
改进YOLOv3-SPP的无人机目标检测模型压缩方案
2021-11-12 15:09黄文斌陈仁文袁婷婷
计算机工程与应用 2021年21期
黄文斌,陈仁文,袁婷婷
南京航空航天大学 机械结构力学及控制国家重点实验室,南京210016
随着深度学习的发展,计算机视觉被广泛引用于无人机等嵌入式移动设备上。无人机应用范围广泛,在航拍、侦查、搜救等场景中发挥巨大作用。在执行这些任务中,核心的任务之一就是目标检测,识别通过机载航拍摄像头捕捉到图像中的目标,对目标分类和定位。
利用无人机进行目标检测和其他目标检测任务相比,面临着许多挑战:(1)航拍影像不稳定性,高度和角度变化大,目标尺寸变化大和照明条件变化大。(2)机载计算设备算力低下。(3)精度和和速度难以权衡。
目前,基于卷积神经网络的目标检测算法大致分为两类:一是双步目标检测(two stage),首先通过网络产生候选区域,再放进卷积模型进行分类。如2014年Girshick提出区域的卷积神经网络[1](RCNN)、后来又相继提出Fast R-CNN[2]、Faster R-CNN[3]、R-FCN[4]、Mask R-CNN[5]等。二是基于回归思想的单步(one stage)目标检测,如2016年Redmon等人提出YOLO网络[6],其基本过程为首先将图片划为S×S的网格,然后每个网格负责检测落在该网格中心的目标且预测两个边界框(bounding box)和类别信息,最后在输出层直接输出边界框和类别信息,该算法在Pascal VOC2012数据集上mAP达到63.4%,每秒检测45帧图片,此外针对YOLO网络目标检测准确度低的问题研究人员相继提出SSD[7]、YOLOv2[8]、YOLOv3[9]、YOLOv4[10]、YOLOv5[11]
等。单步目标检测算法特别是YOLO系列检测算法速度明显远远快于双步目标检测算法,精度稍低于双步,但仍在可接受范围内[12],受到大多数工程应用青睐。
尽管如此,作为深度卷积网络模型,YOLO网络仍然过于复杂,对于无人机硬件造成一定压力。为了精简模型,获得更加轻量化,运算量小,速度更快的模型,模型压缩的概念被提出来。主要有以下几种压缩方向:网络剪枝[13]、参数量化[14]、设计轻量化网络等。模型剪枝是其中较为成熟的方法,剪枝可以在保证模型性能情况下去除掉网络中冗余的参数量和权重,降低网络的复杂度,提高泛化能力[15]。
目前剪枝比例最大的方法是Li[16]提出的卷积核剪枝,主要思想是对网络输出精度影响较小的卷积核进行枝,通过移除网络中那些卷积核以及其所连接的征图,使网络计算量大幅度降低。2017年,Liu提出通过在BN层添加稀疏因子训练的方法进行通道剪枝,将模型的大小压缩了20倍,在多个网络上取得了不错的效果[17]。2019年,北理工的Zhang利用在核剪枝和BN稀疏训练,再微调,不断迭代剪枝的方式,在VisDrone2018无人机数据集上进行了测试,浮点运算次数下降了90.8%,参数量下降了92.0%,与检测精度相当的YOLOv3相比,但是速度仅仅快了两倍[18]甚至低于Tiny-YOLOv3。这种方式虽然能够有效减小模型大小,但是受制于木桶效应,对速度的提升不大。
