
社交网络中意见领袖挖掘方法综述
2021-11-17 08:25熊雪军
计算机与生活 2021年11期
郭 奕,徐 亮,熊雪军
西华大学 电气与电子信息学院,成都610039
移动互联网技术的应用已经取得卓越成效,催生了各种各样的社交平台,全球每天有数十亿人活跃在互联网中,消息的传播速度、传播广度、影响力与日俱增。人们既是消息的接收者,也是传播者和生产者,能在网络中进行观点输出,对商业产品、公共事件以及政府政策等事物发表自己的看法。社交网络中的每个个体都会受到其他个体观点的影响或拥有影响其他个体观点的能力。但是每个个体影响其他个体的能力大小不同,在社交网络的消息传播过程中,对普通个体的观点或行为具有极强的引导力和影响力的那些人可以被称为意见领袖。
社交网络中的意见领袖挖掘(opinion leader mining),又称意见领袖识别(opinion leader identification)或意见领袖发现(opinion leader discovery),其实质是在复杂的社交网络中,找出那些对其他个体的观点形成、行为趋势起着重要作用的少数个体。挖掘出这些少数个体并发挥他们的特殊作用,可以在政治、经济、社会等领域产生积极效果。政治上可以促进政府政策与制度的宣传与实施,经济上可以帮助企业推广产品,社会上一方面可以引起大家对社会公共问题的广泛讨论、引领舆论的方向、引导社会价值取向朝着健康方向发展;另一方面可以针对网络上的舆情进行监控,预防和及时处理重大舆论事件,维护社会稳定。
本文参考了众多学者的论文,主要包括收录于SCI 和IEEE Xplore 中的期刊论文、会议论文以及CNKI 上的硕博毕业论文。这些论文对“意见领袖”的起源、挖掘、应用这三方面进行了广泛的研究,给本文提供了丰富的参考资源。中英文检索关键词如表1 所示。对于在CNKI上检索到的文献进行了摘要关键词词频分析,生成词云图如图1 所示,从中可以看出意见领袖挖掘所用到的技术和应用场景。
本文首先详细阐述了意见领袖的定义和特点以及挖掘意见领袖的意义;然后整理了现有的意见领袖挖掘方法,将其归纳为四类实现方法,并分别阐述了这四类实现方法的基本思想、关键技术以及各自的优缺点;最后,结合现有方法的不足以及相关领域的最新研究动态,探讨了意见领袖挖掘的未来研究方向。
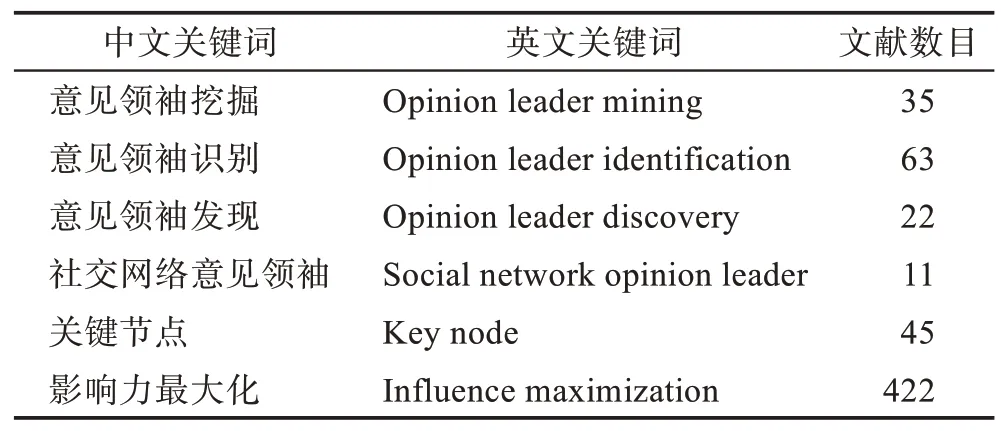
Table 1 Retrieve keywords表1 文献检索关键词

Fig.1 Wordcloud of keywords图1 文献关键词词云图
1 意见领袖挖掘概述
1.1 意见领袖的定义与分类
“意见领袖”一词起源于拉扎斯菲尔德的著作《人民的选择》[1],书中拉扎斯菲尔德定义了两级传播理论,即消息的传播遵循这样一个过程:消息由大众媒体经过意见领袖再传到普通受众。拉扎斯菲尔德等人认为,意见领袖最先知晓消息,根据自己经验、知识对消息进行处理,再将其传播给其他普通个体。对消息的处理工程中往往包含他们自己的观点,这对他人的态度,甚至是行为起着重要的导向作用。
有很多学者对社交网络中意见领袖做出了解释,目前并没有一个比较权威的定义,但是这些定义大都体现了意见领袖对人们态度、观点、行为的影响[2-5]。经过总结,本文将意见领袖定义为:在社交网络的消息传播过程中,对普通个体的观点或行为具有极强的引导力和影响力,直接或间接地推动普通个体观点的形成,影响其观点倾向甚至是行为趋势,扩大了消息的传播广度和深度的少数个体。
意见领袖可以分为三类:观点型意见领袖、群体型意见领袖、事件型意见领袖[6]。意见领袖对普通个体展现出的强大影响力与他们自身的特点密不可分,而不同意见领袖往往具有不一样的特点。
观点型意见领袖:这一类意见领袖往往具有一定的专业性,掌握了一个或多个领域一定的专业知识,拥有较为权威的背景和丰富的经验。在相关的网络社区中,他们的观点往往能被多数人认可。
群体性意见领袖:这一类意见领袖可能并不是在某一领域的专家,但是他们拥有丰富的信息资源和广泛的关注度。例如一些官方媒体或自媒体账号,他们凭借高超的信息整合能力也能形成较为专业的内容而被大众广泛接受。
事件型意见领袖:这一类意见领袖指的是某个热点事件的主体或与之相关的人。他们可能不具备专业性,但因为他们处于热点事件之中从而拥有广泛的关注度,他们的观点、行为同样对大众拥有极强的影响力,只是这种影响力具有一定的时效性,大多会随着事件热度的降低而逐渐消失。
其中事件型意见领袖随热点事件而产生,通过热点事件就能够发现,本文提到的意见领袖挖掘,主要是指观点型意见领袖与群体型意见领袖。
1.2 挖掘意见领袖的意义
在社交网络的消息传播过程中,意见领袖既有积极影响也有消极影响。积极的影响力包括:设置网络议事日程、掌握舆论走向、吸引众人发声。消极的影响力包括:滥用话语权、误导受众群体[7]。
