
一种基于公平性的无人机基站通信智能资源调度方法
2021-11-28 03:45吴官翰赵建伟高飞飞
中兴通讯技术 2021年2期
吴官翰 赵建伟 高飞飞
摘要:空天地一体化网络是未来6G的关键内容。结合高精度波束赋形,无人机(UAV)的视距链路(LoS)可很好地作为空天地一体化网络的补充,但地面用户与基站间的相对运动极易造成信道容量失衡。提出一种噪声深度确定性策略梯度(Noisy-DDPG)方法。该方法以最大化通信公平性和系统容量为目标,利用DDPG优化分配方案,通过调整奖励函数策略参数来实现公平性和信道容量的平衡;通过在策略网络中利用可学习参数噪声进行扰动,得到更合理的分配方案。仿真实验验证了该算法的有效性。
关键词:无人机基站;资源调度;DDPG;公平通信;参数噪声
Abstract: The space-air-ground integrated network is an important part of the future 6G, which can be well complemented by the unmanned aerial vehicles (UAV) line-of-sight(LoS) link combined with high-precision beamforming. However, the random channel characteristics of mobile users can easily cause channel capacity imbalance. In this paper, the Noisy-Deep Deterministic Policy Gradient (Noisy-DDPG) is proposed. To maximize communication fairness and system capacity, the Deep Deterministic Policy Gradient(DDPG) is used to optimize the allocation strategy. Besides, fairness and channel capacity are differently emphasized by adjusting the reward function policy parameters. Moreover, the learnable parameter noise is used to disturb the policy network to obtain a more reasonable allocation plan. Finally, various simulation results to verify the effectiveness of the algorithm are proposed.
Keywords: UAV base station; resource allocation; DDPG; fair communication; parameter noise
研究表明,預计到2030年,以固定基站为主的5G移动通信将无法满足日益增长的数据业务需求,大量新生业务将产生海量数据资源,物理世界与数字世界之间的界限将更为模糊[1]。在此背景下,集中式的数据处理中心将承受更为巨大的压力,遥远的云端服务器也不利于满足远端用户低时延的数据处理需求。
无人机作为移动载体,可搭载5G/超5G(B5G)通信基站或边缘服务器,并结合高精度的波束赋形形成指向性强、增益高的窄波束,以减少邻居干扰,有效克服毫米波及以上频段射频信号衰减巨大这一现实问题[2-3]。将无人机基站作为未来空天地一体化网络的中间节点,卸载部分用户通信与计算任务,成为一种具有潜力的组网方式[4]。在一个无人机小区中,用户的随机移动将带来不可预知的动态拓扑结构,基站单一的带宽、功率分配策略往往会造成小区内信道容量失衡。一种合理的通信资源分配机制能够有效提升用户通信的公平性,并最大化系统平均信道容量。
