
基于HardSoftmax的并行选择核注意力
2021-11-12 14:58闵卫东段静雯
计算机工程与应用 2021年21期
朱 梦,闵卫东,张 煜,段静雯
1.南昌大学 信息工程学院,南昌330031
2.南昌大学 软件学院,南昌330047
3.江西省智慧城市重点实验室,南昌330047
作为下游网络,卷积神经网络(Convolutional Neural Networks,CNNs)在计算机视觉中发挥了重要的作用,比如目标检测、语义分割、图像生成等。更好的、更快的卷积神经网络架构一直是研究的热点。而且,卷积神经网络已经被应用到许多实际项目中,比如交通管理[1-3]、摔倒检测[4-7]、人脸识别[8-10]等。网络深度已经被许多工作[11-13]证明是非常重要的。但是深层网络存在退化的问题:随着网络深度的增加,准确率变得饱和,然后急速下降。为了解决深层网络退化的问题,ResNet[14]提出了残差连接。ResNet开启了卷积神经网络架构设计的新纪元,以致于后来的卷积神经网络都开始借鉴残差连接的思想。
PreResNet[15]证明了残差连接的重要性,并提出了预激活残差模块。Wide ResNet[16]通过加ResNet的宽度,从而更加有效地提升ResNet的性能。ResNeXt[17]将分组卷积融合到残差瓶颈模块中,提出了多路信息传输的结构。Inception系列[18-20]提出了多路的、多核的级联连接模块。DenseNet[21]提出了密集级联连接模块,有效地减少了网络参数量。DPN[22]通过结合残差连接和密集级联连接,使特征既能重利用,又能再发现。
最近,各种不同形式的注意力被应用到卷积神经网络中,有效地提升了网络的性能。图1列举了卷积神经网络中三种经典的注意力。SENet[23]开创性地提出了Squeeze-and-Excitation(SE)通道注意力,自适应地重标定通道特征响应。MobileNetV3[24]考虑到SE通道注意力中的Sigmoid计算代价是昂贵的,提出了计算更轻量的HardSigmoid来替换Sigmoid。SKNet[25]提出了选择核(Selective Kernel,SK)注意力,自适应地选择不同卷积核尺寸的分支。ResNeSt[26]提出了分割(Split)注意力,自适应地选择分割分支。在这三种注意力中,SE通道注意力通过Sigmoid计算通道权重。SK注意力和Split注意力则通过Softmax计算不同分支的通道权重。
随着计算算力的提高,网络架构的设计已经从手工设计转移到自动搜索。MnasNet[27]在MobileNetV2[28]结构的基础上,引入了SE通道注意力。MobileNetV3通过引入平台神经网络适配(platform-aware neural network adaptation)和HardSwish激活函数,扩展MnasNet。EfficientNet[29]仍然在MobileNetV2结构的基础上,引入了模型复合压缩方法,在网络效率和准确率之间达到了很好的平衡。这些方法主要基于强化学习[30-32]、进化搜索[33]、可微搜索[34]或其他学习算法[31,35]。
然而,不管是手工设计的网络架构,还是自动搜索的网络架构,它们彼此不同,这会使得下游网络难以建立。但是,注意力可以在几乎不改变原来网络架构的同时,以额外的、非常轻量的参数量和计算复杂度,有效地提升网络性能。另外,注意力还可以扩大神经网络架构自动搜索的空间,并潜在地提高整体性能。因此,研究更好的、更轻量的注意力是非常重要的。本文提出了基于HardSoftmax的并行选择核(Parallel Selective Kernel,PSK)注意力。首先,针对Softmax包含指数运算,对于较大的正输入很容易发生计算溢出的问题,本文提出了计算更安全的HardSoftmax来替换Softmax。然后,不同于SK注意力将全局特征的提取和转换放在特征融合之后,PSK注意力将全局特征的提取和转换单独放在一个分支,与具有不同核大小的多个分支构成并行结构。同时,PSK注意力的全局特征转换使用分组卷积,进一步减少参数量和计算量。最后,PSK注意力通过HardSoftmax注意来关注不同核大小的多个分支。一系列的图像分类实验表明,简单地用Hardsoftmax替换Softmax,也能保持或提升原注意力的性能。HardSoftmax的运行速度在实验中也比Softmax更快速。PSK注意力能够以更少的参数量和计算量追平或超越SK注意力。

