
基于改进YOLOv3 网络的非机动车检测
2021-12-01 05:26杨紫辉任洪娟
智能计算机与应用 2021年8期
杨紫辉,江 磊,任洪娟
(上海工程技术大学 机械与汽车工程学院,上海 201620)
0 引言
近年来,自动驾驶技术和机动车驾驶辅助技术不断突破与升级,智能驾驶系统发展势头迅猛。在此基础上,路况信息的获取、识别便显得尤为重要,逐渐成为了智能驾驶系统研究应用的基础与关键,而非机动车的精准检测识别便是智能驾驶系统的重要组成部分[1-2]。
传统的目标检测方法是使用人工设计的图像特征来进行检测,如HOG 算子、SIFT 算子等,但由于真实场景复杂多样性,难以提取非机动车等目标特征,传统方法难以满足实际使用的需求。同时随着深度学习技术的不断发展,基于深度卷积神经网络的目标检测和目标跟踪算法被不断提出,如R-CNN(Region Convolutional Neural Network)、Fast-RCNN等,目标检测率得到了大大提升,基于深度卷积网络的目标检测已经成为了主流检测方法。在2015 年,Joseph Redmon 提出了YOLO(You Only Look Once)系列算法,极大地提升了算法检测的速度。
在驾驶场景中执行目标检测背景复杂,要测量的目标密集分布或重叠,摄像机的观看距离不固定,导致目标大小不同。特别是较小的目标,如非机动车、行人和交通标志,具有像素少、分辨率低、特征不明显的特点,YOLO 算法对该类目标的检测性能并不理想[3-4]。由此,本文基于改进优化的YOLOv3网络对非机动车进行检测,通过复制增加骨干网络得到特征提取辅助网络,由此提高整个特征提取网络的性能,并在辅助网络与骨干网络的特征信息融合时采用注意机制,重点对有效特征通道进行处理,抑制无效信息通道,提高网络的处理效率,经测试整个优化网络的性能和功能满足实际应用。
1 YOLOv3 网络结构分析
YOLO 系列是一种典型的网络结构为端到端的算法[5],相较于R-CNN 系列的两阶段网络算法,YOLO 算法的网络结构更加简洁。YOLO 算法的网络是首先生成候选推荐区域,然后执行检测与判断。其检测速度更加迅捷,原因在于其将候选区域机制和检测集成到了同一网络中。
1.1 训练过程