积极的影响力可以加以利用,而消极的影响力则应当得到管控。目前意见领袖在众多领域中都发挥着极其重要的作用。在商业营销中,意见领袖可以提高商品的知名度,开展更加吸引人的互动式营销,以此来提高商品的销量[8-10];在舆情监控方面,意见领袖对社会舆论的方向有一定的引导作用,挖掘出意见领袖有助于对社会网络舆情进行有效的引导和防控[11];在政策宣传方面,通过意见领袖对政策的广泛传播能够让大众了解政策的内容并引发讨论,使民众积极参与到政策的制定过程中,这有助于政策的推行和完善。
2 意见领袖挖掘方法分析
根据所采用的技术不同,本文将现有的意见领袖挖掘方法归纳为四类,分别为基于评分规则的方法、基于社交网络图的方法、基于影响传播模型的方法、多维融合的方法。下文将分别阐述这些方法的基本思想、关键技术以及各自的优缺点。
2.1 基于评分规则的方法
2.1.1 方法概述
基于评分规则的意见领袖挖掘方法的主要思想是为社交网络中的用户影响力建立一定的评价规则,利用这些规则来衡量一个用户是否为意见领袖。其实现思路如图2 所示,基本步骤如下:
步骤1选取特定的用户信息作为特征信息;
步骤2基于选定的特征信息构建评分公式;
步骤3根据评分公式计算所有用户的得分并排序,将得分高的用户视为意见领袖。

Fig.2 Methods based on scoring rules图2 基于评分规则的方法
这类方法的关键在于选取哪些用户信息作为特征信息,以及如何基于这些信息来构建评分公式。因此,基于此方法的研究成果主要集中在特征信息的选取和评分规则的构建这两方面。
2.1.2 特征信息选取
网络社交平台上可以提取出用户的众多信息,其中主要包含属性信息和行为信息。不同的平台含有的用户信息不同,本文以包含用户信息较多的新浪微博平台为例,列出了该平台中拥有的用户信息类型及具体内容,如表2 所示。

Table 2 Users'information on Weibo表2 微博平台用户信息
目前并没有研究或者理论表明,哪种用户信息最能体现用户的意见领袖特性,即便是“粉丝数”这样能直接反映用户影响力的信息都会因为“水军”和“僵尸粉”等因素的干扰而使得其可信度降低。因此研究者们都是从逻辑推理的角度选择适当的用户信息作为特征信息。如张倩基于发布推文数量、转发数量、回复数量等作为特征信息,提出用户领导力(包括用户活跃度、用户影响力、用户扩散中心度)计算公式来确定最终的意见领袖[12]。Li等人以转发、评论、发文、浏览行为等为特征信息,提出以专业性、创新性、影响力和活跃度的综合值来选出意见领袖[13]。袁竹星提出3 个一级指标(用户历史活跃度、用户历史传播力、用户活跃度)和8 个二级指标(包括原创微博活跃度、粉丝数、被转发数等)来计算用户的初始影响力[14],如表3 所示。

Table 3 Example of feature extraction表3 特征信息提取示例
2.1.3 评分规则的构建
目前的评分规则多种多样,主流方式是提取多种特征信息进行线性或非线性组合,也有提取较少的特征信息并引入其他理论构建的评分规则。本小节主要从特征信息、创新点和局限三方面分析三个典型的评分规则,如表4 所示。
TTV(total trust value)由Aghdam 等人提出[15],仅仅选取了用户的评论数作为特征信息,基于此计算JC(Jaccard)系数来衡量某一用户与其他用户信任关系强度,其评分公式便于计算,但特征信息仅仅包含用户的评论数,准确性不高;带惩罚项的评分公式由王君泽等人提出[16],其在一定程度上能够抑制数据中的一些非自然现象的影响,优化领袖的识别结果,但这要求惩罚项设置要合理,否则效果适得其反;MilestonesRank 由Riquelme 等人提出[17],Milestones的提出意味着不同时段的数据所能够表征的用户重要性程度不同,逻辑上这符合社交平台中话题讨论的规律,考虑时间因素,提高了意见领袖的识别结果,实现过程相比于其他一般的评分规则稍加复杂。
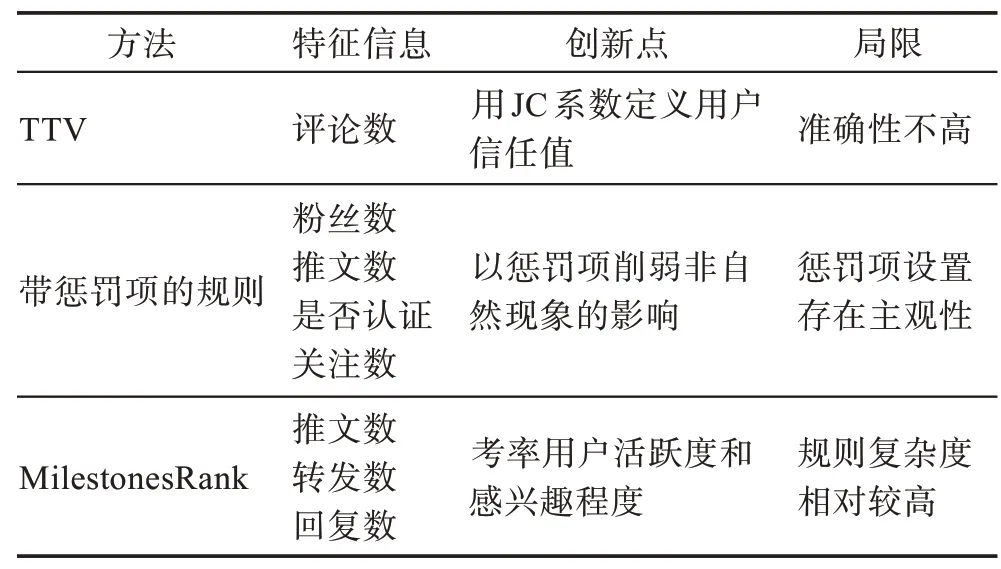
Table 4 Comparison among three scoring rules表4 三个评分规则的比较
2.1.4 方法述评
某些社交网络中蕴含了许多能够反映意见领袖特征的信息,基于评分规则的方法充分利用这些信息来构建评分规则对用户进行评分,从而挖掘意见领袖。当可以获得的用户信息比较单一时,构建的评分规则并不能够很好地体现用户在社交网络中的重要性。因此该方法仅仅适用于拥有较为丰富的用户信息的场景。在构建评分规则之前,应当结合实际的应用场景挑选反映领袖特质的用户信息作为特征信息。多数评分规则是特征信息之间的线性组合,因此分析不同特征信息之间的关系及其重要性程度以构建合理的评分规则尤为重要。
基于评分规则的最大的优点在于原理简单,复杂度低,能够在较短时间内获取较为可靠的结果,适用于大型网络。然而,此方法也存在着如下不足:(1)此方法会对社交网络中所有用户进行无差别的计算,但意见领袖是少数用户,大多数用户明显不可能是意见领袖,这无疑耗费了大量不必要的时间和算力;(2)迁移性差,不同社交网络蕴含的用户信息不同,针对某一社交网络设计的规则无法迁移到另一社交网络中进行使用;(3)片面性,仅仅考虑了一些数量信息,没有考察社交网络中的文本信息和用户间的拓扑结构关系。
