
我国区域城市招投标领域企业信用价值研究
——基于KSVM 研究方法
2021-11-19 14:24楼裕胜
经济与管理 2021年6期
孔 杏 ,楼裕胜
(1.浙江开放大学 教学中心,浙江 杭州 310012;2.浙江金融职业学院 信息与互联网金融学院,浙江 杭州 310018)
一、问题的提出
我国已处于全面推进社会信用体系建设加速发展阶段。2013—2019 年,国家连续发布10 个信用建设相关文件,反映出党中央对社会信用体系建设工作的高度重视。企业作为社会经济发展的一个重要主体,信用建设至关重要,企业信用评价则是较长一段时间备受关注的一个焦点。自从约翰·穆迪开创企业信用评价模式以来,无论是学术理论还是实践部门,都在不断地完善评价的信息体系及评价模型方法,力求评价的准确性。信用既包含诚信行为,也包含信用能力。传统意义上的诚信行为强调自身的修养,但随着市场经济体制的完善,诚信更加强调“真实无欺、遵守约定、践行承诺、讲究信誉”为一体的社会规范[1]。信用本质则是一种契约精神,代表的是允诺能力,可以说诚信是意愿,信用则是能力,只有“诚信意愿+信用能力”同时具备,信用关系才能得以维系。诚信意愿表现出来的诚信行为为政府的业务监管提供决策依据,信用能力为交易对手在市场交易中提供决策信息[2],具有诚信意愿的企业是否意味着也同样具备良好的履约能力? 或者说具备履约能力的企业又是否会按时履约,二者之间是否存在一致性? 本文将重点聚焦企业诚信行为和信用能力的一致性研究,从企业信用内部结构的稳定性视角分析企业的信用价值,这是企业信用评价的创新,对企业内部管理也有积极影响。
二、文献综述
企业信用评价方法的发展大致经历了三个阶段:第一阶段为经验判断阶段。经验判断时期主要以专家过往经验为依据,随后为了避免评判的主观性,在评价方法中逐步应用了数学分析方法,财务比率模型被最早应用到企业信用评价模型中。第二阶段是统计计量分析阶段。统计计量分析主要包括二次判别模型、logit 和logistic 回归模型、probit 模型。刘兢轶等[3]运用因子分析和logit 模型对中小企业信用风险评价进行研究,并得到模型预测准确性较高的结论。刘丹等[4]通过对商业银行信贷数据的分析,验证了Woe-Probit 逐步回归模型的有效性。统计计量分析法在预测、识别等方面具有优势,且易于对模型进行经济学解释,但对数据要求较高,主要依赖企业财务指标,使得评价信息存在局限性,且当解释变量较多时容易产生多重共线性问题[5]。第三阶段是机器学习阶段。机器学习则以大数据为基础,数据来源广、类型丰富,可通过获取企业大量相关信息来实现对企业更为全面的信用评价,机器学习方法主要包括神经网络、支持向量机等。肖斌卿等[6]的研究表明,模糊神经网络模型在小微企业信用评级中具有较高的检测精度。信用评价中经常会遇到样本量不大、数据缺失、存在异常数据等问题,对此神经网络无法解决[7],国内一些学者开始将支持向量机(SVM)应用到企业信用风险评估中。
