
基于内嵌物理机理神经网络的热传导方程的正问题及逆问题求解
2021-11-13 07:19程艳青钱炜祺
空气动力学学报 2021年5期
赵 暾,周 宇,程艳青,钱炜祺,*
(1. 空气动力学国家重点实验室,绵阳 621000;2. 中国空气动力研究与发展中心,绵阳 621000)
0 引言
自从Hinton[1]在2006年提出深度学习的概念之后,最近几年深度学习在科学领域和商业领域已经取得了巨大的成功。一般来说,深度学习需要大量的训练样本,通常应用在大数据领域,而且由于过度依赖训练数据,导致泛化能力差,同时还具有以下缺点:缺乏推理和因果关系的表达能力而导致表征能力弱;无法解释形成决策的推理过程;很难在计算过程中导入选择性注意力机制。
在实际工程领域,受成本限制,所获取到的样本数据量是有限的。因此,很难将深度学习技术直接应用于小样本问题领域。但是这些数据通常都包含由物理定律、经验规则或者领域知识构成的先验信息。如何将深度学习方法有效运用到包含先验信息的小样本数据领域,相关学者做了大量研究。其中,美国布朗大学Karniadakis教授团队做出了较为出色的工作。他们通过将蕴藏在小样本数据中的先验信息编码到深度网络中,提出了一种新的深度学习算法—内嵌物理机理神经网络[2](Physics-informed neural networks,PINNs),该网络可以由神经网络对输入及模型参数进行自动微分所获取。PINNs通常受到数据中包含的物理定律的约束,而这些物理定律一般可以建模成时间相关的非线性偏微分方程。这样就可以利用PINNs发展出一类新的偏微分方程数值求解方法以及一类新的系统辨识和模型反演的数据驱动方法。PINNs方法的核心思想是将上述原问题(即求解偏微分方程的正问题或者逆问题)转换为优化问题求解。与传统的偏微分方程数值求解方法以及系统辨识方法相比,PINNs具有以下几个特点:
1)PINNs可以作为训练辨识一体化的方法,即在求解偏微分方程的同时,根据附加信息直接辨识出方程中的未知参数。
2)与传统的基于网格的偏微分方程数值求解方法相比,PINNs是无网格的,这样可以节省大量的网格绘制与生成时间[3],而且还可以避免求解高维PDEs时会遇到的维度灾难问题。
3)与传统的基于变分原理求解偏微分方程方法相比,PINNs可以求解不满足变分原理的偏微分方程[4]。