2.2 基于社交网络图的方法
2.2.1 方法概述
如果将社交网络中每一个用户看成一个节点,用户之间各种交互行为,比如点赞、转发、评论等蕴含了这些节点之间的某种联系。如果把这种联系用连接节点之间的线来表示,那么社交网络就可以被表示为一个复杂的社交网络图。社交网络图中蕴含着丰富的拓扑结构信息,于是大量的研究从用户间拓扑结构的角度探索用户重要性的计算方法,进而挖掘出意见领袖,该方法的实现过程如图3 所示。

Fig.3 Procedure of method based on social network图3 基于社交网络图的方法处理流程
从图3 中可以看出,基于社交网络图的意见领袖挖掘方法的重点在于社交网络图的构建以及节点重要性的计算,下面将分别对这两个重点内容的研究进行介绍。
2.2.2 社交网络图的构建
一般来说社交网络图可以被定义为G=(V,E,W)。其中V代表节点集合,即社交网络中的所有用户;E是连接用户之间的边的集合,边代表节点之间的联系;W代表各边的权重集合,可以表征节点之间联系的强弱。将图抽象为数学表达即可以表示为一个邻接矩阵。
权重的确定可以根据实际网络中用户间的交互关系来确定,例如肖宇等人通过BBS 网络中用户共同参与讨论的次数来确定权重[18],仇丽青等人通过用户之间发布微博数与转发数的比例作为权重[19]。
根据网络图有向或无向,有权重或无权重,可以构建出有向有权网络图、有向无权网络图、无向有权网络图、无向无权网络图,如图4 所示。
有向网络中节点间交互是单向的,而无向网络中节点间交互是双向的。针对不同类型的社交网络,就可以构建不同的社交网络图。例如在知乎这样的问答网络中,问题回答者占主导地位,则可以理解为有向网络,节点方向由回答者指向提问者和其他阅读者。相比于知乎,微博这样的社交平台中会存在大量的评论信息,评论者的影响力不可忽略,可以理解为无向网络。
2.2.3 重要性计算
社交网络图中的重要性计算主要是从拓扑结构角度对网络中所有节点的重要性进行衡量,反映网络中节点在网络中的位置或拓扑关系的重要性。本小节主要分析图论中常见的几个中心性度量指标以及经典的PageRank 算法。
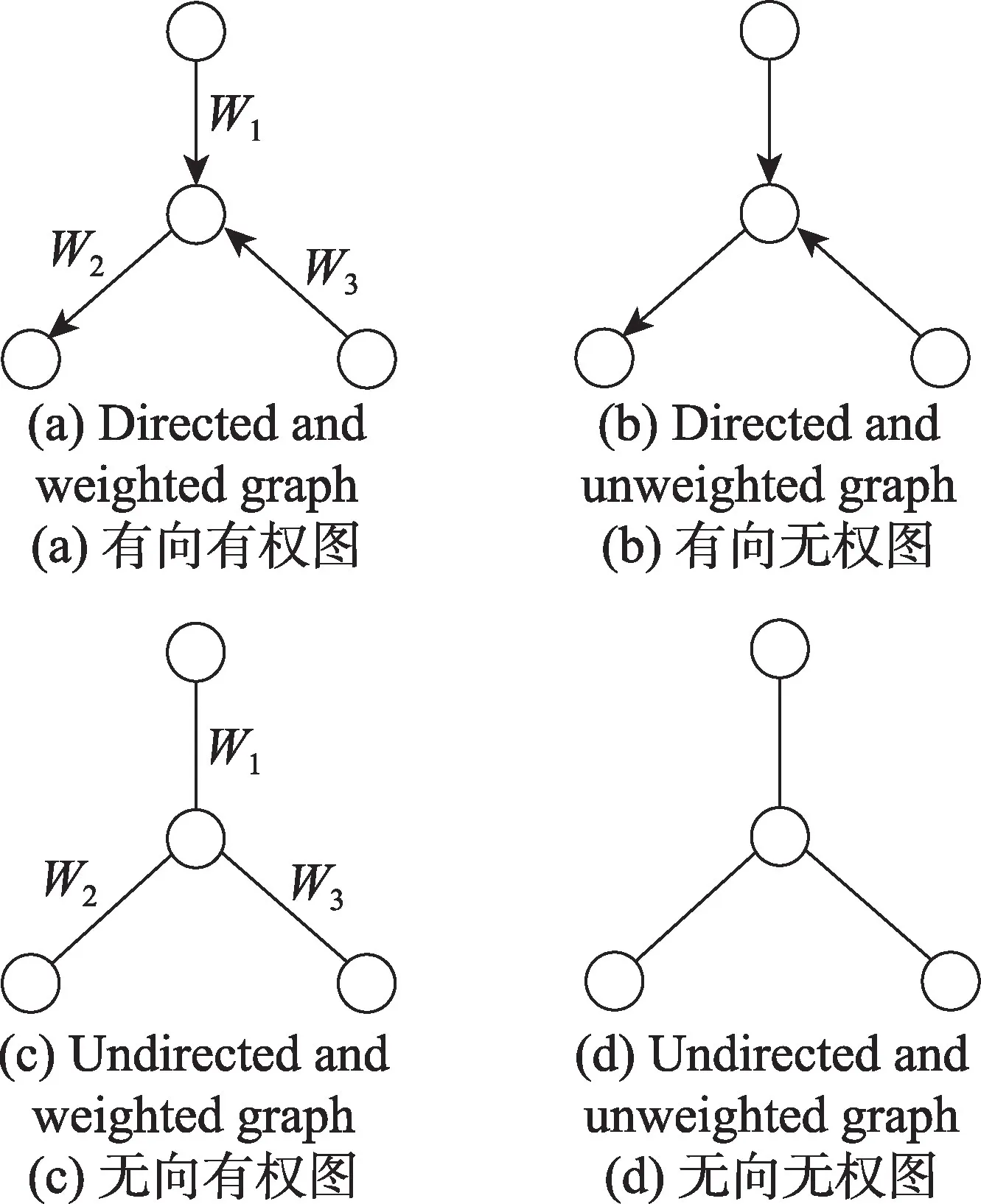
Fig.4 Four types of social network graph图4 四类社交网络图
(1)中心性度量
中心性是衡量网络中节点重要性的指标,早在20 世纪Freeman 就提出了两种节点中心性指标:度中心性(degree centrality,DC)和中介中心性(betweenness centrality,BC)[20]。后续又有人提出了接近中心性(closeness centrality,CC)和特征向量中心性(eigenvector centrality,EC)[21]等多种中心性衡量指标,它们的含义如表5 所示,表中N代表网络中的节点数量。

Table 5 Four types of centrality measures表5 四种中心性度量指标
度中心性在无向图中表征某一节点与网络邻居节点的关联程度,是节点直接的、局部的重要性衡量指标[20,22];接近中心性表征的是网络中某一节点与其他节点的接近程度,以节点之间的距离表征节点的重要性程度[23-25];中介中心性表示经过节点vi的最短路径数,即网络中其他节点之间的最短路径必须经过节点vi,这样的路径越多则表示该节点对信息传播越重要[20,26-27];特征向量中心性是一种同时考虑邻居节点数量及其重要性的衡量指标[28-29],更能反映社交网络中的用户间关系,其中PageRank 的应用和研究最为广泛,故在后文单独进行分析。
(2)PageRank 及其改进
PageRank 由Page 和Brin 于1998年提出[30],本质上属于Eigenvector Centrality 中的一种,被用于计算网页的重要性,其计算表达式如式(1)所示。式中N为网页数量,PR(pi)代表网页pi的PageRank值,M(pi)是指向网页pi的所有网页的集合,L(pj)是网页pi所指向网站的数量,d是一个值为0 到1 的阻尼系数,经实验验证将d设为0.85 比较合适[31-32]。
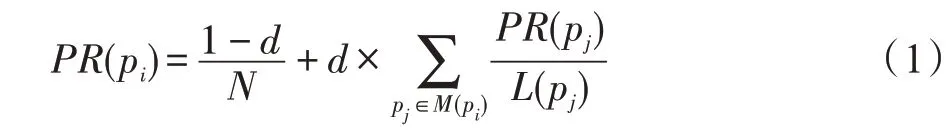
将PageRank 算法应用于意见领袖挖掘任务时主要存在两个问题:
问题1原始算法中每个节点的初始PR 值相同,这与社交网络中不同节点间影响力大小不同的情况不符,该如何确定节点影响力初值?
问题2原始算法中节点PR 值平均分配给与其相连的节点,这与社交网络中同一个节点对不同节点的影响力大小不同的情况不符,该如何确定节点影响力分配权重?
