
三维泰森并行优化算法在虎龙沟矿区资源储量估算中的应用
2021-11-16 08:43:42秦阳
煤矿现代化 2021年6期
秦 阳
(晋能控股煤业集团虎龙沟煤业公司地测科,山西 朔州 038300)
0 引言
虎龙沟矿位于大同市西南处,井田南北向宽度约2.07 km,东西向长度约6.0 km,井田可采5、8、9号煤层,其中5号和8号煤层是稳定煤层,9号煤层是极不稳定煤层,煤层倾角为1°~8°,最低可开采厚度为0.70 m,主要开采的煤层是气煤,可选性较差,可用做动力和气化煤。
1 模型构建
矿井地质模型的构建过程如图1所示。

图1 模型构建过程
主要包括对矿山原始数据的采集、数据预处理、空间数据、数据模型计算以及矿体体视化。其中,原始数据是包括井田钻孔、地质概况等数据;数据预处理是对原始数据进行分析、化简以及规则化处理,过滤无效的数据,并对数据进行统一处理,减小计算的规模;空间数据包括矿井的空间坐标以及品味属性,对模型进行三维属性界定;数据模型计算是通过插值算法得到的规则体模型;矿体体视化是根据插值结果将属性反应在矿体模型中。
2 优化算法分析
2.1 三维泰森串行算法
三维泰森串行算法是根据模型的三维坐标,依次访问模型的每个体素,参照泰森多边形理论,即空间任意一点的品味属性就是与它最近已知点的品味属性,通过插值计算后得到规则的体素,串行算法的步骤如下,流程图如图2所示:

图2 三维泰森串行算法流程
1)确定插值范围,如果达不到矿体大小的要求,对原始的钻孔数据按插值范围进行分块,同时确定每块数据的起始和终点坐标,执行串行遍历,每块数据都进行三重循环,做到完全遍历。
2)按照1×1×1的插值密度,对空间范围内所有的坐标点和原始钻孔数据的坐标点都进行遍历,将空间点坐标与已知点坐标进行比较计算,执行串行遍历。
3)对插值范围内的所有点与已知点根据欧拉公式计算出欧氏距离,根据计算的距离大小,求出最小值,在最小距离下,对待估算的点进行赋值,在三重循环结束后,结束串行算法。
2.2 并行算法
由于串行算法要进行三重循环,加大了数据的计算量,考虑到模型时单指令多数据流模型,利用G P U的体系结构,对三维泰森串行算法进行优化,采用并行算法,算法流程如图3所示。
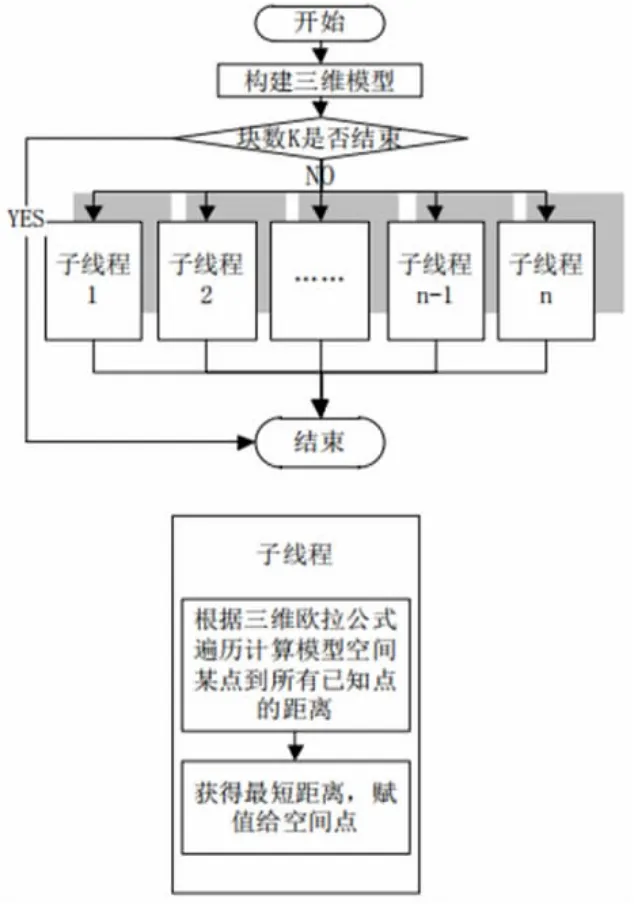
图3 三维并行算法流程
利用G P U中多个AL U的性质,根据体素进行并行计算,每个体素映射在三维计算单元内,通过单独的子线程进行品位计算,将重复遍历的数据放置在Thread中,在Thread中重复遍历的部分就是在串行算法中空间点坐标与已知点坐标进行遍历后,求出的最小距离,将这一部分程序放在Thread中,程序可以同时计算,互不影响,提高了遍历速度,需要注意的是,对G P U要进行三维索引,使空间坐标点与G P U线程索引ID相互对应,在Thread执行完所有程序后,并行算法结束。受某些硬件条件的限制,需要将模型进行划分,按照一定的规则和顺序,对每块进行并行计算,直到所有的块都计算为止,整个模型的品味属性才完成计算。
2.3 实验结果
为了验证优化的并行算法的可行性,随机选取不同规模的三维数据,分别进行串行和并行计算,实验结果见表1。
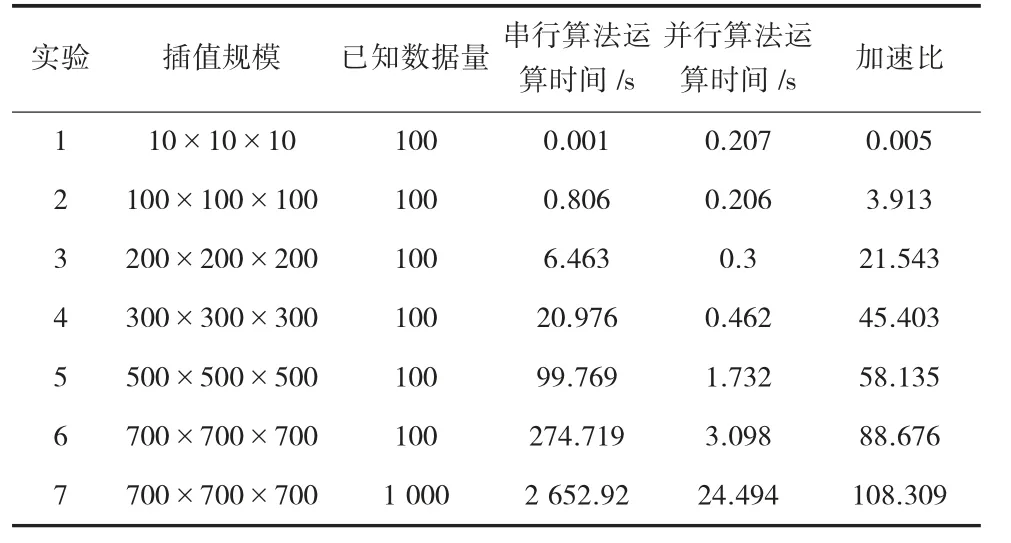
表1 三维泰森插值法串并行情况对比表
根据表1,在单机并行插值规模不断增大时,已知数据量不变,在插值规模为10×10×10时,并行算法运算时间为0.207 s,串行算法运算时间为0.001 s,其加速比为0.005,在插值规模较小时,G P U的加速效果不是太明显,而随着插值规模的增大,G P U的性能明显提升。可以看出,在插值规模为700×700×700时,并行算法运算时间为3.098 s,而串行算法运算时间长达274.719 s,加速比为88.676。在单机并行插值规模不变时,已知数据量增大,在插值规模均为700×700×700时,已知数据量为100条时,并行算法运算时间为3.098 s,已知数据量为1000条时,并行算法运算时间为24.494 s,随着数据量的增大,串行和并行的运算时间也会相应的增加,由于数据量的增加,导致要进行距离比较的数据量相应增加,进而运算时间也就不断增加。
综上所述,在插值规模较小时,由于数据传输的延迟性,G P U并行算法的优势不太明显,而随着插值规模的不断增大,G P U并行算法的运算时间大大提高,模型的空间插值效率也得以提高,节省了模型构建时间。
3 应用效果
对虎龙沟矿建立煤质矿体模型,进而对煤炭资源储量进行精确估算,模型的插值规模为3 700×4 237×71,对每个空间点估算品味属性,分别采用串行算法和优化的并行算法进行分析,构造出矿体化模型,得到煤炭资源储量的对比结果见表2。