注:gap表示全局平均池化,gconv表示分组卷积。
1 HardSoftmax定义和基于HardSoftmax的并行选择核注意力
本章首先定义了HardSoftmax,然后介绍了基于HardSoftmax的并行选择核注意力。
1.1 HardSoftmax定义
Softmax的定义如公式(1)所示:
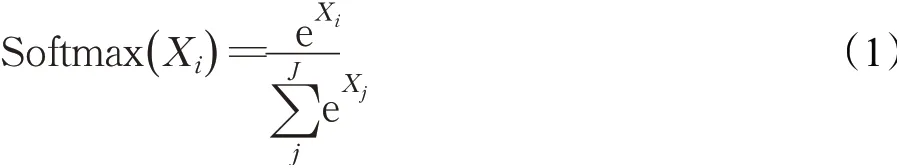
其中,Xi为第i个节点的输出值,J为输出节点的个数。通过Softmax可以将输出值转换为范围在[0,1]及和1的概率分布。众所周知,对于较大的正输入,指数运算是很容易发生计算溢出的。为了解决这个问题,常用的方法是将每一个输出值减去输出值中最大的值,从而让输出值小于或等于0,那么进行指数运算就不会发生计算溢出,如公式(2)所示:

不同于公式(2)所示的解决方法,本文的想法是寻找计算更安全的E(Xi),来模拟指数函数eXi的形状,从而保留Softmax相似的分布特性。为了设计E(Xi)来模拟eXi,本文首先提出了一个新颖的激活函数,被称为幂线性单元(Power Linear Unit,PLU),定义如公式(3)所示:

其中,α为一个预设的固定值,满足α∈(0,1],通常α=0.5。
幂线性单元的一阶导函数如公式(4)所示:
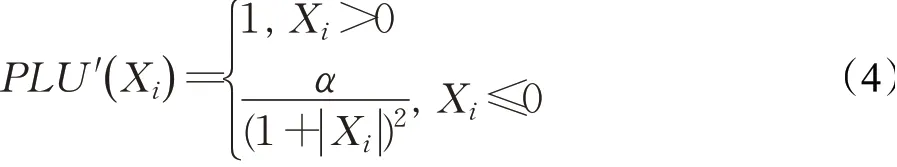
显然,∀Xi∈R,PLU′(Xi)>0,所以PLU(Xi)是严格地单调递增。当
为了更好地模拟eXi的形状,这里令α=1。那么有:-1。也就是说,当α=1时,PLU(Xi)处处可导,严格地单调递增,以Yi=-1为下界,无上界。图2绘制了当α=1时,PLU(Xi)的函数图像。

图2 当α=1时,PLU(Xi)的函数图像Fig.2 Shape of PLU(Xi )when α=1
然后,本文让PLU(Xi)向上平移一个单位,满足PLU(Xi)+1>0。最后,本文用E(Xi)=PLU(Xi)+1替换Softmax中的eXi,从而构造了计算更安全的HardSoftmax,定义如公式(5)所示:

1.2 基于HardSoftmax的并行选择核注意力
基于HardSoftmax的并行选择核注意力如图3所示,它可以抽象成公式(6):

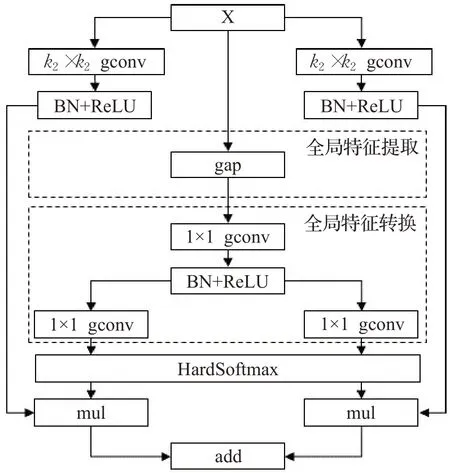
图3 基于HardSoftmax的并行选择核注意力Fig.3 Parallel selective kernel attention based on HardSoftmax
公式(6)中Cout表示不同核大小分组卷积(如图3中的k1×k1和k2×k2的分组卷积,其中k1通常等于3,k2通常等于5)的输出通道数;M表示不同核大小的分支数量(如图3中的2个分支)。其中,Xk满足公式(7),fk表示GConvk[17]→BNk[18]→ReLUk[36]。GCoutk又满足公式(8)和(9),g表示GConv→BN→ReLU→GConv。公式(9)先通过本文提出的HardSoftmax计算,再进行通道分割。