研究者们对上述问题进行算法改进,形成了多种更加适用于社交网络中意见领袖挖掘的算法,较为典型的如表6 所示。从表中可以看出改进后的PageRank 算法通过将用户的属性信息和行为信息纳入考虑,解决了初值问题和权重问题。虽然各种方法采用的数据集或评价指标不同,但可以肯定的是,它们都不同程度地提高了挖掘效果。除此之外,文献[39-41]也对PageRank 进行了改进,但是基本思路与表格中方法的思路类似,故而没有列出。
2.2.4 方法述评
基于社交网络图的意见领袖挖掘方法着重从用户间拓扑结构关系,利用网络分析中的一系列重要性衡量指标来挖掘意见领袖,着重表现用户在网络中位置上的重要性。社交网络图的构建与节点重要性的计算是此方法的两个关键步骤。构建社交网络图要参考实际网络中的用户信息和交互行为,如果无法构建社交网络图,就不能使用此方法。
节点重要性的计算方法中,度中心性、邻近中心性、中介中心性从不同方面都能在一定程度上表征节点在网络中的重要性。但单独使用三者中任何一个指标直接挖掘意见领袖都不能得到比较可靠的结果,因此它们往往只作为挖掘任务的一部分影响因素而不单独使用。
PageRank 算法作为特征向量中心性中的一种,同时考虑与节点相连的数量及其重要性,可靠性相对较高,可以将其单独应用于意见领袖挖掘。针对PageRank 算法的不足,一系列改进的PageRank 算法将丰富的用户信息与用户间拓扑关系结合起来,弥补了基于评分规则的方法没有考虑用户间拓扑关系的缺点,使挖掘结果可靠性大幅提升。但由于Page-Rank 算法迭代过程需要进行大量的计算,耗时长,其仅仅适用于数十万节点数量的网络,对百万级节点的大型网络不具备适应性。

Table 6 Comparison of different methods based on PageRank表6 改进的PageRank 算法对比
2.3 基于影响传播模型的方法
2.3.1 方法概述
挖掘意见领袖的目的就是希望发挥其影响力,尽可能多地影响他人,即最大化影响范围。如果能刻画出一个人的影响力范围,那么影响范围大的则可以认为是意见领袖。因此意见领袖的挖掘可以看成是一个影响最大化问题,即尝试在网络中找出给定数目的K个节点使得其在网络中的影响范围最大,然后认定这K个节点为意见领袖。该方法的大致流程如图5 所示。

Fig.5 Procedure of methods based on influence transmission model图5 基于影响传播模型的方法处理流程
(1)基于用户信息构建社交网络,与2.2 节所述社交网络图的构建相同,但一般构建为有权有向图;(2)选择一个传播模型来确定消息传播规则;(3)设计算法实现传播模型,模拟消息在社交网络中传播,以此寻找影响范围最广的K个节点,将它们视为意见领袖。该方法的研究重点并不在社交网络图的构建,而主要集中在影响传播模型和消息传播模拟这两部分。
2.3.2 影响传播模型
影响最大化问题的研究需要基于特定的传播模型,传播模型规定了用户的影响是如何在网络中进行扩散的。根据传播模型设定规则,就可以表征出一个节点的影响范围。目前研究最多、应用最广泛的模型有两个:独立级联模型(independent cascade,IC)[42]与线性阈值模型(linear threshold,LT)[43]。
线性阈值模型[43-45]由Granovetter 于1978 年提出,在该模型中,网络中的节点存在激活和静默(未被激活)两种状态。节点V是否能被激活由它的激活阈值和它所有前驱节点的作用及权重共同决定。线性阈值模型如图6 所示,图中V表示节点,特别地,VS0和VS1表示初始节点,E表示节点间影响大小,T表示节点的激活阈值。
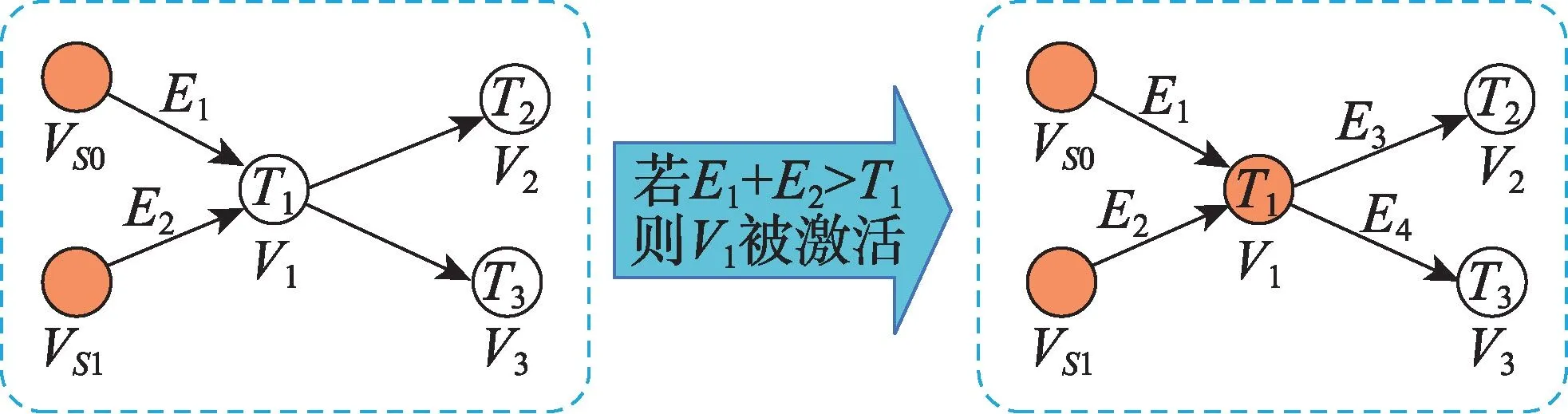
Fig.6 Linear threshold model图6 线性阈值模型
独立级联模型最早由Goldenberg 等人提出,与线性阈值模型相区别,线性阈值模型中的激活条件并不是一个阈值,而是一个概率,它是一个基于概率的模型[42,45-47]。如果给定K个初始激活节点,那么该模型下的影响传播过程如下:K个初始节点可以激活与自己相连的静默态节点,激活成功的概率一定,且这一概率在不同节点之间是相同的,称为传播概率。对某一静默态的节点V,激活态节点只有一次机会去激活。独立级联模型示意图如图7 和图8 所示,P表示传播概率。