本文将在YOLOv3-SPP网络基础上进行优化,主要创新点如下:
(1)优化损失函数,将焦点损失(GIoU)代替平方和作为定位误差,提升目标定位精度。
(2)新的数据增强方式。对数据集特定类别降采样处理,一定程度上解决类别不均衡问题。引入随机拼接(RICAP)场景组合的训练方式同时提升精度和训练效率。
(3)在迭代剪枝基础上,加入层剪枝,对模型的残差层进行修剪,减小前向推理层数,进一步缩小模型并提升推理速度。最终剪枝厚的模型参数量下降97%,速度提升近3倍,精度和速度均超过最新的YOLOv5轻量模型。
1 改进YOLOv3-SPP网络
YOLOv3是YOLO系列第三代网络,相比前两代有了很多改进。主要在于,以Darknet-53作为基础网络,去掉了全连接层,大量使用残差(Residual Network)跳层连接,每一个最小的卷积层,由卷积操作、批标准化(Batch Normalization)和Leaky-Relu激活函数组成。使用卷积下采样操作代替池化层使之成为了一个全卷积网络。最终在3个尺寸(13×13、26×26、52×52)上输出目标物体的预测。
YOLOv3-SPP网络在YOLOv3的基础上在第五、六层卷积之间增加了一个SPP模块[19],如图1。这个模块主要是由两个不同的池化操作组成,借鉴了空间金字塔的思想,提取局部特征和全局特征,可以提升模型的感受野,有利于待检测数据集中目标大小差异较大的情况,实验中对检测的精度上有了很大的提升。

图1 YOLOv3-SPP网络Fig.1 YOLOv3-SPP network
原始的YOLOv3中利用平方损失MSE作为损失函数来进行目标框坐标位置的回归。直接计算回归框和原始框的坐标差,但是不同质量的预测结果,利用MSE评价指标有时候并不能区分开来。本文采取广义交并比(GIoU)[20]作为回归框定位损失。除了和IOU类似的尺度不变性,在回归框和真实框没有良好对齐时,会导致最小封闭凸面面积增大,从而使GIoU的值变小,而两个矩形框不重合时,依然可以计算GIoU,一定程度客观的衡量了两个框的位置关系。
2 数据增强方案
数据增强(Data Augumentation)是常用的提高网络训练效果的方法,可以扩充样本、防止过拟合。常见的增强方式有对图片进行翻转、旋转、缩放、均衡化等。近年比较新的增强方式还有如随机擦除(Ramdom Erasing)[21]和Cutout[22]。
