
基于CATBL算法的恶意URL检测
2021-11-20 01:56修位蓉王欢欢
计算机工程与设计 2021年11期
修位蓉,王欢欢,卞 琛
(1.广州商学院 信息技术与工程学院,广东 广州 510700;2.新疆大学 软件学院,新疆 乌鲁木齐 830091;3.广东金融学院 互联网金融与信息工程学院,广东 广州 510521)
0 引 言
随着恶意URL灰色产业的发展,恶意URL不仅在外观上与良性URL极为相似,进入之后的所见内容也同样难以分辨,而现有的恶意URL检测方式大多是基于传统、单一的算法模型,检测效果欠佳,因此针对恶意URL检测的研究显得尤为迫切。
深度学习算法是机器学习算法领域中一个新兴方向,在自然语言处理、数据挖掘、图像处理、机器翻译领域都取得了不错的表现,同时也为恶意URL检测研究注入了新的活力。本文基于深度学习算法提出CATBL并联联合算法,将主机信息特征、URL信息特征、纹理图像特征进行特征融合,然后利用融合过后的特征使用CATBL并联联合算法进行恶意URL分析检测。
1 国内外研究现状
针对恶意URL检测相关研究,目前国内外的研究人员已经提出了多种检测方法与检测技术。如国外的Chaochao Luo等[1]使用自动编码器表示URL,然后将表示的URL输入到提议的复合神经网络中进行检测,为评估提议的系统,对HTTP CSIC2010数据集和收集的数据集进行了广泛的实验。N Vanitha等[2]通过使用机器学习算法(称为逻辑回归)自动对URL进行分类,该算法用于二进制分类,通过学习网络钓鱼URL,分类器可达到97%的准确性。N.B等[3]使用决策树分类器对基于时间分割的数据分组具有更好的性能,准确度为88.5%,提出的框架可以实时收集数据并以分布式方式处理以提供态势感知,通过向现有系统添加额外的资源,可以轻松地将建议的框架扩展为处理各种大量的网络事件。Huaizhi Yan等[4]提出了一种使用堆叠去噪自动编码器模型的深度学习方法,以学习和检测内部恶意特征。Ripon Patgiri等[5]在文中将恶意URL检测视为二进制分类问题,使用测试数据测试了几种知名分类器的性能,并特别研究了随机森林算法和支持向量机(SVM),这些具有很高精度的算法用于训练数据集,以对好URL和坏URL进行分类。Baojiang Cui等[6]基于梯度学习的统计分析和使用S形阈值水平的特征提取相结合,提出了一种基于机器学习技术的新检测方法,使用朴素的贝叶斯,决策树和SVM分类器来验证该方法的准确性和效率。
在国内,李敬涛等[7]对基于机器学习的JavaScript恶意脚本检测方案进行了改进,所设计的检测改进方案能够对JavaScript脚本及包含恶意脚本的HTML页面进行高效准确的检测。李艳等[8]利用信息论测度知识来检测JavaScript混淆代码,能够捕获基于统计特征检测器的逃逸攻击,并对混淆代码进行反混淆,最后利用机器学习知识来检测JavaScript恶意代码。左雯等[9]设计了基于关键字的用于恶意URL检测的神经网络模型;该模型用卷积神经网络进行URL的特征抽取,使用GRU进行时间维度上的特征捕获,并实现了一套用于恶意URL的可视化检测系统。吴海滨等[10]提出基于上下文信息的恶意URL检测方法,该检测方法利用预处理方法解决URL中存在大量的随机字符组成单词的问题,使用特殊符号作为分隔符对URL分词,对得到的分词结果使用Word2vec生成词向量空间,训练卷积神经网络提取文本特征并分类。
