
基于评论文本图表示学习的推荐算法
2021-11-18 02:18杨粟森张举勇
计算机工程 2021年11期
杨粟森,刘 勇,张举勇
(1.中国科学技术大学 数学科学学院,合肥 230000;2.南洋理工大学及英属哥伦比亚大学百合卓越联合研究中心,新加坡 639798)
0 概述
随着网络信息量的爆炸式增长,推荐系统在诸如电商平台、在线多媒体平台等场景中发挥着越来越重要的作用。推荐系统通过分析用户过往的购买或观看行为,推断用户的喜好并为他们推荐感兴趣的项目。传统推荐算法[1]的性能受限于用户行为的稀疏度,针对这一问题,各种辅助信息被引入到推荐系统中。评论文本作为一种重要的辅助信息,能够描述用户对项目在不同方面的兴趣爱好。
目前,基于评论文本的推荐方法主要包括基于主题建模的方法[2-4]和基于深度学习(如卷积神经网络、循环神经网络)的方法[5-7],尽管这些方法已经取得了一定的性能提升,但是仍然存在一些局限。基于主题建模的方法仅能捕捉全局水平的文本语义信息,忽略了文本中重要词序和词的上下文信息;基于深度学习的方法虽然可以有效捕捉相邻词的上下文信息,但是在捕捉词与词之间长期、全局和非连续的依赖关系时存在一定的局限性。例如,对用户在多条评论中出现的同一个词而言,无法同时考虑到这个词在不同评论中的相邻词信息(全局和非连续依赖)。除此之外,近年来出现的基于注意力机制的方法[8-10]对评论文本中每个词、句子或者评论赋予重要性权重,但是该类方法只考虑用户或者项目侧的单一静态喜好,无法捕捉交互水平的喜好特性。例如,对于用户的“运行速度快”这一评论,在预测用户对平板电脑的评分时的重要性程度高于预测同一用户对鼠标的评分时的重要性程度。
针对上述问题,本文提出基于评论文本图表示学习的推荐算法RGP。将每个用户或项目的所有评论集构建成一个评论图,图中的节点为评论中的词,边为词与词之间的共现和词序关系。通过图的拓扑结构来捕捉评论文本中词与词之间长期、全局和非连续的依赖关系。使用基于连接关系的图注意力网络聚合每个节点的邻接点信息,同时考虑词序关系。在此基础上,使用基于交互关系的注意力机制加权融合图中所有节点的表征,得到最终的图表征。将用户和项目ID 的嵌入表征以及其评论图表征耦合输入并采用因子分解机(Factorization Machine,FM)[11]进行评分预测。
1 相关工作
1.1 基于评论文本和主题建模的推荐方法
基于文本主题建模的方法对评论文本应用主题建模技术学习用户和项目的潜在特征分布。文献[2]提出HFT 模型,通过LDA 主题模型[12]从评论文本中学习用户和项目的特征表示。文献[13]将主题模型和混合高斯模型相结合,提高推荐精度。文献[14]利用非负矩阵分解法导出评论文本的主题分布,并使用转换函数将主题分布和相应的用户或项目的潜在特征因子对齐。文献[3]提出一种将评论文本与用户喜好相结合的评分提升方法,该方法能获得更准确的主题分布。
1.2 基于评论文本和深度学习的推荐方法
深度学习的快速发展推动了其在基于评论文本的推荐模型中的应用。文献[15]使用堆叠的去噪自编码器(SDAE)学习评论文本的深度特征,并利用概率矩阵分解预测评分,SDAE 使得模型拥有自适应学习特征的能力,但其未考虑文本中的词序和局部相关性。文献[5]提出DeepCoNN 模型,利用卷积神经网络从评论文本中提取语义信息,使用因子分解机捕捉用户和项目表征之间的交互信息,卷积神经网络可以在提取文本特征时考虑词与词的先后顺序和相关性,但是其不具备对文本更细粒度的特征融合和可解释性。
近年来,研究人员使用注意力机制来进一步提高推荐的准确性。文献[7]通过联合矩阵分解和基于注意力机制的门控循环网络(GRU),从评论和评分中学习用户和项目的表征,在捕捉词序的同时使用注意力机制提高了模型的可解释性。文献[8]在DeepCoNN 的基础上,通过注意力机制对每个评论进行评分,从而学习更丰富和更细粒度的语义信息。但是,上述2 种模型在提取文本特征时都仅考虑用户或项目单一侧的文本信息,并未在交互水平上捕捉用户和项目的相关性。为此,文献[16]提出CARL 模型,其综合考虑用户和项目的评论,通过注意力机制来重点关注用户和项目之间更相关的评论内容。文献[17]提出基于对偶的交互注意力机制,以捕捉用户和项目评论的相关性,但其忽略了句子层面的细粒度信息和用户的个性化喜好。为了捕捉更细粒度的语义,文献[18]应用3 个注意力网络依次学习句子、评论和用户与项目的表征。为了考虑用户或项目本身的个性化喜好,文献[10]应用基于用户/项目的注意力机制从评论文本中学习用户/项目的个性化表征,但其缺乏对交互水平喜好特性的捕捉。除此之外,一些基于评论特性(aspect)的推荐方法[19-21]近年来被提出,这些方法通过应用基于特性的表示学习来自动检测评论的不同特性,联合学习特性、用户与项目的表征。
不同于上述基于深度学习的推荐方法,本文借助图表示的优良性质,将每个用户或项目包含的全部评论表示成一个图,以更好地挖掘词与词之间的依赖关系,从而进行更精确的评分预测和项目推荐。
2 基于评论文本图表示学习的推荐模型
本文基于评论文本图表示学习的推荐算法RGP 网络结构如图1 所示,其包含3 个模块:用户模块(图1 的左两列);项目模块(图1 的右两列);基于FM 的预测模块。用户模块和项目模块网络架构相同,分别用来学习用户和项目表征,预测模块以用户和项目表征为输入,计算用户对项目的评分。