本文采用VisDrone2019数据集,VisDrone2019数据集由天津大学机器学习和数据挖掘实验室的AISKYEYE团队收集。由各种安装在无人机上的摄像头捕获,涵盖了广泛的方面,包括位置、环境、物体和密度等。VisDrone2019相 比2018多了1 580张test-chanllenge标注图片[17],本文只采取训练集(6 471)和验证集(548)进行所有的训练和验证。
图2 (a)展示了数据集中10个不同类别目标总数统计情况,可以看出类别数量及其不均衡,其中行人(类别0)和轿车(类别3)数量远远超过其他类别,三轮车(类别6,7)和公交车(类别8)数量非常小。和道路上出现的真实目标出现比例相符合,这也是航拍数据集较普遍问题。类别不均衡容易导致不同类别精度差异,训练后的模型预测结果更加偏向于数量较多的类别。
图2 (b)对数据集中目标框大小的分布情况进行了可视化,图2(c)是目标出现位置分布可视化图。从两图可以看出,目标框大小不均,小目标数量大,目标出现位置集中与图片的中间。
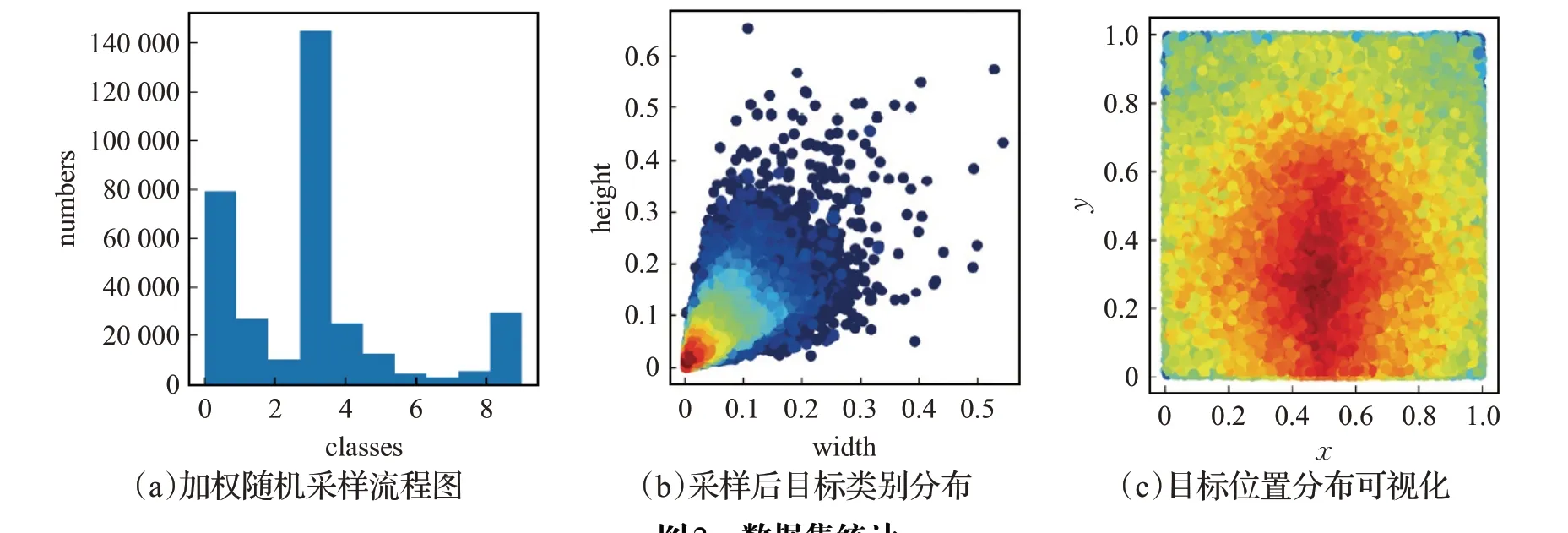
图2 数据集统计Fig.2 Original datasets visulaization
数据集类别不均衡和大量密集小目标使VisDrone成为了难度很大的数据集。
2.1 类别均衡化处理
针对航拍数据集的缺陷,采用加权随机采样(Weighted Random Sampling)[23]。总流程如图3(a)所示。按照对类别样本数的影响不同可分为过采样[24]和欠采样[25]两大类。过采样通过增加少数类样本使其与多数类样本数相同以实现各类别分布均匀。与过采样相反,欠采样是通过减少多数类样本来达到类别间的相对均衡。加权随机采样根据样本权重采样,可同时对特定类别进行过采样和欠采样。

图3 数据增强流程图Fig.3 Flow of data enhancement
首先进行数据扩增和清洗。数据集中最大为1 1 920×1 080分辨率图片,每张图以步长为200分辨率,滑动窗口大小为640×640分辨率大小剪裁成多张小图。一张1 920×1 080大图最多可以剪裁成12张小图。并删除掉其中不包含目标的图片。最终训练集由6 471扩增到56 710个。
再对每个数据进行加权。为了提高少数类样本比例,根据图2(a)统计结果,10个类别中对于少数类别2,6,7,8,9的目标较大权重0.15,多数目标0,3较小权重0.05。按照标签计算每个样本数据权重:

其中,Ki为类别权重,Ni为对应类别目标框数目,w为该样本总的权重。
按照加权随机采样算法[26],步骤如下:
(1)对于集合V中的元素vi∈V,选取均匀分布的随机数ui=rand(0,1),计算元素特征
(2)将集合按ki排序,选取前m大的元素。
本例中,集合V为数据集,vi为样本,wi为式(1)得出的样本权重,ki就是采样的分数。
由于裁切步长不大,避免遗漏图片信息,加权随机采样后数据集类别数目分布如图3(b)所示。相比原始数据(图2(a)),目标类别比例得到一定平衡。
