
基于机器学习的玛湖地区水平井压裂设计优化
2021-11-22 09:06:26马俊修石胜男张景臣何小东李雪晨郭丁菲
深圳大学学报(理工版) 2021年6期
马俊修,石胜男,陈 进,张景臣,何小东,李雪晨,郭丁菲
1)中国石油新疆油田分公司工程技术研究院,新疆克拉玛依 834000;2)中国石油大学(北京)非常规油气科学技术研究院,北京 102249
中国新疆玛湖致密砂砾岩开发普遍采用“水平井+大规模体积压裂”技术,油藏具有砾石粒径变化大、岩性复杂和非均质性强的特征,导致各井的压裂条件参差不齐,且压裂后井间生产效果差异较大.明确玛湖地区水平井的压裂效果主控因素、实现产能预测和定量优化压裂参数一直是玛湖压裂水平井开发的重点和难点[1].
近年来,机器学习方法在油气田开发中的应用日益广泛,基于机器学习方法的产能预测及压裂工艺参数优化研究成为不少学者研究的重点.WANG等[2]采用GDE全局优化算法,基于200口井的数据建立了经济模型,优化了财务净现值;ANIFOWOSE等[3]结合支持向量机和人工神经网络,成功预测了储层孔隙度和渗透率;叶俊华等[4]采用灰色关联法对吉006断块压后主控因素进行了分析;张杰等[5]基于神经网络、决策树及聚类等方法,建立了压裂施工效果预测模型;陶亮等[6]结合层次分析法与灰色理论建立了产能模型,并将其应用于松辽盆地致密油藏,取得了良好的现场效果.综上所述,国内外学者在建立压裂效果预测模型上开展了大量研究,但多侧重于产量预测以及主控因素分析,对进一步的压裂参数优化研究较少.
本研究基于收集的玛湖地区压裂水平井数据,通过缺失值填补、异常值识别和数据缩放等预处理工作提高数据质量,基于随机森林算法分析了影响水平井压裂效果的主控因素,建立各项特征参数与最终可采储量(estimated ultimate recovery, EUR)之间的数学模型,从而实现水平井的压裂参数定量优化,达到针对性地指导压裂方案的目的.
1 特征参数选取及预处理
在数据分析和挖掘的过程中,数据是极其关键的要素,数据的质量对最终获得的模型或结论的影响很大[9-10].由于各种原因,油气田现场的数据往往存在数据缺失、数错误和异常等现象.因此,在进行产能预测及压裂设计优化前,本研究先对数据进行缺失值和异常值的分析处理,以及数据预处理,提高数据集的质量,保证最后所建模型的准确性.
1.1 缺失值处理
对75口井18个特征参数的缺失率进行统计分析发现,停泵压力的缺失率为26.7%,地层压力、泊松比、杨氏模量和最小水平主应力的缺失率为20%,平均含油饱和度、Ⅰ类储层厚度、平均孔隙度、裂缝间距和施工排量的缺失率在5%以下,其他参数不存在缺失值.雷蕾等[11]研究发现,当缺失率超过5%时,对分类模型的准确率会有影响,需采取填补等方法进行预处理后再进行建模.
本研究采取精细的缺失值处理策略,当缺失率>25%,且属性重要程度低时,直接删除该属性(停泵压力);当缺失率<5%,采用中位值简单填补方式(平均含油饱和度、Ⅰ类油层厚度、平均孔隙度和裂缝间距);当缺失率>5%,且属性重要程度高时,采用随机森林多重插补的方式(地层压力、泊松比、杨氏模量和最小水平主应力),将每个缺失值的特征作为其他特征的函数建立随机森林模型,使用该函数的值作为估算,通过变量之间的关系对缺失数据进行预测,使得填补的缺失值更加真实.
1.2 异常值识别
异常值指远离绝大多数样本点的特殊群体,也称为离群点,通常这样的数据点在数据集中都表现出不合理的特性.如果忽视这些异常值,在某些建模场景下就会导致结论的错误(如神经网络回归模型等),所以在数据的探索过程中,有必要识别出这些异常值并进行处理[12-13].
