
基于改进SSD的多尺度低空无人机检测
2021-11-20 01:57刘朋飞冯水春卞春江
计算机工程与设计 2021年11期
刘朋飞,周 海+,冯水春,卞春江
(1.中国科学院国家空间科学中心 复杂航天系统综合电子与信息技术重点实验室,北京 100190;2.中国科学院大学 计算机科学与技术学院,北京 101408)
0 引 言
目前,针对无人机的检测技术主要分为两种,以雷达检测技术[1]、红外检测技术、声学检测技术[2]、激光探测技术等为主的基于非视觉特征的技术和基于视觉图像特征的检测技术。基于非视觉特征的技术在检测时,存在诸多问题,比如雷达视野盲区很多,探测近距离目标能力差;无人机多采用无刷直流电机作为动力装置,发热很少,因此红外辐射非常低,给红外探测带来很大的困难。
当前,以卷积神经网络为代表的基于视觉图像特征的检测技术发展迅速,Faster RCNN[3]、YOLO[4]、SSD[5]、Retina-Net[6]等模型相继被提出,同时,对低空无人机目标检测大多研究弱慢小目标,缺少对无人机运动过程中尺度变化问题的研究[7,8],这导致检测网络无法有效学习目标的多尺度特征,文献[9]在进行无人机检测时,图像背景较为单一,没有考虑低空中其它干扰目标的情况,在低空实际检测场景中具有局限性。
由于当前没有较为统一的无人机图像数据集,所以本文建立了包含多种低空场景、多尺度无人机目标的数据集,共20 000张,基于SSD检测框架,在VGG16网络的基础上,引入Conv3_3特征图,构建金字塔特征提取网络,增强对无人机目标的特征提取能力,然后,通过研究卷积特征图中理论感受野、有效感受野和先验框的关系,重新设计了不同尺寸和长宽比的先验框,并利用测试集图像和视频进行实验验证,实验结果表明,本文提出的改进SSD模型提高了对低空无人机的检测准确率,并且对于视野内的其它干扰物,具有较好的鲁棒性。
1 建立低空无人机目标数据集
本文的检测无人机对象主要是120 m以下飞行空域内的无人机。现有的研究工作中还没有公开、通用的无人机数据集可以用来进行模型训练,文献[10]针对低空弱小无人机目标检测场景,建立了一个由15 000张无人机目标图像组成的训练数据库,但是该数据集是从大型网络图像数据库中搜索和在包含无人机目标的视频中截取,并没有充分考虑低空目标场景。因此,本文通过研究目标检测领域主流的数据集,针对当前低空无人机检测领域实测数据样本匮乏的情况,为提高深度神经网络模型的检测精度和泛化能力,建立了一个低空背景下的旋翼无人机目标图像数据集,充分考虑了低空场景下的各种背景、目标的尺度、姿态及可能的负样本。
利用大疆无人机(包括4种型号,DJI Inspire、DJI Phantom4、DJI Marvic Air、DJI Marvic PRO)在中国科学院国家空间科学中心怀柔园区附近进行试飞,并实地拍摄无人机多尺度照片,由于拍摄场景单一,无人机种类少等条件限制,实地拍摄的图片较少,仅挑选出500张作为数据集图片,不能满足神经网络训练的需要,因此,本文采用借鉴CVPR The 1 st Anti-UAV Workshop & Challenge(CVPR第一届“反无人机”挑战赛)的数据集和合成图像两种方式扩充无人机数据集。
