
基于双对抗机制的图像攻击算法
2021-11-18 02:18黄静琪贾西平陈道鑫柏柯嘉廖秀秀
计算机工程 2021年11期
黄静琪,贾西平,陈道鑫,柏柯嘉,廖秀秀
(广东技术师范大学计算机科学学院,广州 510665)
0 概述
深度学习是学习样本数据的内在规律和表示层次的算法,在学习过程中获得的信息对文字、图像和声音等数据的解释具有很大的帮助[1]。由于深度学习系统的训练过程和训练模型一般是封闭的,而训练数据集和预测数据需要与用户交互,因此容易受到未知恶意样本攻击[2]。如果在训练数据集中出现恶意样本,则称之为投毒攻击;如果在预测数据中出现恶意样本,则称之为对抗攻击[3]。对抗攻击利用对抗样本扰乱分类器的分类,使模型预测错误,从而破坏模型可用性。对抗样本是在原始样本中添加扰动而产生的,通过人类肉眼观看和原始样本基本没有区别。对抗攻击的难点在于攻击成功率和扰动之间的平衡。一般地,扰动越大,攻击成功率越高,但是攻击样本与原始样本的视觉差异越明显,反之亦然。
GOODFELLOW 等[4]提出快速梯度标志攻击(Fast Gradient Sign Method,FGSM)方法,通过在梯度方向上添加增量来产生扰动,然后对原始图像添加扰动生成对抗样本,使网络产生误分类。SU 等[5]提出基于差分进化生成单像素的对抗性扰动,目的是通过改变输入图像的一个像素值,达到在最小攻击信息的条件下对更多类型的网络进行欺骗。MOOSAVI-DEZFOOLI 等[6]设计对 于任意 给定的DNN 分类器都可实现图像攻击的扰动,生成的扰动仅与模型本身相关,具有较小的范数,在不改变图像本身结构的情况下,能使分类器以较大概率分类错误,从而实现对于DNN 的攻击,同时这些扰动对人类肉眼而言几乎不可察觉。SZEGEDY 等[7]将神经网络做出误分类的最小扰动求解方程转化成凸优化过程,寻找最小损失函数的添加项,使得对图像添加小量的人类察觉不到的扰动,便可达到误导神经网络分类的效果。XIAO 等[8]等提出一种通过学习来逼近原始实例的分布和生成对抗实例的AdvGAN 算法。一旦生成器训练完成,该算法就可以有效地使用所有原始实例来产生对抗性干扰实例,从而潜在地促进防御的对抗性训练。AdvGAN 攻击算法在公共MNIST 攻击挑战中获得第一名,加速了对抗样本的产生,生成的样本更加自然[9],并且受到了研究人员的广泛关注。
针对图像攻击,可以构建鲁棒的分类器或者防御模型,使其在输入攻击图像时也能实现分类正确。防御模型基本原理分为两种:一种是从分类器本身出发进行防御,即训练更加鲁棒的分类器;另一种是对输入的攻击图像做一定的预处理后再传给分类器,目的是尽可能减少攻击噪声。DZIUGAITE 等[10]通过图像压缩技术去除图像攻击所添加的抽象扰动,将图像复原为没有扰动的图像,从而达到防御效果。