支持向量机(SVM)是一种基于人工智能的信用风险评估方法,贝森斯(Baesens)和格斯特尔(Gestel)在2003 年首次把支持向量机方法引入到信用评价领域,并得出SVM 作为信用风险评价工具与线性回归和神经网络方法相比具有运算速度快、准确率高的优势[8]。SVM 在个人、企业信用风险评估领域具有较高预测准确率已经得到相关学者的验证[9-10],与BP 神经网络相比,SVM 更具有效性和优越性,预测精度更高[11-12]。SVM 模型在进行信用风险评价时存在的问题,国内学者也在对其进行不断改进。SVM 模型受噪声和奇异点影响较大,适应能力和抗噪性还有待提高,姚潇等[13]、Yu et al.[14]提出的模糊近似支持向量机和近支持向量机(TLSPSVM)能够有效降低噪声和奇异点对模型分类结果的影响。目前各种类型SVM 模型在处理分类样本时默认样本分布是均衡的,并未考虑样本非均衡性问题。针对样本不平衡数据分类问题,国内学者提出了一种改进SVM-KNN 算法,即KSVM。KSVM较SVM 对样本数据分类具有更高的准确率也得到了国内一些学者的验证。李蓉等[15]通过数值实验证明了KSVM 算法比单独使用SVM 进行分类具有更高的准确率。王超学等[16]在对UCI 数据集大量实验基础上发现,KSVM 算法能提高对少数类样本的识别率。此外,部分学者尝试将SVM 与其他方法相结合,运用组合算法模型进行信用评价,此种应用最大的贡献在于提高模型预测精度和分类准确度[17-21]。当然,SVM 的应用中还有一些问题尚待解决。在支持向量机应用中,核函数的选择是核心问题之一,它对分类器的性能有重要影响,核函数的选择和参数的设置问题在理论界还未得到解决,目前更多的是凭借经验,主观性较强。因此,近些年在个人信用评分模型研究中,国内外学者将重点聚焦在构建组合分类器模型。刘玉峰等[22]通过对三种不同分类器的对比,验证了subagging 集成分类器在特定情况下能有效提高模型精确性。Danenas et al.[23]研究了基于支持向量机的分类器,研究表明虽然SVM 分类器不同,但是产生的结果比较接近,分类器及其参数的选择是否合理仍需要重点关注。
现有关于企业信用评价的研究大多是基于受评对象外部视角,运用各种方法以评判发生违约风险的可能性,鲜有从企业内部开展信用价值研究。本文从诚信行为和信用能力这两个企业信用的重要影响因素之间的关系着眼,研究二者的内在一致性,其贡献如下:通过构建企业信用价值指标体系,对诚信行为与信用能力的相互关系进行验证,为二者之间的理论关系提供实证依据;从诚信行为和信用能力是否匹配角度进行企业信用评价,从过去、现在以及将来的动态视角综合考察企业是否有主观履约意愿和具备客观履约能力,为企业信用价值研究提供新的思路和方法。
三、企业信用价值指标体系构建
本文从诚信和能力这两个企业信用的重要影响因素之间的关系着眼,构建企业信用价值指标体系,该指标体系包含两部分内容:一是企业诚信行为,二是企业信用能力。企业主观上是否具有履约意愿可通过以往企业表现出的诚信行为反映,因此,以企业生产经营状况并结合政府部门的监管结果构建企业诚信行为指标体系。企业是否具备客观的履约能力反映在企业业务运营和项目管理水平等方面。因此,企业信用能力指标体系包含企业整体素质、项目管理、保障能力、运营能力四个维度,具体指标体系如表1 所示。

表1 企业信用价值指标体系
四、实证分析
(一)模型介绍
支持向量机(Support Vector Machine,SVM)适用于解决由于样本数量较少而造成的结果偏差问题,同时应对维数灾难和过拟合现象也具有天然优势。支持向量机模型和结果易于理解,方便推广,是目前普遍接受的机器学习方法。
