
融合短文本层级注意力和时间信息的推荐方法
2021-11-17 08:27:24邢长征郭亚兰张全贵赵宏宝
计算机与生活 2021年11期
邢长征,郭亚兰,张全贵,赵宏宝
辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛125105
互联网和信息技术的突飞猛进,使用户和项目数量、种类大规模增长,同时也使信息过载问题日益严重,而推荐系统的出现能够有效缓解信息过载问题,在购物、医疗和教育等领域被广泛应用。
在推荐系统中,如何准确学习用户和项目表示对于推荐项目是非常重要的[1]。经典的协同过滤推荐算法基于用户历史记录(显性评分、点击率等信息)为用户和项目进行建模[2-5]。但协同过滤算法在推荐过程中不具有可解释性且存在冷启动问题,因此,通过用户对项目的显性评分等信息为用户和项目准确建模存在一定的困难。
互联网和信息技术的发展使越来越多的数据能够被感知获取。包含图像、文本、标签在内的多源异构数据蕴含着丰富的用户行为信息及个性化需求信息,融合了多源异构辅助信息的混合推荐方法由于能够缓解传统推荐系统中的数据稀疏和冷启动问题,越来越受到重视[6]。用户对项目的评论包含丰富的信息,不仅能够反映项目的部分特征,还能够表达用户偏好。不同用户在同一项目下的评论能够反映出该项目的特征;同一用户对不同项目的评论文本潜在地包含用户的偏好,提供用户的丰富信息,因此,当用户对项目显性评分数据稀疏时,用户对项目的评论文本可以显著加强用户和项目的表示学习,对提高推荐系统的性能是非常有帮助的[7]。
神经网络可以对评论文本进行深层次理解,保留评论文本的上下文语义信息。因此,整合评论文本为用户和项目建模做推荐的深度学习技术已经引起了越来越多的关注[7-12]。其中,Zheng 等人[7]提出的DeepCoNN(deep cooperative neural networks)模型,Chen 等人[8]提出的NARRE(neural attentional regression model with review-level explanations)模型,Seo 等人提出的D-Attn[9]模型(dual attention based model)和Wang等人提出的WCN[10]模型(word-driven and context-aware networks),具有优越的推荐性能,但是仍然存在一些缺陷:(1)DeepCoNN[7]、NARRE[8]、D-Attn[9]和WCN[10]将多条评论文本连接成一个长文档,采用基于局部视野的卷积神经网络进行编码,丢失的长距离特征较多。(2)DeepCoNN[7]、D-Attn[9]、WCN[10]模型将文档中的不同单词、评论视为同等重要;NARRE[8]模型应用评论级注意力来区分不同评论对用户和项目建模的重要性。实际上,不同的单词、评论在用户和项目建模时有不同的贡献。(3)现有的神经网络推荐模型,对用户嵌入和项目嵌入通过简单的连接或逐元素的乘积,只考虑了用户和项目属性的低阶交互关系。(4)上述模型都忽略了时间因素对用户偏好预测和项目特征提取的影响,随着时间的变化,用户的兴趣、偏好以及项目的特征也会不断变化。
基于以上几点原因,本文提出基于深度学习的推荐模型,融合短文本层级注意力和时间信息的推荐方法(recommendation method integrating review text hierarchical attention with time information,RHATR)。该方法具体内容如下:
(1)充分利用用户对项目的评分和短文本信息,短文本信息可展示用户对项目所有特征中某个特征的喜欢与否;评分信息可以反映用户对某一项目的感兴趣程度。通过对单条评论文本应用单词级注意力,挖掘单条评论文本中情感词和关键词等有效信息,学习用户和项目表示;对含有时间因素的用户评论集和项目评论集分别应用评论级注意力,提取有效的评论,进一步学习用户和项目动态表示。
(2)将交互建模为用户嵌入和项目嵌入的点积用外积代替。外积运算过程中,不仅包含内积结果,还含有更多的特征。充分考虑了用户属性和项目特征的高阶交互相关性,使得交互更具有表达性和语义上的合理性。
1 相关工作
最近几年,通过用户对项目的评分信息为用户做推荐的方法有基于矩阵分解和深度学习两种。矩阵分解是主流的协同过滤方法[2,5,13-14],例如,Koren 等人[2]提出了基于奇异值(singular value decomposition,SVD)矩阵分解,从用户和项目的评分矩阵来学习用户和项目的潜在表示。Salakhutdinov 等人[5]提出基于概率的矩阵分解模型(probabilistic matrix factorization,PMF),将评分矩阵分解为两个低维矩阵的乘积,分别表示用户属性和项目属性。由于用户和项目之间的关系由简单的几个因素线性组合决定,只能提取模型的浅层次特征。李婷等人[15]提出了一种将用户历史行为归一化为用户对项目的评分的方法,从而缓解显性评分稀疏性问题,使用改进的皮尔逊相关系数(Pearson correlation coefficient,PCC)计算用户之间的相似性,并利用增量更新算法计算当前用户和其他用户之间的相似性,而不是所有的用户。该方法很好地应用在个性化网站上。但是基于用户的增量协同过滤算法只能提取用户偏好的浅层次特征。
