
基于多通道卷积神经网络的非结构化数据标注
2021-11-17 08:37:16米启超赵红梅林丽萍
计算机仿真 2021年6期
米启超,赵红梅,林丽萍
(1. 河南城建学院电气与控制工程学院,河南 平顶 467036;2. 西安交通大学化工学院,山西 西安 710049)
1 引言
早期的数据标注工作中,所标注的数据通常由相关领域内的专家,或使用计算机进行标注。虽然可以保证标注质量,但往往效率低下,延误研究,同时成本较高[1-2]。众包模式下,大任务较为复杂,通过拆分成小任务的方式降低复杂度,依据互联网接口,网络用户得以使用,通过零散时间即可完成小任务,获取报酬。众包模式可以充分体现群众智慧,潜能巨大,具有较为重要的商业价值,利用群体智慧,解决社会资源冗余问题。
基于此原因,提出了众包标注方法,该方法通过较高的任务开放性,提高了标注速度,并降低了成本[3-5]。但该方法标注质量较低,需要依赖算法和函数来添加众表标注的标签,来改善标注数据的质量,需要确定标注中的任务函数,并建立相关模型。早期研究者采用EM算法,对标注者进行混淆矩阵计算,后续又采取了RY真值推断算法,并利用其中的敏感性参数来提高标注任务函数的准确度[6-8]。但该方法无法具体的体现出标注者的差异性,获取的标注函数可靠性不高。而考虑到标注者的特性和差异性问题,运用多通道卷积神经网络技术,可以对其进行深入的运算,具有较高的研究前景。
2 基于多通道卷积神经网络的非结构化数据标注方法设计
2.1 非结构化数据查询处理
在进行标注之前,需要对所需标注的数据进行确认查询处理,确定与被标注数据的关联数据,避免出现漏标或错标[9-10]。在进行非结构化的数据查询处理中,采用Hive分布式查询框架进行数据查询处理。框架结构如图1所示。
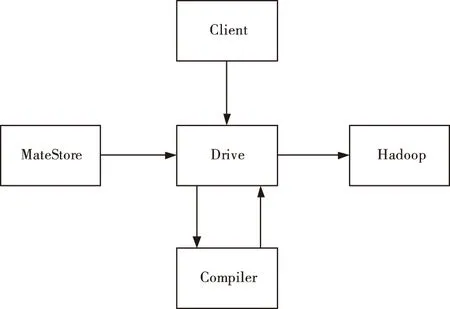
图1 Hive查询框架结构示意图
如图1所示,图一中Driver模块对非结构化数据进行编译,并优化其中的执行语句。而Compiler模块由Driver模块进行控制和调用,并将获取到执行语句转为MapReduce执行策略,转换完成后传输回Driver模块中。而Hadoop模块作为策略的执行引擎,通过Dricver将从MapReduce策略数据导入至Hadoop中,并进行查询。并设置Compiler将获取到的数据转换至一组一元操作符,并获取到抽象语法树,然后利用框架中的Semantic Analyzer对语法书中数据进行语法分析。同时利用相似性检索技术进行查询,通过给定的元素(在本文中,该元素为需要进行标注的数据),并寻找其中相似的元素,数据集设为A而查询元素则设为s,相似性检索即为
SS(A,s)={a|θs(a,b),a∈A}
(1)
其中,不同集合下的相似度计算则如下所示
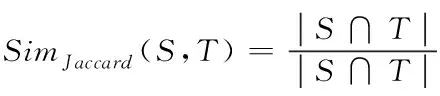
(2)
其中SimJaccard(S,T)的结果代表集合S以及集合T的相似度,|S∩T|代表集合S与集合T之间的交集,|S∩T|则代表集合S与集合T之间的并集。通过对其中标注数据相似度的查询,确定标注数据有关信息,利于开展进一步的标注。
2.2 众包标注集

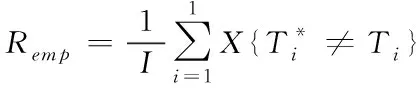
(3)
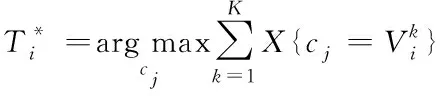
(4)
通过式(4)可以将标注任务形式化,但通过该方法后,标注时对标注者没有体现出差异性,因此需要对其进行进一步的推算。
2.3 多通道卷积神经网络差异性识别
利用多通道卷积神经网络对其中的神经元结构带入标注任务和标注者,并得出其中的最适应标注任务分配,同时给出不同标注者的差异性[11-12]。根据卷积神经网络的结构,得到网络输出公式h,公式为

