
基于Stacking模型融合的股票趋势预测
2021-12-03 13:20:28李昊博西南大学
环球市场 2021年32期
李昊博 西南大学
一、引言
股票在很大程度上是一种金融活动、国民经济的一种体现,在文化、经济生活中有着非常重要的功能,无论是对国家、社会抑或是人民都有着重要影响。如果我们可以通过推理演算的方式预测股票市场发展方向,这会对投资者大有裨益。
股票价格预测需要对股票市场有深刻而全面的认识的证券分析师,根据股票市场的发展,对股票市场未来的发展方向和涨跌幅度作出全面的预测。近年来,随着大数据分析、人工智能等技术的飞速发展,相关研究人员开始将机器学习理论、数据挖掘等方法应用在股票趋势预测领域研究中,通过从大量金融统计数据中挖掘重要信息,从而为股民们提供合理化建议。张倩倩(2020)对各种股票预测方法研究进行综述[1],介绍了基于传统时间序列和隐马尔可夫模型的传统预测模型、基于机器学习与深度学习的决策树、神经网络和组合模型等新的创新模型,对比了上述模型的优缺点,总结出一套基于神经网络模型的股票预测法的关键步骤。朱磊(2016)提出假设我国股市不是弱势有效市场,对可能影响明天开盘价和收盘价的8 个因素进行相关性检验,最后通过格兰杰因果检验选出明天收盘价和开盘价的格兰杰导因,可是单纯只是使用了单一的支持向量机算法[2]。罗必辉(2016)引入流形学习中的线性局部切空间排列算法[3]文章本次采用改良的支持向量回归(svr)算法对股票价格进行预测。Stacking 集成学习模型的出现,通过将不同模型进行集合来进一步提升模型总体性能,为股票趋势预测方法提供了良好思路。盛杰(2018)等人使用 Stacking 集成学习算法组合 Logistic,SVM,K 近邻和 CART决策树多个基本算法进行学习形成分类器,最终结果显示准确率比单一算法的分类器效果提高了94%[4]。Stacking 在各个行业数据研究中相比较单一模型算法,效果取得了显著的提升。
为此,本文在对股票趋势预测研究过程中,首先深刻研究logistic 回归、随机森林、GBDT 算法以及SVM 算法在趋势预测上的应用,并以此为基础,结合实际股票数据提出了一种基于stacking 模型融合的股票趋势预测算法。
二、逻辑回归模型
在常规的回归模型中,主要是阐明了自变量和因变量期望之间的线性关系。但是在分析和预测股票数据时,我们研究的变量并不是简单的线性关系,所以我们需要使用Logistic 模型。
Logistic 模型是一种通用的回归分析模型,常用于信息提取、疾病自主诊断、制定经济期望以及更多其他领域。例如,寻找疾病的致病因子、计算疾病发生概率等,其中概率值实由 Sigmoid 函数计算得到,将大于指定概率值的部分分为一类,将小于指定概率值的部分分为另一类。
Logistic 回归模型是从线性回归算法演变而来,是用来预测有不同解释变量构成的分类函数的概率[5]。一般情况下,logistic模型是二进制变量,其中0 代表事件不会发生,1 则代表事件将会发生。在这个模型中,一个自变量可能并不是连续变量,不过它也可以是一个类别变量。与线性回归模型差异在于,该模型不需要自变量和因变量之间的线性关系,即也不需要因变量和误差变量之间的正态分布。
Logistic 回归模型方程如下:
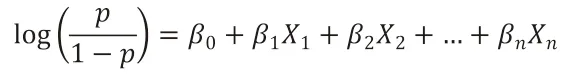
公式中:p代表因变量y=1 的概率,为自变量(回归系数),经由计算样本数据获得。
Logistic 回归在进行股票趋势预测过程中,构建预测变量和已有自变量的线性模型,预测变量将通过算法函数转换成概率
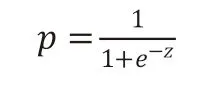
Logistic 模型算法作为一种成熟稳定的预测算法,通常具有较高的预测精度。主要有以下几个优势。首先,Logistic 回归计算效率高,可通过较少的数据来得到整体趋势;其次,Logistic 回归在数据处理过程中不易受到小噪声的影响,鲁棒性强。
三、随机森林
