
基于数据驱动的图书馆用户画像模型构建方法研究
2021-11-18 22:44赵建建
新世纪图书馆 2021年10期

摘 要 构建基于数据驱动的图书馆用户画像模型体系以提升图书馆的资源推荐精准度。论文从用户对资源的需求出发进行分析,通过对用户行为数据的采集与特征选取,以层次分析法为分类标准,构建用户的标签体系。运用TF-IDF算法对标签的权值进行计算,构建个体用户画像,再以标签为载体进行聚类分析构建群体用户画像模型,为图书馆开展精准推荐服务提供依据。
关键词 图书馆 用户画像 层次分析法 标签体系
分类号 G250.7
DOI 10.16810/j.cnki.1672-514X.2021.10.008
Research on the Construction Method of Library User Profiles Model Based on Data Driven
Zhao Jianjian
Abstract User profiles model system is aimed to help libraries to accurate recommend resources based on data driven. This paper conducts an analysis and built a user tag system through acquisition and feature selection of user behavior data with the analytic hierarchy process as a standard for classification. The profiles of individual users are constructed by calculating the weight of tags with the term frequency–inverse document frequency (TF-IDF) algorithm, and a cluster analysis is conducted based on tags to build a model of group user portrait, so as to provide a basis for libraries to deliver precise recommendation services.
Keywords Library. User profiles. Analytic hierarchy process. Tag system.
目前,圖书馆逐年增加的纸质资源和电子资源给图书馆的管理带来压力,而用户又迫切需要图书馆提供个性化、精准化的信息服务。针对以上问题,图书馆需要树立“数据即服务”的理念,采用大数据技术分析用户利用图书馆资源的特征,挖掘用户行为产生的海量数据之间的相关性,预测用户对资源的动态需求,以弥补用户反馈机制不畅造成的图书馆对用户需求的认知偏离。近年来,图书馆不断引入各种智能设备,这些设备制造的大量终端用户数据为分析用户资源需求特征提供了数据保障。大数据具有海量性、多样性、高速性和价值性等特点,而用户画像则是有效的大数据分析工具,利用用户画像可以实现图书馆资源、读者信息需求之间的有效衔接,进而推动基于用户需求的图书馆资源建设,构建具有精准推送、个性化服务的智慧图书馆,提升图书馆资源的利用率,降低用户的使用门槛。
1 用户画像研究概述
