
基于互联网数据的消费者信心指数滚动预测研究
2021-11-29 10:43朱建霖李挽澜
西安交通大学学报(社会科学版) 2021年6期
孙 景,朱建霖,李挽澜,高 哲
(西安交通大学 经济与金融学院,陕西 西安 710061)
投资、出口和消费是拉动中国经济增长的三驾马车。受新冠肺炎疫情的影响,世界经济遭遇重创,国际贸易受到影响。2020年5月14日,中共中央政治局常务委员会会议首次提出“深化供给侧结构性改革,充分发挥我国超大规模市场优势和内需潜力,构建国内国际双循环相互促进的新发展格局”。中国是人口大国,蕴含着有无限可能的消费市场,通过提升消费者信心拉动消费,以国内新需求替代外部需求滞纳产能,才能真正实现经济内循环,保持GDP的持续增长。消费者信心指数(Consumer Confidence Index,CCI)是预测经济走势和消费倾向的指标,它综合反映并量化消费者对当前及未来经济形势、收入水平及收入预期的判断,以及消费心理状态的主观感受等,是衡量市场经济条件下居民消费动向的重要参数。及时准确地统计和预测消费者信心指数,对预判消费及宏观经济形势、调整宏观经济政策都具有重要的现实意义。
20世纪40年代,美国密歇根大学调查研究中心的Katona[1]最早提出了消费者信心指数的概念与方法。中国国家统计局于1997年开始在全国范围内开展消费者信心指数的调查与编制。目前,中国消费者信心指数编制基于消费者电话问卷调查展开。该调查每月进行一次,通过电话问卷调查收集居民对经济环境与家庭收支的看法,问题涉及受访者对经济现状的看法、对未来生活的预期、对国民经济的估测等方面。然而,消费者调查需要经过问卷设计、样本抽取、调查访问、数据整理汇编等多个环节,耗费较多的时间与人力物力资源,难以及时更新,其准确性与时效性面临挑战。
互联网时代,人们每天都会使用网络并产生大量数据,而这些数据为科学研究提供了新的数据来源。互联网的产生与应用为了解消费者心理与行为提供了新的途径,为提高消费者信心指数预测准确性与时效性提供了大量的优质数据。互联网数据种类繁多,本文将以互联网数据的两个典型代表:网络搜索关键词指数数据和网络新闻文本数据为依据,对消费者信心指数进行预测。
一、文献综述
国内外学者在利用网络搜索数据和网络新闻数据预测经济及消费者信心指数方面已经做了一些研究。
在利用网络搜索数据和新闻媒体数据进行经济预测的相关研究中,Ettredge等[2]利用网络搜索数据预测失业率,并发现与美国官方发布的失业率之间存在显著的正相关。Guzman[3]提出了一种基于谷歌搜索元数据的通胀搜索指数,能对通货膨胀率进行有效预测。Smith[4]根据“经济危机”“金融危机”和“衰退”等关键词的谷歌搜索量变化来预测外汇市场的波动。Choi等[5]利用谷歌趋势数据预测当下经济活动,指出经济学家、投资人、财经记者每月都在关注政府发布的经济运行情况报告,但这些报告的发布普遍滞后。而谷歌每天都在产生大量与经济发展相关的搜索数据,而与此相关的搜索行为与当下的经济活动之间必然存在不容忽视的关系,或许可以对预测当下的经济活动起到非常重要的作用。在此基础上,文章还举例说明了如何利用谷歌趋势预测美国零售业、汽车、住房和旅游销售情况等。Thorsrud[6]将挪威主要商业报纸分解成若干个新闻主题,对GDP进行季度预测,预测效果最多可提升15%。
