
基于远程学习的关键词提取技术研究
2021-11-19 03:25:08曹聪慧漆为民
电脑与电信 2021年8期
曹聪慧 兰 强 侯 群 漆为民*
(1.江汉大学人工智能学院;人工智能研究院,湖北 武汉 430056;2.东风汽车财务有限公司,湖北 武汉 430056)
1 引言
近年来,互联网已经成为全球最大的分布式的信息库,据不完全的统计显示,全世界每年出版的各种文献资料和新发表的论文总数突破1000万,互联网上已有超过400亿张网页。而文本的形式仍然是大部分信息的表现形式[1],如何准确高效地提取出对用户有用的信息成为急需要解决的问题。
目前,利用文本聚类、关键词提取、自动文摘、信息搜索等计算机技术对文本信息进行处理,再将其直观地呈现给用户是一个较热门的研究方向。基于统计学的聚类算法包括有Fisher提出的COBWEB算法以及Gennari等人提出的CLASSIT算法等[2],但是精确度都不高。首都师范大学的王少鹏等人将LDA算法和TF-IDF相结合,虽然能够较好地利用文本聚类对舆论新闻等进行简单分析[3],但是该方法的数据仅仅来自于网络舆情分析,对其他应用场景的适应性差。对于英文关键词提取的研究,华人科学家ZHANG K等利用支持向量机来建立分类的模型来判断文档中的词是否是关键词,这个方法最大的缺点是需要大量的训练语料,需要大量的人力去进行标注[4]。TRIESCHNIGG D等利用词性和TF-IDF构建SVM模型,用这个生成模型来提取关键词,效果要强于TF-IDF方法,但是这种方法只选择了单词作为关键词,局限性很大[5]。对于中文语言关键词的提取,2008年,方俊等提出了采用词义代替词,来对待选词的语义进行代表以此来提高算法的各项指标[6]。钱爱兵,江岚增加了词性、词语长度、词语位置等属性来对传统的TF-IDF进行改进抽取了关键词[7],但是该方法没有考虑到分词词典的丰富性和未登录词的识别问题,会导致许多重要关键词的遗漏。关于远程学习,目前有关将远程学习技术应用到关键词提取领域的研究极少。仅有的研究有,福州大学的王姬卜利用百度百科远程学习构建了中文地理实体关系的语料库,并通过实验验证了所建语料库的有效性[8]。俞霖霖利用远程学习结合语义匹配和机器学习设计了候选答案抽取算法,但该方法缺少标准中文语料,通用性较差[9]。杨文通过网络爬虫对百度百科进行爬取,利用远程学习方法构建了知识图谱,但其爬取的数据量固定,知识更新有一定的局限[10]。
综上,现有的文本聚类或关键词提取技术通常都有应用范围小、适应性差或需要大量语料标注浪费人力等缺陷,并且准确率得不到保证。鉴于此,本文不需要语料标注,先使用基于LDA算法的文本聚类建立了模型,再用FP-growth算法进行关键词提取,能够实现对大数据文档的聚类,并能计算出聚类之后的关键词集,同时还利用网络远程学习对最终的结果进行筛选,提高筛选准确度,应用范围较广。
2 基于远程学习的关键词提取系统总体设计
基于远程学习的关键词提取系统开发设计的主要目的是实现对于中文文本的聚类和关键词精准抽取的功能。系统结构图见图1。

图1 基于远程学习的关键词提取系统结构图
本系统的设计中利用了隐含主题模型中的LDA算法模型对文本进行聚类,利用停用词删除方法实现了文本的去噪预处理,利用LDA算法模型的结果和FP-growth算法对聚类之后的关键词进行了抽取,并且使用远程学习算法结合百度百科知识对最终结果进行了精确筛选,以提高关键词提取系统的各项性能。
3 系统实现的关键技术和方法
3.1 基于LDA算法的文本聚类