通过实验发现,该方法在少量扰动的情况下,防御效果较好,但随着扰动的增加,难以解决神经网络的安全风险问题。LUO 等[11]提出一种基于中央凹机制的防御方法来防御生成的对抗扰动。ROSS等[12]使用输入梯度正则化训练模型,使其具有平滑的输入梯度和较少的极值,同时对预测分布与真实分布之间散度的敏感性进行适当惩罚,这样小的对抗扰动就不会对输出具有显著影响,提高了对抗攻击鲁棒性。LI 等[13]用变分 自编码 器(Variational Auto-Encoder,VAE)训练模型,通过对实例压缩来提取符合分布的数据特征,然后根据数据特征进行解压缩还原成实例。在压缩和解压缩过程中,VAE 能够过滤许多扰动信息,实现对攻击的防御。DUBEY等[14]假设对抗性扰动使图像远离图像流形,通过对包含大量图像的海量数据库的最近邻搜索,建立一种针对对抗图像的成功防御机制,使图像近似投射回图像流形。LIU 等[15]提出一种基于感知哈希的防御方法,通过比较图像的相似性来破坏扰动产生过程,从而达到防御目的。基于卷积稀疏编码,SUN等[16]在输入图像和神经网络的第一层之间引入稀疏变换层,并构造一个分层的准自然图像空间。该空间逼近自然图像空间,同时消除了对抗性扰动。吴立人等[17]在基于动量的梯度迭代攻击算法[18]的基础上,加入动量因子,使攻击在损失函数的梯度方向上快速迭代,稳定更新,有效地避免了局部最优。
现有图像攻击算法多数较为脆弱,只要对攻击图像做适当处理,就能使攻击模型的攻击性能大幅下降,导致图像攻击失效[19]。本文在AdvGAN 算法的基础上,针对现有图像攻击在VAE 防御下攻击不稳定的问题,提出AntiVAEGAN 算法,以生成对抗网络的训练方式,训练得到一种抵抗VAE 防御的AntiVAEGAN 模型。在AntiVAEGAN 算法的基础上,进一步提出改进的对抗攻击算法VAEAdvGAN,以解决防御能力提升时攻击不稳定的问题。
1 抵抗VAE防御的对抗攻击算法AntiVAEGAN
1.1 AntiVAEGAN 算法原理
AntiVAEGAN 算法结构如图1 所示,主要由以下部分组成:
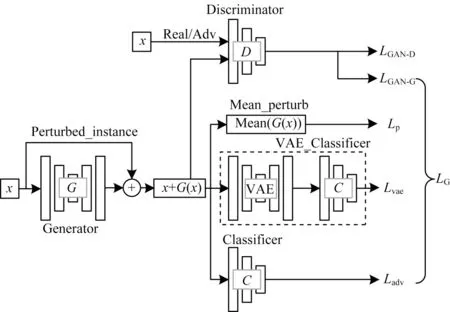
图1 AntiVAEGAN 算法结构Fig.1 Structure of AntiVAEGAN algorithm
1)生成器G。G的主要作用是根据输入原始实例x,生成一个扰动G(x),添加到实例x上,组成攻击图像x′(x′=x+G(x))。
2)鉴别器D。D的主要作用是判别输入的数据是生成的攻击图像还是原始图像,将x+G(x)和x输入到鉴别器进行判别训练。鉴别器有助于促进生成器生成与原始图像无法区分的攻击图像。
3)被攻击的图像分类模型C。C代表实验中被攻击的图像分类模型。