学界对用户画像的研究主要集中在用户画像的基本问题、用户画像的模型构建和用户画像的应用价值三个方面。
1.1 用户画像的基本问题
用户画像的基本问题主要包括用户画像的概念、理论基础和实践意义。交互设计之父Alan Cooper最早提出了用户画像的概念,用户画像即用户角色,是真实用户的虚拟代表,是建立在一系列真实数据上的目标用户模型[1]。David Travis认为一个完整的用户画像应该具有基本性(Primary)、真实性(Realistic)、移情性(Empathy)、目标性(Objectives)、独特性(Singular)、数量性(Number)、应用性(Applicable),并将其总结为PERSONA,一个应用系统要满足其七大特征才能构成一个完整的用户画像模型[2]。许鹏程等在David Travis的七个特性的基础上提出了大数据环境下的用户画像特性,认为其应该具有可迭代性、知识性、聚类性、交互性、时效性和区隔性,并对这六大特性进行了详细的解释[3]。李丹认为用户画像是对用户行为进行的分类,是通过大数据技术从海量用户特征中抽取信息对用户进行类别刻画,构建用户的特征全貌[4]。晁明娣认为用户画像是对用户特征的信息整合、筛选、聚类建构,实现知识在大数据环境下的利用、增值与再创造,以用户行为特征的标签化刻画用户画像全貌,以用户需求为导向进行资源推荐[5]。宋美琦认为对用户数据的充分利用是用户画像研究的前提,用户画像研究在本质上就是对用户特征进行研究的过程[6]。
1.2 用户画像模型构建
王乐、倪维健等分析了用户Web行为特征,并依据用户的网络日志构建了层次化的用户标签体系,采用Stacking组合模型完成标签的自动识别与结果分析,利用模式堆叠的方法构建多种分类器,进行用户特征值提取和语义库构建[7]。徐海玲以概念格理论为基础,以标签形式标记不同用户群体的属性值,采用层次显示和基于关联规则描述标签,通过建立群体用户兴趣画像,实现了对用户的精准描述[8]。吴智勤以用户的社交网络数据作为分析载体,通过机器学习的方法进行模型分析,通过开源分布式平台Spark系统中的GraphX算法库等专用的机器学习工具挖掘社交数据,全面获取用户特征,通过构建用户兴趣标签、用户社交标签和知识标签来构建用户画像[9]。学者Leung和Lee采用排序学习的方法,基于搜索引擎的原理构建了基于概念向量的用户画像[10]。Jomsri P. 通过图书ID、借还时间等图书信息构建了基于用户画像的图书推荐系统[11]。
1.3 用户画像的应用价值
单晓红以北京市携程网酒店为案例,以网上用户评论数据为基础,将画像模型属性分为用户基本信息、酒店信息和用户评论信息三方面,构建了基于三个维度的用户画像模型,从而为酒店开展精准营销提供决策依据[12]。李嘉兴、王晰巍等通过对老年人手机移动终端日志的使用行为分析,以微信为分析媒介,根据老年人的使用能力、交互能力、使用强度构建了老年人行为特征的用户画像模型,为国家老年人事业发展提供智力支持[13]。林燕霞依据社会认知理论,采用主题模型的概念来构建用户画像模型,通过文本挖掘的方法抽取出用户喜爱的微博主题,利用空间向量来计算用户之间对微博主题的偏好程度,计算出用户的相似度,实现了群体用户画像模型的设计[14],对微博舆情分析有理论研究意义。任中杰运用爬虫技术采集数据构建用户画像,通过贝叶斯分类器对评论文本进行情感分析,以天津危化品事故为例,通过设计用户画像模型对突发事件的网络用户进行了情感分析[15]。目前国内刘海鸥、张亚明、刘速等学者针对用户画像在图书馆的应用做了很多尝试,但主要是从理论方面对用户画像的相关问题进行了论述,缺乏实证研究。