在分析的样本空间中,定义最优分类超平面的基本形式为:

在控制‖ω‖保持最小的前提下,可以令g(x)满足分类间隔达到最大。若样本是线性的,目标函数定义为:

再通过求解二次规划问题(QuadraticProblem,QP),解决线性可分问题。
若样本是非线性的,则需要引入非负松弛变量ξi(i=1,2,…,m)和惩罚参数C,再通过拉格朗日乘子法,在约束中加入拉格朗日乘子αi≥0,目标函数定义为:

使用支持向量机的假设条件是样本数量大致相等且分布平衡,这样才具有较高的分类精度。对于不平衡数据的分类,支持向量机结果可能不太理想。
KSVM 是为了解决位于最优分类面附近的样本分类错误的问题而提出的改进SVM 算法。研究证实,SVM 分类器对位于两个类别重叠交叉位置的样本具有一定的分类错误,若对这部分样本点分类进行改进,将会有效提高SVM 分类器的准确率。将KSVM 分类器下的支持向量集代表对应类别,即SVM 分几类就有几个支持向量,同时将这些支持向量组成新的样本,再结合KNN 对其进行分类,提高样本重叠位置分类的准确率。
KSVM 分类器是将SVM 分类下的两类支持向量作为两个样本点,φ(xi)为xi的映射函数。根据则yi=1 和yi=-1 的支持向量的样本点分别为:

记φ(xi)·φ(x)为K(xi,x)。SVM 分类超平面的最优解就是由φ(x)+和φ(x)-这2 个代表点构成。
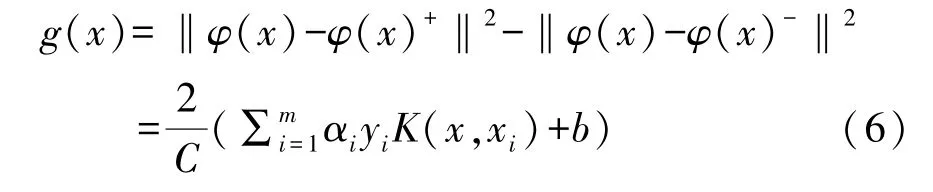
假设样本点与最优分类面的实际距离为d,给定距离的分类阈值ε,若|d|>ε,则认为样本点与最优分类面相距较远,SVM 分类器可以对其进行类别划分;若|d|<ε,认为样本点距离最优分类超平面较近,SVM 分类器分类错误的概率较大,应该使用KNN 进行分类。
支持向量机中采用径向基核函数,能够比较容易地获取样本数据间所包括的局部信息的优点,所以学习能力较强,而且由于径向基核函数可以逼近非线性函数,所以比较适用于处理非线性问题。在运用KSVM 模型的同时,将其与双隶属度SVM 模型、传统SVM 模型的判别精度进行对比,从而更为客观地评价模型的适用性。
(二)计量分析
为了验证企业诚信行为与信用能力的一致性,根据表1 构建的指标体系,本文运用KSVM 方法对浙江、江苏省12 个城市的292 家园林招投标企业调查获取的数据,开展实证分析。根据企业诚信行为指标体系计算企业诚信行为得分,将得分按照设定的标准把企业划分为两类:诚信行为优秀和诚信行为仍有不足。从信用能力与诚信行为具有一致性研究假设出发,通过信用能力指标体系对企业诚信行为进行预测,将预测结果与企业诚信行为分类结果进行对比,预测值与真实值一致性程度越高,信用能力与诚信行为关系越密切,即信用能力强的企业诚信行为也好,反之亦然。由于本文是关于诚信行为和信用能力一致性的研究,因此关于企业诚信行为得分的计算过程只作简要介绍。
