
分布式互联网敏感信息属性基加密仿真研究
2021-11-17 08:36沈国良
计算机仿真 2021年5期
沈国良,郑 滔
(1. 苏州大学信息化建设与管理中心,江苏 苏州 215006;2. 南京大学软件学院,江苏 南京 210046)
1 引言
信息属性基加密技术是根据密码学原理提出的,它是由信息密钥属性基加密与信息密文属性基加密两种方法组成。而敏感信息安全引起诸多组织高度重视,但是组织内部敏感信息管理所使用基础设备是非常昂贵的,如何以便宜的价格来完成可靠的敏感信息存储,并且能够保证敏感信息安全与高效使用,同时遵守有关政府信息保护法规法律、不泄露信息隐私是亟须特别重视的问题。
相关研究人员对该方面研究诸多。例如闫玺玺[1]等人采用多机构方法对敏感信息属性基进行加密,首先使用半策略隐藏方法,把敏感信息属性分成属性值与属性名两部分,再对敏感信息属性值做隐藏处理,完成隐私保护,这样有效避免敏感信息属性值泄露给其他人。此外,信息加密过程中只对与访问策略有关属性做加密处理,并不是对该系统所有属性做加密处理,而是改变原有敏感信息保护的属性基加密方法。在极大程度上缩短密文长度。但该方法信息安全仅仅依赖DBDH假设,具有一定局限性,同时计算较为复杂,浪费大量时间。陈丹伟[2]等人针对敏感信息属性基加密过程会泄露一部分信息问题,提出一种全新的敏感信息属性基加密方法。先采用线性秘密分享矩阵函数作为该系统访问结构,使方法具有很强表达能力,可以随机表达访问,再通过三种质数合数阶双线性群来构建,实现安全隐藏敏感信息的目的,随之利用双系统加密方法来验证其安全性。但该方法需要占据系统大量空间,结果准确率较低。
为此,提出一种新的分布式互联网敏感信息属性基加密方法,经验证该方法简化了计算时间,提高了准确率,缩短了系统运营成本,增强了信息安全性,有效解决了上述存在的问题。
2 分布式互联网敏感信息的分解
在安全信息库服务系统组成中,可信板块是保护信息隐私安全的重要一步,因此将可信板块中敏感信息分解到不相同的分布式信息库中并保存,做到敏感信息隐私安全保护。信息分解分为水平分解与垂直分解两种方式[3]。其中水平分解是将信息记载水平分解到若干信息库中,即敏感信息R=R1∪R2∪…∪Rn;而垂直分解是将记载的不相同属性基分解在若干个信息库中,即R=R1▷◁R2▷◁…▷◁Rn。但由于水平分解在该系统保护作用较小,可忽略不计,所以仅考虑敏感信息属性基的垂直分解。
2.1 敏感信息属性基的自动检测
信誉用户在外包信息过程中,可以直接指出敏感信息属性基,但是对于那些不属于敏感信息属性基的,则可以通过对这些信息属性基进行分析来区分。比如,在统计信息库中,人名与身份证件号都属于个人隐私,即敏感信息属性基,但是出生日期、性别以及邮政编码等都属于非个人隐私,即非敏感信息属性基,而事实上可以采用连续操作的方法来确定其身份证编码与个人姓名[4]。为此,对信息库中的敏感信息属性基做自动检测是非常必要的。
信誉用户信息库中的信息用R(A1,A2,…,An)表示,其中A1,A2,…,An代表关系R的属性基。为了完成属性基的自动检测,做了如下设定:
设定一:准标志集合。Q表示准标志集合关系R中最小属性集合。
设定二:准标志。α表示准标志的某一个属性基集合,这部分属性基的取值结果可以很容易确定关系R中的α一部分信息。
设定三:属性基乘域。n1,n2,…,nk表示关系中属性基不相同取值个数,即D=n1×n2×…×nk。
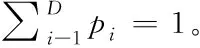
E[Xi]=npi(1-pi)n≈npien
(1)


(2)
定义一:假设D≤n,则D/e表示已标识记录总数量的敏感信息属性基的检测期望值上限。
证明:假设f(x)=xex,则f′(x)=(1-x)ex,f″(x)=(x-2)ex,根据f′(1)=0,f″(x)<0,得到期望函数f(x),当x=1此处有一个极大值。已标识记录的敏感信息属性基检测期望值上限即为
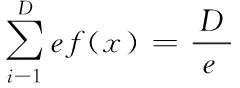
(3)
定义二:假设D≥n,则nen/D表示已标识记录总数量的敏感信息属性基检测期望值上限。
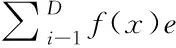

