
基于高速公路通行大数据的跨区域货运分析建模技术
2021-12-01 02:42:32叶劲松
交通运输研究 2021年5期
周 雷,张 平,叶劲松
(交通运输部科学研究院,北京 100029)
0 引言
我国“十四五”规划提出,要坚持实施区域重大战略、区域协调发展战略、主体功能区战略,健全区域协调发展体制机制,推动区域协调发展[1]。其中,交通运输将充分发挥先行和支撑作用[2]。随着交通信息化的深入应用和新技术的进步,积累了大量的交通信息资源,行业数据规模爆发式增长,其中高速公路数据是交通行业一项非常重要的资源,其对于分析区域货运交互关系具有很高价值,能有效服务于“十四五”期区域重大战略和区域协调发展战略。
当前,基于大数据技术的高速公路数据分析建模研究主要集中在高速公路运营管理、高速公路道路维护、高速公路安全管理等方面,基于大数据技术进行高速公路货运情况分析的研究还比较缺乏。已有研究中,Emami 等将卡尔曼滤波应用到连通车辆环境中,实现短期流量预测[3];Dai 等提出了一种信息增强LSTM 模型用于预测单条道路的交通流变化[4];Park 等基于大数据技术,通过车辆传感器采集的车流速度和车辆数量数据,采用K-Means 算法对交通事故类型进行分类[5];朱熹在Spark 平台上利用K-Means 算法搭建路网交通运行状态的判别模型[6];陈昭明等构建了混合Logit 模型来反映各因素对事故严重程度的影响[7];马千惠结合离线检测和在线检测方法,设计了车辆偷逃费稽查系统[8];代洪娜等利用高速公路收费系统OD 流量数据提出了PSL 路径选择模型,进行车流量分配[9]。
目前国内对于高速公路货运情况的研究大多为基于统计指标计算方法优化的单省份区域货运研究,缺乏跨省跨区域研究,也缺乏将统计分析方法和大数据技术相融合的应用研究。王龙飞等提出了一种基于车辆行驶OD 和通行量数据的交通运输量计算方法,针对传统基于分层抽样的交通运输量调查法进行了优化[10];段莉珍等提出了一种改进的区域路网货物运输量统计方法[11];张忠民等研究了基于波动系数的统计修正方法[12]。秦芬芬等以北京为例,基于需求方调查数据进行了城市货运特征研究[13];王剑波等利用高速公路数据采用抽样调查的方式对四川通道货运情况进行了研究[14];任敏采用专项调查的方式对贵州货运情况进行了研究[15]。
为分析跨省跨区域货运情况,本研究提出基于高速公路通行大数据的跨区域货运分析建模技术,以海量高速公路通行数据为基础,利用大数据技术并创建相关模型,获取公路货物运输信息,由此分析区域间货运往来、交通以及经济联系强度,探索相关数据结果在实际中的应用价值,以期为区域重大战略和区域协调发展战略提供决策支撑。
1 高速公路通行大数据概况
1.1 高速公路通行大数据内容及特点
高速公路通行大数据主要来自于高速公路联网收费系统,车辆通行一次便在收费系统中产生一条记录。高速公路通行大数据原始数据包含高速公路通行明细数据和各类字典数据,具体数据指标如表1所示。

表1 高速公路通行大数据内容及指标
高速公路通行大数据具备典型的大数据特征,主要表现在以下方面。
(1)数据总体规模大:覆盖了全国29 个省13.6 万km 的高速公路,约9 000 个收费站,每年数据量为TB级。
(2)数据增长速度快:高速公路通行数据每月增长超过8亿条,容量达到300GB。
(3)数据内容丰富:高速公路通行数据包含车辆进出高速收费站的相关行程信息,以及车牌号、行驶里程、车货总重等指标。
(4)数据潜在价值高:高速公路通行数据可反映高速公路运营现状,对于行业管理部门把握交通运输特征,制定发展战略具有重要作用。
1.2 高速公路通行大数据预处理
因为高速公路通行原始数据的数据量巨大,无法保证所有的数据都符合质量要求,数据预处理工作是针对采集得到的高速公路通行原始数据,根据审核规则,识别其中不合理的数据,并简单修复部分错误数据[16],以满足数据分析的需要。数据清洗与审核的流程如图1所示。

