
场内外特征融合的残缺图像精细修复
2021-11-23 02:23:34周纪勇张国梁
光学精密工程 2021年10期
徐 涛,周纪勇,张国梁,蔡 磊
(1.河南科技学院 人工智能学院,河南 新乡453003;2.河南科技学院 机电学院,河南 新乡453003;3.国家电网全球能源互联网研究院有限公司,北京102209)
1 引 言
图像修复是将因遮挡、模糊、传输干扰等各种因素造成信息缺失或损坏的图片,利用图像缺失部分邻域的信息和图像整体的结构等信息,并按照一定的信息复原技术对图像的缺失或损坏的区域进行修复[1-2]。图像修复技术具有独特的功能,已被应用到许多图像处理的场景中,例如删除图像中不需要的物体,去除目标物上的遮挡物体,修复损坏等。图像修复的核心技术是图像修复区域既要保持全局语义结构,又要保证生成逼真的纹理细节[3-5]。
传统的修复方法大多数是基于纹理合成和基于结构来实现图像信息的复原。基于纹理合成的技术通常利用低级特征的区域匹配和补丁来修复图像的缺失像素[6-9],例如:彩色特征(RGB)值的均方差或尺度不变特征变换(SIFT)特征值[10]。此类方法对静态纹理的合成效果较好,但并不适应于图像结构复杂的场景。基于结构的图像修复方法常常依据图像信息的结构性原则,采用逐步扩散的方式修复图像,该类方法普遍适用于修复小范围缺失的图像[11-13],当待修复目标信息大量缺失时修复效果就会明显下降。
深度学习方法的快速发展为图像修复模型开辟了一条新的路径。基于深度学习的图像修复模型是将一个深度神经网络通过在数据集中经过大量的训练,学习到图像更多深层次的特征信息,从而得到更加逼真的图像修复效果[14-16]。近年来,生成式对抗网络(GAN)作为一种无监督的深度学习模型被应用于图像修复领域[17,28],使得基于深度学习的图像修复得到了进一步的发展,其通过编码器完成图像修复,并借助判别器对修复图像的真实性进行评价,从而有效提高了图像的修复质量。
真实环境中普遍存在遮挡、模糊、传输干扰等因素,极易造成目标特征的严重缺失,现有图像修复方法难以充分利用完整区域预测缺失区域特征,造成修复区域存在着特征不连续、细节纹理模糊等问题。基于此,本文提出一种基于场内外特征(External Features and Image Features,EFIF)融合的残缺图像精细修复方法,将从知识库中提取关于待修复目标的文本描述定义为场外特征,并将待修复目标完整区域的信息定义为场内特征,其修复结果如图1所示。首先,通过编码器将场外特征编码到神经网络模型中,利用改进的动态记忆网络(DMN+)算法[18-20]对待修复目标一致的场外特征进行检索,并实现与场内特征的融合,生成包含场内外特征的残缺图像优化图,从而解决目标信息不足的问题。其次,构建带有梯度惩罚约束条件的生成式对抗网络(WGAN-GP)[21-22],指导生成器对优化后的残缺图像进行粗修复,获得待修复目标的粗修复图。最终利用相关特征连贯的思想改进WGAN-GP的网络结构,得到特征连续、细节纹理清晰的精细修复图。