4)VAE 防御模 型Origin_vae。Origin_vae 的 主要作用是对输入数据进行特征提纯处理。输入数据经过Origin_vae 模型编码和解码处理后会过滤掉大部分扰动,留下原始图像特征。引入Origin_vae有助于促进生成器生成具备反VAE 防御的攻击实例。
5)图像分类模型VAE_Classifier。输入数据经过Origin_vae处理后,输入到图像分类模型Classifier,从而达到防御效果。
6)计算扰动均值的Mean_perturb。Mean_perturb用于计算生成扰动G(x)的均值并度量生成攻击图像的隐蔽性。
鉴别器D的目标是区分原始实例x和生成实例:

原始实例x是真实数据集下的一个样本,区分原始实例和生成实例有助于生成器生成与原始实例接近的攻击实例。
假设D(x)和D()分别表示鉴别器鉴别原始数据和生成数据的预测值,Pt和Pf分别表示数据判别为真和假的标签,则二分类交叉熵损失函数表示如下:
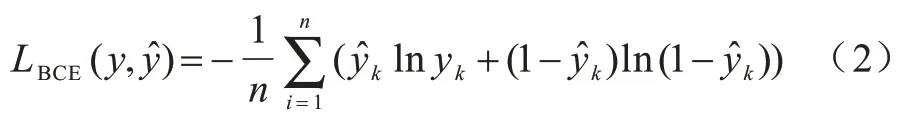
对抗神经网络的损失函数可用式(3)和式(4)表示,它们的作用分别是反向传播优化鉴别器和生成器。
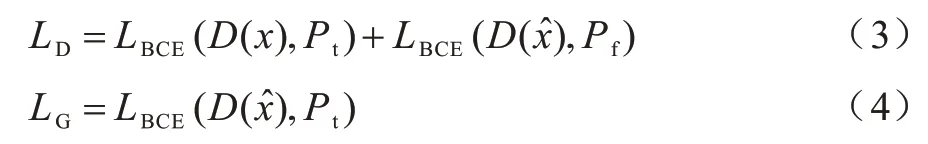
将x+G(x)输入图像分类模型Classifier 后,用r表示Classifier 正确分类的概率,o表示除r之外其他类中最大的概率。欺骗图像分类模型Classifier 的损失函数表示如下:

其 中:Ld=r-o;max(0,Ld)>0 表示攻 击失败,max(0,Ld)=0 表示攻击成功。因此,Ladv有助于生成器生成能够欺骗图像分类模型的扰动图像。
在x+G(x)输入Origin_vae 后,将其输出作为图像分类模型Classifier 的输入,vvae_r表示图像分类模型Classifier 输出的概率分布中正确分类的概率,vvae_o表示除vaer以外其他类中最大的概率。Origin_vae模型的损失函数表示如下:
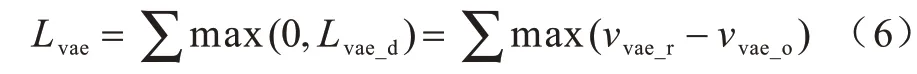
其中:max(0,Lvae_d)>0 表示攻击失败,max(0,Lvae_d)=0表示攻击成功。因此,Lvae有助于生成器生成能够抵抗防御的扰动图像。
G(x)扰动的均值损失函数表示如下:

假设LG代表Ladv、Lvae、Lp线性汇总的损失函数,α、β、λ表示权重,使用LG损失函数进行反向传播,优化生成器。LG损失函表示如下:

1.2 AntiVAEGAN 算法流程
AntiVAEGAN 算法流程如图2 所示,其中,j表示第j轮迭代,i表示第i张图像,m表示数据集中用于训练的图像总数;n表示模型训练的最大迭代次数。具体步骤如下:
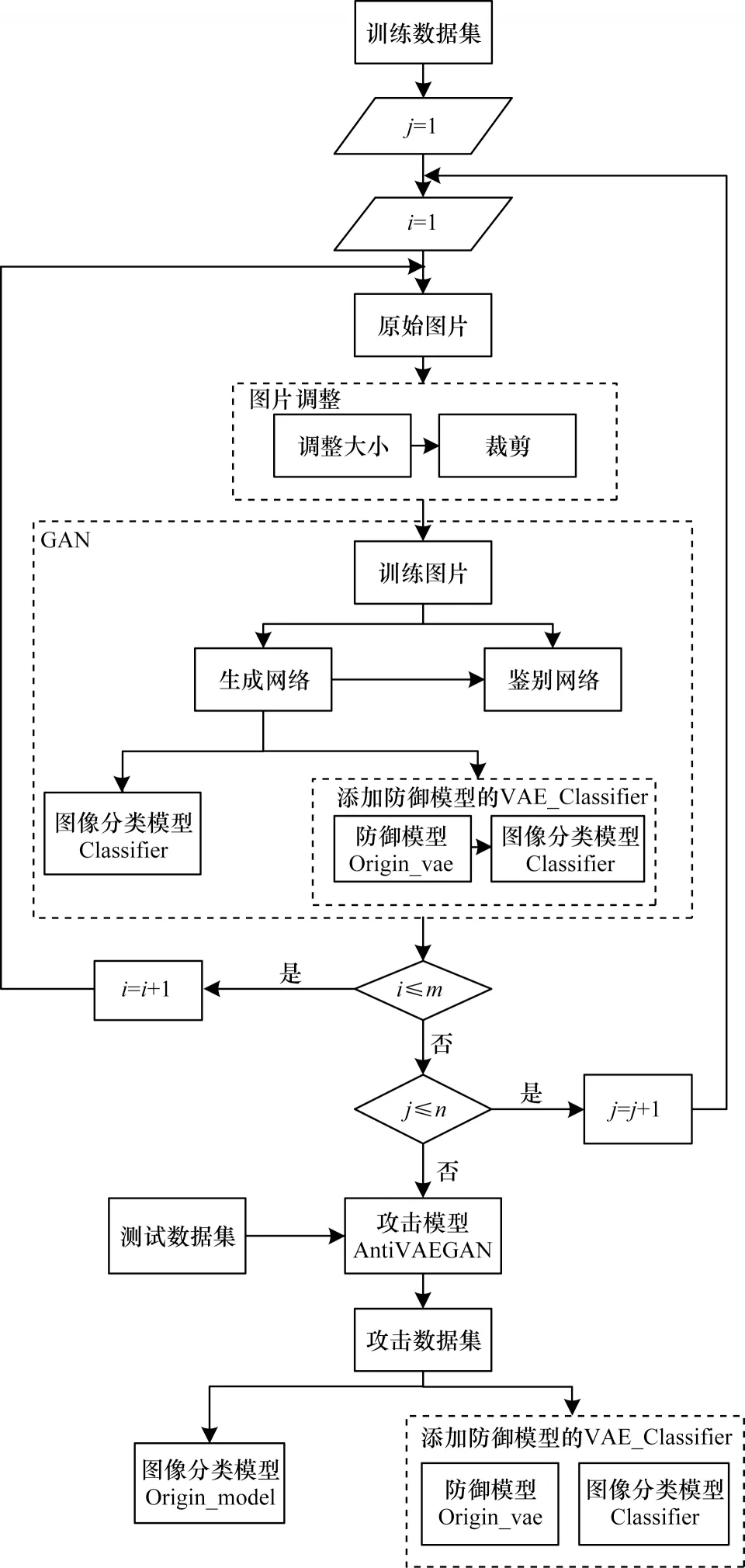
