
格上筛法研究现状与发展趋势*
2021-11-20 02:14路献辉王鲲鹏
密码学报 2021年5期
毕 蕾,路献辉,3,王鲲鹏
1.中国科学院 信息工程研究所 信息安全国家重点实验室,北京 100093
2.中国科学院大学 网络空间安全学院,北京 100049
3.密码科学技术国家重点实验室,北京 100878
1 引言
格密码近年来广受关注.由于量子计算机的迅速发展,一些经典模型下的困难问题在量子计算环境下变得可以被有效求解.如果大规模的量子计算得以实现,现有的公钥密码安全将受到巨大的威胁和挑战.因此,许多国家的政府和研究机构已逐步发起了在量子计算模型下安全的公钥密码算法,即后量子公钥密码的研发工作.格密码由于在安全性、公私钥尺寸、计算速度上的优势,以及抵抗量子攻击的能力,是其中最受瞩目的类型之一.2020年,NIST后量子密码算法标准征集的第三轮7个方案中有5个是基于格构造的,格密码在未来有望替代RSA等现行公钥密码算法成为新一代的公钥密码标准.
格理论最初在密码学中是一种分析工具,曾被用于分析背包密码体制、RSA密码体制等[1,2].1996年,Ajtai[3]开创性地给出了格中唯一最短向量问题(unique shortest vector problem,uSVP)在worstcase下到小整数解(small integer solutions,SIS)问题在average-case下的归约证明,即这些困难问题在最坏情况下的困难性可以归约到一类随机格中问题的困难性,因此基于格的密码体制可以提供最坏情况下的可证明安全性.
1997年,Ajtai-Dwork[4]首次将其作为一种设计工具,构造了第一个具有可证明安全的基于格的公钥密码体制AjtaiDwork,该方案的安全性基于格上唯一最短向量问题(unique shortest vector problem,uSVP)的困难性.此外,初期的格密码方案还有NTRU密码体制[5]、GGH密码体制[6]等.这一时期的格密码方案由于存在密钥尺寸过大或者缺乏严格的安全性证明等缺陷,无法满足实际应用的需求.
2005年,格密码理论取得突破性进展—Regev[7]提出了基于带错误的学习(learning with errors,LWE)问题的公钥加密算法,大幅度缩小了密文和密钥尺寸,同时又将加密算法的安全性归约到了格上最坏情况困难问题的难解性—在量子归约下,它至少与worst-case下的最短向量问题(shortest vector problem,SVP)的变体一样困难.此后,LWE问题在格密码方案的设计中得到了广泛的应用.研究者们基于LWE问题提出了许多格密码方案,如加密[8]、数字签名[9]、密钥交换[10]、全同态加密[11]等.
目前,大部分格密码方案是基于带错误学习(learning with errors,LWE)问题和NTRU假设构造的,而LWE和NTRU都可以用SVP求解算法进行求解,因此SVP求解问题的算法对于分析这些格密码方案的实际安全性至关重要.
1.1 最短向量问题
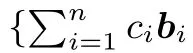
求解SVP的常用算法是BKZ算法,在使用BKZ算法求解SVP时,需要将SVP精确求解算法嵌入BKZ算法的每一个基本模块作为子程序,最终输出最短向量的近似解.使用BKZ算法进行实际安全性分析,并将其中内嵌的精确SVP求解算法的复杂度作为算法总的时间复杂度的评估方式称为coreSVP方法,这种方法是目前应用最广泛的格密码具体安全性评估方法.
SVP精确求解算法主要有以下四类:枚举(enumeration)[12]、筛法(sieving)[13]、基于voronoi的方法(voronoi-based approach)[14]和离散高斯抽样(discrete Gaussian sampling)[15].其中可实用化的有枚举和筛法.枚举的时间和空间复杂度分别为2ω(n)和poly(n),而筛法的时间和空间复杂度均为2Θ(n),其中n是格的维度.相比于枚举算法,筛法的时间复杂度更低,因此是目前实用化格密码算法实际安全性评估中主要使用的SVP精确求解算法.
1.2 筛法求解SVP
筛法是在2001年由Ajtai-Kumar-Sivakumar[13]首次提出的,称为AKS筛法(AKS Sieve).AKS筛法求解SVP可分为三个步骤:首先生成指数级别的格向量,然后对这些向量进行筛选,在每一轮筛选中,将这些向量按照一定的规则遍历、约化,使得向量的长度越来越短,最终得到一定数量的长度为O(λ1(Λ))的格向量,最后将这些向量两两相减,即可得到格中最短向量s∈Λ∧||s||=λ1(Λ).按照这一思路构造的筛法统称为AKS类筛法.
除AKS类筛法外,还有另一类构造思路不同的筛法,称为MV类筛法.这类筛法的初始列表是一个空列表,在算法过程中不断抽取格向量并使用已经在列表中的向量对其进行约化,再约化后的向量添加至列表中,重复此过程直至找到格中最短向量.第一个MV类筛法是由Micciancio-Voulgaris[16]提出的列表筛法(ListSieve).
AKS筛法和列表筛法都是理论算法,即它们的正确性和复杂度都有严格的理论证明,并不依赖任何启发式假设.但为了证明它们的正确性,算法中使用了一些随机扰动技术,这种技术使算法本身效率很低,因此理论算法很难在实际中使用.基于这两种理论算法,研究者们又提出了它们所对应启发式版本—NV筛法(NV Sieve)[17]和高斯筛法(Gauss Sieve)[16].启发式算法去掉了扰动技术,并引入了一些启发式假设,使得算法丢失了对于正确性和复杂度的理论保障,但是在实际使用时更加高效.
据此,我们可将现有筛法按筛取的方式不同以及是否依赖启发式假设分为四大类,如图1所示1图中数组(c t,c s)表示算法的时间复杂度和空间复杂度为和.下文中的复杂度表示中2cn亦指2cn+o(n).该图中未标识出减秩筛法,因为该类算法着重于实际应用,并未在复杂度层面对算法进行优化..近十年来,研究者们对这四类筛法中的基本算法进行了各种改进(如表1所示),主要目标是优化筛法中的遍历过程.Pujol-Stehlé[18]指出利用生日悖论可降低AKS筛法和列表筛法最后一个步骤中需要的长度为O(λ1(Λ))的向量的数目,从而降低算法的空间和时间复杂度.
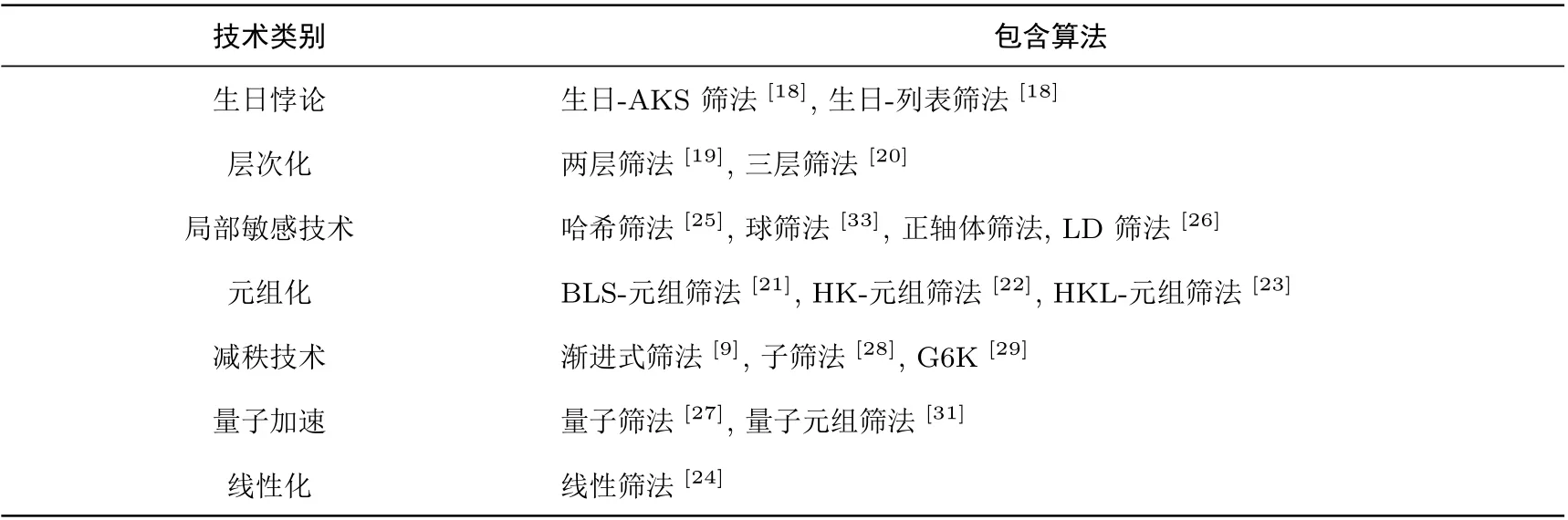
表1 筛法技术分类Table 1 Sieving algorithms classified by technique
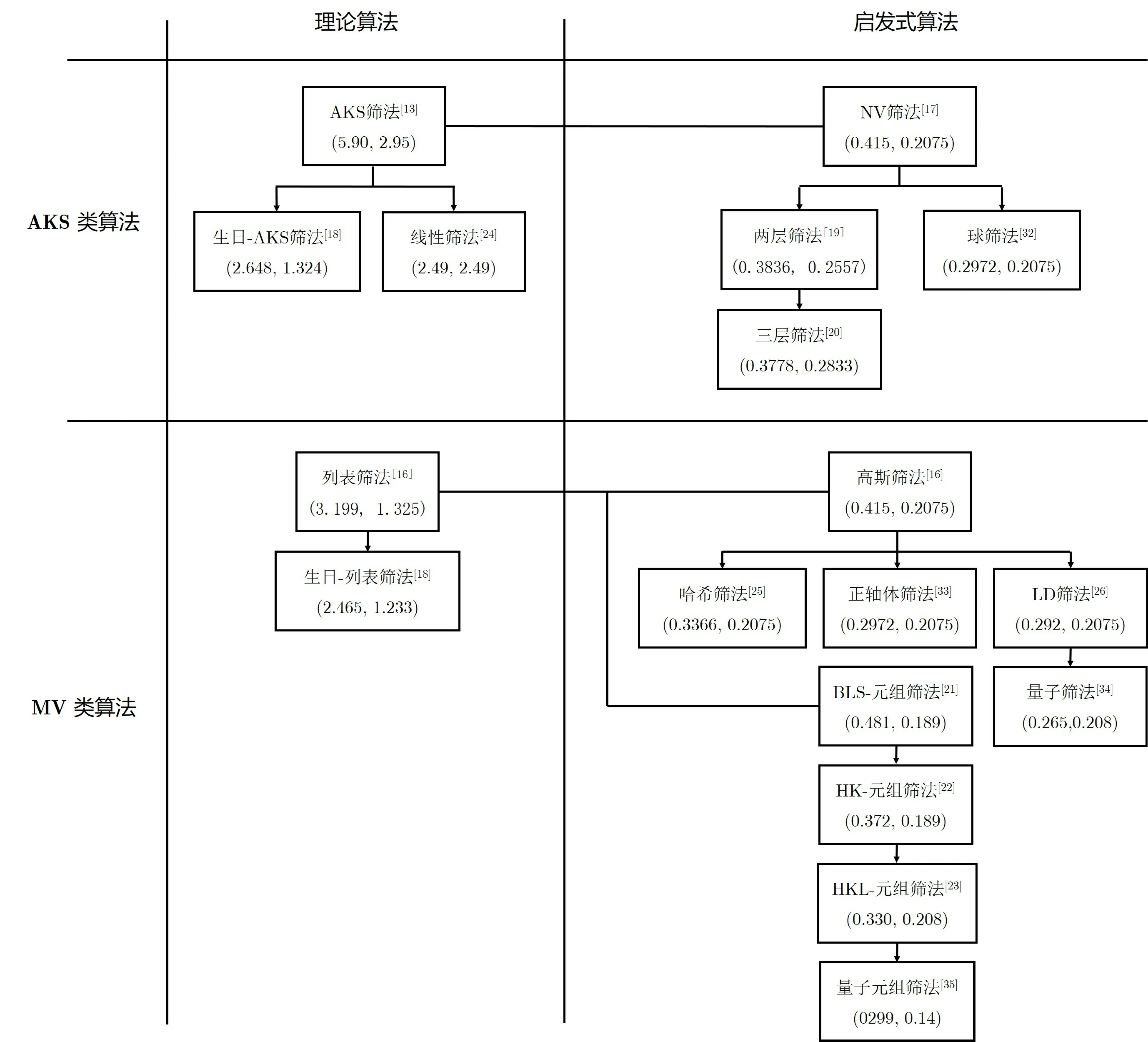
图1 筛法发展历程Figure 1 process of sieving
Wang-Liu-Tian-Bi[19]和Zhang-Pan-Hu[20]提出的层次筛法(Level Sieve)以NV筛法为起点,将筛法的每一轮分为多个层次进行,使得算法从遍历所有向量变成先划分大区域,再在大区域中进行分别遍历和约化,使得算法所需遍历向量数目减少,时间复杂度降低.Bai-Laarhoven-Stehlé[21]提出的元组筛法(Tuple Sieve)以列表筛法为基础,在约化向量时每次约化多个向量而非仅仅两个,这使算法需要的初始格向量个数减少,从而降低了算法的空间复杂度.之后,Herold-Kirshanova[22]和Herold-Kirshanova-Laarhoven[23]对元组筛法中寻找短向量的过程给出了更快的算法.Mukhopadhyay[24]提出的线性筛法(Linear Sieve)将之前筛法用球形区域划分空间的方式换为用超立方体,从而降低了搜索向量进行约化得时间.另外,局部敏感哈希技术[25]、局部敏感过滤技术[26]以及量子Grover搜索算法[27]都被用来加速筛法中遍历搜索的过程.从实际执行效果层面,渐进式筛法[9]、子筛法[28]和G6K[29]利用减秩技术对筛法的实际执行效果进行了优化,其中G6K是目前分析密码安全性的主要实际工具.
发展到现在,筛法理论算法的时间和空间复杂度已经由最初的(25.9n,22.95n)(AKS筛法[13])降低到了(22.49n,22.49n)(线性筛法[24]). 启发式算法中复杂度最低的经典算法是Becker-Ducas-Gama-Laarhoven[26]提出的LD筛法,它的时间和空间复杂度为(20.292n,20.208n),复杂度最低的量子算法是Laarhoven[30]提出的量子筛法,它的时间和空间复杂度为(20.265n,20.208n).目前coreSVP方法分析格方案的具体安全性时的经典和量子复杂度来源即为LD筛法和量子筛法.本文主要描述筛法发展过程中的重要思想和关键技术,总结目前存在的主要问题,并展望将来的发展方向.
1.3 组织结构
本文剩余的内容安排如下.第2节介绍相关的基础知识.第3节和第4节介绍筛法的四个类别,其中第3节介绍AKS筛法和NV筛法,第4节介绍列表筛法和高斯筛法.接下来的章节按照时间顺序介绍各种改进的方法.第5节介绍生日-AKS筛法和生日列表筛法.第6节介绍层次筛法.第7节介绍使用LSH/LSF技术的筛法.第8节介绍元组筛法.第9节介绍减秩筛法.第10节介绍量子加速筛法.第11节介绍线性筛法.第12节总结筛法当前存在的主要问题和未来的发展趋势.
2 预备知识
2.1 符号
在本文中,符号Z和R表示整数集合和实数集合.标准渐进函数O(·)、Ω(·)、Θ(·)、o(·)、ω(·)定义如下:f(n)=O(g(n))意为存在正整数c和n0,对于所有n≥n0有f(n)≤c·g(n);f(n)=Ω(g(n))意为存在正整数c和n0,对于所有n≥n0有g(n)≤c·f(n);f(n)=Θ(g(n))意为既有f(n)=O(g(n))又有f(n)=Ω(g(n));f(n)=o(g(n))意为对于任意正数c,存在n0使得对于所有n≥n0有f(n)≤c·g(n);f(n)=ω(g(n))意为对于任意正数c,存在n0使得对于所有n≥n0有f(n)≥c·g(n).符号poly(x)表示关于变量x的任意未指定多项式函数.向量用小写黑体字母表示(例如x),矩阵用大写黑体字母表示(例如X).符号||·||表示向量的二范数ℓ2,或称欧式范数.符号dist(a,b)表示a和b之间的欧式距离.符号B n(x,r)表示一圆心为x,半径为r的n维球,符号B n(r)=B n(0,r).
2.2 格和格上困难问题
定义1(格)已知Rm中的n个线性无关的行向量b1,b2,···,b n(m≥n),这组向量的所有整系数线性组合的集合称为Λ,记为
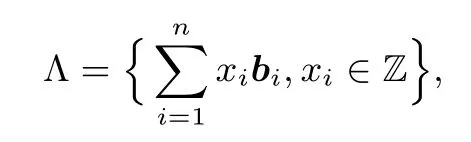
其中线性无关的向量组b1,b2,···,b n(m≥n)称为格Λ的一组基,n为格的秩,m为格的维数.当m=n时,称Λ为一个满秩格.格Λ上的最短向量的范数记为λ1(Λ)=minv∈Λ{0}||v||.
定义2(最短向量问题,shortest vector problem,SVP)给定格Λ,寻找一个格向量u∈Λ{0}使得||u||=λ1(Λ).
3 AKS筛法和NV筛法
筛法是Ajtai-Kumar-Sivakumar于2001年首次提出的,称为AKS筛法[13].其基本思想是首先生成一定数量的格向量,让它们通过一系列越来越“细”的筛子,使得留下来的向量长度越来越短,最终找到最短的那一个.由于其庞大的空间开销,算法一直未能实用化.直到2008年,Nguyen-Vidick基于AKS筛法提出了第一个筛法的启发式算法NV筛法[17],可以应用于维度小于50的格,筛法才开始走向实用化.下面分别介绍AKS筛法和NV筛法.
3.1 AKS筛法
AKS筛法算法可分成三个步骤.首先,从一个较大的范围B n(2O(n)O(λ1(Λ)))中抽取2O(n)个格向量.然后,通过一系列“筛取”的过程,输出一定数量的B n(O(λ1(Λ)))中的格向量.最后,将得到的B n(O(λ1(Λ)))中的格向量两两相减并输出最短的那个,即可以接近1的概率得到格中的最短向量.
“筛取”的过程是AKS筛法的核心,也是时间复杂度最高的部分.“筛取”的过程分多轮进行,每一轮输入集合L⊂Λ∩B n(R)中的向量,输出尽可能多的Λ∩B n(γR)中的向量,其中γ∈(0,1)称为收缩系数.具体地,在一轮筛法中,从输入集合L中选择一个子集C作为“中心”,集合C满足如下两个性质:第一,集合C中任意两个向量之间的距离都大于γR,即对于任意的v1,v2∈C,有||v1−v2||>γR;第二,对于中心之外的每个向量w∈LC,都存在C中的一个向量v,使得||w−v||≤γR,即w−v∈Λ∩B n(γR).因此,LC⊂Λ∩B n(R)中的每个向量对应一个Λ∩B n(γR)中的输出向量.在每一轮筛取结束后,集合C中的向量将被丢弃.由于集合C中任意两个向量之间的距离都大于γR,并且C⊂B n(R),这两个条件保证了每一轮丢弃的向量的数目不会太多.
为了保证“筛取”结束后输出的B n(O(λ1(Λ)))中的格向量是不同的,AKS筛法算法还引入了扰动(perturbation)技术.具体地,在算法的第一步中,首先从B n(ξλ1(Λ))中随机抽取向量x,其中ξ>0.5是选定的扰动系数.为了能够最终找到格中的最短向量,扰动不能太大,一般会选择ξλ1(Λ)=O(λ1(Λ)).对每个随机抽取的向量x,可找到基本区域中的向量y,使得v=y−x是一个格向量.由于向量y在基本区域中,有||y||≤R0:=nmaxi||b i||.因此,||v||≤R0+ξλ1(Λ).在第二步的“筛取”过程中,给定许多对(v,y)⊂Λ×B n(R),其中||v−y||≤ξλ1(Λ),算法会输出(v′,y′)⊂Λ×B n(γR+ξλ1(Λ)),并保持||v′−y′||=||v−y||≤ξλ1(Λ).在执行线性多次“筛取”之后,即可以得到B n(O(ξλ1(Λ)/(1−γ)))中的格向量.当选择合适的γ和ξ之后,Ajtai-Kumar-Sivakumar证明,算法会以很高的概率输出长度O(λ1(Λ))的非零格向量.AKS筛法详见算法1.