(1)CVPR第一届“反无人机”挑战赛共有160段高质量的全高清视频序列,并且涵盖了不同的场景和尺寸,包括云雾、楼宇、虚假目标、悬停、遮挡、尺度变化等。考虑到视频序列相邻帧的相似性,每隔0.5 s取一帧图片。
(2)对于合成图像,遵循以下原则:
目标图像:数据集中包括单个目标的图像和两个目标的图像,比例为2∶8。
目标尺寸比例:本文考虑了低空场景下无人机的尺度变化问题,借鉴COCO数据集中对于目标尺度的划分,小目标的尺寸为15×15~32×32像素,中目标的尺寸为32×32~96×96像素,大目标的尺寸为96×96~256×256像素,由于小目标检测难度较大,因此小目标的样本数量更多,具体的目标比例关系为,大、中、小目标=2∶3∶4。
具体合成步骤为:
获取目标图像:首先,在大型图像数据库中搜索得到30类无人机图像,然后进行背景剔除,考虑到在实际检测过程中,视野中可能会出现一些干扰目标,比如风筝、鸟类等,因此,也处理得到了透明背景的鸟类和风筝各20类。然后利用opencv图像处理库,引入随机函数,编写程序实现对无人机的尺寸、旋转角度的随机设置,模拟实际场景下无人机在低空中不同的飞行姿态和拍摄距离。
获取背景图像:在实际拍摄的背景图像上进行分割,步进值为200像素,分割成300×300像素大小的图像,最终选择包含天空、白云、树木、楼房、电线杆、旗杆等背景的图像1000张。
合成图像:通过程序将目标随机组合在背景图像上,最后对整张图片进行高斯噪声处理,模拟实际场景中空气、光线、阴影的影响,并根据保存的随机坐标的值,输出每张图片的标注数据,然后转换为Pascal VOC数据格式。
通过3种图像获取途径,最终得到包含16 000张训练集、2000张验证集和2000张测试集的低空无人机数据集。图1展示了部分数据集样本。

图1 数据集样本示例
2 改进SSD检测框架
2.1 FPN特征提取网络
对低空无人机的检测不仅要考虑检测准确性,还要考虑检测速度,本文基于自建数据集,实验对比了Faster RCNN、YOLO、SSD等,最后选择在检测准确性和检测速度方面表现较好的SSD网络作为本文的改进基础网络及baseline。
SSD使用了卷积网络的多层特征图,因为这些特征图是前向网络计算出来的,没有消耗额外的计算资源,因此并不影响检测速度,但是SSD丢弃了低层的特征图,直接从VGG16网络的Conv4_3层开始构建特征图,将VGG16的最后两个全连接层变为卷积层Conv6和Conv7,然后利用Conv8_2、Conv9_2、Conv10_2和Conv11_2卷积层,去掉Conv6卷积层,共利用6个卷积层,特征图尺寸分别为(38,38),(19,19),(10,10),(5,5),(3,3),(1,1)(单位为像素,后文未注明单位一律为像素),具体结构如图2所示。

图2 VGG16结构
