
基于通道分组注意力的无监督图像风格转换模型
2021-11-13 09:52孙铭一孙刘杰李佳昕
包装学报 2021年5期
孙铭一 孙刘杰 李佳昕
上海理工大学
出版印刷与艺术设计学院
上海 200093
0 引言
图像风格转换是近年来机器视觉领域的研究重点之一。根据图像风格转换模型在训练中是否需要成对的数据,其可分为有监督学习和无监督学习。有监督学习需要成对的数据和人工对数据打标签,导致时间成本过高。无监督学习不需要成对的数据,相较于有监督学习,其数据获取更加简单高效,普适性更高。根据一张输入图像是否能够对应获得多个输出图像,图像风格转换模型可分为单模态模型和多模态模型。在单模态模型中,一张输入图像只能获得一张对应的输出图像,当输入数据不成对时,其局限性便体现在模型的输出结果不确定上。在多模态模型中,一张输入图像可以对应多张输出图像,因而多模态模型能够很好地应对多图像转换任务,例如包装平面设计[1]、文图转换等。
近年来有关多模态无监督图像风格转换的研究越来越多,这些研究都是基于生成对抗网络[2](generative adversarial networks,GAN)。Choi Y.等[3]提出了人脸图像多模态转换模型StarGAN,Yu X. M.等[4]提出了SingleGAN。StarGAN使用星形生成网络结构并在输入中添加目标领域信息,再结合判别器的分类结构和循环重构一致性约束完成图像翻译工作。但是其欠缺对图像重构损失的考虑,因而图像风格转换时某些固定属性会发生变化,导致图像质量下降。SingleGAN则采用类别便签指导方法,在StarGAN的基础之上对网络结构作出改进。2018年,Huang X.等[5]提出的MUNIT和Lee H. Y.等[6]提出的DRIT,均是基于内容与风格分离编码再交叉解码的方法以获得多样的输出。与DRIT不同的是,MUNIT采用自适应实例规范化算法(adaptive instance normalization,AdaIn)的风格特征参数[7]来融合内容特征,以实现图像风格转换。DRIT的转换效果不如MUNIT,而MUNIT的转换效果不如有监督的多模态模型BicycleGAN[8]。但有监督的多模态模型BicycleGAN需要成对的输入数据,这增加了数据集的获取难度,且模型体积庞大。
为了提高无监督模型的输出图像质量,解决局部伪影和局部特征丢失等问题,本课题组在MUNIT的基础上,提出了基于通道分组注意力(channel-divided with attention,CDA)的无监督图像风格转换模型。在生成器部分,构建通道分组注意力残差块。在鉴别器部分,利用多分辨率尺度的全局鉴别器对输出图像进行不同分辨率尺度上的鉴别,利用局部鉴别器[9]对输出图像局部进行鉴别。
1 无监督图像风格转换模型
1.1 模型结构
本文所提的无监督图像风格转换模型的主要创新点如下:
1)采用通道分组注意力残差块构建生成器。CDA残差块主要包含通道分组和通道注意力机制(ef ficient channel attention,ECA)[10-11]两个模块。通道分组模块能够实现残差块内的跳跃连接,减少特征丢失;ECA模块能够自适应地调整特征图通道权值,提高网络对有效特征的关注度,并进一步减少模型参数量以及体积。
2)采用双鉴别器结构构建鉴别器。多尺度全局鉴别器对输出图像在多分辨率尺度上进行联级鉴别,以提高输出图像的结构连贯性与内容完整性;局部鉴别器对输入图像进行剪裁,即获得1/4的图像,以提高输出图像精度。
3)引入 NIMA(neural image assessment)[12]美学评分模型评价风格转换图像质量。NIMA模型对输出图像的真实性进行客观评价,并从图像美学的角度评估图像风格是否美观。将主观评价结果参数化减少了人眼判断的随意性与主观偏差,提高了评价过程的操作便捷性与公平性。
无监督图像风格转换模型的训练网络结构如图1所示。测试时,本模型仅需输入单张边缘图像或者实物图像即可得到转换后的风格图像。

