
JavaScript混淆恶意代码检测方法
2021-11-17 04:32:00牟永敏张志华崔展齐
计算机仿真 2021年2期
王 婷,牟永敏,张志华,崔展齐
(北京信息科技大学网络文化与数字传播北京市重点实验室,北京 100101)
1 引言
随着互联网规模的快速增长和用户人数的迅速增加,互联网公司在产品的用户体验上有着越来越高的追求。前端部分的重要性日益凸显,导致大量的业务逻辑由服务端转移到客户端。Bichhawat等人[1]的研究结果表明超过95%的Web应用选用JavaScript语言进行前端开发。JavaScript语言所具有的跨平台、可远程嵌入、能动态执行的特性在为用户提供更好的交互体验的同时,也给Web应用带来了更多的安全上的风险和威胁[2]。大量的安全报告表明,恶意网页已成为攻击者针对 Web客户端进行攻击的主要途径和平台[3]。因此,恶意JavaScript代码的检测成为一项影响Web应用安全的重要研究课题。
网页中的攻击代码常常具有多样化和隐蔽性的特点,其中17.1%的攻击行为是通过混淆JavaScript代码进行.代码混淆是一种为了避免安全系统检测而改变数据形态的技术[4]。另外,Web前端应用为减少代码体积,加快网页加载速度,通常会对代码进行优化与压缩。压缩后的代码常常与混淆后的代码一样失去可读性,同时也为恶意代码的隐藏提供了便利。随着JavaScript代码压缩与混淆技术的成熟,恶意代码的检测也变得越来越困难。
研究表明,恶意代码的行为常常具有某种规律[5]。如恶意代码通常会更多地调用某几种JavaScript语言的内置函数以实现代码恶意代码的伪装和隐藏,且为完成某种恶意功能,函数的调用顺序以及函数之间的调用图会具有某种一致性。而常用的代码自动压缩与混淆工具为保证代码在混淆前后语义上的等价,通常会保持原有的函数调用信息不变[5]。因此,利用已知的恶意代码中各函数的调用信息可以为新的恶意代码检测的提供参考。
针对以上问题,本文提出了基于函数调用信息的JavaScript混淆恶意代码检测方法。通过提取JavaScript代码中的函数调用序列和函数调用关系图,比较混淆前后函数调用关系的序列相似度和图相似度,得到混淆前后代码中函数的对应关系,为JavaScript混淆代码中恶意函数的检测提供参考。
2 国内外研究现状
2.1 恶意代码检测技术
网页中恶意代码检测的研究已经历了十余年的发展。自2004年开始,基于浏览器的客户端蜜罐(honeypot)系统已成为一类检测客户端恶意代码攻击的有力工具。这些工具通常采用将可以网页加载到易受攻击的浏览器中并观察系统总文件、注册表和进程的变化来检测网页中的恶意代码[6]。
2.1.1 静态分析的方法
Canali等[7]提出的Prophiler是一个利用静态分析进行恶意代码和良性代码分类的系统。Prophiler利用HTML及其关联的JavaScript代码以及URL信息构建有监督学习的监测模型,对代码进行初步分类。再对被判定为恶意的代码利用更精细的工具进行分析。Prophiler的不足是无法应对混淆后的恶意代码。
Curtsinger等[8]提出的ZOZZLE是一个静态的JavaScript恶意代码检测工具,其原理基于这样的假设:恶意的JavaScript代码一定会在最终执行前被反混淆。ZOZZLE利用JavaScript语言或宿主环境提供的可实现从字符串到代码的转换的函数(如document.write, eval)对代码进行反混淆,并将反混淆后的代码转换为抽象语法树、然后将从抽象语法树中提取的特征输入到朴素贝叶斯分类器中。
2.1.2 动态分析的方法
