
海量交易数据抗干扰推荐算法仿真
2021-11-17 07:35:42蔡娟
计算机仿真 2021年6期
蔡 娟
(天津商业大学宝德学院,天津 300384)
1 引言
网络信息的爆发式增长与种类的复杂以及新型电子商务服务的出现,导致用户因种类繁多的信息无法做出有效选择。这种多样性的选择不会出现经济效益,反而会影响用户的满意度。推荐系统被证明是一种非常有效解决信息过载问题的工具。推荐系统对海量数据进行挖掘,为用户展示该用户不熟悉且满足用户当前需求的信息。但在推荐过程中容易出现外界干扰,导致推荐出的数据,不是最优信息,不能有效满足用户的全部需要,导致降低用户的体验。
为了解决这种问题,国内学者提出如下解决方案。文献[1]首先把遗忘曲线与记忆周期作为时间元素引入算法中,使艾宾浩斯遗忘曲线融合指数函数,从而取得时间和兴趣衰减的函数关联度,以此优化用户项目的测评分数,让目标用户对待预测的项目评分更为精准。但是与其它方法相同,该算法在特定的交易平台能够很好完成对数据的推荐,但是大环境中抗干扰能力相对较差。文献[2]首先凭借用户测评矩阵和商品种类信息,建造用户针对种类的用户兴趣偏好矩阵,然后使用K-Means算法对项目集进行聚类,并基于用户编号矩阵搜索预估值所对应的临近用户,然后结合项目相似度的加权算法在所有项目种类中对稀疏矩阵进行填充,进而对用户的编号矩阵聚类,最后,通过填充后的测评矩阵,在所有用户类别中使用协同过滤算法对商品测评分数预测,并与用户矩阵融合,从而达到目的。但是该方法需要对用户偏好、用户编号、商品测评分数设置矩阵,而计算这些矩阵需要消耗大量的时间,导致该算法的推荐效率降低。文献[3]首先从交易数据中提取出用户偏好信息,并将其作为类似邻居的选择指标,然后使用top-k算法确定服务的类型与用户近似邻居集合,最后将连通类似邻居的偏好比值与经调整的皮尔逊相关系数算法估算用户的Qos值,从而偏好信息推荐给用户。但是该方法缺少对干扰元素的抑制,导致推荐给用户的商品不一定是用户的偏好商品。
针对上述问题,本文提出了一种海量交易数据抗干扰推荐算法,该算法首先使用决策树和自适应门限算法对用户偏好进行抗干扰处理,抑制其干扰因素,然后通过融合聚类与协同过滤算法对用户偏好和商品类型分类,最后将两种算法融合构建模型,实现将最优信息推荐给急需用户。
2 海量交易数据抗干扰推荐算法
2.1 随机决策树与自适应门限变换的抗干扰模型
2.1.1 模型期望信号
在交易数据检测过程中,首先使用交易数据决策树进行群体搜索,计算决策节点的误差率,利用ef或ei表示,以此对临近的两个检测周期结果分析Δe=ef-es,其存在三种状况:①若Δe≤T1,表示目前没有监测到交易数据;②若Δe≥TH,表示存在网络交易[4]中含有概念交易数据,利用当前获取的树构造更新劣质子树;③反之证明Δe的产生是因为干扰元素,调整ef与es为接下来的检测提供依据,重复运行上述环节知道完成交易数据的训练。利用当前数据块的分类精度es,来更新每一个历史数据的平均分类精度。
利用FLMS自适应算法对交易数据中出现的干扰因素进行过滤,该算法将阵元1作为主天线自适应处理的期望信号,其它M-1个辅助阵元[5]作为干扰因素抑制信号,自适应的调节权值矢量W,进而对准干扰信号的射入方向实时检测。设定w1代表未授权1向量,因此期望信号是

(1)

(2)