我国研究者张崇等[7]发现网络搜索数据与居民消费价格指数(CPI)之间存在一定的先行滞后关系。他们建构的模型具有很强的时效性,比国家统计局的数据发布提前一个月左右,而且与传统的预测方法相比,模型还具备一定的转折点预测能力。彭庚等[8]利用网络搜索数据,采用改进的逐步回归方法分层建立了三个模型来预测失业率。结果发现,三个模型的拟合优度均在90%以上,说明网络搜索数据对经济、社会问题可以进行有效的预测。董倩等[9]基于百度搜索数据对全国16个城市的二手房价格和新房价格进行了拟合和预测,结果发现网络搜索数据不但能很好地预测房价指数,而且比官方数据发布提前了两周,具有很强的时效性。薛晔等[10]建立决策树—BP神经网络模型,在百度指数的基础上加入了上证综合指数、国际油价、人民币兑换美元汇率等指标,对月度通货膨胀综合指数进行预测,短期预测效果良好,预测结果可靠性有明显的提高。
在利用网络搜索数据和新闻媒体数据预测消费者信心指数的相关研究中,Alsem等[11]发现新闻媒体中的经济形势评论会对消费者信心产生短期影响。Penna等[12]使用谷歌趋势数据构建了美国消费者情绪指数,发现其与密歇根大学发布的消费者情绪指数以及美国咨商局发布的消费者信心指数具有高度相关性,且在时间上领先,可以预测另外两种指数。Vosen等[13]利用与消费相关的谷歌趋势数据建立的消费月度指标成果预测了美国消费者信心指数,其预测效果优于调查数据。
我国研究者孙毅等[14]利用八个行业相关商品的百度指数数据构建了消费者信心指数,并领先于宏观经济景气一致指数6个月,对社会商品零售总额的长期趋势判断更加准确,对短期波动的预测精度更高。刘伟江等[15]通过搜集与消费者信心指数构成相关的中国台湾地区关键词搜索量,运用主成分分析方法合成搜索指数并对该地区消费者信心指数进行预测,研究表明搜索指数与消费者信心指数之间存在长期稳定协整关系,模型拟合程度高、时效性强且具备转折点预测的能力。董现垒等[16]利用百度指数数据对我国消费者信心指数进行了预测,取得较好的效果。刘伟江等[17]利用网络关键词搜索数据生成了网络消费者信心指数(WCCI),以规模以上企业工业增加值(IP)作为测量经济增长的量化指标,其研究表明WCCI与IP之间存在显著的动态相关关系。刘苗等[18]利用百度搜索采集了约17万条新闻,并通过文本挖掘获取新闻的情感倾向,以此为基础构建了新闻消费者信心指数。新闻消费者信心指数与传统消费者信心指数的相关性较高,且对消费短期趋势的判断更加明显。唐晓彬等[19]基于机器学习长短时间记忆神经网络模型,结合相关网络搜索数据构建预测模型对我国消费者信心指数长、中、短期进行了预测,预测结果表明引入网络搜索数据能够提高神经网络模型的预测性能与预测精度。国内外针对利用互联网数据预测消费者信心指数的研究表明,互联网数据本身具有样本量大、时效性强、精准度高、获取成本低等优点,利用互联网数据可以提高预测的时效性和准确性。