图1 RGP 算法网络结构Fig.1 RGP algorithm network structure
用户(项目)模块包含3 个组成部分:构建评论文本图的部分将每个用户(项目)的评论文本集构建成一个图;图表示学习部分应用基于连接关系的图注意力网络和基于交互关系的注意力机制提取整个图的表征;表征融合部分耦合用户(项目)ID 的嵌入表征及其图表征得到最终用户(项目)的表征。用户模块及项目模块的网络架构相同,下文只介绍用户模块的各部分细节。
2.1 评论文本图构建
本文利用文献[22]的方法构建评论文本图,在评论文本中若2 个词共同出现在大小为ω的窗口中(即2 个词的距离小于ω),则连接这2 个词,本文在此基础上保存词序信息。对用户u的评论文本集Su,首先使用诸如句子分词、介词清理的文本预处理技术挑选Su中每条评论的关键词;然后将所有评论构建成一个有向图,图中的节点为评论文本的关键词,图中的边描述了词与词之间在一个固定大小为ω的滑动窗口内的共现关系。
评论文本的词序关系在反映文本语义时显得十分重要。例如,“不是非常好”和“非常不好”传递了不同水平的消极情绪。为在图中保留词序信息,本文定义前向关系ef、后向关系eb、自连接关系es这3 种类型的连接关系。以评论集Su中的一条评论为例,若挑选的关键词(即节点)x2在中出现在关键词x1前,并且x2和x1的距离在原评论中小于ω,则在图中建立从x2到x1的一条边E(x2,x1),此边的连接关系为ef。同时,建立从x1到x2的一条边E(x1,x2),此边的连接关系为eb。若x2在x1前面和后面同时出现(较少见),则将边的连接关系随机设置为ef或eb。此外,为考虑词本身的信息,图中的每个节点增加一条连接到自身的边(例如E(x1,x1))并将其连接关系定义为es。图2 展示了将评论“朋友喜欢这个好看耐用的鼠标”构建成图的例子,评论中“朋友”“喜欢”“好看”“耐用”“鼠标”均被挑选成关键词,“这个”词被去除,并将窗口大小ω设置成3,关键词“好看”在评论中和3 个关键词(“喜欢”“耐用”“鼠标”)的距离小于3,则建立3 条双向边并根据词序定义边的类型。以此类推,构建评论文本图。

