
面向网络入侵检测的GAN-SDAE-RF模型研究
2021-11-12 15:08韩忠华尚文利
计算机工程与应用 2021年21期
安 磊,韩忠华,2,林 硕,尚文利
1.沈阳建筑大学 信息与控制工程学院,沈阳110168
2.中国科学院 沈阳自动化研究所 数字工厂研究室,沈阳110016
3.中国科学院 沈阳自动化研究所 工业控制网络与系统研究室,沈阳110016
4.中国科学院 网络化控制系统重点实验室,沈阳110016
5.中国科学院 机器人与智能制造创新研究院,沈阳110016
随着大数据时代的来临,网络数据呈现出数据量大、维度高且不平衡的特性,在进行入侵检测前,对数据进行不平衡处理和特征降维至关重要[1-4]。目前已有众多学者对基于机器学习的入侵检测方法进行了大量研究,文献[5]提出了基于随机森林的高维不平衡数据分类方法研究,利用生成少数类样本方法(Synthetic Minority Over-sampling Technique,SMOTE)降低数据集的不平衡度来提高少数类的检测率;文献[6]提出了基于卷积神经网络(Convolutional Neural Networks,CNN)和支持向量机(Support Vector Machine,SVM)的报文入侵检测方法,此方法学习速度较快,泛化性能好但面对海量样本时检测速度较慢;文献[7]提出了基于PCA-LSTM(Principal Components Analysis-Long Short Term Memory)的入侵检测方法,此方法在处理小样本数据集时检测准确率较高,面对大量样本时性能较差;文献[8]采用基于欠采样的随机森林算法用于文本分类,在不平衡数据分类上提高了准确率和效率;文献[9]提出一种针对不平衡数据的过采样和随机森林改进算法,通过过抽样法增加少数类的识别率。文献[10]在N-Nakagami信道的基础上,提出了基于BP神经网络的移动安全性能智能预测方法,该方法的预测性能更好。
尽管上述入侵检测方法取得较好的效果,但是现有的研究都是通过采用随机过采样,随机欠采样和SMOTE解决数据的不平衡问题。随机过采样会扩大数据规模增加训练时间,易陷入过拟合;随机欠采样会盲目地删除一些重要信息,影响分类准确率;SMOTE生产的样本不具有多样性[11]。因此,本文提出利用生成式对抗网络(Generative Adversarial Network,GAN)来解决数据不平衡问题。GAN是一种新的生成模型[12],它通过学习目标数据样本的概率分布,从而生成极大相似于目标数据样本的伪造样本,是直接比较伪造样本和目标样本的分布来进行训练生成的新的生成式模型,通过对抗的方式不断地生成最大可能逼近真实样本的伪造样本,提高伪造样本的生成质量,有效解决了传统生成模型在生成过程中由于训练样本不足而导致的过拟合问题[13-15],目前很少被运用在解决入侵检测数据不平衡问题上。
栈式降噪自编码器(Stacked Denoising Autoencoder,SDAE)处理大样本和高维数据相比传统机器学习方法具有学习速度快,泛化性能好,抗噪性强等优点[16]。在数据降维问题上,主成分分析法(Principal Components Analysis,PCA)在面对大量的数据样本时,会产生数据特征表达不完整导致检测误报率上升的问题,宋永强[17]提出一种基于SDAE的物联网分层入侵检测模型,实验表明经SDAE处理后的入侵数据的准确率、误报率和漏报率较PCA方法提高了10.46%,较KPCA提高了8.64%,更适应高维空间的特征提取任务。因此本文采用了栈式降噪自编码器SDAE对高维数据进行空间降维重构。SDAE(Stacked Denoising Autoencoder)在AE(Autoencoder)的基础上对数据信息加入了噪声处理,增强了自编码网络输入层的鲁棒性,并且在DAE(Denoising Autoencoder)的基础上加入了丢失包技术增强了自编码网络之间级联的鲁棒性。
随机森林(Random Forest,RF)是Breiman在2001年提出的一种集成训练算法,作为应用在入侵检测领域中较好的分类算法,集成多个决策树模型所形成的分类器,与神经网络和SVM相比具有检测精度高,调整参数少和易并行化处理等优势。舒斐等人[18]提出基于深度置信网络(Deep Belief Network,DBN)和RF的电网工控系统异常识别方法,该方法在保证高检测精度下极大减少了训练时间,然而由于在识别前没有对数据进行不平衡处理和抗噪降维重构,容易导致输出结果在噪声影响下鲁棒性较差。因此当数据为不平衡数据时随机森林算法对少数类的分类精度不高[19];当数据中冗余属性较多时会影响随机森林算法的速度和精度[20]。近年来,SDAE多次应用在入侵检测领域,但是目前尚未与随机森林方法结合使用。
综上所述,为解决入侵检测数据不平衡且维度高导致整体检测率和罕见攻击类检测率低的问题,本文提出了一种基于GAN-SDAE-RF的网络入侵检测模型,首先利用GAN方法对网络数据进行不平衡处理,在处理后分布平衡的数据集上使用SDAE对高维数据进行特征降维,构建随机森林,建立出可有效识别并处理高维、不均衡入侵数据的入侵检测模型。利用UNSW-NB15数据集进行实验验证,与LSTM、DBN、CNN、SVM和KNN相比结果表明本文提出的检测模型性能更好,正确性和创新性得到了验证。
1 相关工作
1.1 生成式对抗网络
GAN是由Goodfellow等在2014年提出的一种新型生成模型,属于深度学习算法的一种[21]。它的结构属于二人零和博弈,一方的收益为另一方的损失。GAN是由判别模型(Discriminative model,D)和生成模型(Generative model,G)构成的,生成模型G采用特定的方式模拟出某种数据的概率分布,使之与某种目标数据的概率统计分布相同或者尽可能相似。在整个算法最初开始时根据将噪声z输入到G来生成一些数据,D从真实数据和G生成的数据中判断出哪些是G生成的伪造数据。如图1所示,整个过程相当于G和D的博弈过程,G的目的是让它生成的数据不能被D轻易识别,D的目的是尽可能准确地判断数据的来源,不断迭代优化这个过程,最终达到稳态,此时G能够生成接近真实数据分布的伪造数据,并不是单纯的真实数据的复现,通过G生成的伪造数据实现数据扩充的作用。其核心思想可用数学公式表示如下:

图1 生成式对抗网络框架图Fig.1 Generative adversarial network framework
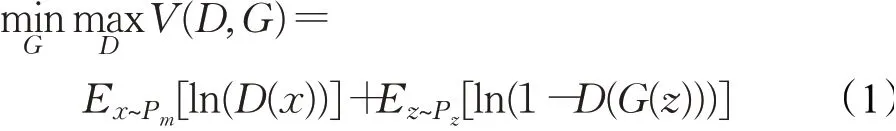
式中,V(D,G)是损失函数;Pm是真实数据分布;Pz是生成数据分布;G(z)表示G通过输入噪声z生成的伪造样本;D(x)表示D判断x为真实数据的概率;D(x)和G(z)交替的最大化和最小化损失函数,最终求出近似最优解的生成式模型。
1.2 栈式降噪自编码器
针对目前的网络数据具有维度高且复杂的特点,本文将自编码网络用于数据的特征提取。深度学习具有强大的数据特征提取能力,采用自编码器(AE)可以实现无监督的对输入数据特征的挖掘和提取,并对高维度数据进行降维。AE的学习目标是使输出数据向量x′尽最大相似重构等于输入数据向量x。
降噪自编码器(DAE)是在自编码器的基础上加入噪声构成的。单层的DAE结构见图2(a)图。DAE的基本过程为:首先在原始数据x中添加噪声数据,使用随机映射函数qD将x转换为x′,然后通过编码函数f将含有噪声数据的x′求得编码后的特征y=f( )

Wx+p,再通过解码函数g得到解码数据这里的f和g为激活函数,设置为sigmoid函数。通过优化重构误差J(x,x͂)来对DAE的参数进行调整,使用梯度下降法最优参数为保存隐藏层参数W(1)作为后一层DAE的输入,进行异常特征的逐层提取,在多个降噪自编码器上下级联形成栈式结构时,再将每个DAE的编码矢量合并构成一个N层的神经网络。逐层训练,反复迭代DAE过程,直到模型到达最后输出层,就可以得到深度结构栈式降噪自编码器SDAE其过程如图2(b)图和图3所示。
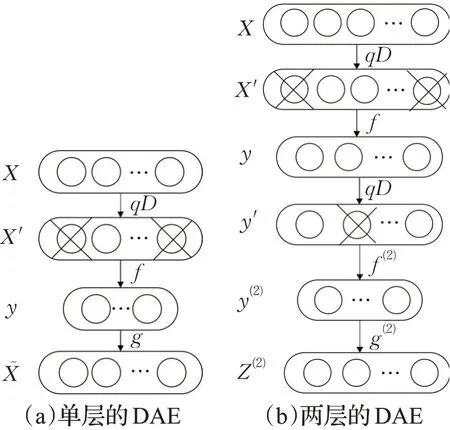
图2 SDAE结构Fig.2 SDAE structure