1.企业诚信行为得分。根据表1 诚信行为指标体系计算企业诚信行为得分并进行分类。具体步骤如下:在对数据进行标准化处理的基础上,采用全局敏感度方法确定评价指标权重,从而得到招投标企业诚信行为综合评价值,根据公式诚信行为得分=综合评价值×100,计算各企业诚信行为得分。在得分基础上,采用高斯混合模型对企业进行聚类分析,将聚类结果与企业诚信行为得分相结合来确定不合格企业,确保结果的客观性。最终剔除其中诚信行为不达标企业共7 家,即诚信行为达标企业285 家。进一步对诚信行为达标的285 家招投标企业进行两分类划分,具体做法是将285 家达标企业诚信行为得分的中点值算出,以三倍标准差作为285 家招投标企业诚信行为优秀标准线。高于标准线,认为企业诚信行为优秀,低于标准线,认为企业诚信行为还有不足。分析结果显示285 家企业中,诚信行为优秀的有133 家,诚信行为仍有不足的有152 家。
2.企业诚信行为与信用能力一致性分析。KSVM 模型设计步骤如下:(1)将样本数据二分类为训练集和测试集,根据训练集数据建立二分类器及分类样本的支持向量集。(2)对测试集中的样本xi,计算样本与分类器的距离f(x)=αiyiK(x,xi)+b。(3)将距离f(x)与距离阈值ε比较,若|f(x)|<ε,即样本点靠近最优分类面,分类器出现分类错误的概率较大,选择KNN 算法;反之,仍选择分类器。(4)若|f(x)|<ε,将支持向量对应的样本点的各个参数引入KNN 算法,计算xi与每一个支持向量之间的距离,选择最近的支持向量所代表的类别作为xi的类别。(5)若|f(x)|>ε,仍选择分类器进行分类,得出xi的所属类别。根据模型参数的选取,对模型测试集进行判别准确率的计算,结果如表2 所示。

表2 模型的分类正确率比较
由表2 的结果可以看出,KSVM 模型的总体准确率最好,正确率达到81.05%,285 家企业中有231家企业的预测值与实际值是一致的。从分类的正确率出发,KSVM 的效果最好,也印证了样本数据的确存在不平衡的问题。KSVM 模型能够降低硬判别所造成的误判,提高企业诚信行为和信用能力一致性判别的正确识别率。
表2 中的模型分类正确率是指所有分类正确的企业数与企业总数的比值,但是考虑一个极端的情况,一个不加思考的分类器,如果对每一个企业样本都将类别划分为诚信行为不足,也能达到53.33%的准确率,即实际285 家达标企业中诚信行为仍有不足的152 家所占比例,但这个分类器在实际应用中显然会带来巨大的损失。因此,单纯靠一个准确率来评价分类器是不全面的。我们进一步从F-value和G-mean来考虑。
F-value能够综合考虑分类的查全率和查准率,定义为:

precision代表查准率,recall代表查全率,β取值范围[0,∞)。β<1 时F-value以查准率为主;β>1时F-value以查全率为主;若取值为1,则表示查全率和查准率同等重要。
G-mean为少数类和多数类的分类精度的几何平均。定义为:

G-mean综合考虑多数类和少数类的分类精度,只有两者达到均衡状态,G-mean的值才能达到最大。因此,选择F-value衡量少数类的分类性能,选择G-mean衡量样本数据整体分类性能。
F-value、G-mean的构建基于混淆矩阵,如表3所示,其中TP 代表少数类中样本判断正确的量;TN代表多数类中样本判断正确的量;FN、FP 则分别表示少数类和多数类中判断错误的数据量。

表3 两类问题的混淆矩阵
