
基于信任模型的中医药方剂相似度计算方法
2021-11-17 07:09:20金涛伟冷荣伟
计算机仿真 2021年2期
金涛伟,冷荣伟,张 迪,刘 畅
(长春中医药大学,吉林 长春 130117)
1 引言
中医学方剂即传承数千年中医药知识的主要知识来源,其已经被收录中医药图书高达上万种,而方剂就是中医药领域内最为关键的研究内容,面对海量的方剂数据,要想得到所需求的信息,并非易事。信息技术的逐渐发展,使得人们能够把各种中医药方剂放置在数据库内永久存储。当前已经存在数十个中医药大学与研究所,构建了不同规模的中医药信息数据库。但由于中医药方剂数据内会出现两种方剂或多种方剂,并且这些方剂会出现十分相似的状态,例如一种方剂和另外一种方剂相比,缺少一味药剂组成成分,其它的成分则完全相同,所以,这些方剂之间存在某种关联或潜在关系。当前,中医药方剂相似度模型,大致是通过功效与组成成分两个方面进行相似度的分析。但只通过这两方面并不能有效且精确地获得其相似度数值,过程也较为复杂。
因此,本文提出了一种基于信任模型的中医药方剂相似度的计算方法。
2 信任模型下中医药方剂相似度计算
信任模型实际上即依靠历史记录与其它评测信息对中医药方剂的信任值进行计算处理,通过信任值计算,为方剂剔除冗余成分。信任反应即一种方剂对另一种方剂的相似度综合评价,通过评价对方剂的将来提供可靠的预测。
2.1 直接信任计算
直接信任度即指方剂凭借自身的直接交互经验,而获得的对其它方剂的信任程度。
1)满意度评测:在两种方剂完成一次交互后,依靠方剂主成分评测方剂次成分提供的药剂,通过s描述,s∈[0,1],其中,0代表完全不同,1代表完全相同,s的值越大,就代表相似度越高。
2)事务干扰因子:在中医药方剂内的各种成分一般不会出现变化,而冗余[1]成分如果添加在主体方剂中,可能会导致方剂的治愈效果降低。所以,在计算方剂信任度时加入事务干扰因子,通过TF来表述事务的关键程度。如果TF值越大,就证明事务对方剂的信任值干扰越大,反之,该事务对方剂信任值的干扰就越小。TF∈(0,1],其距离通过主体方剂决定。
拟定方剂主成分i与方剂次成分j之间交互[2]的次数是m次,那么方剂主成分i对方剂次成分j的直接信任评测Evalij是

(1)
其中,s(i,j,m)代表方剂主成分i与方剂次成分j的第m次交互时相似度的评价,TF(i,j,m)代表方剂主成分i与方剂次成分j的第m次交互内事务的干扰因子。
3)时间衰减函数:为了精确估算方剂内主次成分的信任度,信任模型还需要考虑时间因素对信任值的干扰。距离目前时间相差不远的信任评测更能够映射方剂主次成分的信任度[3],应给予较高的权重,距离目前时间较远的信任评测对方剂主次成分信任度估算干扰较小,应给予较低的权重。针对这一问题,本文使用时间衰减函数对不同时间段内方剂的主次成分进行信任度的干扰估算。时间衰减函数[4]如下所示

(2)
其中,ρ代表调节因子,0<ρ<1,a>0,T代表方剂目前的时间区段,Tk代表最近一次交互开始的时间区段,λ代表方剂每天划分的时间区段数,fk代表时间区段Tk里交互的时间衰减因子。
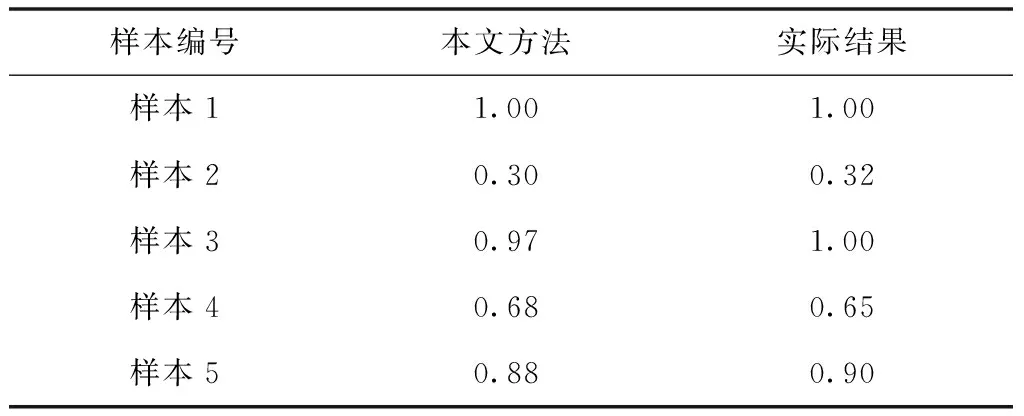
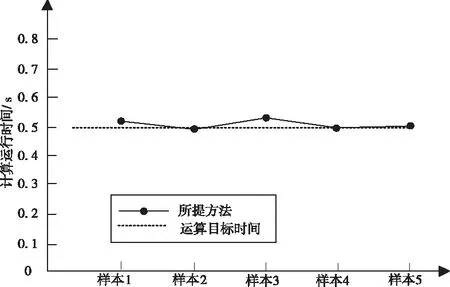
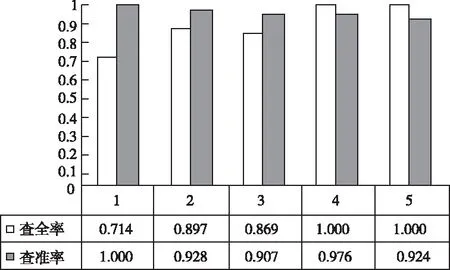