随着深度学习的发展,为了挖掘模型的深层次特征,基于深度学习的推荐方法被广泛应用于推荐系统。Wu 等人[16]提出一种协同去噪自动编码器(collaborative denoising auto-encoders,CDAE),该模型利用可见层和隐藏层两层神经网络来学习用户和项目的分布式表示,为神经网络在推荐系统中的应用提供了广阔前景。Li 等人[17]提出边缘化去噪自动编码器(marginalized denoising auto-encoder,MDA),将深度学习和矩阵分解相结合,来提取用户和项目的深层次特征。
上述方法仅利用用户对项目的评分数据,从评分矩阵中来学习用户和项目的表示,忽略了隐含丰富语义信息的评论文本。信息技术的发展造成了评分数据的稀疏性问题,该问题制约着协同过滤模型的推荐性能。大型商务网站的用户和项目数量非常庞大,用户对项目的评分一般不超过项目总数的1%,两个用户共同评分的项目更是少之又少,数据稀疏性问题是影响推荐系统性能的关键因素。为了缓解数据稀疏性问题,利用评论文本进一步加强用户和项目表示,可以有效提高推荐系统性能。
融合评论文本为用户和项目建模成为近年来的研究热点。从评论文本中学习用户和项目表示已经引起了越来越多的关注[1,7-9,18-22]。许多现有方法从评论中提取主题为用户和项目建模。例如,McAuley 和Leskovec[18]提出隐因子作为主题的方法,使用主题模型技术狄利克雷概率模型从评论中去发现用户和项目的潜在方面。最近几年,一些基于深度学习的方法从评论文本中学习用户和项目表示做推荐[1,7-9,19-21]。Zheng 等人[7]提出的深度协作神经网络(DeepCoNN)模型,由两个并行卷积神经网络(convolutional neural network,CNN)组成,分别从用户评论集和项目评论集挖掘用户偏好和项目特征,从而学习用户和项目表示,很大程度上提高了推荐系统的性能。DeepCoNN模型的用户(项目)评论集是由评论连接得到的一个长文档,训练中要拟合目标用户对目标项目的评分时,目标用户对目标项目的评论包含在文档中。实际中,预测目标用户对目标项目的评分时,一般是得不到目标用户对目标项目的评论,存在一定的不合理性。Catherine和Cohen[19]在DeepCoNN 模型的基础上提出TransNets方法(transformational neural networks)来学习用户和项目表示,TransNets 方法在拟合目标用户对目标项目的评分时,将目标用户对目标项目的评论从文档中删去,利用卷积神经网络得到用户特征向量和项目特征向量表示。这些模型将同一个用户/同一个项目的评论文本连接成一个文档,将文档中的不同评论视为同样重要,忽略了文档中不同单词、不同评论对语义表示的重要性。实际上,不同的单词、评论在用户和项目建模时往往有不同的贡献。Chen 等人[8]提出的NARRE 模型,对同一个用户/同一个项目的评论集采用注意力机制挖掘有效的评论,但在利用卷积神经网络(CNN)进行文本卷积处理时,采用最大池化操作,丢失了评论文本中一些重要信息,因此评论文本中的语义信息不能有效提取。另外,张祖平等人[23]提出了一种基于用户历史行为融合TextRank 和Word2Vec 的推荐方法,通过深度学习技术挖掘用户行为序列间的相似关系,但Word2Vec对用户行为进行训练时,相似语境中的单词具有相似的语义信息,训练结果不受单词上下文顺序的影响,不考虑句法和语法信息。邢长征等人[24]在DeepCoNN和NARRE 的基础上提出了RHAOR 模型(recommendation method integrating review text hierarchical attention with outer product),该模型利用两个并行的神经网络通过主题级和评论级注意力网络对用户和项目评论集进行处理。上述方法忽略了用户偏好和项目特征会随时间而变化。
用户兴趣和项目特征并不是一成不变的,文献[25]指出用户未来的兴趣偏好主要受其近期兴趣的影响,也有文献[26]指出用户的部分偏好在时间的影响下,具有季节性或者周期性的特征,根据时间和用户历史行为的不同为用户进行动态推荐是有助于提高推荐系统的性能的。因此,考虑用户的时间信息特征,根据时间和用户状态的不同进行动态推荐是有必要的。
信息种类的不断更新,使用户偏好随着时间的变化也在不断变化,用户的偏好包括长期偏好和短期偏好。长期偏好反映用户的真实兴趣[27],短期偏好常与最新更新的项目相关联。时间因素对用户偏好和项目特征存在一定影响,如图1 所示,某用户在2010 年9 月7 日对电影Gator Girl的评分为1 分,而该用户在2010 年11 月8 日对同一部电影的评分为5分。用户在不同的时间观看同一部电影给出了不同的评分和评论,因此在为用户做推荐时,应考虑时间因素对用户偏好的影响。粗略统计,同一用户在不同时间对同一项目进行了不同的评分和评论的数据在Movies_and_TV 数据集中占7.2%。由此可见,在提取用户偏好的时候,应该考虑时间因素的影响。