图2 评论文本图示例Fig.2 Review text graph example
对用户u,本文用Gu={Xu,Eu}表示其对应的评论文本图,Xu为节点(即关键词)集,Eu为节点-边-节点的三元组集(xh,r,xt),r为节点xh到xt的连接关系(上述3 种关系之一)。通过同样的方式可以构建项目i的评论文本图Gi={Xi,Ei}。
2.2 图表示学习
2.2.1 嵌入层
用户ID、项目ID、词ID、连接关系ID 作为嵌入层的输入,分别被映射到不同的嵌入空间,得到对应的低维嵌入特征。本文分别用表示用户u、项目i、词x、连接关系r的低维嵌入特征,其中,d0为嵌入空间的向量维数。
2.2.2 基于连接关系的图注意力网络
在评论文本中,词的信息并不独立,一个词的语义信息可以被其周围的词所丰富。为了聚合邻接词的信息,本文提出基于连接关系的图注意力网络。假设输入图为Gu={Xu,Eu},对于图中的节点xh,用Nh={xt|(xh,r,xt)∈Eu}表示xh的邻接点,其中Nh包含xh本身。假设当前处于图注意力网络的第l层,邻接点xt的重要性权重计算方式为:

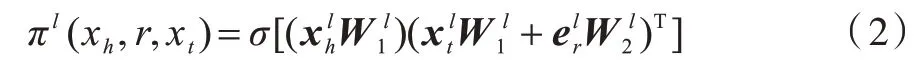
重要性权重描述了邻接点的重要程度,根据此权重,融合邻接点的向量表征,得到xh的输出向量表征为:
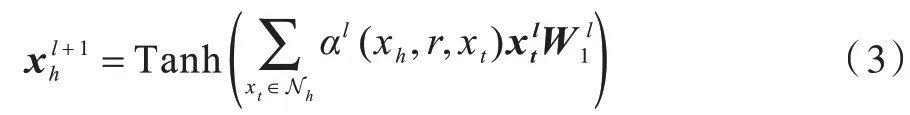
其中:Tanh 为激活函数。通过堆叠多层图注意力网络,传播式地捕捉评论文本中词与词的长期依赖关系。假设堆叠层数为L,可得到对应L个xh的输出向量表征为
2.2.3 基于交互关系的注意力机制
当图Gu的所有节点经过L层基于连接关系的图注意力网络后,本文提出基于交互关系的图注意力机制,聚合节点表征得到整个图的表征。该注意力机制根据用户u和项目i的信息,为图中的每个节点赋予交互水平的重要性权重。假设对上述第l层的图注意力网络的输出节点表征进行聚合,节点xh权重的计算方式为:
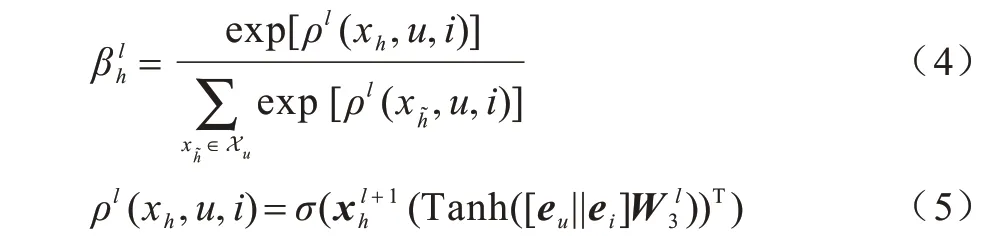

2.2.4 表征融合
为提高模型的表达能力,首先对基于用户ID 的低维嵌入特征eu应用一层非线性变换:

按照同样的流程,可以得到项目i的最终表征qi。
2.3 评分预测
本文使用因子分解机计算用户对项目的评分。首先拼接用户和项目的最终表征:

其中:b0、bu、bi分别为全局偏差、用户偏差、项目偏差量;w∈R1×d′为权重向量,且d'=2(L+1)d1;vn、vm∈R1×k为对应于z的第n维、第m维元素的潜在因子向量;zn为z第n维元素的值;<∙>为内积操作。
为学习整个模型的参数Θ,本文定义模型的损失函数如下:

其中:λ为正则化系数。整个模型可以通过端对端的后向传播算法进行高效训练。
2.4 算法流程
RGP 算法流程如下:
算法1RGP 算法
Vanavanan等[15]对年龄为30~79岁无心血管疾病史的一般人群,进行了一项为期11.7年的前瞻性研究,结果显示随着sdLDL的四分位分组增高,其心血管疾病风险也随着增加。

