
基于GAN的视频流超分辨率方法设计与实现
2021-11-14 01:13李耀兵
无线电工程 2021年11期
李耀兵,李 赟,李 俊
(国家工业信息安全发展研究中心,北京 100040)
0 引言
超分辨率的研究按照对象可划分为单帧图像超分辨率和多帧图像(视频)超分辨率[1]。由于多帧图像多出了时间维度,简单地将视频看作是一个个单帧图像,通过对单帧图像的处理来实现对视频的超分辨率任务,结果通常是视频变得不再平滑,视频内的物体会有移位的现象。图像分辨率定义的直观表现是图像的像素数目,更大的感光元件才能捕获更多的细节信息。因此,要得到高分辨率图像需要感光元件(图像传感器)有更大的感光面积,同时需要更大的带宽来传输高分辨率的图像。图像的分辨率越高,图像的细节信息就越丰富。受硬件、功耗和带宽等的限制,图像和视频的分辨率在实际应用中往往达不到理想状态,因此只能在这些因素之间进行均衡。在实际应用中,单纯地通过硬件的方式来提升图像分辨率的代价太高。因此,在当前的硬件基础上,通过算法提升图像和视频的分辨率成为研究界和工业应用所期盼的重要技术之一[2]。
按照输入图像的数量,可以将图像超分辨率分为单帧图像超分辨率算法和多帧图像超分辨率算法。单帧图像的超分辨率算法包含基于插值的和基于学习的方法。基于插值的方法执行速度快,但得到的结果有时过于模糊,可能存在锯齿效应,复原质量较差。基于学习的方法具有更好的处理效果,引起了大家的普遍关注[3-5]。
近年来,基于学习的单帧图像超分辨率算法通过样例数据集,学习低分辨率图像到高分辨率图像间的非线性映射关系。通过构建低、高分辨率图像的训练数据集进行训练。当训练数据集包含的信息充足时,基于学习的单帧图像超分辨率算法可以得到具有很高质量的超分辨率结果。传统的基于学习的方法包括最近邻[6]、邻域嵌入[7]、稀疏表示[8]、锚近邻回归[9]和随机森林[10]等机器学习方法。
董超等[11]将卷积神经网络引入到单帧图像超分辨率中。在此之后,深度学习在单帧图像超分辨率中得到了广泛应用。He等[12]提出了深度残差学习方法,可以解决图像识别中深层卷积神经网络的降质问题。深层卷积网络的降质问题是指随着网络层数的加深,网络的拟合能力不增反降。深度残差网络通过在卷积神经网络中添加跨步连接,使得深层卷积神经网络的优化变得容易,从而提高了卷积神经网络的容量和表达能力。深度残差学习被引入到单帧图像超分辨率中取得了视觉质量很好的超分辨率结果。
上述单帧图像的超分辨率算法可以直接用于视频超分辨率重建,但由于没有利用视频中的帧间互补信息,往往不能取得很好的超分辨率结果。目前,通过对多帧图像超分辨率的研究,将超分辨率分成了4个阶段:特征提取、对齐(对准)、融合以及重建。当视频中有大范围运动且模糊严重时,对齐以及融合算法决定了最终视频超分辨率的质量。生成对抗网络(Generative Adversarial Networks,GAN)[13]通过生成器和判别器之间的对抗使生成器生成更加逼真的结果,得益于这一特性,采用GAN结构做单帧图像和多帧图像超分辨率的工作引起了很多学者的关注。
本文采用SRGAN[14]的基础结构用于多帧图像,超分辨率生成器部分采用EDVR[15]中的PCD模块用于相邻帧对齐,TSA模块用于相邻帧融合。同样,也将生成器部分的BN层去除减少人为制造的噪声。
1 基于GAN的多帧图像超分辨率
多帧图像的相邻帧之间有较强的相关性。多帧图像超分辨率问题涉及到了三维领域,因为多了时间变量,随着时间的推移,图像中的物体会产生一定程度的位移。如果通过计算得到了这个位移矢量,就可以将发生位移之后的图像减去这个位移矢量,减去位移矢量后的图像就和发生位移前的图像达到了对齐的效果。之后,将对齐的几个相邻帧进行融合操作,可以得到更多的细节信息,再进行图像的重建时可以达到更好的超分辨率效果。更好的对齐算法能够更精确地估计图像的位移矢量,下一步融合可以通过对齐的相邻帧得到更多的细节信息。因此,多帧图像超分辨率中最重要的操作是对齐和融合。发生位移后的图像减去位移矢量,也叫做运动补偿。光流法之类的算法都是采用显式的运动补偿,即先求出位移矢量,再用扭曲的操作进行运动补偿。采用隐式运动补偿方式的多帧图像超分辨率网络可以达到比光流法更好的效果。相邻帧对齐算法PCD来自于EDVR,它采用隐式的运动补偿方式,达到了很好的相邻帧对齐效果。相邻帧融合算法TSA来自于EDVR,采用基于时间和空间注意力机制的融合算法。将结合PCD和TSA之后的GAN网络称为SRGAN-PT。