彩图
在图1中,无监督图像风格转换模型为对称结构,包含两个结构相同的生成器GA、GB,两个结构相同的风格编码器ESA、ESB,以及两个结构相同的鉴别器DA、DB。鉴别器DA由多尺度全局鉴别器GD和局部鉴别器LD组成。输入图像A(实物图像)与输入图像B(边缘图像)互为各自的风格图像,均在生成器和风格编码器完成图像内容和风格的编码,进而实现两个生成器之间的交叉解码,得到的输出图像再进入鉴别器进行鉴别以及前向反馈,最终完成整个训练网络的调整与优化。基于循环一致理论,无监督图像风格转换模型能实现实物图像与边缘图像的互相转换。现有的边缘提取算法,如Canny算子、Sobel算子等,均能检测出清晰完整的边缘,因此本研究不是将图像A到图像AB(边缘图像)的风格转换作为研究重点,而是将图像B到图像BA(实物图像)的风格转换作为研究重点。此转换涉及的主要模块有生成器GA、风格编码器ESA、鉴别器DA,转换过程可描述如下:
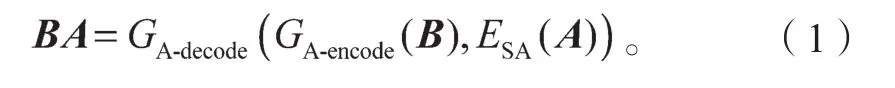
1.2 风格编码器
风格编码器保留了MUNIT中的方法,由两个下采样层、一个池化层以及一个全连接层组成。提取图像的风格编码后,多层感知器(multilayer perceptron,MLP)对其进行加工处理,以一维的AdaIN参数形式融合到生成器的解码器中,与内容信息共同解码,从而获得新的风格图像。 MLP是一种前向的全连接神经网络结构,每一层的单个神经元均与下一层中的所有神经元连接。其中,AdaIN的工作机制是,给定一个内容图像和一个风格图像,通过调整输入的内容图像的均值和标准差来匹配输入的风格图像,从而实现图像间的风格转换。假设输入的内容图像为c,输入的风格图像为s,则AdaIN归一化操作公式为
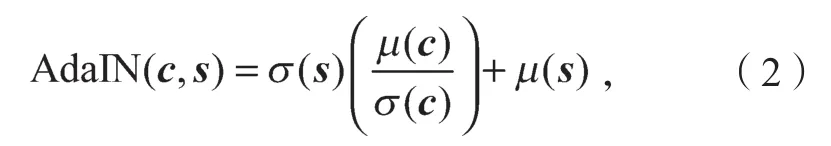
式中:μ(c)、μ(s)分别为内容图像、风格图像的均值;
σ(c)、σ(s)分别为内容图像、风格图像的标准差。
式(2)将内容图像与风格图像的均值和标准差对齐,即通过传递特征统计信息在特征空间进行风格转换。以图1中的风格编码器ESA为例,在图像风格转换过程中,ESA对输入图像A进行编码,提取其风格特征信息sA,

1.3 生成器
生成器为编码器-解码器结构,其中,编码器由两个下采样层和4个通道分组注意力残差块CDA组成,解码器由4个通道分组注意力残差块CDA和两个上采样层组成。编码器和解码器的主要构成模块均为通道分组注意力残差块CDA,该残差块的构建主要参考了Gao S. H.等[13]提出的res2net。res2net能够以更细的粒度来表示多尺度特征,同时增加了每个块内网络层的感受野,在目标检测、语义分割等机器视觉任务中其有效性得到证实。
边缘图像中,边缘在整张图像中的占比远小于空白部分,过大的感受野会使边缘信息占比更少,导致网络学习很多无效信息,使生成的图像质量下降,出现伪影、空洞等现象。倘若缩小感受野,则会增加参数计算量,加重模型负担。因此,本研究在不改变感受野大小的前提下,将残差块中basicblock模块的第二层卷积层按照通道数n均分为两个维度相同的网络,一个为常规3×3卷积,另一个作为浅层信息,通过concat跳跃连接[14]与卷积后的特征图进行拼接,重构n通道特征图。在改进后的残差块末端引入ECA,构建通道分组注意力残差块结构,如图2所示。
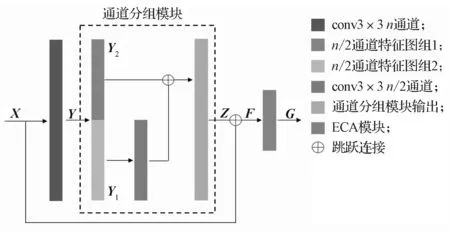
图2 通道分组注意力残差块结构Fig. 2 Structure of CDA residual block