算法1 AKS筛法Input:Λ,γ,ξ,N Output:A shortest vector ofΛ 1 R0←n max i||b i||;2 L←Sampling(Λ,ξ,N,R0); ▷算法2 3 R←R0;4 for j=1 to k do ▷k表示算法3执行的轮数,由R,γ,ξ定义得到5 L←Sieving(L,R,γ); ▷算法3 6 R←γR+ξλ1(Λ);7 end 8 find v0∈Λs.t.||v0||=min{||v−v′||where(v,y)∈L,(v′,y′)∈L,v̸=v′};9 return v0.算法2 AKS筛法中的Sampling子算法Input:Λ,ξ,N,R0 Output:A set{(v i,y i,i∈[1,n])}⊂Λ×B n(R0)and y i−v i is uniformly distributed in B n(ξ)1 for i=1 to N do$←B n(ξλ1(Λ));3 v i←ApproxCVP(−x i,Λ); ▷ApproxCVP指Babai’s rounding算法4 y i←v i+x i;5 end 6 return{(v i,y i,i∈[1,n])}.2 x i算法3 AKS筛法中的Sieving子算法Input:A set L={(v i,y i,i∈I)}⊂Λ×B n(R)and∀i∈I,||y i−v i||≤ξλ1(Λ),R,γ Output:A set L′={(v′i,y′i,i∈I′)}⊂Λ×B n(γR+ξλ1(Λ))and∀i∈I′,||y′i−v′i||≤ξλ1(Λ)1 C←∅;2 for i∈I do 3 if∃c∈C s.t.||y i−v c||≤γR then L′←L′∪{(v i−v c,y i−v c)}5 end 6 else 4 C←C∪{i}8 end 9 end 10 return L′.7
3.2 NV筛法
在AKS筛法中,为了使算法的输出结果和复杂度有理论保障,算法引入了扰动技术.但这一技术在算法的实际执行中的作用并不显著.当把扰动去掉,而直接在格点上进行操作时,可以使算法的执行更高效.基于这样的想法,Nguyen-Vidick[17]提出了AKS筛法的启发式版本——NV筛法.这样得到的启发式算法执行效率高,但无法保证一定可以得到格中的最短向量,也无法直接给出复杂度的界的证明.
与AKS筛法相似,NV筛法也分成三个步骤(见算法4).首先,用Klein近似最近平面算法算法抽取N个格向量放入集合L中.然后进行“筛取”,在每一轮的“筛取”过程中,长度在γR以内的向量直接通过“筛取”进入下一轮,而其他长度大于γR的向量将按照与AKS筛法中相同的方法,通过选取“中心”集合C得到剩下的长度在γR以内的向量.重复这一“筛取”的过程直到某一轮中所有通过“筛取”的向量都是零向量.最后,输出最后一轮“筛取”之前所有向量中长度最小的向量.