(3)
所以FLMS的迭代过程使用式(4)、(5)计算,其中n代表迭代次数
e(n)=d(n)-wH(n)x(n)
(4)
w(n+1)=w(n)+2μx(n)e*(n)
(5)
FLMS算法计算量较小,并且容易被实现,但是该算法会被延迟抽头的数量所影响,随着延迟抽头的总数增加,其收敛的速度会大幅度降低,无法达到实时处理的效果。在延迟抽头[6]数量增加时,需要快速收敛的自适应算法才可以实现实时跟踪,并抑制相关的干扰因素。
2.1.2 模型干扰抑制过程分析
为了提高海量交易数据的抗干扰性,本文通过自适应门限的变换干扰抑制方法对交易数据中的干扰因素进行处理,保证网络上的顺利交易。凭借DFT的变换域技术抑制窄带干扰的原理构造,用图1表示。

图1 变换或抑制干扰的原理构造图
首先通过加窗操作对输入的交易数据处理,进而改进DFT引发的频谱[7]泄露问题,利用合适的滤波算法对干扰谱线进行降低操作或归零,然后将约束操作的频域分量转换为时域,再进行后续的处理。但是加窗操作会使交易数据出现衰减的情况,所以需要将交易数据进行重叠操作,进而修正。
约束操作可以利用自适应算法凭借干扰的波动情况拟定适合的自适应门限,进而保证系统能够更加准确的过滤相关的干扰因素,保证有价值的信号可以顺利的传输。如果噪声为高斯白噪声,则白噪声干扰信号用e描述,T表示分析门限。其监测门限的确定指标是
Rr{|S(k)+G(k)|≤T}=1-e-T22Nδ
(6)
式中,S(k),G(k)分别为使用在描述噪声谱线和信号谱线,N表示FFT的点数,σ为使用在描述高斯噪声方差。若式(6)的交易数据流小于门限T,则能够降低高于门限的价值信号产生的干扰。利用式(6)时需要单独预测σ,但是在现实情况中其拥有一定的限制性。经常可以凭借谱线幅值获取平方Ck=(S(k)+G(k))2(k=1,2,…,N)来确定门限。首先拟定一种较大的固定门限Tm,保证Ck(k=1,2,…,N)的最大值Cmax小于Tm,再检测门限可以按照下列公式自适应设置为

(7)
式中,H为门限优化因子。应选择适合的门限优化因子确保式(7)的概率最大化。运行FPGA操作前应当明确FFT的点数N,根据利用的FPGA部件资源的排序和快速博里叶转换[8]获取相关的逻辑资源,通过MAT-LAB获取Tm和H。FPGA中的转换域操作的数据在A/D转换前能够利用自助增益管理进行处理,使相关的信号波动转换区域拥有稳定性。此类情况下分析网络交易数据在没有干扰条件下,输入的信噪比范围与数据块长度,能够获取不同信噪比时的Cmax。因此对于一个交易快从不同的数据码元进行FFT处理,获得的Cmax存在一定的差异性,需要以最大的Cmax保证Tm值,本文设定Tm=3.8×1011。H的取值可以经过下式计算

(8)
考虑到一定的冗余度,可以选择H=20。这样,自适应门限就可以经过式(8)确定了。利用上述分析的方法可以实时的对交易数据中存在相关的干扰因素进行处理,并确保网络交易的顺利运行。
2.2 海量交易平台的个性化信息推荐
在购买商进行商品交易时,主要利用交易对象以及需求交易的商品种类进行推荐的,不过由于商品交易存在选择性。因此,需要将所有经过聚类技术的预推荐交易信息进行分组。
所有的商品交易信息平台都是从事各种行业的购买商获取商品的主要途径,同时可以及时、有效且精准的将信息推荐至所需用户。其商品信息的交易平台推荐模块,其主要是利用算法分析、数据采集以及信息推荐所组成,具体如下图所示。