YOLOv3 的网络结构通过使用预定义的候选区域来取代R-CNN 网络中的RPN。其将特征映射分成s × s网格,为了预测目标会在每个网格生成b个边界框,最后在特征地图上生成可以覆盖整个特征地图区域的预测边界框,其数量为s × s × b,同时直接对生成的预测边界框进行边界回归。为了防止预测边界框是冗余的,需要对每个预测边界框进行置信度计算,然后为置信度设置阈值,阈值以上的预测边界框保留用于回归,低于阈值的边界框直接删除。其中,每个边界框的置信度由两部分组成:预测目标类别概率和预测边界框与实际帧的重合度。
置信度计算公式(1)为:
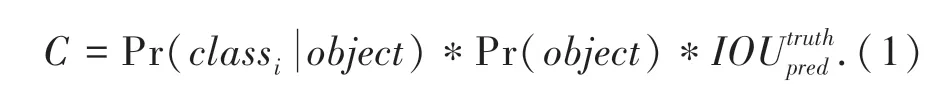
为了减少工作量,可以通过对预测边界框设置阈值的方式消除多数无用边界框,但某些单体对象可能同时持有多个边界框来预测对象,从而在特征映射上产生冗余的预测边界框。因此,YOLOv3 使用非极性非最大抑制算法去除冗余检测框,从而得到一个对目标精确检测的目标框。
1.2 网络结构
由于网络的不断深化,梯度消失和梯度爆炸等问题会在训练过程中凸显出来,这类问题可以通过引入残差网络来解决。通常为了提取更深层次的特征信息,会使用将进入残差模块前的特征与残差模块输出的特征相结合的方法。YOLOv3 采用了新的网络结构darknet-53。darknet-53 主要由53 个卷积层组成,包含大量的3×3,1×1 卷积核。YOLOv3与v1 和v2 的网络结构相比,其利用剩余网络设计了快捷连接模块,如图1 所示。

图1 剩余结构网络图Fig.1 Residual structure network diagram
快捷连接模块的使用一方面有利于解决网络层过多造成的梯度消失问题,另一方面使整个网络的总层数达到106 层,更适合于特征提取。同时,YOLOv3 采用多尺度检测机制,分别检测13×13,26×26 和52×52 的特征映射,增强了提取小目标的能力,其网络结构如图2 所示。
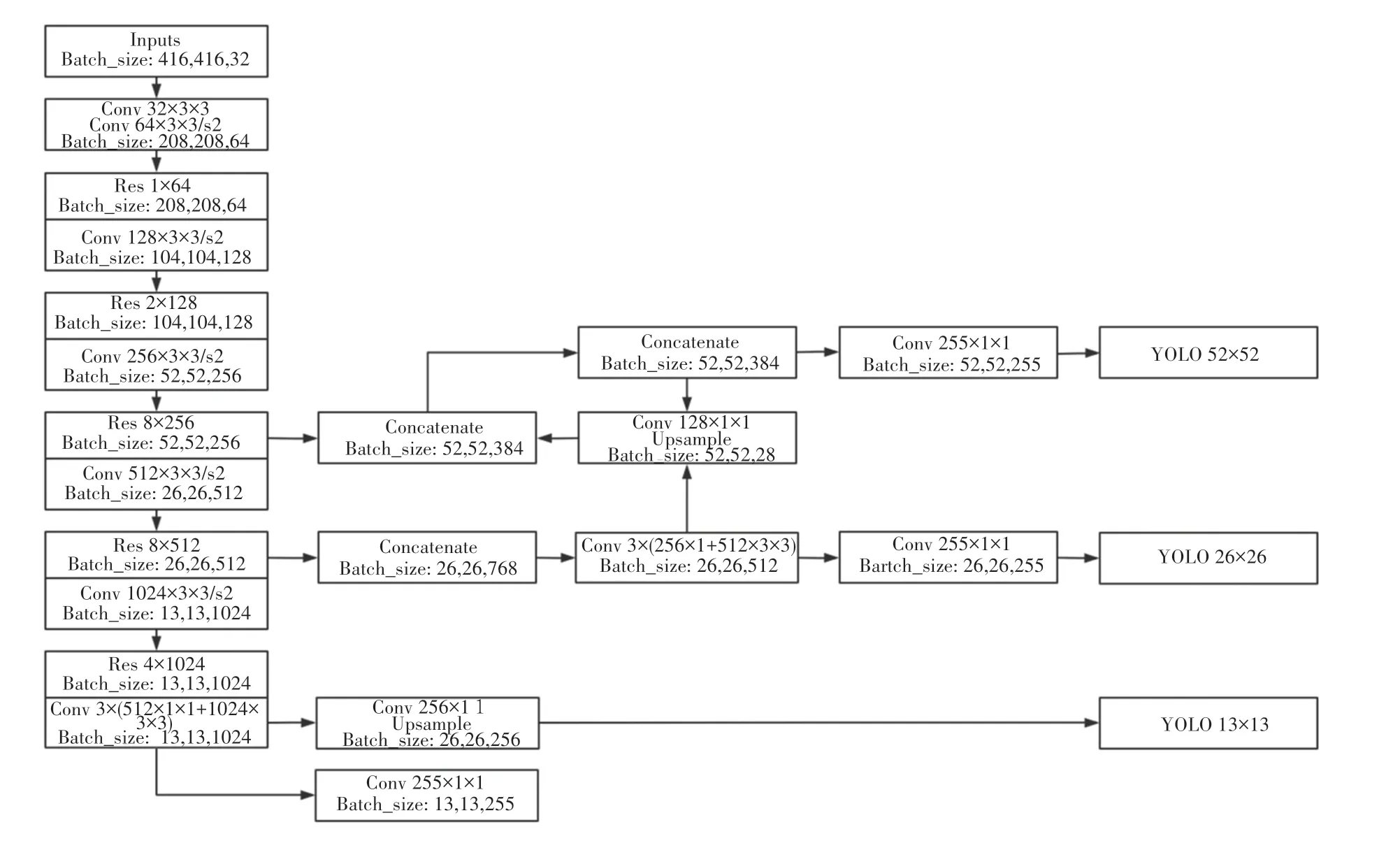
图2 YOLOv3 网络结构图Fig.2 YOLO v3 network structure
