
基于知识图谱的智能信息推荐模型构建仿真
2021-11-18 04:09杨雅志
计算机仿真 2021年1期
杨雅志,钟 勇,李 骏
(1. 中国科学院成都计算机应用研究所,四川 成都 610041;2. 成都工业学院,四川 成都 611730;3. 中国科学院大学,北京 100049)
1 引言
当前,网络数据量的飞速增长不仅加快了信息传输速度,也对用户造成了信息过载问题,无法高效提取兴趣信息。信息推荐技术不仅能够为用户提供可用的信息服务,且在用户没有明确描述需求时,只要通过用户对其它物品的历史行为信息,就能够准确挖掘其个性化需求,根据兴趣偏好,为用户主动提供所需要的信息。信息推荐技术作为网络个性化服务的关键环节之一,具有重要的研究意义与探索价值,也因此涌现出众多相关学者对信息推荐技术展开研究。
文献[1]将用户经历作为隐式反馈的累积数量定义,提出一种平衡系数的自适应网络智能信息推荐模型。采用用户历史经历数据替代平衡系数,在模型中添加阻尼系数,实现深入优化,最后有效结合阻尼系数与用户经历,架构智能信息自适应推荐模型。但是该模型的智能效果较差,应用适应性不理想。文献[2]提出基于知识网络的信息推荐模型。设定最近邻优先的候选知识选择方案,结合最大可学习支撑度优先的未学知识推荐算法以及知识关联结构,对用户知识需求进行挖掘。但是该模型耗时较长,知识推荐时间没有得到明显缩短。文献[3]提出基于矩阵分解模型的协同过滤推荐模型。将矩阵分解与协同过滤结构进行融合,得到耦合物品属性信息相似度的推荐模型。但是该模型的应用过程难度较高,无法进行广泛应用。
为解决传统方法存在的问题,提出基于知识图谱的智能信息推荐模型。采用三元组构成的知识网络与本体论,设计知识图谱与结构化模型;组建由课程实体间关系构成的知识图谱网络结构;利用FP-Growth挖掘算法,获取频繁项集合与关联规则,动态更新知识图谱,引入信息推荐路径达成度与SVR检测模型完成推荐。
2 知识图谱分析
将知识图谱划分成数据层与模式层。利用SPO三元组[4]表示各知识,通过知识网络生成知识图谱;采用本体论对结构化概念模板进行架构,以有效控制知识冗余。逻辑结构与构建技术共同组成知识图谱,其构建技术部分如图1所示。
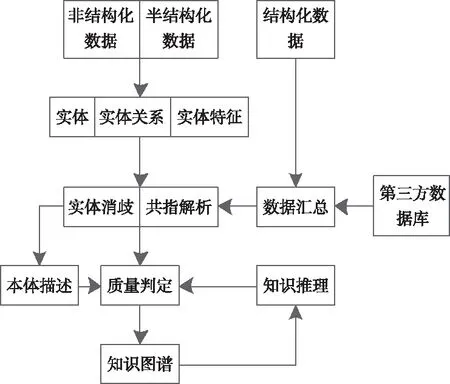
图1 知识图谱技术结构示意图
技术模块主要分为构建阶段与流程动态更新两部分,构建阶段是在初始数据内采用一些策略对知识事实进行提取,并将其以元素形式存储到知识库[5]的逻辑结构中;而更新过程则包含三个阶段:信息提取、知识汇总与知识处理。
3 基于知识图谱的智能信息推荐模型构建
智能学习信息推荐模型可以通过分析与挖掘学习数据,获取相关有效信息,进一步辅助与指导教学活动的顺利进行。该模型的设计目标是为不同的学习者提供与之相匹配的学习路径与学习内容,实现因材施教的个性化学习策略。
3.1 模型总体设计原理
图2所示为经过扩展与改进传统各单元模型获取知识图谱下智能信息推荐模型,结构部分有领域知识模型、学习者模型以及自适应引擎模型三个模块。