无论是网络搜索行为还是网络新闻都具有时效性强的特点,通过以往研究中的特征关键词“静态”筛选方法都难以满足消费者信心指数预测建模准确性需求。本文将挖掘网络新闻语义特征关键词并获取相应的百度搜索指数作为消费者信心指数预测建模的数据基础,通过时间窗口的设置与滑动,滚动筛选预测建模的关键词解释变量,使变量选择更具时效性,利用多种机器学习及回归方法建立提前1~4个月的消费者信心指数预测模型,根据准确率对预测模型进行筛选,通过分析比较宏观经济指标数据和互联网数据在预测建模中的表现,给出不同类型数据在消费者信心指数预测建模中的应用建议。
二、机理分析
消费者信心指数是反映消费者信心强弱的指标。消费者信心既受宏观经济因素的影响,也受消费者个体的微观因素影响。宏观经济发展形势向好,居民收入水平提高,社会消费品日益增多,才能保持或提升消费者信心。经济运行、消费结构、物价水平、货币政策等宏观因素都能对消费者信心指数产生影响。宏观经济指标是否达到消费者的预期水平,会影响消费者对现状的满意程度和对未来的预期。此外,宏观经济的发展状况会影响消费者的消费需求,从而影响消费者信心。个人收入、消费态度、投资策略、家庭开支与经济预期等是影响消费者信心的个体微观因素,这些因素会直接影响消费者的消费情绪及消费行为。
网络新闻具有更新快、内容全等特点,它突破了传统媒介的束缚,让人们更便捷地接触新事物,传播热门话题。随着移动互联网的普及,网络新闻受众不断增多,网络新闻内容对大众情绪、社会心理的影响力不断增强。网络搜索行为不仅与人们的现实需求与客观环境相关,还受到人们对事物的主观认知与心理偏好的影响。而消费者信心也受客观因素与主观因素的影响。消费者在产生消费需求、开展信息收集与购买决策时,往往会阅读网络新闻和使用搜索引擎。消费者可以通过财经类新闻了解经济运行、消费结构、物价水平、货币政策等宏观经济形势与政策。在购买商品时,消费者也会通过搜索引擎查找合适的产品,判断商品的购买时机与价格是否合理等。此外,当消费者遇到就业、收入以及投资理财等相关问题时,也可以通过网络搜索引擎获取相关信息。因此,浏览网络新闻或搜索网络信息已经成为消费者判断宏观经济形势、辅助消费决策的重要手段。无论是消费者信心指数的宏观影响因素还是微观影响因素的变动,都可以通过以网络新闻数据与搜索引擎数据为代表的互联网数据进行捕获,并通过关键词搜索指数的形式体现出来。互联网数据与消费者信心指数的关联机理如图1所示。

图1 互联网数据与消费者信心指数的关联机理
三、数据获取与预处理
为了收集与消费者信心指数预测有关的互联网数据,本文首先基于微观因素分析,确定若干个重要的初始关键词数据。然后以初始关键词为基础,采集相关的网络新闻数据,形成网络新闻语料库,并对网络新闻文本数据进行分词处理,通过TF-IDF值词汇重要性度量,筛选网络新闻热点词,通过建立词向量模型从网络新闻中筛选初始关键词的近似词,通过百度搜索引擎需求图谱得到初始关键词的相关词,将初始关键词及以上三类拓展关键词合并,形成网络关键词库,并获取每个关键词的日均百度指数数据。最后对数据进行缺失值填补、异常值处理和频率转换等预处理。互联网数据的获取与预处理流程如图2所示。