可以看到,在VGG16网络结构图中,Conv4_3属于较高的卷积层,大小为38×38,本文数据集图片大小为300×300,小目标无人机的尺寸最大在30×30左右,Conv4_3特征图中,无人机目标的特征大小为4×4左右,小目标的低层细节特征表达不明显,所以本文在SSD网络中添加Conv3_3卷积层,Conv3_3比Conv4_3的特征图大一倍,30×30无人机的特征大小为8×8左右,Conv3_3增强了低层特征图对于小目标无人机的特征表达。
Conv8_2的特征图大小为10×10,相比于原图片,缩小了30倍,30×30的无人机目标在此特征图上的特征变成了一个像素,语义信息丰富(高层特征,比如机翼、摄像头等),但是失去了低层特征(比如边缘、纹理等细节信息)的表达。所以,本文将Conv3_3,Conv4_3,Conv7,Conv8_2这4个特征图构建为FPN(特征金字塔网络)[11],将细节信息较多的低层特征和语义信息较多的高层特征进行融合。
FPN包含两个部分:第一部分是自底向上的过程,第二部分是自顶向下和侧向连接的特征融合过程。
自底向上的过程:自底向上的过程和普通的CNN没有区别。现代的CNN网络一般都是按照特征图大小划分为不同的阶段,每个阶段之间特征图的尺度比例相差为2。Conv3_3,Conv4_3,Conv7,Conv8_2这4个特征图的尺度比例依次降低,相对于原图的步长分别为4、8、16、32。同时,通道数保持原来不变。
自顶向下过程以及侧向连接:自顶向下的过程通过上采样的方式将顶层的小特征图(例如Conv8_2的尺寸为10×10)放大到上一个特征图一样的大小(例如Conv7的尺寸为19×19)。既利用了高层较强的语义特征(利于分类),又利用了低层的高分辨率信息(利于定位)。上采样利用最近邻差值算法。
同时,为了将高层语义特征和低层的精确定位能力结合,借鉴残差网络的侧向连接结构,将上一层经过上采样后和当前层分辨率一致的特征,通过相加的方法进行融合。因为不同特征图的通道数可能不同,所以为了修正通道数量,将当前特征图先经过卷积操作,具体结构如图3所示。
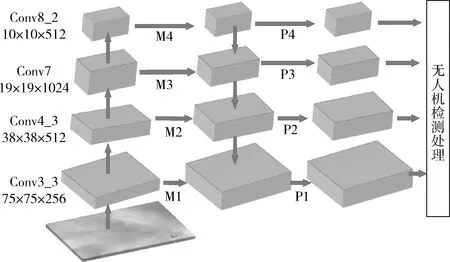
图3 FPN结构
Conv8_2特征图先经过卷积,得到M4特征图。M4通过上采样,再加上Conv7特征图,经过卷积后的特征,得到M3。这个过程再做两次,分别得到M2和M1。M层特征再经过卷积,得到最终的P1、P2、P3、P4层特征。
本文中,所有M层的通道数设计成256。
同时,为保证SSD网络对于大、中尺度无人机目标检测的鲁棒性,保留了更高层的特征图,所以,本文利用了7个特征图进行检测。图4展示了该检测模型的总体结构。从图4可以看到,用于检测的特征图包括FPN特征提取层(最终输出为4个特征图)和其余3个更高层次的特征图。低层特征图提取的是无人机的细节信息,例如旋翼的边缘轮廓、机身的纹理等,而高层特征图将细节信息进行融合,可以提取到旋翼类型、机身、摄像头,直至无人机类型等高层特征。
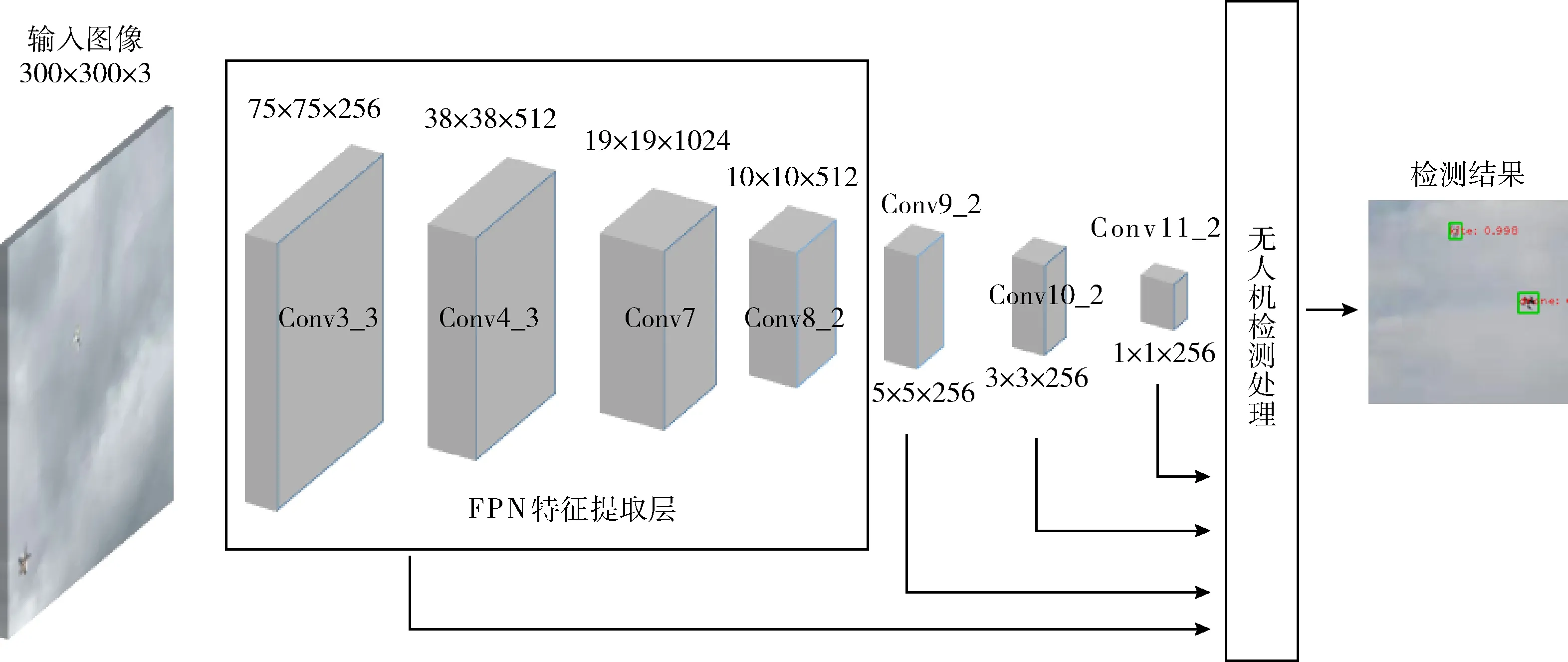
图4 基于FPN的SSD检测框架结构