(5)
在式(5)中,xi代表神经元中的第i个输入,wi代表在神经元中的第i个输入权重,b代表偏置值,f代表神经元激活函数,h代表输出公式。当其中的WTx的结果作为线性结果,同时其中的激活函数引入了WTx的结果映射。而在多通道的卷积神经元网络中,假设其中网络的输入值为x,网络中的权值矩阵为w以及偏置矩阵则为b,输出为hw,b,在网络进行反向传播中,将网络中的期望输出值设为y(x)。所训练的样本个数为n,根据网络反向传播理论,在反向传播中会出现损失函数,本文将损失函数设为E,则损失函数在神经网络中的平方误差为
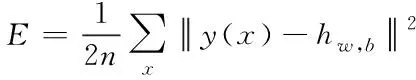
(6)
而在网络的训练中,需要首先对其中的权重值w以及偏置值b进行初始化。而在训练中,由于选取了反向传播来带入标注指示函数,并对神经网络中的参数进行更新,而在该过程中,网络呈梯度下降的过程,如下图所示:

图2 神经网络中的梯度下降图
根据在多通道卷积神经网络的梯度下降理论,可以根据梯度下降方向得出的神经网络的权重值w以及偏置值b,并更新得出的w以及b值。获得的更新公式如下
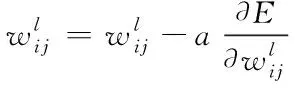
(7)

(8)

2.4 任务标注模型

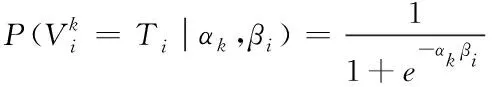
(9)
在(9)中αk系数代表标注值能力的系数,βi系数代表标注任务的难度,而当其中的βi参数为固定参数,而αk数值越大则反映标注者的标注能力越好。而当αk数值为0时,说明该任务里,标注者的正确标注概率仅为50%。而通过将双标签任务扩展到多标签任务标注中时,首先假设一共存在J种标注类型,并建立标注集合C={cj|j=1,2,3,…,J}来表示,而当标注目标i的标注真值为m时,则该标注者k的标注正确率为
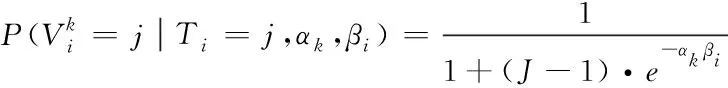
(10)

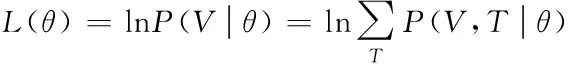

(11)
在式(11)中,存在的隐变量T的和对数,运用Q函数,而在累加形式下,表示出期望状态,代表了完全数据下的标注似然函数InP(V,T|θ),而其中的观测数据V在对估计参数θn下的为观测数据T的后验概率分布P(T|V,θn)的期望值
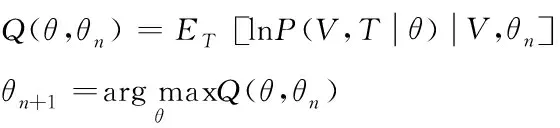
(12)
由此得出在(12)中,算法的迭代过程等价与Q(θ,θn)函数。借由此得出标注函数的解值,根据解值,确定标注模型参数,依据标注模型完成数据标注方法设计。
3 实验论证分析
为了测试本文设计的非结构化数据标注方法的有效性,本文选取了Airfares、Music、Hotel以及Books等4个领域中的非结构化数据,共160个WDB数据集,进行标注统计分析。并与文献[1]、文献[2]中的标注方法进行对比实验。

表1 硬件配置表
3.1 实验标注数据
由于目前对非结构化数据标注方法缺乏相关的测试标注设计,因此本文数据资源通过搜索引擎下载获得,实验中使用的数据集情况如下表2所示。