图1 本文所提出修复模型的修复结果Fig.1 Restoration results of the proposed restoration model in this paper
2 相关工作
2.1 外部知识与情景记忆
自然知识有助于提高深度学习模型的理解能力,因此,人们越来越倾向于利用场外知识库改进数据驱动模型。现有的人工智能知识库是通过人工构建的[23],因此将知识库中的常识性知识提炼到深度神经网络是一个重要的研究领域。Wu等人[24]将提取到常识性知识编码为向量,并将其输入到神经网络中,与视觉特征结合起来为推理提供了额外的线索。Kumar等人[25]提出了基于情景记忆的网络模型,该模型将注意条件作为输入并经过网络进行推理从而输出结果。然而该模型是否能够直接应用于图像领域还是未知的,为了解决这一问题,Xiong等人[20]在DMN模型的基础上改进了其存储和输入层,在输入融合层采用双向的门循环单元(Gate Recurrent Unit,GRU),并提出了一种能够回答视觉问题的图像输入模型。
2.2 图像修复
目前的图像修复方法主要分为两类,一类是非学习的图像修复方法,一类是基于学习的图像修复方法。前者是传统的基于补丁的修复方法,后者是学习图像的深度特征,通过训练基于深度学习的修复模型最终推断缺失区域的特征信息,从而实现残缺图像的修复。非学习的方法主要是通过扩散邻近信息或复制背景最相关区域的信息来填补缺失区域[10,15]。这类方法面对缺失区域小的图像可以产生平滑和逼真的结果,然而对于缺失区域较大的图像即使采用高计算成本仍不能获得逼真结果。为了解决这一问题,Barnes等人[26]提出了一种快速最邻计算的图像修复方法,大幅度的提高了计算速度,且能得到一个高质量的修复效果。尽管非学习方法对于表面纹理合成非常有效,但这些模型面对大面积缺失的图像具有一定的局限性。
基于学习的图像修复方法通常是利用深度学习和GAN策略实现残缺图像的修复。Deepak等人[27]提出了一种基于上下特征预测的图像修复方法,该方法通过上下文编码器提取整个图像的深度特征,并对缺失部分的生成做出合理假设。同时利用像素损失函数,使生成的结果更加清晰。然而,它在生成精细纹理时的效果并不理想。为了解决这一问题,Yu等人[29]提出了一种基于上下文注意的生成式图像修复。该模型包含一个上下文注意层,其原理是将已知补丁的特征信息作为卷积处理器,通过卷积设计将生成的补丁和已知的上下文补丁进行匹配,从而得到具有精细纹理的修复效果,但是该方法未考虑残缺区域的语义相关性和特征连续性问题。为了解决这一问题,Liu等人[22]提出了基于精细化深度学习的图像修复模型。该方法采用一种新的连贯语义层,并通过连贯语义层保留上下文语义情景结构,使其推测出来的残缺部分更加合理。
总体来看,现有修复方法仅是对场景内的特征进行深度卷积学习,在面对特征信息不足的残缺图像时,现有修复模型就会呈现出不能有效修复或修复效果精细纹理缺失的现象。因此本文结合自然知识,提出了基于场内外特征融合的残缺图像精细修复方法,其原理结构如图2所示。
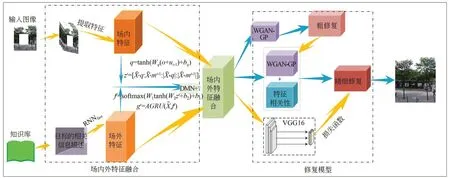
图2 本文所提出修复模型的原理图Fig.2 Schematic diagram of the proposed repair model in this paper
3 场内外特征融合图像修复算法
3.1 常识性知识的检索和嵌入
当图像目标特征严重缺失,造成数据严重不足时,现有的修复模型难以实现对其有效的修复。本文利用知识库中的常识性知识弥补原图像目标信息不足的问题。图像中目标是残缺的,由于特征信息的不足无法实现对其准确地修复。通过检测图像背景中存在的目标β,根据知识库中相应的常识性知识,推测出与目标β具有高度相关性的目标集合,定义为{α1,α2,…,αk},该目标集合中的有效信息对整体缺失区域修复工作构成直接的引导作用。将依据常识性知识获取待修复区域高相似度目标集合的过程表示为:

目标集合{α1,α2,...,αk}是仅依据知识库中单一相似性对目标β的初步推理描述,知识库中还包含着大量对目标集合中每个元素αk的细节语义特征描述信息,这些细节语义信息的有效获取将极大弥补待修复目标信息不足的问题。在保证提取过程中目标特征描述与知识库中相应语义实体相匹配的基础上,本文对每个元素αk细节语义特征描述信息的嵌入过程表示为:
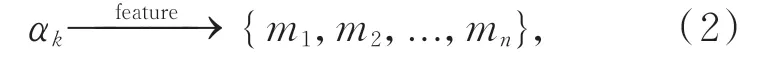
其中,{m1,m2,...,mn}是从知识库中检索到的对目标αk细节常识性描述。为了对检测到的常识性知识进行编码,本文将这些常识性描述{m1,m2,...,mn} 转 换 成 单 词 序 列{M1,M2,...,M n},并且通过mt=w e M t的映射关系将句子中的每一个单词映射到一个连续的向量空间中。然后通过基于循环神经网络(RNN)的编码器对这些向量进行编码:
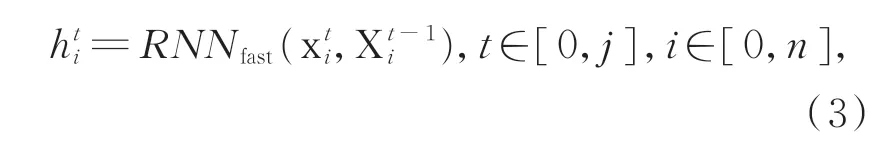
其中:x ti表示检索到的关于物体αk的第i句特征描述中第j个单词的映射向量,X t-1i表示编码器的隐藏状态。同时将双向门控循环单元(GRU)引入到编码过程中,最终编码器的隐藏状态hti表示第j个特征描述的句子的向量重现。同时将这些文本向量定义为场外特征X E。
3.2 特征融合
从知识库中得到的常识性知识存储到知识存储单元的内存槽中,用于推理和知识的更新。将外部知识融入到目标特征提取的过程中,用来弥补原目标物特征的不足。将k个对象在知识库相对应特征的语义描述编码到神经网络,那么存储空间中就含有k×n个相关的特征向量。但是,伴随储存空间特征向量的几何式增长,将极大增加从候选知识中提取有用信息的难度。为了解决这一问题,本文通过改进的DMN+算法实现基于情景问答的场外知识检索,获取最具相关性的待修复目标特征描述,其原理如图3所示。

图3 场外特征的检索与获取Fig.3 Retrieval and acquisition of external features
采用改进的DMN+算法对检索场外特征X E进行推理,以获取其特征的描述集合{x E}。利用DMN+模型的注意机制生成场内外特征融合的相关性约束。为保证模型对上下文信息的理解和原始输入的记忆,对DMN+的输入层进行改进,将残缺图像Igt输入到模型中,并有效的提取目标特征信息oˉ作为DMN+模型的第一层输入,第二层及以上层的输入为原始输入oˉi+1和前一层输出i的总和,如公式(4)所示:
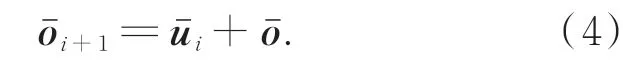
通过对上下文的学习,使提取到的特征之间进行信息交互,以获取更多的与目标信息相关的场外特征信息,更有利于实现图像的修复。将目标特征向量输入到全连层,其处理过程的具体公式如下:

其中:q表示目标αk映射后的目标向量,Wq,bq表示映射参数。zt表示相关的场外特征XE、模型情景记忆mt-1和被映射的目标向量q之间的交互作用,∘表示元素相乘的运算符号,|⋅|表示元素的绝对值,[:]表示是多个元素交互运算。值得说明的是,模型情景记忆mt-1和被映射的目标向量q需要先通过复制扩展达到具有相同维度,才能与场外特征XE进行交互运算。ft表示softmax层的输 出,W1,W2,b2和b1表 示 的 学 习 参 数。AGRU(•)表示DMN+模型的注意机制,其机理是将GRU中的更新门用事实K的输出权重f t k代替:
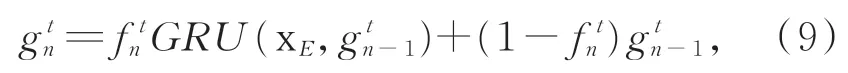
其中:g tn用来表示当所有对目标β的特征描述都被查看后的GRU状态。并通过注意力机制利用当前的状态和DMN+模型的情景记忆更新储存器的记忆状态,如公式(10)所示:
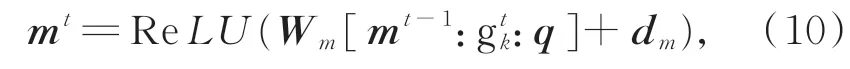
其中,mt表示更新后的情景记忆状态,通过记忆有用的知识信息来弥补原目标数据的不足。利用最终情景记忆挑选与目标信息相关的场外特征信息,如下所示:

其中:Wc和dc表示学习参数,Xf表示目标融合后的特征。从而利用外部知识丰富了残缺图像原有的特征信息,解决了缺失目标物特征信息不足的问题。
3.3 修复模型构建
本文所设计的残缺图像精细修复模型由三部分网络构成,即:场内外特征融合网络,粗修复网络和精细修复网络,其总体网络结构如图4所示。将信息残缺的图像Iin输入到场内外特征融合网络,得到一个特征信息更加丰富的输出结果,并将其输入到粗修复网络,获取粗修复图像Ir。将待修复的图像Iin和粗修复图像Ir同时输入精细修复网络,通过提取叠加区域的有效特征信息,生成最终的精细修复图像Im,从而实现对残缺图像的精细修复。下面将着重描述粗修复网络和精细修复网络的模型构建过程。

图4 本文所提残缺图像精细修复方法的网络模型Fig.4 Network model of the proposed method for fine restoration of incomplete images
3.3.1 粗修复网络设计
本文所设计的粗修复网络是基于对抗神经网络策略的修复模型。它是将编码器的每一层都与解码器的对应层特征相关联。利用编码器生成待修复图像的深度特征表示,并通过解码器预测出缺失区域信息。在图像修复模型中损失要优于现有的GAN损失,且与重建损失函数结合时会产生一个更好的效果。基于WGAN-GP网络获取生成数据和原始数据之间的Wasser⁃stein-1分布比较距离。其目标函数为:

其中:L表示1-Lipschitz函数的集合,Pg表示隐含xˉ=G(z)中的模型分布,z表示生成器的输入。
引入梯度惩罚约束条件,将梯度与输入掩膜相乘,其原理如下:


其中:∏(Pr,Pg)表示Pr和Pg采样点分布集合的γ(x,y)的边际。通过对以像素为单位测量距离进行损耗评估,并利用梯度惩罚约束条件训练和优化原始WGAN-GP网络的生成器,使其更易学习并匹配出待修复区域的有效信息,提升粗修复网络模型的稳定性。
3.3.2 精细修复网络设计
将待修复的图像Iin和粗修复图像Ir同时输入到精细修复网络中,以促使网络更快的捕获图像中有效的特征信息,极大地提高了修复网络的修复效果。精细修复模型的网络结构与粗修复模型的相似,不同的是为了增强残缺区域的语义相关性和特征连续性,提出了一种新的相关特征连贯层,并通过特征相关性对上下语义情景结构进行保留,使其推测出来的残缺部分更加合理,如图5所示。
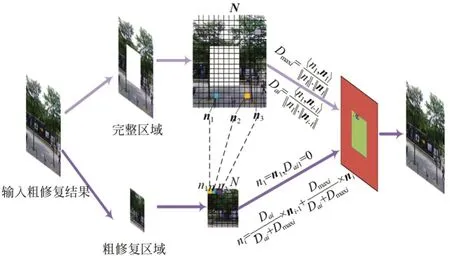
图5 相关特征连贯原理图Fig.5 Coherent schematic diagram of related features
特征相关性分为搜索和生成两个阶段。对于修复区域N生成每一个补丁ni(i∈(1,k),k表示小补丁的个数),通过相关特征连贯层搜索与图像信息完整区域最匹配的补丁nˉi,用于初始化ni。并将nˉi作为主要的特征信息,与已经生成的补丁ni-1融合,最终反向还原出ni作为有效的修复补丁。补丁间的相关度判断如下式所示。
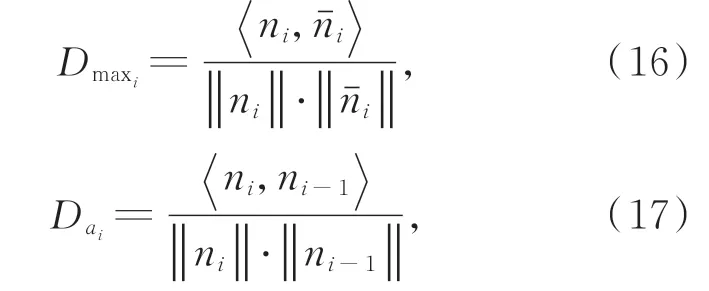
其中:D ai表示这个邻近补丁之间的相似性,Dmaxi表示最匹配的补丁nˉi和完整区域补丁ni之间的相似性。将D ai和Dmaxi视为生成补丁的权重,这样每一个补丁都包含着先前补丁的信息。最终生成的补丁信息表示如下:
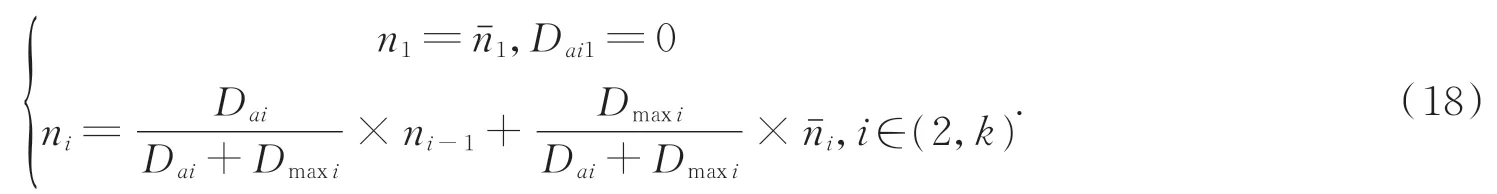
由于补丁的生成过程是一个迭代过程,每一个补丁在迭代的过程中均获得了更多的背景信息,且与之前生成的所有补丁(n1~ni-1)和nˉi都具有相关性。将Nˉ中提取的补丁用作反卷积滤波器对N进行重建,从而获取更加逼真的修复结果。
为进一步提高图像修复的效果,本文引入特征修复识别器,通过识别器区分原始图像和已修复图像,并根据修复特征信息,计算出对抗损失函数D M和D R,将D M用于精细修复网络,D R用于粗修复网络。如式(19)所示:

其中:D代表鉴别器,E Io表示所有真实取平均值的操作,E Im表示所有修复结果取平均值的操作。
3.4 修复模型的损失函数
为提高场内外特征融合网络检索相关场外特征的能力和优化注意机制参数,在采用改进的DMN+网络进行场内外特征融合时定义一个优化损失函数,如下式所示:
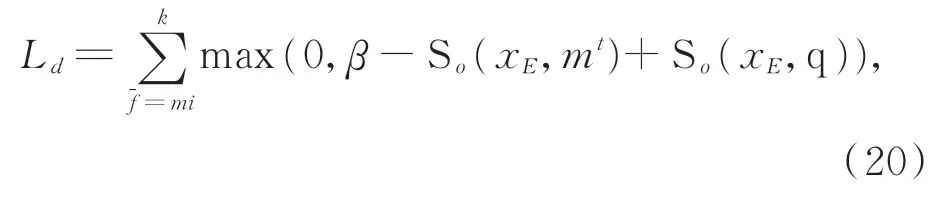
其中:SO(⋅)表示情景记忆和场外特征之间的匹配度,SR(⋅)表示场内特征和场外特征之间的匹配度。
在修复网络构建的过程中,现有的图像修复模型通常利用知觉损失提高图像修复网络的识别能力。但是,知觉损失容易误导相关语义连贯层的训练过程,本文引入一致性损失函数对现有损失函数的构建进行了改进。通过经预训练的VGG-16网络[30]提取原始图像的深度特征。并将残缺区域的原始深度特征设定为相关语义连贯层及其编码器对应层的目标,并计算出训练网络的一致性损失函数L c,如下式所示:

其中:φm表示经预训练的VGG-16网络参数。W(⋅)表示编码器中相关特征连贯层的深度特征,W d(⋅)是解码器中相关特征连贯层对应层的深度特征。
将Wasserstein-1距离作为判断条件,构建出修复网络的损失函数如下式所示:
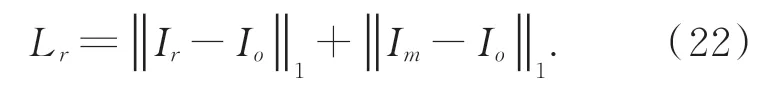
将式(19)~式(22)所构建的特征融合优化损失函数、训练网络一致性损失函数、修复网络损失函数和粗修复网络对抗损失函数进行加权平均,获取所提残缺图像精细修复模型的总体损失函数L g,如下式所示:
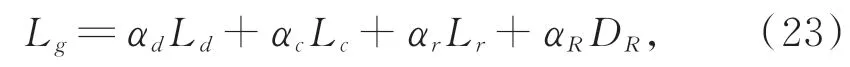
其中:αd,αc,αr,αR分别为优化损失、一致性损失、修复损失、对抗损失的权衡参数。
4 实验结果及分析
为验证所提残缺图像精细修复模型的有效性,分 别 基 于Places2[31],Real-world Underwater Image Enhancement[32]和Underwater Target数 据集与现有的方法进行了定性和定量的对比实验,具体实验结果及分析如下。
4.1 实验设置
本文设计的实验基于Places2,Real-world Underwater Image Enhancement(RUIE)和Un⁃derwater Target三个数据集。在实验中不使用任何数据标签。为了模拟图像缺失的现象,本文将采用方形掩模对图像目标区域进行遮掩。同时对三个数据集的原始数据进行训练。学习率设置为2×10-4和β=0.05。权衡参数设置为αd=0.1,αc=0.1,αr=1,αR=0.001。将本文所提EFIF算 法 与SH(Shift-net)[3],GLCI[15],CSA[22]三个代表性算法模型进行对比。实验的硬 件 配 置 为:CPU为Intel(R)Core(TM)i7-8700K@3.70 GHz,GPU为RTX 2080 Ti。内存为64 G。运行环境为Python3.7,模型采用Py⁃Torch库编写,操作系统为Ubuntu-16.04。
4.2 定性评价实验
4.2.1 Places2数据集实验结果
Places2数据集是由麻省理工大学负责维护的场景图像数据集。数据集涉及400多个场景,共包含1千万张图片。该数据集是图像修复领域广为应用的数据集之一。本文从数据集中选取大量的建筑、风景图片,用于训练和实验。
在Places2数据集中的仿真结果如图6所示。最左边的一列为经过掩模处理后的输入图像,最右边一列是原始图像,中间分别为SH,GLCI,CSA和EFIF修复模型的修复结果。实验(a)~(c)为建筑图像的修复,实验(d)~(e)为风景图像修复。从实验结果可以得出本文提出的图像修复结果比其他修复模型的修复结果更能有效的修复目标的特征。同时在纹理重建方面也更加合理。

图6 现有修复模型与本文修复模型在Place2数据集中比较,从右到左依次为输入图像,SH、GLCI、CSA、粗修复、EFIF及原图Fig.6 Comparison of the existing restoration model and the restoration model in this paper in the Place2 database,from right to left,the input images,SH,GLCI,CSA,roughly repaired image,EFIF,and the original image
4.2.2 RUIE数据集实验结果
RUIE数据集是由大连理工大学—立命馆大学国际信息与软件学院提出的一个针对水下图像研究的数据集,具有图像数据量大,图像场景、色彩多样,检测目标丰富等特点。其常用于水下目标的检测与识别、水下图像的增强与复原。本文从RUIE数据集选取大量的水下雕塑,汽车残骸等进行仿真实验。与SH,GLCI和CSA图像修复模型作对比,其仿真结果如图7所示。