2.2 基于有效感受野的先验框设计
文献[12]的研究证明,理论感受野区域内的像素对输出向量的贡献不同,对有效感受野(实际起作用的感受野)的影响呈高斯分布,有效感受野仅占理论感受野的一部分,且从中心到边缘快速衰减。有效感受野实际上是远小于理论感受野的,并且由于卷积初始化、激活函数等不同,感受野的具体形态也有所区别。
在设计先验框时,其大小应该和特征图的有效感受野相匹配。先验框过大或过小都会导致与检测目标的IOU过小,很难回归到Ground Truth,从而使得召回率较低。
为了设计更加符合有效感受野尺寸的先验框,本文计算了各个特征图的理论感受野。以Conv3_3为例,对于理论感受野的计算,采用从顶层到浅层的计算方式,Conv3_3的预测层采用尺寸为3×3,stride为1的卷积核,所以预测层的一个点映射到预测层的输入就是3×3的区域,Conv3_3输出的3×3的区域映射到Conv3_3的输入层,就是5×5的区域,5×5的区域映射到Conv3_2的输入就是7×7的区域,Conv3_2的输入是Conv3_1的输出,因此Conv3_1输出的7×7区域映射到Conv3_1层,就是9×9的区域,相同的计算方式,映射到Conv1_1的输入是48×48的区域,因为Conv1_1的输入就是原始输入图像,所以Conv3_3预测层的理论感受野是48×48。
利用同样的计算方法,可以得到Conv4_3特征图的理论感受野为108×108。原始SSD中Conv4_3特征图中设置的先验框最小尺寸为30×30,最大尺寸为42×42,对于数据集中15×15的小目标来说,最小先验框的尺寸是小目标无人机的近两倍。
从图5中可以看到,有效感受野的尺寸大于小目标的尺寸,先验框的尺寸设置和无人机的尺寸不匹配,在先验框坐标回归时,会造成先验框和目标不能有效匹配。

图5 Conv4_3特征图先验框与感受野匹配
因此,鉴于Conv4_3卷积层有效感受野大于目标尺寸的情况,本文研究了Conv3_3卷积层的有效感受野,Conv3_3的理论感受野为48×48,借鉴文献[12]的研究成果,图6展示了Conv3_3特征图下最小尺寸15×15的无人机、有效感受野、理论感受野的关系。
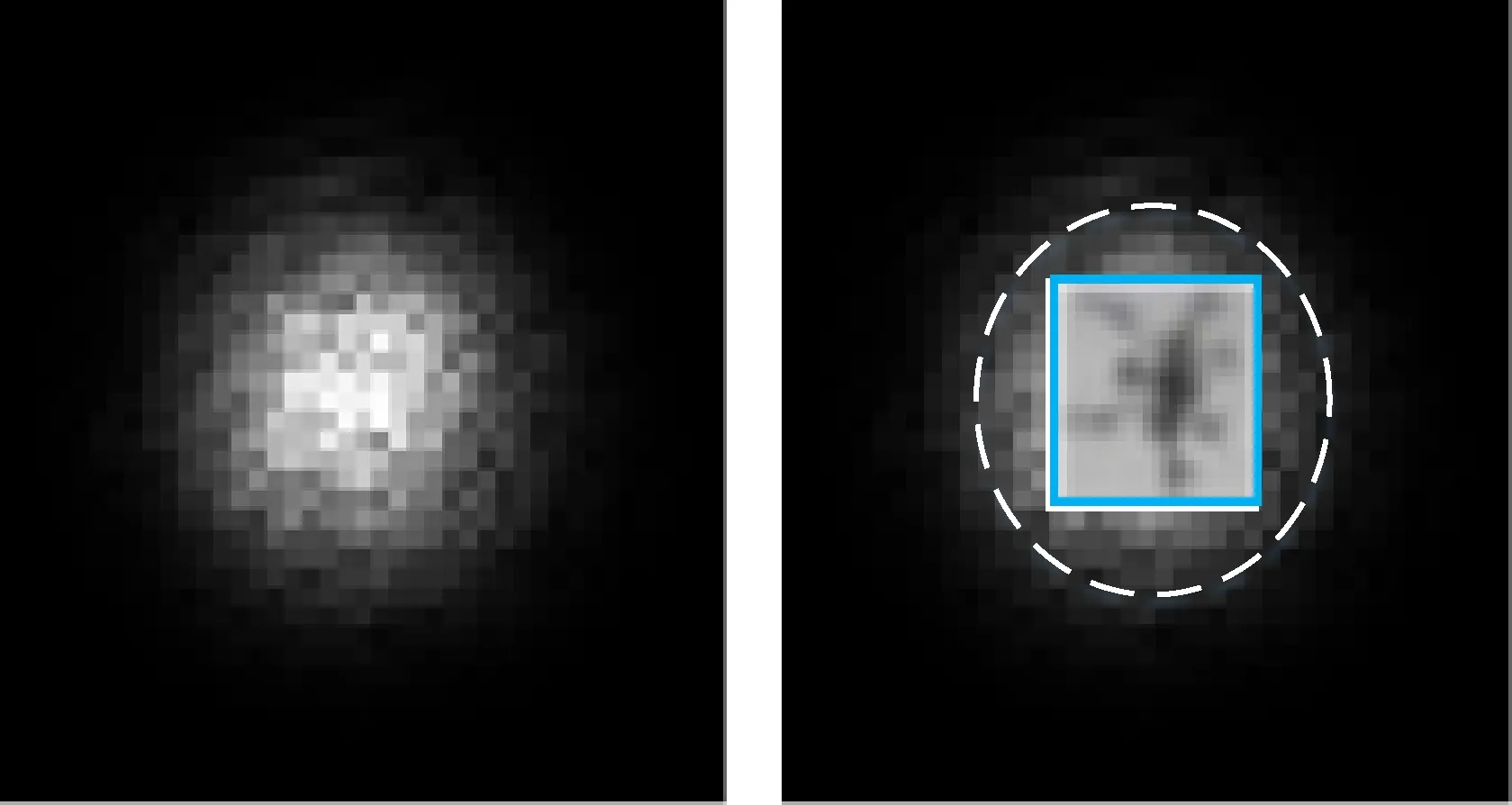
图6 Conv3_3特征图先验框与感受野
15×15尺寸的无人机与Conv3_3层的有效感受野大小基本相同,因此,将Conv3_3卷积层的先验框尺寸设计为15×15左右,可有效回归至小目标无人机位置,并在后续的实验中得以验证。之后的卷积层利用有效感受野依次设计先验框。
原始的SSD先验框尺寸和长宽比设计如下:
先验框的尺寸,按照以下公式线性递增,高层特征图的先验框尺寸较大
(1)
其中,m指的除了Conv4_3层的特征图个数。sk表示先验框尺寸相对于图片的比例,而smax和smin表示比例的最小值与最大值。
对于之后的特征图,先验框尺寸线性增加,先将尺寸比例扩大100倍,增长步长为
(2)
将各个特征图的比例除以100,再乘以图片大小,最终得到各个特征图的尺度。