图2 信息推荐模块结构示意图
推荐模块主要是利用待测用户所需求的精准性、数据的相关性、各个需求层次的顺序、分类精准性等进行考虑。与此同时还要考虑推荐信息吸引度以及多样性等。
本文将聚类思想引进协同过滤算法中,首先需要对购买商所存在的交易信息分数进行评测,然后分类,并估算标准用户和普通用户间的相似度,对交易信息中所触碰到的用户进行估算,最后能够对目标商家与该交易用户之间的类似度进行排序。
2.2.1 待推荐内容信息项目测评矩阵
首先拟出相关的定义S={U,V,N,Tij},其中U={u1,u2,…,un}、V={v1,v2,…,vn}、Bi={x1,x2,…,xn}、N={n1,n2,…,nn}、Tij={tn,m,1≤n,1≤m}。
U代表用户推荐集合,V为内容数据的推荐集合,Bi表示第i种推荐对象凭借待推荐的内容信息测评集合,N是Bi的中心向量集合,而Tij为用户对待推荐内容的数据测评联系,即测评矩阵。矩阵内容如表1所示。
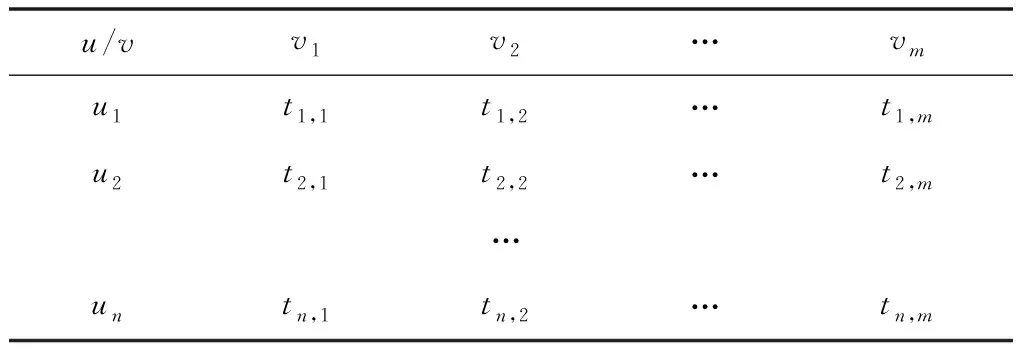
表1 待推荐内容信息项目测评矩阵
在交易系统中,vm代表购买商和交易需求的信息评测关系,即指购买商un相对交易所需求信息tn,m的测评数据。
2.2.2 用户相似度计算

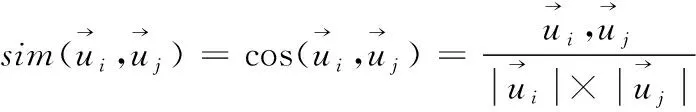
(9)
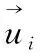
商品交易信息集合Vij,那么ui,uj即购买商共通测评的关系程度集合,再以式(9)为基础,对用户ui,uj之间的相同项目类数关系值进行相似度计算,其公式如下