以往的恶意URL检测大多基于黑名单技术[11,12]、信誉系统[13]、主机特征[14,15]、词汇特征、蜜罐技术[16]、入侵检测技术[17]。本文提出一种基于CATBL的恶意URL检测算法。
本文的主要贡献如下:
(1)提取主机信息特征、URL信息特征,并且利用图像处理相关技术提取出纹理图像特征,之后将筛选后的纹理图像特征、URL信息特征、主机信息特征进行了有效特征融合,并且使用并联联合CATBL算法模型进行检测。
(2)利用CNN提取深层次局部特征,Attention机制调整权重,注意力机制与CNN算法进行并联处理得到更加有效的特征信息,然后双向LSTM提取全局特征,与注意力机制和CNN的并联联合算法模型进行并联处理得到全面的特征信息,将并联联合CATBL算法用于恶意URL分析与检测。
2 算法模型
2.1 特征分析
在检测研究中提取的特征对于恶意URL的检测结果有着至关重要的影响,提取有效的特征对于恶意URL检测研究也是非常重要的。因此,本文不仅提取主机信息特征、URL信息特征,还将在图像处理相关技术学习基础上提取的纹理图像特征用于恶意URL检测。
2.1.1 主机信息特征
主机信息能够从主机名的属性中获得,其中可以获得主机的多种相关信息,深入URL数据的主机内部获得信息,能够提高特征的有效性,有利于恶意URL检测的相关研究,通过学习主机信息特征能够获得主机时间、身份、主机位置等相关信息,此处提取获得的主机信息包括百度反链、百度安全、百度是否收录、百度权重、360是否收录、百度1天反链、百度7天反链、百度1天收录、百度7天收录等等多种信息,用于恶意URL检测以提高检测结果。本研究借助主机信息采集网站人工提取得到了20种主机信息特征,进行筛选、过滤之后得到数据的15种主机信息组成为本文的主机信息特征。
2.1.2 URL信息特征
由于原始的URL数据是字符串,通过对机器学习的学习可以理解其是不可行的,因此必须将数据进行处理以得到有效的信息,此特征是从URL数据本身得到的,故此类信息称之为URL信息特征。此处提取获得的URL信息特征包括URL长度、其它字符的个数、首个小数点的位置、大写字母的个数、最长字符的个数、顶级域名是否为五大域名、分隔符之间字符的最大长度、小写字母的个数、URL中总数字个数、是不是IP地址等等多种信息,用于恶意URL检测以提高检测结果。本研究使用Java代码提取出21种数据本身共性较大的信息,进行筛选、过滤之后得到URL信息特征。
2.1.3 纹理图像特征
如图1所示,基于图像处理的相关技术,由于恶意URL在纹理上的相似性,将图像处理技术用于URL特征提取,恶意URL被映射到未压缩的灰度图片上[18,19]。在获得的URL数据的二进制字符基础上,把8位无符号整数范围内的二维空间域纹理图像特征转换为与灰度图像灰度值范围相对应,以得到纹理图像特征用于恶意URL检测以提高检测结果。