图2 AntiVAEGAN 算法流程Fig.2 Procedure of AntiVAEGAN algorithm
步骤1通过对原始图像进行大小调整和中心裁剪,得到统一大小的训练图像。
步骤2建立生成网络,将训练图像输入生成网络,生成攻击图像。
步骤3建立判别网络,与生成网络形成Gener‐ator-Discriminator 对抗训练。将训练图像和攻击图像输入判别网络进行判别,将判别损失结果用于优化生成网络和判别网络。
步骤4建立图像分类模型Classifier,建立Classifier 与Origin_vae 防御模型的组合图像分类模型VAE_Classifier,将生成网络生成攻击图像分别输入这两个模型,将攻击损失结果用于优化生成网络。
步骤5将以上步骤进行多次迭代,利用Gener‐ator-Discriminator 对抗训练方法训练生成网络,训练得到AntiVAEGAN 攻击模型。
步骤6在攻击模型中输入测试数据集,将生成的攻击数据集分别攻击图像分类模型和添加防御模型的图像分类模型,统计实验数据。
1.3 AntiVAEGAN 算法评价
利用攻击数据集中的样本对图像分类模型进行攻击,统计图像分类模型正确分类的样本数目,进而计算图像分类准确率和攻击成功率。
图像分类准确率指模型正确分类的样本数占攻击数据集样本总数的比例maccuracy,计算公式如下:

其中:mnum表示模型正确分类数;dnum表示攻击数据集样本总数。
攻击成功率指模型错误分类的样本数占攻击数据集样本总数的比例asuccess_rate,计算公式如下:

2 改进的对抗攻击算法VAEAdvGAN
2.1 VAEAdvGAN 算法原理
VAEAdvGAN 算法借鉴GAN 对抗训练结构,衍生出另一个对抗模型——生成器和VAE 防御模型的对抗模型,以Generator-Discriminator 与Generator-VAE 双对抗结构进行训练,从而对抗提升防御模型的防御能力与攻击模型的攻击能力。VAEAdvGAN算法结构如图3所示。VAEAdvGAN 算法在AntiVAEGAN 算法的基础上,添加了Further_vae 防御模型,用于与生成器对抗训练,动态提升Further_vae 的防御能力。

图3 VAEAdvGAN 算法结构Fig.3 Structure of AVEAdvGAN algorithm
对抗训练Generator-VAE 的损失函数表示如下:

2.2 VAEAdvGAN 算法流程
VAEAdvGAN算法流程如图4所示,具体步骤如下:
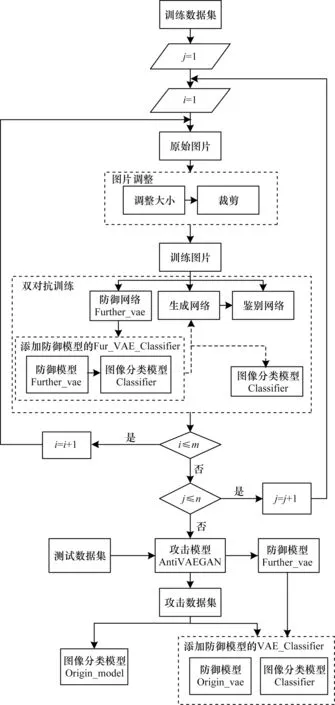
图4 VAEAdvGAN 算法流程Fig.4 Procedure of VAEAdvGAN algorithm
步骤1通过对原始图像进行大小调整和中心裁剪,得到统一大小的训练图像。