2.5 算法时间复杂度
假设每个用户或项目的评论文本所挑选关键词的数量为Nw,则构建评论图的时间复杂度为O(ωNw),图的构建可在训练外离线进行。基于连接关系的图注意力网络的时间复杂度为,L为堆叠层数。基于交互关系的注意力机制的时间复杂度为综上可知,RGP 算法的总时间复杂度为
3 实验和结果分析
3.1 实验设置
3.1.1 实验数据
本次实验使用亚马逊评论公开数据集Amazon 5-score 中的3 个子类别数据集Instant Video、Tools and Home Improvement、Baby。3 个数据集均包含用户对项目1~5 之间的显示评分以及来自Amazon 网站的用户真实评分。表1 所示为3 个数据集的统计信息。

表1 数据集统计信息Table 1 Datasets statistics
3.1.2 实验设定和度量指标
本文将每个数据集随机划分成训练集(80%)、测试集(20%),随机取训练集的10%作为验证集。为验证本文所提算法的预测准确度,实验均采用均方差(MSE)来衡量预测评分和真实评分的差异,MSE计算公式如下:
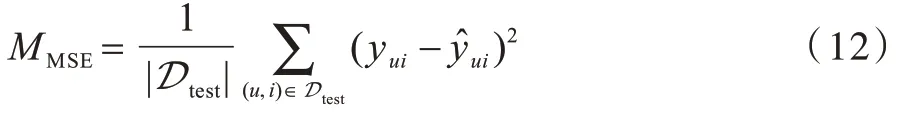
其中:Dtest为测试集。MSE 值越小,表示模型预测结果越准确。
3.1.3 对比算法
本文将RGP 算法与以下5 个基准算法进行对比:
1)PMF[1]是经典的概率矩阵分解模型,未用到评论文本信息。
2)DeepCoNN[5]通过卷积神经网络CNN 提取评论文本集的语义特征,用来计算用户对项目的评分。
3)NARRE[8]使用注意力机制计算每条评论的重要性分数,并为预测评分提供评论水平的解释性。
4)NRPA[10]使用基于个性化注意力机制的评论表征编码器和用户/项目表征编码器,依次得到评论表征和用户/项目表征。
5)DAML[17]使用局部注意 力机制过滤评论 信息,使用交互注意力机制学习用户和项目评论的互相关性。
3.1.4 超参数设置
对于RGP 算法,通过网格搜索法寻找最佳的超参数:嵌入空间和表征空间的向量维数d0和d1在{8,16,32,48,64}中选取,学习率r在{0.005,0.001,0.000 5}中选取,正则化系数λ在{1,0.5,0.1,0.01}中选取,训练批次大小和堆叠层数L分别在{64,128,256}和{1,2,3,4}中选取。对比算法均根据原文献进行参数初始化,通过微调使其达到最佳性能。
3.2 性能比较