图1 纹理图像特征分析
2.2 特征融合
将已有特征进行融合是为了提高特征在URL的检测实验中的效果,充分挖掘各类特征的隐藏信息,有助于得到更好的检测,此处将主机信息特征、纹理图像特征、URL信息特征进行了充分的融合[20],其伪代码见表1。

表1 特征融合
在表1中,SL是将数据进行标注自动生成的label文件,SF1是将主机信息特征进行输入,SF2是将URL信息特征进行输入,S是将主机信息特征与URL信息特征进行训练、融合得到S块特征,SF3是将纹理图像特征进行输入,S是将S块特征与纹理图像特征进行训练、融合得到新的S块特征,在subtrain.drop代码中是将label文件与S块特征进行学习、训练,在subtrain代码中是将得到恶意URL进行分析与检测结果。
2.3 CATBL算法
深度学习算法已经在图像处理、自然语言处理、语音识别等领域取得成效,同时也为恶意URL检测研究带来了新的希望。在深度学习的算法模型中,卷积神经网络(convolutional neural network,CNN)是一种专门用来处理具有类似网络结构的且由卷积层、池化层、全连接层组成的神经网络。其中,卷积层与池化层将要组成多个卷积组,并且逐层进行提取特征,然后利用多个全连接层完成分类。但是卷积神经网络中输入的关联性较差,输出的也相对独立,存在一定的弊端,Attention对于弥补这个弊端具有一定的成效,注意力机制借助人类的思维模式,关注焦点,考虑上下文存在的关系,建模长距离能力强大,具有提取语义特征的能力,增强其关联性,因此考虑将卷积神经网络与Attention机制进行结合。长短时记忆(long short-term memory,LSTM)[21]是基于循环神经网络(recurrent neural network,RNN)改进的,循环神经网络具有强大的连接能力,获取时间动态的能力以及学习上下文相关信息的能力,但存在梯度爆炸或者消失问题,LSTM可以解决简单循环神经网络存在的此类问题。LSTM利用引入输入门(input gates)、遗忘门(forget gates)和输出门(output gates)以控制信息传递,有利于解决长期依赖弊端。
因此,CATBL并联联合算法模型首先将卷积神经网络与注意力机制进行并联联合处理得到CAT并联联合算法模型,然后将CAT并联联合算法模型与Bi-LSTM算法再次进行并联联合处理,称之为CATBL算法。卷积神经网络由卷积层、池化层和全连接层组成,其中池化层不仅可以缩小输入矩阵的尺寸,加快计算速度,有效防止过拟合并降低特征维度;卷积层与池化层将要组成多个卷积组,逐层进行提取特征;最后通过构建多个全连接层完成最终分类。CATBL算法的输入层为M∈{(x1,y1),(x2,y2)…(xn,yn)}, (x1,x2…xn) 用于表示输入的特征,yn∈(1,0) 表示URL的label,卷积层的计算公式为
(1)
其中,l表示层数,Mj为一个输入特征,T为某一神经元,C为偏移向量。
池化层不仅可以缩小输入矩阵的尺寸,并且可以加快计算速度,而且可以有效的防止过拟合,并降低特征维度。池化层的计算公式为
