
基于投影法和卷积神经网络的手写汉字图像分割研究*
2021-11-26 05:43孟范泽刘思霖
电子技术应用 2021年11期
张 莉 ,孟范泽 ,刘思霖 ,冯 锐 ,王 钢 ,蔡 靖
(1.吉林大学 仪器科学与电气工程学院,吉林 长春 130026;2.北华大学,吉林 吉林 132013)
0 引言
随着科技的发展以及人们日常生活工作中对手写汉字识别的需求与日俱增,精确识别手写票据、手写试卷以及档案信息表等文件中的手写汉字,将会为社会带来极大的便利。然而,汉字类别繁多,字形结构复杂,一直是手写字体识别中的难点和热点[1],且个人手写汉字字体特点也不尽相同[2]。从文献[3]可以看出,随着所需识别汉字的数量以及神经网络复杂程度的提升,相应的计算时间也会呈指数形式提升[4-5]。由此可见,实现对手写汉字图像的有效分割,将会减少手写汉字的识别量,相应地也降低了手写汉字识别的复杂度与计算时间。
为了达到精准分割、有效识别的目的,本文建立了卷积神经网络(Convolutional Neural Networks,CNN)手写汉字识别模型。对投影法和轮廓检测法的适用性进行了对比分析,通过实验对投影法在手写汉字识别中的适用性进行了验证。
1 投影法
图像是由像素组成的,一幅M×N 个像素的数字图像,各像素点的灰度值构成M 行、N 列的矩阵[6]。图像被二值化后,有色像素点的灰度值变为1,无色像素点灰度值为0。二值图的灰度矩阵A 如式(1)所示:

首先需要对文字图像进行二值化处理,二值图像为白底黑字[7-8]。投影法基于这种二值图像的特点来对图片分割。用式(2)对每行的像素点进横向行投影,求得每行的黑色像素点数记为Sum(i)。

其中,Sum(i)中的首个非零元素即为文字图像的上边界,行号记为Row(k)=i,k=1。从Sum 中的i 号元素起对Sum中的元素遍历,并对x 号元素及x-1 号元素进行异或逻辑运算,结果每出现一次1,在Row(k+1)中记录x 的值,并将Sum(i)中最后一个不为0 的元素行号记录到Row中的最后一个元素,此为文字图像的下边界。遍历结束后,根据Row 中记录的行号,对图像进行分割并输出,即可分割出文字图像中的每行文字。
基于同样的原理,对分割好的每行文字图像进行纵向投影,并重复上述步骤,即可得到每行文字图像中的每个文字图像。
2 对比分析
2.1 基于CNN 卷积神经网络的手写汉字识别模型
本文使用基于MATLAB 的DeepLearning toolbox CNN卷积神经网络神经网络模型,针对分割算法的适用进行了研究[3],LeNet-5 经典CNN 网络架构原理图如图1所示。

图1 LeNet-5 经典CNN 网络架构原理图
在图1中,Input 为输入图像;C1、C3 为卷积层,其功能是对输入数据进行特征提取,每一个神经元都进行局部的特征提取,在更高层将其整理合并;S2 为采样层(池化层),池化层对卷积层提取出来的特征图进行池化处理,可以在减少数据处理量的同时保留有用信息,即对图像由高分辨率向低分辨的转换,通常卷积层池化层交替分布,使得特征图数目逐渐增多,分辨率逐渐降低;F5为全连接层,全连接层在卷积神经网络中可以看作是一个“组合器”,把卷积层提取的局部特征重新通过权值矩阵组装起来,形成完整的图像[9]。
针对手写体汉字的识别,本文采用的是MATLAB toolbox 中nnet/cnn 目录下的内置函数“Make predictions on data with network”,其运行结果界面如图2 所示,原图像与其识别结果均显示在界面图中。

图2 识别结果界面
2.2 对比分析
为了验证投影法的适用性,本文选用轮廓检测法[10-11]与投影法进行对比分析。轮廓检测法的基本原理是对二值化后的图片进行顶部和底部轮廓检测,获得文字高度。之后分别进行轮廓线的凹检测和凸检测,记录凹、凸轮廓处的位置,确认是凹或凸轮廓后,对图片进行分割,并保存为BMP 图片。本文选用如图3 所示大小为972×443 的手写汉字图片作为原始图像。