2.2 随机场景组合增强
随机图像裁剪和修补(RICAP[26])方法对于图片分类任务有着不错的效果,将四幅用于分类的图片拼成一张,对于用Softmax激活函数分类的CNN网络起到了标签平滑(Label Smoothing)的效果,RICAP在CIFAR-10上实现了2.19%的测试提升。
本文借鉴RICAP[26]方法,将RICAP用于目标检测。将不同场景图片组合在一起,提升模型鲁棒性和精度。主要包含如下步骤:
(1)随机生成切分四张图片的中心点坐标(xc,yc)将图片分成左上、右上、左下、右下角大小不同四个部分。
(2)从训练集中随机选取四张图片,进行随机翻转、旋转、缩放等基本的数据增强。
(3)将四张图片放置于四个角上。对于图片大于分割部分情况:对图片进行裁切,使之布满整个角。对于图片小于分割部分:对多余部分进行零填充。
(4)批训练时,随机拼接的图片按照批(Batch)大小成批训练,如图4。每一个批都将由随机拼接的图片组成。每张训练图片样本包含密集的不同场景的目标,样本随机性和场景多样性得以提高。批标准化时,每层可以计算来自4×BatchSize张图片的激活统计,效率提升四倍,这让BatchSize的设置可以大大降低,节省显存。相比不用组合增强方式训练,效率大大提升,收敛速度加快,精度提升。

图4 随机场景组合示意Fig.4 Ramdom scene combination
3 模型的剪枝压缩策略
YOLOv3以Darknet53作为基础网络,相比前两代参数量大大增加,一般训练完权重接近250 Mb。其中大量的计算主要来自卷积运算,卷积运算的目的在于提取到更多的特征,网络层次越深能够挖掘的特征也就越多。而对于目标类别需求较少的任务,或者小样本的数据集,卷积运算存在大量“冗余”。由此产生了一个很大的模型压缩方向——稀疏化网络,在不同结构层次上稀疏化。权重剪枝的主要原理是剪掉链接中不重要的小的权重,一般用于全连接层,然而这种方式一般需要专门的稀疏矩阵运算库和硬件做加速,对于内存节省也非常有限。而通道剪枝直接剪掉不重要的卷积核和相应的特征图,不需要额外的硬件加速就能起到良好的运存节省和加速效果。因此,本文采取通道剪枝中压缩效果最好的——基于BN层的通道剪枝策略[27]。
总的压缩方案如图5所示。首先进行初始预训练收敛到较高的精度。再通过BN层γ做比例因子进行稀疏训练,模型通过学习衡量每个通道的重要程度。随后按照设定剪枝比例剪掉不重要的通道,即卷积核和相应的特征图,模型宽度收窄。本文初始设定70%剪枝比例,迭代后最终达到97%剪枝比例。在通道剪枝基础上,每个残差层比例因子之和排序,衡量残差层的重要程度,并剪掉一定数目残差层。模型前向推理层数减小,最后微调恢复精度。整个流程可以进行循环迭代。每一轮迭代中残差层的修剪是可选项,在图中用虚线表示。