2 图书馆用户画像数据来源及设计
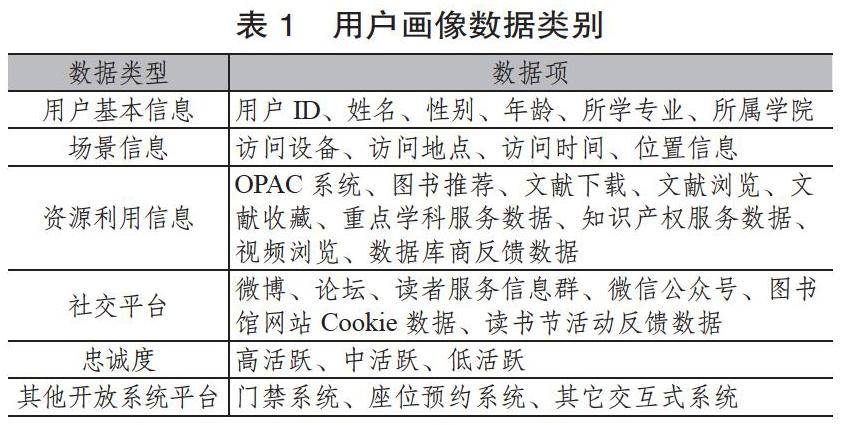
图书馆用户画像模型是建立在读者真实数据的基础之上构建的虚拟化画像模型。图书馆用户数据的来源主要是读者人口统计学属性和图书馆的各类资源平台、社交平台。用户的人口统计学属性又称为基本数据信息,随着时间的推移变化不大,可将其列为用户画像定性分析的范畴。读者对图书馆各类资源平台的访问数据、社交平臺交互式数据属于动态信息,随着时间、地点、场景等使用维度的变化,读者的科研兴趣、阅读偏好可能会发生变化,可将其列为用户画像定量分析的范畴。用户画像数据类别如表1所示。
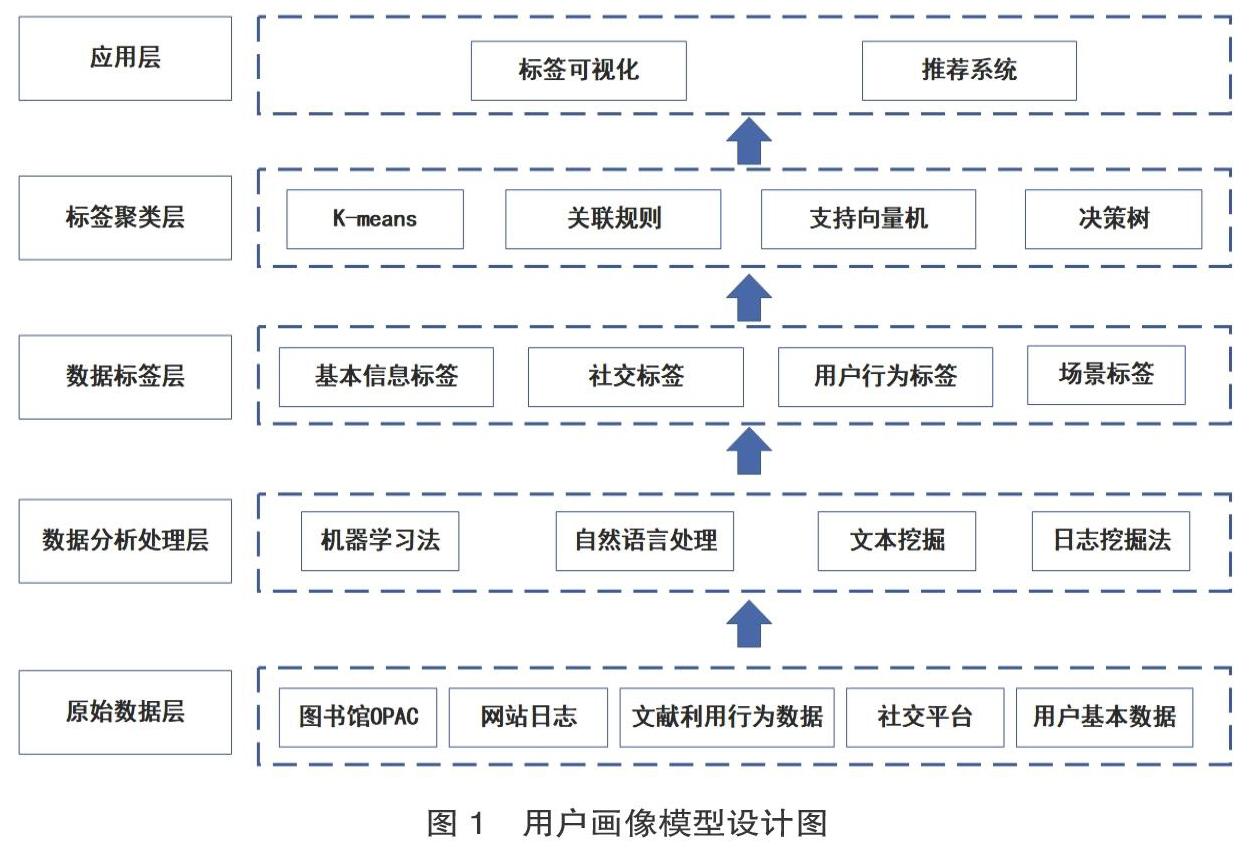
用户画像的设计需要实现两方面的目标:第一,图书馆用户画像的构建能够准确理解用户的资源需求;第二,按照用户画像的模型,图书馆推送给用户的数据应该是用户所需要的或者和用户需求相关的资源。用户对资源的需求情况可通过用户背景、用户行为特征和上下文信息等分析获取,用户画像设计的目标是尽可能全面细致地抽象描绘出用户的信息全貌。常见的用户画像分析方法有定性分析方法和定量分析方法,所谓定性分析方法主要是通过网络链接发放调查问卷、会员注册时填写基本资料等形式收集的用户信息,此类信息的精准度高但样本量有限。定量分析是运用技术手段对用户特征进行刻画,其中最重要的核心问题是通过建模对用户潜在的信息需求和兴趣进行分析,根据用户的基本信息、场景信息、资源利用信息、资源忠诚度等建立用户偏好模型。图书馆用户画像本质上就是与该用户相关联数据的可视化的展现,即用户需求信息的标签化。图书馆用户画像设计如图1所示。
3 用户画像模型的构建
3.1 用户数据的采集
数据是一切分析的前提,用户画像模型的构建首先需要抽取出用户的关联性数据。用户画像的数据来源主要包括用户基本信息数据,中国知网、万方知识服务平台等文献类网站资源用户行为数据,图书馆网站门户用户数据和社交平台数据等。用户基本信息主要保存在关系型数据库中,属于结构化数据;图书馆门户网站用户数据可通过HTML中的标记区分抽取,属于半结构化的数据;文献类网站资源用户行为数据、社交平台数据以文本的形式存放,属于非结构化数据。用户画像数据采集需要将半结构化、非结构化的数据转化为结构化数据进行存储。
半结构化数据的抽取,常用的技术方法有基于知识图谱包装器的抽取和网络爬虫法等。基于知识图谱包装器的抽取方法在于包装器能够将数据从HTML网页中抽取出来,并将数据还原成结构化的数据[16];网络爬虫法利用常见的开源框架如python的Scrapy,java平台的WebMagic等,通过简单的配置完成爬虫规则的定义、爬取、清洗、去重、入库等操作,从而获取相关用户特征。目前免费网络爬虫软件八爪鱼采集器就是一款简单、可视化的网络爬虫工具。
非结构化数据的抽取可基于深度学习和日志挖掘法等。深度学习法通过构建文本分类、主题模型等机器学习模型获取文本的特征;日志挖掘法是对日志数据进行清洗、集成,对用户会话行为等进行数据预处理,得到结构化的数据文件,最后利用数据挖掘方法进行分析[17]。