计算出三个模型各自的F-value和G-mean值,具体如表4 所示。

表4 模型F-value 和G-mean 值的比较
F-value和G-mean值都是越高越好,从表4 中我们可以看出KSVM 从少数类分类性能和整体分类性能来看,都要优于双隶属模糊SVM 和传统SVM,因此可以认为KSVM 的模型更加适用于企业样本数据。
3.模型分类概率分析。将KSVM 模型应用于企业信用分类,在提高模型分类正确率的同时还能给出该企业对应两种类别的隶属度,也就是模型判定企业属于两种类型的概率值。企业所属诚信类别的概率值如表5 所示。

表5 企业所属诚信类别的概率值
单个企业诚信行为二分类的概率值合计为1,若企业诚信行为存在不足的概率值大于诚信行为优秀的概率值,则企业会被模型分到诚信行为不足的一类;反之,则被分到诚信行为优秀的一类。231 家预测值与实际值一致的企业中,99 家企业实际情况与预测结果均为诚信行为优秀,132 家企业实际情况与预测结果均为诚信行为存在不足。对于实际和预测诚信行为都优秀的企业,它们在招投标过程中更有可能中标,因此对于这类企业可以按照模型的分类概率高低进行排序。理论上认为预测属于诚信行为优秀的概率值越高,企业中标可能性越大,实际值和预测结果都优秀的企业排序如表6 所示。
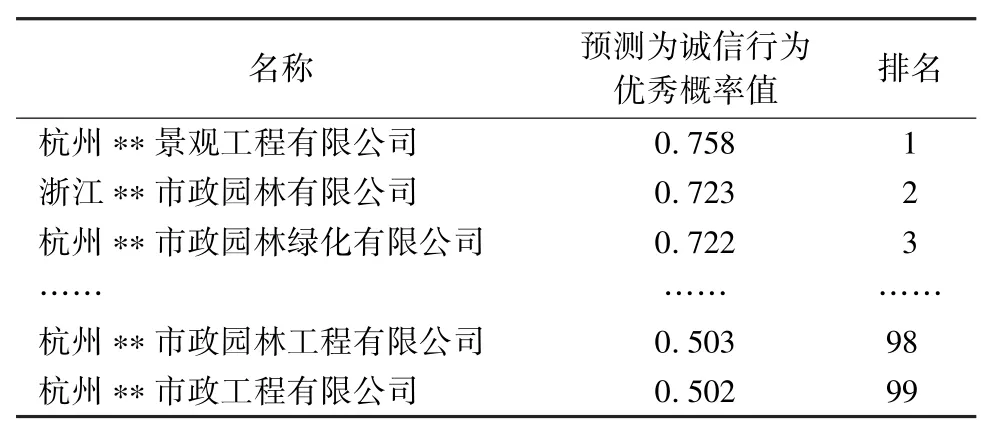
表6 诚信行为优秀的企业排序
对于诚信行为优秀的企业,如杭州∗∗景观工程有限公司模型预测概率值最大,诚信行为和信用能力的一致性匹配最佳,在招投标企业竞争中的优势也就越大。而对于预测概率值低的企业,如杭州∗∗市政工程有限公司,虽然也属于诚信行为优秀的企业,但是诚信行为和信用能力的一致性匹配程度并不高,该企业或许诚信行为良好,但自身在履约能力方面可能存在不足,因此在招投标企业中的竞争优势也就难以突出。
在实际应用中,模型也会将本身诚信行为优秀的企业误分为诚信行为存在不足,或将诚信行为存在不足的企业误判为诚信行为优秀。这两种误判对于决策方来说带来的损失是不同的。将诚信行为优秀的企业误判为诚信行为存在不足会使决策方失去选择优秀企业的一个机会,可能会带来一些损失,但是将诚信行为存在不足的企业误判为诚信行为优秀的企业有可能会给决策方带来重大损失。表7 为诚信行为优秀但被误判为诚信行为不足的企业。

表7 诚信行为优秀但被误判为诚信行为不足的企业
有34 家企业诚信行为实际情况为优秀但被误判为存在不足。模型认为这类企业的诚信行为和信用能力是不匹配的。因此,本文将该类企业与诚信行为实际值和预测结果均为优秀的99 家企业信用信息进行对比,分析该类企业究竟是哪些信用能力指标存在显著差异。
企业信用能力分为四大类指标,包括运营能力、企业素质、保障能力和项目管理。在运营能力和企业素质指标中,两类企业的差异并不大。34 家错分企业在项目管理和保障能力的大部分指标,总体上都要优于99 家分类正确的企业。其中,只有企业的知识产权数量存在明显差异。99 家分类正确的企业中知识产权数量大于20 的有24 家,浙江∗∗集团股份有限公司的知识产权数量甚至达到了339 件,平均每家企业知识产权数量也超过20 件;而34 家错分的企业中仅有6 家企业的知识产权数量大于20,杭州∗∗园林工程有限公司拥有最高知识产权数量58 件,每家企业的平均知识产权数量也仅有9.5件。由此可见,知识产权因素对企业诚信行为和信用能力一致性有很大影响。
