
大数据平台下网络舆情风险演化模型仿真研究
2021-11-17 07:34:38任昌鸿童春燕
计算机仿真 2021年6期
任昌鸿,童春燕
(重庆师范大学涉外商贸学院,重庆 401520)
1 引言
随着我国网络技术的不断发展,网络已经成为人们日常生活中必不可少的元素。网络使用率的增加,导致网络舆情风险出现。网络舆情指的是互联网上流行的对社会问题不同看法的网络舆论,实质上是社会舆论的一种表现形式,主要是通过互联网对热点与焦点问题中影响力较强的观点与言论进行传播。现今比较被大众所接受的网络舆情定义为:网络舆情主要是以网络为载体,以事件为核心,对广大网民态度、情感、观点、意见等进行传播、互动、表达与后续的影响[1]。网络舆情信息比较多元、表达较为快捷,具有开放与虚拟的特性,导致其具有直接性、随意性、多元化、突发性、隐蔽性、偏差性等特点。但是,随着网络社会的崛起,网络舆情逐渐的成为现实社会的“晴雨表”,也是一种不可忽视的频发性社会现象[2]。网络舆情主要是通过对民意进行聚合,对社会产生深刻的影响。但是其也存在着较大的风险,近几年,由于负面的网络舆情导致当事人抑郁、自杀的事件频发,网络舆情风险也逐渐的受到人们的重视。
为了对网络舆情风险进行详细的分析,国内外对网络舆情风险演化模型进行了研究,并取得了一定的成果。目前使用较为广泛的模型为基于多数原则的网络舆情风险演化模型、基于有限信任的网络舆情风险演化模型以及基于Sznajd的网络舆情风险演化模型。其中,基于多数原则的网络舆情风险演化模型主要的思想为观点聚合,在该模型中,个体观点呈现为二元离散状态,更加简单,并简化了分析的过程;基于有限信任的网络舆情风险演化模型认为观点交互行为主要出现在观点差值小于给定的信任阈值时,以此为基础,对观点模型进行建立,分析网络舆情风险演化过程;基于Sznajd的网络舆情风险演化模型是粒子交互模型中的典型代表,主要的思想为:更多的个体会更加让人信服,因此,该模型主要是将观点进行聚合,以此为基础,对网络舆情风险演化模型进行构建[3]。但是上述三种方法均存在着网络舆情风险预测准确性低、控制效果差的缺陷,无法满足现今互联网的需求,为了解决上述问题,基于大数据平台对网络舆情风险演化模型进行构建,并设计仿真对比实验对构建的网络舆情风险演化模型性能进行测试与分析。
2 网络舆情风险演化模型构建