步骤2建立生成网络与防御网络Further_vae,使用AntiVAEGAN 攻击模型和Origin_vae 防御模型分别对生成网络和防御网络进行初始化。
步骤3将训练图像输入生成网络,生成攻击图像。
步骤4建立判别网络,对训练图像和攻击图像进行判别,与生成网络形成对抗训练,将判别损失结果用于优化生成网络和判别网络。
步骤5将训练图像和攻击图像输入Further_vae防御网络,与生成网络形成对抗训练,将防御损失用于优化防御网络。
步骤6建立图像分类模型Classifier以及Classifier与Further_vae 防御模型的组合图像分类模型Fur_VAE_Classifier,将生成网络生成的攻击图像分别输入这两个模型,将攻击损失结果用于优化生成网络。
步骤7通过以上步骤,以生成器与鉴别器、生成器与VAE 双对抗训练方法训练生成网络,以生成器与VAE 对抗训练方法训练防御网络,训练得到攻击模型VAEAdvGAN 和防御模型Further_vae。
步骤8在攻击模型中输入测试数据集,将生成的攻击数据集分别攻击图像分类模型和添加防御模型的图像分类模型,统计实验数据。
3 实验结果与分析
3.1 实验环境和数据集
实验硬件环境为64 位Linux 操作系统、16 GB 内存、Intel i7-7800X CPU、3.5 GHz×12 主频、GeForce GTX 1080 Ti GPU。系统运行于PyTorch 0.4 深度学习框架,使用Python 3.6 版本。
实验数据集包括28像素×28像素的黑白MNIST数据集[20]和32 像素×32 像素的彩色GTSRB 数据集[21]。MNIST 数据集的训练集有50 000 张图像,由250 个不同人手写的数字构成,测试集有10 000 张图像,使用具有4 层卷积层的10 分类神经网络作为图像分类模型。GTSRB 数据集是一个德国交通标志检测数据集,包含43 种交通信号,训练集有39 209 张图像,测试集有12 630 张图像,使用vgg16[22]作为图像分类模型。
3.2 实验效果对比
图5和图6分别是使用AntiVAEGAN和VAEAdvGAN攻击模型对MNIST 数据集的攻击效果。图7 和图8 分别是使用AntiVAEGAN 和VAEAdvGAN 攻击模型对GTSRB 数据集的攻击效果。由上述结果可以看出,原始交通标志图像遭到攻击后,图像中出现了一定的干扰信息,但这些干扰信息基本不影响人眼对标志的判别,但却能成功欺骗分类网络。另外,与AntiVAEGAN算法相比,VAEAdvGAN 算法产生的干扰信息看起来更为复杂。

图5 AntiVAEGAN 对MNIST 数据集的攻击效果Fig.5 Attack effects of AntiVAEGAN on MNIST dataset