YOLOv3 使用3 个不同比列的特征映射来预测检测结果。当输入图像的分辨率确定时,基本尺度特征图的大小为原始分辨率的1/32,其余2 个尺度分别为1/16 和1/8。例如,当输入图像的分辨率为416×416 时,其基本尺度特征映射的大小为13×13× n,通过上采样获得26×26×n的特征映图;将其与上一个卷积层的输出融合,从而获得26×26× m的第二尺度特征图;基于第二尺度特征图,用同样的方法得到52×52× w的第三尺度特征图;通过对每个尺度特征图的类别预测、边界框和目标分数来预测三维张量编码。在此过程中,检测帧共4 个参数,目标评价1 个参数,类别数为80 个。每个尺度特征映射单元预测3 组上述信息,即3×(4+1+80)=255 维信息。最后3 个尺度的输出张量维分别为y1=13×13×255,y2=26×26×255,y3=52×52×255。
2 研究改进YOLOv3
本文的设计旨在研究非机动车的检测问题,其检测内容为道路中行驶的非机动车,包括自行车、电动助力车等,需要测试的目标具有多样性特征。针对该情况,本文将YOLOv3 的特征提取网络分为两部分进行优化。第一部分是通过增添骨干网络来获得特征提取辅助网络,提高整个特征提取网络的性能;第二部分是对骨干网络和辅助网络的特征信息融合采用注意机制,提高对有效特征通道的关注度,抑制无效信息通道,提高网络处理效率。
2.1 特征提取辅助网络结构
YOLOv3 的特征提取网络采用darknet-53,以残差结构形式加深采样深度。其中剩余模块内部结构相对简单,使得整个网络简单易用,但特征提取能力无法优化。本文优化骨干网络的主要方式是通过增加复制剩余模块来拓宽整个网络,并对增加复制所得到的剩余模块结构进行微调,优化后的网络如图3 所示。
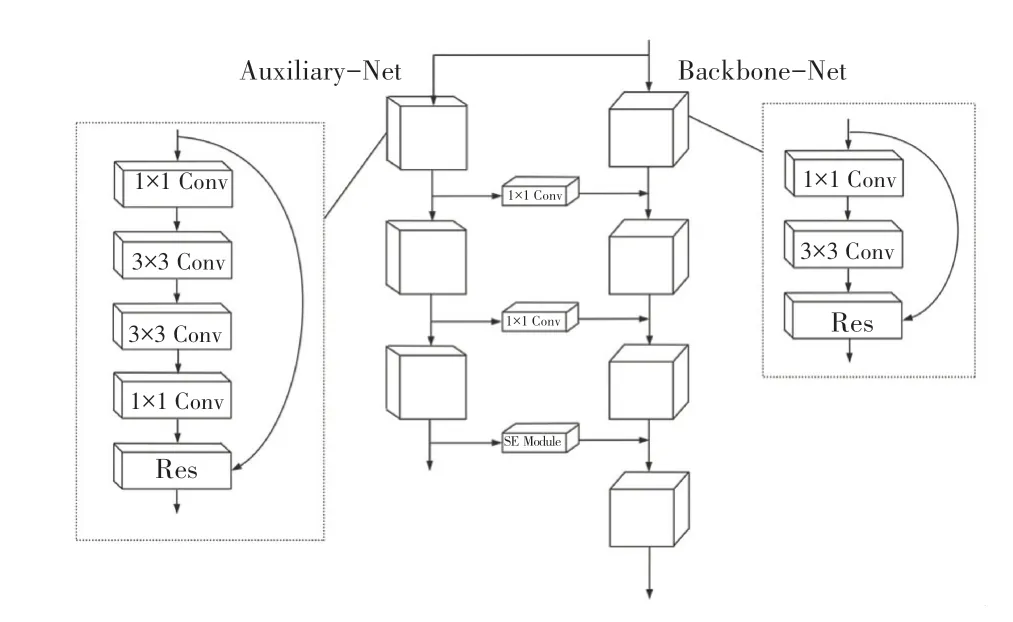
图3 YOLOv3 优化网络结构图Fig.3 Optimized YOLO v3 network structure
与单一结构的原始网络相比,本文增加了一个比骨干网络规模更小的特征提取辅助网络,骨干网络的旁路由多个剩余模块组成。与YOLO 残差模块相比,本文对辅助网络残差模块进行了改进,其具体实现方式为将原来的残差模块使用3×3 卷积核进行特征提取,而辅助网络中的残差模块使用两个连续的3×3 卷积核获得5×5 的接受域,最后将提取的特征合并到骨干网络中。
2.2 注意机制