图1 数据预处理流程
数据预处理流程包含数据采集、数据抽取、数据上传、数据入库、数据审核等步骤。
(1)数据采集:高速公路原始数据的采集方式分为两种,分别是文本及数据库。文本数据通过FTP 方式进行采集,数据库数据通过数据接口的方式进行采集。
(2)数据抽取:数据抽取环节对高速公路原始数据的格式进行初步审核,抽取初步审核通过的数据进行上传,并压缩高速公路原数据文件到备份目录。
(3)数据上传:将抽取的数据以每10 000 条数据一个压缩包的形式上传到交换服务器。
(4)数据入库:将上传的数据入库至中间数据库。
(5)数据审核:对中间数据库的数据进行内容审核,判断数据是否存在超限、重复等问题,并对这些问题进行处理,经审核通过的数据入库大数据平台,并上传审核结果。
2 基于高速公路通行大数据的跨区域货运分析模型构建
2.1 车辆轨迹追踪算法模型
为进行跨区域货运分析,需确定在高速公路上行驶车辆的起讫点及其具体的行车轨迹。在现有海量高速公路通行明细数据中,一辆车的一次通行记录被分割成了多条记录,车牌号是一辆车的唯一标识。理论上,根据车牌号、出入口时间、出入口站点编码的组合即可判断两条记录是否属于同一辆车的一次出行,形成完整的车辆行驶轨迹。但事实上,在实际数据中存在着车牌号字段无法识别的问题。针对此问题,本研究建立了车辆轨迹追踪算法模型,以快速、准确确定车辆行驶路径。算法流程如图2所示。

图2 车辆轨迹追踪算法流程
(1)建立路网关系
根据各收费站所在的地理位置确定收费站之间的路径关系,建立全国高速公路收费站路网关系表。
(2)判断车牌号是否匹配
根据收费站出入口站点位置,参考历史数据中出入口时间,可估算收费站之间的合理行驶时间T。在车辆轨迹追踪中,在合理的时间范围T内,车牌完整且完全相同的记录可进入车牌串接。而时间T内由于车牌原因未成功匹配的数据先进入车牌修正,再进行车牌串接。
(3)车牌修正
采用贝叶斯推断方法中基于多个属性指标的匹配概率公式对未成功匹配的数据进行车牌修正[17]。选取车货总重、轴数、通行介质编号3 个重点指标进行贝叶斯匹配概率P的计算。基于3个属性指标的匹配概率公式为:

式(1)中:W1为车货总重变化比;W2为轴数差;W3为编号相似度;P(S|W1)为匹配车辆车货总重变化比在特定数量段的概率;P(S|W2)为匹配车辆轴数差在特定数量段的概率;P(S|W3)为匹配车辆编号相似度在特定数量段的概率;P(H|W1)为不匹配车辆车货总重变化比在特定数量段的概率;P(H|W2)为不匹配车辆轴差在特定数量段的概率;P(H|W3)为不匹配车辆编号相似度在特定数量段的概率。若匹配成功的记录中存在车牌完整的记录,则可对其他记录进行车牌修正。
(4)车牌串接
以车牌为基础,汇聚相同车辆的行驶记录,并根据出入收费站时间、收费站路网关系,形成车辆行驶轨迹。
(5)路径还原
结合车辆轨迹信息,计算高速公路上出发、到达、过境等各类车辆的跨省OD 信息,最终实现高速公路上出发、到达、过境等各类车辆跨省行驶记录的串接,追踪车辆连续出行起讫点,还原高速公路车辆真实行驶路径。
2.2 高速公路主要指标统计模型
为进行跨区域货运分析,需获取各省高速公路货运信息以及省与省之间的货运交互信息。但高速公路的通行数据量非常庞大,货车指标数据存在丢失的现象,如果进行简单的删除,会丢失很多有用的信息,使得计算指标的准确性降低,从而与实际产生误差。因此,本研究针对货车数据中货运量、货运周转量等关键指标,尝试对缺失数据进行补全,最大限度提高补全数据的契合度和准确度。
2.2.1 货运量统计算法模型
货运量统计算法流程如图3 所示。货运量测算准确性主要取决于车货总重,识别车货总重时会有缺失值,故算法重点在于补全缺失数据。
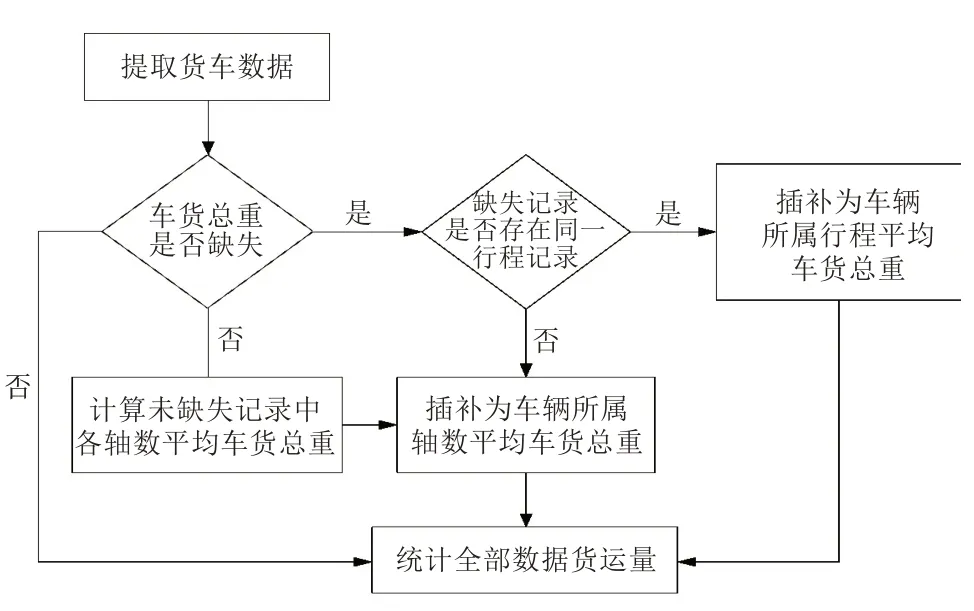
图3 货运量统计算法流程
(1)提取数据中货车数据,判断车货总重是否缺失
从数据中将货车的车货总重提取出来,得到货车总数据量为N,然后将车货总重缺失的数据量记为n。
(2)判断缺失记录是否存在同一行程记录
利用缺失货车车货总重记录中的车牌号、收费站及时间信息,查询相同车牌号一段时间T内的行车记录。若存在,将该车的行车记录按时间排序,缺失车货总重记录为第i条,若第i-k条数据的车货总重与第i+k条数据的车货总重相差不超过5%,则可判断为该车的同一行程记录。
(3)对存在同一行程记录的缺失数据中的车货总重进行插补
对得到的轴数相同、行程相同的货车数据求均值,用该均值对相应的缺失数据进行插补,插补值为:

式(2)中:h为相同行程;Nmh为相同轴数相同行程的该货车数据量;为相应的平均值。
(4)对剩余缺失数据进行插补
按照轴数分别求得各轴数车货总重的平均值,再利用该值对剩余缺失数据进行插补,即插补值为:
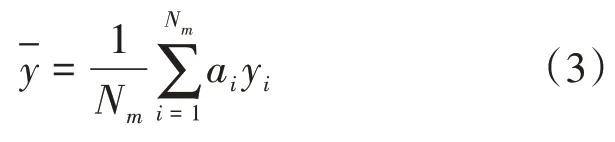
式(3)中:当第i个数据有车货总重时,ai=1;数据没有车货总重时,ai=0;Nm为查询到的不同轴数的总量。
2.2.2 货运周转量统计算法模型
货运周转量等于货车运量乘以里程。其测算准确性主要取决于车货总重和里程,这两项数据在进行识别时都会有缺失值,需补全。货运周转量统计算法流程如图4所示。

图4 货运周转量统计算法流程图
(1)提取数据中货车数据,插补车货总重
提取数据中的货车数据,并利用2.2.1货运量统计模型补全车货总重缺失数据。
(2)判断缺失里程数据行驶路径
一般在未开通新高速公路的情况下,站到站之间的路径不会发生变化。但站到站之间的路径不止一条,需利用出入口时间差、车牌号等辅助进行路径判断。
本研究采用距离公式——异构欧几里德重叠度量进行数据样本之间的计算。假设两个数据样本xa和xb之间的距离为d(xa,xb),则:

式(4)中:wj为第j个变量的权重,dj(xaj,xbj)为样本xa和xb之间第j个变量间的距离,可定义为:

当第j个变量是离散型变量时,通过函数d0计算:
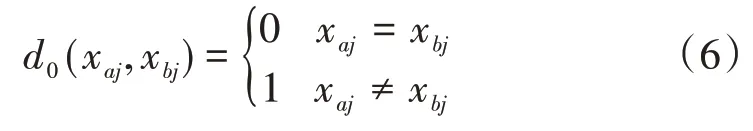
当第j个变量是连续型变量时,通过函数dN计算:

收费站位置信息为确定里程的决定信息,通过出入口时间可判断行驶里程的长短,货车司机一般会选择熟悉的路径行驶,利用车牌号可查询该车的历史行驶路径,从而辅助判断缺失里程记录的行驶路径。因此本研究选取收费站信息、出入口时间差及车牌号来进行里程插补。
权重设置上,采用基于样例学习的权重调整方法。w1,w2,w3分别表示收费站信息、出入口时间差、车牌号的权重,w1+w2+w3=1。出入口收费站信息是确定里程的决定性因素,因此其权重需大于另外两个指标权重之和,最低为0.6;在这个设定下,可规定w1以0.1为步长,从0.6增加到0.8,计算不同组合下插补结果的精准度。随机选取一段时间内的高速公路货车记录进行实验,随机抽取20%的数据作为缺失样本,测算各权重插补结果的精准度。所有可能的权重组合及实验结果如表2所示。

表2 里程插补所需指标权重组合及实验结果
由表2 可知,出入口收费站信息、出入口时间差、车牌号权重分别为0.7,0.2,0.1 时平均精准度最高,因此选取0.7,0.2,0.1 作为权重来进行里程插补。
(3)插补里程
提取与缺失数据距离最小的样本中的里程进行插补。
2.3 模型实现
为实现上述模型,本研究提出了基于高速公路通行大数据的跨区域货运分析应用架构,如图5所示。