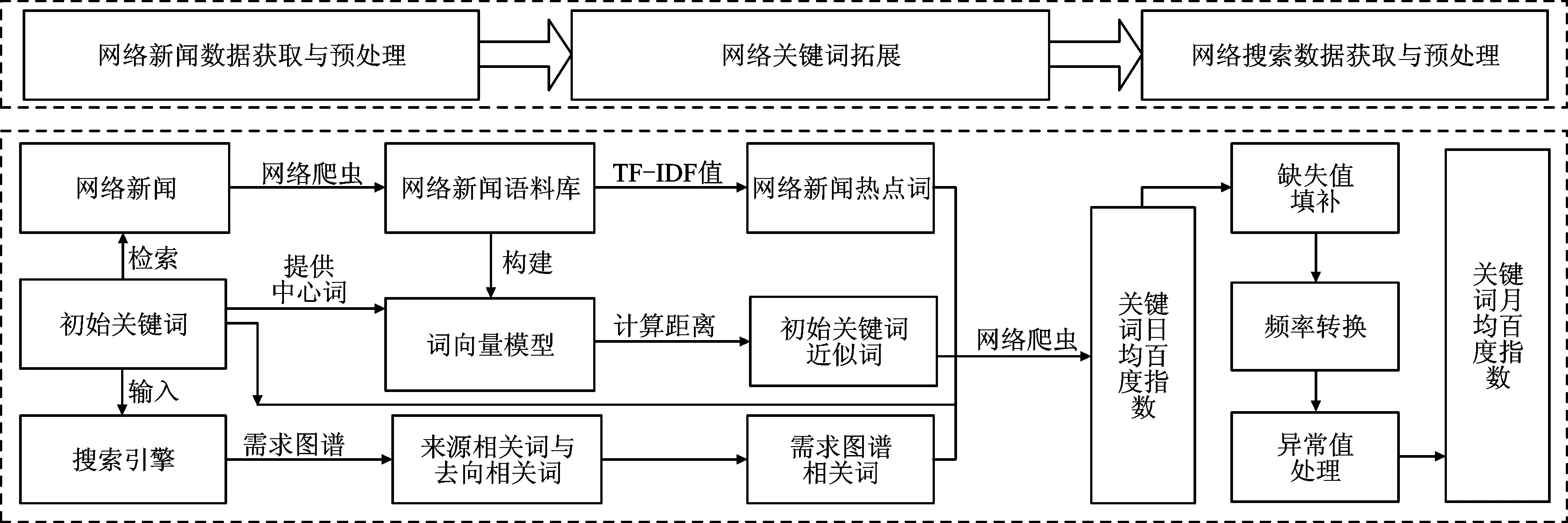
图2 互联网数据的获取与预处理流程
(一)初始关键词的确定
基于互联网数据与消费者信心指数的关联机理分析,本文考虑了个人收入、消费态度、投资策略、家庭开支、经济预期共五个微观因素,确定了“收入”“就业”“购物”“消费”“投资”“物价”“经济”7个初始关键词。
(二)网络新闻数据的获取与预处理
作为国家重点新闻网站,人民网以新闻报道的权威性、及时性和多样性为特色,能全面反映我国社会经济的现实情况,因此本文以人民网新闻作为网络新闻数据的数据源。首先,采集人民网与“收入”“就业”“购物”“消费”“投资”“物价”“经济”7个初始关键词有关的网络新闻共计7 134篇,采集的数据包括新闻的时间、标题与新闻内容文本,并根据这些数据建立网络新闻语料库。其次,对新闻文本数据进行分词处理,词汇是中文语言表达含义的基础,因此分词也是进行中文文本处理的必要环节,本文所使用的分词工具为python开源工具jieba分词。最后,利用TF-IDF值度量词汇重要性,在分词结果中筛选出网络新闻热点词,形成网络新闻热点词库。本文筛选了网络新闻语料库中TF-IDF权重较大的100个词汇作为网络新闻热点词。
(三)初始关键词的近似词筛选
除了网络新闻热点词,在网络新闻语料库筛选出与7个初始关键词近似程度较高的词汇,作为初始关键词近似词,加入网络关键词库。为了度量词汇间的近似度,本文构建了词向量模型,基于语义对网络新闻文本词汇进行向量化表示,并通过计算初始关键词向量与其他词汇向量的余弦距离,衡量网络新闻文本词汇与初始关键词的近似程度,并针对每个初始关键词,选取与其最接近的10个网络新闻文本词汇,作为初始关键词的近似词。本文采用python开源工具gensim中的Word2Vec词向量模型实现新闻文本词汇的向量化表示。在Word2Vec词向量模型训练中,设定的参数见表1。

表1 Word2Vec词向量模型参数
经训练后,可以得到在网络新闻语料库中出现4次以上的新闻文本词汇的向量化表示,每个词汇对应一个400维向量,可以通过余弦距离判断两个词汇之间的近似程度。本文首先从词向量训练结果中获取7个初始关键词的400维词向量,其次计算每个初始关键词与其他网络新闻文本词汇之间的余弦距离,最后选取余弦距离值较大的前10个网络新闻文本词汇作为初始关键词近似词,加入网络关键词库。
(四)基于需求图谱的初始关键词相关词获取
通过百度指数平台自带“需求图谱”的相关检索词进行关键词拓展。本文根据百度指数平台的“需求图谱”与“关键词相关性分类”,围绕“收入”“就业”“购物”“消费”“投资”“物价”“经济”7个初始关键词拓展了70个关键词作为需求图谱相关词,加入网络关键词库。
(五)网络关键词百度搜索指数的获取与预处理
通过理论分析与关键词拓展,获取了初始关键词、网络新闻热点词、初始关键词近似词、初始关键词相关词共四类关键词,形成网络关键词库,再利用网络爬虫获取关键词日均百度指数。
由于互联网数据产生机制复杂多变,数据质量参差不齐,可能存在缺失值、异常值情况,因此本文根据关键词百度指数缺失率情况,丢弃缺失率高于5%的数据,并对剩余关键词日均百度指数缺失数据利用拉格朗日插值法进行填补。