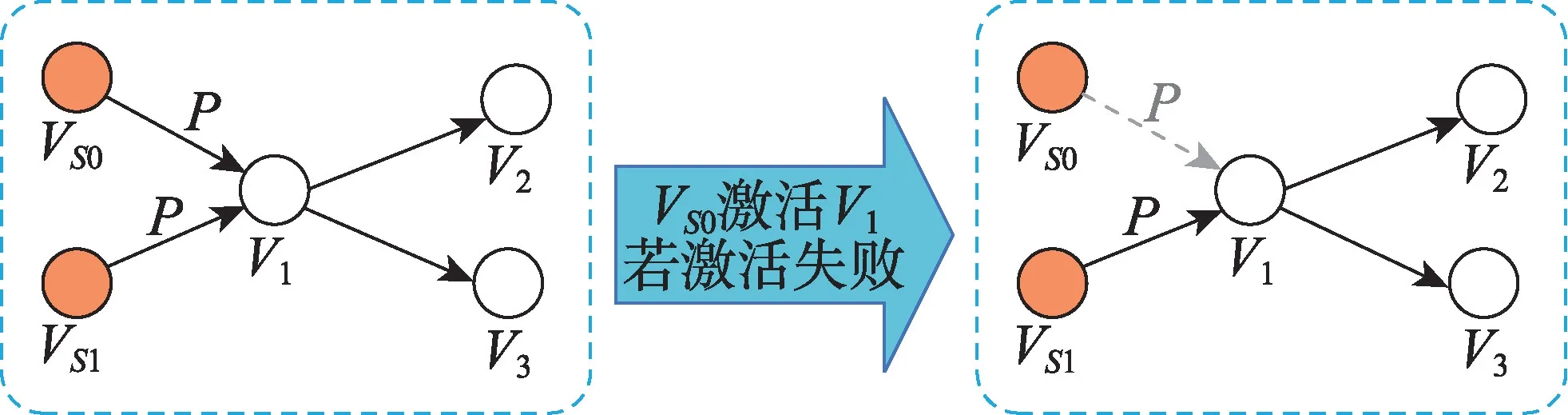
Fig.7 Independent cascade model(activation failed)图7 独立级联模型(激活失败)
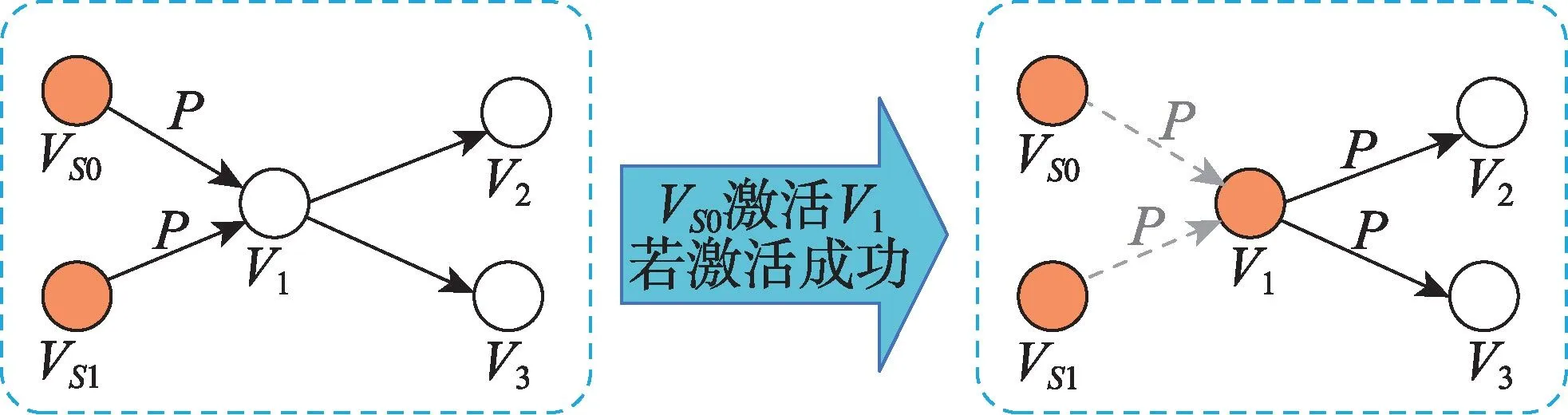
Fig.8 Independent cascade model(activation succeeded)图8 独立级联模型(激活成功)
除了上述的两个模型之外,研究者们还提出很多其他的模型,比如触发模型(triggering model)[48]、递减级联模型(decreasing cascade model)[48]、加权级联模型(weighted cascade model)等[49]。这些模型都是在上述两种模型上的改进,不再赘述。
2.3.3 影响最大化问题
影响最大化问题就是给定传播模型,在网络中找出K个节点,模拟消息传播,使得K个节点的影响范围最大。针对这一问题,目前的研究中主要有如下三类算法:
贪心算法:最基本的贪心算法是Kempe 等人提出的BasicGreedy 算法[48],此类算法寻求最广的影响范围,但时间复杂度极高,不具有伸缩性。
启发算法:最基本的启发算法同样由Kempe 等人提出,叫作Degree Centrality[48]。此类算法的影响范围无法匹配贪心算法,但特点是时间复杂度非常低,具有伸缩性。
其他算法:指基于贪心算法或者启发算法进行外部改进而形成的算法,多是将贪心算法和启发算法进行结合,或是对传播模型进行改进。
三类算法的研究成果如表7 所示。表中仅仅展示了一部分较为代表性的算法,并分析了它们各自的创新点和是否具备伸缩性。伸缩性指当网络节点数量剧增时,其运行时间是否还能保持可接受范围。具备伸缩性则说明该方法能够应用于百万级大型网络,反之不行。此外需要说明的是,大多数学者从研究影响最大化问题本身出发,主要是对贪婪算法效率低与启发算法传播范围小两方面进行改进,而少有结合社交网络中意见领袖挖掘任务的特点进行相应优化,类似的还有文献[60-63]中提及的方法。
2.3.4 方法述评
基于影响传播模型的方法同样要基于社交网络图,但与2.2 节中基于社交网络图的方法不同的是,该方法是一种动态的方法,通过模拟信息的传播过程,捕捉拓扑结构上承载的动态信息,量化网络中节点的影响范围以挖掘出意见领袖。影响传播模型是对现实世界消息传播过程的简单抽象,规定影响在社交网络的传播规则。基于传播规则解决影响最大化问题就是实现意见领袖挖掘的过程。这是一种客观的方法,可靠性高,只要用户间拓扑关系已知就可以采用此方法取得较为可靠的结果。
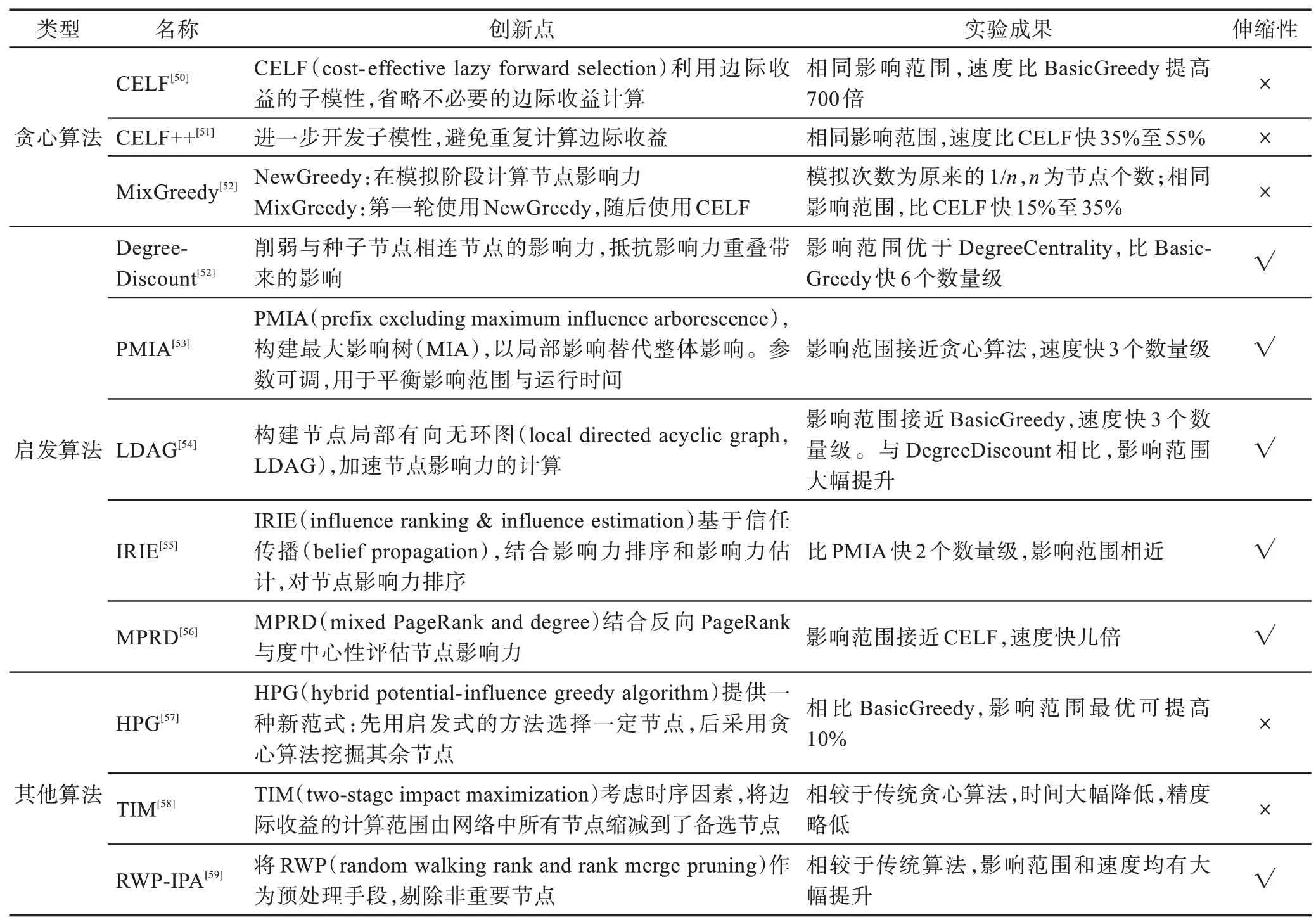
Table 7 Comparison of different methods based on influence diffusion model表7 基于影响传播模型的挖掘方法对比
目前解决影响最大化问题的算法在追求最大的影响范围的同时,尽可能地降低时间复杂度。虽已经取得一些重大进步,但仍存在如下三个问题:(1)贪心算法以节点为单位模拟信息传播使得计算量随着网络规模的上升而急剧上升,且无法避免。面对实际情况中百万级甚至是千万级节点个数的社交网络时,该方法并不适用。(2)现实中的消息传播规律复杂得多,传播模型中传播规则的设定并不一定能很好地模拟社交网络中的消息的传播规律。(3)没有充分利用社交网络中丰富的用户信息。
上述问题中,问题1 和问题2 实际是一对矛盾体。要让传播模型更加贴近真实世界就需要添加相应的规则,这必然会增加模型的复杂度,对大型网络的适应性更差。针对问题3,本文认为可以借鉴2.2节PageRank 的改进思路,利用丰富的用户信息设定传播模型中的阈值、权重或概率。在不改变传播规则的前提下,即不改变传播模型算法复杂度,使其更加适用于社交网络中的意见领袖挖掘任务。
2.4 多维融合的方法