图3 SDAE特征提取Fig.3 SDAE feature extraction
SDAE的训练过程:第一阶段,无监督的逐层训练参数,每个隐含层即为每个DAE预训练过程逐层提取的特征,第二阶段,对整个栈式结构的参数进行整体调整,得到模型最优解。
1.3 随机森林算法
随机森林是由Breiman在2001年提出的一种集成学习算法,此方法可以被看作是多个决策树的集合,如图4所示。随机森林利用Bagging算法对原始数据集进行随机采样,得到各个数量相同但互不相同的数据子集。首先,N棵决策树对应N个数据子集,由指数最小原则选出M个特征变量中m个属性中的最优划分。节点的属性分类采用CART算法,对于数据集D,使基尼指数尽可能的小,数据集中被选中的样本分错的概率越小。选中的属性个数为随机特征变量,依次训练大量的决策树,然后将所有的决策树形成森林。
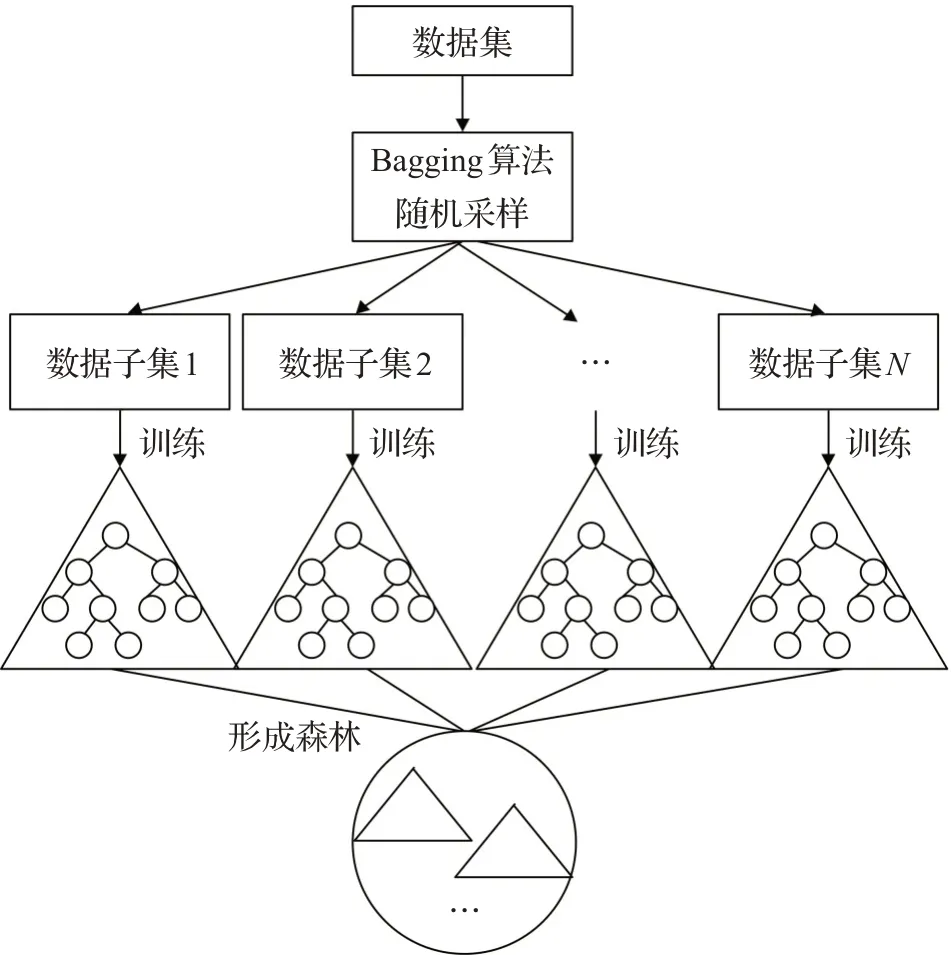
图4 随机森林图解Fig.4 Random forest illustration
随机森林的分类结果是在考虑所有决策树结果的基础上进行综合投票后产生的,样本的最终分类为所获票数占总得票数比值最大的类别。在进行数据分类时,随机森林算法拥有良好的抗噪性,能处理缺失值和异常值,由于引入了部分随机性,令随机森林具有了更好的鲁棒性。但是在面对高维和不平衡数据集时单独采用随机森林方法不能确定数据样本相关性最小以及少数类数据分布是否均衡,导致分类精度低,因此在训练随机森林分类器之前需要对数据进行不平衡扩充以及特征降维。
2 入侵检测模型研究
GAN是一种采用对抗的方式学习真实样本分布的生成式模型。该模型无需预先建模,即可生成高质量的新样本。在入侵检测过程中由于某几类异常数据数量极少,导致入侵检测使用的数据集数据分布不平衡,因此本文运用GAN生成少数类训练样本,减少不平衡训练样本对检测准确率的影响。
SDAE是一种深度学习方法,包含输入层,N个隐含层和输出层,以DAE为基本单元,顺序逐层堆叠构成深度网络结构,具有深层的特征提取能力,并且利用DAE的降噪特性使模型的泛化能力增强。可以将高维数据最大可能的降维,得到最具有特征的数据,得到重新构成的原始数据,更容易被随机森林学习。
随机森林算法集成多个决策树模型所形成的分类器,具有检测精度高,调整参数少以及易于并行化等优势,但其缺点在于当数据集维度过高时算法的训练时间长、检测精度低;当数据集分布不平衡时算法对少数类样本的检测能力极低。考虑到网络数据具有维度高、不平衡等特性,鉴于GAN、SDAE和随机森林算法独有的良好性能,充分利用GAN和SDAE的优点将两种方法相结合,针对传统随机森林算法的缺点去处理网络数据进而提高随机森林算法的分类准确率。在运用GAN生成少数类样本后,结合生成的少数类样本和原始数据集,构成一个新的且样本分布均衡的数据集,并通过Bagging算法将新的数据集抽样产生多个样本分布均衡的数据子集,然后采用SDAE将每个数据子集进行特征降维,每个降维后的数据样本分别对应每一棵决策树,进行训练。在检测阶段通过结合每棵决策树的分类结果进行投票,最终汇集所有决策树形成森林并得出分类结果,构建基于GAN-SDAE-RF的网络入侵检测模型。整体框架如图5所示。