在全局特征转换模块中,1×1分组卷积的分组数等于不同核大小分组卷积的分组数。并且在全局特征转换模块中,第一个1×1分组卷积的输出通道数(即第二个1×1分组卷积的输入通道数)的按公式(10)计算:
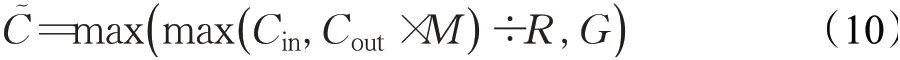
这里Cin为不同核大小分组卷积的输入通道数;R为一个正整数,通常为4;G表示不同核大小分组卷积的分组数。如果采用标准的卷积,那么按公式(11)计算:与图1(b)显示的SK注意力相比,本文提出的PSK注意力有如下不同:
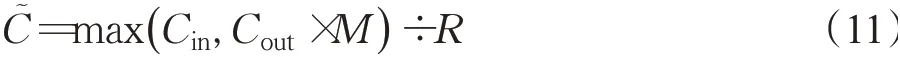
(1)全局特征的提取和转换被单独放在一个分支,与具有不同核大小的多个分支构成并行结构。那么,这些分支可以并行地运行,从而降低整体的计算延迟。
(2)全局特征的转换,使用1×1的分组卷积(group convolution,gconv)[17]。与标准的卷积相比,分组卷积已经被证明[37],可以有效地降低参数量和计算量,同时只会降低很少的性能。
(3)全局特征的转换,第一个1×1的分组卷积后面(即ReLU前面)使用了BN算法,帮助权重学习更加稳定。
(4)使用HardSoftmax注意,来关注不同卷积核大小的多个分支。HardSoftmax保留了Softmax相似的分布特性,但它的计算更安全。
2 实验及结果分析
本章展示了将SE通道注意力、SK注意力、Split注意力和基于HardSoftmax的PSK注意力分别融合到不同骨干网络的实验结果。本章也展示了SE通道注意力分别使用Sigmoid和HardSigmoid的对比结果,以及SK注意力和Split注意力分别使用Softmax和HardSoftmax的对比结果。
2.1 实验环境
本文的所有实验结果都在配置如表1描述的计算机上完成的。

表1 实验环境配置Table 1 Hardware and software setups
2.2 数据集
Fashion-MNIST。Fashion-MNIST数据集[39]由10个类别、70 000幅时尚产品图像组成。每幅图像是28×28像素的灰度图像。每个类别包含7 000幅图像。训练集包含60 000幅图像,评估集包含10 000幅图像。
CIFAR。CIFAR数据集[40]由32×32像素的RGB图像组成。CIFAR-10数据集包含10个类别,CIFAR-100包含100个类别。训练集和评估集分别包含50 000和10 000幅图像。
2.3 模型细节
本文采用两种骨干网络:ResNeXt[17]和Mobile-NetV3[24]。然后将SE通道注意力、SK注意力、Split注意力和基于HardSoftmax的PSK注意力别融合到这两种骨干网络中。值得注意的是,MobileNetV3-Small中的某些线性反转瓶颈模块本身就包含了SE通道注意力。因此,本文将MobileNetV3-Small中原来包含的SE通道注意力全部删除,再作为骨干网络。为了适合28×28和32×32像素的图像,ResNeXt和MobileNetV3都只保留最后三次下采样。另外,ResNeXt的宽度变为原来的一半,即所有层的通道数变为原来的一半。
2.4 训练细节
输入到模型的图像采用减去均值,再除以标准差的方式进行预处理。本文还使用了数据增强,包括随机旋转、随机平移和随机水平翻转。所有的模型都采用交叉熵(categorical cross entropy)损失函数和跟随文献[41]进行初始化。在Fashion-MNIST数据集上,所有的模型都使用AdamW[42]进行训练;在CIFAR数据集上,所有的模型都使用SGDM[43]进行训练。对于骨干网络为Mobile-NetV3-Small的模型,批处理大小为256;对于骨干网络为ResNeXt的模型,批处理大小为32。在Fashion-MNIST数据集上,训练周期为60,在前20个周期内,初始学习率为0.001,接下来的40个周期,每隔20个周期,学习率衰减为原来的0.1倍。在CIFAR数据集上,训练周期为150,在前80个周期内,初始学习率为0.1,接下来的70个周期,每隔35个周期,学习率衰减为原来的0.1倍。本文还采用了L2权重衰减,从而帮助训练过程更加稳定。对于所有卷积层和全连接层的权重,权重衰减率为5×10−4。
2.5 HardSoftmax的实验结果及分析
表2 显示了不同模型在Fashion-MNIST、CIFAR-10和CIFAR-100数据集上的分类准确率。Params的单位为百万(million)。MAdds表示先做乘法再做加法的运算次数,单位为百万(million)。对于骨干网络相同的不同模型,加粗表示每列的最优结果。表中的Params和multiply adds(MAdds)是跟随torchstat计算的,输入为32×32像素的RGB图像,类别数为100。不管是标准的SE通道注意力还是使用Hard-Sigmoid的SE通道注意力,当它们融合到骨干网络中,不能一致地提升原骨干网络的分类准确率。即SENet50(16×4d)和[SENet50(16×4d)+HardSigmoid]的分类准确率并不是总能优于ResNeXt50(16×4d)。同理,[MobileNetV3-Small+SE]和[MobileNetV3-Small+SE+HardSigmoid]也是如此。但是,不管是使用Softmax的SK注意力和Split注意力,还是使用HardSoftmax的SK注意力和Split注意力,当它们融合到骨干网络中,不能一致地提升原骨干网络的分类准确率。