算法4 NV筛法Input:Λ,2/3<γ<1,N Output:A short non-zero vector ofΛ 1 L←∅;2 for j=1 to N do 3 L←L∪v sampled by using Klein’s randomized nearest plane algorithm;4 end 5 remove all zero vectors from L;6 L0←L;7 repeat 8 L0←L;9 L←Sieving(L,γ); ▷算法5 10 remove all zero vectors from L;11 until L=∅;12 compute v0∈L0 s.t.||v0||=min{||v||,v∈L0};13 return v0.算法5 NV筛法中的Sieving子算法Input:A set L⊂Λ∩B n(R)and shrinking factor 2/3<γ<1 Output:A set L′⊂Λ∩B n(γR)1 Set R←max v∈L||v||;2 initialize L′←{}and C←{0};3 for each v∈L do 5 4 if||v||≤γR then L′←L′∪{v}6 end 7 else if∃c∈C s.t.||v−c||≤γR then L′←L′∪{v−c}9 end 10 else 8 11 C←C∪{v}12 end 13 end 14 return L′.
NV筛法算法中最重要的参数是初始输入向量的数目N和收缩系数γ.当参数γ确定后,最终输出的格向量的长度只与算法执行的轮数相关,轮数越多则最终得到的格向量越短.而算法会在所有初始抽取的N个向量用完之后结束,因此算法轮数受限于每轮算法执行时损失的向量数目.而算法执行过程中向量损失的主要来源是被用于作为“中心”.因此衡量“中心”集合的规模|C|对于确定参数和分析复杂度至关重要.为了分析|C|,Nguyen-Vidick使用了如下假设,并在低维度的实验中对其合理性进行了验证.
假设1令C n(γ,R)={x∈Rn,γR≤||x||≤R},假设L∩C n(γ,R)中的向量是均匀分布的.

实验证明,NV筛法在维度小于50的格上可以正常使用.但由于空间复杂度过高,致使在格的维度超过50之后,就很难再将其实用化.
4 列表筛法和高斯筛法
2010年,Micciancio-Voulgaris[16]提出了一种新的筛法理论算法,称为列表筛法,并给出了对应的启发式版本,称为高斯筛法.与AKS筛法和NV筛法在一开始就先生成大量格向量不同,列表筛法和高斯筛法从一个空列表L开始,逐步抽取和约化得到更短的格向量加入列表,直到找到满足条件的短向量.
4.1 列表筛法
列表筛法算法使用列表L储存每一轮生成的格向量.每一轮算法随机抽取一个格向量,用列表L中的向量对其进行约化,使它尽可能地短,约化之后将其放进列表L中,已经在L中的向量不再改变或移除.当约化得到的向量长度小于等于µ(目标短向量长度),即可作为最终的结果输出.详见算法6.