图5 基于GAN-SDAE-RF的网络入侵检测模型框架Fig.5 Network instrusion detection model framework based on GAN-SDAE-RF
2.1 少数类训练数据扩充
利用GAN生成对抗网络对训练数据中较少的攻击类型Analysis、Shellcode、Backdoor、Worms进行数据生成,通过类别内扩充,具体步骤为:
步骤1首先分别分离出只包括Analysis、Shellcode、Backdoor、Worms攻击类型的四个真实数据集。
步骤2依据GAN模型输入格式要求将128的数据转换为12×12的矩阵向量,剩余的16维补0。
步骤3给定生成模型一个取值范围在[−1,1]的144维噪声s,将该生成的假数据与分离出来的真实数据进行混合,训练判别器。
步骤4根据设定的迭代次数进行判别模型的训练迭代,直至判别结果最优,此时固定判别模型的参数,将判别的结果反馈给生成模型。
步骤5根据设定的迭代次数进行生成模型的训练迭代,直至判别结果最差,此时固定生成模型的参数,不断迭代此过程,直至GAN模型平衡。
步骤6将生成的少数类数据作为扩充样本与原始数据进行补充,将扩充的样本重组为144维特征,取前128维数据作为扩充的样本,得到平衡的训练数据集。
2.2 SDAE训练过程
利用SDAE对扩充后的数据进行特征提取,如图6所示,训练过程为:

图6 SDAE训练过程Fig.6 SDAE training process
步骤1构建第一个DAE,设定每个规则θj:x1,x2,…,xn,θj为对象网络的隐含层神经元,x1,x2,…,xn为输入层神经元集。
步骤2确定θj和x1,x2,…,xn之间的连接权重Mθj,当输入神经元对应规则中的激活元素,那么M=1,否则M=-1,剩余与θj关系不大的权重设为较小的随机值。神经元偏差设为随机值。
步骤3利用反向传播算法训练网络,更新连接权值。
步骤4对每一个DAE重复步骤1~3,直至全部的DAE完成训练。
2.3 模型的训练
将GAN模型生成少数类样本、SDAE特征提取和随机森林算法构建并行化设计。如图7所示,整个并行化设计思路如下:
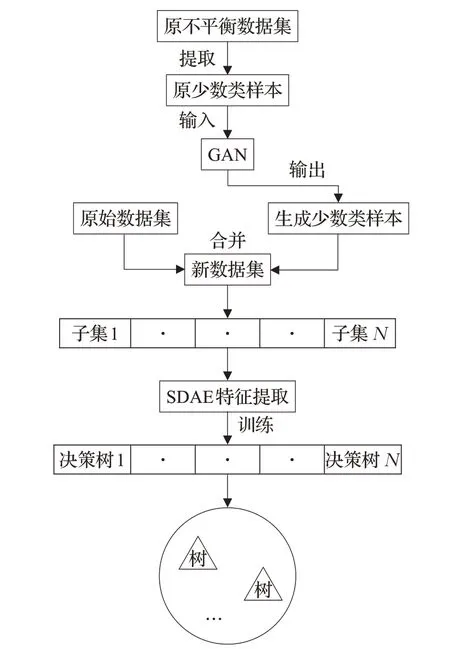
图7 模型训练过程Fig.7 Model training process
步骤1首先将网络上捕获的数据集进行数值化和归一化处理,然后GAN模型从少数类样本中进行少数类样本扩充。
步骤2将GAN模型生成的少数类样本与原数据样本整合,获得一个新的且平衡的数据集,通过Bagging算法将新的数据集随机抽样产生多个数量相等且分布平衡的数据子集。
步骤3将每个数据子集通过SDAE进行特征提取,得到重构后的新的数据子集。
步骤4每一个数据子集根据决策树的生成方式训练出相应的决策树模型。
步骤5汇集所有的决策树形成森林。
3 实验与分析
为了验证本文基于深度学习的入侵检测模型,搭建仿真实验环境,应用基于tensorflow-GPU1.13的Keras2.2.4深度学习框架进行实验仿真,操作系统为Windows10,使用英特尔i5-6300HQ 4核处理器,内存大小为8 GB,同时使用NVIDIA GTX960显卡来加快GPU的运行速度。
3.1 数据数值化和归一化
实验使用的数据集为UNSW-NB15数据集,是入侵检测领域研究的最新的数据集。该数据集由澳大利亚网络安全中心(ACCS)于2015年创建,其中涵盖了大量低占用入侵和深度结构化的网络流量信息,代表了现代网络流量模式,调整了训练集和测试集,更适合用于模拟目前的复杂的网络环境,使测试结果更好[22-23]。该数据集有9种不同的现代攻击类型,49个特征,比NSL-KDD多5种攻击类型,包含2 540 044个样本,包含9类攻击,分别为Fuzzers、DoS、Analysis、Reconnaissance、Exploit、Shellcode、Worm、Backdoor、Generic。每一条数据具有47维特征和1个具体攻击类别标识、1个攻击与正常类别标识。
(1)应用独热编码对字符型特征数值化。
数据集中protocol_type、service和state包含字符型特征,则首先需要将字符型特征应用独热编码转换为数值型特征,protocol_type包括TCP、UDP、ICMP的3种类别,则转换为数值型特征为三维特征[1,0,0]、[0,1,0]、[0,0,1],对于service有70种情况,因此数值转换为70维特征,state有11种情况,因此数值转换为11维,通过数值化处理后,整个数据集就变成了130维数值型特征,其中前128维为特征,后二维为类标签。
(2)归一化处理。
处理完字符型特征后,数据集中的特征分为两个属性,连续型和离散型,这就使得不同特征之间差异较大,故需要将数据集中的特征值归一化至[−1,1]区间,本文运用min-max标准化方法进行归一化处理,这样只是对数据进行了压缩处理,并没有改变数据的原始性信息[24]。转换公式如下,ymin和ymax分别表示原始特征值的最大值和最小值,y则代表转换前的特征值。