彩图
在图2中,假设原始输入数据为X,经过第一层卷积后输出Y,
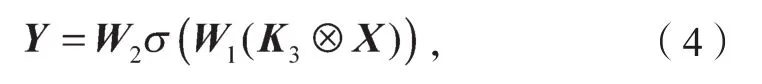
式中:W1、W2分别为第一层3×3卷积、第二层通道分组模块的权重;
σ为Relu激活函数;
K3为3×3卷积核;
第二层卷积按照通道数均分为两个网络,分别得到n/2通道的特征图Y1、Y2。Y1通过跳跃连接与Y2进行拼接,重构n通道特征图Z,
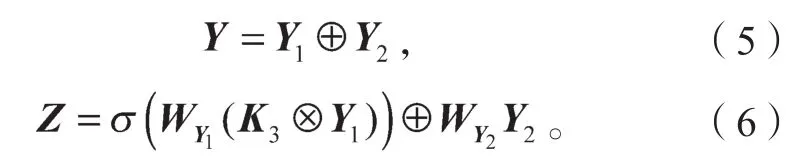
残差块的输出F满足如下公式:
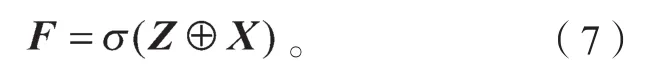
通道分组是通过将特征先拆分后融合的策略,使卷积网络能更高效地处理边缘特征。这既实现了边缘特征的深度提取,又实现了浅层边缘特征的重复利用,保留了更多的有效信息[13]。
随后,F作为ECA层的输入数据,进一步完成各通道权重的自适应调整。ECA是由Wang Q. L.等提出,通过不降维且自适应地捕捉图像各特征图之间的跨通道交互,自适应地调整更新各特征图通道的权值,并对各特征图通道间的内部依赖关系进行建模,从而降低模型的复杂程度,提高网络对于有效特征的关注能力。ECA结构如图3所示。
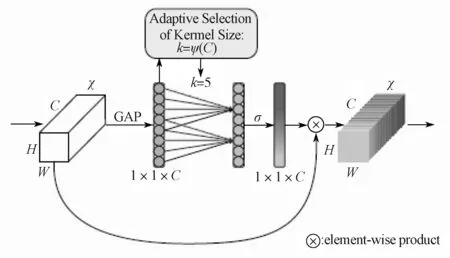
图3 ECA结构Fig. 3 Structure of ECA
ECA去除了全连接层,在全局平均池化后通过一个可以权重共享的一维卷积对特征图进行学习。该一维卷积涉及超参数k即一维卷积的卷积核尺寸,它代表了局部跨通道交互的覆盖率。超参数k与输入特征图通道数C之间存在如下映射:

因此,k为

式(8)~(9)中γ和b为常量,γ=2,b=1。
重构后的特征图F可表示为集合{ni}(i=1,2,…,n),则在ECA层中,第i个通道的局部跨通道交互权重wi为