1.1 多帧图像超分网络SRGAN-PT
随着对多帧图像超分辨率的研究,一般将这个过程分解为4部分:特征提取、相邻帧对齐、相邻帧融合和图像重建。每部分是独立的功能模块,这样能够达到更好的效果,也更容易对某一具体的功能进行优化。生成器模型如图1所示。
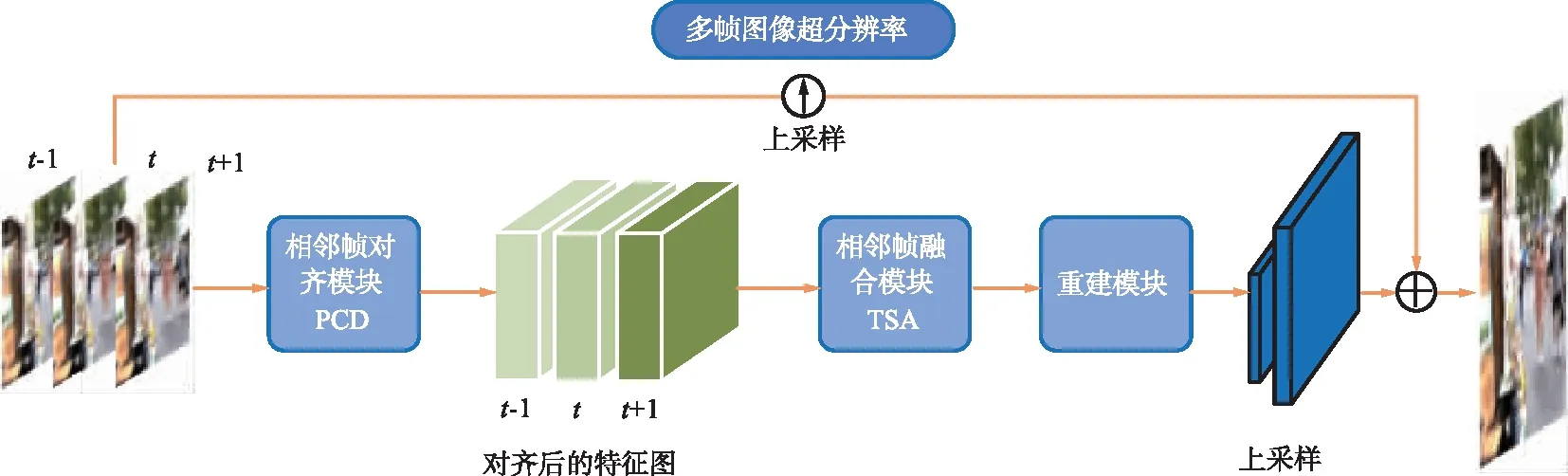
图1 生成器模型Fig.1 Generator model
基于GAN的多帧图像超分辨率模型的生成器主要由相邻帧对齐PCD模块、相邻帧融合TSA模块和图像重建模块组成。下面描述一下生成器的大体计算过程。给定2N+1个连续的低质量视频帧 ,将中间帧作为参考帧,其他帧作为相邻帧。视频恢复的目的是估计出一个高质量的参考帧,它接近于ground truth帧。每一个特征级别的相邻帧都经过PCD模块处理与参考帧对齐,TSA融合模型融合不同帧的图像信息,这2个过程将在后面详细描述。融合后的特征会经过重建模块,重建模块是一个简单的残差块之间的串联结构,重建后的特征图再经过上采样操作得到初步超分辨率帧,最后上采样后的帧会跟初始输入的直接上采样的参考帧进行加和操作得到最终的超分辨率帧。
包含金字塔结构、级联结构和可变形卷积的对齐模块(PCD):首先介绍可变形卷积在对齐中的应用,将每个相邻帧的特征与参考帧的特征对齐。不同于基于光流的方法,变形对齐应用在每一帧的特征上,Ft+i,i∈[-N,+N]。当给定一个有K个采样位置的可变形卷积核,令wk和pk为权重以及第k个采样位置的特定偏移。例如一个3×3的卷积核,它的K=9,并且pk∈{(-1,-1),(-1,0),…,(1,1)}。在每个p0位置处对齐后的特征:
(1)
可学习的偏差ΔPk和调制标量Δmk由相邻帧和参考帧连接后的特征来预测:
ΔPt+i=f([Ft+i,Ft]),i∈[-N,+N],
(2)
式中,ΔP={Δp};f是由一些卷积层组成的函数;[.,.]表示拼接操作。为了方便,只考虑可学习偏差ΔPk,忽略调制参数Δmk。因为p0+pk+Δpk是分数,所以需要用双线性插值来对坐标取整。为了解决复杂的运动和大视差对准问题,采用了 PCD模块,即:金字塔处理和级联细化。
PCD对齐模块包括金字塔结构、级联和可变形卷积,如图2所示。
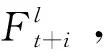
(3)
(4)
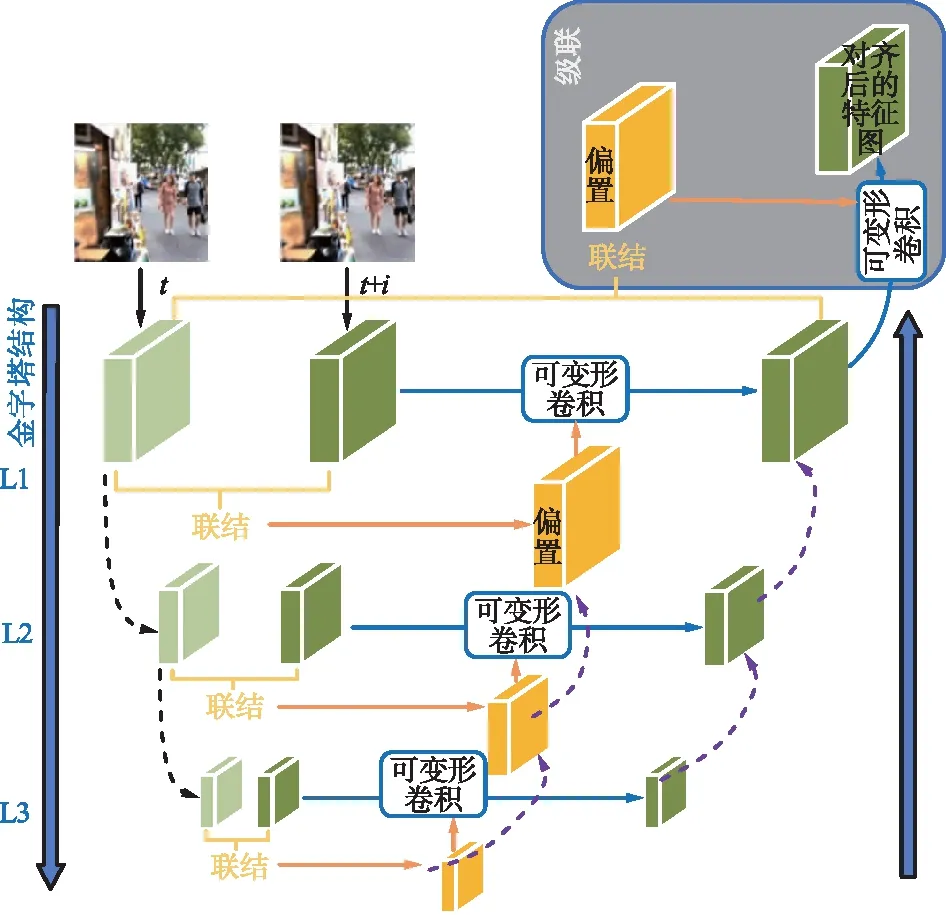
图2 PCD对齐模块,包括金字塔结构、级联和可变形卷积Fig.2 PCD alignment module,including pyramid structure,cascade and deformable convolution
式中,(.)↑s表示s倍扩大;DConv为可变形卷积;g为具有多个卷积层的通用函数。采用双线性插值实现2倍上采样。本文使用3层金字塔,即L=3。为了降低计算成本,卷积层的特征图没有随着空间尺寸的减小而增加通道数。在金字塔结构之后,后续的可变形对齐被级联以进一步细化粗对齐的特征。PCD模块以由粗到细的方式将对齐提高亚像素精度。PCD对准模块与整个框架一起联合学习,没有额外的监督或其他任务例如光流的预训练。
基于空间和时间注意力机制的融合算法,帧间的时间关系和帧内的空间关系是融合的关键,因为:① 由于遮挡、模糊区域和视差问题,不同的相邻帧不能提供相同的信息;② 没有对齐以及错误对齐对后续重建效果产生不利影响。因此,在像素级对相邻帧进行动态聚合是有效融合必不可少的。为了解决上述问题,采用TSA融合模块,在每帧上分配像素级的聚合权重。在融合过程中采用了时间和空间的注意力机制,如图3所示。