(2)
其中,l表示层数,Mj为一个输入特征,T为某一神经元,C为偏移向量,m表示池化层窗口大小。
但是CNN中输入的关联性较差,输出的也相对独立,对于滋生快速且变化种类多样的恶意URL,不能达到很好的识别和分类效果,缺乏检测新生成的恶意URL的能力,恶意URL检测的普遍性较差。然而,Attention对于弥补这个弊端具有一定的成效,注意力机制借助人类的思维模式,关注焦点,弱化无用信息的注意力,考虑上下文存在的关系,建模长距离能力强大,具有提取语义特征的能力,增强其关联性,因此将CNN与Attention机制在此处进行了并联联合算法的处理以期望算法模型能够优劣互补。首先,我们从输入层输入两层特征M∈{(x1,y1),(x2,y2)…(xn,yn)}, 且 (x1,x2…xn) 表示输入的特征,yn∈(1,0) 表示URL的label,且注意力计算权重的公式为
(3)
其中,Wi表示计算得到的注意力权重,Mi表示特征输入,同时对T进行了注意力加权,输出特征S的计算公式为
(4)
长短时记忆能够获取时间动态并学习上下文相关信息,能够有效解决长期依赖的弊端,并能防止循环神经网络的梯度爆炸或消失问题,因此将其并联得到CATBL联合算法。
LSTM的结构图如图2所示。

图2 LSTM结构
在时间t的LSTM更新公式如下
it=σ(wiht-1+uixt+bi)
(5)
ft=σ(wfht-1+ufxt+bf)
(6)
(7)
(8)
ot=σ(woht-1+uoxt+bo)
(9)
ht=otΘtanh(ct)
(10)
其中,σ是非线性sigmoid函数,Θ是两个向量间的点乘操作。xt是时间t处的输入矢量,ht是存储时间t处的所有有用信息的隐藏状态矢量。ui,uf,uc,uo表示输入xt的不同门的权重矩阵,wi,wf,wc,wo是隐藏状态ht的权重矩阵。bi,bf,bc,bo表示偏向量。
LSTM在学习上下文相关信息的能力方面只能学习到上文信息,无法完成下文信息的学习,对未来的信息是无法进行预测的。但是Bi-LSTM通过增加一层反向的LSTM解决了这个问题,在t(t=1,2,3,…,n) 时刻的输出为
Ht=hbt+hft
(11)
其中,Ht是Bi-LSTM模型在t时刻的输出,hbt是前向LSTM在t时刻的输出,hft是后向LSTM在t时刻的输出。
综上所述,Bi-LSTM的基本结构如图3所示。图3中 {M1…Mn}, {Mn…Mt} 为前向LSTM模型输入, {Ma…Ms}, {Ms…Mi} 为后向LSTM模型输入, {H1…Hn}, {Hn…Ht}, {Ha…Hs}, {Hs…Hi} 为Bi-LSTM算法在t时刻的输出。
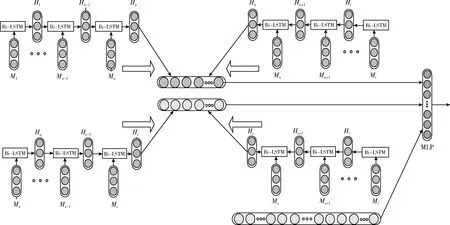
图3 Bi-LSTM结构
基于以上分析,设计CATBL并联联合算法,其模型结构如图4所示。图4展示将融合后的特征作为输入层的特征分别输入到CNN、注意力机制和Bi-LSTM算法,将CNN与注意力机制进行并联联合处理后得到新的全局特征,此时输入层特征经过Bi-LSTM算法训练学习后得到新的信息,再与CNN_Att算法进行并联联合处理得到深层次局部特征从而获得更加全面的数据特征信息,最后softmax分类器进行分类并得到恶意URL检测结果。