式中:θ为sigmoid函数;
wj为所有通道间共享的权重;为ni的k个相邻通道的集合。
可视化通道特征通常表现出一定的局部周期性,因此,通过权重共享的方式捕获局部的跨通道交互,既可以实现有效边缘信息的提取与利用,又避免了捕捉跨所有通道交互所带来的模型复杂度与计算量[10]。经过卷积核大小为k的一维卷积后,结合式(7),通道间的信息交互权重矩阵w为
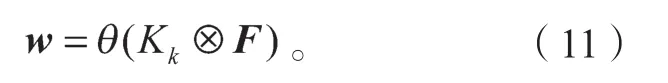
式中Kk为k×k卷积。
通过权重矩阵w实现输出特征图各通道的权值自适应调整,以不降维方式捕获更多有效边缘信息,因此通道分组注意力残差块的最终输出G为

1.4 鉴别器
鉴别器由两部分组成,分别是用于鉴别整张输出图像的多分辨率尺度全局鉴别器GDA以及用于鉴别剪裁后局部输出图像的局部鉴别器LDA。全局鉴别器GDA采用多尺度结构,即先对图像BA进行多次降采样操作,生成大小不同的图像,再通过多分辨率尺度并联鉴别,使输出图像的全局内容连贯和全局结构合理。全局鉴别器GDA包含3个不同的鉴别分辨率尺度,分别是256×256, 128×128, 64×64,每个尺度均输出一个判断值,随后通过加权平均得出整个全局鉴别器的判断值。局部鉴别器LDA为单尺度结构,其输入为剪裁1/4的图像BA后的图像BAcut,大小为128×128。局部鉴别器LDA对局部图像进行鉴别后输出一个判断值,随后与全局鉴别器GDA的判断值通过加权平均方式计算出鉴别器DA的最终判断值。
全局鉴别器和局部鉴别器均采用PatchGAN[15]结构。PatchGAN是将图像分成若干个70×70的小块,每个小块输出一个判断值,最终根据得到大小为m×m的矩阵计算判断值。PatchGAN可以综合考量整张图像不同部分的影响,使得判断结果更加准确。
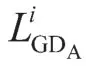

式中:E为期望;
p(•)为图像的分布;
GD(i=1, 2, 3)为全局鉴别器中3个不同尺度的鉴别器;
cB为图像B的内容信息;
sA为图像A的风格信息。

式中为各尺度全局鉴别器的权重系数。
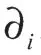
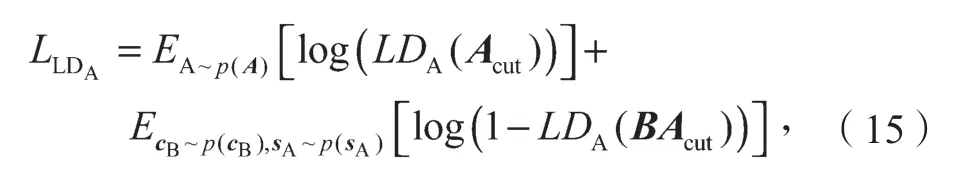
式中Acut为剪裁1/4的图像A后的图像。