2.1 网络舆情信息获取
要想对网络舆情风险演化模型进行构建,首要的任务就要对网络舆情信息进行获取。通过研究发现,协程网络爬虫算法更加适用于网络舆情信息的获取[4]。具体的信息获取过程如下所示。
通过协程网络爬虫算法得到网络舆情信息为
X={x1,x2,…,xn}
(1)
为了对网络舆情信息中的观点进行提取,首先采用加权技术对信息中的关键词进行提取。采用权重对词的关键程度进行表示,词权重计算公式为
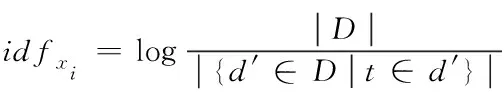
(2)
其中,idfxi表示的是第i个词的权重值;log表示的是底为10的对数公式;|D|表示的是网络舆情信息集合D中信息的总数;{d′∈D|t∈d′}表示的是包含词t的信息数量。
在网络舆情信息中,若是关键词k出现了n次,而网络舆情信息总词数为N,则词频为n/N。
由于网络舆情信息中含有大量的相似关键词,为了简化网络舆情信息,将相似的关键词进行集合,对相似关键词权重进行计算,得到
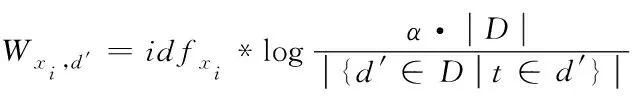
(3)
其中,Wxi,d′表示的是相似关键词权重值;α表示的是计算参数。
通过式(3)得到各个相似关键词的权重值,以此为基础,对网络舆情关键词分布图进行构建。
通过统计分析方法得到词频的二维与三维图,如图1所示。
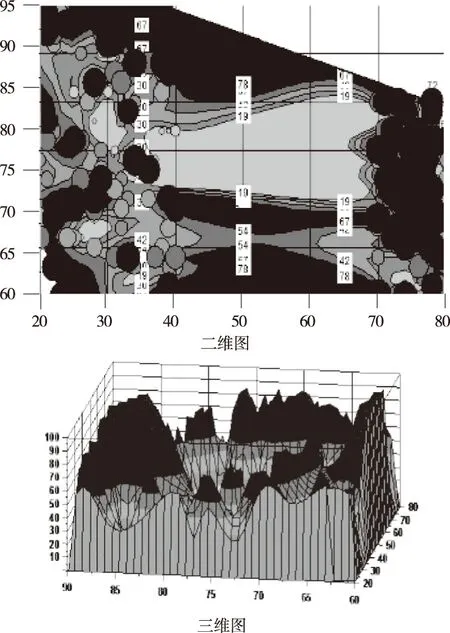
图1 网络舆情词频二维、三维图
根据上述得到的网络舆情词频图,通过聚类算法获取网络舆情观点信息,得到

(4)
通过上述过程完成了网络舆情信息的获取,并得到了网络舆情观点信息集合,为下述网络舆情观点的聚合提供数据支撑。
2.2 网络舆情观点聚合规则设定
以上述得到的网络舆情观点集合为基础,采用Weisbuch-Deffuant模型对网络舆情观点聚合规则进行设定,以此为基础,对网络舆情观点进行聚合[5]。具体的过程如下所示。
忽略网络舆情观点聚合空间中流失的情况,设定网络规模为M,将其中各个个体构成的社会网络记为G(M,E),其中,E表示的是网络中边的数量。
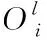
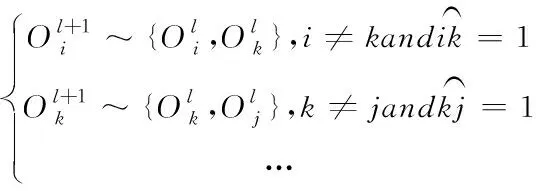