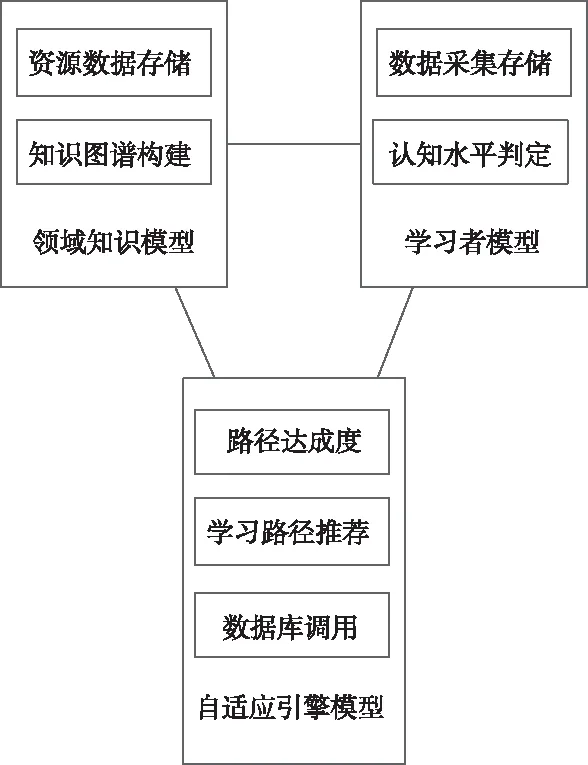
图2 基于知识图谱的智能信息推荐模型结构示意图
推荐模型可用性的判定依据为其工作流程对用户的适用性,分别以模型管理者与学习者的角度,对基于知识图谱的智能信息推荐模型进行分析。
针对管理者方面,推荐模型应具备资源上传与管理等功能,若想防止该模型出现冷启动[6]问题,则需要在资源上传前进行初始知识图谱的架构,采用存储于资源数据库里的资源与知识图谱模型数据,为自适应引擎模型提供可调用数据,在学习资源得到一定积累后,通过关联规则算法挖掘出知识之间相关性,从而动态更新知识图谱;
针对学习者方面的运行流程则相对繁琐,若首次使用推荐模型,则需要通过注册基本信息,完成学习者模型的架构,为了便于今后的信息推荐,用户需在下一次使用时,先在登录界面进行相关信息的匹配,然后,依据个人信息选择学习与测试内容,模型通过分析处理采集到的学习数据与测试成绩,检测学习者的认知水平,将其与知识图谱进行结合,匹配可达学习路径,根据推算的各学习路径达成度,实现路径推荐列表的创建,从而令学习者的进一步学习更加便捷,而且,基于学习者模型的数据,推荐模型将完成诸如知识点掌握程度与学习路径等学习者能力图谱的架构,使学习者的下一步学习内容选取,能够通过比较能力图谱与知识图谱得以实现。
3.2 基于知识图谱的智能信息推荐模型的构建
采用知识图谱对知识实体、实体间关系以及知识特性进行知识表达,是领域知识模型的主要功能。由于学习阶段的最小知识体系单位是课程,知识图谱的主要研究目标是课程实体。
利用下列公式对知识表达三元组进行描述
F={E,R,T}
(1)
式中,E为全部课程实体集合,R为各课程实体间的关系集合,T为课程实体内部特征集合。
图3所示为课程实体间关系所构建的知识图谱网络框架示意图。
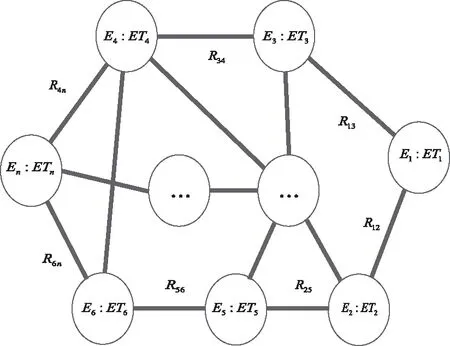
图3 知识图谱网络框架示意图
图3中各代数式的含义如下:具体课程实体为Ei,课程实体Ei和Ej的映射关系为Rij,与集合R相对应,课程实体Ei内部特征集合为ETi。
领域知识模型的工作流程如图4所示,初始架构流程为图4中的方框区域,框外区域则主要用于动态更新知识模型。

图4 领域知识模型结构示意图
动态更新知识图谱的目的是提升知识图谱的适用性,需要采用关联规则的FP-Growth[7]挖掘算法来完成,通过压缩存储事务数据集,对FP-Tree进行架构,从而获取全部频繁项集合与关联规则。
FP-Tree的创建步骤为:对数据库D进行扫描,达成各实体支持度的运算,按照支持度降序对所得的频繁1-项集合进行排序,获取频繁项集合L;标记tree根节点T为“null”;迭代运算各学习路径Di;按照频繁项集合L的排列顺序,对各学习路径Di内的实体进行求取,获取频繁项集合,第一个实体为p,除此之外,频繁项集其它实体构成的项表为P;实现函数insert_tree([p|P],T)的调用。