式中αCD、βLD分别为全局鉴别器、局部鉴别器的权重。
鉴别器的结构如图4所示。
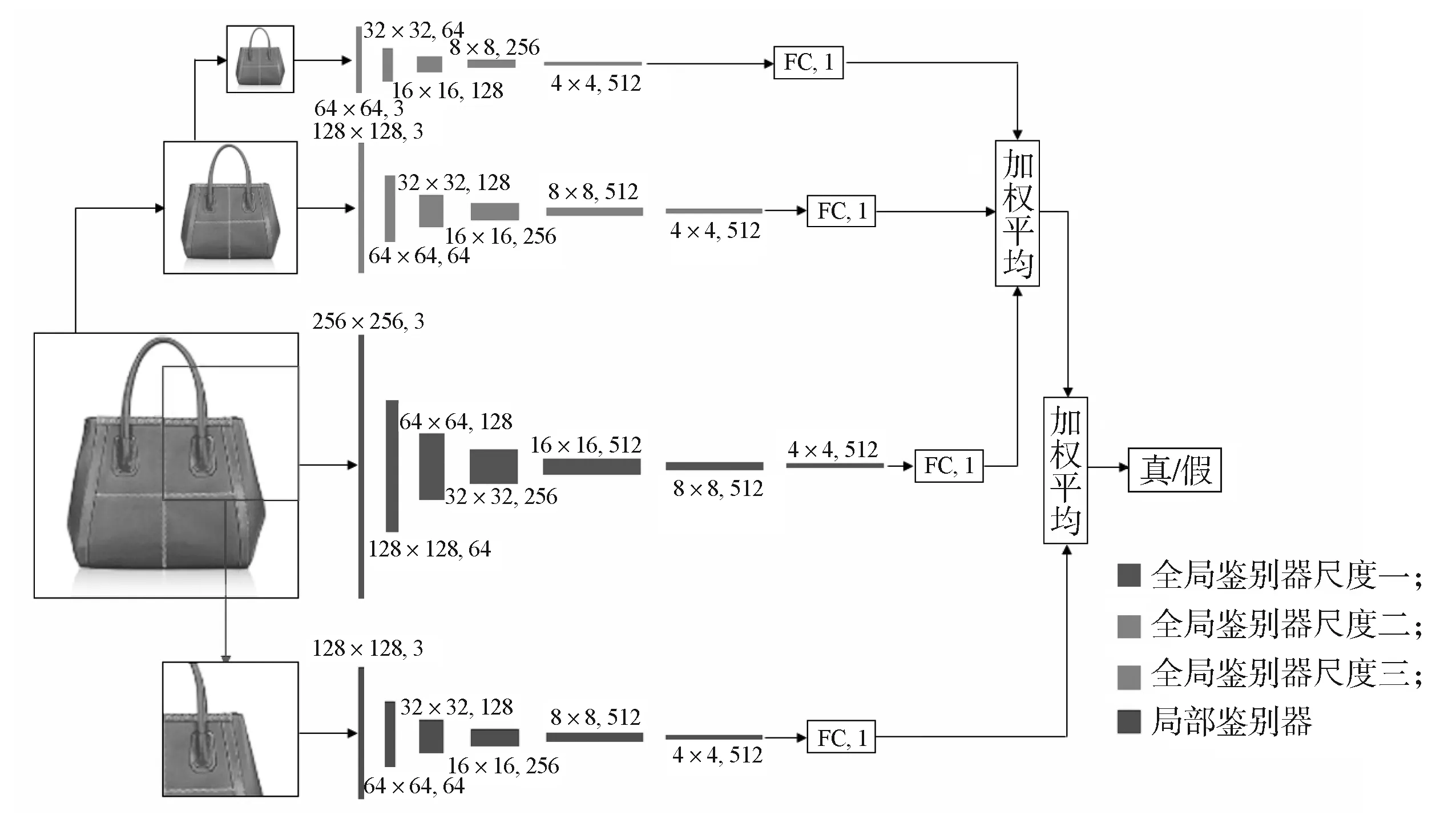
图4 鉴别器的网络结构Fig. 4 Network structure of discriminators

彩图
1.5 目标函数
无监督图像风格转换模型的总体目标函数为
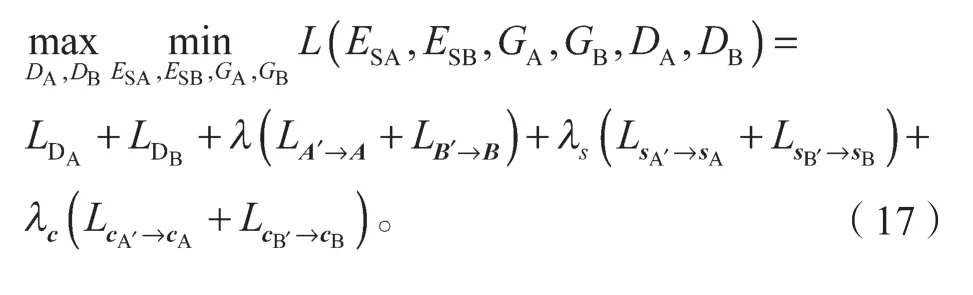
如式(17)所示,目标函数包括4个部分。
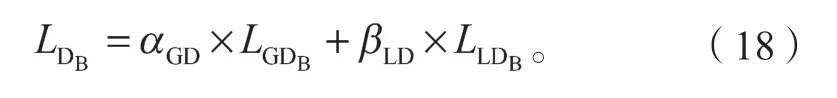
2)源域图像与重构源域图像间的循环一致性损失LB′→B与LA′→A。
在生成器GA中,编码器对输入的边缘图像B进行编码,提取其内容编码cB,即