表2 不同模型在不同数据集上的分类准确率Table 2 Classification accuracy rate of different models on different datasets
表3 显示了HardSoftmax和Softmax的比较结果。表3的结果是通过比SK注意力和Split注意力分别使用HardSoftmax和Softmax的准确率汇总而来的。结果表明,使用HardSoftmax的注意力在大多数情况下都能够超越使用Softmax的注意力。

表3 HardSoftmax优于或劣于使用Softmax的数量Table 3 Number of HardSoftmax outperforming or underperforming Softmax
计算复杂度是评价Softmax和HardSoftmax优劣的另一个重要指标。在实际评估中,本文实现的HardSoftmax是慢于PyTorch标准实现的Softmax。本文猜测PyTorch标准实现,对Softmax进行了并行加速。为了最大的公平,表4列举了PyTorch标准实现的Softmax、本文实现的Softmax和本文实现的HardSoftmax的速度比较结果。速度是通过在CIFAR-100数据集上训练和评估SKNet50(16×4d)一个周期的时间进行衡量的。结果表明,本文实现的HardSoftmax略快于本文实现的Softmax。结果也表明,本文实现的Softmax明显比PyTorch标准实现的Softmax更慢。所以,本文有理由相信,如果HardSoftmax也是PyTorch的标准函数,那么HardSoftmax的实际运行速度一定会获得更大的收益。

表4 HardSoftmax和Softmax的速度比较Table 4 Comparison of speed between HardSoftmax and Softmax
2.6 基于HardSoftmax的并行选择核注意力的实验结果及分析
基于HardSoftmax的PSK注意力的实验结果仍然列举在表2中。从结果可知,当PSK注意力融合到骨干网络中,依然能够稳定地提高骨干网络的准确率。与[SK注意力+HardSoftmax]相比,PSK额外增加的Params和MAdds更少,同时准确率也能几乎不变或提升。当骨干网络是ResNeXt50(16×4d)时,PSK注意力额外增加的Params和MAdds更多,但它的准确率总是优于[Split注意力+HardSoftmax]的准确率。然而,当骨干网络是MobileNetV3-Small时,PSK注意力额外增加的Params和MAdds更少,但它的准确率总是劣于[Split注意力+HardSoftmax]的准确率。本文认为,MobileNetV3-Small中的3×3或5×5卷积核尺寸是通过自动搜索出来的,所以不同层的卷积核尺寸已经是最优的结果,所以当骨干网络是MobileNetV3-Small时,不管是SK注意力,还是本文提出的PSK注意力,准确率都会劣于Split注意力的准确率。
表2 还显示了PSK注意力的消融实验结果。这里的消融实验是指,在PSK注意力的全局特征转换模块中,使用标准1×1卷积,再和[SK注意力+HardSoftmax]进行比较。由结果可知,随着参数的增加,[PSK注意力+标准1×1卷积]明显优于PSK注意力。表5显示了[PSK注意力+标准1×1卷积]和[SK注意力+HardSoftmax]的比较结果。表5的结果是通过比较[PSK注意力+标准1×1卷积]和[SK注意力+HardSoftmax]的准确率汇总而来的。结果表明,[PSK注意力+标准1×1卷积]是和[SK注意力+HardSoftmax]持平的。再结合表2中MAdds分析,[PSK注意力+标准1×1卷积]的MAdds是略低于[SK注意力+HardSoftmax]的。这说明,将全局特征的提取和转换被单独放在一个分支,与具有不同核大小的多个分支构成并行结构,并不会带来准确率的损失,却可以带来信息多路传输的优势,充分利用显卡的并行性,从而降低整体的计算延迟。

表5 消融实验,PSK注意力优于或劣于SK注意力的数量Table 5 Ablation experiment,number of PSK attention outperforming or underperforming SK attention
3 结束语
本文提出了计算更安全的HardSoftmax和基于HardSoftmax的并行选择核注意力。一系列的图像分类实验表明,简单地用Hardsoftmax替换Softmax,也能保持或提升原注意力的性能。HardSoftmax的运行速度在实验中也比Softmax更快速。基于HardSoftmax的并行选择核注意力能够以更少的参数量和计算量追平或超越选择核注意力。未来的工作包括在更多场景下比较HardSoftmax和Softmax的性能,以及测试并行选择核注意力的性能。
猜你喜欢
电气技术(2022年4期)2022-04-28
当代水产(2019年11期)2019-12-23
学生天地(2019年28期)2019-08-25
数学物理学报(2018年1期)2018-03-26
知识经济·中国直销(2017年5期)2017-06-15
现代工业经济和信息化(2016年4期)2016-05-17
现代养生·下半月(2015年6期)2015-09-07
电测与仪表(2015年18期)2015-04-12
中国学校体育(2014年11期)2014-05-10
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