随机森林(Random Forest,RF)是一种经典的集成学习,它属于Bagging(Bootstrap aggregating)类型,它将原始数据和决策树划分特征做随机处理,并将随机训练数据和特征引入到决策树的训练过程中。这种集成算法的优点是多个弱分类器以特征方式集成在一起,比单一分类器具备更好的性能。Bagging 算法处理流程主要分为以下几步,首先,用Bootstrap 方法进行采样,得到多个新训练集,再依据每个训练集获得一个新的弱分类器。在对新得到的样本数据进行分类计算时,将所有由弱分类器产生的投票结果集合在一起,最终的投票分类器是得到终极分类结果。
随机森林算法最初由美国加州大学的统计学教授Leo Breiman 在2001 年提出,它是在Bagging 的基础上对样本特征进行了随机抽样,在构造弱分类器的过程中,每个训练集都只包含样本部分属性,且每个训练集用到的属性都不完全相同,在每个具备原样本基本特征的新样本上分别建立决策树,最终通过投票形成最终分类结果。这样可以减少决策树和模型泛化误差之间的相似度。采用多个弱分类器的并行投票结果以得到均值,从而保证较高的分类精度。大量的研究表明,随机森林算法对高维数据和噪声具备较好的处理能力。模型中每个决策树都会产生一个独立的结果,可以通过多棵决策树的多个结果组合的方式生成最终预测结果[6]。
随机森林有许多优点:该算法具有很强的适用性,可以对各种类型的数据生成高精度的分类算法。对源数据的分布要求较低,不对缺失值敏感,及时发现数据有遗失,依然可以维持准确度,因此在前期不做预处理也不会对结果造成很大影响;该算法模型训练速度快,而且还可以并行处理,大大提高了运算速度。
四、梯度提升决策树
GBDT 算法由 Jerome Friedman 提出并改进,采用了Boosting 的思想,也被称为MART(Multiple Addictive Regression Tree),是经典集成学习算法的一种,其原理是通过构建多个弱学习器,通过多次迭代最终组合形成一个强学习器,并且强学习器的性能均优于其中任何一个多学习器。
该算法的基本原理是每次迭代都要减少原模型的残差,并在残差约简的梯度方向上训练新模型。因此GBDT 的每个预测函数必须采用一个序列,以串行的方式顺序产生,后一个模型参数需要上一轮模型的结果。见图1。
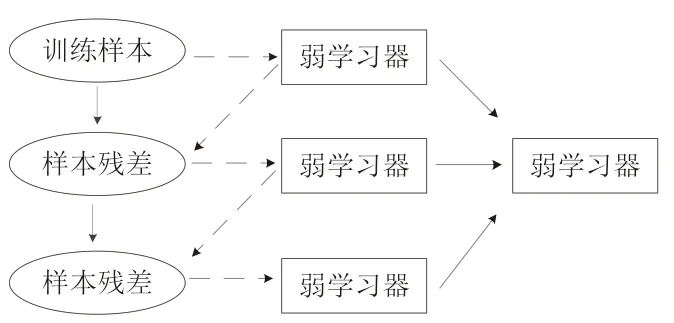
图1 GDBT原理图
假定指定训练集的D={(x1,y1),(x2,y2)…,(xm,ym),},最大迭代次数为k,损失函数L(y,f(x))=log(1+exp(-yf(x))),其中y ∈{-1,+1},输出时为f(x),步骤如下:
首先,初始化弱学习器:
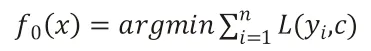
其次,对迭代次数k=1,2,…,T,有如下操作:
(1)分别计算样本i=1,2,…,m的负梯度误差:

(2)通过(xi,ri)(r=1,2,…,m)等数据,拟合得到新的回归树,最后得到第k回归树,相应的叶子结点区域为Rtj(j=1,2,…,J),其中J代表回归树k 的叶子结点个数;
(3)对叶子区域j=1,2,…,J,计算最佳负梯度拟合值:
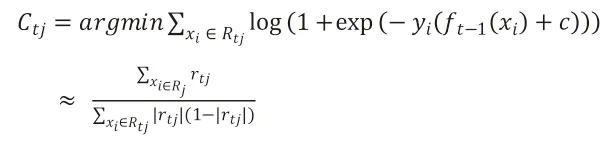
(4)更新强化学习器:
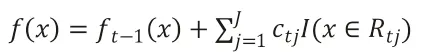
最后,得到强化学习器f(x)的表达式:
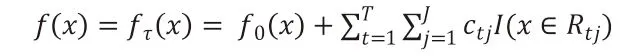
五、支持向量机
支持向量机算法(svm)是一种性能较好的、在小样本和高维数据模式中具有独特的优势的算法。它的提出,是以支持向量机理论和结构风险最小化理论为核心,是一种新机器学习方法。支持向量机的主要策略就是为了使得结构风险最小化,数据会依据核函数被映射到一个高维或无穷维度的特征空间,而后在得到的特征空间方便对数据采用线性学习机的方法处理,最终能够解决样本数据在低纬空间中线性不可分的问题[7]。相较于神经网络,SVM 算法出现过度拟合的现象的可能性更低,尤其是对于数据量小的分类问题,具有出众的性能,解决方案更加优化。所以近些年,它在指定股票价格期望中普遍的运用。
SVM 引入特征变换的方法来将原空间中的非线性问题转换成新空间中的线性问题。首先,要把特征向量从低维空间映射至高维空间中:
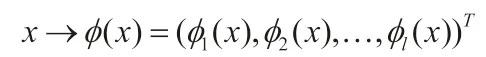