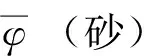
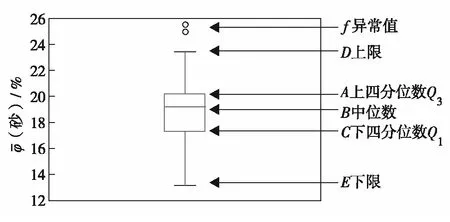
图1 箱型图识别平均砂比Fig.1 Box diagram to identify average sand ratio
1.3 数据标准化
由于数据类型复杂,且数据单位、属性和产能的影响方式均不同,在模型优选分析计算时需要进行如式(1)的标准化处理,以消除不同数量级和不同量纲的影响.
(1)
其中,yi为标准化处理后样本i的特征输出;xi为样本特征; min(xi)为样本特征最小值;max(xi)为样本特征最大值.
2 压裂水平井产能预测模型建立
2.1 基于随机森林的压裂效果主控因素分析
为明确各储层参数、工程参数对产能的非线性影响程度,本研究采用随机森林方法确定产能的主控因素.随机森林是一种集成机器学习方法,在决策树的训练过程中进一步引入随机属性选择而形成的.相比决策树,该方法泛化性更好,并能够得到各变量的相对重要度.随机森林建模时随机采样未被抽到的数据称为袋外数据集,这些数据没有参与训练集模型的拟合,可以用来检验模型的泛化能力[15-16].在对模型进行重要性排序时,使用相应的袋外数据计算它的袋外误差r1. 然后袋外数据中的某个特征顺序被随机变换,再次计算袋外误差r2. 假设随机森林有N棵树,则某个特征的重要性I为
(2)
根据上述原理,建模计算得到玛湖地区水平井各项特征因素对产能的重要性评分,各项特征参数重要性总评分为1.0[17].储层参数总评分为0.550,2级储层主控参数依次为含油饱和度、孔隙度、钻遇率和地层压力,评分分别为0.175、0.152、0.051和0.046;工程参数的重要性总评分为0.45,2级施工主控参数裂缝间距、总液量、总砂量、施工排量和平均砂比分别为0.152、0.112、0.094、0.042和0.031.由此可见,玛湖地区水平井的产能受储层参数影响较大,但在进行压裂施工参数优化时,应重点考虑裂缝间距、总液量和总砂量等工程参数,以获取最大产能.
2.2 产能预测模型工作流程
逆传播(back propagation, BP)神经网络是一种按误差逆传播算法训练的多层前馈网络,根据输入的训练样本,可自动适应和确定各神经元的连接权重[18].BP神经网络基本思想是梯度下降法,利用梯度搜索技术,使网络的实际输出值和期望输出值的误差均方差为最小[19-20],是目前应用最广泛的神经网络模型之一.遗传算法(genetic algorithms, GA)通过学习模拟生物进化论和自然界遗传机制,形成一种并行随机搜索最优化方法[21].
本研究建立了产能预测的BP神经网络模型,并使用遗传算法进行优化,模型的工作流程如图2.使用遗传算法优化神经网络模型可以获取更加准确的初始权值和阈值,神经网络模型进行优化后,可以更好地反应出输入数据与输出数据之间的关系,达到精确预测的目的.

图2 遗传算法优化BP神经网络过程Fig.2 BP neural network process optimized by genetic algorithm
2.3 产能预测模型的训练及验证
本研究以16个储层及施工参数作为输入特征值(表1),以EUR作为输出参数,建立特征参数与产能之间的3层BP神经网路模型,设隐含层的神经元为20个,网格训练的学习率为 0.001,期望误差为 0.05.通过反误差函数不断调节网格权值与阀值,直到网格输出误差逐步达到期望误差,完成网格训练.本次模型使用遗传算法的个体编码长度应包括中间层到输入层的16×20个连接权值,输出层到中间层的1×20个连接权值以及20+1个阈值,遗传算法的个体编码长度最终为16×20+1×20+20+1=361.
共收集压裂水平井75口,按照数量比为85∶15划分训练集和测试集,分割后训练集为64口,测试集为11口,数据集的原始产量分布如图3.