图7 现有修复模型与本文修复模型在RUIE数据集中比较,从右到左依次为输入图像,SH、GLCI、CSA、粗修复、EFIF,及原图Fig.7 Comparison of the existing restoration model and the restoration model in this paper in the RUIE database,from right to left,the input images,SH,GLCI,CSA,roughly repaired image,EFIF,and the original image
从仿真结果来看实验(a)、实验(b)、实验(c)表示轻微模糊的场景实验。实验(d)、实验(e)和实验(f)表示严重模糊的场景实验。实验(b)中,SH模型的修复结果存在着目标丢失的现象。SH,GLCI和CSA修复模型在实验(a)、实验(b)、实验(e)、实验(f)的修复中均存在着修复区域模糊,并不能有效地修复缺失区域的纹理。实验(b)、实验(d)、实验(e)对应粗修复图像的修复区域纹理模糊现象。本文所提出的修复结果能够有效的修复缺失区域特征,且能够生成合理的图像纹理。如实验(c)、实验(e)所示修复的结果与原图十分接近。
4.2.3 Underwater Target数据集实验结果
Underwater Target数据集是本文研究团队针对水下图像所建立的数据集。主要用于水下复杂场景中特征提取、目标检测与识别、场景理解,为自主式水下航行器(Autonomous Underwa⁃ter Vehicle,AUV)实现自主航行能力、目标识别与跟踪、自主规划路线和协同控制提供重要保障。在水下图像处理领域的研究中有着重要意义。其中包括鱼雷、潜艇、蛙人、AUV等类别。本文从Underwater Target数据集中选取大量的鱼雷、潜艇、AUV图像进行实验,与SH、GLCI和CSA图像修复模型对比。如图8所示。从仿真结果来看实验(a)、实验(b)为不同场景下的鱼雷修复。其中实验(a)表清晰的场景,实验(b)表模糊的场景,实验(c)表示模糊的场景AUV的修复实验。实验(d)、实验(e)分别表示清晰、模糊场景下的潜艇的修复。实验(b)中,SH,GLCI模型修复的结果存在特征丢失现象。实验(a)、实验(d)中,粗修复图像存在修复区域纹理模糊的现象。本文模型能够更好的修复残缺区域,同时注重修复区域的纹理,如实验(b)、实验(c)本文修复结果接近于原图像。从而说明了本文模型更注重于结构和纹理的修复能力。

图8 现有修复模型与本文修复模型在Underwater Target数据集中比较,从右到左依次为输入图像,SH、GLCI、CSA、粗修复、EFIF,及原图Fig.8 Comparison of the existing restoration model and the restoration model in this paper in the Underwater Target data⁃base,from right to left,the input images,SH,GLCI,CSA,roughly repaired image,EFIF,and the original im⁃age
4.3 定量评价实验
4.3.1 定量评价指标
由于个体的差异、喜好等主观因素的影响,对实验结果的评价会在一定程度上存在片面性。为了获取更准确的修复结果的质量评价。在上述式(22)修复网络的损失函数单一定量评价指标的基础上,本文引入峰值信噪比PSNR[33]和结构相似性SSIM[34]两个评价指标,对修复结果进行更加客观的定量评价。峰值信噪比是通过两张图像对应的像素点的误差评价图像的质量。其值越大表示图像的修复结果越好,如下式所示:

其中:m,n表示图像尺寸的大小,MSE表示张图像之间的均方差。MAX x2表示图像中所取的最大值。
SSIM指标从图像的亮度、对比度以及结构信息衡量图像的结构相似性,从而评价图像的失真程度,其值越大说明失真越小,修复图像越接近于原始图像,如下式所示:
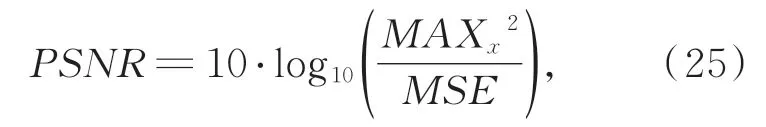
其中:σx和σy分别为原图像和修复图像的平均值,σx2和σy2分别表示原图像和修复图像的方差,δxy表示协方差,C1,C2为用来维持稳定的常数。
4.3.2 定量评价实验结果
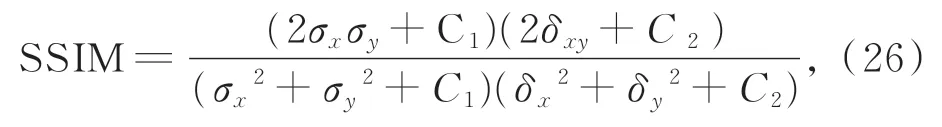
本文使用PSNR,SSIM和L r损失作为定量评价的衡量指标,其中PSNR和SSIM能客观的反映模型修复残缺图像的性能。L r用来测量修复图像和真实图像间的距离。本文修复模型与对比修复模型在Place2、RUIE和Underwater Target数据集中的PSNR,SSIM和L r损失值,如表1所示。从表中可以看出本文修复模型在Place2、RUIE和Underwater Target数据集取得了最优结果,PSNR值和SSIM值是最大的,L r损失是最低的。本文模型图像修复结果的PSNR值最高为35.98,相比CSA算法提高了2.17%。SSIM值最高为0.983,相比提高了1.08%。L r损失最低为0.71,相对降低了6.96%。

表1 Place2、RUIE和Underwater Target数据集各修复结果的客观数据Tab.1 Objective data for restoration results in Place2,RUIE and Underwater Target database
Underwater Target数据集主要用于模糊、复杂水下场景中危险性目标的识别与重构。其特征提取难度极大,对修复算法有效性的挑战最为显著,本文将图8每个仿真结果的PSNR、SSIM用柱状图的形式直观的展现出来,用以更加客观的展现所提修复模型面对复杂环境的修复效果,如图9所示Underwater Targe数据集中本文所提算法PSNR最高为26.75,相比CSA算法提高了1.44。SSIM最高为0.935,相比CSA算法提高了0.006。从而可以得出所提算法的修复结果一致优于现有对比模型。

图9 Underwater Target数据集中本文修复模型和对比修复模型修复结果PSNR、SSIM值的柱状图Fig.9 Histograms of PSNR and SSIM values for restoration results from this restoration model and comparative restora⁃tion models in the Underwater Targe dataset.
5 结 论
本文提出一种基于场内外特征融合的残缺图像精细修复方法。首先,通过改进的DMN+算法实现与目标相关外部知识和图像特征的融合;其次,将融合后的特征输入到带有梯度惩罚约束条件的对抗生成网络生成粗修复图像;最后,利用相关特征连贯层对粗修复图进一步优化,获取纹理清晰、特征连贯的精细修复图像。在三个复杂程度不同的数据集中进行实验验证。本算法在视觉定性对比和客观定量两方面均优于现有对比修复模型。图像修复结果的PSNR值最高为35.98,SSIM值最高为0.983。
伴随残缺区域的增大,所提算法修复效果衰减较为明显,在后续研究中将探索场内外特征自主加权融合策略,针对不同修复任务自适应决策场内外特征所占百分比,并将进一步深入研究所提修复算法在水下场景感知领域的应用。
猜你喜欢
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
学与玩(2018年5期)2019-01-21 02:13:06
文苑(2018年18期)2018-11-08 11:12:30
幼儿画刊(2018年7期)2018-07-24 08:25:56
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
中国科技博览(2016年2期)2016-04-25 20:32:39
小学生导刊(2016年34期)2016-04-11 00:49:44
电测与仪表(2015年5期)2015-04-09 11:30:52
中国卫生(2014年2期)2014-11-12 13:00:14