LDA是一种假定某些隐含参数的生成模型,是一个包含有文档集、主题、词语的三层结构,把主题看作是对应的文档集中所有词汇的混合分布,把文档集中的文档看作是对应的所有主题的混合分布。
步骤为如下四步:
(1)从Dirichlet分布α中取样生成文档i的主题分布θi;
(2)从主题的Multinomial分布θi中取样生成文档i第j个词的主题zi,j;
(3)从Dirichlet分布β中取样生成主题zi,j对应的词语分布
LDA算法是依据这里已经有的数据来对θ和φ进行再计算,就是估算文档—主题和主题—词语的概率。其中z是一个隐藏的变量,即对于每一个单词来说,它所对应的主题是不确定的。而θ和φ都是含有超参数的Dirichlet分布,因此对于LDA算法的本身也是估算α和β这两个参数值。概率模型可表示为:

对上式进行计算可以得出:
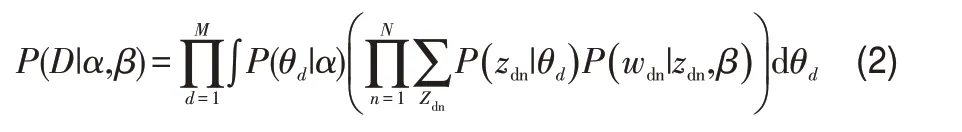
其中D代表整个文档,M代表文档中语句的总数。
由于上式中的α和β是不能够直接得到的,所以LDA的作者使用了变分推理的方法来计算函数的最小值,并且采用了中间值的办法来让LDA计算过程更简单,然后用EM算法求出α和β的值。现在通常都采用Gibbs采样的办法来计算估计值。
3.2 基于停用词删除方法的去噪预处理
本文采用了删除多数停用词的方式来进行文本的预处理,对本文获得到的数据进行清洗,去除垃圾词汇和数据,提高了文本挖掘的准确性。
停用词可以分为两类,一类是使用十分广泛的单词,还有一类是出现概率很高但是实际意义不大的词。如“啊”“比”“你”“的”等[11]。文本挖掘中碰到这样的词语就无法保证系统能够给出真正的最准确的答案,会使文本挖掘的效率和准确度降低。同时,过多的标点符号也会对文本挖掘的结果有很大的影响,标点符号也是需要去掉的停用词。因此,将停用词删除是有效的去噪预处理方法。
3.3 基于FP-growth算法的关键词抽取
FP-growth算法是把频繁项集的数据用一定的办法压缩到一个FP-树里面,然后再通过对叶子节点和父节点数据的判断来对信息进行适当的挖掘和分析。基于FP-growth算法的关键词抽取的输入是事务数据库D和最小支持度阈值min_sup。该算法的输出是频繁模式的完全集。构造FP-树的步骤为:
(1)扫描事务数据库D一次。收集频繁项的集合F和他们的支持度。对F按支持度降序排序,结果为频繁项集L。
(2)创建FP-树的根节点,用“null”来进行标记。对于D中的每个事务Trans,执行:
选择Trans中的频繁项,并按L中的次序排序。设排序后的频繁项集表为[p|P],其中p是第一个元素,而P是剩余元素的表。调用insert_tree([p|P],T)。该过程执行情况如下,如果T有子女N使N.item-name=p.item-name,则N的计数增加1;否则创建一个新节点N,将计数设置为1,链接到它的父节点T,并将其链接到具有相同item-name的节点。如果P非空,递归调用insert_tree(P,N)。
而FP-树的挖掘则通过调用过程FP-growth(FP-tree,null)实现,调用Procedure FP-growth(tree,α)函数,其具体步骤为:
(1)如果tree包含单个路径P,那么遍历路径P的每个节点组合(记为β);
(2)产生模式β∪α,支持度support=β中节点的最小支持度;
(3)对每个节点αi在Tree的头部都执行:
1)产生模式β=ai∪β,它的支持度是support=αisupport;