将数据集划分为两部分包括训练数据集(175 341个样本)和测试数据集(82 332个样本)[25],具体见表1。
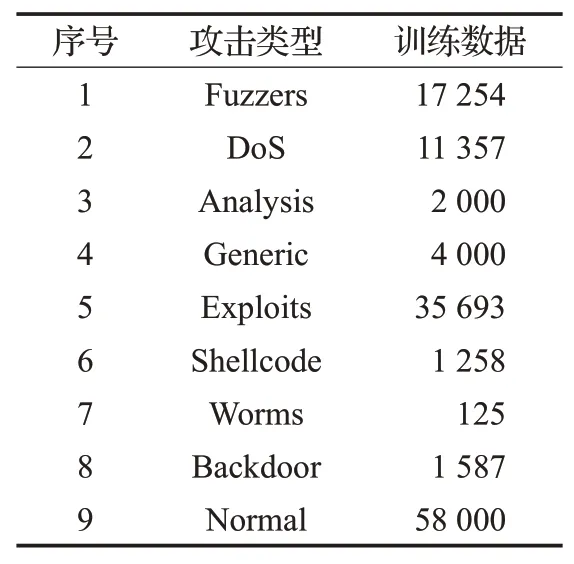
表1 数据集明细Table 1 Data set details
3.2 评价指标
为了验证不同模型的检测性能,需要根据模型的检测样本类别和样本实际类别进行计算,本文主要采用准确率(ACC)、均方误差(MSE)、误报率(FPR)和漏报率(FNR)对模型进行评估,假设ti代表第i个样本的实际类别,t′i代表第i个样本的检测类别,样本集为n,漏报事件m项,误报事件f项。当ti=t′i时,代表模型检测准确。则在样本集n上的准确率为:

其中,L(x)代表检测函数,当样本集中所有的检测结果类别与样本实际类别相同时,准确率为1。
均方误差是衡量误差的平均值,评价数据变化程度的一种方法,计算公式如下:

误报率为:

漏报率为:

因为网络入侵检测数据复杂,评价模型好坏的标准难以界定,因此本文通过ACC、MSE、FPR和FNR对各模型检测结果进行综合对比,验证模型的精确性和稳定性。
3.3 参数设置
本文从Analysis、Shellcode、Backdoor、Worms类攻击样本中分别选取了2 000、1 258、1 587、125个真实数据样本对GAN进行训练。GAN的初始参数包括batch-size设置为50,epoch为100,学习率设置为0.000 2,选取relu函数作为模型的激活函数,使用Adam优化器。以Analysis类攻击样本为例,最终生成器损失和判别器损失变化曲线如图8和图9所示,从图中可以看出训练次数到达5 500次左右,生成器和判别器的损失开始收敛。

图8 生成器损失曲线Fig.8 Generator loss curve

图9 判别器损失曲线Fig.9 Discriminator loss curve
通过SDAE对处理完不平衡问题的训练数据样本进行降维操作,SDAE作为深度学习模型,它的初始参数是由逐层贪婪训练最小化原始数据和重构数据的重构误差所得到的权重。通过BP算法微调初始参数的交叉熵来确保最小重构误差,从而得到最优结果。输入层节点数与数值化处理后的数据特征值保持一致,这里设为122,通过不同SDAE网络结构对比实验,采用四层网络结构准确率最高,DAE1为122-100,DAE2为100-60,DAE3为60-30,DAE4为30-5。每层的神经元个数分别为122、100、60、30、5,batch-size设置为64,epoch设置为3 000。如图10所示,选取均方误差作为衡量重构误差的标准,可以看出训练5次时MSE趋于稳定。设置各层DAE及SDAE模型的训练次数为10次,通过实验分析噪声比例对准确率的影响,如图11所示,噪声比例在[0.2,0.6]区间准确率最高,结合多次实验结果选取均值,因此本次设置为0.4。

图10 SDAE训练次数Fig.10 SDAE training times

图11 噪声比例与准确率影响图Fig.11 Influence graph of noise ratio and accuracy
选取categorical_crossentropy为损失函数,其专门用于多分类问题,设置bach_size为64,epoch为10,运用Adam优化算法对模型进行反向传播训练。
通过仿真实验,综合整体的随机森林模型性能,如图12所示,算法最终选择的森林规模为550棵,决策树最深度为12,权重分别为1、3、1、5、3.5。