图3 TSA融合模块,包括时间和空间注意力机制Fig.3 TSA fusion module,including time and space attention mechanism
时间注意力的目标是计算在嵌入(embedding)空间的帧的相似性。在embedding 空间中,相邻帧更容易跟参考帧相似,应该被给予更多的关注。对于每一帧,相似距离h为:
(5)
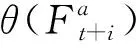
(6)
(7)
式中,⊙以及 [.,.,.] 表示element-wise multiplication以及concatenation。 从融合的特征中计算出空间注意掩码,采用金字塔设计来增加注意力接受域,融合的特征被掩模通过元素的乘法和加法调制。
判别器部分跟上文的SRGAN-PR的判别器部分一致。当生成器通过多帧图像合成最后的超分辨率的图像后,会将其跟原始的高分辨率图像一起作为判别器的输入,得到生成图像是真实图像的概率。
1.2 损失函数部分
生成器最终损失函数由2部分组成,一个CharbonnierLoss:
(8)

(9)
式中,DθD(GθG(I[t-N:t+N]))表示重建图像GθG(I[t-N:t+N])是真实高分辨率图像的估计概率。为了更佳的梯度,将损失定义为-logDθD(GθG(I[t-N:t+N]))而不是log[1-DθD(GθG(I[t-N:t+N]))]。最终的损失函数为:
(10)
2 实验与结果分析
首先介绍了实验环境和数据,然后介绍了实验过程,最后将本文的方法和其他相关算法进行对比,证明本文算法在视频流超分辨率方面的优势。
2.1 实验数据
由于Vimeo-90K全部数据量太大,所以将它的测试数据集当作本文的训练数据集,将Vid4-41作为测试集。训练集数据集由7 824个小视频组成,每个视频有7帧图像,图像尺寸为448 pixel×256 pixel。通过对高分辨率图像使用bicubic算法4倍下采样得到低分辨率图像,图像尺寸为112 pixel×64 pixel。
2.2 实验过程
PCD对齐模块采用5个残差块(RB)进行特征提取。在重构模块中使用了10个RBs。每个剩余块中的通道大小设置为64。数据集图像大小为112 pixel×64 pixel×3 pixel。图像读入后进行随机的剪裁,增加数据的丰富性。Mini-batch大小设置为16。网络需要5个连续的帧作为输入。用随机水平翻转以及90°旋转增加训练数据。设置β1=0.9,β2=0.999的Adam optimizer来训练模型 。学习率初始化为4×10-4。使用PyTorch框架实现超分辨率模型。使用Geforce RTX 1080Ti单卡服务器训练网络。
2.3 实验结果
几种方法的超分辨结果对比如图4所示。