随后,解码器根据内容编码cB以及图像A的风格编码sA,解码获得新的风格图像BA,即
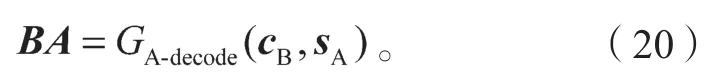
按照循环一致性理论,生成器获得的风格图像BA也能经编码与解码操作得到重构的输入图像B′。B′的重构过程如下:


式(21)~(22)中:cBA为风格图像BA的内容编码;
sB为输入图像B的风格编码。
图像B′与原始输入图像B之间的损失为

同理,图像A与重构图像A′之间的损失为

对重构图像B′进行风格编码,可得风格编码sB′。sB′与sB(呈正态分布)之间损失应当满足如下约束关系:
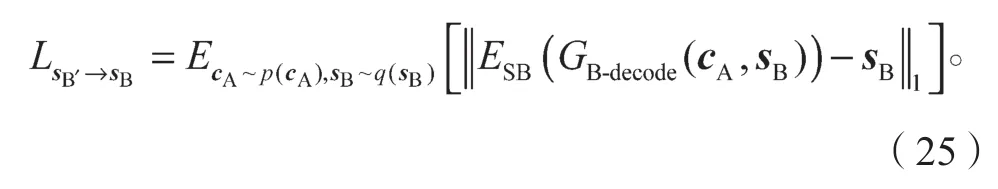
式中q(·)为风格编码sB的分布。
同理,重构图像A′的风格编码sA′与风格编码sA之间的损失函数为
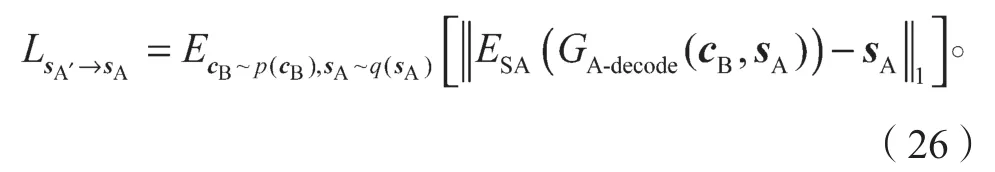
重构图像B′的内容编码cB′与输入图像B的内容编码cB应该是一致的,则cB′与cB之间应当满足如下约束关系:
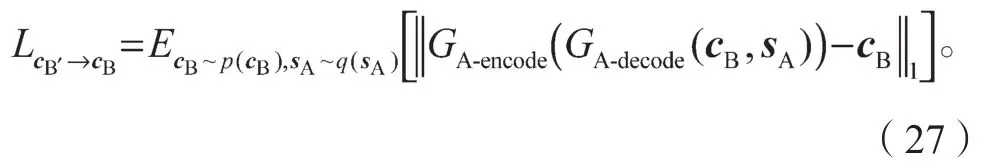
重构图像A′的内容编码cA′与输入图像A的内容编码cA之间的损失函数为