(5)
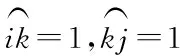
在网络舆情观点聚合中,个体交互程度具有非充分性与异质性的特性,个体对他人观点的接受程度也是不同的。在网络舆情观点聚合过程中,收敛系数主要是对个体对他人观点接收程度进行描述的变量,其取值的不同直接影响着观点聚合的效果。因此,收敛系数设置为一个固定值并不合理[8]。本节采用收敛系数的分布f(μ)对收敛系数进行代替。另外,将信任阈值与观点距离引入,其满足下述公式
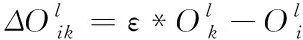
(6)
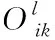
根据上述公式得到网络舆情观点聚合一般规则为
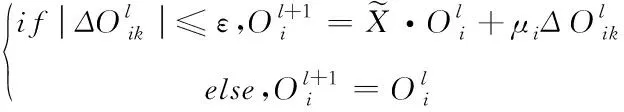
(7)
其中,ε为值域[0,1]上的一个固定值。
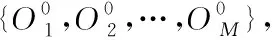
方式一:随机加边[9]。主要是依据概率在网络个体中进行随机选择,使新加入个体与其联系进行建立;
方式二:依据度值权重进行非等概率加边[10]。主要是依据网络连接的“马太效应”对新加入个体与已存在的个体进行连接,其概率为
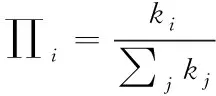
(8)
同时,网络中具有名人效应,以方式二进行加边更加符合实际的情况。因此,得到大数据平台下网络舆情观点聚合流程如图2所示。
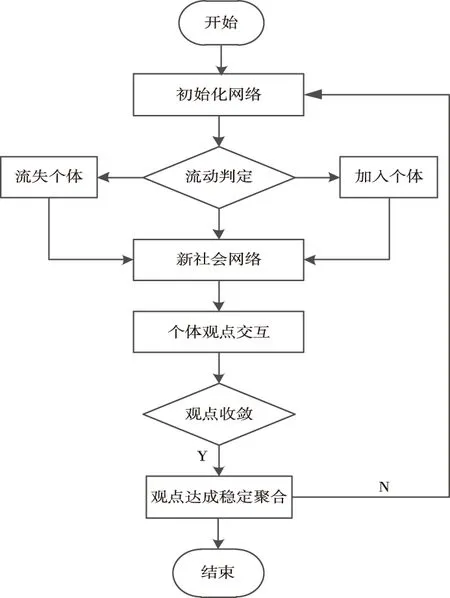
图2 大数据平台下网络舆情观点聚合流程图
通过上述过程完成了网络舆情观点聚合规则的设定,并对观点进行了聚合,为网络舆情风险系数的计算做准备。
2.3 网络舆情信息扩散模式搭建
以上述得到的网络舆情观点聚合结果为基础,采用仓室模型对网络舆情信息扩散模式进行搭建,具体的模式搭建过程如下所示[11]。
仓室模型是现今使用较为广泛的模型类型,仓室模型示意图如图3所示。
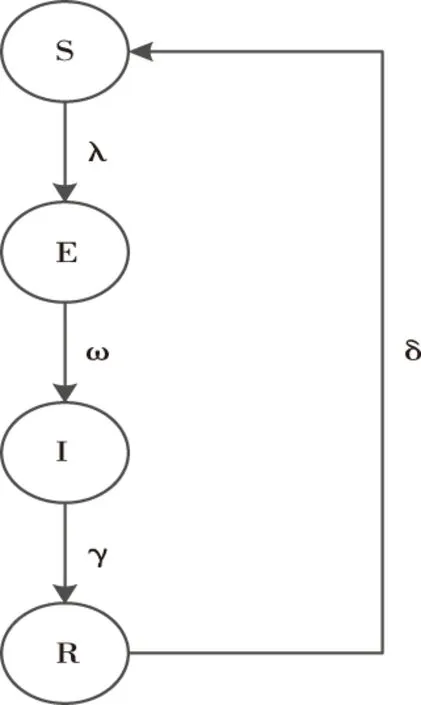
图3 仓室模型示意图