Xu等[5]提出的JStill通过分析器方法调用信息捕捉混淆恶意代码中的特征,结合静态分析和轻量级的运行时检查,检测混淆后的代码中的恶意代码。JStill的设计思想基于如下假设:混淆后的恶意代码在被执行前需要进行一定程度的反混淆以完全实现其恶意功能,而反混淆的过程必然会调用特定的一组函数,因此这组特定函数的调用情况可以作为判断恶意代码的一个依据。JStill将函数调用分为了原生函数(native function)、内置函数(built-in function)、DOM方法以及用户定义函数四类。JStill总结了恶意代码在函数调用上与良性代码的差别,包括:恶意代码会从静态的角度隐藏一些在反混淆中常用的函数的参数,使得这些参数不会被静态分析工具获取或分析,因为参数通常会暴露代码的恶意行为;恶意代码会隐藏函数定义,使得从静态分析的角度解析不到函数的定义等。JStill主要关注基于编码/加密的混淆恶意代码的检测。
Gorji等[6]提出了一个基于内部函数调用序列检测混淆恶意代码的方法。该方法的检测分为两个阶段。首先是行为收集阶段,通过在浏览器中加载真实的恶意的网页,利用浏览器的调试工具收集函数调用信息。然后基于正则化的编辑距离将具有相似函数调用序列的网页聚集为等价类,并且为每个等价类生成相应的行为签名(behavior signature)。完成行为收集后,进入检测阶段。一个网页只有在它的函数调用序列至少和一个已知的行为签名匹配时,才会被判定为恶意的。实验表明,该方法生成的行为签名可以有效检测出混淆的恶意JavaScript代码,并且具有较低的误报率。
AbdelKhlek等[9]提出了一个JavaScript代码反混淆工具JSDES。JSDES利用自主构建的Mozilla的SpiderMonkey JavaScript解释器作为JavaScript执行环境的仿真器。JSDES在仿真器中实现了JavaScript恶意代码中常用的函数,并根据代码的运行日志分析各类函数的执行信息,对恶意代码实现反混淆。
2.2 代码混淆技术
2.2.1 数据混淆(Data Obfuscation)
数据混淆通常在代码中将字符串分割成多个变量或子串然后再拼接成原始字符串的策略来对原始字符串进行伪装。拼接可通过调用document.write, eval等函数实现。攻击者还可能通过改变变量的顺序来给代码分析带来更多困难。
2.2.2 编码混淆(Encoding Obfuscation)
编码混淆的方法大体上有两种。第一种是将字符转换成对应的ASCII或Unicode编码值,以便绕开静态分析程序的检测。第二种是利用自定义的加密函数来对原始代码编码。攻击者编写一对加密和解密的函数,使用加密函数将原始代码加密,并在代码执行时调用解密函数将代码解密为原始代码
2.2.3 标识符重命名混淆(Variable and Function (Re-)Name Randomization Obfuscation)
标识符重命名混淆指在不改变程序语义的条件下对标识符做局部或全局的替换,替换后的标识符通常为随机生成的字符串,可读性大大减弱。标识符重命名混淆通常用于加大手工代码分析的难度[9]。
2.2.4 逻辑结构混淆(Logical Structure Obfuscation)
攻击者可以通过改变代码逻辑结构的方式来改变程序的控制流。一个典型的例子是在运行时插入一段永远不会被执行的代码。
2.2.5 动态生成和运行时计算混淆
动态生成(D-Gen, Dynamic Generation)和运行时计算(R-Eval, Runtime Evaluation)是恶意JavaScript代码混淆的常用手段[5]。D-Gen可以在运行时从文本中生成代码,R-Eval可以将字符串表达式转成代码。而恶意代码检测工具通常会在检测过程中忽略字符串常量,从而使得混恶意代码绕过检测。D-Gen和R-Eval这两个JavaScript语言的特性提供了从字符串到代码的转换方法,因此常被用作恶意代码的混淆的手段。
然而,D-Gen和R-Eval特性也常在正常代码中使用,如条件加载,即只在相应的条件满足时加载对应的组件。如JavaScript代码包含只能在运行时取得的信息时(如用户输入、客户端与服务端的交互等),可以借助R-Eval实现条件加载。因此,正常代码和恶意代码因压缩和混淆技术的广泛使用而变得更加难以区分。
3 相关定义
本文将函数调用信息形式化为函数调用关系图和函数调用序列。