本文RGP 算法和对比算法的实验结果如表2 所示。从表2 可以看出,与仅基于评分数据的PMF 算法相比,利用评论文本的算法(DeepCoNN、NARRE、NRPA、DML、RGP)具有更好的推荐性能,因为评论文本中包含的用户偏好和项目属性信息可以对评分数据进行补充;在同样利用评论文本的推荐算法中,使用注意力机制的算法(NARRE、NRPA、DAML、RGP)相较未使用注意力机制的算法(DeepCoNN)具有更优的性能,这是因为注意力机制可以识别每个词、句子或评论的重要性,针对评分行为更加细致地捕捉评论文本的语义信息;在所有基准算法中,DAML 算法表现最佳,其融合CNN 和交互的注意力机制探索用户和项目评论文本自身以及相互的相关性,可以捕捉到更加丰富的有关用户喜好和项目特性的信息。
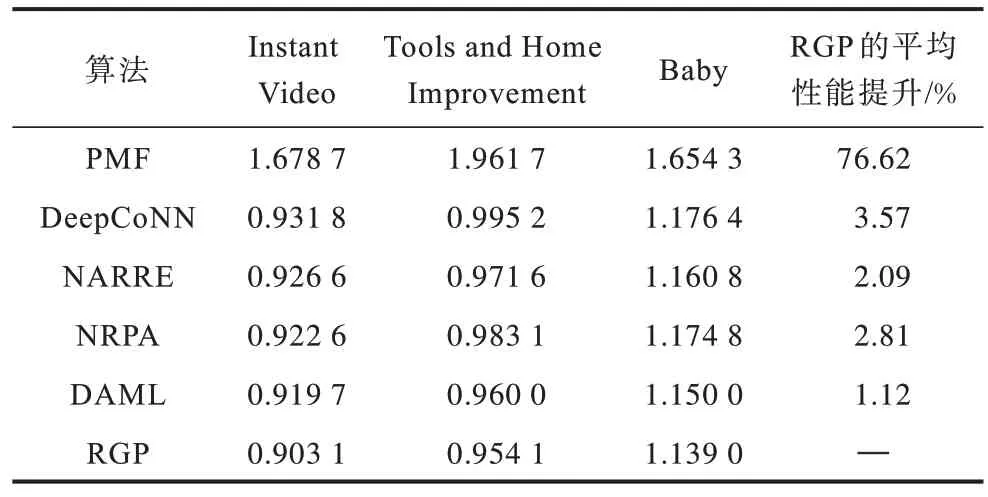
表2 不同推荐算法的性能对比结果Table 2 Performance comparison results of different recommendation algorithms
本文RGP 算法在3 个数据集上的性能都优于对比算法:和使用注意力机制的NARRE、NRPA 算法相比,RGP 中基于交互关系的注意力机制更能捕捉用户对不同项目的不同喜好;和使用交互注意力机制的DAML 相比,RGP 通过将评论文本表示成图并应用堆叠的图注意力网络,可以在捕捉交互水平喜好特性的同时有效捕捉评论中词与词之间长期、非连续和全局的拓扑与依赖信息。
3.3 消融实验
为了进一步验证RGP 算法各个部分的有效性,本文进行消融实验以评估以下4 个RGP 变种算法的性能:
1)RGP-T 算法:从RGP 算法中去除评论图中的边的连接关系,即不考虑词序信息。
2)RGP-A 算法:从RGP 算法的图注意力网络中去除注意力机制,即直接对邻接点的表征做均值聚合。
3)RGP-G 算法:从RGP 算法中去除堆叠的图注意力网络,对初始嵌入表征经一层非线性变换后输入到基于交互关系的注意力机制中。
4)RGP-I 算法:从RGP 算法中去除基于交互关系的注意力机制,直接对图的节点表征做均值聚合。
5 种算法在Instant Video 数据集上的实验结果如图3 所示(在其他2 个数据集上的结果与图3 所示结果类似)。从图3 可以看出:原始RGP 算法的性能优于4 个变种算法,说明在RGP 算法中,基于连接关系的图注意力网络和基于交互关系的注意力机制对性能提升均起到积极作用;在变种算法中,RGP-G 算法的性能最差,验证了将评论文本表示成图的有效性。