(3)
(4)

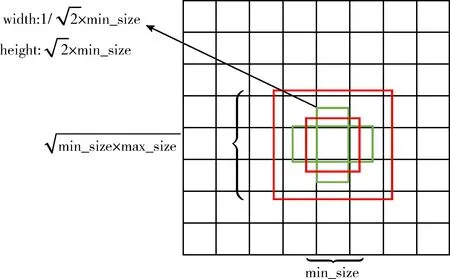
图7 先验框尺寸和长宽比设计
通过计算Conv3_3之后各个卷积层的理论感受野,对比实际感受野和按照上述计算方法得到的先验框尺寸,发现两者相对契合,因此,Conv3_3之后的先验框按照尺寸按照上述方法计算。
经过计算,表1展示了检测模型中各个卷积层的先验框尺寸和理论感受野大小。min_size、max_size分别代表每个卷积层的先验框尺寸,具体的先验框尺寸和数量由上述公式得出,RF代表每个卷积层的理论感受野,随着卷积层的加深,理论感受野逐渐增加,因此先验框的尺寸设置也越来越大,检测目标的尺寸也逐渐增大,这样的先验框设置是相对合理的。
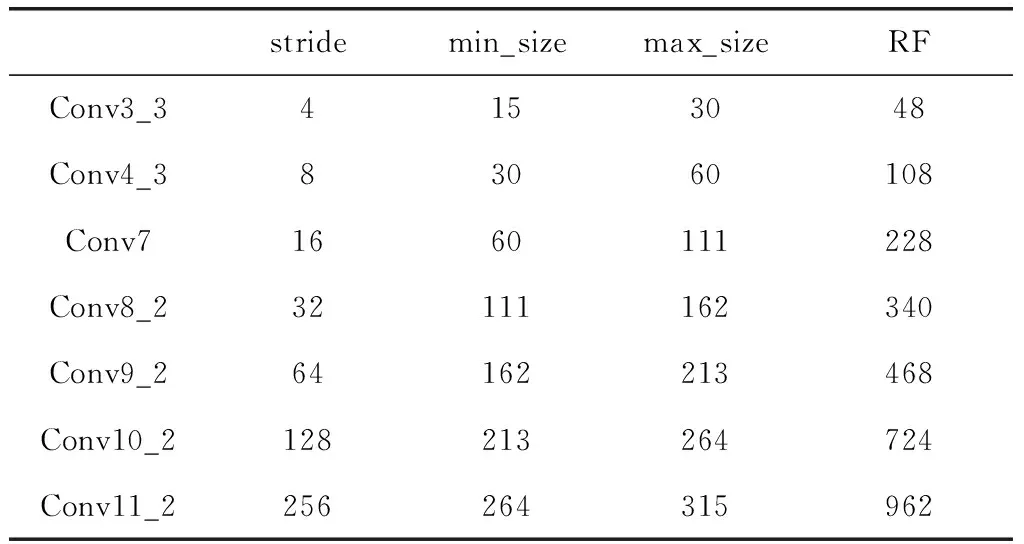
表1 先验框尺寸设计和理论感受野大小
先验框的数量设计其实就是其长宽比例选择,因为数据集中目标具有不同的长宽比例,如果先验框的长宽比例与目标相似,将有助于更快、更准确地进行先验框回归。
SSD模型共提取了Conv4_3,Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2共6个特征图,大小为(38,38),(19,19),(10,10),(5,5),(3,3),(1,1),Conv4_3,Conv10_2和Conv11_2层仅使用4个先验框(两个1∶1比例,2、1/2比例),没有3、1/3比例的先验框,总的先验框数量为
38×38×4+19×19×6+10×10×6+5×5×6+
3×3×4+1×1×4=8732
改进的基于FPN的SSD检测框架增加了Conv3_3的特征图,因为增加的特征图位于前面的卷积层,尺寸较大,如果每个位置设置4或6个先验框,那么先验框数量的暴增将带来检测速度的急剧下降,为了减少计算的复杂度,同时考虑此卷积层主要用于检测15~30范围的小目标,因此Conv3_3特征图上每个单元的先验框只设置一个,尺寸为先验框最小尺寸,尺度比例为1,最终的先验框数量为
75×75×1+38×38×4+19×19×6+10×10×6+
5×5×6+3×3×4+1×1×4=14 357
相比于原来的8732个先验框,数量增加了64%,但是增加的都是小先验框,增强了小目标检测能力。
为了研究不同先验框比例对检测效果的影响,本文设置了对比实验。
(1)去除3、1/3比例的先验框
75×75×1+38×38×4+19×19×4+10×10×4+
5×5×4+3×3×4+1×1×4=13 385
(2)去除2、1/2、3、1/3比例的先验框
75×75×1+38×38×2+19×19×2+10×10×2+
5×5×2+3×3×2+1×1×2=9505
表2显示了不同先验框数量对应的先验框长宽比例情况。

表2 先验框数量设计
以13 385先验框设计为例,表3分析了不同卷积层下先验框的数量情况。

表3 不同卷积层的先验框数量信息