IBM Watson实验室在其开发的的WALA静态开源分析框架中实现了调用图的构建,并针对JavaScript语言的特性,开发了将JavaScript代码标准化的工具JS_WALA,在此基础上实现了面向JavaScript语言的基于指针分析的调用图构造分析以及基于域的调用图构造分析[10]。
刘星[11]等人提出了一种基于函数调用图的恶意代码相似性分析方法,通过函数调用图的相似性距离来度量两个恶意代码函数调用图的相似性,进而分析得到恶意代码的相似性。
定义 1:函数调用关系图G=(V,E)
函数调用关系图G是一个二元组,其中V代表图中的所有节点,E代表图中的所有边。每个节点v代表一个函数,每条边e:v->w代表一个函数调用关系,令v,w为两个函数,若在v的定义中出现了对w的调用,则称v调用了w,v与w具有调用关系。
函数调用关系图反映了函数之间的调用关系,对于简单的代码混淆,函数名可能会被混淆器重构,但函数之间的调用关系保持具有某种不变性,因此可以利用函数调用关系图检测混淆前后的代码。
以代码1为例,其函数调用关系图如图1所示。
代码1
function f0() {
f1();
}
function f1() {
f2();
f3();
}
f0();
f1();

图1 函数调用关系图示例
定义 2:函数调用序列 Seq
函数调用序列Seq是一个由函数组成的线性序列,其中相邻的函数v, w在源代码的语法树中具有中序遍历的顺序关系。
张志华[12]等人提出的函数调用路径用于解决回归测试中的路径爆炸问题,将函数的业务流程抽象为函数调用路径,简化了对函数执行过程的描述。
函数调用序列表达了函数在统一代码片段中的书写顺序,对于简单的混淆的,函数调用序列具有不变性,因此可以用于匹配混淆前后的代码。
代码1的函数调用序列如下图所示:
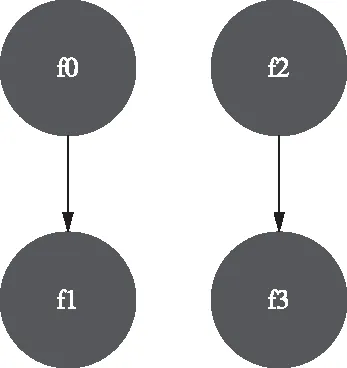
图2 函数调用序列示例
4 基于Closure Compiler的代码混淆
4.1 Closure Compiler的混淆方法
Closure Compiler是Google开发的一个JavaScript代码优化和压缩工具,经优化和压缩后的JavaScript代码可以被浏览器更快地加载和执行。与一般的JavaScript代码编译器不同的是,Closure Compiler并不是将JavaScript编译为机器码,而是将它编译为运行更快的JavaScript代码。Closure Compiler通过解析JavaScript代码,移除无用代码(dead code)然后重写并压缩有用代码,并且检查语法、变量引用以及类型,对JavaScript代码中常见的陷阱(pitfalls)给出警告。
Closure Compiler提供了三个级别的编译选项。分别是只移除空白符、简单优化和高级优化。
1) 只移除空白符(Whitespace-only)的编译等级会将代码中的所有注释和换行符、不必要的空白符和无关的标点(如多余的括号或分号)等字符移除。此等级输出的JavaScript代码在功能上和原始代码等价。
2) 简单优化的编译等级首先进行和只移除空白符的编译等级相同的处理,然后在表达式和函数层级进行优化,包括将局部变量和函数参数名重构为更短的标识符。这样的重命名可以在一定程度上减小代码的字节数。由于此等级只对函数内部的局部变量和参数进行了重命名,因此不会影响到此代码和其他JavaScript代码的交互。
3) 高级优化的编译等级首先进行前两个等级的处理,然后加入一些更复杂的全局优化,使得输出的代码的体积进一步压缩。高级优化会移除无用代码(dead code),此功能在引入庞大的外部库后打包代码时非常有用,可以对没有用到过的库中的代码进行删除以精简代码。高级优化还会对一些函数调用进行“内联”,也就是将函数体展开在函数调用的地方,用以替换函数调用语句。高级优化也会对一些常量进行内联。
4.2 函数调用信息的不变性