Fig.1 Examples of original reviews图1 原始评论示例
为了进一步加强用户和项目的表示学习,捕捉用户偏好和项目特征的动态变化,从而提高推荐系统性能,本文提出融合短文本层级注意力和时间信息的推荐方法(RHATR),对单条评论文本应用单词级注意力,来提取单条评论文本中的情感词和关键词等有效信息。对带有时间因素的用户评论集和带有时间因素的项目评论集分别应用评论级注意力网络,来关注近期有效的评论文本。将交互建模为用户嵌入和项目嵌入的点积用外积代替,挖掘用户和项目属性的高阶交互关系。
2 融合短文本层级注意力和时间信息的推荐方法(RHATR)
2.1 评论文本的层级注意力
评论文本的层级注意力包括两部分:第一部分是对单条评论文本中的单词应用单词级注意力,最终得到单条评论文本的编码;第二部分是对用户评论集和项目评论集分别应用评论级注意力,来获取用户对评论文本的偏好和项目与评论文本之间的相关性,并通过时间信息挖掘时间因素对用户偏好和项目与特征的影响,最终得到用户和项目编码。整体网络架构图如图2。
2.1.1 评论文本编码
评论文本编码单元用来从单词中学习评论文本表示。从图2 中可以看出,评论文本编码单元主要有三层。第一层为单词嵌入,将单条评论文本中的单词转化为序列表示;第二层为单词级注意力网络,采用自注意力机制对单条评论文本中的每个单词向量表示执行关注,得到单条评论文本的单词级注意力向量表示;第三层为两个单向的长短期记忆网络(long short-term memory,LSTM),为了在单词级注意力向量表示中获得相邻单词间的某种依赖关系,最终得到评论文本表示向量。
第一层为单词嵌入层,将单词序列转换为包含这些单词语义信息的低维稠密向量。单条评论文本r由M个单词[w1,w2,…,wM]组成,其中wM表示第M个单词。通过采用GloVe 在维基百科语料库中预训练嵌入,M个单词组成的单条评论文本r用单词嵌入表示:

其中,eM是D维嵌入向量,词嵌入矩阵E∈RM×D,表示为2D矩阵,其中M表示每条评论文本中的单词个数,D表示单词嵌入维度。
第二层为单词级注意力网络。在为用户和项目建模时,每条评论文本中,不同的单词包含的信息量以及重要性不尽相同。例如,在Amazon Instant Video数据集中的一条评论文本“Enjoyed some of the comedians,it was a joy to laugh after losing my father whom I was a caregiver for”,“Enjoyed”和“comedians”这两个单词明显比类似“I”和“for”等单词更具有信息量,更能反映出用户对项目的主观意见以及项目的特性。因此,为了用户和项目建模更加有效,利用单词级注意力机制来选择和关注重要的单词。

Fig.2 Network architecture diagram图2 网络架构图
对于由M个单词组成的单条评论文本,每一个单词对于用户和项目建模的重要性不同。为了提取评论文本的重要信息,采用自注意力机制对单词嵌入表示向量E执行R次关注,得到单条评论文本的单词级注意力向量表示A:
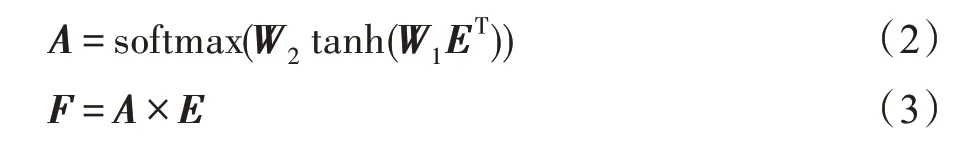
其中,A表示通过注意力网络的计算得到每个单词在每条评论文本中的重要性,大小为R×M。W1∈RV×D,W2∈RR×V是权重矩阵,V是可以任意设置的超参数。tanh()和softmax()函数均为非线性激活函数。F表示保存对每个单词的关注度不变的情况下,降低对不相关单词的关注,F∈RR×D。
第三层为两个单向的长短期记忆网络(LSTM)。针对循环神经网络(recurrent neural networks,RNN)在长序列训练过程中存在梯度爆炸和梯度消失问题,LSTM 由于其自身设计的特点,适用于对具有时序和依赖性的文本类数据进行建模。对于评论文本中每个单词都不是孤立存在的,都依赖单词的上下文信息。而LSTM 能够有效捕捉整条语句的上下文信息,加强对上下文的理解。本文应用LSTM 获取单条评论文本中相邻单词间的某种依赖关系,将矩阵F表示为[f1,f2,…,fR],使用两个单向的长短期记忆网络处理评论文本:


其中,H为评论文本表示向量,H∈RR×2I。
BI-LSTM 很好地利用了评论文本的上下文信息进行处理,但得到的特征矩阵H的列维度较大,包含的信息过多。通过卷积神经网络(CNN)进行降维处理,从而找出关键特征。因此,采用CNN 来处理不仅可以保持嵌入矩阵的上下文信息,而且可以对矩阵H进行局部卷积,从而达到降维目的,减少冗余维度,即非关键信息对模型建模的影响,使模型学习难度降低。
最近几年,许多基于深度学习的文本处理方法比传统的方法取得更好的性能,例如TextCNN 和TextRNN。本文在DeepCoNN 模型上进行改进,在DeepCoNN 中,CNN 采用池化层,由于池化层在对嵌入矩阵进行下采样的过程中,仅仅保留了局部接受域的最大值,会丢失特征矩阵的关键信息。因此,本文利用CNN 对评论文本向量H进一步提取特征时不采用池化层,而采用卷积层。
设卷积层由m个神经元组成,每个神经元与卷积核K∈Rτ×2I相关联,对嵌入矩阵H进行卷积运算,第j个神经元产生的局部特征zj表示为式(8):

其中,bj是偏置项,*是卷积操作,relu 是非线性激活函数。

其中,W∈R1×(R-τ+1)表示权重矩阵,bj∈R1表示偏置项。
将m个神经元的输出串联,得到单条评论文本的特征向量[o1,o2,…,om]。同理,最终得到用户评论集的特征向量α:

其中,ouP表示用户u的第P条评论的特征向量。
2.1.2 用户/项目编码
用户/项目编码单元是基于用户评论/项目评论表示,用来进一步加强用户/项目表示。在为用户和项目建模时,同一个用户/同一个项目的不同评论往往能够反映出不同的用户偏好和项目特征。而且用户的偏好和项目与评论文本之间的相关性会随时间的改变而变化。
因此,本文通过对含有时间因素的用户评论集和项目评论集采用评论级注意力网络来进一步加强用户和项目表示。采用文献[8]提出的评论级注意力方法挑选评论集中有效的评论文本。以用户评论集为例,用户/项目表示的目标是在用户u的评论中选择关键评论特征,并将这些特征线性组合来表示用户u。注意力网络的输入包括用户u的第P条评论的特征向量、第P条评论的时间和项目ID。添加项目ID 用来标记被用户评论过的项目。
为了衡量时间因素对用户偏好的影响,使用文献[28]提出的自适应指数遗忘函数来定义用户评论的新颖性,如式(12):

其中,α为调整新颖性下降速度的超参数,times(u,r)返回一个非负整数。
对考虑时间信息的用户评论集,注意力网络表示为式(13),得到用户评论集中用户对每条不同评论文本的偏好程度:
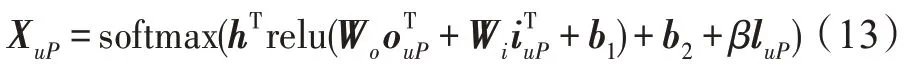
其 中,Wo∈Rl×m,Wi∈Rl×m,b1∈Rl×1,h∈Rl×1和b2∈R1×1属于模型参数,l为注意力网络的中间层大小,β为用于调整时间因素对用户和评论文本相关性影响的超参数,XuP表示第P条评论对用户u的特征集贡献。
在获得每个评论的注意力之后,用户u的特征向量加权和表示为式(14):

其中,P为用户评论集中评论文本的个数。Ou为基于评论级注意力的输出向量,通过区分每条评论的贡献,并在向量空间中表示用户u的特征。
将Ou传递到全连接层,计算用户评论集的k维特征向量表示Xu:

其中,权重矩阵Wo∈Rk×m,b0∈Rk。
2.2 评分预测
对于得到的用户和项目表示Xu、Xi,采用外积交互层型[29]来获取不同特征维度间的高阶交互信息,得到用户特征向量和项目特征向量的外积特征交互图;在外积交互图上利用多卷积隐藏层来提取更高抽象级别的特征表示;最后采用基于矩阵分解算法的潜在因子模型进行评分预测。
外积交互层:已知得到的用户评论集特征向量Xu和项目评论集特征向量Xi,在同一向量空间中,将用户ID 嵌入、项目ID 嵌入分别与用户评论集特征Xu、项目评论集特征Xi联合来表示用户特征嵌入Pu和项目特征嵌入Qi,如式(16)、式(17):

其中,pu和qi分别表示用户ID 嵌入和项目ID 嵌入,用来唯一标识参与评分预测的目标用户和项目。Xu和Xi分别表示用户评论集特征和项目评论集特征。
对用户特征嵌入Pu和项目特征嵌入Qi进行外积交互,得到一个外积交互图E,如式(18):

其中,E是k×k的矩阵。
多卷积隐藏层:本文采用多卷积隐藏层来从上述矩阵中挖掘更抽象级别的特征表示。对E进行卷积处理,第i层的如下:

其中,K′表示卷积核,*表示卷积运算,bi′表示第i层的偏置项。
最终输出的张量大小为1×1×n,通过调整维度得到向量V。经过式(21)计算多卷积隐藏层的输出z。

其中,We表示权重矩阵,大小为1×n;be表示偏置项,大小为1×1。
评分预测层:本文利用基于矩阵分解算法的潜在因子模型,来预测用户u对项目i的评分Ru,i,如式(22):