4)由于PINNs采用了自动微分,因此可以避免传统数值方法中由差分格式带来的误差影响。而且自动微分是直接对神经网络的输出而不是对数据进行微分,因此,PINNs对包含噪声的输入数据具有较强的鲁棒性。
5)PINNs可以有效地解决不适定的偏微分方程逆问题。
6)由于PINNs中的损失函数是非凸的,会存在多个局部极小值,因此基于梯度下降的优化算法几乎一定会陷入某个极小值,从而导致PINNs的求解结果不唯一。
7)PINNs对于每个新的实例(例如,方程参数变化)就需要重新训练网络。后续,Lu等[5]提出了DeepONet去解决这个问题。该网络可以直接对数据中的非线性算子进行近似,例如,如果数据是从偏微分方程获得,则可以直接学习出积分算子,从而近似出偏微分方程的解。
Jagtap等[6]将PINNs中的激活函数修改为自适应激活函数,大大加速了训练收敛速度。具体做法是在激活函数中引入一个超参数,并将该参数作为神经网络参数进行优化。在PINNs的理论基础层面,Shin等[4]针对椭圆型和抛物线型偏微分方程,证明了PINNs训练得到的网络可以一致收敛到偏微分方程的解。
经过最近两年的发展,PINNs发展出了一大类家族—cPINNs[7]、fPINNs[8]、nPINNs[9]、sPINNs[10-11]、vPINNs[12]以及XPINNs[13]等。前面四种可以分别用来求解离散域非线性守恒律方程、分数阶偏微分方程、非局部椭圆型偏微分方程、随机偏微分方程,vPINNs则是以Petrov-Galerkin方法为基础求解偏微分方程,而XPINNs可以求解任意复杂几何域上的非线性偏微分方程。
Lu等[14]基于Tensorflow开发出了一个Python工具包—DeepXDE,该工具包对上述算法进行了整合,并且还可以用来进行多保真度数据建模,以及从数据中直接学习非线性算子和函数关系。更进一步地,PINNs由于其原理简单,灵活度高,效果良好,已被英伟达、ANSYS、西门子等公司采用。英伟达已经开发出了SimNet[15]工具包,用来求解偏微分方程的正问题、逆问题以及数据融合问题。
虽然PINNs方法目前发展迅速,但是对求解正问题时的精度以及求解逆问题时的鲁棒性还需要进一步分析。本文则针对一维热传导方程对上述问题进行了研究。
1 PINNs的基本结构