(a) Bicubic

(b) EDVR

(c) 本文方法

(d) 原始高清图像图4 几种方法的超分辨结果对比Fig.4 Comparison of super-resolution results of several methods
由图4可以看出,将GAN跟PCD和TSA结合后的网络初步达到了期望的结果,比Bicubic效果好了不少,但是跟目前的前沿模型EDVR有明显差距。
PSNR结果对比如表1所示。

表1 PSNR结果对比Tab.1 Comparison of PSNR results
SSIM结果对比如表2所示。

表2 SSIM结果对比Tab.2 Comparison of SSIM results
由PSNR和SSIM的计算结果来看,跟前沿模型有不小差距。分析可能的原因是对于GAN的调教能力欠缺,另外受限于机器,网络深度比较浅,训练数据集的规模较小,但是总体上还是达到了对于视频超分的目的。
3 结束语
对于多帧图像超分辨率,最关键的2个步骤是相邻帧对齐以及相邻帧融合。本文采用SRGAN的基础结构,并在此之上采用PCD模块和TSA模块解决上述问题。传统光流算法只适用于小范围位移场景,而PCD算法可以适用于大范围的位移,以及画面模糊等场景。PCD采用金字塔结构从粗到细地进行帧间对齐,再级联一个可变性卷积模块增加模型的鲁棒性。相邻帧融合之后需要充分考虑帧与帧之间的空间和时间冗余,本文的TSA模块,采用基于时间和空间注意力机制的融合算法,时间注意力和空间注意力可以将对齐帧进行修整,与参考帧更相似的部分会给予更高的权重,之后的融合过程会保留更多有用信息,令融合后的参考帧内容更加丰富。同时保留了SRGAN的判别器部分,令生成器能生成更多的内容信息。实验结果表明,上述模块设计有助于解决多帧图像超分辨率中的相邻帧信息之间的对齐,以及相邻帧之间的融合问题,给多帧图像的超分辨率方法提供了更多的可能性。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
数学物理学报(2019年3期)2019-07-23
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年9期)2018-11-02
北京航空航天大学学报(2018年1期)2018-04-20
制造技术与机床(2017年7期)2018-01-19
自动化学报(2017年5期)2017-05-14