图5 模型压缩方案Fig.5 Flow of model compression
3.1 稀疏训练
稀疏训练是剪枝最重要的一步。它的主要思想是在卷积网络中下一个卷积之前给每一个通道乘一个权值γ,并加入损失函数联合训练,在训练过程中,通过梯度下降网络自动学习调整这些权值,不重要的通道权值将会趋近于0。剪枝时,权值按照大小排序,根据设定的比例将小权值对应的卷积核和特征图都剪掉,如图6所示。

图6 BN层通道剪枝示意图Fig.6 Diagram of channel sparse
基于BN层的稀疏方法最为常用,批标准化(Batch Normalization,BN)是广泛应用于神经网络训练的优化方法,可以提高训练效率和模型的泛化能力。原理如
第n层卷积层特征图 BN层稀疏因子 第n+1层卷积层特征图式(1),μΒ和σΒ分别是每个批的均值和方差,γ和β是归一化平移和缩放的参数。利用γ作为缩放因子不引入额外参数,并且YOLOv3-SPP每个卷积层都有BN层,利用BN层的参数γ作为稀疏训练的缩放因子[23]可以起到稀疏效果,并且不会带来额外的花销。
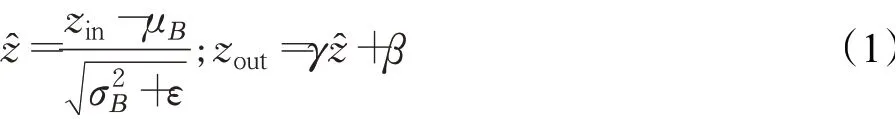
将γ添加到损失函数进行优化。其中(x,y)是训练输入和目标,W是网络中可训练参数,第一项是原始损失函数,g(γ)是在缩放因子上的惩罚项,γ是两项的平衡因子,选择L1正则化方法:g(γ)=|γ|
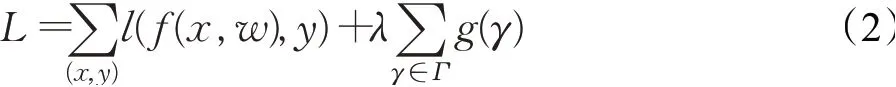
稀疏训练过程,损失函数中稀疏比例因子λ的大小影响稀疏速度,因子越大,稀疏速度迅速,BN层比例因子迅速收缩接近0。但是可能带来损失函数大小升高,精度下降迅速和过拟合。本文取λ=0.005进行稀疏训练,如图7展示了稀疏训练过程各指标变化曲线,由此可见稀疏速度可观,精度在训练之后得到较大恢复。
图8 、图9展示了稀疏前后BN层γ值分布变化。稀疏训练前,BN层γ值分布大致呈现正态分布,均值在1附近。稀疏后每一层γ值大幅减小到0.1以下,许多层γ的收缩到接近0。这些小值对应的通道就是模型通过训练学习得出的“不重要的通道”。
3.2 通道剪枝
稀疏训练之后,对BN层所有γ值绝对值从大到小排序,人为设定一个全局剪枝比例决定哪些因子对应通道进行修剪,修剪掉该因子对应的卷积核和特征图。本文选取初始70%通道剪枝比,后续循环剪枝后达到了97%。除了对主干网络中普通的卷积层进行剪枝,本文同时对残差结构的卷积层进行剪枝。跨层连接的残差结构包含两层,一层1×1卷积,随后3×3的卷积。对第一层的通道剪枝不影响和主干网络维度匹配。对于第二层卷积层,本文通过取后面相连的卷积层修剪的通道取并集后剪枝,剪掉这些通道,不影响和之后的卷积层维度匹配。
3.3 修剪残差连接层