2 实验
本实验是在Linux18.04系统、Pytorch1.0平台完成。训练数据来自iGAN-project的手提包图像集。输入图像和输出图像的大小均为256×256。为了验证本文方法的有效性和优越性,用两组不同的测试数据(数据来自iGAN-project和网络)测试BicycleGAN模型[8]、MUNIT模型[5]、DRIT模型[6]与本模型,利用NIMA(neural image assessment)距离[11]、LPIPS(learned perceptual image patch similarity)距离[16]评价4种模型的输出图像质量,并比较模型的体积和参数量。MUNIT模型、DRIT模型和本模型均为无监督模型,输入数据为边缘图像;BicycleGAN模型为有监督模型,输入数据为一一对应的“边缘+实物”图像对。
2.1 评价指标
1)NIMA距离
引入NIMA模型对4种模型的输出结果进行真实性评价。NIMA模型是由谷歌于2017年提出的模拟人眼对图片美观度进行打分的模型,通过计算归一化的EMD(Earth mover’s distance)距离(见式(29))对任意图像生成评分直方图,即给图像进行1~10的预测评分。预测评分越高,代表图像质量越高,图像更加美观。

式中:CDFp(k)为预测评分的概率累加值,而不是独立的预测获得每一个评分的概率;
当标签中的评分越高,则累计概率越大。相比于人眼打分机制,NIMA模型可以避免人眼主观性较高、观测环境不统一、人眼样本属性不一致等因素带来的偏差。
2)LPIPS距离
参考BicycleGAN、MUNIT,引入LPIPS距离对4种模型的输出结果进行多样性评价。LPIPS距离由图像深度特征间的L2距离加权获得。参考图像x与失真图像x′之间的距离为

⊙为矢量wl对通道进行缩放操作。
2.2 iGAN-project的手提包图像测试实验
从NIMA距离、LPIPS距离以及模型的体积和参数量方面,比较BicycleGAN模型、MUNIT模型、DRIT模型与本模型的优劣。测试数据来自iGAN-project的手提包图像。
训练本模型时,输入图像为手提包边缘图像B,图像B经编码器编码内容信息后与实物图像A的风格信息[17-18]共同解码获得输出图像BA,即不同风格的着色手提包图像。部分实验结果如图5所示。

图5 手提包风格转换结果Fig. 5 Handbags’style conversion results

彩图
与BicycleGAN、MUNIT相似,测试实验选取50张输入图像,每张输入图像随机采样获得10张输出图像,计算500张输出图像的NIMA距离均值。对50张输入图像的每张图像随机采样获得38张输出图像,计算1900张输出图像的LPIPS距离均值。4种模型的实验结果评价如表1所示。

表1 实验结果评价Table 1 Evaluation of experimental results
由表1可知:从输出图像的美观度来说,本文方法的NIMA值最高;从输出结果的多样性来说,本文方法与MUNIT和DRIT模型差不多,与BicycleGAN模型相比,本文方法的多样性提升了约10%;从模型的体积与参数量来说,本文方法的模型体积最小,参数量最少。可见本文方法能够以更小的模型体积、更少的模型参数量获得更加美观且多样性的输出结果。
2.3 纸质手提盒图像测试实验
在包装的外观设计中,从设计草图到设计稿的过程,同样可以看作是一次图像间的风格转换。本实验从网络选取1张纸质手提盒图像,生成测试数据集。按照实验要求,先将图像统一裁剪为256×256,再利用Canny算子提取图像边缘,通过反相操作,获得白色背景的边缘图像(见图6)。4种模型的实验结果如图7所示。
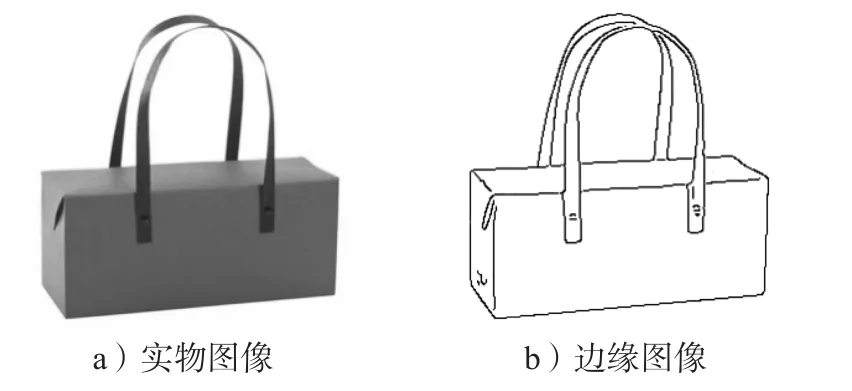
图6 纸质手提盒实物图与边缘图Fig. 6 Physical image and edge image of paper portable box
由图7可知,BicycleGAN模型、MUNIT模型以及DRIT模型的输出图像在局部细节上如提手与纸盒的黏合处,均存在严重的伪影,导致输出图像的局部边缘细节不清晰;BicycleGAN模型和DRIT模型的输出结果还出现了着色不均现象,一定程度上影响了输出图像的美观度;本模型的输出图像相对拥有更为清晰的局部细节,在提手与纸盒的黏合处并未出现肉眼可见的大面积伪影,并且图像着色均匀,美观度更高,整体观感更佳。