近年来,人工智能在自动控制、目标识别、语义识别等领域大放异彩,极大地推动了各行业的进步与发展。将人工智能与通信技术有机结合,是未来5G和6G的一个发展方向。深度强化学习(DRL)[5-7]具有强大的特征提取和多维决策能力,能够针对通信资源多维度的特点,做出最明智的动作决策,为无人机基站资源调度决策提供了可能[8-10]。现有研究大多集中于无人机路径规划、系统信道容量优化等方面,以满足用户最低服务质量(QoS)需求,但未考虑用户通信的公平性需求[8]和移动通信本身巨大的能量消耗[9]。
为解决信道容量失衡的问题,本文提出了一种基于公平性的噪声深度确定性策略梯度(Noisy-DDPG)无人机基站功率、带宽调度方法,在传统DDPG基础上结合可学习参数噪声扰动方式进行前期探索,使噪声方差依据梯度下降自适应调整;通过将训练好的策略模型用于无人机基站通信的实时部署,为任意分布的地面用户提供合理的通信资源分配方案。和传统DDPG训练方式相比,NoisyDDPG表现出更优秀的性能:在达到相同公平指数条件下可以获得更高的系统平均信道容量。
1系统模型与问题建模
如图1所示,在边长为D的正方形区域内,我们将单无人机基站悬停在目标区域上空,从功率和带宽两个维度,对N个运动的地面用户进行动态资源调度,在满足用户公平通信的同时最大化平均信道容量。我们定义Ptotal和Btotal分别为无人机基站总发射功率和可用带宽,以频分复用方式对用户进行带宽分配,在保证公平性的同时最大化平均信道容量。
1.1空地信道模型



公式(10)、(11)为总资源的约束,公式(12)为每个用户的最小带宽需求。值得注意的是,由于基站到每个用户的路径损耗不同,无人机在保证公平通信时势必会在资源分配上略微向边缘用户倾斜,从而提升其信道容量;但是从整个通信系统来看,这可能会影响平均信道容量的提升。因此,公平指数f (t)和平均信道容量Cmean无法同时达到最大化,在不同场景下便需要考虑不同的侧重。
2基于Noisy-DDPG的资源调度算法
传统方法可采用遗传算法、粒子群算法、模拟退火算法等启发式算法解决以上的问题,但这一类算法一般用于通信资源实时调度,在每个时隙间隔均需要针对不同拓扑进行迭代。这不仅需要较多的计算开销,还需要大量的时间成本,不利于有实时性需求的优化。DRL是利用训练有素的神经网络模型,完成当前状态到最佳决策动作的直接映射,在实时控制决策方面具有优良特性。利用DRL的泛化能力能够处理未训练过的类似状态。
2.1资源调度的MDP模型
强化学习是建立在马尔可夫决策过程(MDP)基础之上,通过优化(st,at,rt,st)轨迹、最大化Bellman方程得到的累积奖励。其中,st为t时刻状态,at为决策动作,rt为采取动作后的单步奖励,st为采取动作后转移到的下一个状态。MDP通常由(S,A,P,R,γ)进行定义,S 为状态空间,A 为动作空间,P 为状态转移矩阵,R 为奖励空间,γ为折扣因子(代表智能体对未来奖励的重视程度)。

2.2 DDPG算法
深度Q网络(DQN)算法开创了DRL先例,即用神经网络解决无限维的状态映射问题。传统DQN这类基于价值的强化学习算法只能处理离散有限的动作空间,而DDPG算法利用Actor-Critic模式和确定性策略梯度的方式解决了连续动作空间输出的问题。
DDPG算法中定义了4个神经网络结构,Actor现实网络和Actor目标网络的结构相同,Critic现实网络和Critic目标网络的结构相同。作为策略网络,Actor网络用来为当前状态输出决策动作;作为评估网络,Critic网络用来评价Actor输出的策略,拟合Q(st,at)函数,并用θμ、θμ分别表示Ac? tor现实网络参数和目标网络参数,θQ和θQ分别表示Critic现实网络参数和目标网络参数。对于Critic网络的更新,我们定义其损失函数为:
2.3 Noisy-DDPG算法
在DRL的训练过程当中,通常需要在训练前期添加一定的不确定性来丰富经验,探索更充分的样本空间,以使智能体学习更加全面。当前,DDPG通常采用给输出的动作施加衰减的高斯噪声来进行探索。相比于在策略网络的输出中添加噪声的方式,在神经网络权重中添加参数化噪声能够实现更加全面的探索[5]。

3仿真实验及对比分析
本次实验中,动作噪声是在输出的动作上直接加入不断衰减的高斯噪声,并使其满足公式(15)、(16)的约束,以形成合法决策。我们通过在训练前期引入动作的不确定性来获取更加多样性的经验样本。参数噪声是直接扰动神经网络参数,使网络通过学习自适应调整噪声参数。
3.1实验参数设置
3.2实验结果及对比分析
为满足不同场景对公平指数的要求,可在训练前设置不同的参数λ。λ越大,通信的公平性越能得到重视,用户之间的理论信道容量差异则越小。但過大的λ则会导致无人机基站减少对通信系统信道容量的考虑,在追求高公平指数的同时在一定程度上忽略了系统内部资源合理调度对平均信道容量的影响。因此,在设置λ时需要调整好对信道容量公平性与系统平均信道容量的侧重关系。
图2为训练累积奖励变化情况,图3与图4分别为在不同λ时收敛到的平均公平指数的变化情况和平均信道容量的变化情况。图2—4都反映了在λ=1、5、10时,无人机基站对通信系统公平性和平均信道容量的不同侧重。从图2可以发现,在所有λ下,参数噪声训练方式相对于传统动作噪声方式能收敛到更高的累积奖励,从而验证了所提方法的优越性。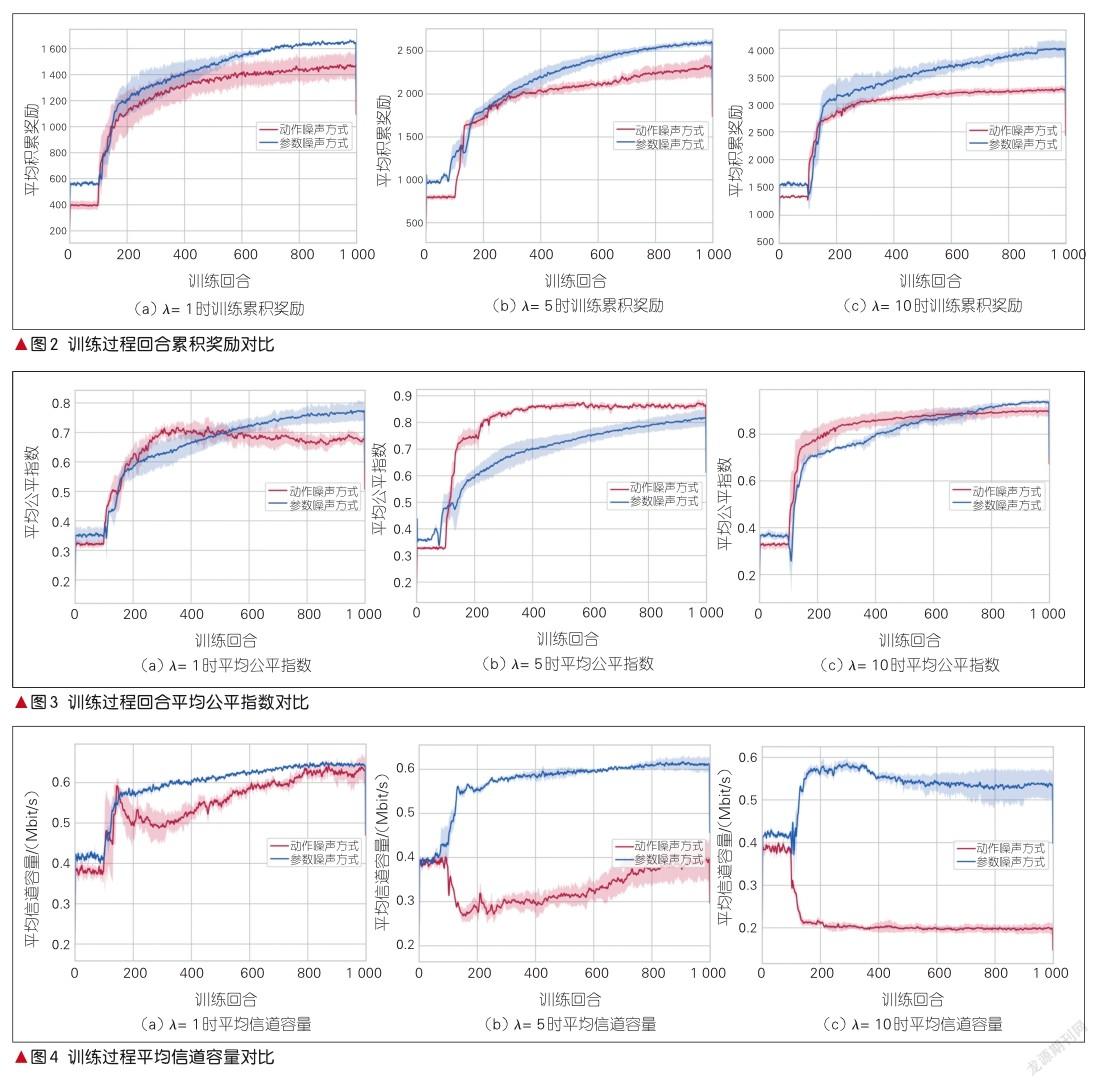
在图3和图4中,λ= 1时参数噪声方式的公平指数最终收敛到0.79,平均信道容量收敛到0.65 Mbit/s,动作噪声DDPG方式的公平指数收敛到0.68,平均信道容量收敛到0.64 Mbit/s。分析实验后我们发现:在训练后期,动作噪声方式的公平指数有所下降,而平均信道容量有所回升。这是因为在训练后期,该方式放松了对公平指数的追求,将通信资源倾向于距离较近的用户,以公平性的下降换取平均信道容量的提升。反观参数噪声DDPG方式,各项指标提升均较为稳定。λ= 5时参数噪声DDPG方式的公平指数最终收敛到0.84,平均信道容量收敛到0.62 Mbit/s,而动作噪声DDPG方式的公平指数最终收敛到0.87,平均信道容量收敛到0.43 Mbit/s。可以发现,此时动作噪声的方式更倾向于追求公平指数带来的奖励,而忽略了系统内部资源合理调度对平均信道容量的影响。这导致动作噪声方式所收敛的累积奖励低于参数噪声方式,而参数噪声方式却能在保持公平指数的同时保证了平均信道容量的大小,很好地平衡了两者的关系。在λ=10时,两种方式均倾向于公平指数带来的高回报:参数噪声方式公平指数最终收敛到0.94,平均信道容量收敛到0.55 Mbit/s;动作噪声方式公平指数收敛到0.90,平均信道容量收敛到0.21 Mbit/s。因为追求高公平指数,两种方式在平均信道容量上均会有所降低。但是参数噪声方式显然在分配方面更加合理,在达到相同公平指数的前提下能够保证更好的平均信道容量,从而可以带来更高的收益。
4结束语
针对未来空天地一体化网络中无人机辅助通信的多维资源调度公平性问题,本文提出了一种名为Noisy-DDPG的资源分配策略模型训练方法。这种方法适用于无人机搭载5G大规模天线阵列辅助地面移动通信的场景。在不同公平性需求下,通过调节奖励函数参数λ来实现公平指数与平均信道容量不同程度侧重,以使多维通信资源分配得更加合理高效。在模型训练时,采用一种可学习的自适应分解高斯噪声对输出策略进行扰动,使DDPG算法能够在训练中进行更深层次的探索。相比于传统动作噪声的探索方式,本文所提的方法能够获得更好的效果,仿真实验也进一步验证了方法的有效性。
致谢
本文的部分研究成果和撰写指导得到火箭军工程大学贾维敏教授的帮助与鼓励,在此谨致谢意!