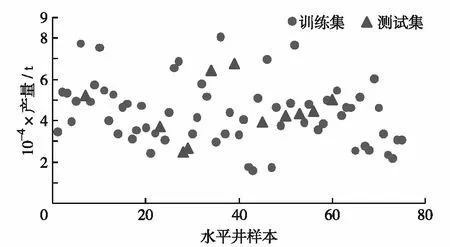
图3 训练样本与测试样本产量的原始分布情况Fig.3 The original distribution of the output of training samples and test samples
使用训练集数据训练模型,并基于模型在测试集上的评分评估模型性能.采用决定系数R2评估模型的性能.决定系数R2得分反映因变量的全部变异能通过回归关系被自变量解释的比例,如式(3),R2越接近1,样本中预测值和真实值越相近,表示回归分析中自变量对因变量的解释越好.
(3)
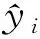
模型训练后,为验证优化后的模型性能,将其预测测试集样本的结果与原始数据及未经优化后的BP模型预测结果进行对比,结果如图4.由图4可见,使用遗传算法优化后的神经网络模型(GA-BP)效果更好,该模型测试集的决定系数得分R2=0.76, 未经优化的决定系数得分R2=0.62, 证明该模型该模型性能优良,泛化能力好,具备一定的适用性.
图4 测试集样本预测结果Fig.4 Test set sample prediction results
3 单井压裂设计优化
3.1 产能预测应用
为了进一步验证玛湖地区水平井体积压裂产能预测模型的适用性,以玛湖地区某两口待压井(井1和井2)为例,开展产量预测.将其邻井数据输入产量预测模型中,验证模型的性能,同时与已投入生产的邻井相比,在储层及工程参数相似的情况下,使用模型验证储层特征相近的临井情况,可以为井1和井2提供一定参考,井1、井2及邻井的特征参数如表1,井1邻井与井2邻井预测的EUR分别为54 356 t和25 394 t,与真实值相比,误差均在11.3%以下,证明该模型性能良好.使用模型预测井1和井2的EUR分别为58 758 t和26 034 t,与其邻井相比,预测的EUR数值更接近.
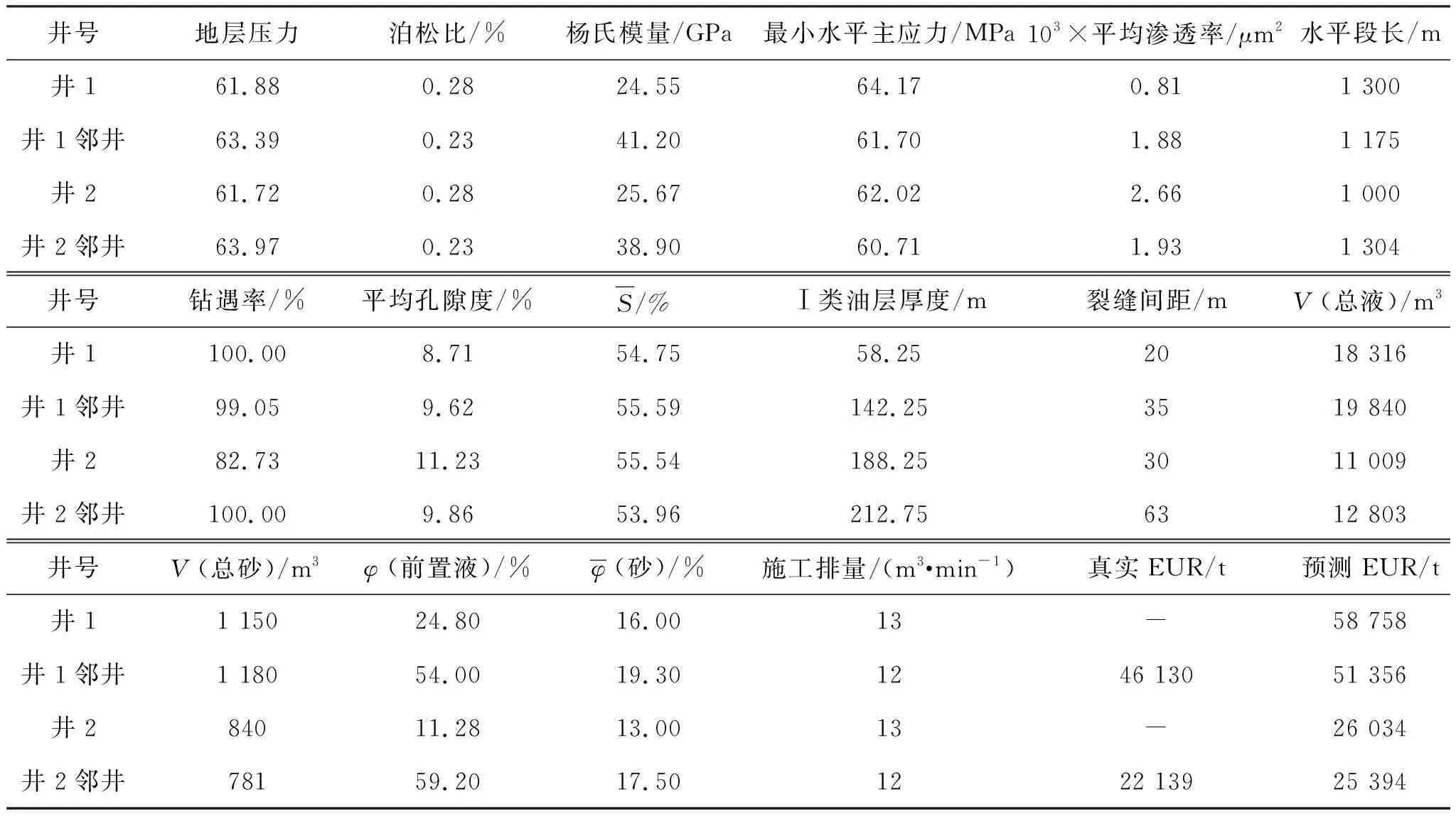