二级网络与骨干网络的连接有两种不同的方式。第一种方式是辅助模块的输出首先由1×1 卷积核集成,然后传输到骨干网络;第二种方式是将注意机制增添到深度辅助网络的两个网络之间。当网络达到一定深度时,其中的语义信息也变得更高级,辅助模块将发挥对有效特征进行处理和传输,对无效特征进行信道抑制的作用。
由于SE 模块具有结构简单,易于操作的优点,本文采用SE 模块实现两个网络之间的注意机制。通过SE 模块的增加,达到对辅助模块输出特性的重新校准。工作流程大致可分为挤压和激励。挤压是为了更好地现实每层中各信道的特征值分布,将二维特征映射通过平均池转化为一维特征映射,此时特征映射大小转换为1×1×c;激励是使用一个全连接神经网络,对压缩之后的结果做一个非线性变换,该过程由两个全连接层组成,其中会加入一个缩放参数SERadio 来减少通道个数,从而降低计算量。
3 实验结果与分析
3.1 数据集训练
本文使用的数据集来自BDD100K。2018 年5月加州大学伯克利分校AI 实验室对外发布了BDD100K,该数据集是目前规模最大、内容最具多样性的公开驾驶数据集,主要内容由10 万段高清视频组成,其中每段视频内容约40 s,分辨率为720 p,帧数为30 fps。BDD100K 发布时,该实验室同时设计了一个图片标注系统,该系统通过对数据集中每个视频的第10 s 关键帧进行采样,从而得到了10万张图片,并对其进行标注。
本文在通过多次调整参数后,对模型进行了12 000次的迭代训练。通过损失曲线的实时绘制,可以直观地观察到训练过程中的实时动态,如图4所示。图4 中蓝色折线为本文模型训练工程中对应的平均损失曲线。其中,横坐标表示训练迭代次数,纵坐标表示训练过程中的损失值。
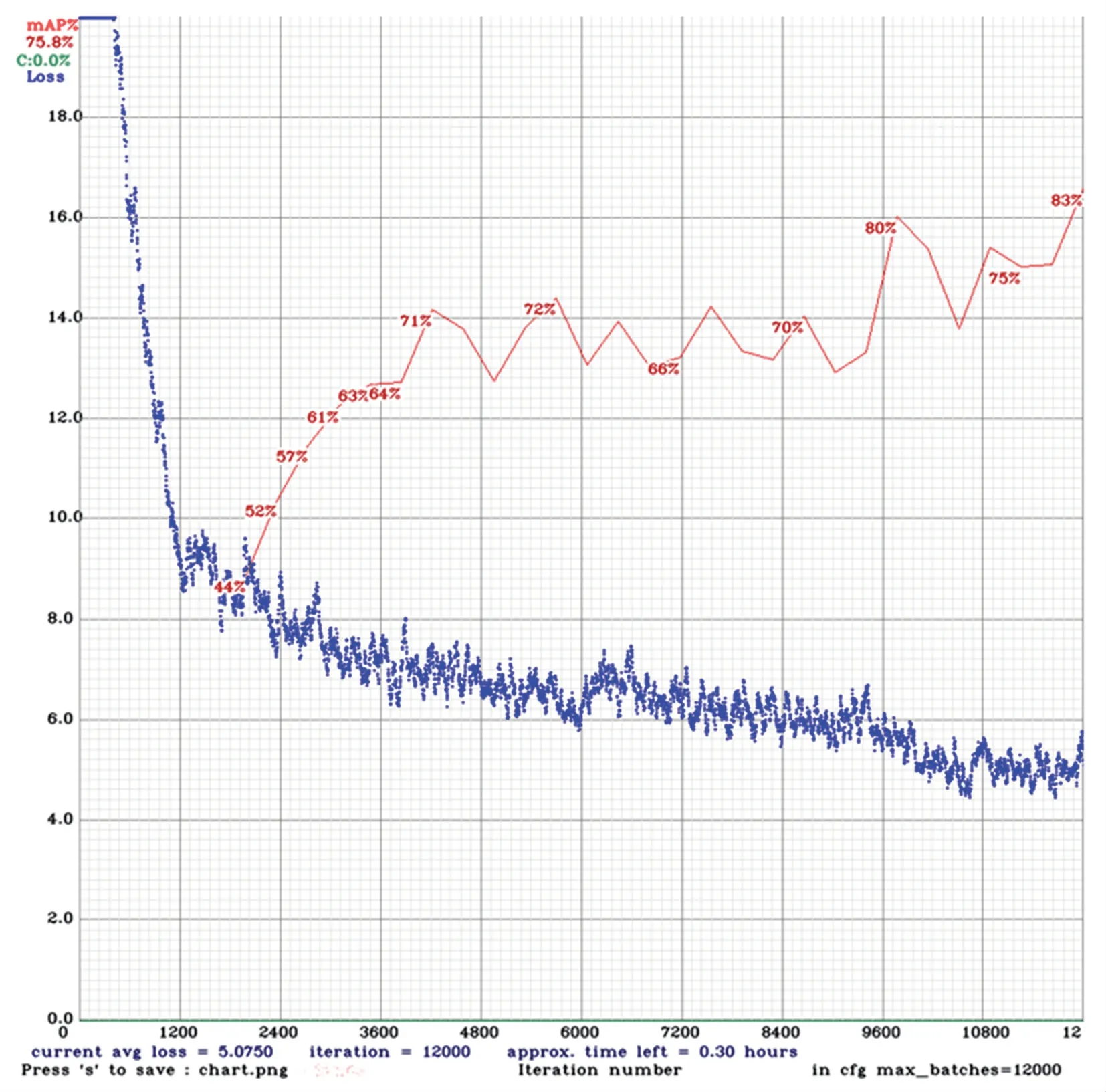
图4 训练函数损失图Fig.4 Training loss function graph
3.2 模型测试与比较
使用测试集对训练好的模型进行测试,测试指标主要为对目标的召回率和检测的准确率。其中,目标召回率R(Recall)和检测准确率P(Precision)计算公式如下:
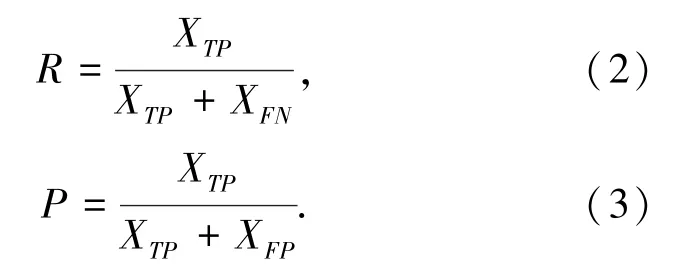
其中,XTP表示算法中正确分类的正样本,即被正确检测出的目标数;XFN表示错误分类的负样本,即没有被检测出的目标数;XFP表示错误分类的正样本,即被错误检出的目标数。