前文所述的三种方法各有优缺点,研究者们综合考虑各个方法的优点,提出了融合拓扑结构信息的评分规则的方法。此外,在使用原始方法之前加入主题社区划分和文本情感倾向分析,分别形成了面向主题的意见领袖挖掘方法与融合文本信息的挖掘方法。本节将叙述分析上述三种方法各自的思路与特点。
2.4.1 融合拓扑信息的评分规则
基于评分规则的意见领袖挖掘方法仅仅考察了用户的一些基本的数量信息,并没有考虑到用户之间形成的拓扑结构关系。而基于社交网络图的方法中有多种重要性衡量指标。两种方法具有互补性,因此研究者们将社交网络图中的节点重要性衡量指标引入评分规则作为其中的重要组成部分,这样同时考虑了用户信息和结构信息,如图9 所示。
将两种方法结合后,挖掘效果得到进一步提高。例如,宋倩倩等人提出基于用户粉丝关注度、粉丝影响力、用户转发消息率等信息的用户领导力计算公式,然后结合度中心性来挖掘意见领袖,将领导力得分高且中心性明显的用户视为意见领袖[64]。Cao等人提出了PCA-SNA(principal component analysissocial network analysis)算法[65],该算法结合节点的度中心性、邻近中心性、中介中心性,采用主成分分析法(PCA)确定三者的权重得出用户最终的重要性结果,从而挖掘出意见领袖。
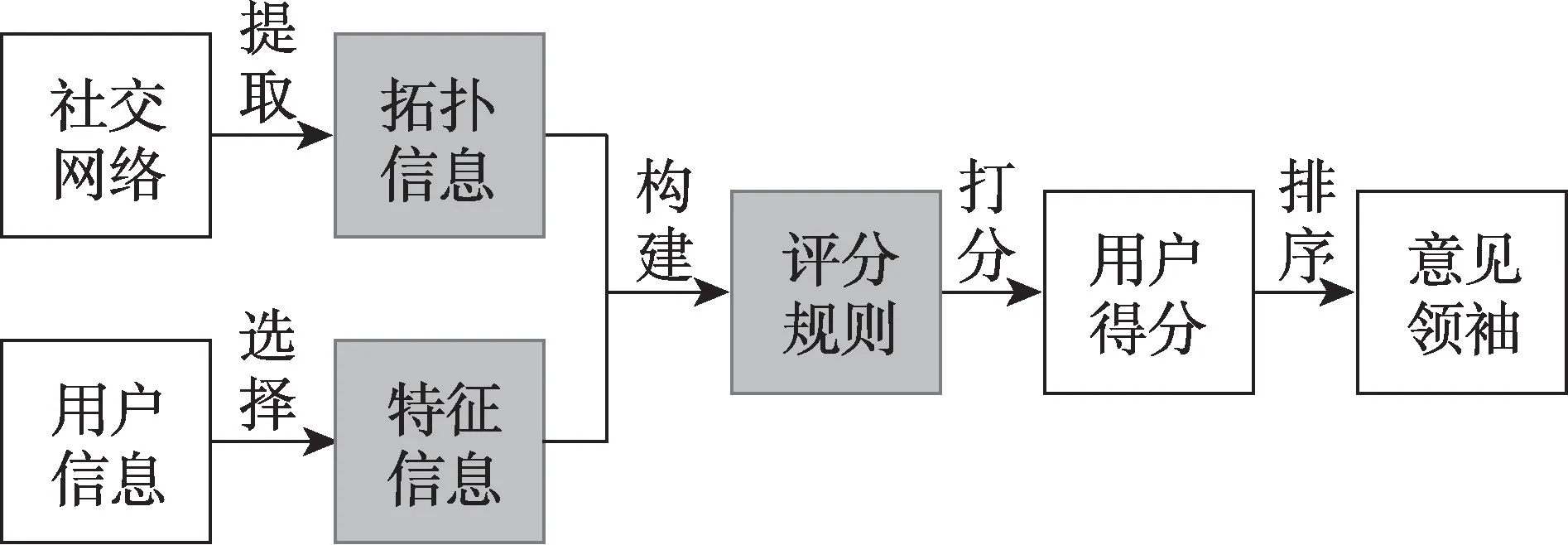
Fig.9 Scoring rules integrated with topological information图9 融合拓扑信息的评分规则
2.4.2 面向主题社区的意见领袖挖掘
社交网络中用户之间的交互通常以某一特定的主题而展开,不同的主题下都存在着意见领袖,张米等人通过实验也证明主题特征是意见领袖不可忽略的一个特征[46]。因此针对网络中明显存在的社区特性,研究者们提出了面向主题的意见领袖挖掘[66],先对社交网络中的用户进行主题社区划分,再使用传统的挖掘方法进行挖掘,如图10 所示。

Fig.10 Opinion leader mining for thematic community图10 面向主题社区的意见领袖挖掘
典型的面向主题社区的挖掘方法有文献[67-72]中所提出的一系列方法,它们之间的最大区别在于主题社区划分方法不同,社区划分后所采用的意见领袖挖掘方法不同。而社交网络中的主题社区发现方法有多种,主要可以分为启发式算法、基于优化的算法、聚类算法[73]。其中启发式算法有GN(Girvan and Newman)算法、派系过滤算法等[74-75];KL(Kernighan and Lin)算法、基于最大流或最大割的算法[76-78];聚类算法中又分为基于相似度的层次聚类和混合聚类算法[73]。主题社区发现本身就是一个重要的研究课题,但不属于本文主要研究内容,故不再赘述。
综上所述,面向主题的意见领袖挖掘将整个网络划分成多个主题社区,分别挖掘出各个主题下的意见领袖。此方法具有如下特点:
(1)针对性:可以剔除其他不感兴趣的社区,仅针对感兴趣的社区挖掘,大幅提高挖掘效率,这对于商业中的精准营销有重要意义。
(2)局部性:针对社区的挖掘获取到的是局部的意见领袖,其在社交网络中的全局影响力并不高,因此不适用于对全局影响力有所需求的场景。
2.4.3 融合文本信息的挖掘方法
社交网络中的文本信息蕴含了某一用户对其他用户或是对某件事的情感态度。有研究者将这些能够反映意见领袖影响力的情感态度考虑到意见领袖的挖掘过程之中,结合一般的挖掘方法,进一步提高了意见领袖的挖掘准确率。
文本的情感倾向性分析是自然语言处理领域的一个重要研究方向,大致的倾向分析可以分为正向、负向、中性三种情感。考虑社交网络上推文、评论、回复等文本内容的情感倾向性分析有助于提高意见领袖挖掘结果的可靠性。例如,陈志雄等人通过对文本进行情感分析,实现对意见领袖的情感倾向的分类,可以挖掘带有特定情感倾向的意见领袖[79]。曹玖新等人采用用户的结构特征、行为特征和情感特征来度量用户的影响力,其中情感特征正是通过对粉丝的评论进行情感倾向分析,将其正向评论数占总评论数的比例定义为粉丝对该用户的情感支持度[80]。
2.4.4 方法述评
多维融合的方法并没有提出新方法,只是在已有方法的基础之上进行改进融合,考虑更多的因素以此提高意见领袖挖掘的质量。