表1 井1和井2与邻井特征参数及预测结果
3.2 单井压裂设计优化
由2.1节分析主控因素得知,影响玛湖地区水平井的工程参数主要为裂缝间距、总液量以及总砂量.实际压裂过程中,多种参数之间存在着相互影响,需要在多参数相互影响下,利用正交试验的方法进行多参数影响下的优化研究.正交试验就是对多因素可能产生关联影响的探究,通过正交表进行因素的排布,在各因素不同水平值的排列组合的众多方案中,选取有代表性的水平值,形成最优方案[22],井1及井2的正交表参数如表2和表3.
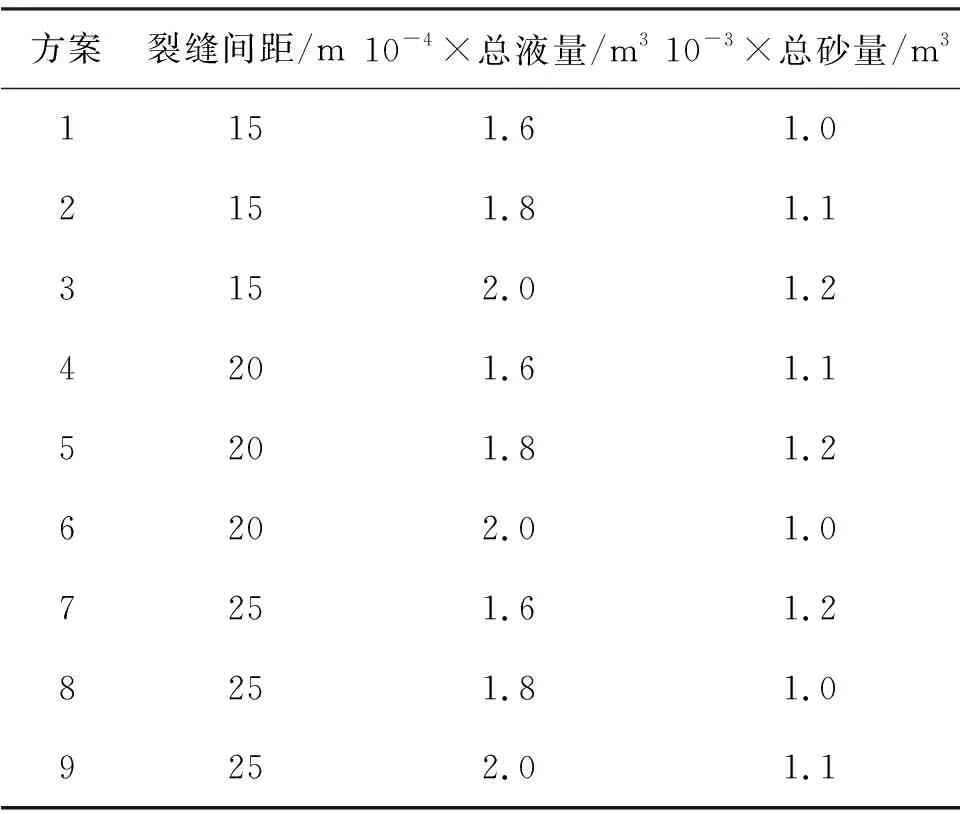
表2 井1正交参数表
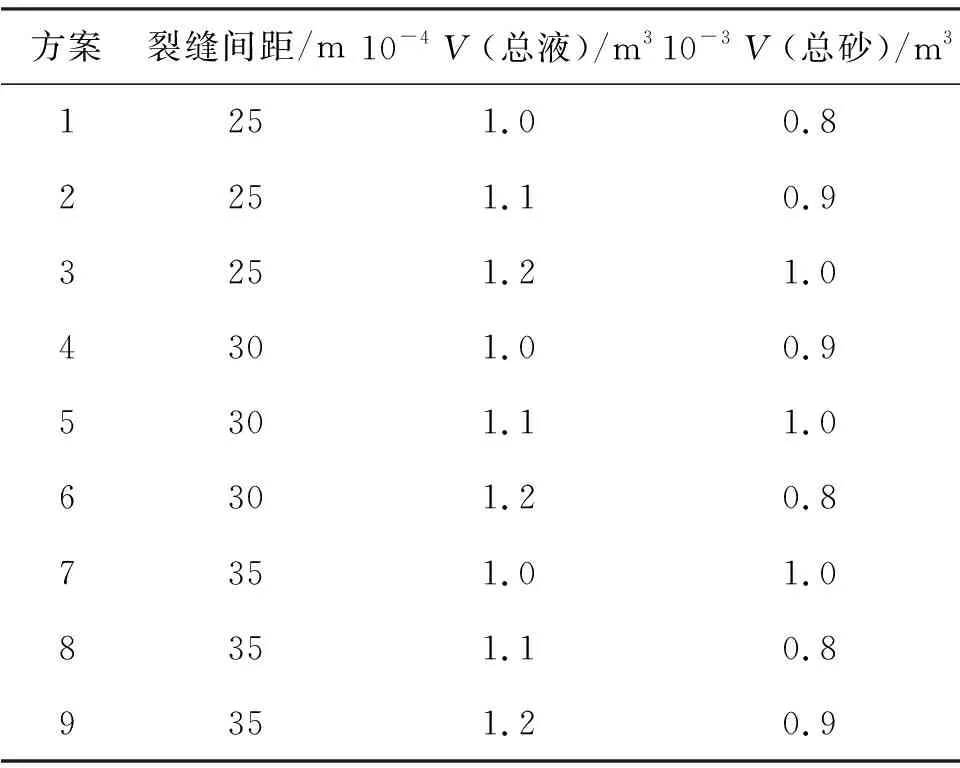
表3 井2正交参数
根据不同的设计方案,预测不用压裂规模下的油井产能情况,并测算相应方案下的压裂投资,综合考虑产能和经济成本,选取最优的压裂方案,得到井1与井2的EUR预测结果如图5和图6.