图6 VAEAdvGAN 对MNIST 数据集的攻击效果Fig.6 Attack effects of VAEAdvGAN on MNIST dataset

图7 AntiVAEGAN 对GTSRB 数据集的攻击效果Fig.7 Attack effects of AntiVAEGAN on GTSRB dataset

图8 VAEAdvGAN 对GTSRB 数据集的攻击效果Fig.8 Attack effects of VAEAdvGAN on GTSRB dataset
3.3 分类准确率对比
使用M1 表示MNIST 数据集的图像分类模型,M2 表示M1 与Origin_vae 防御模型的组合图像分类模型,M3 表示M1 与Further_VAE 结合的图像分类模型。MNIST 数据集分别在无攻击、FGSM[4]攻击、AdvGAN 攻击、AntiVAEGAN 攻击、VAEAdvGAN 攻击后的分类准确率对比如表1 所示。由表1 可以看出,M1 图像分类模型在FGSM 攻击下分类准确率下降到 27.96%,而在AdvGAN、AntiVAEGAN 和VAEAdvGAN 攻击下分类准确率明显下降,从无攻击的99.00%降到不到4.00%,表明FGSM 攻击算法效果一般,而其他3 种攻击算法效果较好。对M2 图像分类模型,无攻击的分类准确率为98.00%,AdvGAN 攻击效果不佳,攻击后分类准确率下降不明显,为19.35 个百分点,FGSM 攻击有一定效果,分类准确率下降了69.68 个百分点,AntiVAEGAN 和VAEAdvGAN 攻击效果非常明显,分类准确率大幅下降。对M3 图像分类模型,AdvGAN 攻击效果非常差,AntiVAEGAN 攻击效果也一般,而VAEAdvGAN和FGSM 攻击使得分类准确率下降较多,攻击效果较好。
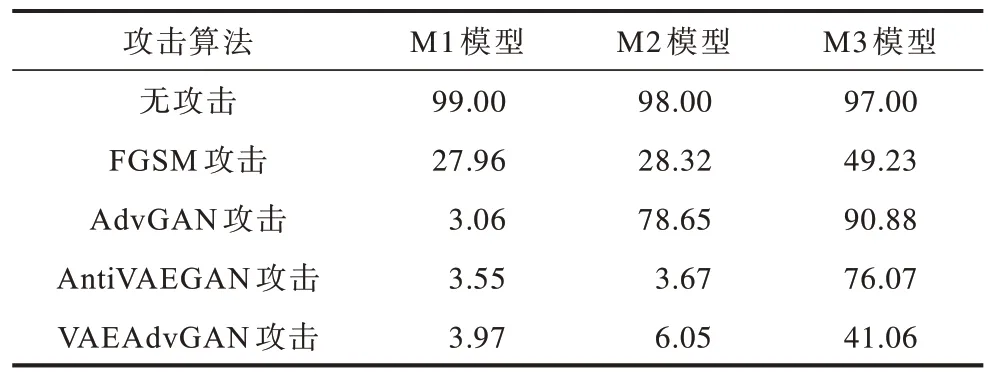
表1 MNIST 数据集分类准确率对比Table 1 Comparison of classification accuracy of MNIST dataset %
使用G1 表示GTSRB 数据集的图像分类模型,G2表示G1 与Origin_vae 防御模型的组合图像分类模型,G3 表示M1 与Further_VAE 结合的图像分类模型。GTSRB 数据集分别在无攻击、FGSM 攻击、AdvGAN 攻击、AntiVAEGAN 攻击、VAEAdvGAN 攻击后的分类准确率对比如表2 所示。由表2 可以看出,G1 图像分类模型在各种攻击下的分类准确率都明显下降,其中FGSM攻击效果最差,而AntiVAEGAN 和VAEAdvGAN 攻击效果较好。对G2 图像分类模型,无攻击的分类准确率为79.52%,AdvGAN 攻击效果最差,VAEAdvGAN 和FGSM 攻击效果次之,AntiVAEGAN 攻击效果最好。对G3 图像分类模型,AdvGAN 攻击效果很差,AntiVAEGAN 攻击效果也一般,而FGSM 和VAEAdvGAN 攻击使得分类准确率下降最多,攻击效果较好。