通过观察Google Closure Compiler的编译方法,发现简单优化虽然改变了函数和变量的标识符,但函数之间的嵌套调用关系以及顺序执行关系具有某种不变性,由此可以通过提取并比较两份代码的函数调用信息来为代码行为的相似性提供依据。另外,对于一些内置函数的调用,混淆并不会改变函数名,因此JavaScript语言或宿主内置的函数名在混淆前后的不变形也为函数调用序列一致性的检测提供了线索。
本文将函数调用信息形式化为函数调用关系图和函数调用序列,将代码相似性的检测问题规约为图相似度和序列相似度的计算问题。以函数调用关系图和函数调用序列作为代码结构信息的载体。
5 基于函数调用信息的JavaScript代码混淆恶意代码检测方法
本文利用Antlr4构建JavaScript代码解析器,首先进行词法分析,得到token序列,再进行语法分析,得到抽象语法树;然后遍历抽象语法树,并通过在遍历器中设置提取函数调用信息的事件监听器,在遍历的过程中收集函数调用关系图和函数调用序列。最后采用基于图和序列相似度的比较算法计算函数节点的相似度。函数调用信息的提取流程如图3所示。
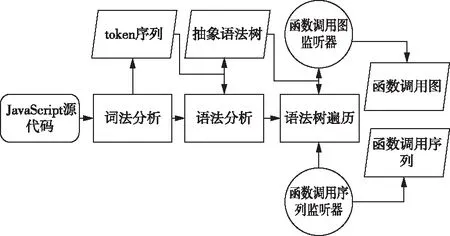
图3 函数调用信息提取流程
5.1 函数调用关系图的提取
函数调用关系图的提取是在遍历到函数调用节点时记录当前的被调函数和调用函数,将相应的节点和边纳入函数调用关系图。
Algorithm Function Call Graph Extraction
Input:
file: JavaScript source file
Output:
graph: Function call graph
tokens=lexer.tokenize(file)
AST=parser.parse(tokens)
listener=FunctionCallGraphListener()
graph=walk(AST, listener)
return graph
FunctionCallGraphListener:
If enterMethodDefinition:
currentFunction=this.method
If enterMethodInvocation:
graph.addEdge(currentFunction, this.method)
5.2 函数调用序列的提取
Algorithm Function Call Graph Extraction
Input:
file: JavaScript source file
Output:
graph: Function call graph
tokens=lexer.tokenize(file)
AST=parser.parse(tokens)
listener=FunctionCallSequenceListener()
graph=walk(AST, listener)
return graph
FunctionCallSequenceListener:
If enterMethodInvocation:
sequence.add(this.method)
return sequence
5.3 函数调用信息相似度的比较
本文对函数调用序列的相似度采用混合的正则化编辑距离计算。对函数名、函数内部特征及函数参数信息分别计算编辑距离,然后取平均值。
6 实验
6.1 实验数据集
本实验采用使用广泛的开源JavaScript库Underscore和jQuery,以及部分Alexa网站发布的网站的代码作为良性的代码数据集,并利用Google Closure Compiler对原始JavaScript代码进行混淆,得到混淆后的对比数据集。
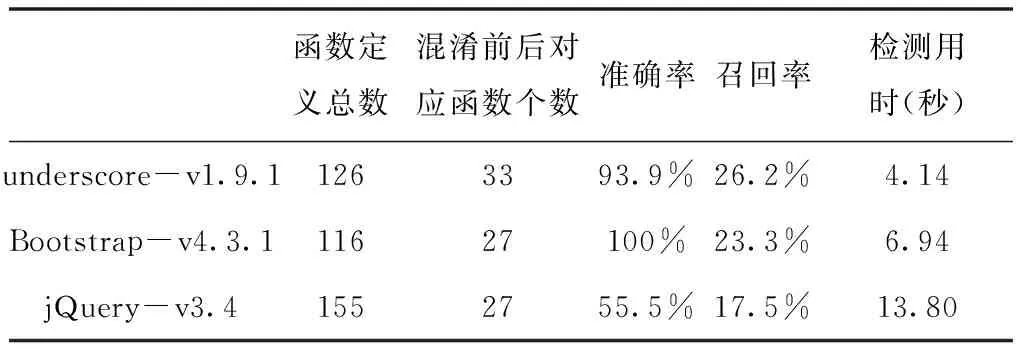
实验原始数据集及静态分析得到的信息如表1所示,原始代码数据来自cdnjs.com。
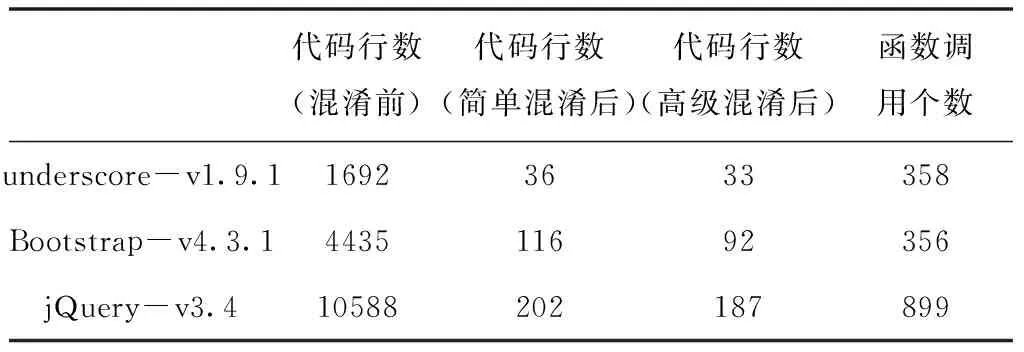
表1 实验数据集统计信息
混淆前后的样例代码如下:
∥ Trim out all falsy values from an array.