由于消费者信心指数数据是月度数据,因此要对作为消费者信心指数预测变量的网络关键词数据进行频率转换,即将关键词日均百度指数转换为月均百度指数。假设M月有m天,关键词X在M月的日均百度指数为x1,x2,…,xm,则其在M月的月均百度指数为(x1+x2+…+xm)/m。
(六)对关键词月均百度指数的异常值进行处理
通过标准差与平均值之比计算每个关键词的月均百度指数变异系数。统计结果表明,网络关键词库中的关键词月均百度指数变异系数均低于4,且大部分关键词低于3,数据离散程度并不高,可以采用均值加减3倍标准差作为正常值的上下界。对超出上下界的做异常值处理,即超出上界的用上界值替换,超出下界的用下界值替换。
四、变量筛选机制设计
本文将以网络关键词百度指数作为解释变量,消费者信心指数作为被解释变量建立回归模型以实现对消费者信心指数的预测。随着时间的推移,要在不同的预测时点筛选出不同的预测建模解释变量。无论是网络新闻热点词还是网络关键词搜索量都会随时间的变化而变化,作为候选解释变量的许多关键词与某些时点的消费者信心的相关性较弱,不宜作为解释变量;部分关键词百度指数之间可能存在多重共线性,要通过关键词取舍来消除此类问题;如果将网络关键词库的所有关键词作为解释变量,维度过高无法建模,因此也需要对关键词进行筛选。由此可见,从网络关键词库中筛选解释变量是滚动预测建模的必要环节,解释变量筛选机制如图3所示。

图3 解释变量筛选机制
作为候选解释变量,网络关键词库中关键词与消费者信心指数均有一定的相关性,称为特征变量。本文使用滚动预测方法,在每一个预测时点分别建立提前1个月、2个月、3个月和4个月的消费者信心指数预测模型,因此从网络关键词库中筛选解释变量的过程中,也需要采用窗口滑动的模式,分别生成4个解释变量集合。为了提升预测精度,不仅要考虑特征变量的当期数据与消费者信心指数历史数据之间的相似程度,还要考虑特征变量滞后1~11期的数据与消费者信心指数历史数据之间的相似程度。因此,需要将特征变量滞后期数据也加入解释变量的筛选,并筛选出与消费者信心指数历史数据相似性最高的滞后期数据作为该特征变量的数据参与建模。
在特征变量的相似性检验过程中,本文分别通过皮尔森相关系数、K-L信息量、均值哈希与差值哈希等方法检验领先1~4个月的消费者信心指数历史数据与特征变量的当期及滞后1~11期数据的相似程度,并将相似度高的特征变量选为建模解释变量。通过特征变量相似性检验筛选解释变量的具体步骤如下:(1)计算特征变量与消费者信心指数历史值之间的皮尔森相关系数,并将相关性最高的3个特征变量选为预测建模解释变量。(2)进一步计算剩余特征变量与消费者信心指数间的K-L信息量,并将K-L信息量绝对值最小的前3个特征变量选为预测建模解释变量。(3)分别针对均值哈希值和差值哈希值进一步计算剩余特征变量与消费者信心指数间的汉明距离,并分别筛选出汉明距离最小的2个特征变量作为预测建模解释变量。通过以上步骤筛选出10个预测建模解释变量。