Conv3_3特征图的先验框尺寸为20×20左右,数量为5625,占所有先验框数量的42%,Conv4_3特征图先验框尺寸为35×35左右,数量为5776,占所有先验框数量的43%,这些较小先验框,占先验框总量的85%左右,数量多而密集,能够更加有效地检测小目标,而更深的卷积层先
验框尺寸大,但是少而稀疏,用于检测较大目标,这种设计更加科学,适用于多尺度的目标检测场景。
3 实验与结果分析
3.1 开发环境和网络训练设置
本文选用PyTorch深度学习框架,PyTorch提供易于使用的API,不仅具有强大的GPU加速的张量计算,同时还支持自动求导动态神经网络,具体的软硬件开发环境见表4。
表4 实验开发环境
基础网络采用在VOC2007+2012数据集上的预训练模型,并将网络的预测卷积层权重进行随机初始化。训练阶段采取10折交叉验证的方法,网络批大小(batch size)设为32,采用Adam优化器,将网络训练分为两个阶段。首先固定VGG16卷积部分的权值,单独训练被随机初始化的部分,初始学习率设为0.001,学习率每个epoch下降为原来的0.94;当网络AP上升并逐渐收敛时,再调整VGG16卷积部分的权值,由于网络已经经过调整,所以将初始学习率下降为0.0001,开始对整个网络进行训练,学习率下降到0.000 01后不再变化。
3.2 评价指标
目标检测中常用的指标包括真正例(true positive,TP)、假正例(false positive,FP)、假反例(false negative,FN),其中TP表示正确识别的正样本数量,TN表示正确识别的负样本数量,FP表示错误识别的正样本数量,FN表示错误识别的负样本数量。在此基础上,精确率(precision)和召回率(recall)可以定义为
(5)
(6)
单一的precision或recall指标并不能全面衡量检测算法的性能,因此本文选取平均精度(average precision,AP)作为检测算法的评价指标,其计算方法为:将某类目标的检测结果按照置信度排序,以置信度为阈值进行划分,根据不同的Recall (R0,R1,…,Rn) 下对应的最大Precision (P0,P1,…,Pn), 求平均精度AP,计算公式为
(7)
3.3 实验结果与分析
(1)在SSD检测网络中加入了改进后的特征金字塔提取器,通过加入Conv3_3卷积层提高小目标检测能力,为了研究不同尺度比例的先验框的检测影响,设计3种不同数量的先验框,并与Faster R-CNN(ResNet101)和YOLOv3(Darknet-53)模型,在无人机目标和鸟、风筝两类负样本上进行了对比实验。实验结果见表5。
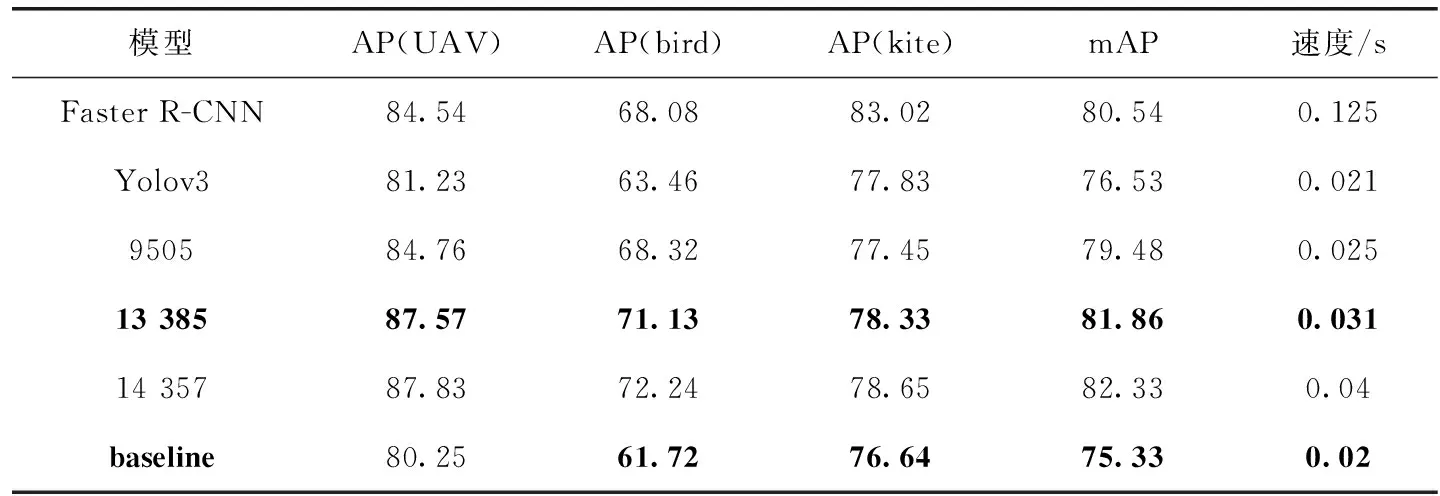
表5 不同数量先验框和模型的检测准确率和速度对比
baseline是原始SSD检测网络的检测结果,Faster R-CNN 的mAP最高,但检测速度很慢,每秒只能检测8张图片,YOLOv3通过引入特征金字塔、残差网络等思想,增加了计算量,检测准确率略高于SSD,但是检测速度低于SSD。