算法6列表筛法Input:Λ,µ,N Output:v∈Λ∧||v||≤µor⊥1 Initialize a list L={0};2 for i=1 to N do 6 if∃w∈L s.t.||v−w||<µthen 3 (v,p)←sampling(Λ,ξ,µ); ▷算法7 4 (v,p)sieving((v,p),L); ▷算法8 5 if v/∈L then 7 return v−w;8 end L←L∪{v};10 end 11 end 12 return⊥.9

算法7列表筛法中的Sampling子程序Input:Λ,ξ,µOutput:(v,p)∈Λ×R n 1 e$←B n(ξµ);2 p←e modΛ;3 v←p−e;4 return(v,p).

算法8列表筛法Sieving子程序Input:(v,p),L Output:reduced pair(v,p)1 while∃w∈L s.t.||p−w||≤||p||do 2 (v,p)←(v−w,p−w)3 end 4 return(v,p).
接下来分析列表L长度的上界,从而得到时间与空间复杂度.算法终止前每一轮得到的约化后的向量与L中已有的向量均距离较远(至少为µ).根据这一性质,利用球填充(sphere packing)问题的分析结果,可给出|L|的上界,据此可以得到算法的空间复杂度.算法的每一轮需要使用新抽取的向量与L中的所有向量进行两两组合计算,因此算法时间复杂度的上界约为|L|2.
在上面的分析中存在一个问题:算法的某些轮得到的向量可能已经存在于L中,即发生了“碰撞”.当遇到这种情况,算法既浪费了时间,又没有得到更短的向量.因此在分析算法的时间复杂度时,需考虑这样的事件发生的概率.为此,列表筛法和AKS筛法一样,采用了“扰动”技术.在抽取格点v时,实际抽取的是一对向量e,p,再计算v=p−e,其中e满足||e||≤ξµ,这里ξ>0.5.这样得到的向量,满足v在B n(p,ξµ)中均匀分布,且B n(p,ξµ)中包含多于1个格向量的概率大于0.因此,当B n(p,ξµ)中包含两个距离小于等于µ的格向量时,抽到其中一个向量两次的概率和同时抽到这两个向量的概率相同.据此,可以得到发生碰撞的概率的上界.可以看出,当ξ增大时,|L|上升,但发生碰撞的概率降低,反之亦然.因此ξ的选择对于算法最终的复杂度至关重要.
4.2 高斯筛法
高斯筛法是列表筛法的启发式版本(详见算法9),它与列表筛法的区别在于,在抽取了一个随机的格向量v并对其进行长度上的约化时,列表筛法只利用列表L中的向量对于v进行约化,而高斯筛法还利用v对L中已存在的向量进行约化.当这个过程结束后,列表中的所有向量都是两两互相约化的,即
∀w1,w2∈L:||w1±w2||≥max{||w1||,||w2||}.
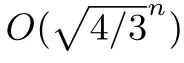

算法9高斯筛法Input:Λ,µOutput:v∈Λ∧||v||≤µ1 Initialize a list L={0}and a stack S=∅;2 repeat v←v−w;6 end 7 while∃w∈L s.t.||w||>||v||∧||w−v||≤||w||do 3 Get a vector v from S(or sample a new one);4 while∃w∈L s.t.||w||≤||v||∧||v−w||≤||v||do 5 8 L←L{w};S←S∪{w−v};10 end 11 if v has changed then 9 12 S←S∪{v}(unless v=0);13 end 14 else L←L∪{v};15 until v satisfying||v||≤µ;
除了约化方式的不同,高斯筛法还去掉了列表筛法中的扰动技术,因此高斯筛法的时间复杂度并没有一个可以证明的上界,但可以估计时间复杂度大约为将列表中的向量两两组合检查否可以互相进行约化的时间,因此时间复杂度大约为列表长度的平方级别,即O((4/3)n).
5 生日-AKS筛法和生日-列表筛法
2011年,Pujol-Stehlé[18]提出,利用生日悖论(birthday paradox)可降低筛法成功找到最短向量所需的向量总数,因此可以降低算法的复杂度.Pujol-Stehlé对AKS筛法和列表筛法进行了优化,优化得到的算法分别称为生日-AKS筛法(AKS Sieve-birthday)和生日-列表筛法(ListSieve-birthday).
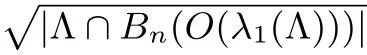
由于使用生日悖论结论时需要集合中的向量是互相独立同分布的,但AKS筛法的最后一个部分中的向量并不满足这个条件,因此需要对算法进行一些调整.可以证明这些调整带来的开销很小,对于整体复杂度的下降没有影响[32].
6 层次筛法
2011年,Wang-Liu-Tian-Bi提出了一种的新的启发式算法—两层筛法(Two-Level Sieve)[19],在这一新的框架下,之前的NV筛法可视作一层筛法(One-Level Sieve).之后在2013年,Zhang-Pan-Hu通过进一步改进两层筛法的结构对算法进行优化,提出了三层筛法(Three-Level Sieve)[20].通过使用多层筛的技术,层次筛法以增加空间复杂度为代价降低了算法的时间复杂度.
6.1 两层筛法
Wang-Liu-Tian-Bi提出,可以将原始的NV筛法看作一层筛法,那么两层筛法即为利用“两层筛”的技术.具体地,算法的每一轮分为两层:第一层首先将C n(γ2R)={x∈Rn:γ2R≤||x||≤R}中的格向量划分进不同的半径为γ1R的大球中(γ1>1),所有大球需覆盖C n(γ2R);第二层再将每个大球中的格向量划分进不同的小球中(详见算法10).可以看出,对于每个格向量,一层筛的大球数目较少,二层筛时只需与已确定的大球内部的小球中心点相比较即可,因此减少了比较时间,降低了时间复杂度.但同时,由于需要存储的向量数量变多,导致空间复杂度上升.

算法10两层筛法Input:A set S⊂Λ∩B n(R)and shrinking factors√2/3<γ2<1<γ1<√2γ2 Output:A set S′⊂Λ∩B n(γ2 R)1 Set R←max v∈S||v||;2 Initialize S′←{}and C1←{0},C2←{0};3 for each v∈S do 4 if||v||≤γ2 R then S′←S′∪{v};6 end 7 else 5 8 if∃c∈C1 s.t.||v−c||≤γ1 R then 9 if∃c′∈C c2 s.t.||v−c′||≤γ2 R then 10 S′←S′∪{v−c′};11 end 12 else C c2←C c2∪{v};13 end 14 else 15 C1←C1∪{v};16 C2←C2∪{C v2={v}};17 end 18 end 19 end 20 Return S′.
6.2 三层筛法
三层筛法的思路和两层筛法类似,采用了“三层筛”的技术,以增大空间复杂度为代价,进一步降低了算法的时间复杂度.
一个自然的问题是,是否可以继续增大层次的数目来降低算法的时间复杂度.对此,文献[20]指出,这种想法是可行的,但由于这样做的技术难度越来越高,而收益却越来越低,所以没有继续的必要.之后,Laarhoven在详细分析了两种层次筛法的复杂度后,给出了k层筛法(k-Level Sieve)的算法框架和空间、时间复杂度的分析方式[30].