图5 基于高速公路通行大数据的跨区域货运分析应用架构
(1)数据来源层进行数据预处理,生成高速公路通行数据。
(2)数据处理层利用Spark技术实现车辆轨迹追踪模型,并生成高速公路跨省车辆起讫明细数据。
(3)数据分析层基于高速公路通行数据及高速公路跨省车辆起讫明细数据实现高速公路主要指标统计模型,生成高速公路各省货运信息、高速公路各省交互货运信息、高速公路车籍地汇总信息。
(4)数据应用层则结合应用场景展示分析结果。
(5)在数据存储方面,本研究使用Hadoop系统提供的HDFS 存储数据处理层中的明细数据。数据分析层中的各类汇总数据的数据量较小,但查询响应实时性较高,因此为保证数据应用层的使用要求,存储到关系数据库中。
3 模型应用
基于高速公路通行大数据的跨区域货运分析建模技术可应用于多个领域,本研究具体介绍3个方面:一是统计决策应用,二是高速公路安全监管,三是与铁路、港口数据的融合应用。
3.1 统计决策应用
3.1.1 行业运输量统计应用
(1)运输量统计
传统运输量统计工作主要是借助抽样调查、典型调查、重点调查等调查方式开展的,由于存在着抽样量不足、数据不够准确、人为引导偏差等问题,导致运输量统计的准确性得不到有效保证。通过本研究模型,可直接生成高速公路货车运输量统计指标,解决前述问题。图6 所示为全国部分省区市高速公路货车流量分析。