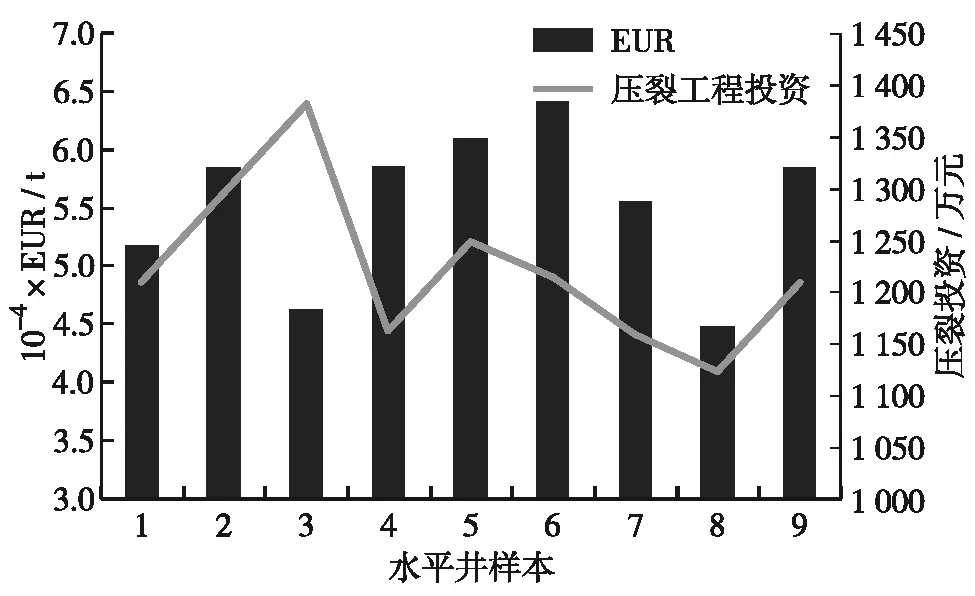
图5 不同方案下井1预测产能与投资Fig.5 Productivity and investment of Well 1 under different plans
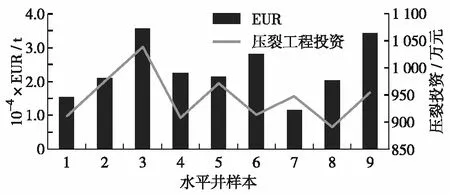
图6 不同方案下井2预测产能与投资Fig.6 Productivity and investment of Well 2 under different plans
综合考虑产能与压裂投资,井1选择方案6(裂缝间距为20 m,总液量约为2×104m3,总砂量约为0.1×104m3)为最优施工参数组合,此时预测EUR为64 225 t,在此压裂规模下的压裂投资为1 213.5万元,符合投资限额要求.在此方案下的EUR相较于原58 758 t提高了9.3%.井2选择方案9(裂缝间距为35 m,总液量约为1.2×104m3,总砂量约为900 m3)为最优施工参数组合,此时预测EUR为34 264 t,在此压裂规模下的压裂投资为954.4万元,符合投资限额要求.在此方案下的EUR相较于原26 034 t提高了37.3%.
4 结 论
1)随机森林算法确定了影响玛湖地区水平井EUR的主要储层参数依次为含油饱和度、孔隙度、钻遇率以及地层压力,主要工程参数为裂缝间距、总液量和总砂量.
2)基于各特征参数与最终可采储量之间的BP神经网络模型,利用遗传算法对各层的权值及阈值进行优化,该产能预测模型决定系数达到0.78,模型性能较好.
3)应用建立的产能模型进行压裂参数优化,井1与井2的最终可采储量分别提高了9.3%和37.3%,可为现场水平井压裂参数的优化设计提供参考.
4)不同区块的储层特征、流体性质和井网特征均不相同,水平井产能参数影响程度也会不同,本研究所建立产能预测及压裂参数优化方法可推广至其他油藏,为现场压裂设计提供参考.
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
云南化工(2020年11期)2021-01-14 00:50:42
矿产勘查(2020年5期)2020-12-25 02:39:14
制造技术与机床(2017年11期)2017-12-18 06:46:39
录井工程(2017年1期)2017-07-31 17:44:42
西南石油大学学报(自然科学版)(2016年6期)2017-01-15 14:14:10
天然气勘探与开发(2015年3期)2015-12-08 08:28:37
中国海上油气(2015年3期)2015-07-01 16:32:08
电测与仪表(2015年7期)2015-04-09 11:40:04