融合拓扑结构信息的评分规则弥补了传统评分规则方法未考虑用户间拓扑结构关系的缺点,以此使结果更加准确。但这与2.2 节中改进的PageRank的融合有着本质的区别,因为其实质还是评分规则的建立,所以算法复杂度并没有明显增大,仍然能适用于大型的网络。而那些融合了用户信息的PageRank算法却不能够适用于大型网络。
面向主题社区的意见领袖挖掘方法,将社交网络划分成一个个小的社区再使用一般方法以社区为单位进行意见领袖识别,获取的局部性意见领袖对商业上的精准营销有重要意义。这种方法适用于具有明显社区特性的网络,而且结果依赖于社区划分的准确性,因此社区划分是其关键的一步。
融合文本信息的挖掘方法利用自然语言处理的相关技术对社交平台中的文本信息进行文本倾向性分析,与一般办法结合进一步提升挖掘效果。其最大的优点在于能够得到用户对所挖掘出的意见领袖的倾向,这在舆情监控方面具有重要价值。
2.5 评价指标分析
研究者们提出了很多方法来衡量意见领袖挖掘结果优劣,但是目前并没有一个普遍公认的评价方法。经过整理总结,本文将已有的评价方法分为三类:影响范围、主观逻辑推理分析、客观指标,如表8所示。其中影响范围实际也是一种客观指标,但其需要基于传播模型计算,故单独列出。
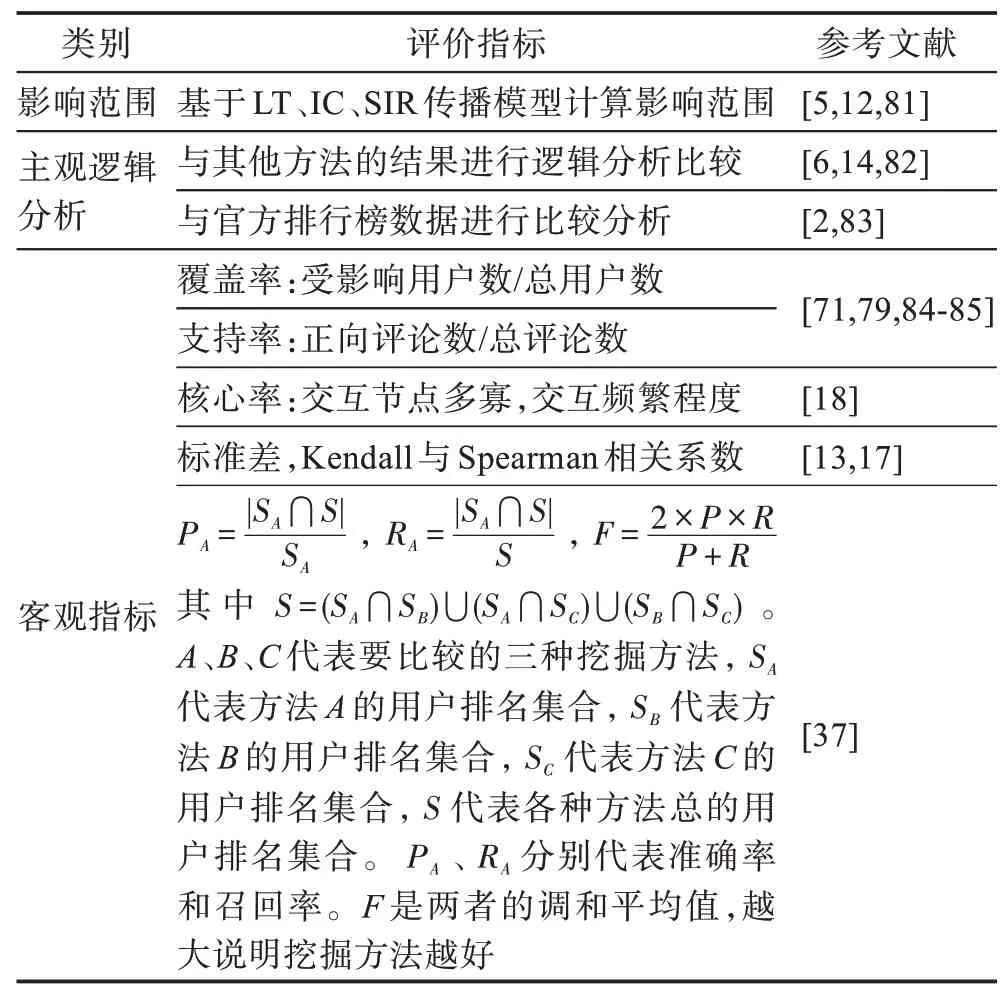
Table 8 Three types of evaluation indicators表8 三类评价指标
“影响范围”源于本文2.3 节所述的基于传播模型挖掘方法,该方法使用“影响范围”和算法效率判断自身优劣,而其中影响范围同时也能够作为衡量其他方法挖掘结果优劣的指标。基于LT、IC、SIR 进行消息模拟计算影响范围,从而比较不同算法的效果。这种评价指标是一种客观的指标,在已有的评价方法中具有较强的说服力。但是现实传播情况远比传播模型复杂得多,需提高传播模型与现实情况的相似度以进一步提高评价的合理性。
主观逻辑分析的评价方法从用户的属性信息、行为信息等方面分析各方法挖掘结果的差异,试图对这种差异做出合理解释并以此来说明某一方法的优点。此评价方法依赖于大量的用户信息,主观性强,说服力不高,不适用于仅知拓扑结构关系而无其他信息的网络。
客观指标中覆盖率指受影响用户数占所有用户数的比例;支持率指正向评论的数目与所有评论数量之比;核心率指所得结果与用户之间相互联系的紧密程度;标准差用来描述用户影响力值的离散情况,标准差越大,影响力越离散,则用户影响力排名区分度越大。Kendall 系数与Spearman 系数用于衡量不同挖掘方法产生的结果的相关性。在文献[12]中,作者用人工评价结果与算法挖掘结果进行相关性分析说明其算法的准确性;在文献[16]中,作者将单一的中心性指标的挖掘结果与所提算法的结果进行相关性分析,从而说明其所提算法的准确性。上述客观指标都具有一定合理性,但局限在了各自挖掘方法的结果集合之中。只有文献[72]提到的评价方法综合考虑了多种挖掘方法的结果,使用准确率、召回率、F系数作为评价指标,相较而言具有更强的说服力。
综上所述,无论哪种挖掘方法都具有一定的合理性,如果某种方法能与多种方法结果的并集取得最大交集,则能够从一定程度上说明该方法的优越性。因此本文认为,文献[37]中的准确率、召回率、F系数是目前较为合理评价方法之一。而基于传播模型的方法通过模拟的消息的传播取得的影响范围同样是一个较为合理的评价方法,可应用于已知用户拓扑信息的场景。
3 总结与展望
3.1 总结
社交网络中的意见领袖在商业营销、政策宣传、舆情监控、环境保护等领域发挥着巨大的作用。本文以社交网络中意见领袖的挖掘方法为切入点,较为全面地总结了现代的意见领袖挖掘方法。根据方法思路的不同,本文将其分为四类:基于评分规则的方法、基于社交网络图的方法、基于影响传播模型的方法、多维融合的方法。通过对四类方法的细致分析,本文总结了它们的优点和面临的挑战。
四大类方法的对比分析如表9 所示,此表概括总结了这四大类方法的适用条件、优点、局限和关键内容。适用条件主要考虑是否拥有用户信息和用户间拓扑结构关系;优点主要考虑各种方法的突出特点;局限主要考虑方法的伸缩性、复杂度和需要使用到的复杂技术;关键内容则是这些方法的关键技术步骤或重要分支。