由于添加了尺寸较大的Conv3_3特征图,导致先验框的数量增加,由表5看出,先验框的数量为14 357时,无人机的检测准确率最高,为87.83%,但是检测的速度较慢,为0.04 s/帧。
当先验框数量为13 385时,无人机的检测准确率为87.57%,略低于87.83%,但是此时模型的检测速度为0.031 s/帧,相比于0.04 s/帧,下降了28%。改进后的模型相比于原始的SSD、YOLOv3和Faster R-CNN,取得了更好的检测效果。
从检测实时性的角度考虑,先验框数量为13 385(即删除所有3、1/3比例的先验框)时表现较优,具有较好的实用价值。
(2)除了在不同种类的目标下进行不同比例先验框的对比实验,本文还研究了不同比例先验框对多尺度无人机目标的检测影响。
影响表6中baseline检测效果的主要是小目标无人机,虽然小目标样本最多,但是检测准确率较低,在加入Conv3_3低层特征图,融合了低层特征和高层特征,构建特征金字塔网络后,当先验框数量为14 357时,小目标的检测AP从71.64%提高到了84.65%,相比于小目标,对大、中无人机目标的检测效果并没有提高太多,这也符合最初的网络设计构想,低层特征图先验框小,主要用于检测小目标,实验结果表明特征融合提高了小目标的检测准确率,并且对大、中目标的语义理解能力也有提高。

表6 不同数量先验框对各尺寸无人机的检测结果
然后,在去除Conv7、Conv8_2、Conv9_2卷积层中3、1/3比例先验框之后,数量减少为13 385,此时,对小目标无人机的检测准确率几乎没有影响,而对于大、中目标的
影响虽然比小目标大,但是影响也很小,因为3、1/3比例的先验框都在较深的卷积层内,主要预测大、中目标。
最后,去除了所有2、1/2比例的先验框,因为很多目标的尺寸都是这个比例,并且除了新添加的Conv3_3卷积层外,所有的卷积层都设置了这个比例的先验框,因此,检测准确率全部降低,甚至跌到了baseline以下,但是小目标的检测效果还是比baseline要好,提高了12%左右,这进一步说明了Conv3_3卷积层对于小目标检测的作用,并且由于Conv3_3卷积层原来也只有1比例的先验框,因此对于小目标的检测准确率几乎没有降低。
考虑到检测实时性,去除3、1/3比例的先验框对无人机的检测准确率并没有太大影响,因此在实际应用时,应优先考虑使用先验框数量为13 385的检测算法。
(3)不同卷积层对各尺寸无人机的检测影响。在对无人机的实际检测过程中,可能会有不同的检测需求,比如某段时间需要重点关注大目标无人机,某段时间需要检测小目标,为了满足这种模块化定制需求,同时为了更加深入了解模型中各个卷积层对不同尺寸目标的检测能力,本文通过去除不同的卷积层,实验对比不同卷积层对各尺度无人机的检测效果,表7中的标记代表去除该卷积层。

表7 不同卷积层对各尺寸无人机的检测影响