其中,z表示多卷积层的输出,反映用户对项目的局部偏好,bu和bi分别表示用户和项目的偏置项,反映了不同用户、不同项目对评分数据的影响;μ表示全局偏置项,为所有评分数据的平均值,反映了在不同数据集上,用户评分的差异。
2.3 网络模型训练
本文的主要目标是进行评分预测,将其视为回归任务,均方误差(mean square error,MSE)用于网络模型训练。目标函数如式(23):


当模型欠拟合时,只需要调节正则化因子λ,调小甚至置零;过拟合时将其调大。
3 实验
本文实验环境的操作系统是Ubuntu16.04,显卡GTX1080Ti,CPU 型号E5-2673v3 48 核64 GHz。通过tensorflow-gpu1.14.0 和python3.6 的深度学习库来实现。
3.1 数据集
本文使用包括用户评论、评论时间和评分信息的4 个公开数据集来验证模型的性能。其中3 个数据集来自Amazon 的5-core 项目评论数据集(http://jmcauley.ucsd.edu/data/amazon),分别是Amazon_Instant_Video、Toys_and_Games、Kindle_Store。另一个数据集来自Yelp Challenge 2017(https://www.yelp.com/dataset_challenge)的餐厅评论数据集。实验仅保留每个用户的9 条评论和每个项目的36 条评论。表1 总结了每个数据集的用户总数、物品总数、评论总数。这些数据集的评分在区间[1,5],每条评论均有相应的用户评论时间。
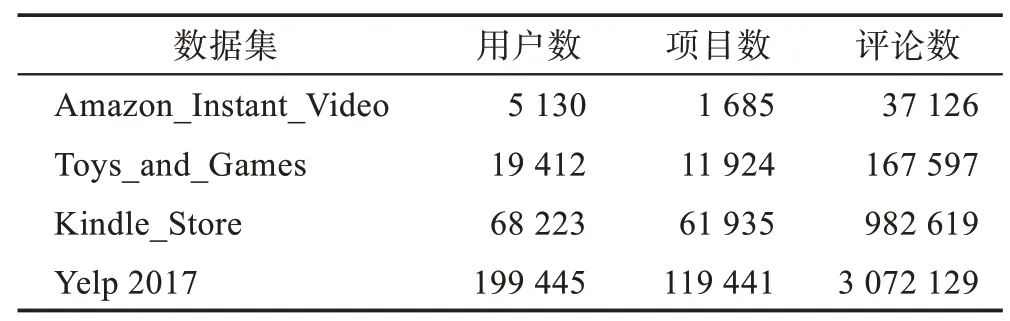
Table 1 Related information of datasets used in experiments表1 本文实验数据集的相关信息
3.2 评价指标
实验采用均方根误差(RMSE)作为评价指标。当评分预测结果为实值,均方根误差为评分预测值Ru,i与真实值误差的平方和与所有测试实例数目N比值的平方根,如式(25)。均方根误差用来反映推荐算法在评分预测中的准确性。均方根误差越小,模型的性能越好;反之,均方根误差越大,误差的离散度较高,模型的性能越差,反映了在评分预测中,评分预测值偏离真实值较大。
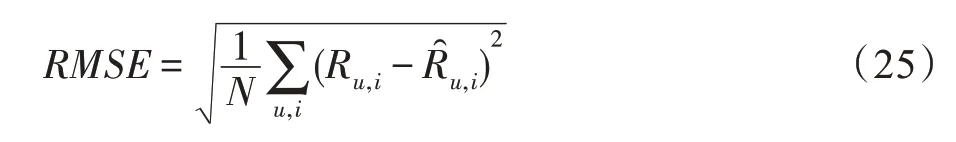
3.3 性能评估
将提出的模型与以下传统的模型进行对比。
(1)概率矩阵分解模型(PMF)[5]:仅利用用户对项目的评分信息,通过矩阵分解为用户和项目的潜在因子建模。
(2)非负矩阵分解模型(non-negative matrix factorization,NMF)[4]:仅利用评分矩阵信息,考虑用户对项目的评分均为正值,主要特征在于分解后的矩阵元素都是正的,来学习用户和项目表示。
(3)HFT 模型(hidden factors as topics)[22]:利用评论文本和评分共同推荐,通过评分矩阵分解和LDA(latent Dirichlet allocation)为用户和项目建模,没有捕捉单词的上下文语义和语序。
(4)卷积矩阵因式分解模型(convolutional matrix factorization,ConvMF)[30]:有效利用项目评论文本的上下文信息,将卷积神经网络(CNN)融合到概率矩阵分解(PMF),使用CNN 来提取项目评论文档的上下文特征。
(5)深度协作神经网络模型(DeepCoNN)[7]:同时利用用户和项目评论文本信息,采用两个并行的CNN 网络分别从用户评论集和项目评论集中来学习用户偏好和项目特征。
(6)Attn+CNN 模型[21]:基于注意力的CNN,利用评论文本和评分信息做推荐,使用CNN 并对评论文档中的单词施加注意力来学习用户和项目的表示。
(7)NARRE 模型[8]:利用用户对项目的评分和评论文本信息进行推荐。该模型在DeepCONN 模型的基础上,考虑到不同的评论对于用户和项目建模重要性不同,将注意力机制引入到模型探索评论文本的有效性,并且选取有效的评论来提供模型的可解释性。
3.4 实验设置和参数选取
实验中,单词的嵌入采用GloVe 在维基百科语料库中预训练嵌入来初始化词嵌入矩阵。每个数据集随机选择80%的用户-项目对用于训练,10%用于验证,10%用于测试。每个实验独立重复3 次,每次取RMSE 的最优值。最后结果为3 次实验RMSE 最优值的平均值。参数的调整范围如表2 所示。