下面以求解非线性偏微分方程的正问题和逆问题为例,阐释PINNs的基本网络结构及其训练方式。
非线性偏微分方程的一般形式可以表示为:
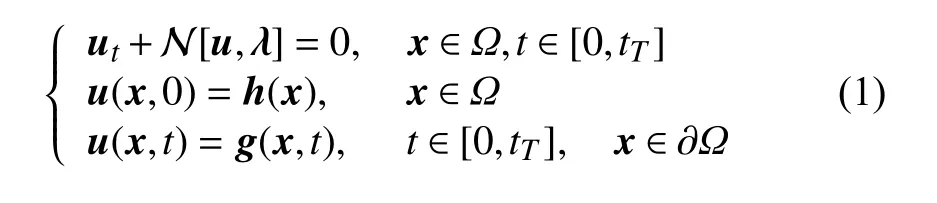
其中,u是上述偏微分方程的解, N[u,λ]为带有参数λ的非线性算子, Ω 是RD的 子集,tT为终端时刻,h(x)为方程的初始条件,g(x,t)为方程的边界条件。
首先,建立一个深度网络n(x,t;θ)去近似u,并定义偏微分方程的残差为PINN的输出:
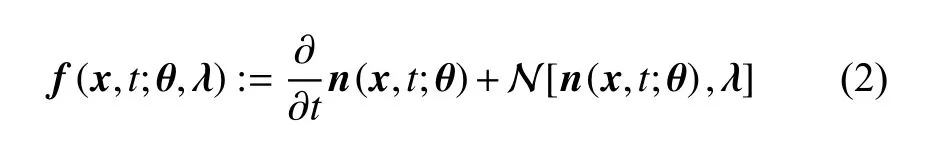
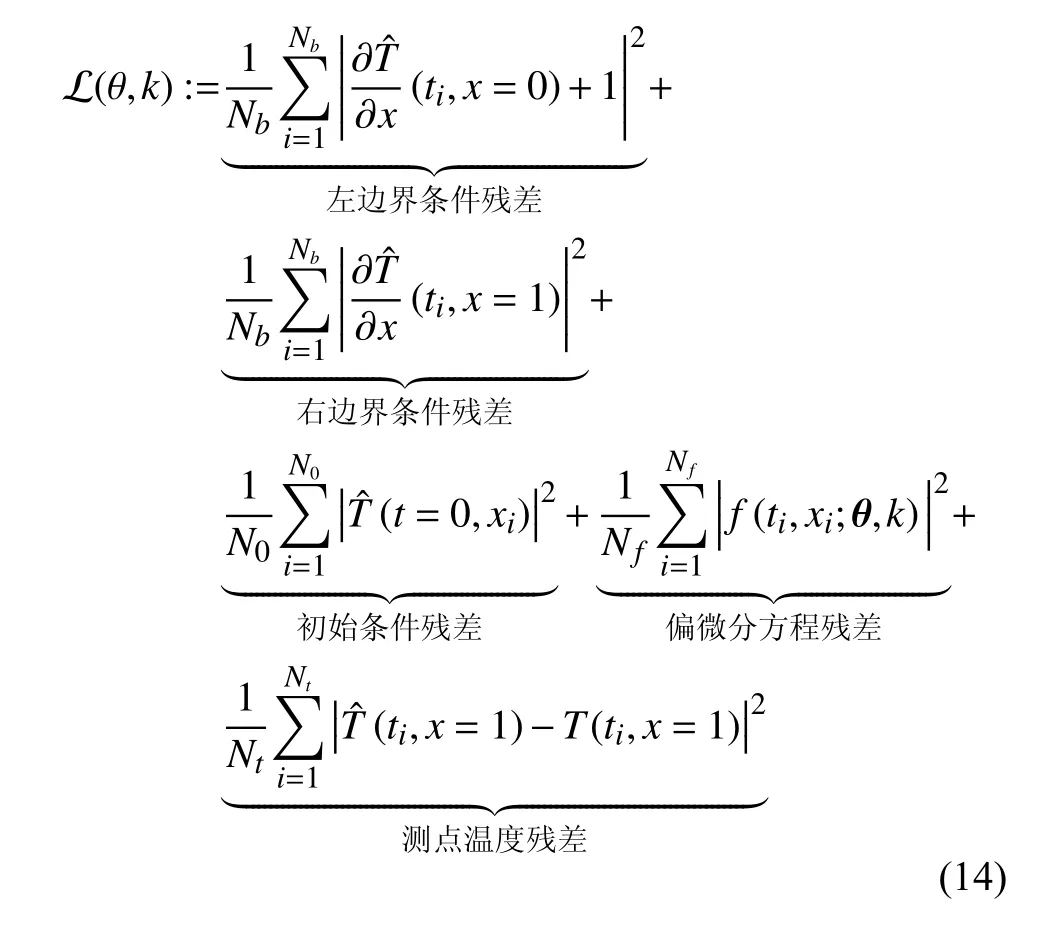
上式中的偏导数都可以通过自动微分得到。相应地,损失函数可以给定为:

损失函数的训练集分为三部分,第一部分为初始条件和边界条件的采样点集,第二部分为对偏微分方程残差进行采样的配置点集。配置点集一般有两种选取方式,第一种为类网格点选取方式,第二种为伪随机离散取点方式,如图1所示。当针对高维非常规区域上偏微分求解问题,伪随机离散取点方式具有更强的灵活性。第三部分为已知的数据样本集,该部分标签数据用来对方程中的参数进行辨识。
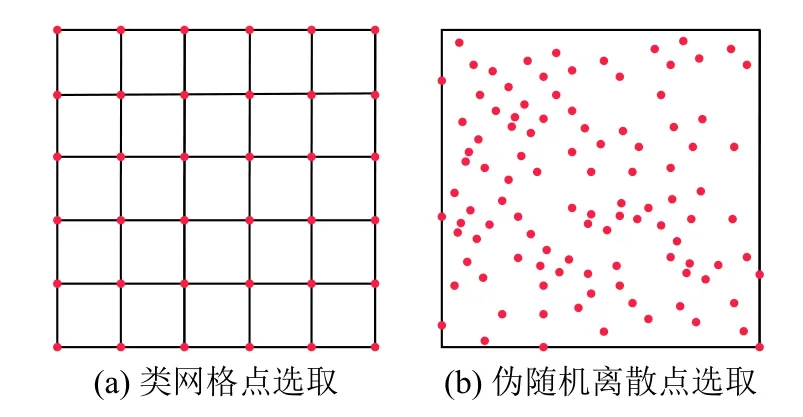
图1 配置点离散方式Fig. 1 The distribution of collocation points
从损失函数式(3)的组成可以看出,偏微分残差项起到了正则化作用,这样可以增强网络n(x,t;θ)的泛化能力。而从另一个角度看,通过自动微分构建偏微分方程残差并将其引入到损失函数的过程,可以看作是将该偏微分方程表示的物理规律嵌入到深度网络的过程。
最后,基于该损失函数,通过梯度下降方法对深度网络参数θ和方程参数λ进行训练。
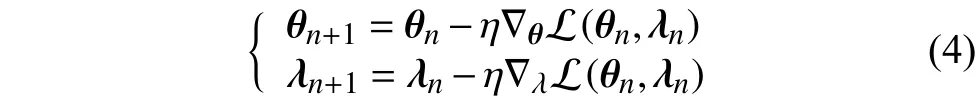
最终,通过训练就可以求得使损失函数(3)最小的 参 数 θ∗和 λ∗,而 方 程(1)的解可以用神经网络=n(x,t;θ∗)来表示。PINNs的网络结构及训练过程可以用图2表示。
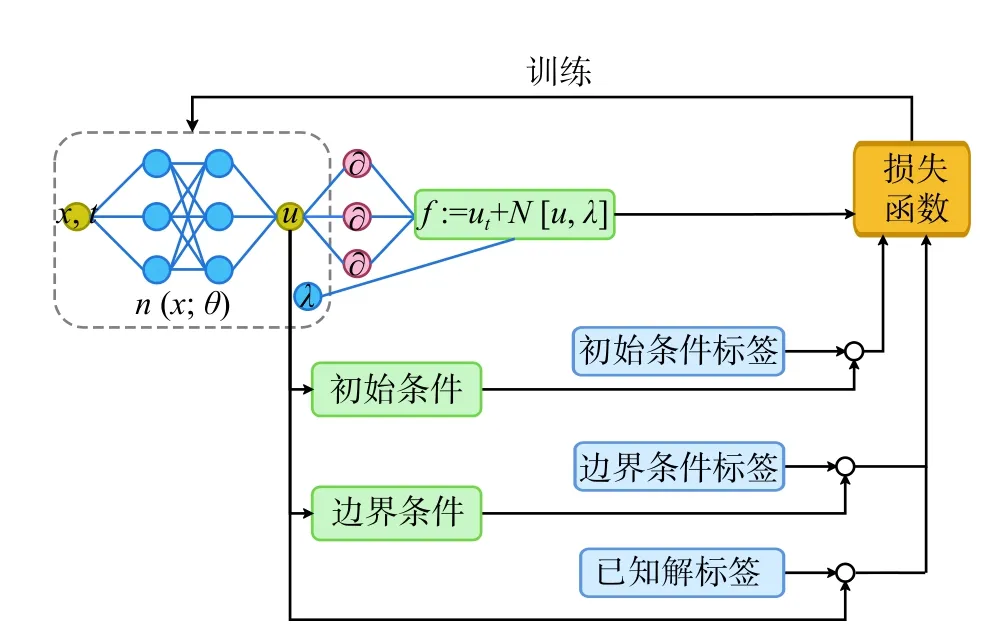
图2 PINNs基本原理图Fig. 2 A sketch of PINNs
2 PINNs方法的应用