可将线性支持向量机的决策函数进行替换,得到非线性条件下的支持向量机,其分类函数为:
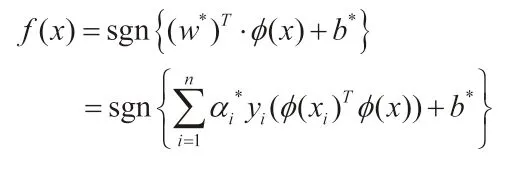
六、“堆叠法”(Stacking)
近年来,机器学习算法不断发展进步,同时集成学习模型接踵而来。Stacking(堆叠)模型是由多个模型集合而成的复合机器学习模型。20 世纪90 年代以来提出的Stacking 就是一种由多种子模型复合组成的机器学习模型,通过将不同模型按一定规则进行“堆叠”来进一步提升预测性能。
Stacking 模型是由两层模型(简单模型组合与上层模型)组成的。第一级包括多个ml 模型,称为主要学习者,第二级包括一个 ml 模型,称为第二学习者。其工作方式首先由原始数据选用不同算法进行建模,各个子模型分别用建立好的参数算法对数据进行预测,输出各自的预测结果。然后第二个学习者检索第一个预测。通过这样处理,次级学习器可以吸取初级学习器的优点,使得预测结果比单一模型更加精准,同时,Stacking 在搭建过程中也可避免单一模型出现的数据过拟合问题。
首先,需要对数据集进行划分(测试集和训练集),并添加其他学习模型进行训练和预测。在此过程中,采用随机抽样的方法将训练数据分成5 组,在利用不同模型进行预测时分别用不同的样本组进行预测,然后在相互之间对结果进行验证。其次,将不同模型产生的预测结果作为新的5 个特征,对次学习器再次进行学习训练,集中前期基础模型特点,提高预测准确性。在本文中为预测股票趋势,分别用随机森林、逻辑回归、GBDT、SVM 模型进行5 折交叉验证。每一个折叠作为一个测试集,并通过训练其他4个折叠模型得到预测值。在五轮训练结束后,计算五个预测值的算术平均值,并将每个预测值加入训练集,得到最终的预测模型。
七、基于Stacking模型融合的股票趋势预测
(一)数据取样
(1)选取样本数据集,采纳在较低波动环境下的股票,即快速增长和快速下跌等不稳定现象稀有的样本数据,数据来源于平安银行2016 年1 月1 日至2021 年2 月4 日相关技术指标的样本数据1342 行,其中,训练集1095 行,测试集247 行。
(2)数据特征的选择,当前预测股票价格已有常规分析流程,同时也取得一定的成果。在特征选择过程中,并不是所有的数据标签对于整个模型的预测具有积极意义,不恰当的选取反而会降低模型预测的准确度,同时,选取的指标稀少,信息不足,又难以表股票市场的复杂性。因此,选取合适的技术指标对于预测市场行为具有关键的意义。本文选用了开盘价、最高价、最低价、收盘价、涨跌、成交量(手)作为关键技术指标进行分析。
(二)数据预处理
在数据采样环节后,对样本数据进行标准化处理,并获得时间序列中较晚的数据作为测试数据,早期的数据作为模型生成和评价的训练数据检查数据(特征值)是否有缺失值,删除缺失值;检查数据中(特征值)是否存在无限数据,若有则进行删除;对标签值进行检查;重命名检索到的标签。将‘t’改为‘股票代码’,‘trade’改为‘trading date’,‘open’改为‘opening price’,‘high’改为‘highest price’,‘low’改为‘closet price’,‘pre’改为‘close price’,‘change’改为‘price up or down’,‘pct’改为‘price up or down’,‘volume’改为‘volume’改为‘volume’(hand),‘amount’改为‘tover’。最后,将平安银行每一天的涨跌情况进行特征构建,以MFI指标(MFI=100-[100/(1+PMF/NMF)])构造出一类特征:
1.典型价格(TP)=当日最高价、最低价与收盘价的算术平均值;
2.货币流量(MF)=典型价格(TP)×十四日内成交量;
3.如果本日货币流量>前一交易日的货币流量,则将本日货币流量视为正货币流量;
4.如果本日货币流量<前一交易日的货币流量,则将当日的货币流量视为负货币流量;
5.当MFI>80 时为超买,在其回头向下跌破80 时,为短线卖出时机,标记为1;
6.当MFI<20 时为超卖,当其回头向上突破20 时,为短线买进时机,标记为0。