图3 在Instant Video 数据集中的消融实验结果Fig.3 Ablation experimental results in the Instant Video dataset
3.4 参数敏感度实验
为分析超参数对模型性能的影响,本文进行2 组参数分析实验,2 个超参数分别是表征空间的向量维数d1和基于连接关系的图注意力网络层的堆叠数量L。
针对不同的表征空间向量维数{8,16,32,48,64},在Instant Video 数据集上进行实验的结果如图4 所示(在其他2 个数据集上的结果与图4 所示结果类似)。从图4 可以看出:当维数设置为16 时,模型推荐性能最佳,更高的维数不仅不会提升性能,还会造成时间和空间复杂度提升;对于不同的数据集,最佳维数不是固定不变的;当数据集的训练样本足够时,应适当提高维数以增强模型的拟合能力,而当训练样本较少时,应适当减少维数以避免模型过拟合。

图4 表征空间的向量维数对模型性能的影响Fig.4 Effect of vector dimensions of representation space on model performance
针对不同的图注意力网络堆叠层数{1,2,3,4},在Instant Video 数据集上进行实验的结果如图5 所示(在其他2 个数据集上的结果与图5 所示结果类似)。从图5 可以看出:当层数设置为3 层时,模型推荐性能最佳,这是因为当层数太少时,模型无法从评论文本中捕捉足够的有效信息;而当层数太多时,模型会由于参数过多导致过拟合。
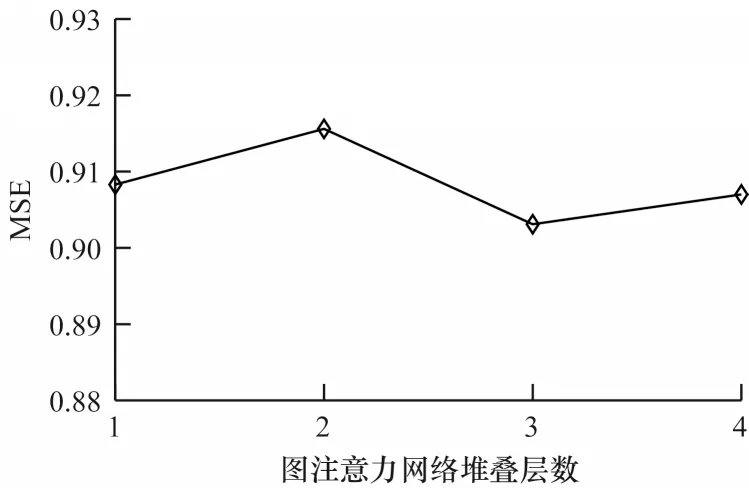
图5 图注意力网络堆叠层数对模型性能的影响Fig.5 Effect of stack layers of graph attention network on model performance
3.5 注意力机制分析
为验证模型中注意力机制所发挥的作用,本文提取一对在Instant Video 测试集中的用户(ID 为742)和项目(ID 为1551)的交互记录(评分为5),并提取模型在此用户和项目的评论文本图中所计算的注意力分数。
基于连接关系的图注意力网络在用户和项目的评论文本图中所计算的注意力分数分别如图6、图7所示。由于真实评论文本图的节点数和邻点数过多,此处只呈现了部分有说明性的重要节点。可以看出,不同的邻点拥有不同的注意力权重,并且能够表达用户或项目特性的邻点权重相对更高。例如,在图6节点“great”的邻点中,“storyline”(权重0.099 2)和“show”(权重0.098 1)更能表达用户喜欢视频的剧情和故事线,则对应的权重更高一些,而邻点“job”(权重0.056 3)的权重更低一些。图7 的情况与图6 类似。因此,基于连接关系的图注意力网络可以有效捕捉不同邻点对中心节点的重要性程度,从而实现过滤信息的作用。

图6 用户的部分评论文本图和注意力分数Fig.6 User’s partial review text graph and attention scores

图7 项目的部分评论文本图和注意力分数Fig.7 Item’s partial review text graph and attention scores
基于交互关系的注意力机制在用户和项目的评论文本图中所计算的注意力分数(括号中的数值)如表3 所示,这里只呈现和图6、图7 相关并且更能说明用户和项目特性的节点词。可以看出,在注意力机制中,更能体现其特性的词的注意力权重更高,而一些无关词的权重相对较低。如在用户评论图中,“characters”和“storyline”的权重更高,说明用户比较注重视频的演员和剧情;项目评论图中“actors”和“story”的权重更高,并且伴有正向评价,说明此视频的剧情和演员都不错。因此,用户对此视频的评分为5 分,说明喜欢该视频。基于交互关系的注意力机制可以使得模型更加注重评论中意义丰富的词,从而实现动态捕捉用户和项目特性的目的。

表3 部分词及其对应的基于交互关系的注意力分数Table 3 Partial words and their corresponding attention scores based on interaction
4 结束语
本文提出一种基于评论文本图表示学习的推荐算法RGP,其能有效融合评论文本和图表示学习的性能优势。引入基于连接关系的图注意力网络和基于交互关系的注意力机制,可以更加充分地捕捉词与词、交互行为与评论文本之间的相关信息。在Amazon 数据集上的实验结果表明,相对PMF、DAML等算法,RGP 算法可有效提高推荐精度。下一步将尝试引入更多的非评分辅助信息,以建立更为准确的用户偏好和项目特征分布,从而提高推荐精度。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
小雪花·成长指南(2022年1期)2022-04-09
国际眼科杂志(2021年9期)2021-09-15
装备制造技术(2020年2期)2020-12-14
文苑(2018年21期)2018-11-09
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国卫生(2015年12期)2015-11-10
中国卫生(2015年9期)2015-11-10
中国卫生(2014年3期)2014-11-12