Darknet53网络中存在大量残差跳层可有效防止梯度消失,降低过拟合并且增加鲁棒性。但仍然存在一定冗余,剪掉对精度影响不大。由此在通道剪枝之后,近一步剪掉一定数目残差连接层。针对每一个残差层结构第一个卷积层进行评价,对各层γ求和再进行大小排序,按照设定的剪层数目,对于排名靠后的,剪掉整个残差。为了不影响SPP模块完整性,只剪掉主干网络的残差连接部分。
主干网络总共有23处残差,每剪掉一个残差同时剪掉它里面两个卷积层,即总共有69个层可以剪。本文尝试剪掉了12个残差层,总共剪36层。因为直接剪掉卷积层和连接层相当于直接减少了向前推理的层数,模型由113层变成71层,通过测试推理速度确实能够得到较大提升。
4 实验结果与分析
4.1 实验环境与评价指标
本文训练和测试环境为:谷歌GPU云计算平台,使用NVIDIA Tesla P100-PICIE显卡,显存大小16 GB,采用Pytorch框架。
本文采取平均精度(mAP)、准确率、召回率、F1值、FPS作为评价指标。其中F1值是对准确率和召回率的综合得分,计算方式为:

准确率和召回率越大越好,因此F1值越大模型性能越好。
模型测试的置信度阈值选取0.001,IOU阈值选取0.5,无批处理,单张图片测试。
4.2 数据增强结果分析
从表1各模型性能测试对比结果和图10数据增强和GIoU训练过程曲线对比可以看出,GIoU损失函数改进使模型(YOLOv3-SPP-G)的总体性能有了很大的优化。以GIoU作损失模型精度相比原始MSE损失模型(YOLOv3-SPP-M)在三个分辨率下mAP分别上涨了6.4、9和9.5个百分点,F1值也有全面提升,平均上涨8个百分点。从图10训练曲线对比也可看出,GIoU定位损失训练过程中收敛更快,相比原始MSE损失训练效率更高。
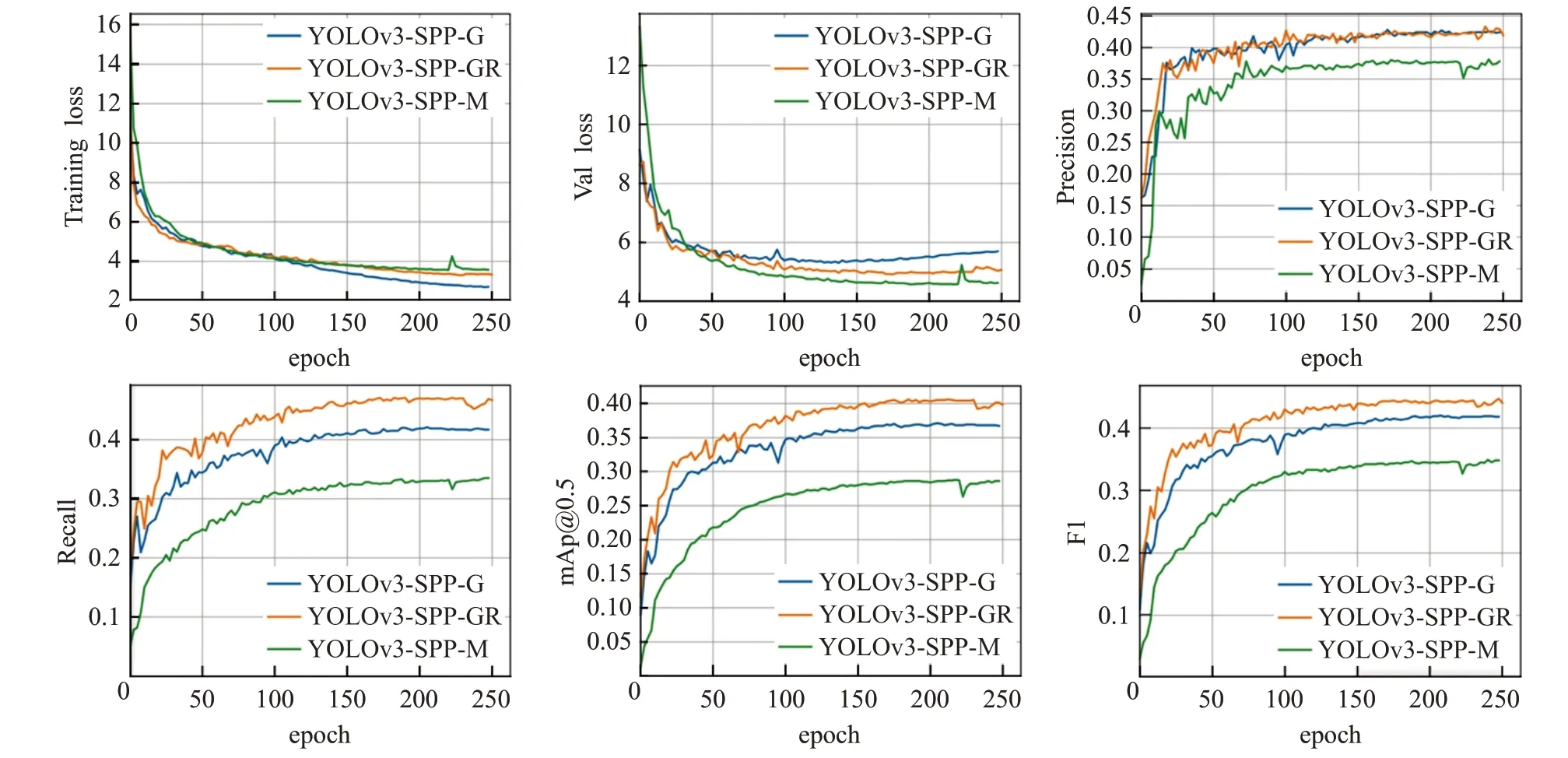
图10 MSE,GIoU,GIoU+数据增强训练过程曲线对比Fig.10 Training curve of MSE,GIoU and GIoU+data enhancement

表1 文中所有模型性能测试对比Table 1 Evaluation results of baseline model and pruned models
再对比未使用本文数据增强的YOLOv3-SPP-G和采用本文数据增强模型(YOLOv3-SPP-GR),采用增强训练的模型测试性能进一步提升。640和832分辨率大小mAP上涨4.2个百分点,F1值也有大约3.2个百分点的提升。
从图10训练过程曲线看,用GIOU做定位损失的模型精确率(Precision)和召回率(Recall)都有提升,F1和mAP也同时提升。说明GIoU损失确实能有效规范预测框的位置,从而整体上让定位精度更高。采用本文数据增强方案的模型,在准确率上几乎没有提升,也就是正确分类和定位的能力没有提升,而召回率有所增加,说明模型能找到检测出目标的能力提升了。结合两个改进后的YOLOv3-SPP模型在各个指标都超过最新的YOLOv5s和YOLOv5m模型。