2)构造β的条件模式基和条件FP-树treeβ,若treeβ不为空,调用FP-growth(treeβ,β)。
3.4 基于远程学习算法的关键词筛选
3.4.1远程学习
远程学习指的是利用开放资源的信息和数据来提高关键词的准确度。本文利用网络资源,将得到的短语结果放到网上,基于百度百科知识库的应用进行搜索。这种方式的好处就是网络资源丰富,而且数据更新快,更容易发现新词,网络上的数据涵盖各个方面,免去了建立字典的麻烦。
3.4.2字符串匹配度
对于两个字符串String1和String2之间的匹配度用百分比的形式表示为:
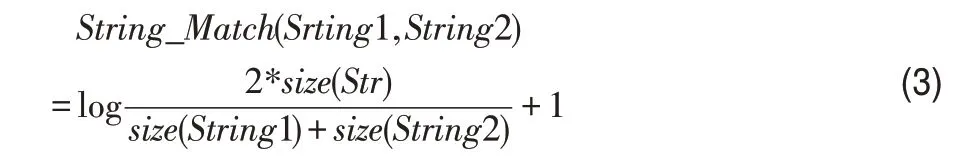
其中,Str=String1∩String2表示的是字符串String1和String2之间共同拥有的最长子串。size(Str)表示的是字符串String1和字符串String2之间最大子串的长度。size(String1)表示的是字符串String1的长度,size(String2)表示的是字符串String2的长度。
3.4.3汉语比对算法
本文设计了基于百度百科和匹配度公式的汉语比对算法,来对上面通过LDA算法进行文本聚类和FP-growth算法提取得到的关键词进行筛选。该算法的输入为:用制表符隔开的短语数组S1和阈值p。输出为:删除了一些噪声词的用制表符隔开的短语集合S2。算法如图2所示。
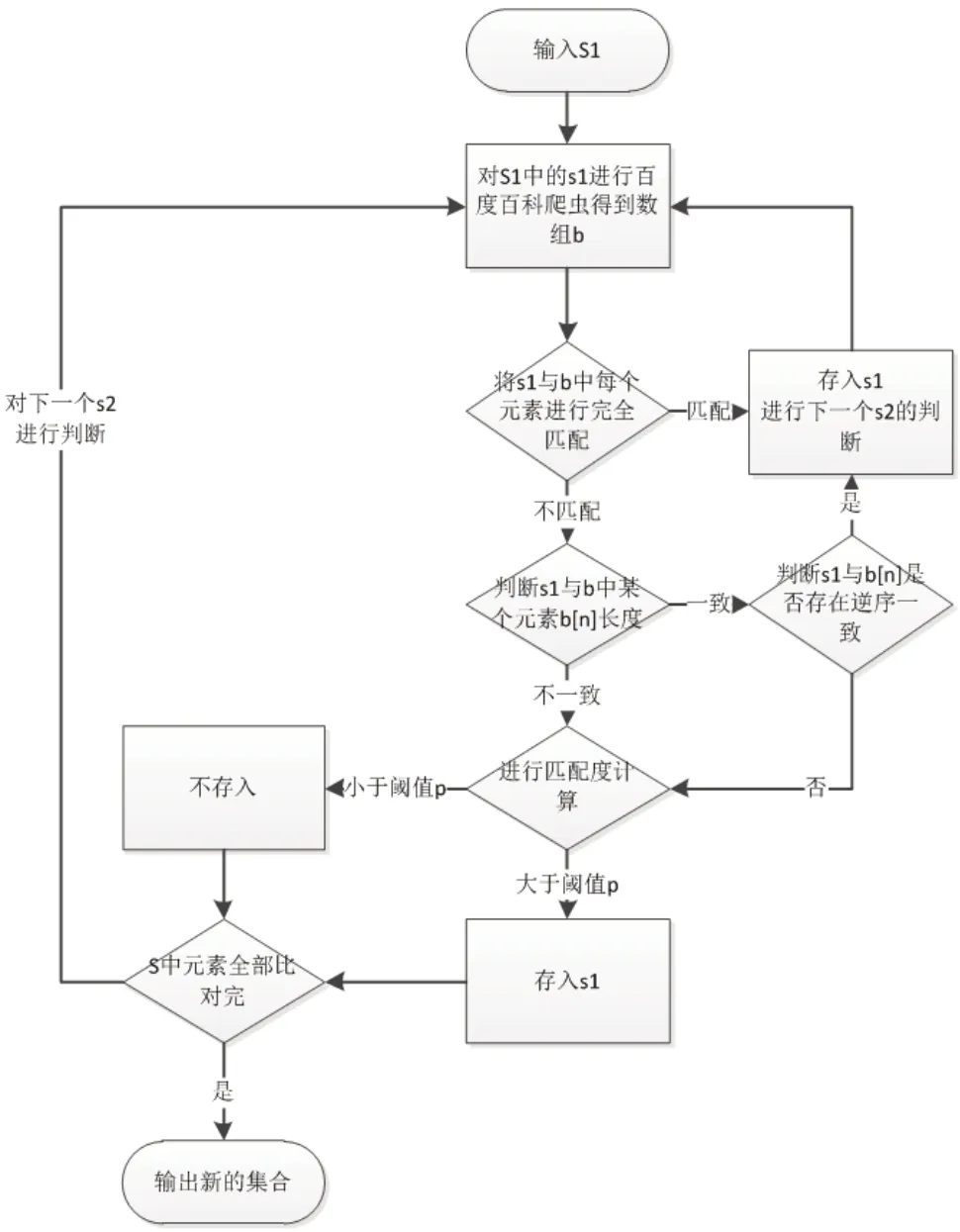
图2 基于百度百科和匹配度公式的汉语比对算法
3.4.4算法测试
为了测试汉语比对算法的效果并选取出合适的阈值,从中国人民大学的网络与移动数据管理实验室所提供的领域分类(CCF目录)论文收录(http://cdblp.ruc.edu.cn/)中的论文中随机选取了50篇论文,人工随机选取了1038个正确短语以及600个错误短语作为实验语料进行实验。
该汉语比对算法的拦截成功率呈现一定的规则。在阈值为30%左右的时候,对正确短语和错误短语的拦截率成功率相等,为96%。随着阈值的增加,对于正确短语的拦截成功率下降较为明显,错误短语的拦截率趋于100%。当阈值过高时,虽然拦截错误短语的能力提高了,但一些正确的短语会被拦截,这是因为有一些我们认为正确的短语在百度百科中还没有被收录。当阈值为交点坐标30%时就可以基本满足筛选的需求。因此,该汉语比对算法在选择合适阈值0.3用来进行关键词的筛选。
4 系统实现及实验
4.1 系统实现
基于远程学习的关键词提取系统的实现流程如图3所示。

图3 基于远程学习的关键词提取系统的实现流程
首先该系统输入主题词参数n,用于LDA算法的主题建模和生成词典文件(pt网络文件)。其次,输入最小置信度阈值λ和最小支持度阈值min_sup,FP-growth算法要用这两个参数挖掘词与词之间的关系来生成词和关键词集。最后,筛选阈值p用于短语比对算法对噪声词进行筛选。通过上述的三个步骤,来生成需要的关键词集。
4.2 实验
4.2.1实验数据来源
选择中国人民大学的网络与移动数据管理实验室所提供的领域分类(CCF目录)论文收录(http://cdblp.ruc.edu.cn/)中的论文数据11490条论文标题作为实验语料。其中包含了计算机网络分类的3314条数据,模式识别分类的2276条数据,软件工程的2880条数据以及算法理论分类的2520条数据。
4.2.2实验步骤
(1)将采集到的语料先进行去噪处理。
(2)将语料和主题数n,最小置信度阈值λ,最小支持度阈值min_sup和筛选阈值p输入到系统中。这里本文采用的主题数为4,λ为0.5,min_sup为5[3]。筛选阈值p初值为0.3。