表2 实验测试数据集
为了减低实验困难程度,阈值标注通过专家给定,黄金标签个数为1000个,经过深度学习进行标签预处理操作,标注对象个数为11270个,实验共收集10名标注者信息,判断修改标签域与标签值。
3.2 实验评价标准
在进行数据标注中,标注的基准值是通过手工方式得出的数据标注结果,并计算其中的标注正确率、召回率以及F-measure数值来进行评价。
而标注正确率代表正确标注的数据块个数以及经过查询得出的数据个数比值召回率代表在标注时得到的正确标注数据个数和查询得到数据块个数比值。而F-measure则代表标准的数据标注能力评判值,数值越接近100%,代表性能越优秀。本文实验将运用上述中的三种指标进行实验结果评价。
3.3 实验结果
在运用数据标注方法实验中使用的数据集分别进行数据标注后,对获得的标注结果进行评价。获得的标注结果如表3所示。
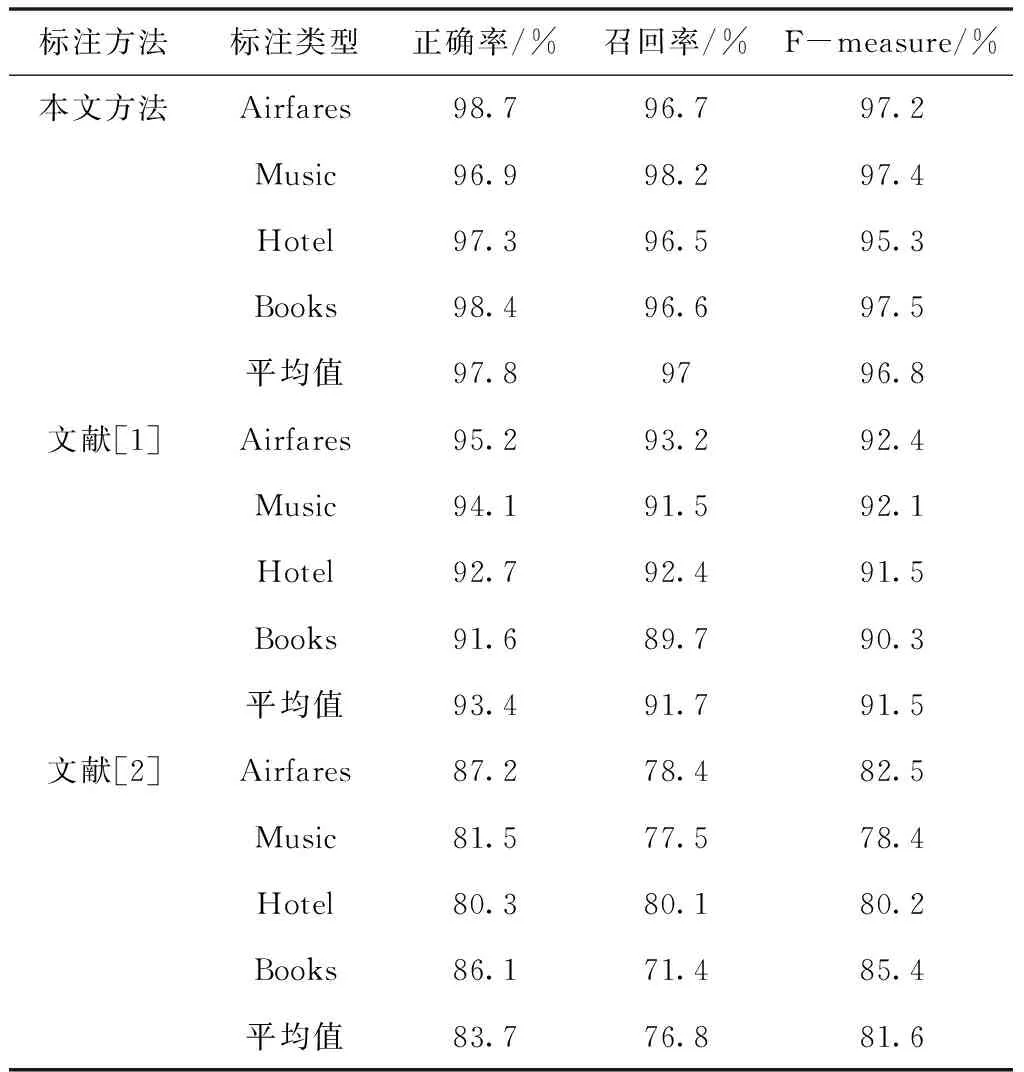
表3 标注方法间的性能比较表
依据表3中的数据中可以发现,本文设计的数据标注方法在标注的正确率、召回率以及F-measure上均高于其它标注方法。证明本文设计的数据标注方法存在较高的可行性。
为直观判断标注效果,在对象标注界面中,包括了标注者当前任务完成情况,当前可选择标注的标签,以及待标注的图片,标注者只需先选中标签,就可以在图片中快速框选对象,并为对象打上此标签。 对象判断任务中,用户可以判断此标签是否包含有效的对象。

图3 标注对象图
边框调整模块可以对标签范围框进行调整,将内边距较大的标注范围框调整为紧贴标注对象,提高标注质量。
图4展示了标注者的标注点分布,以及通过 原始聚类和本文卷积神经网络的聚类效果对比。

图4 聚类算法效果图
由上图可以看出,本文方法聚类效果较好,标注对象选中密度较大,传统方法的标签域范围较大。主要原因在于本文方法建立Hive分布式查询框架,对其中与标注目标相关的数据进行相似性查找,同时建立众包标注集,确定相关标注概念。对标注集中的标注差异性,利用多通道卷积神经网络对其差异性进行确认,提高了标注准去率。
4 结束语
在本文中,利用多通道卷积神经网络技术,对标注者的差异性进行了深入挖掘,获得了标注任务函数,并根据函数建立了任务标注模型,得出了非结构化的数据标注方法,该方法下标注质量较高性能较好。但本文研究中,只考虑了对标注者给出的任务标签数据的情况,而在实际中,往往会提供额外的特征信息条件。因此后续的研究中,将会研究与额外的数据标注信息进行结合,进一步改善数据标注质量。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
电子制作(2019年11期)2019-07-04 00:34:38
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:35
计算机工程(2015年8期)2015-07-03 12:20:27