2.1 一维热传导方程求解及其精度分析
在物体边界给定为第二类边界条件后,可得到如下的一维热传导控制方程[16]:
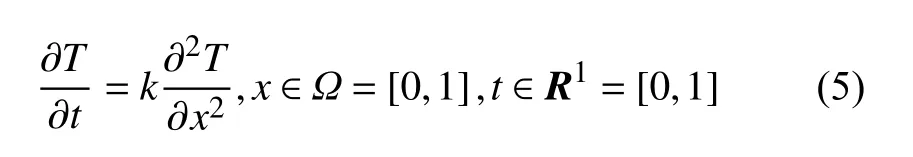
边界条件:
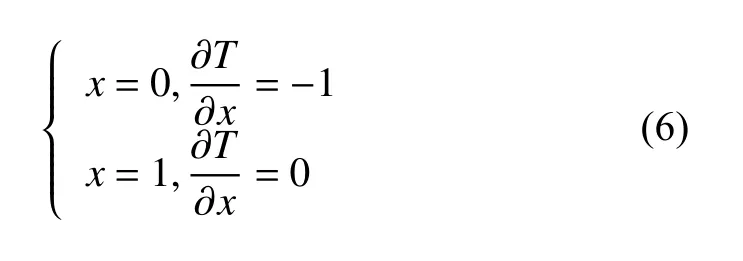
初始条件:
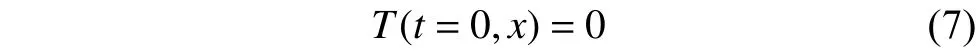
本节的目的是在已知边界条件和初始条件的情况下,利用PINN求解导热系数k= 1时方程(5)的解。
首先设计一个深度网络n(x,t;θ)去近似方程(5)的解,即:
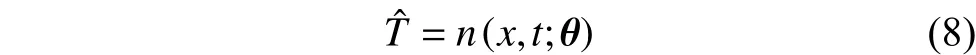
该网络包含2个输入,1个输出,3个隐层且每个隐层包含40个节点,隐层节点的激活函数设置为sigmoid。随后对n(x,t;θ)的输出进行自动微分,定义PINN为:

接着,选择如下均方误差的和作为损失函数:
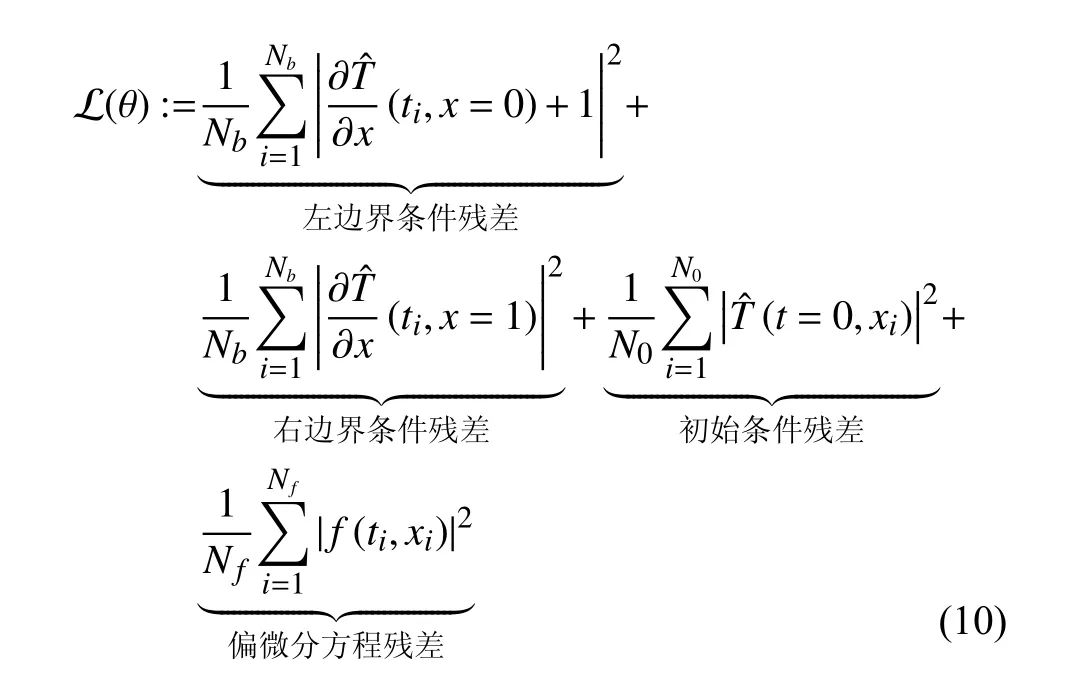
其中,Nb和N0分别为边界点和初始点训练集大小,Nf为方程配置点训练集大小。在本文中,首先给定Nb和N0分 别为80和100,以及在时间空间域 Ω×R1内采用类网格点方式选择Nf= 8000个配置点。接着,采用Adam优化器并设置学习率为0.001对所建的网络n(x,t;θ)进 行训练。即在训练过程中,通过给定边界条件数据集、初始条件数据集{ti,xi;Ti}以及方程残差点集 {ti,xi;fi},通过优化寻找最接近观测数据集以及偏微分方程残差的参数 θ∗所确定的深度网络。最后,利用训练完的网络预测区域(x,t)∈[0,1]×(0,1]内的温度值。
还需要特别注意的是,由于PINN会从不同的网络初值收敛到不同的解,因此,在本文中,随机初始化20次训练PINN,损失函数随迭代步数变化情况如图3所示。

图3 20次不同初始权重网络的损失函数随迭代步数变化Fig. 3 Loss functions with 20 different initial weights versus the iteration step
从图3可以看出,从不同的初始权重出发,网络经过大约10000次左右的迭代训练后,损失函数都可以收敛。