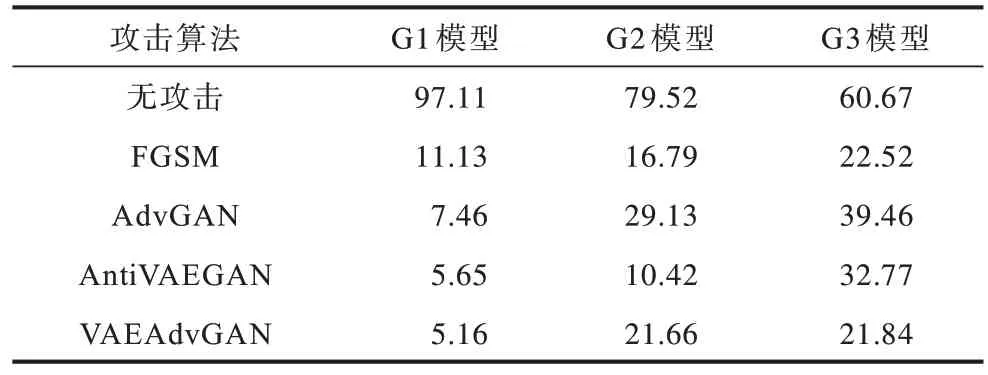
表2 GTSRB 数据集分类准确率对比Table 2 Comparison of classification accuracy of GTSRB dataset %
3.4 攻击成功率对比
MNIST 数据集分别在FGSM 攻击、AdvGAN 攻击、AntiVAEGAN 攻击、VAEAdvGAN 攻击后的攻击成功率对比如表3 所示。由表3 可以看出,FGSM 对M1 和M2图像分类模型的攻击成功率都在89%以上,但对M3分类模型的攻击成功率一般,只有42.73%。AdvGAN对M1 图像分类模型的攻击成功率为96.94%,但对M2图像分类模型的攻击成功率仅为21.35%,对M3 图像分类模型的攻击成功率更低,低至9.12%。这表明AdvGAN 的攻击不稳定,在VAE 防御模型的防御下,AdvGAN 的攻击被大幅抵消。AntiVAEGAN 对M1 图像分类模型的攻击成功率为96.45%,与AdvGAN 的攻击成功率仅相差0.49 个百分点,但对M2 图像分类模型的攻击成功率高达96.33%,是AdvGAN 攻击成功率的4 倍多,攻击效果明显更好。AntiVAEGAN 对M3 图像分类模型的攻击成功率也较差,仅为23.93%,但比AdvGAN 的9.12%好。VAEAdvGAN 对M1 图像分类模型的攻击成功率为96.03%,与AdvGAN 和AntiVAEGAN 相差不多,对M2 图像分类模型的攻击成功率为93.95%,比AntiVAEGAN 的攻击成功率低了2.38 个百分点,但仍远高于AdvGAN 的21.35%,对M3图像分类模型的攻击成功率为58.94%,是AntiVAEGAN的2 倍多。
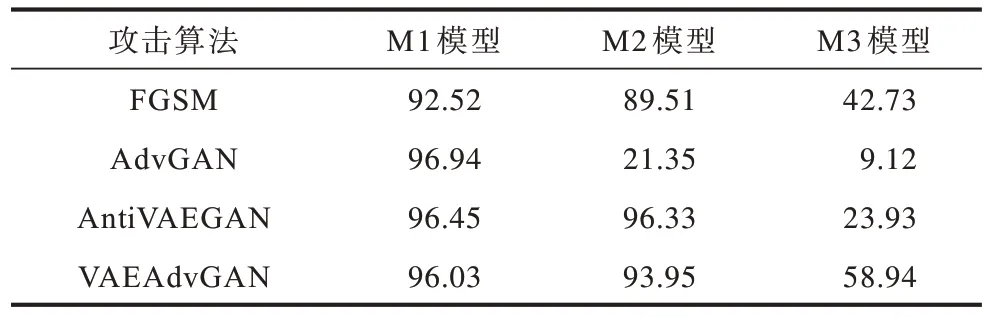
表3 MNIST 数据集攻击成功率对比Table 3 Comparison of attack success rate of MNIST dataset %
GTSRB数据集分别在FGSM 攻击、AdvGAN攻击、AntiVAEGAN 攻击、VAEAdvGAN 攻击后的攻击成功率对比如表4 所示。由表4 可以看出,对G1 图像分类模型,FGSM、AdvGAN、AntiVAEGAN、VAEAdvGAN的攻击成功率分别为89.51%、92.54%、94.35%、94.84%,AntiVAEGAN 和VAEAdvGAN 的攻击成功率高于AdvGAN,更高于FGSM。对G2 和G3 图像分类模型,FGSM 和AdvGAN 的攻击成功率都明显低于AntiVAEGAN 和VAEAdvGAN,AntiVAEGAN 的攻击成功率更高。对G3 图像分类模型,AdvGAN 攻击成功率最低,FGSM 和AntiVAEGAN 的攻击成功率差不多,VAEAdvGAN 的攻击成功率最高。