对于文本类资源用户特征的提取主要包括专用名词或者有特定含义的名词短语,比如从文本语料库中抽取出的资源类别、时间信息、用户机构信息等。再者,对用户特征的提取需要考虑特征语义之间的关联性,比如A特征属于B特征的范围,B特征属于C特征的范围,那么A特征也属于C特征的范围,通过语义的分析挖掘,找出特征值之间的集合关系。第三,通过特征值的关联性分析,建立用户之间的关联度。随着时间等因素的改变,用户对资源的需求呈现动态变化过程,在这里要考虑时间衰减对于用户聚类的影响。对于跨媒体类用户特征的提取,例如对于视频、图像类用户特征的挖掘,主要采用人工智能的方法,将用户特征自动生成语义和逻辑合乎视觉内容的描述性文本,从而将视频、图像类用户特征按照文本类数据进行抽取。
3.2 标签体系的构建
用户画像可简单理解为是对海量数据进行分类的标签,根据用户的学历、学科背景,资源需求的差异,统计用户的标签特征,建立用户画像的标签体系,通过标签统计区分不同的用户群体。
标签的指标体系是建立用户画像的关键环节,从用户角度将标签分为基本属性、行为数据、社交属性、场景数据四个维度。但标签的一个重要功能就是用来统计分析,为此需要考虑标签的统计功能和规则功能,建立标签之间的关联度。画像标签的构建参照面向对象程序设计的思想,定义如下表2所示。
图书馆用户的标签体系按照结构化标签设计思路,将用户的数据维度分为两层标签结构。一级维度对应着数据类型(用户基本数据、用户行为数据、社交平台、场景数据),二级维度对应着相应的数据项。用户画像的标签体系如图2所示。
3.3 标签权重计算
标签体系的建立是按照层次结构进行构建的,可借助层次分析法对用户特征值进行权重计算。层次分析法(Analytic Hierarchy Process),简称AHP,是由美国匹兹堡大学教授萨蒂提出,是将决策问题有关的元素分解成目标、准则、方案等层次,在此基础上进行定性和定量分析,按照用户的数据资源类别建立递阶层次模型。例如某用户画像A为层次模型的目标用户,将准则层按照用户数据层次分为用户基本数据(B1)、用户行为数据(B2)、社交数据(B3)、场景数据(B4),相应的方案层为准则层对应的数据项。
3.3.1 准则层权重计算
用户画像A在准则层划分为B1-B4四个层次,通过判断矩阵对准则层之间的重要程度进行量化,判断矩阵采用1-9进行量化构建,通过构建同层次因素间的判断矩阵,计算出矩阵的最大特征值及特征向量。特征矩阵的构建根据图书馆资源整体使用情况和图书馆领域专家进行统筹考虑同层准则的重要性[18]。例如用户的图书借阅一般周期性较长,而用户对期刊论文的下载可能每天都在进行,那么可定义用户对期刊论文下载的量化较强重要于对图书的借阅。定义aij表示准则层bi与bj重要性的量化准侧如下:
若aij值为2,4,6,8,则表示相邻判断的中间值,aij值为相关值的倒数,则为bj相对bi重要性的量化准则。建立好准则层的两两对比矩阵,通过计算出矩阵的最大特征根λ和特征向量,采用几何平均法(方根法)或者规范列平均法,得到所求权重向量。
构建判断矩阵A=(aij)n×n,用aij表示第i个因素相对于第j个因素的比较结果。将矩阵A的各行向量进行几何平均法,然后进行归一化,即可得到各评价指标权重Wi和特征向量W。
AHP设定了C.I.(Consistency Index) 和R.I.(Random Index)两个判断是否满足一致性的参数。
其中C.I.(Consistency Index) = (λ为判断矩阵的最大特征根)。
R.I.为平均随机一致性指标,是关于矩阵维度n的离散函数,不同的n值对应不同的R.I.,从而避免了因为矩阵维度不同而出现的不一致问题。通过AHP的随机一致性比率C.R.(Consistency Ratio)来计算判断矩阵的一致性问题,其公式如下:
若C.R.<0.1,则满足研究要求。否则,需要对权重指标进行重新赋值,重新进行一致性检验,直到满足C.R.<0.1为止。
3.3.2 动态标签权重计算
层次分析法是将用户行为分为目标层,准则层和方案层,其中方案层即为准则层的数据项。由于用户在某一准则层上不同数据项有着不同的行为权重,因此将用户每一次的特征项(浏览、收藏、下载等)以对应的标签来表示,建立用户特征项与标签之间的映射关系。某用户同一标签出现的次数越多,说明该用户对该类标签资源利用率越高;如果该标签在全部用户标签体系中出现的次数越多,说明该标签的重要性降低。对用户与标签之间的权重分析可以采用TF-IDF来进行分析。
TF-IDF(Term Frequency-Inverse Document Frequency)是计算文档中词或者短语权值的方法。TF指的是一个给定的词语在该文档中出现的频率,IDF是对一个词语在整个文档中重要性的度量,表示某一个词语在整个文档集中出现的频率[19]。
假设Tm用来表示一个标签T被用于标记某个用户P的次数,TFm用来表示这个标签在所有标记用户P的标签中所占的比例,则公式表示如下:
TFm反映了用户P与标签T之间的关联关系,这个度量值越大说明用户T与该标签的关系越紧密。
IDF(P,T)用来表示标签T的的稀缺程度, 表示这个标签T在全体用户中所有标签出现的频率,则
。对于标签T来说,如果它在全体用户中出现的频率很低,但却用来标识用户P,那说明标签T与用户P之间的关联更加紧密。这样,利用TF-IDF得到用户P在某数据项上的标签T的权重为:
在分析用户与标签之间的关系时,时间是一个重要的上下文信息。随着时间的变化,用户对资源的需求也是在动态变化的,需要考虑随着时间的推移,用户对标签权重的衰减度。时间衰减是指随着时间的推移,用户的历史行为和当前行为的相关性不断减弱[20]。对于时间衰减度的函数模型,国内陈彬彬[21]等通过实验方法提出了如下公式:
其中T表示当前时间,T-t表示现在与学术行为发生的时间差,f(t)表示经过T-t衰减后的值,其取值为[0,1]。α表示衰减因子,其可通过回归计算得出。
综上,基于层次分析法和时间衰减的动态用户画像标签权重计算公式为:用户标签权重=准则层权重*时间衰减*TF-IDF计算标签权重。
3.4 画像的可视化
用户画像的标签体系可以标注用户一段时间内对资源的喜好程度,而可视化的图形方式可以将用户的标签体系以更加直观的形式展示出来。常见的统计图表、关系型数据库都可以进行数据的展示,采用易词云软件可对用户标签进行分析。易词云软件具有词频分析功能,通过对标签进行分析,生成词云数据,用可视化的形式直观的对用户的喜好进行表示。在易词云中,字体越大说明用户对该标签的活跃度高。反之,字体越小说明用户对该标签的活跃度低。
4 基于用户画像的精准图书推荐服务
图书馆传统图书推荐多采用读者对图书的借阅量、借阅图书类别来进行统计,设定某一个频次,将高于此频次的同类图书推荐给读者。此类方法简单易行,但对于从未借过图书或者很少借书的读者,无法收集读者的数据信息,在统计过程中存在冷启动,不能有效的对读者进行聚类。采用用户画像模型进行图书推荐服务可按照基于用户基本信息属性、用户社交属性、用户行为属性、用户场景属性四个层次,按照层次分析法确定权重。用户行为数据主要包含用户的借阅、瀏览、文献服务等,用户基本属性主要包含所学专业、所在学院信息等,用户社交属性主要包含用户在图书馆各类平台的互引、互赞等交互式操作等,场景信息主要指用户所在线下图书馆位置信息等。本文认为用户行为属性和用户基本属性较重要于用户社交属性、场景属性,因此依据层次分析法按照0.4、0.3、0.2、0.1对用户行为属性、基本属性、社交属性、场景属性赋予权重。用户画像可从以上四个维度对读者进行刻画,分别基于这四个维度采用TF-IDF进行权重计算,然后基于层次分析法和时间衰减的动态用户画像标签权重计算公式得到用户标签权重。