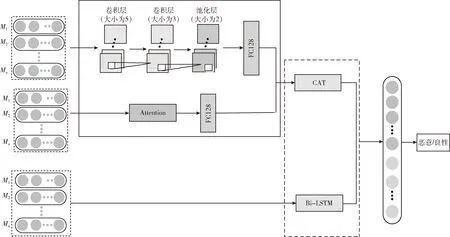
图4 CATBL结构
3 实验及分析
3.1 实验数据
本实验的数据是基于公开数据集PhishTank与爬虫抓取的良性URL组成的两万条URL数据集。在组成数据集之前,我们将从PhishTank上下载得到的恶意URL与爬虫得到的良性URL进行了简单的去重、降噪等处理之后得到了一万条数据,其中有效恶意URL和良性URL均保留一万条,其后将数据进行标注自动生成label文件,同时,在此数据集上进行特征提取。
3.2 实验环境
算法的实验环境配置见表2。
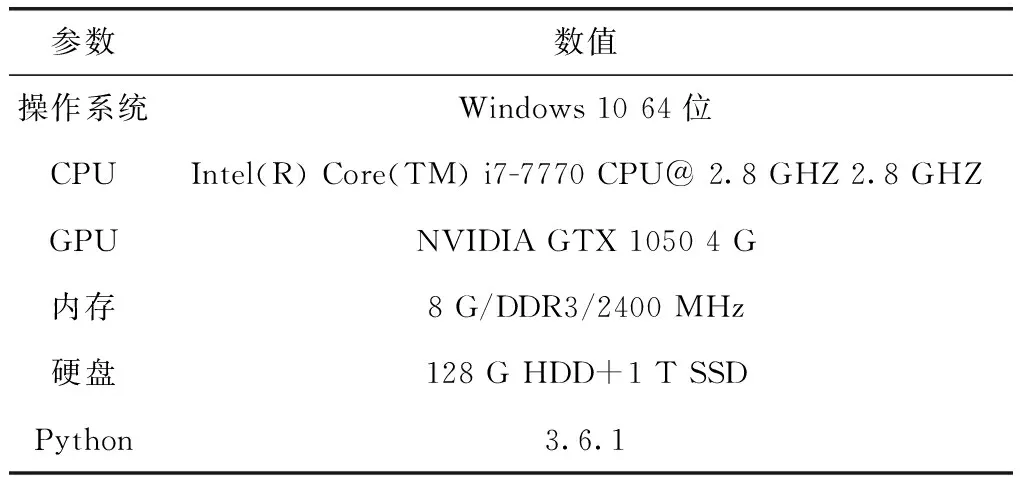
表2 实验环境的设置
3.3 最优参数的设置
算法模型参数的设置对于恶意URL检测的结果起着至关重要的作用,前期工作在大量的实验基础上得到实验最优参数的设置,表3展示了迭代次数(ep)、批处理量(batch_size)、卷积核的个数(filters)、卷积核的大小(filters_size)以及测试集的划分(test_size)等重要参数信息,3.4节将对批处理量等最优参数的获取过程进行详细说明。
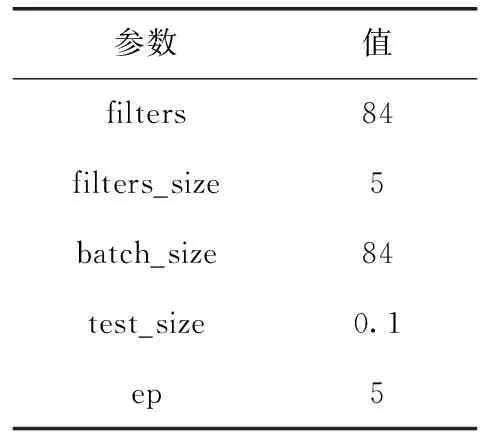
表3 最优参数的设置
3.4 实验结果与分析
本节将从批处理量参数对检测结果的有效性、纹理图像特征对检测结果的有效性、URL词向量特征对检测结果的有效性与CATBL串联联合算法及其它机器学习算法的检
测结果进行对比以进行本文的检测结果分析。
3.4.1 批处理量参数对检测结果的有效性
实验首先测试批处理量可变参数,为使检测效果达到最优,实验在同一数据集不同数据量条件下进行对比,通过多次测试以得到最优参数配置,实验结果如图5所示。

图5 批处理量参数测试
由图5中的多组检测结果可以看到,在不同的数据量下批处理量参数不同时,获得的检测结果有一个共同点,即是当批处理量参数为84时检测结果最高,由此可以得到批处理量参数为84时为该参数的最优配置。
3.4.2 纹理图像特征对检测结果的有效性
算法在不同的数据量下进行了添加或删除纹理图像特征的方式进行检测实验,以得到的恶意URL检测的准确度来说明纹理图像特征的有效性。
从图6可以看出,当无纹理图像特征时,得到的最高检测结果为97.8%,而添加纹理图像特征之后,得到的最高检测结果为98.8%,且在不同的数据量下都具有更优的检测结果,所以可以得知纹理图像特征对于恶意URL检测的结果有着非常重要的影响。

图6 纹理图像特征对检测结果的有效性
3.4.3 URL信息特征对检测结果的有效性
此节在不同的数据量下进行了添加或删除URL信息特征的方式进行检测实验,得到恶意URL检测的准确度以说明URL信息特征的有效性。
从图7可以看到,当无URL信息特征时,得到的最高检测结果为96.6%,而添加URL信息特征之后,得到的最高检测结果为98.8%,且在不同的数据量下都具有更优的检测结果,所以可以得知URL信息特征对于恶意URL检测结果有非常重要的影响。