算法11三层筛法Input:A set S⊂Λ∩B n(R)and shrinking factors 0.88<γ3<1<γ2<γ1<√2γ3 Output:A set S′⊂Λ∩B n(γ3 R)1 Set R←max v∈S||v||;2 initialize S′←{}and C1←{0};3 for each v∈S do 4 if||v||≤γ3 R then S′←S′∪{v};6 end 7 else 5 8 if∃c1∈C1 s.t.||v−c1||≤γ1 R then 9 if∃c2∈C c12 s.t.||v−c2||≤γ2 R then 10 if∃c3∈C c1,c23 s.t.||v−c3||≤γ3 R then 11 S′←S′∪{v−c3};12 end 13 else C c1,c23 ←C c1,c23 ∪{v};14 end 15 else C c12←C c12∪{v};16 end 17 else 18 C1←C1∪{v};19 end 20 end 21 end 22 return S′.
7使用LSH/LSF技术的筛法
2015年,Laarhoven[25]提出使用局部敏感哈希(locality-sensitive hashing,LSH)技术对筛法中穷搜的部分进行加速,并在高斯筛法上进行了实现,改进后的算法称为哈希筛法(HashSieve).相比于高斯筛法,哈希筛法在保持空间复杂度不变的基础上降低了时间复杂度.
LSH有许多不同的类型,哈希筛法使用的是角(angular)LSH,在这之后,Laarhoven-Weger[33]以及Becker-Laarhoven[34]又分别提出了利用球(sphere)LSH和正轴体(cross-polytope)LSH加速的筛法球筛法(SphereSieve)和正轴体筛法(CPSieve).球筛法和正轴体筛法又进一步降低了哈希筛法的时间复杂度.
2016年,Becker-Ducas-Gama-Laarhoven[26]提出使用一种与LSH类似的、称为局部敏感过滤(locality-sensitive filters,LSF)的技术对筛法进行加速,改进后的算法称为LD筛法(LDSieve).相比于使用LSH技术的三个算法,LD筛法的空间复杂度不变,时间复杂度更低.
7.1 LSH和LSF技术
LSH.LSH是用来解决最近邻搜索(near(est)neighbor searching,NNS)问题的一项技术.正式地,最近邻搜索问题定义为:
定义3(最近邻搜索问题,near(est)neighbor searching,NNS)给定一列n维的向量L={w1,w2,···,w N},对于一个目标向量v/∈L,找到一个w∈L使得它是L中离v最近的向量.
显然,这个问题可以通过遍历列表L解决.但当列表L规模较大时,这样做的时间复杂度很高.而使用LSH技术可以降低解决问题的时间复杂度.正式地,LSH函数簇H有性质如下:
定义4对任意v,w∈Rn,一簇函数H={h:Rn→N}对于测度D有如下性质:
(1)如果D(v,w)≤r1,那么Prh∈H[h(v)=h(w)]≥p1,
(2)如果D(v,w)≥r2,那么Prh∈H[h(v)=h(w)]≤p2,那么称H对于测度D是(r1,r2,p1,p2)-敏感的.
根据定义4,如果有p1≫p2,那么可使用H以不可忽略的概率区分在测度D下与v距离至多r1和至少r2的向量.
具体地,使用LSH技术时,首先从哈希簇H中随机选择t×k个哈希函数.之后,构造t个哈希表T1,T2,···,T t,每个表T i中使用由k个哈希函数组合得到的哈希函数组,表示为h i.对每个w∈L,计算它的t个哈希值h1(w),h2(w),···,h t(w),并根据每个哈希值h i(w)将w存放在哈希表T i中相应的位置.那么,当给定目标向量v后,计算它的t个哈希值h i(v),将每个哈希表中与之发生碰撞的所有w∈L取出作为一个集合,这个集合即为离v较近的向量的集合.之后,再遍历这个集合中寻找离v最近的向量即可.
考虑图2中一个使用角LSH技术的实例:给定列表L={w1,w2,···,w10}和目标向量v,要求找到L中距离v最近的向量.该实例中使用3个哈希表,每个表中使用k=2个超平面来划分空间(即为选定的哈希函数),因此使用2k=4个哈希桶存放相应哈希值的向量.可以看出,使用多个哈希表可以使得靠近目标点的向量尽可能地不被遗漏.对于每个哈希表(即每种空间划分的方式),首先对L中的向量计算哈希值(即落在平面中的哪个区域)并存放在相应的哈希桶中.之后,计算v的3个哈希值,与每个哈希表相比对,将与之哈希值相同的向量取出并存储,留待最后遍历时使用.在该实例中,最终得到的与v距离较近的向量的集合为C={w6,w7,w8,w9,w10}.那么在寻找离v最近的向量时,遍历集合C即可.
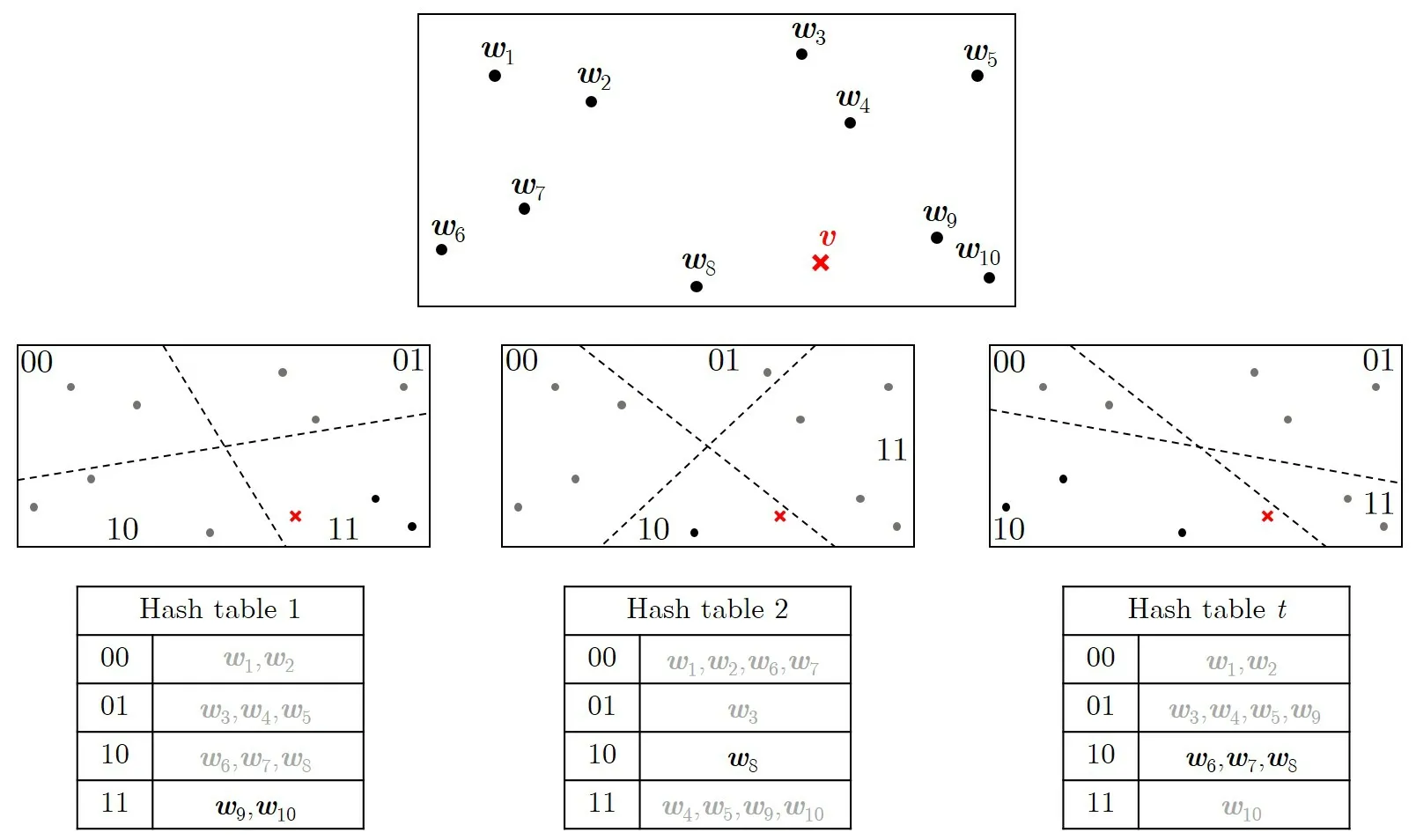
图2 局部敏感哈希实例Figure 2 Example of locality-sensitive hash
显然,算法解决NNS问题的效率取决于对哈希簇和参数k、t的选择.
•哈希簇:根据选择的哈希簇不同,目前在使用的LSH技术主要可分为:角(angular)LSH(或称超平面(hyperplane)LSH)、球(sphere)LSH、正轴体(cross-polytope)LSH.其中角LSH的理论分析较差但算法运行非常高效,球LSH的理论非常完善但不具备实际操作性.而正轴体LSH则同时具备了以上两个算法的优点:它既有充分的理论保障,在实践中又比角LSH效果更好.
•参数k和t:当选择较大的k和t时,可以将区分“近”和“远”的概率差放大(定义4中的p1−p2),这样可以使筛选出的“较近”的元素的集合较小,最终的比较次数较少,但另一方面,这样做会使得哈希表较长,需要的存储空间较大.因此,需要选择合适的参数k和t来平衡算法的时间和空间复杂度.
LSF.对于LSF技术来说,每个过滤函数的输出是二元的,即通过或没有通过这个过滤函数.因此对于一个列表L,当它经过过滤函数f之后得到的集合L f⊂L中包含所有通过这个过滤函数的向量.L f中的向量在对应的测度下距离较近.
当利用这样的过滤函数来解决NNS问题时,首先给定一个过滤函数的分布F,再抽取t×k个过滤函数f i,j∈F.将每k个进行组合,构造t个过滤函数组f i.对于w,通过过滤函数组f i意味着通过了其中的所有k个过滤函数f i,j,j=1,2,···,k.那么对于列表L,相应地存在t个过滤输出集合L1,L2,···,L t.最后,当输入一个目标向量v时,用t个过滤函数组对v进行检测,对于那些v可以通过的过滤函数组f i,将它对应的L i中的向量全部集合在一起,即为离v较近的向量的集合.再从这个集合中遍历寻找离v最近的向量即可.
7.2 哈希筛法
哈希筛法是利用角(angular)LSH技术对高斯筛法进行优化得到的.具体地,角LSH技术是指在LSH中使用角距离(angular distance)来进行距离的度量:对于向量v和w,它们的角距离定义为
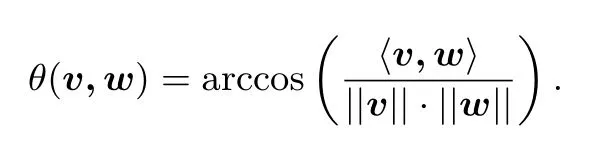
在这样的度量方式下,当两个向量的夹角小时即可认为它们的距离较近,反之亦然.
为了使用角LSH来优化高斯筛法,需要对高斯筛法中的约化条件做一些相应的调整.高斯筛法中的约化条件可写作:
用u2约化u1:如果||u1±u2||<||u1||,那么u1←u1±u2.
根据这样的约化方法,可以使得得到的列表L中的向量都是两两约化的,即对于∀w1,w2∈L均满足||w1±w2||≥max{||w1||,||w2||}.从这个条件可以得到∀w1,w2∈L均满足夹角至少为π/3.据此可以得到一个弱化版的约化条件:
用u2约化u1:如果θ(u1,u2)<π/3并且||u1||≥||u2||,那么u1←u1±u2.
为了分析约化的过程和算法的复杂度,需作如下假设:
假设2随机抽取的向量v,w之间的夹角θ(v,w)和从Rn中的单位球面上随机抽取的两个向量v′,w′之间的夹角θ(v′,w′)服从相同的分布.
在高维空间中,已知随机抽取的两个向量之间的夹角以较大的概率等于π/2.因此在假设2成立时,有∀w1,w2∈L,θ(w1,w2)以很大的概率接近π/2.另一方面,由弱化的约化条件可知,当两个向量可以用其中一个对另一个进行约化时,意味着它们之间的夹角是小于π/3的,而约化之后的夹角一定是大于π/3的,为了简化分析,假设约化之后的向量之间的夹角均为π/2.
利用这些信息,即可定义角LSH所需的函数簇:

直观地,每个a可定义一个如图2实例中的虚线(超平面).而对于v,w,Pr[h(v)̸=h(w)]可利用它们之间的角度进行计算:
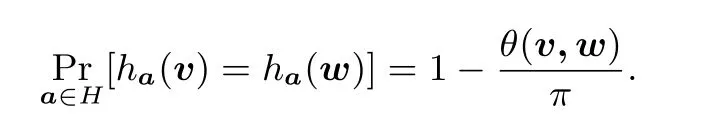

算法12哈希筛法Input:Λ,µOutput:v∈Λ∧||v||≤µ1 Initialize a list L={0}and a stack S=∅;2 initialize t hash tables T i;3 sample k·t random hash vectors a i,j;4 repeat 5 Get a vector v from S(or sample a new one);6 obtain the set of candidates C=∪ti=1 T i[h i(v)];7 while∃w∈C s.t.||w||≤||v||∧||v−w||≤||v||do v←v−w;9 end 10 while∃w∈C s.t.||w||>||v||∧||w−v||≤||w||do 8 11 L←L{w};12 T i←T i{w}for all t hash tables;13 S←S∪{w−v};14 end 15 if v has changed then 16 S←S∪{v}(unless v=0);17 end 18 else 19 L←L∪{v};20 T i[h i(v)]←T i[h i(v)]∪{v}for all t hash tables;21 end 22 until v satisfying||v||≤µ;
7.3 球筛法
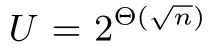


算法13球筛法Input:A set S⊂Λ∩B n(R)and shrinking factor 2/3<γ<1 Output:A set S′⊂Λ∩B n(γR)1 initialize S′←{}and C←{0};2 initialize t empty hash tables T i;3 sample k·t random spherical hash functions h i,j∈H;4 for each v∈S do 5 if||v||≤γR then S′←S′∪{v};7 end 8 else 6 9 obtain the set of candidates C=∪ti=1 T i[h i(±v)];10 for each w∈C do 11 if||v−w||≤γR then 12 S′←S′∪{v−w};13 continue the outermost loop;14 end 15 end 16 T i[h i(v)]←T i[h i(v)]∪{v}for all i∈[t];17 end 18 end 19 return S′.
7.4 正轴体筛法
正轴体筛法是利用正轴体(cross-polytope)LSH技术对高斯筛法进行优化得到的启发式算法[34].正轴体是一类任意维均存在的凸多胞体(如图3是一个三维正轴体),由标准基向量{e i∈Rn}作为顶点定义而成.根据正轴体定义的哈希函数可写作
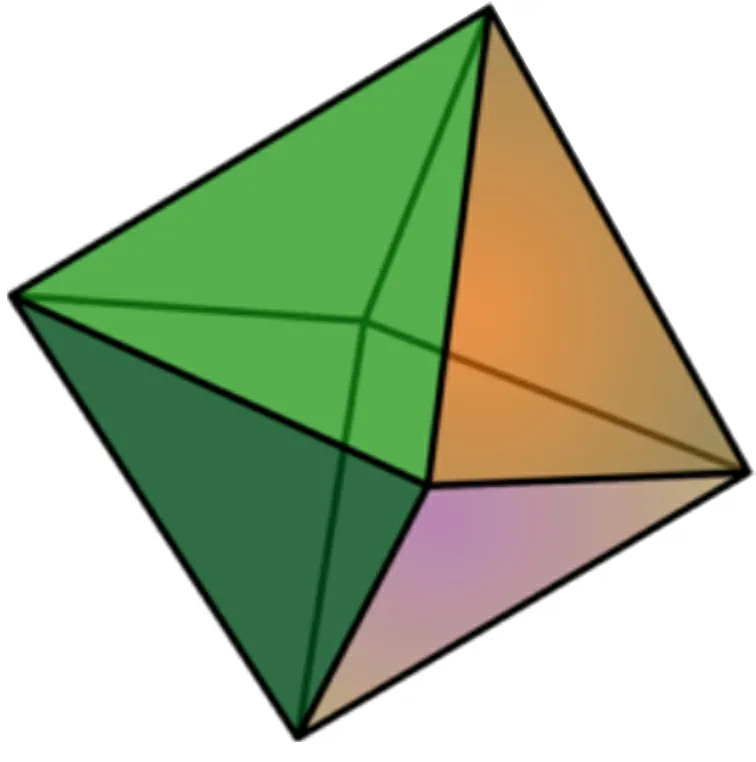
图3 三维正轴体Figure 3 3-orthoplex
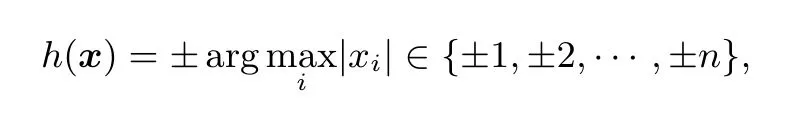
其中符号与绝对值最大的分量的符号一致.例如对于v=(3,−5)有h(v)=−2.
但这样只定义了一个哈希函数,因此我们需要引入一个随机变换,使得它能够成为一个函数簇.令分布A输出矩阵A=(a i,j)∈Rn×n,其中对于任意的i,j有a i,j~N(0,1),即一个标准正态分布.这样即可定义哈希函数簇
H={h A:h A(x)=h A(A x),A~A}.
之后,将这个哈希函数簇在GaussSieve上应用即可得到新的算法CPSieve(见算法14).