FP-Tree的挖掘[8]流程为:空值是集合L的初始值;若tree仅有一个学习路径P,那么,对该路径实体所有组合进行迭代运算,并用β表示,将β内实体极小的支持度值作为实体集合α∩β的支持度,最后返回到集合L与集合α∩β的交集;反之,则用αf表示tree头表内的各频繁项,将αf的支持度作为实体集合β=αf∪α的支持度,完成β条件模式基B的创建,从而对β的条件树treeβ进行求取,如果满足treeβ≠Φ,那么界定fp_growth(tree,β),并停止挖掘。
智能信息推荐该模型主要组成部分为学习者的基本信息与知识状态两大模块,用于对学习者当前的知识状态结构进行表征,推荐对象的个体属性与认知[9]性能。
当已知测试题的所有参数,评估学习者的认知水平时,若作答m个试题的学习者数量为N,θα为第α个推荐对象的权重指标,则1≤α≤N,第j个推荐信息的区分度、数据相似性以及猜测系数分别是ai、bi和ci,如果试题的评分标准为0~1,那么,表达式如下所示

(2)
利用下列公式对认知水平Uα学习者对第m个试题的回答结果进行描述
Uα=(Uα1,Uα2,…,Uαm)
(3)
其中,1≤α≤N。
所以,推导出关于m个推荐信息N个用户回答结果,其矩阵函数U如下
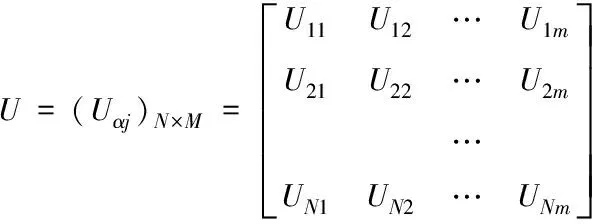
(4)
式中,Uαj是随机变量,取值0或1。
若uαj为观测值,认知水平θα的推荐对象权重指标第j个属性为Pαj,则
Pαj=P(uαj×1)
(5)
如果推荐内容符合局部独立性假设条件,那么,学习者回答结果概率L的表达式如下所示
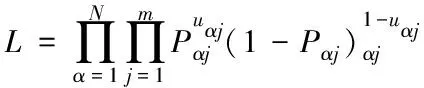
(6)
设定待估算的认知水平数值为似然函数L极大值的自变量数值,由于L与lnL的最大值点一致,所以,取L的对数得出下式

(7)
使lnL的参数偏导为0,则有
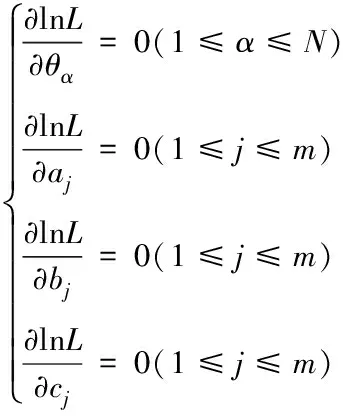
(8)
将上列两式代入合并,得出下列表达式
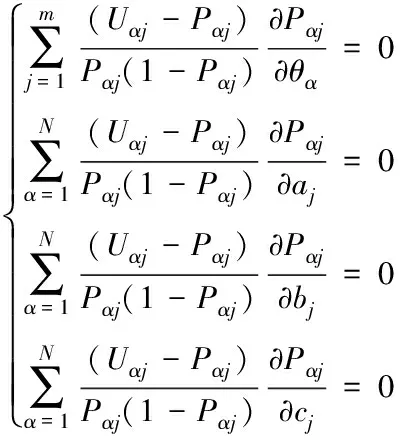
(9)
采用牛顿-拉夫逊迭代法估算θα,下列公式为g(θα)的表达式
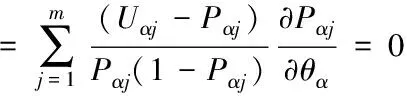
(10)
根据上式推导出下列计算认知水平的迭代公式

(11)
迭代初始值θα0表达式如下所示

(12)
采用下列公式对迭代终止规则进行描述
|θα(k+1)-θαk|<ε
(13)
该模型为实现推荐模型的重要环节,功能是对前两个模型进行推荐路径与推荐内容进行匹配。
利用推荐完成的平均概率来界定路径[10-11]达成度,下列公式为定义表达式
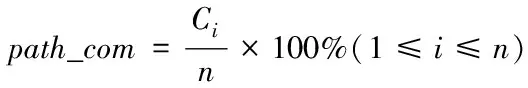
(14)
式中,路径含有的总数据量为n,相似识别对象第i个推荐内容相关度为Ci。
根据所得的达成度,为数据推荐提供最优推荐路径。
自适应引擎模型[12]中SVR模型的检测阶段相当于机器学习的阶段,主要用于解决分类与回归问题。