图3 原始图像
以图3 中的第一行文字为需要识别的目标汉字,分别使用投影法和轮廓检测法对行分割结果进行列分割,得到目标汉字图像,并对目标汉字图像进行归一化处理[12-14],送入CNN 神经网络模型进行识别,流程框图如图4 所示。
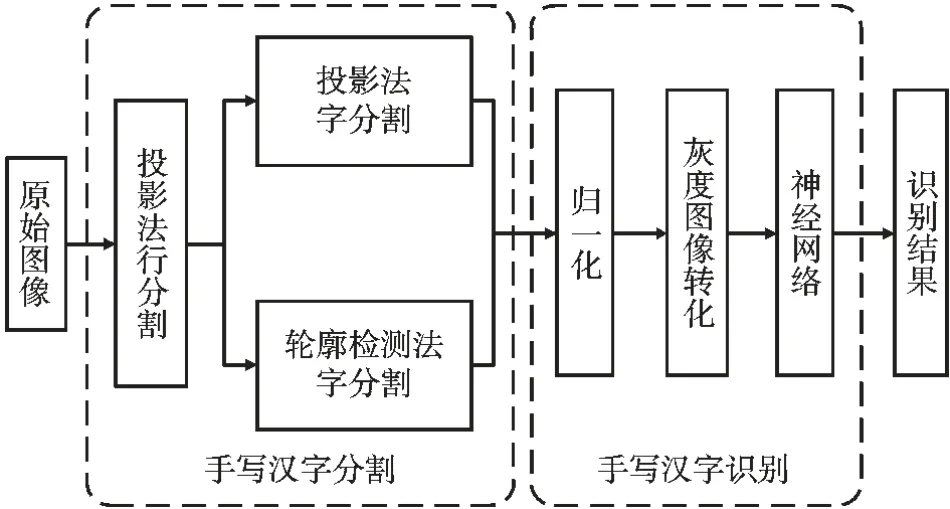
图4 手写汉字识别流程框图
原始图像图1 使用投影法行分割后显现大小为972×150 的第一行图像(如图5(a)所示)、大小为972×150的第二行图像(如图5(b)所示)。

图5 分割结果
采用第一行文字图像(图5(a))进行列分割,得到每个汉字的图像如图6 所示。

图6 分割出的第一行图像
从原始图像(图3)中可以看到,第一行文字从左至右依次为“诀、曙、阿、开、延”,图像大小依次为138×150、103×150、129×150、98×150、144×150。观察图6 分割结果,投影法准确地分割出了原始图像第一行的“诀、曙、阿、开、延”5 个汉字。将图6 所示的5 个汉字图像逐个进行归一化处理并转化为位深度为8 的灰度图像,送入CNN 卷积神经网络模型进行识别,识别结果如图7所示。

图7 神经网络识别结果图
从图7 识别结果可以看出,分割出的“诀、曙、阿、开、延”的手写汉字图像识别结果为“诀、曙、阿、开、延”,分割后的汉字图像识别率为100%。采用相同原始图像,使用轮廓检测法对图5(a)进行列分割,分割结果如图8 所示。

图8 轮廓检测法分割结果图
由图8 可以看出,轮廓检测法将第一行的 “诀、曙、阿、开、延”5 个汉字拆分成了“讠、氵、夬曙、阝、可、开”,仅有“开”字成功分割,且图像存在变形,“延”字在分割过程中丢失。将得到的单字图片归一化并转化为位深度为8的灰度图像后,送入神经网络模型识别结果如图9 所示。

图9 神经网络识别结果图
由图9 可以看出,分割出的“讠、氵、夬曙、阝、可、开”的手写汉字图像识别结果为“井、况、块、诀、椰、刊”,分割后的汉字图像识别率为0%。
综上实验对比两种分割结果,投影法在手写汉字识别过程中的分割效果更好。
3 结论
手写汉字具有汉字类别繁多、字形结构复杂、书写随意性大等特点,提高手写汉字识别的准确度一直是研究的难点和热点。本文从提高识别准确度的目的出发,以CNN 卷积神经网络模型的识别结果为依据,对比分析了投影法和轮廓检测法在手写汉字图像分割处理中的适用性。研究发现,无论是从图像分割的结果来看,还是从文字识别的结果来看,投影法都是更优解。此项研究在手写汉字识别研究工作者以及手写文件信息化处理工作者的工作实践中有着重要影响,同时也为文档管理类工作者在手写资料的整理方面提供了一个切实可行的思路。
猜你喜欢
故事作文·低年级(2021年12期)2021-12-21
装备制造技术(2020年1期)2020-12-25
作文成功之路·小学版(2020年7期)2020-08-24
制造技术与机床(2019年11期)2019-12-04
电子制作(2018年18期)2018-11-14
中国交通信息化(2017年4期)2017-06-06
当代医药论丛(2017年22期)2017-04-12
自动化学报(2016年8期)2016-04-16
电源技术(2015年2期)2015-08-22
电测与仪表(2014年6期)2014-04-04