算法14正轴体筛法Input:Λ,µOutput:v∈Λ∧||v||≤µ1 initialize a list L={0}and a stack S=∅;2 sample t×k random Gaussian matrices A i,j;3 define h i,j(x)=h(A i,j x)and h i(x)=(h i,1(x),h i,2(x),···,h i,k(x))initialize t hash tables T i;4 sample k·t random hash vectors a i,j;5 repeat 9 6 get a vector v from S(or sample a new one);7 obtain the set of candidates C=∪ti=1 T i[h i(v)]∪∪ti=1 T i[h i(−v)];8 while∃w∈C s.t.||w||≤||v||∧||v−w||≤||v||do v←v−w;10 end 11 while∃w∈C s.t.||w||>||v||∧||w−v||≤||w||do 12 L←L{w};13 T i←T i{w}for all t hash tables;14 S←S∪{w−v};15 end 16 if v has changed then 17 S←S∪{v}(unless v=0);18 end 19 else 20 L←L∪{v};21 T i[h i(v)]←T i[h i(v)]∪{v}for all t hash tables;22 end 23 until v satisfying||v||≤µ;
7.5 LD筛法
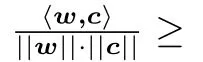
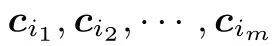
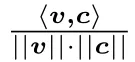
8 元组筛法
2016年,Bai-Laarhoven-Stehlé指出,现有筛法都只考虑了两个向量之间的相互约化,而实际上可以每次约化多个向量[21].根据这样的思想,他们提出了基于列表筛法的新的启发式筛法——元组筛法(Tuple Sieve),或称k-筛法(k-Seive),其中常数k表示每次约化时考虑的向量个数.相比于之前的筛法,元组筛法以增加时间复杂度为代价,降低了算法的空间复杂度,在一定程度上缓解了筛法由于空间复杂度过大而不能应用于实际的问题.之后,Herold-Kirshanova[22]和Herold-Kirshanova-Laarhoven[23]进一步将寻找约化后的短向量的过程看作一个k-列表问题(k-list problem),并给出了更快的算法.
8.1 BLS-元组筛法
BLS-元组筛法的每次约化中考虑k个向量.首先考虑k=2的情况,这时的算法称为双筛法(DoubleSieve).算法的每一轮将一组B n(R)内的向量通过两两约化得到一组B n(γR)内的向量(见算法15).具体地,在每轮中,算法首先将范数小于γR的向量从列表L中去掉、直接进入下一轮,使得列表L中只包含了范数在(γR,R)范围内的向量.然后,对列表L中的每一对向量w,v,如果||v±w||≤γR,则将v±w加入到下一轮的列表中.
下面分析双筛法的时间与空间复杂度.由于算法在约化时所考虑的向量v,w∈L都在(γR,R)范围内,如果γ≈1时,那么||v||≈||w||≈R.此时,事件||v−w||<γR等价于w∈B(R)∩B(v,γR).为了计算该事件发生的概率,需要做如下假设:
假设3在双筛法(算法15)中,假设对于∀v∈L,v/||v||可看作是从单位球面上的均匀分布中抽取的独立同分布的向量.
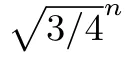
k=3时的算法称为三筛法(TripleSieve,算法16),它与k=2时的区别在于每次约化时使用3个向量,即v±w±x.因此,此时在球覆盖时不只考虑单个的向量,而也会考虑两个向量的和或差也是否也可以覆盖一部分球面.例如,如果有||v−w−x||≤γR,那说明x∈B(R)∩B(v−w,γR).直观上,这也解释了为了什么k=3的情况下覆盖整个球面所需的向量个数比k=2时更少.与双筛法类似,在三筛法的分析中也需要做与假设3类似的假设:
假设4在三筛法(算法16)中,假设对于∀v∈L,v/||v||可看作是单位球面上均匀随机抽取的的独立同分布向量,且∀v̸=w∈L,v±w中范数最小的向量可看作一个随机向量.

算法15双筛法Input:L⊂B n(R),γ,R Output:L′⊂B n(γR)1 L′←{};2 for each v∈L do 3 if||v||≤γR then 4 L′←L′∪{v};L←L{v};6 end 7 end 8 for each v,w∈L do 5 9 if||v±w||≤γR then 10 L′←L′∪{v±w};11 end 12 end 13 return L′

算法16三筛法Input:L⊂B n(R),γ,R Output:L′⊂B n(γR)1 L′←{};2 for each v∈L do 4 L′←L′∪{v};3 if||v||≤γR then L←L{v};6 end 7 end 8 for each v,w,x∈L do 5 9 if||v±w±x||≤γR then 10 L′←L′∪{v±w±x};11 end 12 end 13 return L′

对于更大的k,Bai-Laarhoven-Stehlé指出,算法的时间和空间复杂度可以归纳为k n(1+o(1))和k n/k(1+o(1)).当k趋近于n时,算法的时间和空间复杂度分别趋近于n n+o(n)和n1+o(1).因此,参数k平衡了算法时间复杂度和空间复杂度,逐渐增大k的过程即可视为用时间换空间的过程.
8.2 HK-元组筛法
2017年,Herold-Kirshanova[22]继续发展了元组筛法.他们指出,当把利用筛法求解SVP的每一轮看作k列表问题之后,Bai-Laarhoven-Stehlé[21]只是对所有的可能解进行了遍历去寻找满足条件的那些,而实际上这个过程可以进一步进行优化.具体地,一个近似k列表问题可以归约到满足一定性质的结构问题上,而这样的结构问题可以被更快速地解决.因此,可以利用解决这个结构问题的算法来对现有的元组筛法加速.更进一步地,这样的结构问题还可以与LSH技术相结合,得到一个扩展版的结构问题,Herold-Kirshanova也同样给出了解决这个问题的算法,并把它们一起用在了加速元组筛法上.
下面首先给出近似k-列表问题,结构以及结构问题的定义,然后分析近似k列表问题的解与结构问题的解的关系,最后给出解决结构问题的算法(算法17).
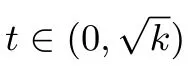
定义6(结构,configuration)对于k个向量x1,x2,···,x k∈S n−1,其中S n−1表示单位球面,结构C=Conf(x1,x2,···,x k)定义为这k个向量的Gram矩阵,即C i,j=〈x i,x j〉,i,j∈[k].
定义7(结构问题,configuration problem)输入k个指数量级的列表L1,L2,···,L k,其中的元素取自S n.对于一个给定的目标结构C和ϵ>0,输出k元组(x1,x2,···,x k)∈L1×L2×···×L k,使其对于所有的i,j∈[k]均满足|〈x i,x j〉−C i,j|≤ϵ.
根据定义可知,若选择目标结构C满足∑i,j C i,j≤t2,那么C对应的结构问题的解(x1,x2,···,x k)满足〈x i,x j〉≈C i,j,∀i,j,因此||∑i x i||2≈∑i,j C i,j≤t2,即(x1,x2,···,x k)也是以t为目标的近似k-列表问题的解.因此,任意一个满足∑i,j C i,j≤t2的结构C对应的结构问题的解都包含在以t为目标的近似k-列表问题的解当中.但反过来,后者所有的解可能需要多个不同的结构问题的解才能完全覆盖.
筛法的每一轮要求输入列表和输出列表的规模基本一样,因此需要找到尽可能多的近似k-列表问题的解.为了求解尽可能少的结构问题同时得到尽可能多的近似k-列表问题解,Herold-Kirshanova选择只求解包含最多解的结构问题.具体地,结构问题可较容易地确定输出解的数目和目标结构C之间的关系:给定|L|k个可能的元组作为输入,目标是输出|L|个元组,它们满足方程|L|k·det(C)n/2=|L|.根据上述方程,选择det(C)最大的C可使结果达到最优,即在输入数目固定的情况下最大化输出列表规模.