(4)
假设D≥n,则得出nen/D已标识记录总数量的敏感信息属性基检测期望值。
定义三:设定n为关系表的大小,D>n/ln(1/α)表示信息属性基集合的属性乘域,得到一个为α准标志的敏感信息属性基集合。
证明:当D>n,根据定义一可知,关系表中最大期望值为D/en1/e<α。根据定义二可知,信息属性值域的属性基集合能够有效找关系表中被标记记录的属性基检测最大期望值,即en/D,并组成α标准志集合记录,再找出检测期望值一定大于α,为此en/D>α,也就符合D>n/ln(1/α)。
检测出的敏感信息属性基能够为敏感信息关系的分解奠定基础。
2.2 敏感信息关系分解
关于垂直分解的方法诸多,而垂直分解需要考虑两个问题。问题一关系分解后必要保证原有信息属性基;问题二被分解后信息必须起到隐私保护作用。
为了确保被分解后信息具有原来信息属性基,就得在每一个信息库中保存并记录关键字,使用关键字拼接方法完成全部查询记录过程。而事实上关键字属性总是展现出敏感信息属性,但不能显示是否保存,这种情况最好的解决方法就是采用序列号的方式[5]对元组进行标记记录。在信誉板块中设置一个序列自动生成装置,并记录每个被分解信息所生成的序号编码ID,此序号编码ID重复出现整个分解关系表中,同时保存到不相同的信息库中[6]。
定义四:隐私制约准则。其是根据初始关系表中的集合属性基进行访问,但每个子集属性基不能同时进行访问。设定P⊆2R,表示P是R的子集的集合。
如果初始关系表中的垂直分解代表D(R)=(R1,R2,…,Rn,E),R1∪R2∪…∪Rn=R同时E⊆R1∧E⊆R2∧…∧E⊆Rn。式中R1,R2,…,Rn分别代表分解后被输送不相同服务端的属性基集合,其中E代表被加密的敏感信息属性基集合。关系分解必须符合隐私制约准则,也就是∀p∈P,P∉(R1-E)∧p∉(R2-E)∧…∧p∉(Rn-E)。
要想符合信誉用户设定的隐私制约准则,就得区分初始关系表中敏感信息属性基与非敏感信息属性基[7]。对初始关系表中的敏感信息属性基做隐私保护处理,降低对该敏感信息加密能力的影响,被加密的敏感信息属性基使用对称加密方法,即a=E(a,k)。其中a代表初始属性基数值,k代表加密密钥。而被加密后的敏感信息属性保存在整个信息库中,密钥则保存在信誉板块中。对于非敏感信息属性基则采用自动检测方式得到极大的准标志属性基集合,需要注意准标志集合不同存储到同一个信息库中,还要将非敏感信息属性基保存到某个信息库中,降低连续操作对查询能力的影响。
3 敏感信息属性基加密的实现
想要提高敏感信息隐私保护和敏感信息查询、处理过程中的平衡,就得使用上述敏感信息关系分解结果对该敏感信息的属性基进行加密[4]。
由上述步骤可知,敏感信息关系分解结果是根据敏感信息的属性基自动检测得到的,将敏感信息分解成若干个信息属性准标志集合,同时将有关分解的信息属性基保存到敏感信息储存设备中;通过上述过程完成了分布式互联网敏感信息属性基的加密。给出分布式互联网敏感信息属性基加密过程如图1所示。

图1 分布式互联网敏感信息属性基加密过程
该方法不用信息库管理工作者来维护隐私信息[9],只需要对敏感信息属性基做加密处理,就可以完成敏感信息的隐私安全保护。虽然只是将敏感信息一部分进行加密,再分解成若干个信息属性基,但其具有极高的信息保护和查询能力。
综合上述步骤,完成了分布式互联网敏感信息属性基加密方法。为了确保加密质量,还设计了基于查询处理的敏感信息加密质量校验模块。
4 基于查询处理的敏感信息加密质量校验
已有加密信息库查询处理方法都没有考虑敏感信息的加密质量校验问题,而分布式互联网敏感信息加密方法充分考虑加密质量问题,采用查询处理的方式对被加密敏感信息属性基的加密质量进行校验。要求信誉板块在收到信誉用户在初始关系表上的SQL查询之后,就要对SQL查询做分析、重写以及优化等处理,获得符合的子查询并将其输送到不相同的信息库系统中,各信息库系统将查询后结果送回信誉板块,由信誉板块总结后送回信誉用户初始信息库数据中。为此,使用分布式信息库查询方法能够有效解决被加密的敏感信息属性基查询问题[10]。
对关系表上信息进行查询,可以用R1▷◁R2▷◁….▷◁Rn代表关系表,并将关系表逻辑查询变换成R1,R2,…,Rn上的查询,最终将各子查询信息输送信誉用户。根据信息查询结果可知,子查询是根据初始信息查询并不是信息保存位置,因此在操作过程中不会形成不同信息库之间的隐蔽路径。
5 仿真结果与分析
为了验证所提分布式互联网敏感信息属性基加密方法的有效性,进行一次仿真。
随机抽取敏感信息集n=4×108条并记录下来,每一条记录都有二十多个属性基。
对敏感信息属性基的自动检测准确度做测试,检测信息集合是从互联网中随机抽取的32480条信息与7个非敏感属性基,这7个属性基分别表示开通时间、空卡记录、使用情况、资源种类、厂商标码、业务种类以及节点类别,每一个信息属性基不同值个数也是不同的,即70、3、9、15、8、45、6,任意抽取10个敏感信息属性基做检测处理,得到如表2结果。