如图3所示,S表示的是个体非知情状态,表示个体没有受到网络舆情信息扩散的影响,对舆情信息认知较少;E表示的是个体知情状态,个体对网络舆情信息具有一定的了解,并受到其扩散的影响;I表示的是传播状态,这些个体是网络舆情信息扩散的主要推动者;R表示的是移出状态,该状态的个体不会受到网络舆情信息扩散的影响,处于免疫状态。
网络舆情信息扩散中个体状态转移流程如图4所示。
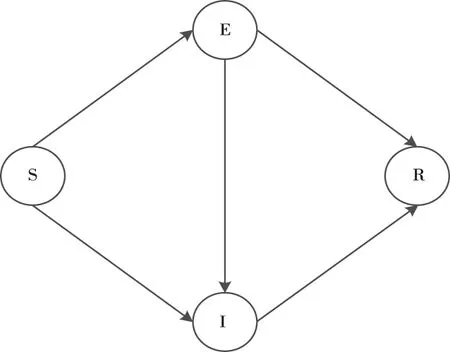
图4 个体状态转移流程图
以图4为基础,对网络舆情信息扩散模式进行搭建,用公式表示为
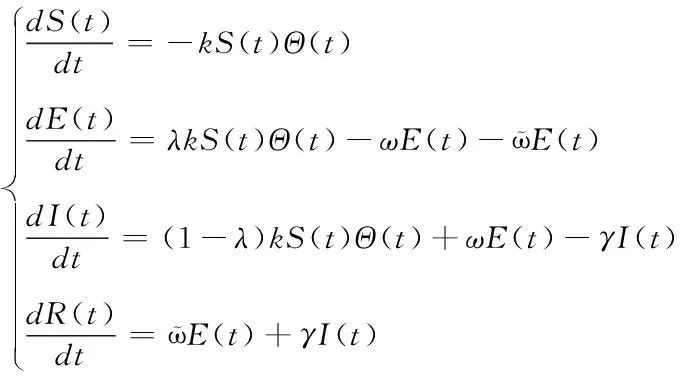
(9)
其中,λ,1-λ,ω,ϖ,γ分别表示的是S→I,S→E,E→I,E→R,I→R之间的转移概率;Θ(t)表示的是t时刻传播节点的概率。
通过上述过程完成了网络舆情信息扩散模式的搭建,对其扩散模型进行了详细的分析,为下述网络舆情风险系数的计算提供支撑。
2.4 网络舆情风险系数计算
以上述搭建的网络舆情信息扩散模式为基础,通过敏感性分析对网络舆情风险系数进行计算[12]。具体计算过程如下所示。
传播概率对网络舆情信息扩散效果有着直接的影响,随着传播概率的变化,网络舆情信息扩散的效果也存在着较大的不同。将上述过程简化为数值模型为
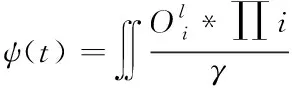
(10)
其中,ψ(t)表示的是网络舆情信息扩散效果。
根据上述公式结果,通过敏感性分析公式计算网络舆情风险系数,得到

(11)
其中,Ξ表示的是网络舆情风险系数,通常情况下,认为网络舆情风险系数越大,则网络舆情风险越大。
通过上述过程实现了大数据平台下网络舆情风险演化模型的构建,为网络舆情风险的预测与控制提供了强而有力的支撑。
3 仿真对比实验
上述过程实现了大数据平台下网络舆情风险演化模型的构建,但是对其是否能够解决现有模型存在的问题还无法确定,为此设计仿真对比实验对构建模型的性能进行测试与分析。
首先对实验平台进行构建,如图5所示。
图5 实验平台示意图
在仿真对比实验过程中,采用构建模型与现有的基于多数原则的网络舆情风险演化模型、基于有限信任的网络舆情风险演化模型以及基于Sznajd的网络舆情风险演化模型进行对比实验。为了保障实验结果的准确性,将实验外部环境参数设置为一致,通过网络舆情风险预测准确性与控制效果对模型的性能进行体现。具体的实验结果分析过程如下所示。