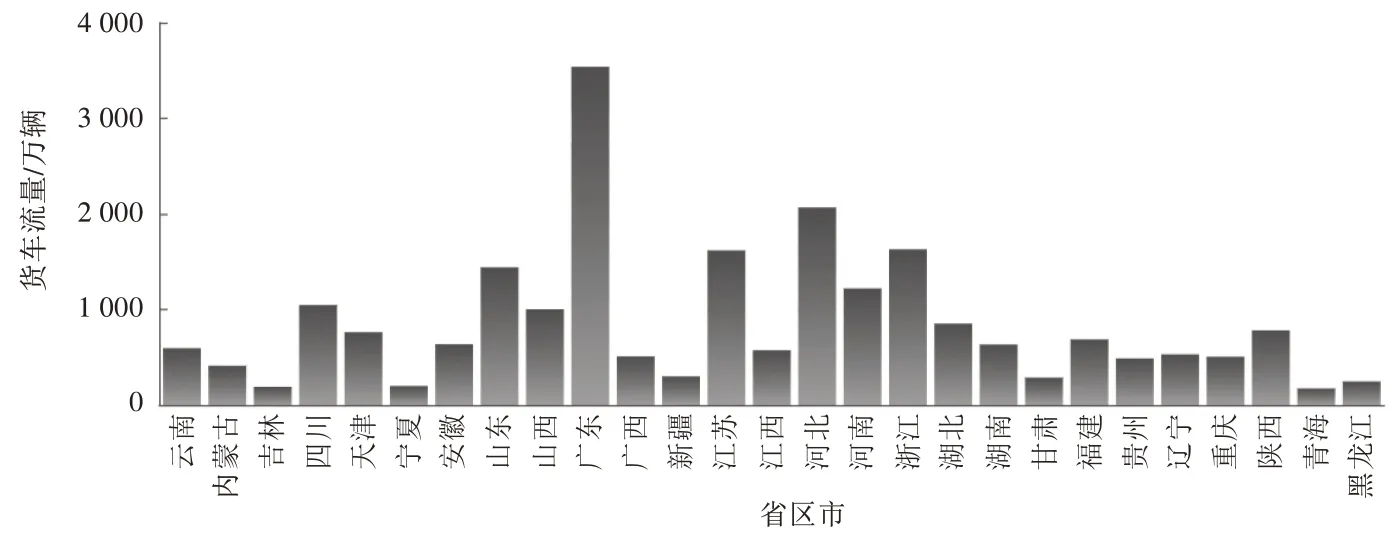
图6 全国部分省区市高速公路货车流量
(2)货车车辆省外运输量统计
本省车籍货车在省外流量、流向的变化特征一直是各省交通管理部门关心的重点。利用本模型可分析本省车籍货车在本省域外的行驶情况,服务管理部门准确掌握本省车籍货车在本省外的分布和运行特征。表3 以重庆为例,分析全国各地市渝籍车货运量情况。
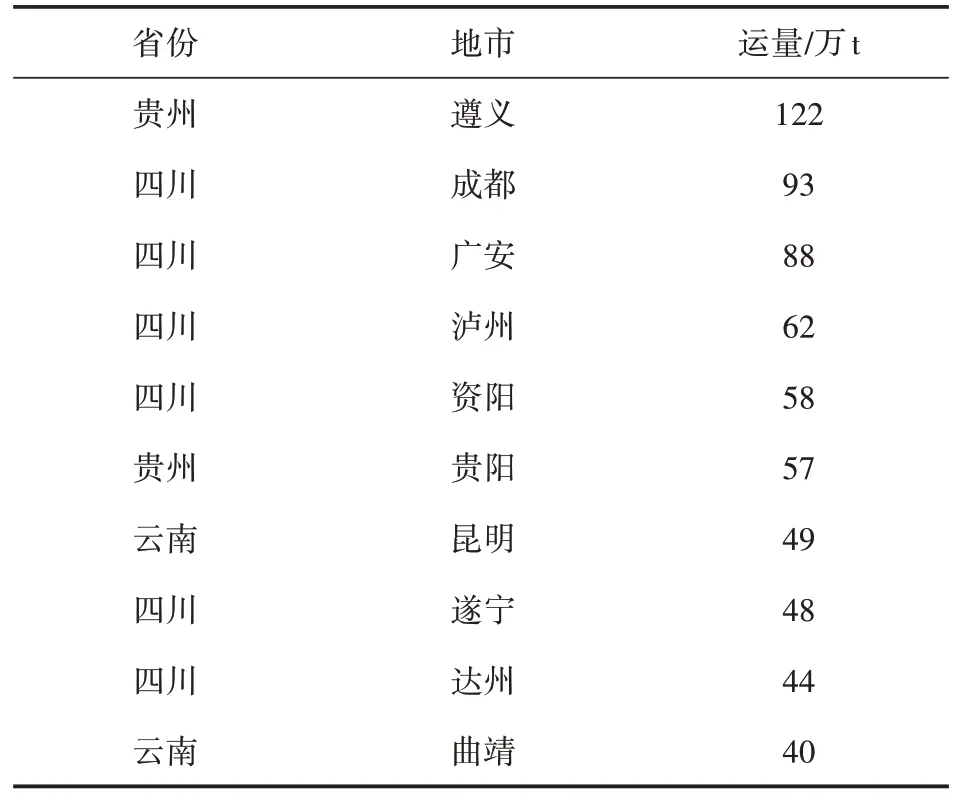
表3 全国各地市渝籍车货运量TOP10分析
3.1.2 经济运行分析
(1)省级区域货运交互分析
依托本研究模型,可分析某一地区到其他省份的货运总量、运力结构、空间分布等方面的特征,准确掌握各地区间的货运交互情况。图7 为重庆出发到全国部分省区市的高速公路货车流量。
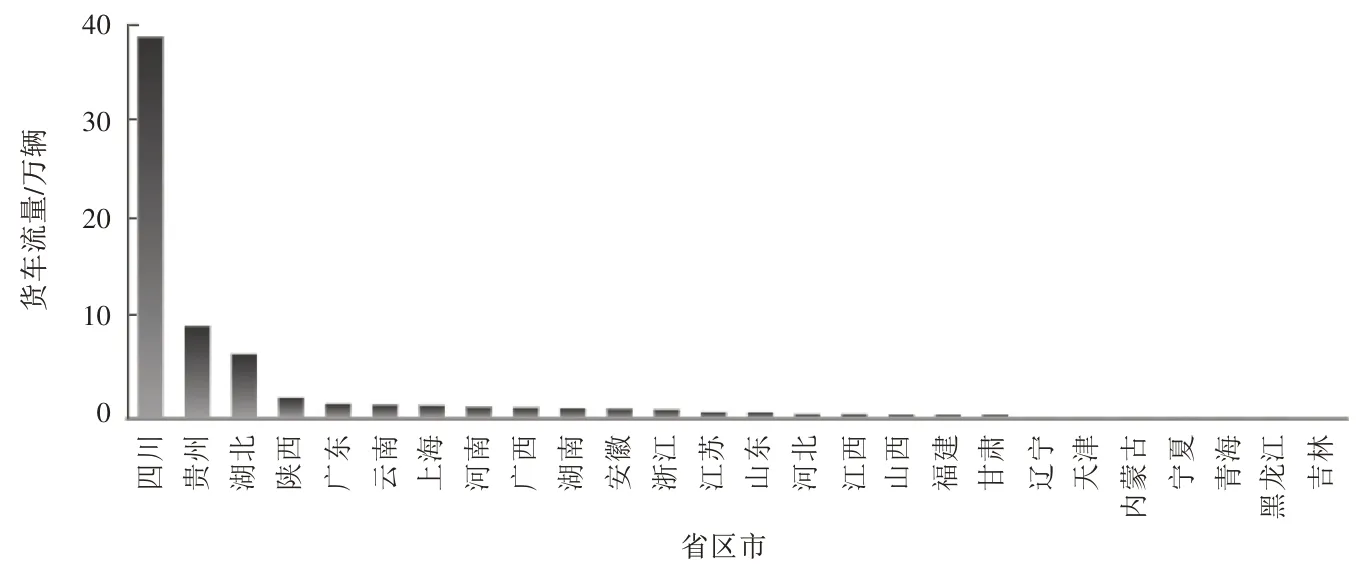
图7 重庆出发到全国部分省区市高速公路货车流量
(2)重点区域货运交互分析
随着我国区域经济发展新战略的渐次铺开,以城市群为主体、大中小城市和小城镇协调发展的格局正在形成。高速公路作为带动区域经济发展的关键要素,其生产运输情况也反映了城市群协同发展带来的影响。利用本研究模型,以成渝城市群为对象,通过货物运输量统计指标展示城市群内部各地区之间的联系强度和互动关系。图8 为重庆出发到四川部分地级行政区的高速公路货运量分析。