Table 2 Search range of model parameters表2 模型参数查找范围
实验中,利用网格搜索的方法寻找能够使模型达到最优的参数,在验证集上对参数经过多次调整,得到的最优参数如表3 所示。

Table 3 Selection of model parameters表3 模型参数选取
3.5 实验结果与分析
实验1整体推荐准确度比较
本文提出的模型和现有的模型在4个数据集上的RMSE值如表4所示。通过分析,可以得出以下结论:
(1)仅考虑用户对项目评分信息的传统推荐方法(例如PMF 和NMF 模型),没有使用评论文本信息的其他方法HFT、DeepCoNN、Attn+CNN、NARRE 的推荐效果好。可见,利用辅助信息评论文本可以提供用户偏好和项目属性的丰富信息,对于为用户和项目建模非常重要。
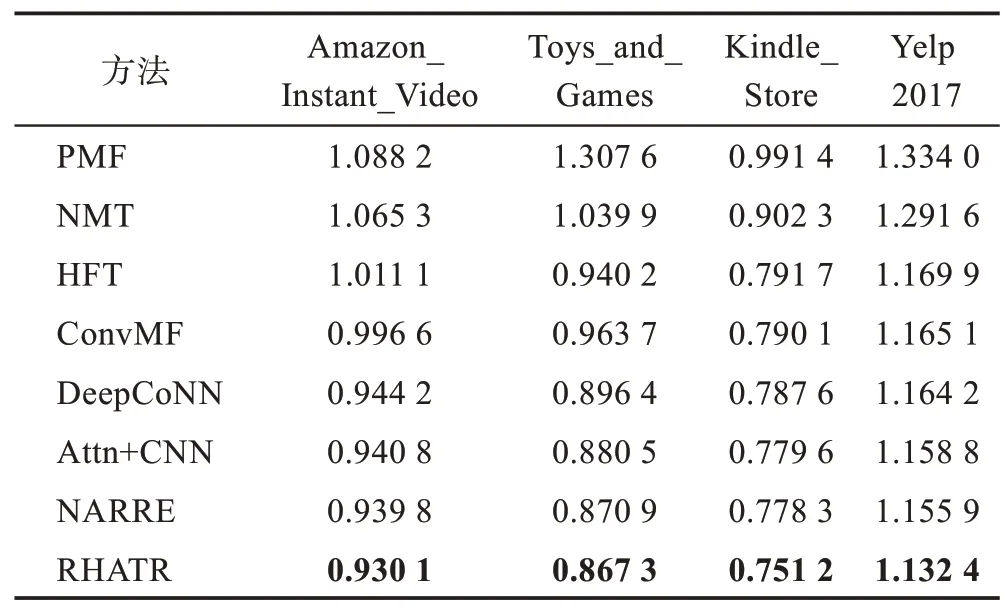
Table 4 Performance comparison of different methods on 4 datasets(RMSE)表4 不同方法在4 个数据集上的性能比较(RMSE)
(2)同时考虑评分和评论文本信息的模型中,基于深度学习技术的DeepCoNN、Attn+CNN、NARRE 模型优于无法捕获上下文语义和单词顺序的HFT模型。
(3)无论是只对评论文档中单词施加注意力机制的Attn+CNN 模型还是仅对评论文档中评论文本施加注意力机制的NARRE 模型,其推荐性能均优于没有施加注意力机制的其他方法。
实验2不同层级注意力的有效性
本文通过实验2 验证不同层级注意力,包括单词级注意力、评论级注意力的有效性。比较本文提出的模型RHATR 与其变体RHATR_W(仅包含单词级注意力)、RHATR_R(仅包含评论级注意力)在4 个数据集上的RMSE,如图3 所示。