在智能推荐模型中信息任意选取n个学习者属性x1,x2,…,xn,通过预处理得到训练样本[x1,x2,…,xn,path_com],经过训练与优化SVR模型的参数,依据输入元组预估路径达成度。若[x1,x2,…,xn]为预估样本,则预估函数表达式为
F=f(x1,x2,…,xn)
(15)
4 实验分析
为评估论文提出的智能信息推荐模型应用性能,实验随机抽取500名用户作为实验样本,此次试验将与文献[1]模型、文献[2]模型进行对比。实验指标为模型的推荐路径完成度以及信息推荐召回率作为评价指标。模型的推荐路径完成度越高,说明信息推荐的成功率越高。推荐召回率越高说明模型应用的精度越高,即模型的应用效果越好。具体对比结果如图5、图6所示。
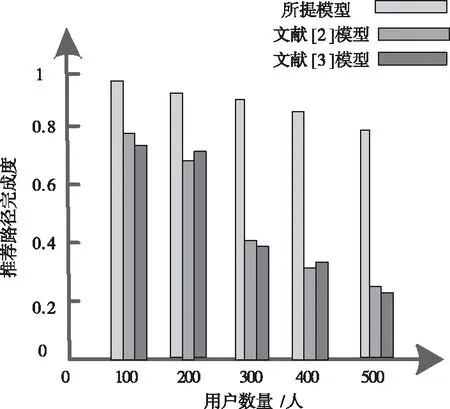
图5 不同模型的信息推荐路径完成度对比
分析图5的三种模型推荐路径完成度的波动趋势可知,随着用户数量的增多,推荐路径的完成度均出现了下降情况,但是传统方法的下降幅度更大,而所提模型在用户人数较多情况下,仍然保持较高推荐路径的完成度,说明即使用户数量较多,所提模型也能够成功按照最优推荐路径完成信息推荐也说明了所提方法具备较好稳定性。
为进一步验证本文模型的实际推荐精度,在不同用户数量情况下,利用所提模型与现有模型推荐路径进行对比并记录,具体对比结果如图6所示。

图6 不同模型推荐召回率
通过图6的召回率波动趋势可知,传统方法召回率最低值为0.7,而所提模型推荐召唤率峰值大于0.9,远高于传统模型,这是因为所提模型利用FP-Growth挖掘算法,获取频繁项集合与关联规则,知识图谱的动态更新能够有效滤掉大误差推荐信息。所以所提模型随着用户人数增加,召回率波动幅度较为平稳,说明所提模型具备较好稳定性。
5 结论
为实现用户的个性化信息推荐、加强体验感与信息提取的可靠性,提出基于知识图谱的智能信息推荐模型。通过数据层、模式层得到的逻辑结构与流程动态更新,改进并扩展传统单元模型,基于初始知识图谱模型,采用知识表达三元组,根据用户与推荐内容关系的知识图谱网络结构进行构建,按照支持度降序排列所得频繁项集合,实现函数调用,通过迭代运算路径实体的所有组合形式,达成全部频繁项集合与关联规则的挖掘,构建并完善智能信息推荐模型。实验结果表明:所提方法推荐准确率及效率远远高于现有方法,具有较好的鲁棒性及实际应用价值。该模型为未来的相关研究奠定了良好的数据基础,拥有重要的现实意义与实践价值。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
电脑知识与技术(2022年11期)2022-05-31
计算机系统应用(2021年11期)2022-01-06
意林·少年版(2020年2期)2020-02-18
知识文库(2019年24期)2019-12-30
现代职业教育·职业培训(2019年6期)2019-10-09
当代陕西(2019年5期)2019-03-21
新城乡(2018年6期)2018-07-09
21世纪商业评论(2018年3期)2018-03-02