以用户行为属性为例,对于用户行为属性数据的获取可以通过OPAC系统、文献资源的下载、图书馆APP平台等,通过数据库管理系统或者Python网络爬虫开源框架Scrapy来获取读者特征。部分图书馆读者的原始特征数据如表3所示:
用户画像即对目标用户以标签的形式进行标识, 通过对标签与标签之间关联程度的分析,不仅可用来分析目标用户,还应该包含用户间的关联分析,即对用户进行聚类,从而建立群体用户画像。一个用户u1如果被打上标签A的同时又被打上标签B,如果在同一时间因素范围内,又有用户um,un被打上标签A与标签B,那我们就说标签A与标签B有相关性,即有共同的用户群体u1,um,un。
定义标签集合{A,B,…}同时被一个用户或者多个用户所标注,则称标签A、标签B、…构成共被标注关系。标签集合{A,B,…}的元素个数称之为共被标注强度,共被标注强度越大说明用户之间的相似度越高。被标注频率最高的标签其在所属用户群体中影响力越大,其余标签依次类似分析。基于此,可通过标签权重对用户进行聚类分析。在基于相似读者的图书推荐过程中,可基于余弦相似度函数来计算读者之间的相似度。
设标签集合T={T1,T2,T3 ……Tm},考虑到时间上下文的因素,在某段时间内通过TF-IDF计算标签权重,标签权重的取值范围为[0,1]。 n个用户的标签权重矩阵T为:
矩阵T的行向量表示用户un对标签集合的活跃度,通过使用余弦相似度函数来计算用户之间的相关性,设定用户um的标签权重向量为A,用户un的标签权重向量为B,sim(um,un)表示用户um,un,的相似度,则计算公式如下:
余弦相似度函数通过空间中两个向量夹角的余弦值来衡量相似度的大小,余弦值越接近于1,说明用户之间的相似性越大。反之,余弦值越接近于0,说明用户之间的相似度越小。通过用户之间相似度的计算来构建群体用户画像。
5 结语
本文从用户画像理论角度对图书馆数据驱动业务的发展做了阐述,对于提高图书馆服务的精准度具有一定的效能。模型以标签为载体,通过TF-IDF计算用户相关联标签的权重,构建个体用户画像。在此基础上,以图书馆图书推荐为案例,以标签为聚类数据项,采用余弦相似度的协同过滤算法将个体用户画像进行聚类,构建群体用户画像,实现了对用户群体的精准分类,图书馆按照不同的分类群体推荐不同的信息资源,实现精准推荐服务。基于用户画像的图书馆构建模型适用于精准知识推荐服务、个性化智慧服务、阅读推广活动、数字图书馆智慧社区构建等。模型充分考虑到了图书馆数据的采集、用户行为的分类、时间的衰减因素、场景因素等,但也存在对画像模型数据颗粒度的划分层次较粗放、缺乏反馈机制和用户的评价机制等不足之处。由于篇幅所限,对动态标签权重的计算方法介绍单一,没有考虑用户数据采集中的数据隐私保护等问题,有待今后进一步深化研究。
参考文献:
COOPER A. The inmates are running the asylum: why high-tech products drive us crazy and how to restore the sanity[M]. Sams Publishing, 2004.