分析表7的结果,Conv3_3卷积层对小目标的检测效果影响最大,对大、中尺寸目标的检测效果影响较小,去除该卷积层后,小目标检测AP降低了13.2%,之后的各卷积层对检测效果的影响逐步降低,值得注意的是,更深的卷积层对小目标检测结果依然有影响,说明小目标的语义信息在深层卷积层中得到了表达。Conv4_3卷积层对中目标的影响最大,AP降低了17.3%,这说明,原来的SSD检测模型最低的卷积层用以预测中等尺寸目标,并没有对小目标给予过多考虑。对大目标影响较大的是Conv7及Conv8_2卷积层,分别为20.3%和14.3%。
另外,由表7可以看到,Conv9_2及更深的卷积层对大尺寸无人机目标的影响较小,这可能是因为本数据集中无人机的尺寸较小,最大的无人机尺寸为256×256,而高层卷积层用以检测更大尺寸的目标,因此,在本数据集下,出于降低模型复杂度和检测时间的考虑,可以适当地根据不同的检测需求,精简对检测效果影响较小的卷积层。
图8(a)和图8(b)展示了原始SSD网络与改进后的模型(先验框数量为13 385)在实地拍摄的无人机图像上的检测对比结果,图8(a)为改进前的检测结果,图8(b)为改进后的检测结果。图8(c)是在CVPR无人机挑战赛视频序列上的检测结果。可以看到,在背景单一,目标尺寸较大的情况下,无人机的检测准确率高,而对于背景复杂,目标较小且模糊的情况,检测准确率较低。

图8 检测结果
4 结束语
本文针对低空无人机检测的实际需求,提出了基于SSD模型改进的检测算法。建立了低空场景下的多尺度无人机数据集,通过引入VGG16特征提取网络的低层特征图Conv3_3,有效改善小目标无人机的检测效果,通过构建特征金字塔,增强了多尺度目标检测能力。
接着分析理论感受野、有效感受野和SSD先验框的设计原理,利用有效感受野技术,重新设计了各特征图的先验框的尺寸和长宽比,使先验框与无人机目标相匹配,并进行不同先验框数量的对比实验。从检测实时性的角度考虑,先验框数量为13 385(即删除所有3、1/3比例的先验框)时表现较优,相比于原始的SSD检测网络,无人机的检测AP提高了7.32%,小目标无人机的检测AP提高了12.89%。
实验结果表明,本文所提出的改进SSD检测算法在低空无人机检测场景中具有很好的多尺度目标检测能力,并且具有较好的实时性和抗干扰能力,在工程应用上具有一定的参考价值。
虽然优化后的方法相较于原始方法在检测性能上有较大提升,但仍存在一些不足:①无人机目标的类别较少,接下来的研究工作可获取更多类别和姿态的无人机图像;②无人机图像光照条件单一,没有考虑傍晚或夜间光照下的检测问题,使得该检测算法应用场景受限,之后的研究将完善这些不足。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
小学生学习指导(高年级)(2021年3期)2021-04-06
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年5期)2017-05-14
红土地(2016年7期)2016-02-27
探测与控制学报(2015年4期)2015-12-15
东南法学(2015年2期)2015-06-05
中国卫生(2014年7期)2014-11-10