图7 纸质手提盒可视化结果对比Fig. 7 Comparison of visualization results of paper portable box

彩图
对图7中的输出结果计算NIMA距离均值,结果如表2所示。

表2 4种模型的NIMA距离Table 2 NIMA distance of 4 models
由表2可知,与BicycleGAN模型、MUNIT模型以及DRIT模型相比,本模型在纸质手提盒的平面设计中表现最优,与图7的可视化效果相吻合。
上述两组实验结果证明了本文所提的无监督图像风格转换模型在包装产品平面设计迁移应用中的有效性。相较于icycleGAN模型、MUNIT模型以及DRIT模型,本模型不仅具有多样性的输出,而且能捕获有效的图像特征,增强图像局部细节。
3 结论
针对多模态无监督图像风格转换模型MUNIT模型的输出图像真实性不高的问题,本文提出了一种基于通道分组注意力残差块的双鉴别器无监督模型。首先,在生成器采用基于通道注意力的深度特征提取残差块CDA,CDA是编码器与解码器的重要组成模块。CDA利用跳跃连接提高生成器部分对于浅层图像信息的提取与利用,并通过ECA实现残差块通道权值的自适应调整,进一步提高网络对有效特征信息的关注度。其次,采用并联的多分辨率尺度全局鉴别器与局部鉴别器,重构相应的损失函数。局部鉴别器使生成图像拥有清晰的局部细节,多分辨率尺度全局鉴别器提高生成图像的全局内容连贯性与结构合理性,以更好地实现网络优化,获得更高质量的输出图像。实验结果表明:本模型不仅拥有更小的模型体积,更少的参数量,且在输出图像的NIMA美观度评价以及LPIPS多样性评价中均取得了更高的得分。此外,在包装类产品的平面设计迁移任务中,本模型也获得了较高的NIMA美观度得分,与BicycleGAN模型、MUNIT模型以及DRIT模型相比,本模型能够获得局部细节更加清晰、完整的输出图像,减少了伪影、特征丢失等问题的产生,进一步证明了本模型在图像特征提取以及利用等方面的优越性,同时证明了将多模态无监督图像风格转换模型应用于包装设计是可行的,多模态的输出能够为设计工作提供更多的设计思路。
在包装类产品的平面设计中,尽管本模型相较于BicycleGAN模型和MUNIT模型,在输出图像质量上有一定的提高,但是输出图像还存有小面积的边界模糊以及轻微的伪影,这将是后续研究需要解决的问题。此外,不同包装类型产品相关数据的获取,以及是否需要添加额外的特定约束条件来获得更加真实有效的输出等,也是后续研究方向。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
成都信息工程大学学报(2022年2期)2022-06-14
中国典型病例大全(2022年7期)2022-04-22
北京大学学报(自然科学版)(2022年1期)2022-02-21
小学生学习指导(中年级)(2021年12期)2021-12-30
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
北京航空航天大学学报(2020年10期)2020-11-14