_.compact=function(array) {
return _.filter(array, Boolean);
};
∥ Internal implementation of a recursive `flatten` function.
var flatten=function(input, shallow, strict, output) {
output=output || [];
var idx=output.length;
for (var i=0, length=getLength(input); i < length; i++) {
var value=input[i];
if (isArrayLike(value) && (_.isArray(value) || _.isArguments(value))) {
∥ Flatten current level of array or arguments object.
if (shallow) {
var j=0, len=value.length;
while (j < len) output[idx++]=value[j++];
} else {
flatten(value, shallow, strict, output);
idx=output.length;
}
} else if (!strict) {
output[idx++]=value;
}
}
return output;
};
simple级别混淆后的样例代码如下:
_.compact=function(c){return _.filter(c,Boolean)};var flatten=function(c,f,g,a){a=a||[];for(var d=a.length,e=0,k=getLength(c);e advanced级别混淆后的样例代码如下: c.compact=function(a){return c.filter(a,Boolean)};c.flatten=function(a,b){return v(a,b,!1)}; 本文的方法首先分别对混淆前后的代码进行词法和语法分析,并以函数定义为单位将语法树切分为函数子树。然后提取每棵函数子树的调用信息,包括函数调用关系图和函数调用序列。再对混淆前后的函数集合各自携带的函数调用信息进行两两比较,取相似度高于一定阈值的函数对,得到混淆前后函数的对应关系列表。 函数调用信息的相似度根据函数调用序列的三组正则化编辑距离值确定。具体如表2和表3所示。 表2 函数的内部的三组编辑距离 表3 函数内部metric列表 函数内部的metric向量对函数逻辑和结构的反应足够充分,因此对metric向量设置了较高的阈值。而函数名会在混淆后发生改变,因此设置了较低的阈值。函数调用序列因函数名的改变而变得难以确定函数节点的对应关系,因此也设置了较低的阈值。 实验环境为一台具有2.3 GHz Intel Core i5处理器的PC机,内存为16G。实验程序采用Java语言实现。 对于得到的混淆前后函数的对应关系,采用人工评判的方式确认结果。结果统计如表4所示。 表4 实验结果 观察实验结果,发现对于代码规模较小的underscore数据集,找到的函数定义个数反而最多,究其原因,与函数调用信息提取所用的解析器的实现有关。本文在实现解析器时,以underscore数据集作为样例,因此对其中出现最多的函数表达式形式定义的函数支持较好,而忽略了其他两个数据集中函数定义常用的形式。 三个数据集普遍准确率大大高于召回率,这主要由于为函数内部metric设置了较高的阈值。假阳性数据则是因为两个函数名相近(如later与b.after)。 JSNice是一款JavaScript语言的重构与反混淆工具,可以根据代码上下文推测出函数原本的具有语义的名字。本文将混淆后的实验数据用JSNice进行反混淆,发现JSNice对部分混淆后的函数并不能准确推测出原有的函数名,如underscore数据集中的_.where函数,在混淆后被换名为c.Xa,而JSNice给出的反混淆结果中此函数名为_.Xa。 检测用时与代码规模成正比,与JSNice的反混淆过程用时基本相当。 本文分析了常用的JavaScript代码混淆器Google Closure Compiler的混淆手段,针对其中的换名策略,观察到了函数调用关系图和调用序列在结构上保持不变的特点,提出了基于函数调用信息的JavaScript混淆恶意代码的自动检测方法。实验表明,此方法可检测出混淆后的恶意代码和混淆前代码的对应关系,并且在检测效果上优于一般的JavaScript反混淆工具。6.2 实验方法与环境

6.3 实验结果与分析
7 结论
猜你喜欢
商品与质量(2019年34期)2019-11-29 03:25:51
测控技术(2018年5期)2018-12-09 09:04:46
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
湘潭大学自然科学学报(2018年2期)2018-05-28 09:04:38
电脑知识与技术(2017年32期)2017-12-15 10:22:23
中国新通信(2017年1期)2017-03-08 03:12:21
信息安全研究(2016年4期)2016-12-01 06:07:05