Fig.3 Effectiveness of different level attention on different datasets图3 在不同数据集上不同层级注意力的有效性
图3 验证了单词级注意力和评论级注意力对于提升推荐系统性能是有效的。在单条评论文本中,不同的单词对于学习用户和项目表示有不同的贡献,因此对评论文本施加单词级注意力有助于识别重要单词,对于评论文本编码是有效的;同样,用户对每条评论文本的偏好程度不同,项目与评论文本之间的相关性也有差异,为用户评论集和项目评论集应用评论集注意力对于推荐系统的性能提升是有帮助的。相比于RHATR_W,评论文本的重要性对于用户和项目建模的准确性优于单词的重要性。
实验3时间因素的有效性
为了验证时间因素的有效性,将式(12)去掉,表示用户在不同时间的评论对于用户偏好和项目特征建模是同等重要的。式(13)改为进行实验。用RHATR_NT 表示。表5展示了实验结果。

Table 5 Effectiveness of time information on different datasets(RMSE)表5 在不同数据集上时间信息的有效性(RMSE)
从表5 中可以看出,引入时间信息的模型在均方根误差上的结果小于没有考虑时间因素的模型。对于用户而言,用户随着年龄的增长,兴趣偏好会不断改变。通过式(12)和式(13)来说明时间信息对于用户偏好和项目特征影响的重要程度。将时间信息考虑在内,对用户进行动态推荐是有必要的。因此,联合用户的评论文本和时间因素对用户偏好和项目特征进行建模对推荐性能的提升是有效的。
4 总结与展望
本文利用用户对项目的评分、评论文本以及时间因素等信息,提出了融合短文本层级注意力和时间信息的推荐方法。RHATR 通过从单条评论文本中提取关键词、情感词等信息为用户和项目建模;并对引入时间因素的用户评论集和项目评论集应用评论级注意力来进一步学习用户和项目的动态表示,挖掘用户和项目的动态属性,从而为用户进行精准推荐。各种对比实验表明,本文方法在预测评分误差上均低于其他方法。考虑到本文使用的GloVe 预训练词向量属于静态编码,同一个单词在不同的评论中具有相似的语义,可能会曲解单词在上下文语境中的含义。例如,Movies_and_TV 数据集中的两条评论文本中的语句“I watch this movie hoping for a enjoyment to watch.This moving was boring and I didn't finish it.”和“This enhances,rather than detracts from,the film's enjoyment because it creates an emotional aura of mystery and sacredness to the subject.”。前者评论文本中的单词“enjoyment”表示了用户的负面评价,而后者的“enjoyment”表示用户的正面评价,而在本文中具有相同的含义。未来的工作将考虑每个单词的表示需要根据评论文本的不同上下文环境而动态变化,来提高推荐性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
阅读(快乐英语高年级)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮当(2018年11期)2018-05-14 11:48:18
传媒评论(2017年3期)2017-06-13 09:18:10
意林(绘英语)(2017年5期)2017-05-15 02:17:23
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