3.1 网络舆情风险预测准确性对比分析
为了保障实验结果的准确性,在网络舆情信息量15MBit与50MBit情况下,对网络舆情风险预测准确性进行实验,通过实验得到网络舆情风险预测准确性对比情况如表1、表2所示。
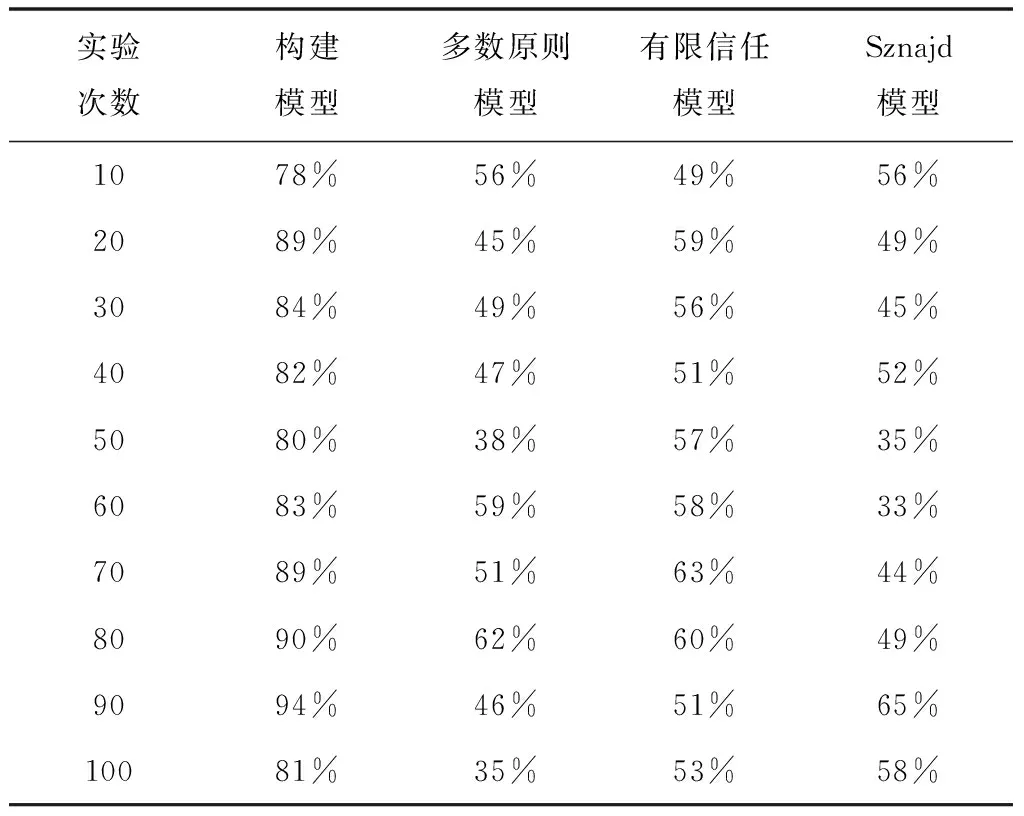
表1 信息量15MBit下网络舆情风险预测准确性对比情况表

表2 信息量50MBit下网络舆情风险预测准确性对比情况表
如表1、表2所示,构建模型的网络舆情风险预测准确性远远的高于现有三种方法,信息量15MBit情况下最大值为94%;信息量50MBit情况下最大值为89%。
3.2 网络舆情风险控制效果对比分析
网络舆情风险演化模型可以通过模型系数的设置对网络舆情风险进行控制,其控制效果直接影响着模型的性能。
通过实验得到网络舆情风险控制效果对比情况如图6所示。

图6 网络舆情风险控制效果对比情况图
如图6所示,构建模型的网络舆情风险控制效果参数远远的高于现有三种方法,说明构建模型控制效果更好。
通过实验结果显示,构建的网络舆情风险演化模型极大的提升了网络舆情风险预测准确性与控制效果,充分说明构建的网络舆情风险演化模型具备更好的性能。
4 结束语
构建的网络舆情风险演化模型极大的提升了网络舆情风险预测准确性与控制效果,为网络舆情风险的预测与控制提供了强而有力的支撑。但是模型的网络舆情风险预测准确性与控制效果依然具有很大的上升空间,需要对模型进行进一步的优化。
猜你喜欢
建材发展导向(2021年10期)2021-07-16 07:13:40
军营文化天地(2018年1期)2018-08-15 00:44:08
中国民政(2016年16期)2016-09-19 02:16:48
中国民政(2016年10期)2016-06-05 09:04:16
疯狂英语(双语世界)(2016年3期)2016-02-27 10:11:55
中国民政(2016年24期)2016-02-11 03:34:38
管理现代化(2016年5期)2016-01-23 02:10:11
营销界(2015年22期)2015-02-28 22:05:04
清风(2014年10期)2014-09-08 13:11:04
安徽医药(2014年4期)2014-03-20 13:13:04