(3)改变筛选阈值p的值,进行重复试验。
4.2.3实验结果和分析
对于没有使用远程学习筛选的关键词提取算法,在图像、软件、算法和网络四个场景上的准确率分别为0.7415、0.9255、0.7738和0.8472,召回率分别为0.5824、0.7248、0.5432和0.6128,F值分别为0.65239006、0.81294601、0.63831155和0.71118378。准确率、召回率和F值的平均值分别为0.822、0.6158和0.70370785。
增加使用了远程学习筛选之后的关键词提取算法,在图像、软件、算法和网络四个场景上的准确率分别为0.9178、0.9654、0.9385和0.9621,召回率分别为0.5792、0.6972、0.5336和0.6131,F值分别为0.71020676、0.80966784、0.68036627和0.74893792。准确率、召回率和F值的平均值分别为0.94595、0.605775和0.7372947。
可以看出,在筛选阈值p为0.3的时候,对于这个文本的每个分类之下的关键词提取的准确率有明显的提高,对于召回率的影响不大,F值有较为明显的提高。实验结果说明增加了基于百度百科的远程学习筛选之后,提高了系统的整体性能。
对比了6个不同的p值0、0.1、0.3、0.35、0.5和1,系统准确率的平均值分别为0.822、0.8569、0.94595、0.9687、0.9867和1,系统召回率的平均值分别为0.6158、0.6432、0.605775、0.5096、0.30786和0.019,系统F值的平均值分别为0.703707852、0.7348、0.73729470、0.66786、0.46929和0.03。可以看出,随着p值的增加准确率在不断增加,当p值为1时准确率达到了百分之百。召回率和F值随着p值的增加有小幅度的上升之后显著降低,这说明p值过高系统的整体效果会很低。对于一个文本挖掘的系统,准确率很高但是有很多有用的信息会被过滤掉,这样的系统并不是我们想看到的。
因此,对于本文的基于远程学习的关键词提取系统,在其他的值都是经验最佳值的情况下,p值的最佳值是0.3左右,由于百度百科里面的资料不是一成不变的,针对每一个类别的知识也不尽相同,p值的最佳值由语料的种类决定。对于增加的百度百科筛选,在召回率波动不大的情况下,对关键词集的准确率提高较为明显。
5 结语
本文针对大数据处理中数据类别混乱、关键词模糊的问题,设计了基于远程学习的关键词提取系统。利用LDA主题模型进行文本聚类,使用停用词删除方法进行去噪预处理,利用FP-growth算法进行关键词的初步抽取。并且利用远程学习的思想结合了百度百科资源提出了汉语比对算法对关键词进行精确筛选。通过实验对比,证明使用远程学习的关键词提取算法可以提高准确率。对筛选阈值进行分析,证明阈值在0.3左右时可以进一步提高系统对关键词的提取准确率。但本系统对于不同语料种类仍存在一定的局限性,阈值要在0.3的左右做相应的微调以达到最佳效果。
猜你喜欢
军事文摘(2022年20期)2023-01-10 07:18:38
英语文摘(2021年11期)2021-12-31 03:25:18
学生天地(2018年19期)2018-09-07 07:06:30
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
军事历史(1986年4期)1986-08-21 06:22:34