同样也存在20 家企业本身诚信行为不足但被错分为优秀的企业,如表8 所示。
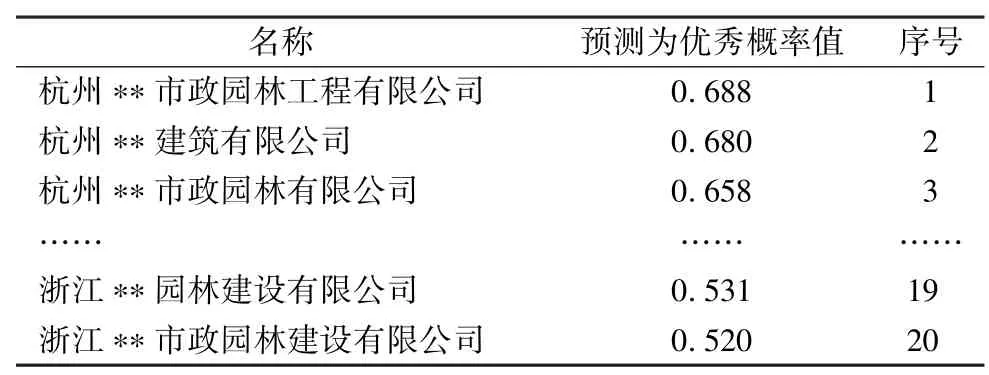
表8 诚信行为不足但被误判为优秀的企业
表8 中的20 家企业诚信行为存在不足但错分为诚信行为优秀,会对招投标环节中确定优质企业造成更大的影响,对于这类企业更应加强各方面信息的识别。通过与“诚信行为实际情况和预测结果均为存在不足”企业的对比分析得知,这类错分的企业仅在企业素质中法人/项目负责人最高学历和建造师人数比例方面拥有优势,法人/项目负责人的学历与二级建筑师的比例都很高,45%的企业二级建造师人数占比都达到100%,企业的法人或负责人最高学历都是大专及以上。由于以上两个因素的影响使其被误判为“诚信行为优秀”企业。进一步将该类企业与“诚信行为实际情况和预测结果均为优秀”的企业信息进行对比,发现该类企业在运营能力、保障能力、项目管理方面差距比较大,且成立年限较短,30%的企业成立年限不足10 年,因此在近5 年中标次数、近5 年中标总金额等方面毫无优势。同时,这类企业的在册人数和参保人数平均只有59.5 人和39.1 人,这方面要远低于诚信行为优秀企业的168.1 人和92.6 人,注册资本和实缴资本也都很低,表明整体资金实力并不强。因此我们可以认为这类被错分为优秀的企业由于成立时间短、规模不大、资金实力不强及近5 年中标次数少等原因,使得企业诚信行为评分也较低,但由于其在企业人员素质方面具有突出优势,导致最终被错分。
五、结论与建议
本文从企业内部视角开展信用价值研究,从诚信行为和信用能力这两个企业信用的重要影响因素之间的关系着眼,通过构建企业信用价值评价指标体系,运用KSVM 模型研究二者的内在一致性。研究结果表明,285 家招投标企业诚信行为和信用能力一致性达到81.05%,即诚信行为优秀的企业信用能力也较强,两者的匹配性较高,诚信行为与信用能力具有一致性的研究假设得到验证。模型分析结果与实际情况较高的吻合度,也说明了KSVM 模型对企业信用价值分析的有效性。对于少数被误判的企业进行深入分析,发现“诚信行为优秀但被误判为存在不足”的原因在于“知识产权数量”指标上的显著差异,而“诚信行为仍有不足但被误判为诚信行为优秀”是由于“企业人员素质”指标的差异。根据以上研究结论,本文提出如下对策建议:
1.积极探索多角度的企业信用价值研究方法,从而实现对企业信用状况更为准确、客观和全面的评价。本研究从企业信用理论出发,通过企业的诚信行为与信用能力一致性来体现企业信用价值,与传统的信用评级有一定的差异,这使得对企业信用的理解视角更加广阔,为政府和相关部门对企业开展信用评判时提供更加立体、多维和翔实的依据,更有利于企业提升内部信用管理水平和层次。
2.加快推进公共信息资源向社会开放,并提升公共信息的准确率和覆盖率,从而创造更多公共价值。我国正处于加快推动大数据产业发展阶段,将政府数据最大限度地开放出来,让社会进行充分融合和利用,有利于释放数据能量,激发创新活力。在我国加快推进社会信用体系建设时期,政府、企业、个人等不同信用主体都已认识到信用的重要性,但难点在于如何去识别不同主体的信用状况。本文构建的企业信用价值指标体系,其指标信息的获取是基于长三角地区高度开放的数量大、覆盖面广的公共信用信息的前提,这使得信用评价结果更为准确,对从信用信息的可得性角度进一步挖掘企业信用价值有一定的实践意义。