图7 URL信息特征对检测结果的有效性
3.4.4 与CATBL串联联合算法对比
在当今的恶意URL检测大多是基于传统的机器学习算法,同时又出现了基于串联联合算法的检测,并且相对于传统的机器学习算法在恶意URL检测方面具有显著的提高,而串联联合算法无法学习得到全面特征,故本节我们将提出的CATBL并联联合算法与CATBL串联联合算法进行对比。
从图8可以看出,在不同的数据量下,CATBL并联联合算法在恶意URL检测结果均高于CATBL串联联合算法检测结果,在保证同样的实验环境与算法参数的情况下,CATBL串联联合算法得到的恶意URL检测的结果最高为98.08%,而CATBL并联联合算法得到的检测结果为98.8%,由此可以看出,CATBL并联联合算法提高了CATBL串联联合算法在恶意URL检测的结果。

图8 CATBL串联与并联算法对比
3.4.5 其它机器学习算法的检测结果
在本节,同单一机器学习算法KNN、高斯贝叶斯、深度学习模型CNN、Attention、Bi-LSTM进行对比以验证提出CATBL并联联合算法在恶意URL检测方面的有效性,其检测结果对比见表4。
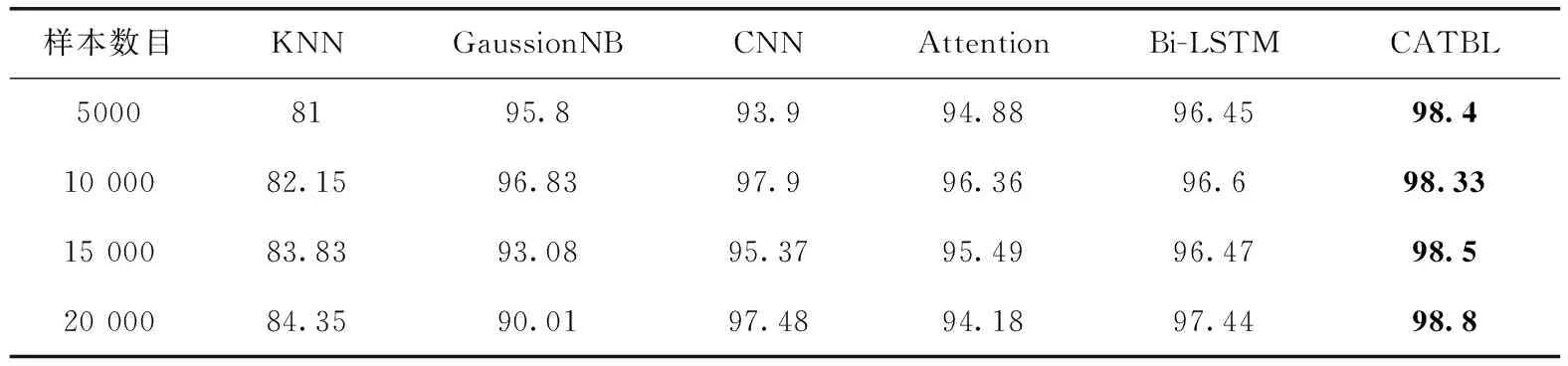
表4 同其它模型对比/%
由表4可以看出,KNN算法得到的最高检测结果为84.35%,高斯贝叶斯得到的最高检测结果为96.83%,CNN算法得到的最高检测结果为97.9%,Attention算法得到的最高检测结果为96.36%,Bi-LSTM算法得到的最高检测结果为97.44%,而CATBL并联联合算法得到的最高检测结果为98.8%,且在不同的数据量下,本文提出的CATBL并联联合算法的检测结果均比KNN模型、高斯贝叶斯算法、CNN算法、Attention与Bi-LSTM算法在恶意URL检测结果高,且有了明显的升高。故可以说明,CATBL并联联合算法提高了恶意URL检测的结果。
4 结束语
本文提出了一种CATBL并联联合算法,提取了主机信息特征、URL信息特征与纹理图像特征用于恶意URL检测,通过从批处理量参数测试、纹理图像特征测试、URL词向量特征测试以及与其它机器学习算法的对比实验进行算法有效性验证,检测结果表明:通过融合主机信息特征、URL信息特征与纹理图像特征训练的CATBL并联联合算法的恶意URL检测准确率达到了98.8%,与传统的检测方式相比有了较为明显的提升。
猜你喜欢
中学生数理化·中考版(2021年10期)2021-11-22
北京航空航天大学学报(2021年9期)2021-11-02
软件(2020年3期)2020-04-20
电子制作(2019年11期)2019-07-04
摄影之友(影像视觉)(2018年12期)2019-01-28
北京航空航天大学学报(2018年1期)2018-04-20
Coco薇(2017年8期)2017-08-03
中国环境监察(2016年7期)2016-10-23
通信电源技术(2016年1期)2016-04-16
Coco薇(2015年5期)2016-03-29