应当注意的是,没有哪种方法能完全适用于所有的现实场景,现实中不同的社交平台可以形成不同的网络类型。方法的选取要依据实际情况而定,主要根据社交平台所能提供的用户信息类型、数据量大小、挖掘准确度、挖掘效率来选取合适的方法。
3.2 展望
社交网络中的意见领袖挖掘方法不断发展,取得了一定成效。但随着时代的进步和技术的革新,值得去探索一些新技术并将其应用于社交网络意见领袖的挖掘之中。针对已有方法的不足和最新的相关理论,本文探讨了以下三个未来的研究方向。
(1)基于图神经网络的聚类挖掘方法
图神经网络(graph neural network,GNN)是目前处理网络图相关问题的一种有效工具,其核心思想是将通过神经网络学习的方法,经由学习到的权重参数,可以将邻居节点的特征信息融入到自身节点的特征信息之中,最终可以得到网络中每一个节点的新的特征向量。一般认为,如果一个节点的邻居节点影响力越大,则其自身的影响力就会越大。将邻居节点的影响力考虑在内,能够提高意见领袖的挖掘效果。而GNN 正好可以巧妙地将邻居节点的信息融合到每一个节点自身特征向量,不需要计算所有节点在网络中的各种中心性指标就可以将拓扑结构信息融合到节点自身信息之中。
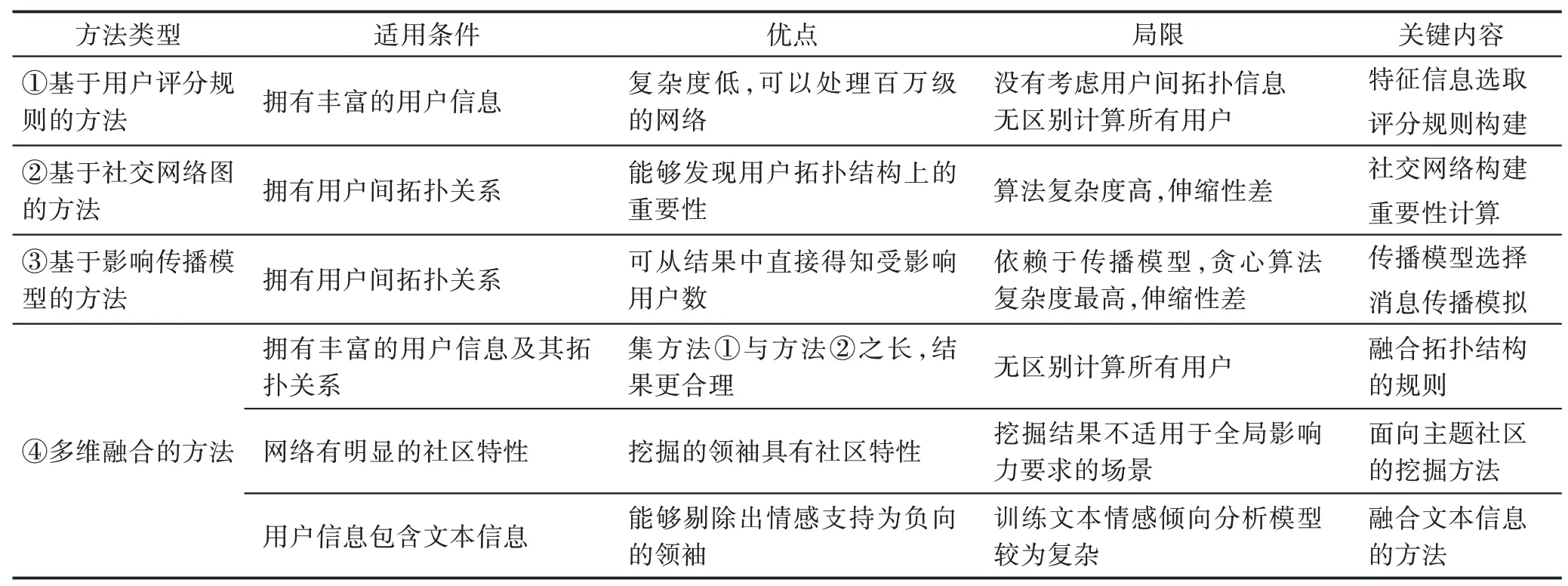
Table 9 Comparison of four types of opinion leader mining methods表9 四种意见领袖挖掘方法对比
因此,基于GNN 的聚类挖掘方法是一个值得尝试的未来研究方向,大致思路如下:挑选能够反映意见领袖品质的信息来初始化每一个节点的初始特征向量,各分量越大则越可能是意见领袖;使用GNN 网络得出包含邻居节点信息的新的特征向量;对新的特征向量进行聚类,找出最具有意见领袖品质的聚类簇作为意见领袖集合。此方法大致流程如图11所示。

Fig.11 Procedure of clustering mining method based on GNN图11 基于GNN 的聚类挖掘方法流程
(2)设计动态模型
目前大多数研究集中于静态的网络,即从某一时间点或时间段的社交网络中挖掘出意见领袖。然而在线社交网络每时每刻都在发生着变化,随着时间推移,每一个用户都可能是下一个意见领袖,而网络中原来的意见领袖的地位也可能在一段时间以后被其他人取代。因此,设计出一种有效的,能够根据社交网络的变化而不断更新信息,快速挖掘出最新的意见领袖的挖掘方法,在商业营销此类对时间较为敏感的领域意义重大。
(3)划分意见领袖等级
大型社交网络中,影响力较大用户的数量较多,其影响力大小分布会比较连续而集中。目前的挖掘方法致力于寻找影响力排名最靠前的部分用户,这样不仅忽略了其他影响相对较小但仍然拥有意见领袖品质的用户,还造成了挖掘结果的同质性,即挖掘出的意见领袖之间的影响力区分度小,处在同一量级。同时,领袖影响力越大,商业成本越高。一些研究者在新浪微博中挖掘出的“人民日报”“今日头条”“腾讯新闻”等类似的官方媒体自然拥有强大的影响力,但其利用此类意见领袖进行营销的商业成本却不是一般企业所能够负担的。
因此,设定一个意见领袖影响力等级划分规则以区分不同量级的意见领袖满足不同层次的需求。本文认为,可以使用覆盖率作为等级划分的指标,即网络中受该意见领袖影响的用户数占整个网络用户数的比例。所谓“受影响”可以用关注关系、交互行为等来定义,即有关注关系或交互行为就可以认为用户受到该意见领袖的影响。例如可以将意见领袖设置为四个等级:一级、二级、三级、四级,分别对应覆盖率40%、60%、80%、90%。研究者们可以根据实际情况探索一个更合理、更有理论依据的划分比例。
猜你喜欢
黄河之声(2022年6期)2022-08-26
导航定位学报(2022年4期)2022-08-15
现代电子技术(2022年4期)2022-02-21
智能计算机与应用(2021年4期)2021-06-05
学苑创造·A版(2019年9期)2019-11-07
意林·全彩Color(2019年7期)2019-08-13
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
好日子(2019年4期)2019-05-11
学苑创造·A版(2019年2期)2019-02-19
当代陕西(2018年12期)2018-08-04