对股票数据进行粗预测。同时,在我们粗预测中,两种趋势的数据并不是完全相等的,还需要进行一定的重采样来保证样本的平衡性,以此来保证实验结果的准确性。
(三)数据建模
在用Stacking 方法进行数据建模过程中,把数据集1342 行划分成训练集和测试集,分别为1095 行和247 行。利用训练集数据对随机森林模型、logistic 模型、gbdt模型和 svm 模型进行了5 次交叉验证。将训练集中1095 行数据平均分成5 折,分别为train1,train2,train3,train4,train5,每折219 行,经过以下步骤的计算即可得到Stacking 融合后的结果。
对于随机森林模型,保留第二、第三、第四、第五次折叠,使用第一次折叠作为验证集得到交叉验证结果,使用测试集得到测试结果。分别得到一维219 行的数据A1 和一维247 行的B1;
保留1、3、4、5 折训练集,并以2 倍训练集作为验证集和预测测试集。一维的219 行数据 a2 和一维的247 行数据 b2;
保持第1,2,4,5 倍训练,并使用3倍作为预测验证集和测试集。分别得到一维219 行的数据A3 和一维247 行的B3;
保持第1,2,3,5 折的训练集,用第4 折的训练作为验证集,用第4 倍的训练作为测试集来预测。分别得到一维219 行的数据A4 和一维247 行的B4;
保持第1,2,3,4 折的训练,用5 倍的训练作为验证集,用5 倍的训练作为预测测试集。分别得到一维219 行的数据A5 和一维247 行的B5;
经过前5 轮训练之后,将A1,A2,A3,A4,A5 这5 个对于验证集的预测值进行纵向拼接,形成1095 行1 列的数据,记为Z1。对于测试集的 b1,b2,b3,b4,b5,求平均值,得到247 行1 列的矩阵,表示为y1。
使用同样的方法来并行训练SVM、GBDT、Logistic Regression 这三个模型,最终可得到Z1,Z2,Z3,Z4,Y1,Y2,Y3,Y4 的矩阵,最终把Z1,Z2,Z3,Z4 并列合并得到一个1095 行4 列的矩阵作为下一步的训练集,Y1,Y2,Y3,Y4 并列合并得到一个247 行4 列的矩阵作为测试集;
将上一步的训练集和测试集带入Stacking 算法并使用Logistic Regression 作为Meta Classifier 进行最后的训练和预测,得到最终的预测结果。
同时增添了混淆矩阵,提高了模型的真实性。这是描述分类模型在一组具有已知真值的测试数据上的性能的常用方法。混淆矩阵示意图如图2 所示,我们将使用混淆矩阵进行模型的评估,准确率通过(TP+TN)/(TP+TN+FP+FN)计算得到,作为评判模型好坏的指标。

图2 混淆矩阵示意图
八、实验结果与分析
我们对处理完成的数据分别使用随机森林、逻辑回归、GBDT 以及SVM 模型进行滚动预测,通过混淆矩阵评估方法分别计算各模型的准确率。然后采用叠加法对上述方法进行拟合,得到了较好的拟合实验结果。
通过对比发现,Stacking 融合模型的准确率为79%要高于其他算法,不同算法准确率如表1 所示。
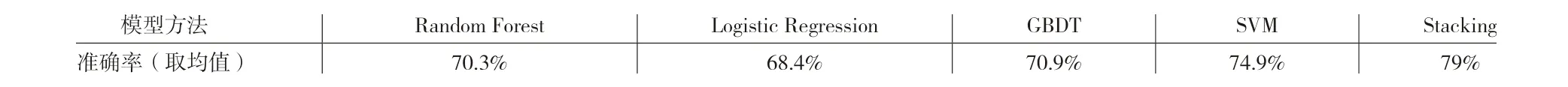
表1 实验结果
九、结束语
本文在研究过程中,采用了基于stacking 模型将机器学习算法融合后对股票趋势进行预测的方法。通过实验得出本方法准确率能够达到79%,预测股票价格的能力明显相较于四种传统的机器学习算法更加优秀。结果表明,基于叠加模型融合的股票趋势预测方法对股票市场价格指数的变化趋势进行预测是可行的。同时也有不足之处,在设计算法的过程中没有加入风险因素,考虑其对所带来的对股票价格的波动影响,在今后的深入研究中,会使用一些神经网络、深度学习等模型增加对风险因素等多场景评估,进一步改进模型的适应能力。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
电子测试(2018年1期)2018-04-18 11:52:35
数学学习与研究(2017年3期)2017-03-09 18:12:42
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
中国老区建设(2016年1期)2016-02-28 09:32:00