表2 互联网记录集合中检测的属性基
属性基乘域的大小直接决定属性基自动检测的准确度,属性基乘域越大,自动检测的准确度就越高。根据表2信息可知,采用所提的分布式互联网敏感信息属性基加密方法中所构建的属性基自动检测方法后,随着属性基数量的增大,属性基乘域也逐渐增大,当属性基数达到最大值7时,属性基乘域也已经达到最大值2.98×108,因此说明所提方法的检测准确度较高,验证了所提方法在属性基的检测方面具有一定的有效性。
敏感信息关系分解的精度对后续敏感信息属性基的加密质量有直接影响。现将敏感信息关系分解精度作为实验测试指标,以文献[1]方法和文献[2]方法作为所提方法的对比方法,分别测试三种不同方法的敏感信息关系分解精度。得到对比结果如图2所示。

图2 三种不同方法的敏感信息关系分解精度对比
分析图2可得出,属性基个数的递增使得铭感信息关系分解精度逐渐增大,因此在属性基个数为7时,分解精度普遍较大。图中看出,文献[1]方法的敏感信息关系分解精度最大值为35%,平均分解精度约为30%;文献[2]方法的敏感信息关系分解精度最大值为78%,平均分解精度约为65%;所提方法的敏感信息关系分解精度最大值为75%,平均分解精度约为72%。对比实验结果得出,虽然所提方法的最大分解精度低于文献[2]方法的最大分解精度,但平均分解精度远远大于两种传统方法,因此验证出,所提方法的分解精度最高。
分别采用文献[1]方法、文献[2]方法和所提方法,对分布式互联网敏感信息的属性基进行加密,以加密漏洞个数为指标,测试三种不同方法的加密质量,得到三种不同方法的加密漏洞个数对比结果如图3所示。
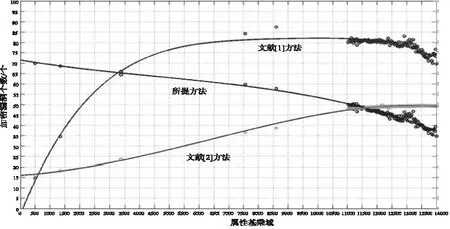
图3 三种同方法的加密漏洞个数对比
根据图3结果可以看出,文献[1]方法的加密漏洞个数随着属性基乘域的增加而大幅度增加,当属性基乘域达到5000时,加密漏洞个数的增加幅度趋于平稳,平均加密漏洞个数约为60个,最终稳定在80个;文献[2]方法的加密漏洞个数随着属性基乘域的增加稳定上升,平均加密漏洞个数约为33个,最中稳定在35个;所提方法的加密漏洞个数随着属性基乘域的增加而线性减少,在属性基乘域为0时,漏洞个数最多为71个,在属性基乘域为14000时,漏洞个数最少为30个,也就是最终的漏洞个数。对比三种不同方法的实验结果可得,文献[1]和文献[2]方法的漏洞个数是呈上升趋势的,而所提方法的漏洞个数呈下降趋势,且所提方法的最终漏洞个数均小于文献[1]方法和文献[2]方法的最终漏洞个数,充分说明所提方法的加密质量最好,具有一定的有效性。
综合上述实验结果得出,所提方法在属性基自动检测、敏感信息关系分解精度及加密漏洞个数方面,均具有一定的优越性,说明所提方法的加密质量最好。
6 结论
通过对互联网中敏感信息属性基存在泄露问题,提出一种分布式互联网敏感信息属性基加密仿真。实验结果表明,该方法能够准确地检测出属性基,且敏感信息关系分解精度最大值可达到75%,平均分解精度高达72%,加密漏洞可以呈现减小的趋势最终稳定在30个左右。该方法优越的加密效果,能够为分布式互联网的隐私信息安全保护起到较大的作用。
猜你喜欢
今日农业(2022年13期)2022-09-15
小学生学习指导(低年级)(2021年9期)2021-10-14
学生导报·东方少年(2019年27期)2019-01-14
阅读(低年级)(2018年2期)2018-05-14
电脑知识与技术(2016年31期)2017-02-27
儿童时代(2016年6期)2016-09-14
科技与创新(2016年7期)2016-04-20
读写算·小学低年级(2015年12期)2015-12-12
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
计算机世界(2009年27期)2009-07-30