通过式(2)能够看出,时间衰减函数f代表所有时间区段里都存在一种对应的衰减因子,同时0 图1 时间衰减因子变化图 拟定方剂主成分i与次成分j在Tk个时间区段[5]里完成了n次交互,那么主成分i对次成分j的直接信任值TDij就是 TDij=Evalij×fk (3) 其中,Evalij代表主成分i对次成分j的直接信任评测,fk代表时间区段Tk的衰减因子。 推荐信任度TR就是,方剂凭借其它方剂的推荐信息而获得的对某方剂的信任强度。推荐可信度RC就是方剂对另一种方剂所给予的评估信任程度。 评测相似度Simij,在中医学方剂内,所有方剂的推荐可信度都是不同的,可信度高的方剂供给的推荐信息要比可信度低的推荐更为信赖。在进行评估的时候,会更为愿意相信和自身信息相差无几的方剂,所以需要给予较高的权重。评测相似度Simij是为了表示方剂主成分i与次成分j的评测相似度。如果Simij值较大,就证明主成分i和次成分j对剩余成分的看法越一致,就是主成分i与次成分j的相似度较高。本文利用余弦相似度函数对两种成分之间的相似度进行描述,描述的公式如下所示 (4) 其中,C(i,j)代表主成分i和次成分j的公共交互成分集合。 所以,主成分i对次成分j的推荐信任度TRij是 (5) 两种方剂之间的综合信任Tij就是通过期间的直接信任与推荐信任所组成的 Tij=αDTij+(1-α)RTij (6) 认定求信方剂和受信方剂之间的相似度代表期间的综合信任权值,就是 α=BSij (7) 在经验丰富,非常信任自身评测时,能够挑选人为评定的方式。但通常来讲,人为评定会存在较强的主观意识,合理性与科学性不足,因此就需要通过一些比较客观的权重进行侧向评定。 当前的方剂之间信任值进行交互方剂的信任决策大致存在两种: 1)依靠综合信任值的距离挑选交互。 这种方式符合日常的交互习惯,通过挑选信任值最好的两种方剂进行交互,但这种方式存在缺点:信任值较高的方剂总会被选中进行交互,其它方剂交互的机会就会变少,没有机会提升自身的信任值,新的方剂与存在交叉[8]交互历史的方剂比较难出头,信任度较高的方剂获得中医学方剂交互请求较多,压力较大。 2)凭借综合信任值收集随机挑选交互。 如果存在n种备选方剂能够挑选其进行试用,其综合信任值是Tij,那么某种方剂j被挑选进行试用的几率Pj能够通过式(8)进行估算 (8) 随机交互方式在确保信任值较高方剂被选中几率较大基础下,有效地解决了第一种方式所产生的缺点[9],因此使用该方法进行信任决策,确定方剂交互。 通过信任模型得到了方剂间存在的关联结果与信任程度,使方剂相似度的计算更为便捷,但由于方剂的种类较多,并且每种方剂之间的组成成分也各不相同,因此需要通过一种分布形式得到计算方剂相似度的规范化因子。 在得到方剂成分分布的情况下,方剂就能够通过其相应的主题分布进行映射描述[10],估算两种方剂的相似度能够转换为估算主题分布的相似度。一般状态下,通常使用DKL来估算几率分布的尺寸,DKL如下所示 (9) 式中,p与q分别为两种几率分布。因为DKL并不是对称的,就是DKL(p,q)≠DKL(q,p),因此使用DKL的对称方式,其计算公式如下所示 Dr(p,q)=rDKL(p,rp+(1-r)q)+(1-r) DKL(q,rq+(1-r)q) (10) 式中,r代表控制参数。 在中医药领域内,中医学方剂相似度计算里,把文档、主体、词项的三者关联构建转换为方剂、证型、组成成分。所以在中医学领域,LDA为在方剂和组成成分之间以几率的形式构建证型关联[11],同时依靠方剂、证型几率分布估算出方剂和方剂之间存在的相似度。在中医学方剂内所有方剂都是通过一些组成成分形成的,所以,能够直接通过组成成分进行相似度计算,不同于网络文档一样需要对文档进行分词处理。 在中医证型模型内基于LDA的大致方法流程如下所示: 步骤1:把数据放置在LDA主题模型内进行处理,处理流程如下: 1)凭借先验几率P(di)挑选一种中药方剂di。 2)凭借方剂证型的Dirichlet先验分布∂内取样产生中医学方剂di的证型分布θi,就是,证型分布θi,是通过超参数为∂的Dirichlet分布产生的。 3)从证型的多项式分布θi内采集样本产生中医学方剂di的第j种组成成分证型Tij。 4)凭借证型、组成成分Dirichlet先验分布b内采集样本产生证型Tij相应的组成成分分布φi,即组成成分分布φi是通过,超参数为b的Dirichlet分布产生的。 5)从组成成分的多项式分布φi内采集样本[12]的最后生成成分Cij。 