除了将相似性检验排名靠前的10个特征变量选入预测建模解释变量,还需要将部分与消费者信心指数相似程度较高,但未选入预测模型解释变量的特征变量通过随机森林进行建模,得到变量重要性程度。在皮尔森相关系数分析、K-L信息量分析、均值哈希分析、差值哈希分析中任意一种相似性检验排名在前10名的变量,才有机会加入随机森林模型。随机森林将随机生成特征变量子集构建决策树,通过不同决策树的表现判断各个特征变量的重要性程度。本文通过随机森林筛选出重要性程度最高的2个特征变量加入预测建模解释变量。在建立每一个消费者信心指数预测模型时,都需要先通过以上机制筛选出12个解释变量。
五、预测模型的建立与选择
本文以国家统计局公布的消费者信心指数为预测目标,基于上文所述的变量筛选机制从网络关键词库中滚动筛选解释变量,通过多种机器学习方法建立消费者信心指数预测模型,对2015年3月—2018年5月的消费者信心指数进行预测。滚动预测的每个时间窗口长度为24个月,初始窗口为2013年3月—2015年2月,结束窗口为2016年5月—2018年4月,共39个时间窗口,提前1~4个月滚动预测了2015年3月—2018年5月共39期消费者信心指数。
在python的sklearn模块中提供了多种函数用来支持模型的建立与评估,本文选取了袋装树回归、随机森林回归、极端随机树回归、梯度提升树回归、自适应提升树回归、多层感知机回归、支持向量回归、岭回归、Lasso回归、弹性网回归、主成分回归、偏最小二乘回归等共12类方法建立消费者信心指数预测模型,这12类模型的类型、名称和sklearn建模函数见表2。
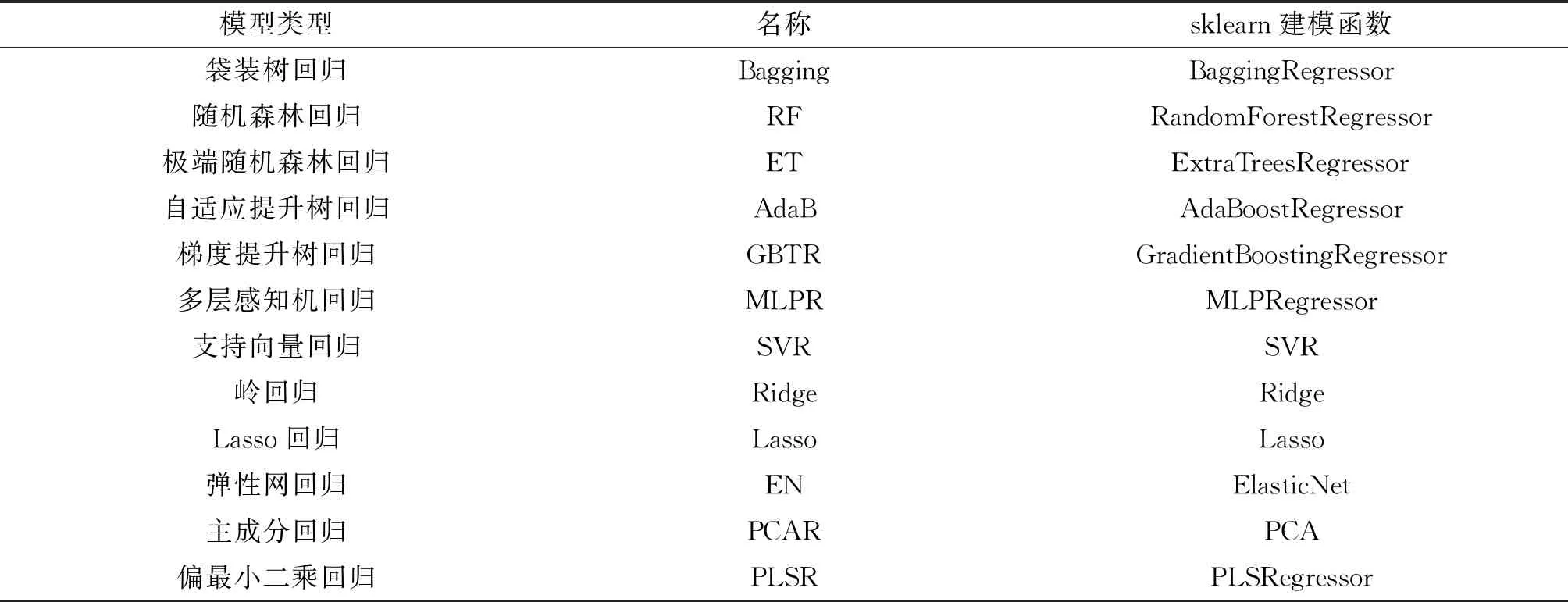
表2 模型类型、名称和sklearn建模函数
本文采用均方误差(Mean-square Error,MSE)评价模型的预测效果。MSE对预测误差的极大、极小值反应灵敏,能够度量预测的精度,MSE值越低,模型的精度越高。为了更好地比较不同模型的预测效果,本文对部分类别的模型设置了多组超参数,并建立多个模型进行实验。超参数是指根据不同建模算法的具体要求所设定的参数。在每一次建模过程中,一般需要设定一组超参数,有些模型是敏感于超参数组合设定的,如果超参数组合设定不恰当,会使得模型的性能下降。本文利用网格搜索法确定超参数,在充分理解每一种模型及超参数预含义的基础上,结合样本数量与预实验效果,确定每个超参数的取值范围、个数及具体数值,并通过穷举法对模型中的多个超参数值进行组合实验,根据模型的MSE值最终选出最优的超参数组合及模型。例如,通过分析判断模型M有k1和k2两个超参数需要设置,利用网格搜索法分别为k1和k2确定n1和n2个有代表性的具体参数值,则模型M的实验超参数组合总数为n1×n2个,即可以训练出n1×n2个模型,最终选出最优的超参数组合及模型。本文在建模实验过程中为12类模型设定的超参数情况见表3,未说明的超参数均取sklearn模块默认值。
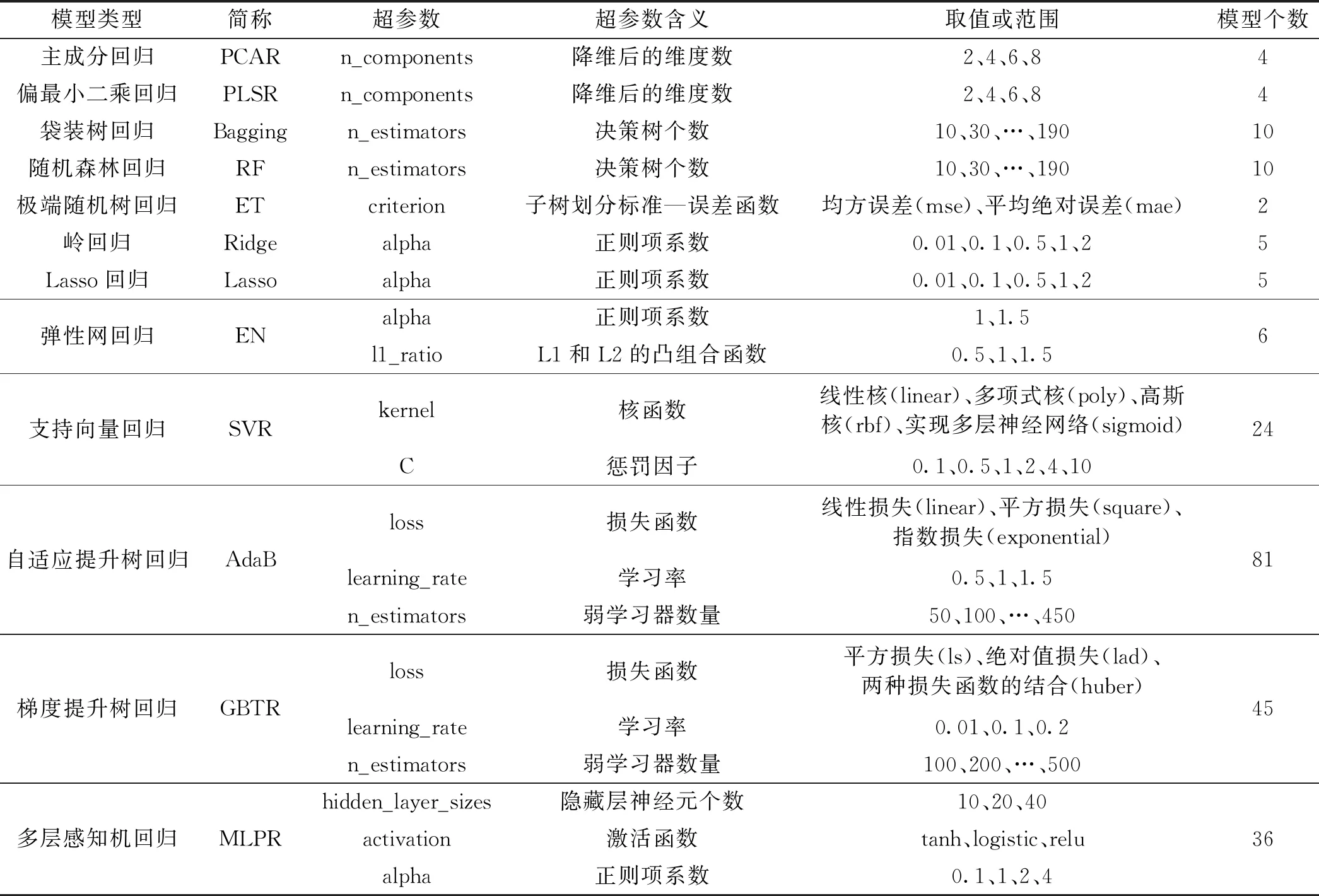
表3 消费者信心指数预测模型超参数设定
根据MSE值,对提前1~4个月的消费者信心指数预测模型前12名进行了排序,结果见表4。

表4 消费者信心指数预测模型MSE值