图12 森林规模与算法性能影响图Fig.12 Forest scale and algorithm performance impact map
3.4 结果与分析
通过运用GAN分别对训练集中Analysis、Shellcode、Backdoor、Worms类攻击样本进行扩充,分析不同训练集扩充比例对于少数类检测率的影响,当比例为0%、40%、80%、120%时进行4组对比实验,结果如表2所示。经过实验得出扩充比例为80%时准确率最高,因此本次扩充比例均选用80%。

表2 不同扩充比例的准确率Table 2 Accuracy of different expansion ratios %
为了证明该入侵检测模型的效果,选用相同的训练集和测试集,分别采用仅通过SDAE提取数据特征的随机森林算法(SDAE-RF)和仅通过主成分分析处理后的随机森林算法(PCA-RF)还有传统的随机森林算法(RF)进行对比实验,模型性能结果比较如表3所示。

表3 模型对比Table 3 Model comparison %
为了验证经过GAN扩充少数类样本后是否提升了算法性能以及经过SDAE处理后的随机森林模型的可行性、准确性和优势,与SDAE-RF和PCA-RF还有传统的RF进行对比。由图13可知,应用SDAE后的随机森林模型对网络入侵数据分类准确率相比于传统的RF模型和PCA-RF模型,分别提升了19.4%和8.9%,通过GAN模型补充少数类样本后对分类准确率提升了1.42%。

图13 算法准确率对比Fig.13 Algorithm accuracy comparison
图14 比较了GAN-SDAE-RF、SDAE-RF、PCA-RF以及RF的均方误差。由图14可知,GAN-SDAE-RF模型的均方误差最低,相比于传统的RF模型,降低了87.4%;相比PCA-RF模型,降低了75.3%;相比SDAE-RF降低了39.63%,由此可知,基于GAN-SDAE-RF的网络入侵检测模型大幅度地降低了网络入侵检测的误差。

图14 算法均方误差对比Fig.14 Algorithm mean square error comparison
为了验证本文提出的基于GAN-SDAE-RF的网络入侵检测模型的优势,选用相同的训练集和测试集,将GAN-SDAE-RF与目前流行的深度学习模型CNN、LSTM模型以及DBN(Deep Belief Networks)深度信念网络模型进行复杂度对比实验。
结果如图15所示,从图中可以看出随着测试样本个数的增加,GAN-SDAE-RF的检测时间比LSTM和DBN的少并且逐渐时间差逐渐拉大。与CNN相比检测时间稍微高一些,但总体相差有限。然后将本文的方法测试结果与其他机器学习方法进行比较,如表4所示。

图15 不同样本个数下检测时间比较Fig.15 Comparison of detection time under different number of samples

表4 与其他方法对比Table 4 Compared with other methods %
通过与目前常用的入侵检测算法对比可以看出,一些经典的机器学习算法例如SVM和KNN算法实验效果较差,整体漏报率非常高,而深度学习算法在整体指标上均优于SVM和KNN,但是对于罕见攻击类的检测率并不高,其中本文提出的基于GAN-SDAE-RF与其他方法相比整体准确率平均提高了9.39%,误报率平均降低了9%,漏报率平均降低了15.24%。并且对于罕见攻击类Analysis、Shellcode、Backdoor、Worms,本文方法的准确率分别为90.13%、88.68%、89.26%、86.58%相比其他方法分别平均提高了26.8%、27.98%、27.85%、39.97%。由此可以证明本文方法的系统性能好且具备创新性。
4 结束语
本文针对目前大数据时代网络入侵检测存在的问题,提出了新的基于GAN-SDAE-RF的网络入侵检测模型,运用无监督的GAN神经网络对网络流量数据样本的不平衡性进行扩充,不仅能够保留多数类数据样本的检测精度,还能够提高数据少数类样本的检测精度,运用栈式降噪自编码器保留了数据样本的特征,极大程度地对数据进行重构,提取特征,并将空间特征输入到随机森林算法中,各个决策树进行投票决策出异常类别。运用具备更多数据特征的UNSW-NB15数据集对模型进行训练与测试,实验结果表明,本文GAN-SDAE的随机森林入侵检测模型在检测精度、误报率和漏报率上取得了良好的效果。目前该模型仅在数据集中测试效果良好,还需要在实际网络环境中进行应用测试,验证该模型在实际网络环境下真实的性能。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
中国交通信息化(2018年5期)2018-08-21
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
