
基于图像LBP特征与Adaboost分类器的垃圾分拣识别方法*
2021-11-15 02:41陈昱辰曾令超张秀妹钟广泽
南方农机 2021年21期
陈昱辰 , 曾令超 , 张秀妹 , 钟广泽
(广东白云学院,广东 广州 510450)
0 引言
随着人们生活水平的提高,对于生活垃圾的有效处理和相关高价值废品的回收再利用,已日益成为社会关注的焦点。目前,生活垃圾多由环卫工人手动分拣,工作强度大、效率低而且严重危害环卫工人身体健康[1]。虽然有用于分类的垃圾回收装置,但是要求丢弃者进行预分类且相关人员需具有很高的环保分类知识,垃圾分类在社会上推广受到一定的限制。
在垃圾识别和图像分类方面,学者们进行了大量的研究。吴健等[2]利用颜色和纹理特征,初步完成了垃圾分类,但由于不同数据集的图像背景、尺寸、质量不尽相同,传统算法需要根据相应数据人工提取不同的特征,算法的鲁棒性较差,并且处理方式复杂,所需时间较长,无法达到实时分类的效果。在非公开数据集方面,Mittal等[3]利用2 561张的垃圾图片数据集GINI,使用GarbNet模型,得到了87.69%的准确率。不过由于相同类别垃圾的特征表征差异性较大,不仅增加了样本的收集量,还无法确保准确率。莫卓亚等[4]通过图片的采集、模型的训练,初步实现了垃圾分类的识别。然而由于模型对预测图片明暗色彩过度依赖,导致不同场景的图片有些识别效果好,有些识别效果差。
针对目前垃圾识别和图像分类精准度、效率上存在的不足,课题组设计了基于LBP特征的级联分类器对果皮和有害垃圾进行识别,这种基于LBP特征的级联分类器具有识别精度、效率较高的特点[5],并采用纹理描述算法对果皮和有害垃圾特征进行提取的方法[6],最终实现对果皮和有害垃圾快速取样识别。
1 基于LBP特征的级联分类器模型分析
1.1 基于LBP图像的编码
LBP编码算法是常见的纹理描述符算法[7],它根据图像的n×n邻域中,中心位置的像素值为阈值,将图像的像素值转换成一个二进制数字。例如,在3×3的邻域中,编码后的像素值是根据阈值(对应的原像素值)以及其相邻的8个像素值决定的。编码前需要将3×3区域的rgb像素值转化为灰度值,并将其与相邻点灰度值进行比较,如果大于阈值为0,否则为1,最终得到由0和1组成的集合,最后沿圆周顺时针追踪像素,得到一个8位数的二进制值,作为该点的像素值。
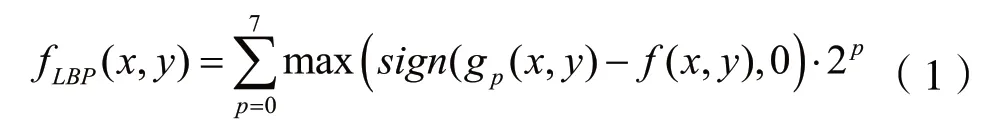
其中,fLBP(x,y)为编码后图像的f(x,y)的灰度值,满足0≤fLBP(x,y)≤255;f(x,y)为编码前图像的(x,y)的灰度值。gp(x,y)与f(x,y)对应关系如表1所示。

表1 gp(x,y)与f(x,y)对应关系
1.2 Adaboost强分类器训练
输入的样本数为m,定义果皮样本的输出为1,有害垃圾等其他样本输出为-1,输出结果集合为{-1,1}。训练弱分类器前,初始化各样本集得到权重系数集合为:
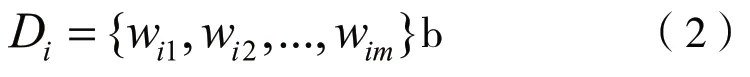
其中,wij为第i级弱分类器的第j个样本的权重系数,wij满足
利用决策树算法,将带权重的图像提取的LBP灰度特征与分类器的特征进行逐个比较,得到弱分类器hi(x)。由于LBP纹理特征计算涉及指数运算,本研究采用的误差计算方法是指数误差计算,得到第i级分类器的误差率ei满足:
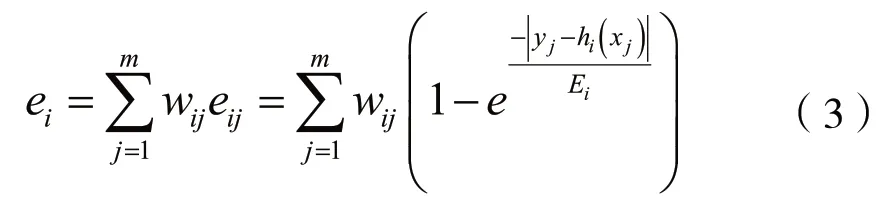
其中,yj为第j个样本的实际分类值(1或-1)。hi(xi)为第i级弱分类器对第j张图片计算得到的预测值,Ei为第i级弱分类器的最大误差,满足:
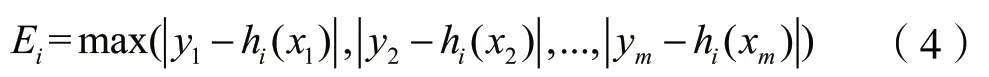
计算第i级弱分类器的学习率权重系数αi,误差越大,学习的权重越大:

根据学习率权重系数αi更新下一级弱分类器各样本的权重系数wij,满足:

对前i级的分类器进行加权平均,得到弱分类器组成的强分类器识别模型[8-10]Hi(x):

Adaboost的强分类器训练模型如图1所示。
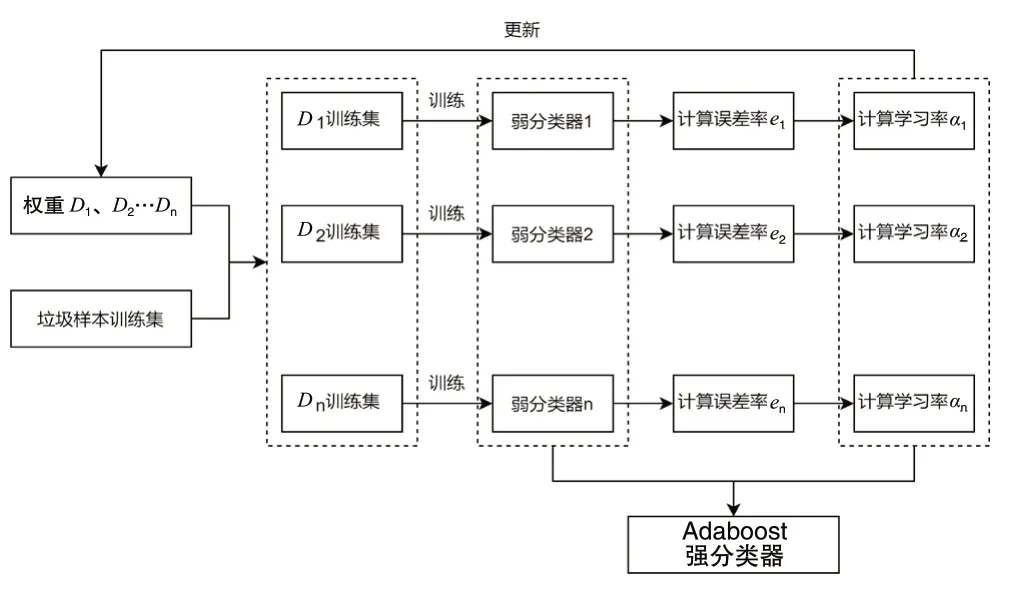
图1 Adaboost的强分类器训练模型
1.3 果皮和有害垃圾识别模型训练
针对果皮和有害垃圾的小样本数据集进行分类器训练,先对这两类垃圾进行分类标定,果皮样本作为正样本,有害垃圾等其他样本作为负样本,并对正样本进行图像尺寸变换为100×100。然后,初始化分类器参数,负样本进行随机裁切后,对所有样本进行LBP特征值计算,迭代训练i级弱分类器,一旦超过用户设定的最大级数nS或者前i级组成的强分类器识别模型小于用户设定的最小报警率FA,训练完成。
算法流程图如图2所示。

图2 算法流程图
主要算法流程如下:
1)输入果皮和有害垃圾样本。随机从果皮和有害垃圾图像库中抽取42张图片,作为训练正样本集进行输入。
2)预处理。对输入果皮和有害垃圾训练图像进行尺度和灰度转换至预训练模型,规定输入尺度大小。
3)建立果皮和有害垃圾识别模型。对LBP特征提取后的图片样本带权重的输入到Adaboost模型训练,通过梯度下降法调整弱分类器的模型权重,并计算学习率权重,产生该级弱分类器的权重系数以及下一级训练输入至弱分类器模型的权重,直至满足终止条件——级数超过设定值、总误差率小于设定值。
4)模型测试。从果皮和有害垃圾图像库中抽取不同类型的果皮和有害垃圾图片,作为测试原本集进行模型测试,以验证模型的精确度。
2 结果与分析
对果皮和电池、废灯管、杀虫剂等有害垃圾进行了识别研究,以123张图片作为训练集,其余的作为测试集。
2.1 网络模型训练基本参数配置
模型训练和测试硬件环境:Intel(R) Core(TM)i5-7300HQ CPU @ 2.5GHZ * 4处理器,16 G内存,NVIDIA GeForce GTX 1050Ti 显卡加速图像处理。软件环境:操作系统为Windows 10 Pro,开发软件为CLion 2019。具体训练参数设置如表2所示。

表2 所有的级联分类器LBP模型训练参数设置
2.2 网络模型训练结果
训练样本大小为123,通过训练层数得出由18级弱分类器加权得到的强分类器预测精确度最接近90%。网络训练参数曲线图以及果皮和有害垃圾识别效果图如图3、图4所示。

图3 网络训练参数曲线图

图4 果皮和有害垃圾识别效果图
2.3 模型测试结果
果皮和有害垃圾数据测试集共用了314张图片,包括香蕉皮80幅、电池97幅、废灯管30幅,杀虫剂107幅,分别测试网络模型,得出识别结果如表3所示。

表3 垃圾图像识别结果
3 结论
1)提出了一种基于级联分类器的LBP特征模型识别果皮和有害垃圾的方法,可提取果皮和有害垃圾的特征,避免了手工特征的设计和提取。
2)基于级联分类器的LBP特征模型具有较高的识别精准度,能够达到快速识别的目的。
3)操作简单,具有较强的健壮性,能够维持某些性能的特征。
猜你喜欢
心理学报(2022年5期)2022-05-16
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
当代陕西(2020年17期)2020-10-28
小学生学习指导(低年级)(2019年9期)2019-09-25
计算机测量与控制(2019年4期)2019-05-08
小学生优秀作文(低年级)(2018年12期)2018-12-13
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
中华手工(2016年4期)2016-04-20