4.3 剪枝和剪层结果分析
本文展示两个通道剪枝比例结果,分别为70%剪枝比例的小压缩比模型(YOLOv3-SPP-GR70-s12)和97%剪枝的大压缩比模型(YOLOv3-SPP-GR97-s12),最模型测试结果数据如表1所示,为了对比剪残差层的效果,70%压缩分别有剪层(YOLOv3-SPP-GR70)和不剪层版本(YOLOv3-SPP-GR70-s12)。
图11 为表中各压缩模型性能数据直方图比较结果,直观地展示了640分辨率下各压缩模型评价效果。通道剪枝和剪残差层后模型无论是参数量、FLOPS、模型大小都得到大幅压缩。其中剪枝97%结合剪12层残差后的模型大小为10 Mb,压缩到原始的4.1%。参数量为2.7 Mb,减小为原始的4.3%,甚至比YOLOv5s更小。
在性能上,相比压缩剪层之前,大压缩比模型mAP仅下降了约2%,小压缩比模型则下降更少。各分辨率下精度依然均高于YOLOv5两个最新模型。对比YOLOv3-SPP-GR70和YOLOv3-SPP-GR70-s12剪 层 和不剪层结果发现,各性能指标不降反升。说明剪掉一定数量模型残差连接并不会影响性能表现,反而在某些数据集上达到正向效果。
在前向推理速度上,剪层和不剪层对速度影响较大。对比YOLOv3-SPP-GR70和YOLOv3-SPP-GR70-s12,剪掉12层就达到了通道剪枝70%的同等以上的加速效果。压缩后模型速度大幅提升。97%压缩和剪层后的模型推理速度大约是原始模型3倍,其中416分辨率达到167 FPS,同样超过了YOLOv5s(116 FPS)以及
YOLOv5m(83 FPS)。修剪,进一步缩减了模型大小,减小了前向推理层数和参数,在实验中该方法能获得较大加速效果。是一个实用的保证精度下的轻量化方法。但由于网络宽度木桶效应,加速效果没有随着参数量的大幅减小而同等比例增加,仍需要进一步研究。
5 结束语
本文基于YOLOv3-SPP网络,针对航拍数据集类别不平衡和密集小目标等问题,提出类别均衡化和随机场景组合的数据增强训练方法,提升了训练效率和模型精度。针对无人机等算力低下设备,提出一种改进模型压缩轻量化方法。在通道剪枝的基础上,结合对残差层的
猜你喜欢
保健医苑(2022年5期)2022-06-10
网络安全与数据管理(2022年3期)2022-05-23
计算机工程与设计(2021年4期)2021-04-22
成都信息工程大学学报(2021年6期)2021-02-12
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
天津诗人(2017年2期)2017-03-16
新校长(2016年8期)2016-01-10
河南科技(2015年8期)2015-03-11
商事法论集(2014年1期)2014-06-27