图8 重庆出发到四川部分地级行政区高速公路货物运输量
3.2 高速公路安全监管
3.2.1 疲劳驾驶筛查
目前,在高速公路上对货车司机进行疲劳驾驶筛查还比较困难。本研究利用行驶里程、出入口时间可综合判断长途货车司机中疲劳驾驶情况,形成预警名单供管理部门核查。表4 所示为在高速公路上行驶时间超过4h,速度大于80km/h的部分车辆记录。

表4 疑似疲劳驾驶名单
3.2.2 高速公路养护
高速公路货车计费方式的变革,一方面提高了货车实载率,进一步推动道路运输结构优化调整,促进公路货运行业集约经营。另一方面,大量重载货车频繁行驶在高速公路上,易造成路面损坏、桥梁断裂,缩短高速公路的正常使用年限。
借助本研究模型可对不同类型货车的流量、载重等时空分布特征进行分析,进而可预判道路受损情况,有助于道路养护人员对受损程度较为严重的路段实施重点监控,同时结合历史养护数据,科学制定道路的大中修计划,为公众提供更加安全的出行保障。
3.3 与铁路、港口数据融合应用
3.3.1 与铁路数据融合应用
为打破传统的区域化发展、强化区域之间的联系与沟通,国务院办公厅通过《推进运输结构调整三年行动计划(2018—2020 年)》[18],以“公转铁、公转水”为主攻方向,触发了全国交通运输结构改革,以实现区域发展的联动性。
通过高速公路跨区域货运分析,再结合铁路现有的电子运单数据,可全面、深入地研究区域间高速公路、铁路不同运输方式的需求和相互竞争关系以及空间分布情况,为铁路运输线路和运营组织的优化提供辅助决策。
3.3.2 与港口数据融合应用
通过本研究模型,可生成高速公路上货车的行驶轨迹,再与船舶到港报告数据、水上AIS 数据相结合,一方面可深入分析港口对内陆腹地经济的拉动作用,另一方面还可面对区域一体化的发展形势,进行港口群的协调发展研究,遏制港口设施重复建设等现象,践行绿色发展理念。
4 结语
随着高速公路信息化的快速发展,高速公路通行数据规模不断增长,为及时掌握高速公路车辆运行规律提供了丰富的数据资源。为充分挖掘高速公路通行数据价值,发挥其在宏观管理决策、运输量统计分析、车辆安全监管等方面的作用,本研究针对全国高速公路通行大数据,通过大数据分析、处理和建模,建立了车辆跨区域行驶轨迹追踪算法,实现了车辆行驶路径的快速、准确还原,为跨省区的车辆交互分析提供了基础;提出了高速公路主要运输指标统计算法,以反映高速公路运输量及相关指标的变化情况,可为各级交通运输管理部门掌握高速公路货运情况提供支撑;基于上述基本算法,形成了高速公路跨区域货运分析模型,可动态反映各省区市间高速公路货运交互规律,为各级行业管理部门制定行业发展政策提供支撑。
但是,本研究对高速公路通行数据的挖掘和应用场景研究方面还相对较为单一,未来可在此基础上继续研究其他货运相关指标,扩充、深化既有的应用场景,不断拓展数据在行业运输量统计、经济运行分析、路衍经济发展及车辆行驶安全风险评价等方面的应用,积极发挥数据应用效益和数据要素价值。
猜你喜欢
幼儿画刊(2023年12期)2024-01-15 07:06:14
中国交通信息化(2022年8期)2022-10-28 06:08:52
中国交通信息化(2022年7期)2022-10-27 06:35:32
中国交通信息化(2019年2期)2019-03-25 03:20:12
无人机(2018年1期)2018-07-05 09:51:00
无人机(2017年10期)2017-07-06 03:04:36
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:30
中国交通信息化(2017年8期)2017-06-06 07:16:31
学与玩(2017年6期)2017-02-16 07:07:24
专用汽车(2016年9期)2016-03-01 04:16:52