表2 煤炭资源储量对比结果
从表2可以看出,采用并行算法估算出的煤炭储量为21 973万t,运算时间约2 401.193 s,而采用串行算法的运算时间约141 471 s,估算出的煤炭储量也与累计的煤炭储量21 867万t有一定的差距,因此,采用优化的并行算法得到的估算结果更准确,算法运算时间也更快。
4 结论
为估算煤炭资源储量,传统的三维泰森串行算法已不能满足要求,以虎龙沟矿为基础,提出三维泰森并行优化算法构建体矿模型,结果如下:
1)通过不同规模的三维数据,对串行算法和并行算法进行对比分析,验证并行算法的可行性,得到利用G P U对插值规模较大的矿体模型进行空间插值并行运算可以提高运算效率。
2)在虎龙沟矿上进行验证,以原始钻孔数据品味属性作为已知数据,采用插值并行算法,估算出煤炭资源储量为21 973万t,与实际储量更贴近,算法运算时间也较快,为准确快速估算储量提供了解决办法。
猜你喜欢
科技创新导报(2021年31期)2021-05-10 14:55:00
矿产勘查(2020年2期)2020-12-28 00:23:38
青年文学家(2020年28期)2020-11-02 13:20:37
档案天地(2019年9期)2019-10-09 06:10:34
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:43
公务员文萃(2016年10期)2016-10-31 00:44:23
读者(2014年21期)2014-10-15 03:14:40
河南科技(2014年16期)2014-02-27 14:13:33
电子设计工程(2014年18期)2014-02-27 12:00:14
意林原创版(2008年9期)2008-07-06 09:40:08