3.政府及相关部门在各重点领域应加强对企业各方面信息的识别。研究结果显示,在285 家企业中有20 家诚信行为不足的企业被误判为诚信行为优秀,这一结果有可能会给决策方带来重大损失。因此,政府及相关部门对于这类现象要引起重视,在进行项目招投标过程中,应从多渠道获取企业相关信息,并加强对信息的识别,以最大可能选择优质企业从而确保项目完成的质量。本文是以招投标领域企业为研究对象,但研究结果也可为其他重点领域如招商引资、政府与社会资本合作项目、政府采购等领域的企业信用评价提供借鉴,以科学评价方法让有主观履约意愿和具备客观履约能力的“双优”企业最大概率中标,不仅能减少该领域腐败现象的发生,也有利于整个社会效益的提高和公共利益的最大化。
4.各部门及机构可对不同信用主体采用本研究所提出的信用评价方法。本文从企业信用内涵出发,从挖掘诚信行为与信用能力二者之间相互关系的视角进行企业信用价值研究,对传统的企业信用一体化评价方法进行了创新,为多维度、多层次分析企业信用价值提供了思路。从信用内涵出发开展信用价值研究的方法不仅可以用于企业信用特征的研究,也可用于政府以及个人等不同信用主体信用状况的分析,因此在一定程度上拓宽了分析的视野,同时也是我国社会诚信体系建设的内在需要。
5.可从不同视角分析企业信用存在的问题。本文以公共信用信息为基础对诚信行为与信用能力关系进行分析,未来借助大数据手段获取的公共信用信息将越来越丰富,整体评价质量也将不断提高,从而对企业信用的评价也更为准确。研究结果表明诚信行为优秀的企业信用能力也较强,即诚信行为与信用能力具有一致性,诚信行为优秀、信用能力强的企业在市场竞争中具有明显的优势。当然也可能存在不一致的情况,若存在不一致,根据所构建的企业信用价值指标体系,可从监测数据和企业自身运营过程中的相关指标进行分析,为深入挖掘企业信用存在的问题提供思路,从微观角度看也有助于企业对自身问题的查找。
6.评价结果有利于在社会经济管理中推广使用。诚信行为和信用能力是信用内涵的两个重要方面,诚信行为体现企业的守信意愿,信用能力则反映企业的履约能力。信用管理的核心是信用评价结果,企业的守信意愿为政府的业务监管提供了决策依据,而企业的履约能力更多的是体现其经济实力,从而为市场交易中交易对手的识别提供决策信息。需要指出的是,本研究构建的企业信用价值指标体系在财务方面的指标数据偏少,因此在一定程度上对企业能力分析稍显不足,后期研究将在信用信息质量不断提高的同时提升信用评价的精度。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
理财周刊(2020年12期)2020-08-12
云南电业(2018年9期)2018-10-21
领导决策信息(2018年16期)2018-09-27
软件导刊(2017年4期)2017-06-20
数学学习与研究(2017年3期)2017-03-09
商(2016年30期)2016-11-09
计算技术与自动化(2014年1期)2014-12-12