(10)
在式(10)中,sim(ui,uj)为购买商ui,uj在商品交易信息集合Vij上的类似值。
2.2.3 加权平均值的预测测评
在使用计算而得到的购买商相关业务集合。再经过交易信息推荐给类似的购买商。设置预推荐购买商ui有K中从事相关业务的用户,凭借式(9)、式(10)的关联度的计算,待推荐的购买商以及待推荐内容中没有测评信息集合关系公式如下所示,就是对P进行测评
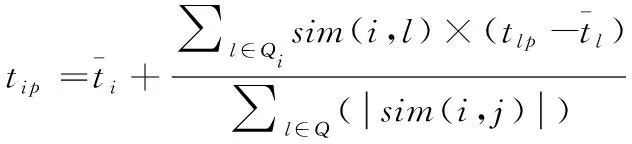
(11)
式中,Qi代表用户ui的K种邻居的集合。tip代表购买商ui在没测评数据集合p上的预测具体分值。
对待测评的交易数据分值计算,接着能够得到分值相对比较高的交易数据项目,然后推荐至用户。将以上的商品交易信息平台与实际的情况进行融合,接着利用聚类思想把协同过滤的推荐算法,其关键的环节为定义并重新叙述。然后再融入聚类计算,以此将用户推荐速度提高,聚类思想的关键性,也可以提升交易平台中的推荐算法精准度。
凭借式(11),计算目标购买商ui,uj相对于没有测评分数项目的评分。对比测评分数的阈值,以此生成项目的推荐集合。故加权平均值的预测的测评,即为用户个性化数据推荐函数。为检验本文方法的有效性及可行性,需对其进行仿真。
3 仿真证明
3.1 仿真环境及参数
仿真环境为Intel Celeron Tulatin1GHz CPU和384MB SD内存的硬件环境和MATLAB6.1的软件环境。在进行仿真的过程中,利用表1的待推荐内容数据项目测评矩阵,结合本文上述算法进行计算,再把计算结果和传统方法计算结果对比。
3.2 误码率分析
在上述参数设置的基础上,进行算法的误码率检测。为检验本文方法的优越性能,本文的误码率检测将在多因素干扰环境下进行,本文将在多址干扰、单音干扰以及三音干扰的情况下,分析数据推荐过程中的误码情况。通常情况,误码率大小介于10E-8~10E-11之间,表示数据推荐性能最优。
通过分析图3可知,在不同干扰条件下,本文推荐算法的误码率均处于10E-8~10E-11之间,说明本文算法具有较高的抗干扰性能。这是由于本文算法利用FLMS自适应算法对交易数据中出现的干扰因素进行过滤,此外,本文算法还考虑延迟抽头数量,采用快速收敛的自适应算法,提高算法收敛速度,实现实时处理,提高抗干扰性,降低算法误码率。


图3 不同干扰条件下的数据误码率
3.3 数据推荐的准确率
检验本文方法推荐精度。在进行实验时,对和目标购买商关联度较高用户排序。将用户数量从1增加至100,间隔每10个用户进行采集一次,就可以得到本文算法与文献算法在海量交易数据中对用户进行商品推荐效果,以误差值为指标,判断用户意图数据的推荐效果。在用户总数的变化中,其算法的TIC分析具体实验结果如下所示。

表2 需求与推荐

图4 推荐情况分析曲线图
根据上述实验,可知本文算法的推荐准确率高。本文方法使用在海量交易数据中,能够有效的为购买商推荐其有兴趣或急需的商品交易数据信息,使得用户在最短时间接受到最有用的信息,并且本文方法不会受到其它干扰因素的影响,能够精准的为用户推荐感兴趣的商品。
4 结论
本文提出的海量交易数据抗干扰推荐算法,基于决策树节点对海量交易数据历史数据平均分类准度进行更新,并通过自适应门限变换算法对交易数据干扰因素进行抑制,最后使用融合聚类算法和协同过滤算法将交易数据干扰抑制算法、加权平均值测评分数和用户相似度融合,获取模块,利用模块内的用户聚类分析算法对交易数据分组,以此通过协同过滤可以将交易数据推送至效用较高的用户,进而实现海量交易数据的抗干扰推荐。仿真结果证明,本文方法能够有效的将干扰因素抑制,并且本文方法的推荐效率较高,不会出现推荐误差。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
雷达与对抗(2022年1期)2022-03-31 05:18:20
汽车实用技术(2022年4期)2022-03-07 06:02:26
中国西部(2021年4期)2021-11-04 08:57:32
华东师范大学学报(自然科学版)(2020年1期)2020-03-16 03:14:55
当代陕西(2019年14期)2019-08-26 09:42:00
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
湖湘论坛(2015年3期)2015-12-01 04:20:17
单片机与嵌入式系统应用(2014年7期)2014-03-24 19:12:05
铁路通信信号工程技术(2014年3期)2014-02-28 16:56:24