算法17 k-list for the configuration problem Input:L1,L2,···,L k,C,ϵ Output:List L of k-tuples(x1,x2,···,x k s.t.|〈x i,x j〉−C i,j|≤ϵfor all i,j 1 L←{};2 for all x1∈L1 do 3 for all j=2,3,···k do j ←FILTER(x1,L j,C(1,j),ϵ); ▷算法18 5 end 6 for all x2∈L(1)2 do 4 L(1)7 L(2)j ←FILTER(x2,L(1)j,C(2,j),ϵ); ▷算法18 8···9 for all x k∈L(k−1)k do 10 L←L∪{(x1,x2,···,x k)};11 end 12 end 13 end 14 return L.算法18 FILTER Input:x,L,c,ϵ Output:L′1 L′←{};2 for all x′∈L do 3 if|〈x,x′〉|≤γR then 4 L′←L′∪{x};5 end 6 end 7 return L′.
8.3 HKL-元组筛法
2018年,Herold-Kirshanova-Laarhoven[23]提出可以将近似k列表问题约化到的结构问题略做调整以使得问题能够被更加快速地解决,并且可以结合LSF技术来对算法整体进行加速.
具体地,文献[22]选择使用det(C)最大的C对应的结构问题,以最大化每一轮输出元组的数目.而Herold-Kirshanova-Laarhoven指出某些结构C虽然det(C)不是最大的,但它们可以使输出元组的搜索更加快速.为了保持对于输出元组数目的要求,就需要增加输入列表的大小.对此,Herold-Kirshanova-Laarhoven给出了对应的关系和分析,并给出了如何找到最优的C来平衡算法的时间和空间.
9 减秩筛法
减秩(rank reduction)技术是一种格上常用的解决困难问题的技术,当求解n维格上的困难问题时,可以首先解决一个n−k维的子格上的问题,利用求解得到的结果再来解决原问题.
2018年,Laarhoven-Mariano[9]提出了利用减秩技术的渐进式筛法(Progressive Lattice Sieving).具体地,对于一个n维格上的SVP,首先在一个低维度的子格上进行筛法,然后逐渐向其中添加其余维度上的基向量,并在此过程中继续筛的过程,直到所有的基向量都添加完毕并找到了完整格上的最短向量为止.减秩技术几乎可以与所有筛法相结合使用,Laarhoven-Mariano提出的渐进式筛法主要考虑了与高斯筛法和哈希筛法这两种效率较高的筛法进行结合,结果显示利用这种方法,可将筛法提速20-40倍.除此之外,由于渐进式筛法的大部分算法过程是在子格中进行,因此算法的空间复杂度更低.
同年,Ducas[28]提出了子筛法(SubSieve),也可以看作是使用了减秩技术.Ducas证明只需要在少于n−k维的格上调用数次筛法,即可解决原格上的SVP,其中k=Θ(n/logn).子筛法对于算法总体的时间、空间复杂度的优化是亚指数级别的,但在实际执行中比其他筛法在70-80维的实验中快10倍.
2019年,基于这两种利用了减秩技术的筛法,Albrecht-Ducas-Herold等人[29]提出了一种开源的抽象的状态机——G6K(General Sieve Kernel),是目前分析密码安全性的主要实际工具.利用这个状态机可以实际地解决格上的SVP.具体地,Albrecht-Ducas-Herold等人利用G6K解决了Darmstadt SVP挑战2https://www.latticechallenge.org/svp-challenge.中的151维SVP,时间比之前的记录快了400倍.之后,在2021年,Ducas-Stevens-Woerden又利用G6K解决了180维的SVP挑战,是目前Darmstadt SVP挑战的最高纪录.
10 量子加速筛法
10.1 量子筛法
文献[30,35]给出了一些启发式筛法在利用Grover算法加速后的时间、空间复杂度(见表2),其中效果最好的是基于LDSieve的量子筛法(Quantum Sieve).
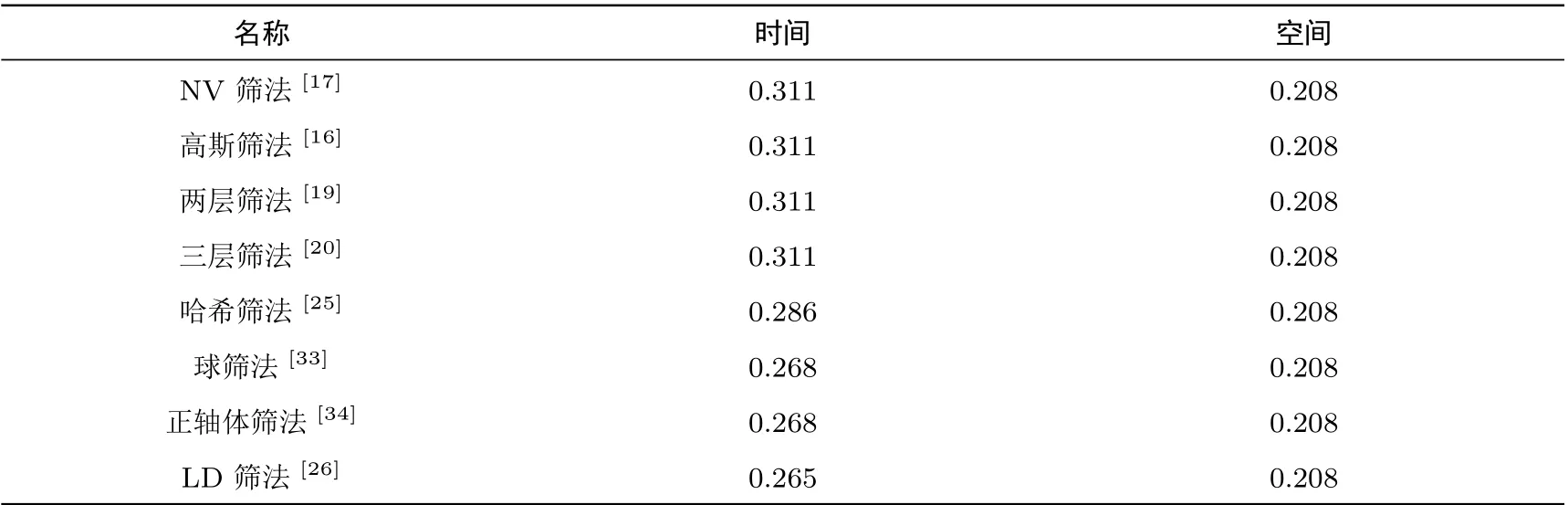
表2 部分启发式筛法的在量子算法加速下的空间、时间复杂度Table 2 Space&time complexity of some heuristic sieving algorithms sped up by using quantum algorithm
10.2 量子元组筛法
2019年,Kirshanova-Mårtensson-Postlethwaite-Roy Moulik[31]提出了元组筛法的量子加速版本.具体地,在解决元组筛法中所引入的结构问题(见第8.2节)时,需要对许多元组进行遍历并判断它们是否满足给定的目标,这一遍历过程可以使用量子Grover搜索算法进行加速.另外,经典的元组筛法在解决结构问题时使用了LSH/LSF技术进行加速,而Grover搜索算法也可与这两项技术结合使用.这是因为在使用这两项技术寻找合适的元组时,是将所有元组按照一定的结构进行分类,之后再选择其中的一些类进行搜索而非全部遍历,这一过程也可利用量子Grover搜索算法进行加速.
11 线性筛法
2019年,Mukhopadhyay[24]基于AKS筛法的框架,提出了一个新的可证明的筛法.新筛法的时间复杂度与空间复杂度是线性关系(之前是平方关系),因此算法命名为线性筛法(Linear Sieve).
AKS Sieve中的一个关键步骤就是对于一个在B n(R)抽取得到的向量y,找到离它最近的中心向量c.这个问题可以看作一个NNS问题(见第7节),可利用LSH和LSF技术解决,但这两项技术的使用都依赖于一些启发式假设,因此不能用于优化可证明的筛法.AKS Sieve的解决方式是在B n(R)中构造很多半径为γR的小球,将空间划分为一些小区域,之后对每个向量y,在由所有的球心组成的中心集合中寻找是否存在一个球心c使得||y−c||≤γR.如果不存在这样的球心,就将这个y对应的格点v加入中心集合成为一个新的球心.
这样做降低了算法的时间复杂度,但同时也增加了算法的空间复杂度.这是因为AKS Sieve中的每个中心点之间的距离都是大于γR的,而当用超立方体划分时会有一些中心之间的距离是小于γR的,因此中心的数目会比之前更多.但可以证明即使是这样,算法的时间复杂度依然比AKS Sieve低.
12 结论
自Ajtai-Kumar-Sivakumar于2001年提出第一个筛法以来,研究者们对筛法进行了大量深入的研究,不仅提出了不同的算法框架,而且通过借鉴其他领域相关问题的技术,提出了许多不同的改进方法,降低了算法的复杂度.本文对目前主要的筛法进行了分类,并梳理了它们之间的关系和发展脉络.
尽管筛法在过去二十多年取得了许多进展,但目前的筛法仍然存在空间复杂度过高、理论与实际效果相差较大[36]等缺点.在实际应用中,筛法只能在低维度的格上进行实验,距离高维度、大规模使用仍然存在一定的差距.由于筛法对于格密码方案的实际安全性分析至关重要,解决筛法在高维格上的应用问题,可以极大地推进格密码分析领域的发展.因此,对于筛法的进一步研究无论是从理论角度还是从实用角度都具有十分重要的价值和意义.
基于目前的研究现状,未来我们还可以在以下几个方面对筛法进行更加深入的研究:
•深化量子加速:目前利用量子算法对于筛法加速还停留在简单地替代筛法中穷搜的阶段,如何更加充分和深入利用量子算法对筛法进行加速尚不可知,这是我们在量子筛法领域需要考虑的问题.
•混合算法:混合算法的框架在格困难问题的求解中是一种常见的思路,而目前大多数筛法都是单独使用,如何与其他算法相结合是未来一个重要的研究方向.例如,2019年Guo-Johansson-Mårtensson-Wagner[37]提出将筛法与BKW算法相结合用来解决LWE问题. 2020年Doulgerakis-Laarhoven-Weger[38]提出将筛法作为一个子程序、与枚举以及切片等技术相结合的算法,该算法比直接使用筛法有更低的时间和空间复杂度.
•借鉴其他领域的技术:在目前对于筛法的改进中,借鉴其他领域的技术是一个重要的工具(例如局部敏感哈希技术),如何利用更多不同领域的想法和技术对筛法进行优化,是未来需要继续考虑的问题.例如,2019年Laarhoven[39]指出了人工智能领域中演化算法(evolutionary algorithm)的部分技术与筛法领域中近年来所发展技术的相似性,并进一步利用演化算法中其他的技术对筛法进行改进.
猜你喜欢
社会科学战线(2022年2期)2022-03-16
大数据(2021年6期)2021-11-22
小学生学习指导(中年级)(2021年4期)2021-04-27
电脑爱好者(2021年8期)2021-04-21
成都信息工程大学学报(2021年6期)2021-02-12
电脑爱好者(2020年20期)2020-10-22
课堂内外(初中版)(2020年5期)2020-06-19
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
电脑爱好者(2015年13期)2015-09-10