AP代表某一分类的精度,通过找到在不同查全率下最高的查准率得到。mAP代表多分类检测模型中所有类别的AP均值,mAP的值越大表示该模型的定位与识别的准确率越高。
测试所使用的200 幅图像中共有482 个目标,使用YOLOv3 算法和改进后的新YOLOv3 算法在数据集上进行测试,分别计算R和P,结果见表1。
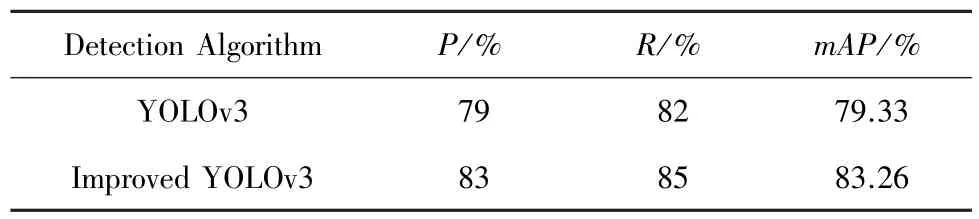
表1 优化模型与原网络模型试验结果对比表Tab.1 Comparison between optimized model and original network model test result
本文模型与YOLOv3 模型检测对比结果如图5所示。

图5 检测结果对比图Fig.5 Comparison of test results
4 结束语
本文主要介绍了一种基于YOLOv3 网络优化的可用于非机动车检测的新YOLO 网络模型。本文的主要工作:
(1)新YOLO 网络模型在原有YOLOv3 模型的基础上,采用了双重特征提取网络结构。采用规模为13×13,26×26,52×52的骨干网络,配置不同特征提取的接收域辅助网络;
(2)辅助网络和骨干网络的特征信息融合采用注意机制,重点对有效特征通道进行处理,抑制无效信息通道,提高网络处理效率。
与YOLOv3 相比,优化后的网络检测能力得到了提升,但由于辅助网络的增加,计算量也会增加,影响了检测时间,但仍可满足实际应用的条件。为了进一步提升网络的检测应用能力,可以使用边缘计算,将模型用于嵌入式设备,推动无人车智能驾驶技术发展。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
故事作文·高年级(2022年2期)2022-02-24
读者·校园版(2019年18期)2019-09-09
汉语世界(The World of Chinese)(2018年5期)2018-11-24
电机与控制学报(2018年9期)2018-05-14
小猕猴智力画刊(2017年6期)2017-07-03
计算机应用(2016年10期)2017-05-12
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
软科学(2014年8期)2015-01-20