参考文献
[1] YOU X H, WANG C X, HUANG J, et al. Towards 6G wireless communication networks: vision, enabling technologies, and new paradigm shifts [J]. Science China information sciences, 2021, 64(1): 110301. DOI: 10.1007/ s11432-020-2955-6
[2] MOZAFFARI M, SAAD W, BENNIS M, et al. Drone small cells in the clouds: design, deployment and performance analysis [C]//2015 IEEE Global Communications Conference (GLOBECOM). San Diego, CA, USA: IEEE, 2015: 1-6. DOI: 10.1109/GLOCOM.2015.7417609
[3] LI B, FEI Z S, ZHANG Y. UAV communications for 5G and beyond: recent advances and future trends [EB/OL]. (2019-06-11) [2021-01-22]. https: //arxiv.org/abs/1901.06637
[4] MISHRA D, NATALIZIO E. A survey on cellularconnected UAVs: design challenges, enabling 5G/B5G innovations, and experimental advancements [EB/OL]. (2020-03-14)[2021-01-23]. https: //arxiv.org/abs/2005.00781
[5] PLAPPERT M, HOUTHOOFT R, DHARIWAL P, et al. Parameter space noise for exploration [C]//Proceedings of International Conference on Learning Representations (ICLR). Vancouver, BC, Canada: ICLR, 2018
[6] FORTUNATO M, AZAR M G, PIOT B, et al. Noisy networks for exploration [C]//Proceedings of International Conference on Learning Representations (ICLR). Vancouver, BC, Canada: ICLR, 2018
[7] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning [C]//27st Conference on Neural Informa- tion Processing Systems (NIPS). Lake Tahoe, Nevada, USA: NIPS, 2013: 1-9
[8] GHANAVI R, KALANTARI E, SABBAGHIAN M, et al. Efficient 3D aerial base station placement considering users mobility by reinforcement learning [C]//2018 IEEE Wireless Communications and Networking Conference(WCNC). Barcelona, Spain: IEEE, 2018: 1-6. DOI: 10.1109/WCNC.2018.8377340
[9] LIU C H, CHEN Z, TANG J, et al. Energy-efficient UAV control for effective and fair communication coverage: a deep reinforcement learning approach [J]. IEEE journal on selected areas in communications, 2018, 36(9): 2059-2070. DOI: 10.1109/jsac.2018.2864373
[10] ZHANG Y, MOU Z Y, GAO F F, et al. UAV-enabled secure communications by multi-agent deep reinforcement learning [J]. IEEE transactions on vehicular technology, 2020, 69(10): 11599-11611. DOI: 10.1109/TVT.2020.3014788
作者簡介
吴官翰,火箭军工程大学在读硕士研究生、酒泉卫星发射中心助理工程师;主要研究方向为深度强化学习、无人机通信组网等。
赵建伟,火箭军工程大学讲师;主要研究方向为5G/B5G、无人机通信组网、深度强化学习等。
高飞飞,清华大学自动化系副教授、IEEE Fellow、国家自然科学基金委优秀青年项目获得者,担任多本知名刊物的编委;主要从事通信原理和智能信号处理技术在无线通信中的应用研究;获2018年中国通信学会青年科技奖、2017年中国通信学会自然科学奖二等奖(排名第1);发表论文160余篇。