实验结果表明,提前1~4个月表现最好的预测模型分别是自适应提升树回归模型(AdaB)、Lasso回归模型(Lasso)和多层感知机回归模型(MLPR),预测模型的均方误差值分别是8.146、8.048、8.192和5.989。另外,极端随机树回归模型(ET)在所有提前期的预测表现中都是最差的,不建议使用该方法进行建模。
各模型在不同提前期下预测的MSE值比较,如图4所示。总体来讲,自适应提升树回归模型(AdaB)、多层感知机回归模型(MLPR)和Lasso回归模型(Lasso)预测误差值相对较小。自适应提升树回归模型在提前1~2个月的消费者信心指数预测中表现最好,其次是Lasso回归模型。在提前3~4个月的消费者信心指数预测中多层感知机回归模型和Lasso回归模型表现最好,其次是自适应提升树回归模型。

图4 各模型在不同提前期下预测的MSE值比较
大部分预测模型出现了预测提前期数越多模型的MSE值越低的情形。整体上看,提前4个月的预测模型精度要明显高于其他提前期的预测精度。由于微观因素的变动需要一定的时间才能传导至宏观层面,因此网络搜索行为对消费者信心指数的影响具有一定的滞后性。
六、预测模型比较
传统的消费者信心指数预测往往是以相关的经济指标作解释变量构建模型。为了比较互联网大数据与宏观经济数据对消费者信心指数的预测能力,本文分别以互联网大数据、宏观经济指标数据和二者综合数据为依据建立消费者信心指数预测模型。影响消费者信心的宏观经济因素主要包括经济运行、消费结构、物价水平、货币政策、经济景气调查、国际贸易等方面。依据这些宏观经济因素,本文选取了国家统计局公布的19个宏观经济指标,具体见表5。

表5 本文选取的宏观经济指标
在建立消费者信心指数预测模型时,将仅使用互联网数据建立的模型名加上前缀“b_”,即B类模型;将仅使用宏观经济指标数据建立的模型名加上前缀“m_”,即M类模型;将使用二者综合数据建立的模型名加上前缀的“mb_”,即MB类模型。不同类别模型的预测结果均能反映真实消费者信心指数时间序列趋势。3类最优模型提前4个月对消费者信心指数的预测结果如图5所示。
本文统计了各类预测模型在3种数据集下提前1~4期预测消费者信心指数的MSE值及排名,并筛选出不同数据集下提前1~4期预测的最优模型,结果见表6。
比较结果表明,在提前1个月预测消费者信心指数时,使用宏观经济指标数据的主成分回归模型(m_PCAR)表现明显比使用其他两类数据更出色;而在提前4个月预测消费者信心指数时,使用互联网数据的多层感知机回归模型(b_MLPR)表现最好;在提前2~3个月预测消费者信心指数时,使用综合数据的多层感知机回归模型(mb_MLPR)有更好的表现,但预测精度相对较低。在使用宏观经济指标数据的所有预测模型中,主成分回归模型(m_PCAR)在提前1个月预测时精度最高,随着预测期限跨度增加,自适应提升树回归模型(m_AdaB)和多层感知机回归模型(m_MLPR)也有较好的表现,但模型预测精度有所下降。在使用互联网数据的所有预测模型中,多层感知机回归模型(b_MLPR)在提前4期预测消费者信心指数时表现突出,在其他提前期的预测中,自适应提升树回归模型(b_AdaB)和Lasso回归模型(b_Lasso)都有所表现。