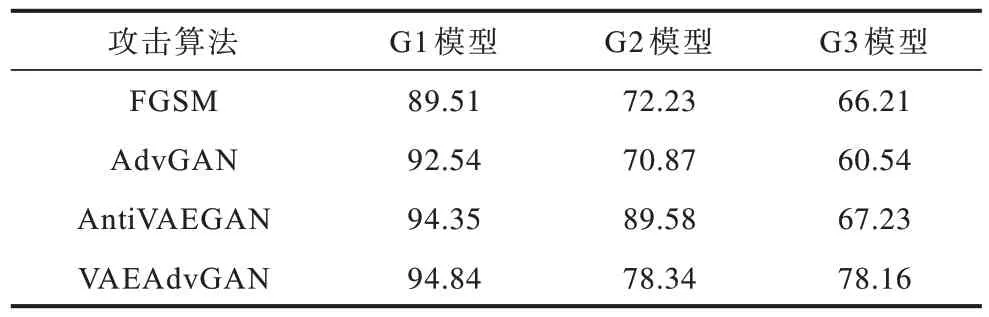
表4 GTSRB 数据集攻击成功率对比Table 4 Comparison of attack success rate on GTSRB dataset %
综合以上实验数据可以看出,在无防御的情况下(如M1 和G1 图像分 类模型),AntiVAEGAN 和VAEAdvGAN 几乎能达到和AdvGAN、FGSM 一样的攻击效果。在VAE 防御下,AdvGAN 攻击成功率大幅下降,但AntiVAEGAN 攻击仍然相对稳定,攻击效果比AdvGAN 更好。这说明AntiVAEGAN 能成功攻击具有VAE防御的分类器,攻击成功率较高,攻击性能更稳定,鲁棒性更强。Further_vae 防御模型通过对抗训练,提升了防御能力,随着Further_vae 模型防御能力的提升,对抗促进了VAEAdvGAN 攻击模型攻击能力的进一步提升。因此,VAEAdvGAN 攻击效果比AdvGAN 更好,且在大部分情况下优于AntiVAEGAN。
4 结束语
本文为解决现有图像攻击算法在VAE 防御下攻击效果不稳定的问题,提出AntiVAEGAN 算法,利用生成对抗网络训练的方式训练得到一种抵抗VAE 防御的AntiVAEGAN 模型。针对防御模型防御能力提升时攻击效果不稳定的问题,进一步提出VAEAdvGAN 算法,以生成器与鉴别器、生成器与VAE 双对抗训练的方式训练得到VAEAdvGAN 模型。在不同数据集上的实验结果表明,本文提出的图像攻击算法提高了图像攻击的鲁棒性和成功率。但由于图像攻击算法生成的扰动不够隐蔽,后续将对此做进一步优化,在保证算法攻击成功率与鲁棒性的同时,尽可能提升攻击隐蔽性。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
当代水产(2022年6期)2022-06-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
中国生殖健康(2020年8期)2021-01-18
数学物理学报(2019年4期)2019-10-10
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国生殖健康(2018年3期)2018-11-06
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
贵州师范学院学报(2016年3期)2016-12-01