TRAVIS D. E-commerce usability: tools and techniques to perfect the on-line experience[M].CRC Press,2002.
许鹏程,毕强. 数据驱动下数字图书馆用户画像模型构建[J].图书情报工作, 2019(3):30-37.
李丹,高建忠. 基于用户画像的图书馆推荐服务初探[J]. 图书馆,2019(7):066-071.
晁明娣. 面向图书馆精準服务的用户画像构建研究[J].图书馆学刊,2019(4):106-111.
宋美琦. 用户画像述评[J]. 情报科学. 2019(4):171-176.
王乐,倪维建,林泽东. 基于模型堆叠的上网行为日志用户画像方法[J]. 山东科技大学学报(自然学版).2018(5):70-77.
徐海玲. 基于概念格的高校图书馆群体用户兴趣画像研究[J]. 情报科学, 2019(9):153-158.
吴智勤. 基于社交网络的高校图书馆用户画像构建研究[J].图书馆学研究, 2018(16):26-30.
LEUNG K W T, LEE D L. Deriving concept-based user profiles from search engine logs[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(7): 969-982.
JOMSRI P. Book recommendation system for digital librarybased on user profiles by using association rule[C].//FourthInternational Conference on Innovative Computing Technology. IEEE,2014:130-134.
单晓红,张晓月,刘晓燕. 基于在线评论的用户画像研究:以携程酒店为例[J]. 情报理论与实践,2018,41(4):99-104,149.
李嘉兴,王晰巍,常颖. 基于移动终端日志的微信老年用户使用行为画像研究[ J ] . 图书情报工作, 2019(22):31-39.
林燕霞,谢湘生. 基于社会认同理论的微博群体用户画像[J]. 情报理论与实践,2018(3):142-148.
任中杰. 面向突发事件的网络用户画像情感分析[J].情报杂志,2019,38(11):126-133.
王昊奋,漆桂林. 知识图谱方法、实践与应用[M].北京:电子工业出版社. 2019:133-137.
王继民. 基于日志挖掘的移动搜索用户行为研究综述[J]. 情报理论与实践 ,2014(3):134-138.
姚远,张蕙. 基于本体的用户画像构建方法[J]. 计算机科学. 2018(10):226-232.
牛温佳,刘吉强,石川. 用户网络行为画像[M].北京:电子工业出版社,2016:100.
赵宏田. 用户画像方法论与工程化解决方案[M].北京:机械工业出版社,2020:114-115.
陈彬彬. 基于双语图书本体匹配的推荐系统的研究与实现[D].南京:东南大学,2016:25.
赵建建 中原工学院图书馆馆员。 河南郑州,450007。
(收稿日期:2020-10-12 编校:刘 明,左静远)
猜你喜欢
小太阳画报(2018年1期)2018-05-14
中国广播(2017年1期)2017-02-21
现代情报(2016年10期)2016-12-15
现代经济信息(2016年24期)2016-11-09
商(2016年27期)2016-10-17
电脑知识与技术(2016年7期)2016-05-19
小天使·一年级语数英综合(2014年8期)2014-06-26