七、结语
浏览网络新闻或搜索网络信息已经成为消费者判断宏观经济形势、辅助消费决策的重要手段。本文提取人民网新闻中的特征关键词,以百度搜索关键词指数数据为基础,采用滑动时间窗口动态筛选解释变量,运用多种机器学习方法建立消费者信心指数预测模型。结果表明,自适应提升树回归模型在提前1~2个月的消费者信心指数预测中表现最好,其次是Lasso回归模型。在提前3~4个月的消费者信心指数预测中多层感知机回归模型和Lasso回归模型表现最好,其次是自适应提升树回归模型。提前4个月的预测模型精度要明显高于其他提前期的预测精度。
本文通过比较宏观经济指标历史数据、网络关键词搜索指数数据、二者综合数据三个数据集下的预测模型发现,相对于宏观经济指标数据而言,网络关键词搜索指数数据可以更早地“感知”消费者信心的变化。在预测短期消费者信心指数时,应当以宏观经济指标历史数据为主,而预测时间跨度增长时,为了吸纳更多微观因素变动信息,可以引入网络关键词搜索指数对预测模型进行补充。如果提前1个月预测消费者信心指数,建议选择使用宏观经济指标数据的主成分回归模型(m_PCAR);在提前2~3个月预测消费者信心指数时,使用综合数据的多层感知机回归模型(mb_MLPR)有更好的表现;提前4个月预测消费者信心指数,建议选择使用互联网数据的多层感知机回归模型(b_MLPR)。
本研究旨在探索基于互联网大数据并利用大数据技术与方法进行消费者信心指数预测的有效性和时效性。研究结果表明,利用互联网数据建立的机器学习模型确实能更早地预测消费者信心指数,且具有较高的预测准确率。然而,互联网大数据预测也存在以下几个方面的问题:(1)大数据方法的基本思想是通过海量数据发现事物之间的相关关系而非因果关系,与传统预测模型相比许多大数据模型中变量的可解释性相对较差;(2)互联网大数据的复杂性和多变性会直接影响模型的稳定性,因此本研究的滚动预测也是为了探求解决此类问题的方法;(3)由于互联网数据本身的片面性,其预测准确性也会受到制约。因此,在统计数据完备的情况下,使用经过检验的传统预测模型如多元线性回归模型、ARMA模型等更加严谨和稳定。
除了本文研究的网络新闻和网络搜索数据外,还可以尝试将社交媒体、电商交易和招聘求职等互联网数据引入大数据预测模型,以期进一步提高预测的准确率。为了优化传统预测模型,可以将互联网数据合成的相关变量引入模型,并检验其是否能够提高消费者信心指数预测准确性。
猜你喜欢
中华魂(2022年10期)2022-10-19
房地产导刊(2022年5期)2022-06-01
成都信息工程大学学报(2021年5期)2021-12-30
民主(2021年11期)2021-11-12
天津外国语大学学报(2021年3期)2021-08-13
天津外国语大学学报(2021年1期)2021-03-29
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
文苑(2020年10期)2020-11-22
科学导报·学术(2020年27期)2020-07-20
初中生世界·九年级(2020年2期)2020-04-10
