算模式下电力企业用户计费档案管理研究
2021-12-04 01:53:36黄公跃林思远董佩纯付婷婷薛冰
中国科技纵横 2021年19期
黄公跃 林思远 董佩纯 付婷婷 薛冰
(深圳供电局有限公司客户服务中心,广东深圳 518000)
0.引言
电力企业的用户计费档案不仅包括的信息内容繁多,且随着不同区域的用电需求不断变化,用户计费档案不仅数量上与日俱增,其中的信息也不断出现新的管理重点[1]。为档案管理工作带来了新的挑战,如何实现对档案的准确分类,为后续的应用和档案提取提供更加快速的定位条件成为现阶段电力企业用户计费档案管理工作中的重点[2]。由于电力企业一般以区域范围为经营活动开展的基础,需要通过对整体用电数据进行分析,为之后的发展决策提供参考,因此大多采用集中核算的模式对数据进行动态分析,这种核算模式的效率与用户计费档案资源管理的可靠性直接相关,由此可以看出,加强电力企业的用户计费档案管理具有十分重要的现实意义[3]。不少专家学者也就用户计费档案管理这一问题进行了相关研究,其中,文献[4]提出了以信息内部之间逻辑关系为基础的档案管理方法,为档案管理提供了一种新的思路,但其逻辑开发阶段的时间成本较高,因此对于部分档案规模较大的单位并不适用;文献[5]借助大数据在信息计算中的优势,对档案信息进行分类,但在实际档案管理中,数据是多样化的,需要对其管理目标进一步优化。
基于此,本文提出集中核算模式下电力企业用户计费档案管理研究,利用集中核算的信息结果,实现对信息的融合处理,以此为基础,实现对档案的准确分类,并通过实验验证了所提方法在用户计费档案管理方面的优越性能。
1.电力企业用户计费档案管理方法
1.1 档案预处理
在对档案进行管理之前,考虑到集中核算产生的数据结果较多,且规模较大,导致用户计费档案中的信息具有多样化的特征,在表现形式和信息类型上不具有统一性,因此,本文采用主成分分析法(Principal Component Analysis,PCA),对集中档案中的数据集进行数据预处理,其主要是将具有相关性的不同维度数据投射到同一数据维度中,为后续的用户计费档案管理提供保障。
假设集中核算得到的待管理档案的信息维度为a×b,档案数量为n,首先需要计算出档案信息的协方差矩阵,将n档案分别表示为[D1,D2,…,Dn],那么档案信息的平均维度可以表示为:

其中,λn表示档案信息的维度,γ表示信息维度的最大差值。通过式(1)将用户计费档案信息归一化,并按照极端得到的λn值的大小,将用户计费档案划分到不同的聚类空间中,γ即为距聚类的最大中心距离。
需要注意的是,实际的用户计费档案资源聚类中心制定标准是不唯一的,可以根据电力企业的管理需求,以不同的指标作为中心。这样就为用户计费档案的个性化管理提供了良好基础。
1.2 用户计费档案特征提取
实现对待分类档案的归一化处理后,需要对用户计费档案特征进行提取,并将其作为用户计费档案分类管理的依据。为此,本文采用关联规则特征分布式挖掘方法,通过计算用户计费档案对目标特征的适应度,判断其聚类结果。
首先,建立了用户计费档案信息特征统计分析模型,其表示为:

其中,T(*)表示用户计费档案信息特征统计模型,k表示目标特征参数,t表示用户计费档案生成时间。利用计算得到的结果将用户计费档案信息以目标特征值大小为标准进行重构,为了确保管理结果最大限度保留档案之间的关联性,对用户计费档案计算得到的所有特征值结果进行主成分划分处理,其表示为:

其中,p为待管理的用户计费档案特征占比,对于用户计费档案中存在的难以准确提取的模糊特征分量,将其作为单独个体独立管理。当使用管理用户计费档案时,首先以特征为基础在聚类中查找目标用户计费档案,如果无法匹配出对应的资料信息时,则在该聚类中匹配目标用户计费档案,并根据匹配结果完成对用户计费档案的聚类划分,以此实现对集中核算中全部用户计费档案的特征提取工作。
1.3 用户计费档案分类管理
在确定用户计费档案的特征提取之后,就可以按照提取结果对其进行分类管理。需要注意的是,由于不同电力企业的规模以及运营成本不同,因此对用户计费档案管理的要求也不同。为此,本文在对用户计费档案进行分类时,以动态的分类尺度标准进行,通过调整聚类用户计费档案特征值距离聚类中心的距离,提高管理灵活性。
假设企业对于用户计费档案管理要求的类别划分为x,那在满足该条件下,将特征提取结果中主成分因素前三的特征作为分类指标,此时聚类允许的最大距离可以表示为:

在此标准下,可以实现对大多数用户计费档案的分类,但也会存在部分用户计费档案到3个中心的距离均满足要求,此时本文将用户计费档案的目标特征占比作为划分标准,将最大占比特征作为分类结果;部分用户计费档案也会存在与3个聚类中心的距离都不满足聚类要求的情况,此时本文将该类用户计费档案的特征与3个中心的关联程度作为划分标准,将关联性最高的特征作为分类结果。
通过这样的方式,实现对用户计费档案的有效管理,提高对用户计费档案的分类精度。
2.应用测试
为了对本文提出的用户计费档案管理方法的应用性能进行测试,以某电力企业的用户计费档案为实验数据,开展了测试,并将文献[4]和文献[5]提出的方法作为测试的对照组,通过对比3种方法的管理结果,提高对本文方法性能评价的客观性。
2.1 测试环境
测试使用的方案数据共包括5类,分别是用电时长、用电类别、密级、电压等级以及所属线路,每类数据1000份,要求分类的最大距离为0.6。以此为标准,分别采用3种方法对用户计费档案进行分类管理。
为了量化分类结果,将用户计费档案分类精度作为评价指标,其计算方式为

其中,Q为分类精度,Nr为分类结果中符合分类要求的档案数量,N为待分类档案的总量,在测试中,该数值为1000。以此为基础,对3种方法的用户计费档案管理结果进行比较和评价。
2.2 测试结果
在上述基础上,分别对比了3种方法的对实验数据的管理结果,具体如表1所示。
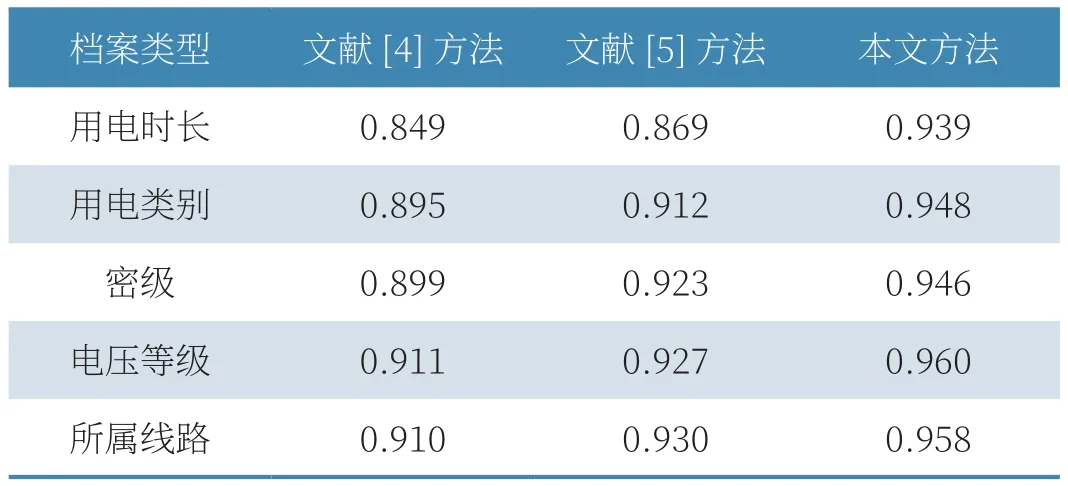
表1 不同方法的档案分类精度
从表1中可以看出,在3种管理方法中,文献[4]和文献[5]对于用户计费档案的管理精度虽然表现良好,但与本文管理方法相比,对于用户计费档案的分类精度仍存在提升空间,特别是对于用电时长的档案,由于其存在形式较多,文献[4]和文献[5]的分类结果均在0.9以下,并不理想。对于类型繁多,种类最为繁杂的用电时长,本文方法通过归一化处理降低了特征提取的误差,因此分类精度仍可达到0.939,对另外两种档案的分类精度均在0.950左右,表明本文提出的管理方法具有一定的研究价值。
3.结语
电力企业用户计费档案资源的数量会随着经营时间的推移而逐渐增加,档案的多样化程度也会不断提高,在此背景下,提高对用户计费档案的管理精度十分必要。本文提出集中核算模式下电力企业用户计费档案的管理研究,实现了对不同类型档案的高精度分类,提高了档案管理工作的效果,以期为电力企业的资源管理工作提供有价值的参考。
猜你喜欢
小学生学习指导·中年级(2024年5期)2024-07-04 17:31:03
通信电源技术(2022年10期)2022-09-21 10:51:24
数学小灵通·3-4年级(2020年4期)2020-06-24 05:51:42
消费导刊(2018年10期)2018-08-20 02:57:10
电子测试(2017年15期)2017-12-18 07:19:27
能源(2017年9期)2017-10-18 00:48:25
通信电源技术(2016年6期)2016-04-20 06:21:48
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
河南科技(2014年7期)2014-02-27 14:11:32