步骤2:去除1)内2)方剂相应的证型分布θi,所有方剂通过相应的证型分布描述,对证型分布数据进行两两KL距离DKL(p,q)计算,计算出的值就是两种方剂的相似度。 仿真环境为Intel Celeron Tulatin1GHz CPU和384MB S是D内存的硬件环境和MATLAB6.1的软件环境。 为了证明本文方法的实用性,拟定了两组实验: 1)样本为五种已知相似度重复类型与相似度重复程度的中医方剂,使用本方法进行相似度计算,通过比较已知数据来确定本文方法的计算方式是否可行。实验结果如表1所示。 表1 本文算法的相似度计算结果 通过表1能够看出,通过本文方法计算出的相似度结果,与实际的相似度计算结果相差不大,并且这些误差较小,可忽略不计,不会对实际方剂造成影响。 在此基础上,对相似度计算时间进行记录,并与运算目标时间进行了对比,记录结果如图2所示。 图2 本文方法相似度计算时间记录结果 如图2所示,五种方剂相似度计算时间与运算目标时间吻合度较高,具有较高的实际应用性。 2)为了定量评测相似重复记录检测效果对各种方剂相似度计算的干扰,建造实验数据生成器,通过1)内的五种方剂,使用本文方法进行相似重复记录检测,凭借查准率与查全率两种阈值对检测结果进行评定。查准率与查全率分别通过式(11)与(12)进行计算。 (11) (12) 式中:Z为检测出的相似重复记录总量;Q为相似重复记录的总量;Y为系统中的相关信息的总量。 结果如图3所示。 图3 本文算法得到的检测结果 通过图3能够看出,在查全率上,本文方法的指标都能够稳定在0.700~1.000之间,这是因为本文方法通过构建信任模型来计算方剂之间的信任值,通过信任值确定方剂指标间存在的误差。而在查准率指标上,能够看出,查准率一直维持在1.000~0.900之间,因为方剂数量的增加,查准率会出现轻微的浮动,但幅度基本都维持在90%以上不会对方剂造成严重的影响,证明本文方法能够对中医方剂进行较为精确的搜索,不会出现遗漏和误差较大的问题,并且不会因为重复记录检测的效果干扰到方剂之间的相似度计算结果。 为了剔除中医学方剂内存在的冗余信息,本文提出了一种基于信任模型的中医药方剂相似度的计算方法,通过构建信任模型计算方剂之间存在的关联,进行相似度计算。但信任模型需要进行多次迭代才能够达到期望阈值,一旦计算量过大就会导致模型构建时间增加,降低计算效率,因此下一步的研究即:优化信任模型,使模型在构造阶段就能够保持平稳状态,减少计算量。
2.2 推荐信任估算

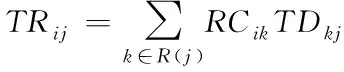
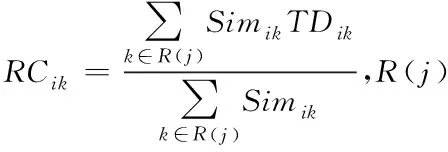
2.3 综合信任估算
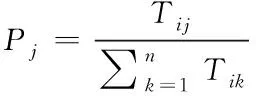
2.4 方剂相似度计算
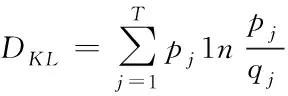
3 仿真证明
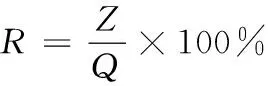

4 结束语
猜你喜欢
中国民间疗法(2021年1期)2021-04-20 02:30:58
家庭影院技术(2021年2期)2021-03-29 07:19:02
家庭影院技术(2021年1期)2021-03-19 05:14:58
中国民间疗法(2020年22期)2021-01-07 07:40:06
中国自行车(2018年11期)2018-12-03 08:20:30
中成药(2018年6期)2018-07-11 03:01:24
环球时报(2018-01-23)2018-01-23 05:25:53
长春中医药大学学报(2017年1期)2017-04-16 05:56:45
中国自行车(2017年1期)2017-04-16 02:54:06
计算机工程(2015年4期)2015-07-05 08:27:45