然后利用训练完的网络分别预测温度场,最后将平均值作为最终结果,并将其与温度场的解析解进行对比,如图4所示。与解析解相比,利用PINN预测整体温度场的均方误差约为2.2865× 10−7。

图4 基于PINN的一维热传导方程求解结果与解析解对比Fig. 4 Comparison of the solution obtained by PINN and the analytical solution of the one-dimensional heat conduction equation
通过对PINN方法分析可知,其求解误差主要包括有限训练点集导致的采样误差、神经网络的逼近误差以及陷入局部最优解导致的优化误差等三部分组成。下面在神经网络结构固定的情况下,即逼近误差一定,分别从空间和时间两个尺度分析采样误差以及优化误差对精度的影响,并且与控制体积方法的求解结果进行对比分析。为分析空间尺度影响,采用以下配置点选取方式:固定100个时间点,分别选取20、40、80、160、320、640和1280个空间点;而为分析时间尺度影响,则采用以下配置点选取方式:固定80个空间点,分别选取25、50、100、200、400、800和1600个时间点,具体如表1和表2所示。
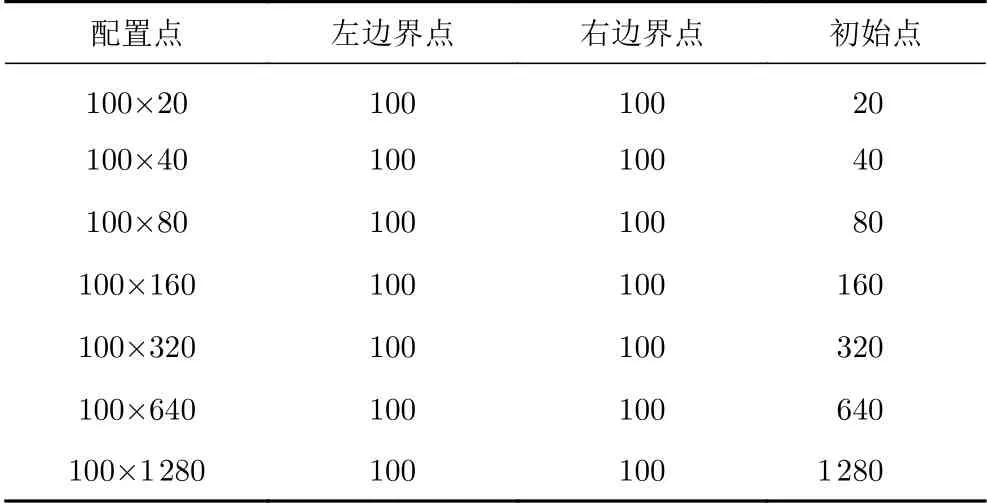
表1 分析空间尺度离散影响的采样点选取方式Table 1 The selection method of sampling points to analyze the influence of spatial discretization

表2 分析时间尺度离散影响的采样点选取方式Table 2 The selection method of sampling points to analyze the influence of temporal discretization
本文训练环境为英伟达RTX2060显卡,显存6 GB,运行频率1800 MHz。在该环境中随机初始化20次训练网络,训练时间随采样点数的变化如图5所示。可以看出,随着采样点数的增加,训练时间呈线性增长的趋势。
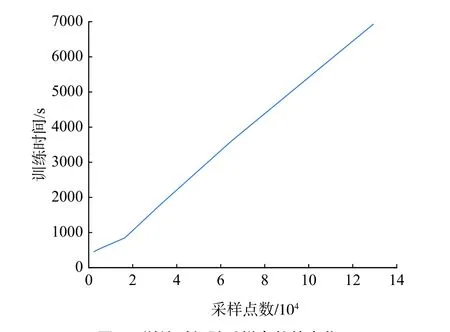
图5 训练时间随采样点数的变化Fig. 5 The training time as a function of the sampling number
利 用 训 练 完 的 网 络 计 算 其 在x= 0 m、0.1 m、0.25 m、0.6 m及1 m处的平均预测值及其对应的均方误差,并与控制体积的求解结果相对比,如图6所示,图中的黑色虚线表示的是O(N−2)收敛速率,其中N为采样点数。

图6 PINN方法与控制体积方法求解精度比较Fig. 6 CA comparison of the solution accuracy of between the PINN and the control volume method
通过对图6的分析,可以得出以下几个结论:
1)当采样点数较少时,时间和空间尺度采样点数对PINN方法的求解精度影响与控制体积方法类似,即在空间采样点固定情况下,求解误差按照O(N−2)速率收敛,而且时间尺度的采样误差相较空间尺度占主要地位。
这是由于在损失函数(10)中,时间尺度采样点对应的有左边界残差和右边界残差两项,而空间尺度采样点只对应一项初始条件残差。
2)PINN方法在采样点数较少时,采样误差为主要误差来源,随着采样点数增加,其求解精度随之提高,但是当总采样点数约大于8000时,两种配置点采样方式的求解精度几乎收敛到同一水平。
这是由于过多的采样点数会导致过于复杂的损失函数,从而使优化误差增大,这让优化误差成为主要误差来源。
下面,固定8000个配置点,分别分析初始和边界条件的采样点对求解精度的影响。左右边界分别选取100个采样点,初始条件分别选取20、40、80、160、320、640和1280个采样点;初始条件选取80采样点,左右边界分别选取25、50、100、200、400、800、1600个采样点时,方程(5)求解精度如图7所示。
从图7可以得出与图6一致的结论,即采样点数少时,采样误差主导了收敛误差,当采样点数增加到一定程度后,优化误差成为了收敛误差的主要组成部分。

图7 配置点固定时PINN方法求解精度分析Fig. 7 The solution accuracy of the PINN with fixed collocation points
2.2 一维热传导方程参数辨识及其鲁棒性分析
本节针对热传导方程(5),在已知初始条件、混合边界条件:

以及Nt个测点温度的情况下,对方程中的导热系数k进行辨识,其中,T0为基于2.1节方程的解析解。通过对上节方法稍加改动,就可以对参数k进行辨识。具体实现步骤如下:
首先,在构建PINN时,将参数k作为待优化变量,即PINN的输出为:
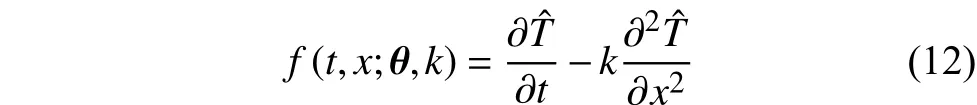
接着,将Nt个测点温度作为标签数据,定义如下损失函数:
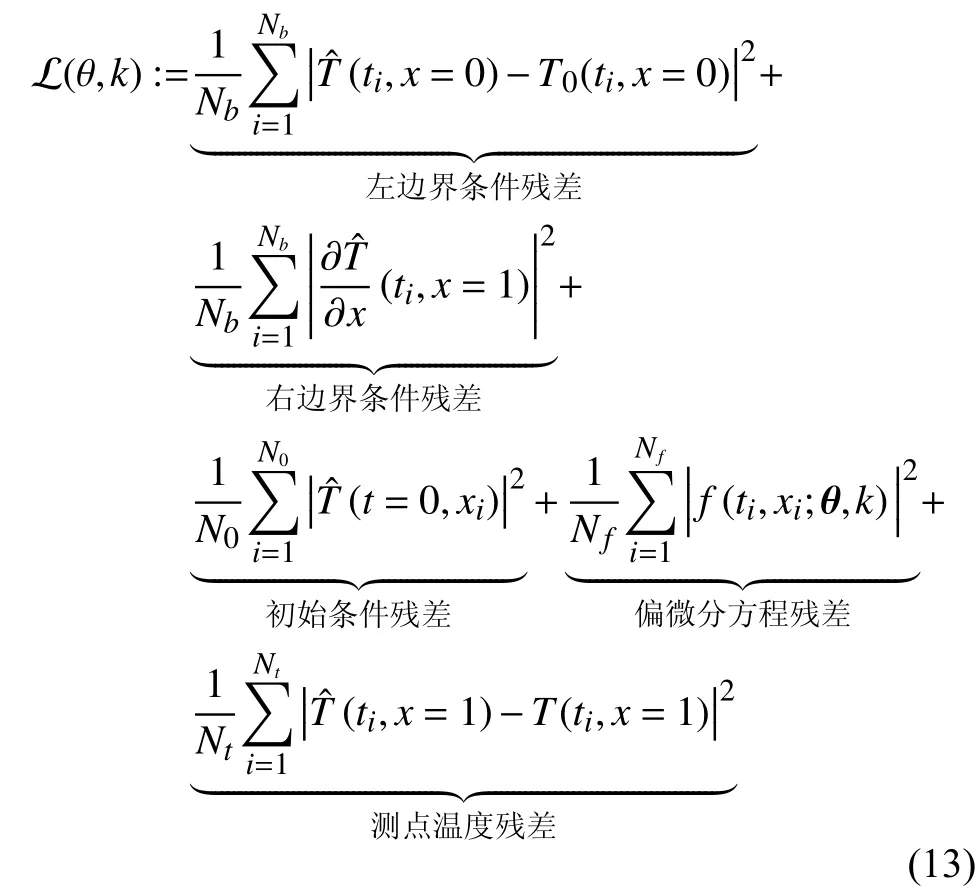
最后,通过Adam算法对所构建的网络进行优化,得到使损失函数最小的k∗。
本文选取网络结构如下:2个输入及1个输出,6个隐层且每个隐层包含20个节点,隐层节点的激活函数设置为tanh。在固定网络初始参数的情况下,同时给定无噪声、10%噪声以及50%噪声测点数据,经过10次蒙特卡洛仿真,PINN训练过程中的损失函数变化如图8所示。可以看出,随着数据中噪声的增大,损失函数的收敛值也变大。

图8 给定不同噪声数据时损失函数随迭代步数变化Fig. 8 Loss functions versus the iteration step for training data with different noisy levels
随后,将PINN方法与共轭梯度法(CGM)的辨识结果进行对比,如表3所示。从表3可以看出,基于PINN的辨识结果与CGM结果精度相当。对于50%的噪声数据,基于PINN的辨识结果有1.253%的相对误差,这说明利用PINN的参数辨识方法对噪声数据具有较强的鲁棒性。这是因为,第一,损失函数中包含初始、边界条件以及偏微分方程残差构成的正则化项,可以防止网络对噪声过拟合;第二,由于采用了自动微分,一方面在计算温度的偏导数时,不会引入标签温度的噪声,另一方面,也可以避免传统数值方法中低精度差分格式对辨识结果的影响[17]。在计算过程中注意到,网络的初始权重对结果影响较大,当选取不恰当时,会导致训练发散。
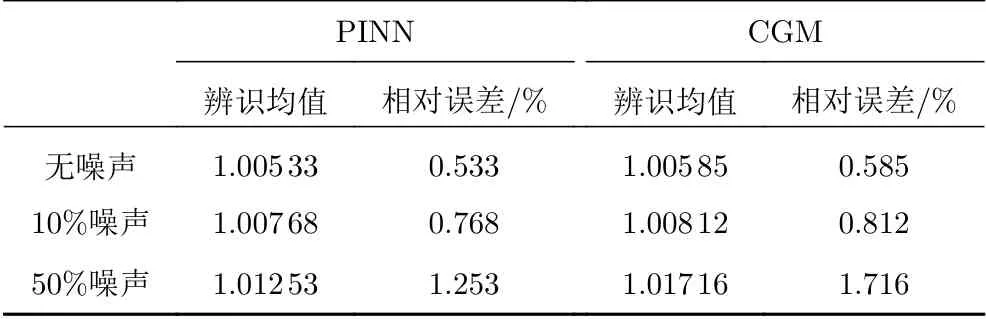
表3 导热系数k辨识结果Table 3 Identification results of the thermal conductivity k
下面研究小导热系数以及边界条件对基于PINN的辨识方法的影响。
已知导热系数k= 0.01时x= 0.1 m处的温度场测点数据,以及边界条件(11),利用PINN方法的导热系数辨识结果如表4所示。从表4可以看出,在给定较小导热系数的测点数据时,基于PINN方法可以对参数k进行高精度的辨识。
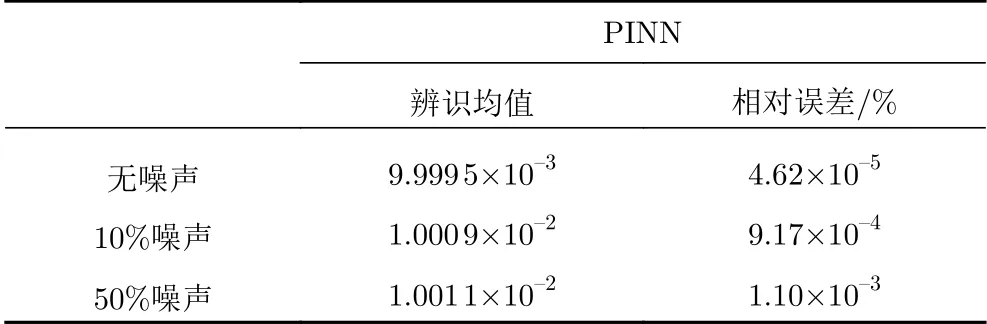
表4 导热系数k辨识结果Table 4 Identification results of the thermal conductivity k
当给定第二类边界条件(6)时,将导热系数k= 1时x= 1 m处的Nt个温度场测点数据作为样本值,定义如下损失函数:
基于PINN方法的导热系数辨识结果如表5所示。从表5可以看出,当热传导方程采用第二类边界条件时,基于PINN方法的导热系数的辨识精度与采用混合边界条件热传导方程的辨识精度相当。
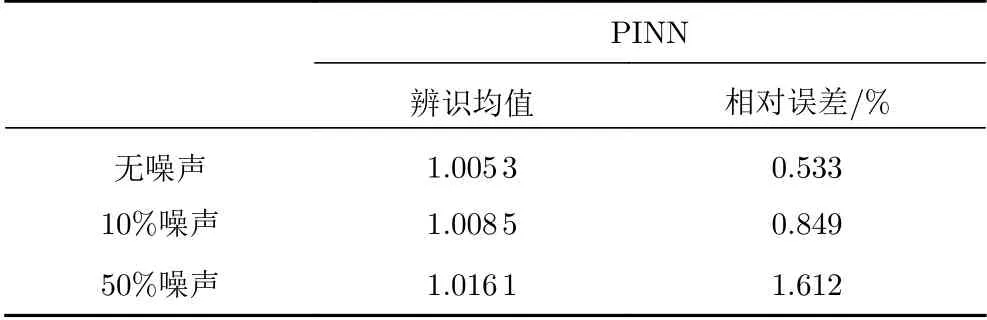
表5 导热系数k辨识结果Table 5 Identification results of the thermal conductivity k
3 结论
针对一维热传导方程的正问题和逆问题,本文介绍了一种内嵌物理机理神经网络的求解方法。该方法将神经网络作为解的近似,并在给定数据和偏微分方程的约束下,对网络进行训练。通过将偏微分方程作为正则化部分加入到损失函数中,使得上述深度网络具有较强的泛化性能以及一定程度上的可解释性。
通过分析热传导方程求解的收敛误差得到,采样点较少时,采样误差是收敛误差的主要组成部分,而当采样点较多时,主导误差变为优化误差。再通过对方程中的未知参数辨识的鲁棒性进行分析得知,由于损失函数中包含了初始条件、边界条件以及方程残差构成的正则项,因此,可以防止网络对噪声出现过拟合,从而增强辨识方法的鲁棒性。但是,基于PINN的导热系数辨识方法在给定不恰当的超参数时,可能会导致训练发散。
猜你喜欢
今日农业(2022年15期)2022-09-20
农业工程学报(2022年12期)2022-09-09
农业工程学报(2022年5期)2022-06-22
现代仪器与医疗(2021年1期)2021-06-09
小天使·二年级语数英综合(2019年10期)2019-11-08
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
读者·校园版(2015年19期)2015-05-14
